目錄
一、前言:
二、Fiddler 抓包工具:
三、http 協議:
1、http 請求:
1.(1)請求行:
1、(2)? 請求頭:
1、(3)? 請求正文:
2、http 響應:
2、(1)? 狀態碼:
2、(2)??響應頭:
2、(3)? 響應正文:?
四、請求行 GET 和 POST 方法的區別:
五、 https 協議:
1、https 工作過程:
1、(1)對稱加密:
1、(2)非對稱加密:
1、(3)中間人攻擊:
1、(4)通過證書解決“中間人”攻擊:
一、前言:
? ? ? ? http 和 https 協議是在應用層的協議,而 https 協議是在?http 協議基礎上加了一個加密解密的工作。
? ? ? ? 在此之前,要先了解 http 的協議格式,http 協議分為請求格式和響應格式。
二、Fiddler 抓包工具:
? ? ? ? 當前網絡環境中,純使用 http 協議的網站很少,更多都是 https 協議的,那么,由于 https 是應用層的協議,一般是查看不了的,怎么才能查看?
? ? ? ? 使用 fiddler 抓包工具,就能從當前計算機的網卡獲取到經過的網絡數據包,相當于一個 “門衛”,所有的網絡數據包想要通過(發送和接收)數據包都要經過這個“門衛”。前面說到,當前網絡環境中,純使用 http 協議的網站很少,更多都是 https 協議,所以安裝 fiddler 時要安裝它的證書才能查看 https 具體內容。
? ? ? ? 下面就是一次抓包的請求和響應結果:
????????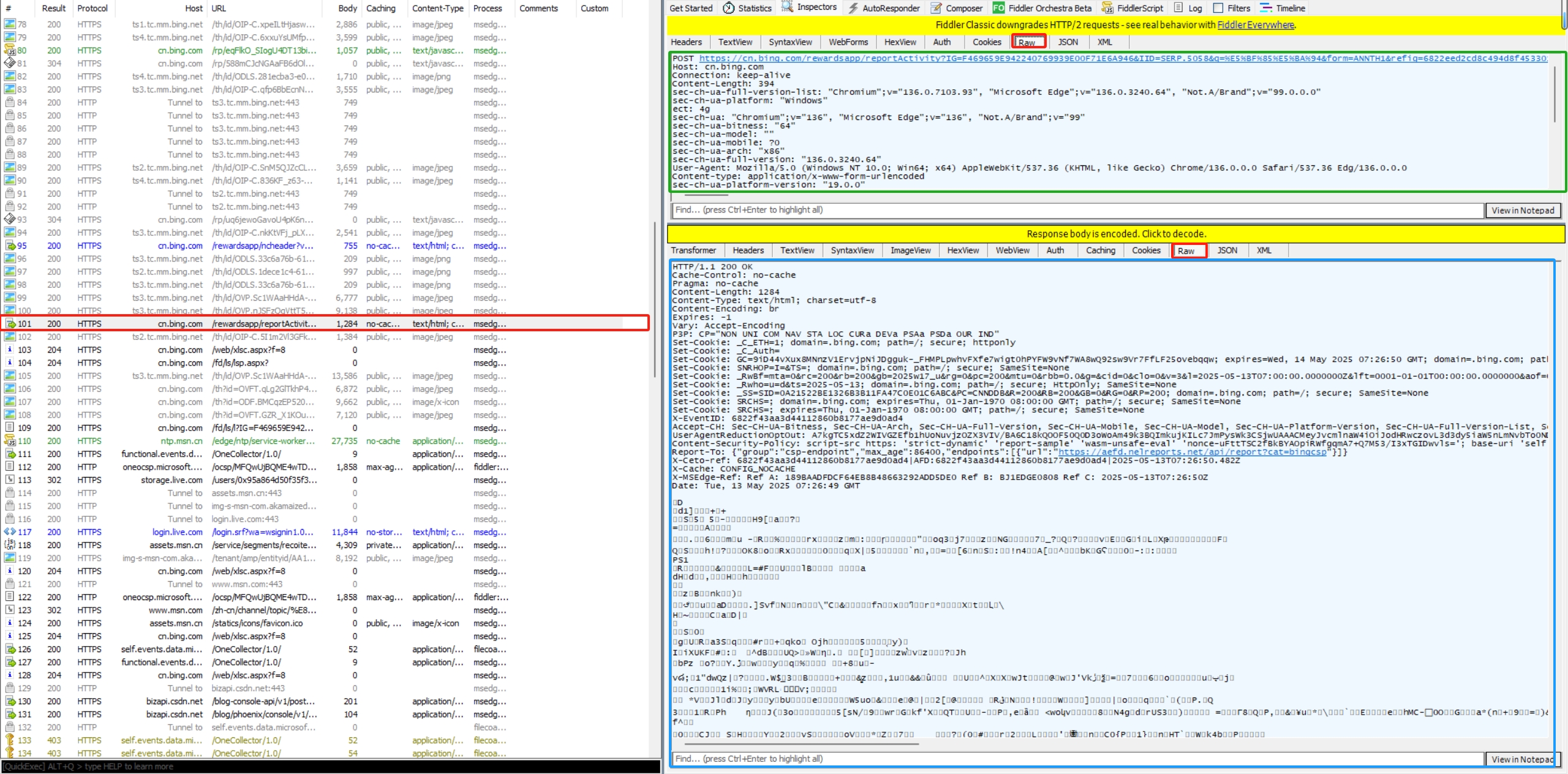
? ? ? ? ?瀏覽器網址欄輸入“bing”進入必應搜索引擎,fiddler 抓到了其中一條左邊紅色圈起來的信息,是當前一次發送的請求和響應。右邊的上面綠色圈起來的是一次請求,右邊下面藍色圈起來的是當前請求的響應結果。
????????點擊 “Raw”,就能顯示 http 的原始數據。點擊 “View in Notepad” 就能把當前的數據以行文本像形式顯現。
三、http 協議:
通過上面的 fiddler 抓包,可以知道,http 協議分為四大部分:
1、http 請求:
? ? ? ? 請求行,請求頭(header),空行,請求正文(body)。
例如:????????
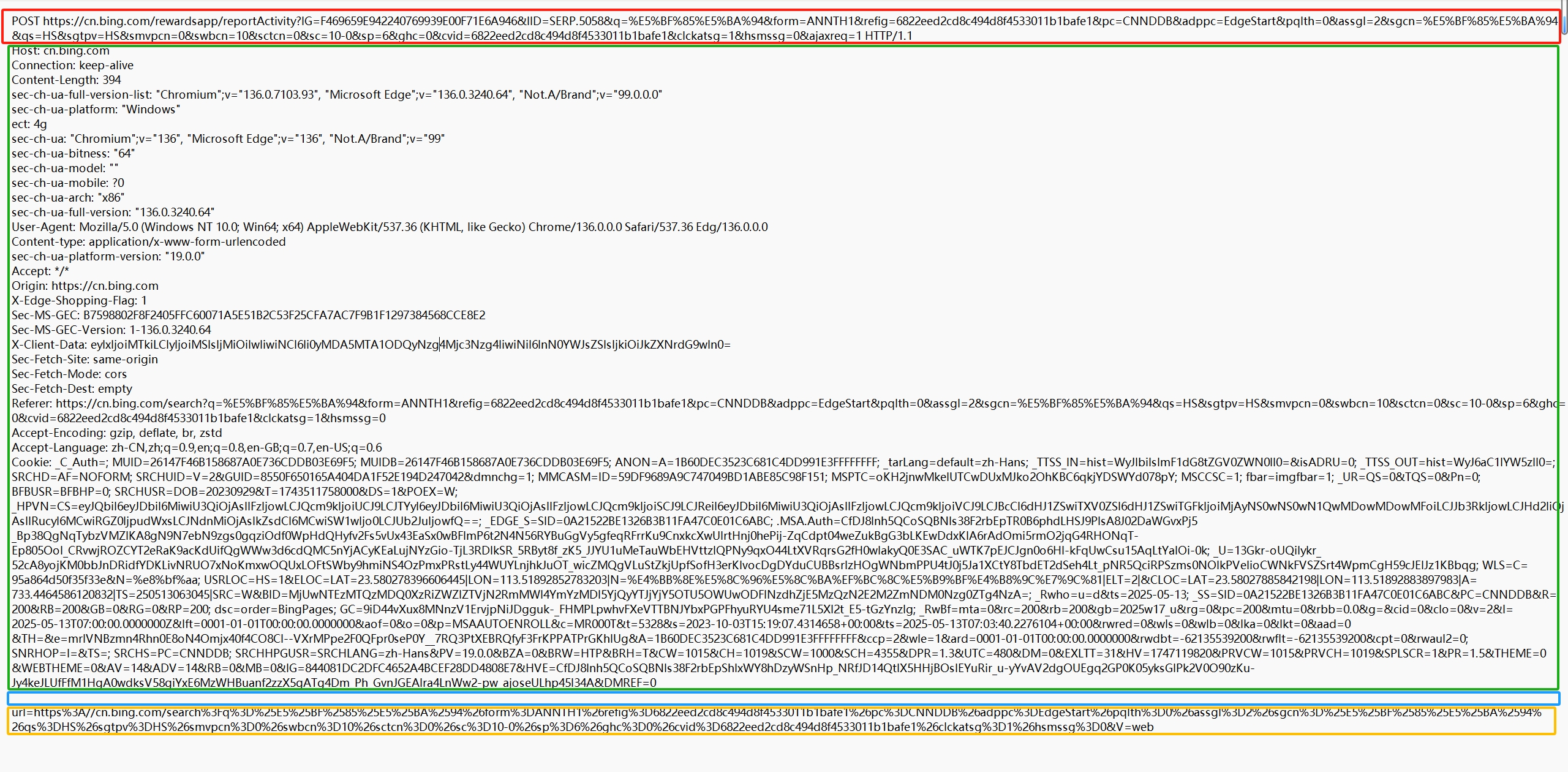
不同顏色圈起來的四個部分,從上到下分別代表,請求行,請求頭,空行,請求正文。
????????其中,空行是請求頭結束的標記。
1.(1)請求行:
請求行由三個部分組成,即:
? ? ? ? 方法 + URL + 版本。
方法
表示客戶端的請求類型:
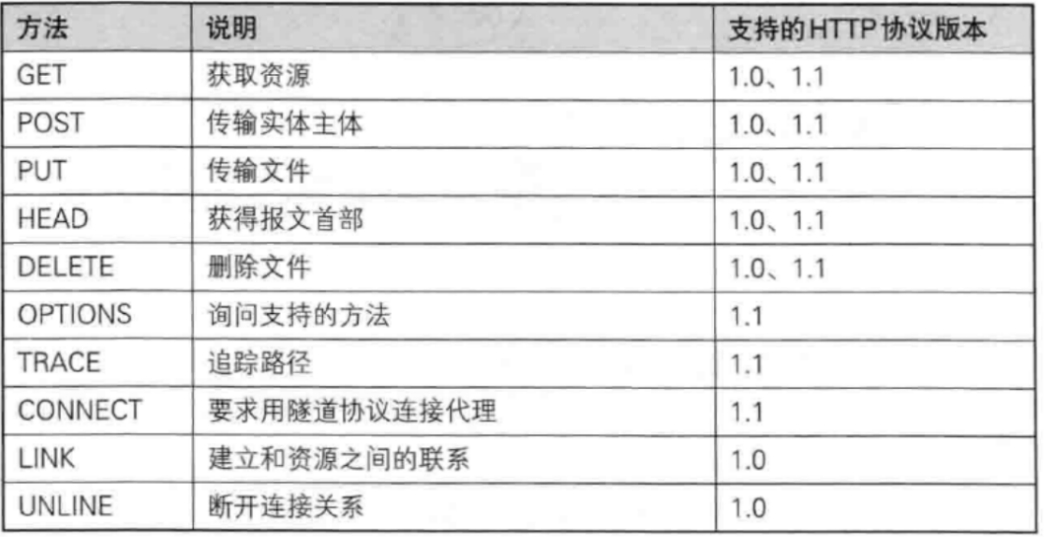
? ? ? ? 其中,GET和POST方法較為常見,但?GET 方法是最常用的 http 方法,常用于獲取服務器的某個資源,比如在地址欄輸入網址,或者在一些頁面點擊鏈接跳轉的時候,大部分都是涉及 GET 方法。
? ? ? ? 值得注意的是,GET 方法一般是沒有請求正文的。(除非開發寫代碼的時候故意構造 body 也可以)。所以,GET 想要給服務器傳遞數據的時候,往往就是通過 URL 的 路徑 / query string 來進行傳遞了。
? ? ? ? 另外,POST方法在下面的場景會用到:
????????比如在某個網站登陸的時候,輸入的用戶名和密碼,其中的請求正文(body)就包含了用戶輸入的用戶名和密碼;或者上傳圖片資源 / 文件的時候,body 里上傳的文件的二進制數據有時候會通過 base64 編碼,變成文本內容,這是為了讓服務器好處理。
???????? 值得注意的是,POST方法是帶有 body 的,通過 body 給服務器傳遞數據。
URL
????????URL 就是我們平時在地址欄輸入的內容(俗稱網址),它表示唯一資源定位符,描述了網絡上的某個資源的具體位置。互聯網上的每個文件都有一個唯一的 URL 。在一些情況下,我們在地址欄輸入的內容可能并不是完整的 URL。比如,當我們只輸入一個域名 “?baidu.com?” 時,瀏覽器會自動補全協議部分,通常默認使用 “https://”,然后形成完整的 URL 進行訪問。
? ? ? ? 完整的 URL 包含的部分:????????
?協議方案名:
? ? ? ? 比如 http 和 https 。
登錄信息(認證):
????????由于現在的網站進行身份驗證一般都不再通過 URL 進行了,一般都會省略。
服務器地址:
? ? ? ? 此處是一個 “域名”,域名會通過 DNS 系統解析成一個具體的 IP 地址。?
服務器端口號:
? ? ? ? 上面的 URL 中的端口號被省略了,當端口號省略的時候,瀏覽器會根據協議類型自動決定使用哪個端口,例如 http 協議默認使用 80 端口,https 協議默認使用 443 端口。
帶層次的文件路徑:
????????指定服務器上資源的具體位置,以?/?分隔不同的目錄和文件名。比如,你訪問一個電商網站,最初進入的是首頁,其 URL 可能是https://www.example.com/,這是網站的根目錄級別。當你點擊進入某個商品分類頁面,如https://www.example.com/category/electronics/,這里的category/electronics/就比首頁的路徑多了一個層級,它表示electronics是category文件夾下的一個子文件夾,用于存放電子產品分類相關的文件或頁面信息。如果你再點擊進入某個具體的商品詳情頁,如https://www.example.com/category/electronics/product123.html,路徑又多了一個層級,product123.html表示具體的商品頁面文件,它在electronics子文件夾下,通過這種層層嵌套的路徑結構,網站能夠準確地定位和展示不同的頁面和資源,讓用戶可以按照一定的邏輯瀏覽網站內容。
查詢字符串(query string):
? ? ? ? 用于向服務器傳遞額外的參數信息,本質就是一個鍵值對的結構,通常以 ?開頭,鍵值對之間用 & 分隔,鍵與值之間用 = 分割。
? ? ? ? 比如,我在瀏覽器輸入 “hello”:????????
? ? ? ? 得到的 URL :
https://cn.bing.com/search?q=hello&qs=n&form=QBRE&sp=-1&lq=0&pq=hello&sc=12-5&sk=&cvid=F469659E942240769939E00F71E6A946? ? ? ? 其中的 q = hello 就是用于向服務器傳遞其中的一個額外參數信息,參數名(q,qs,form......)一般由開發程序員自定義。
片段標識符:
? ? ? ? 標識網頁的某個部分,實現“頁面內跳轉”功能,一般文檔類的網站會有這個。
值得注意的是:
? ? ? ? 上述的 URL 這么多的部分,我們要重點關注?服務器地址 , 服務器端口,帶層次的文件路徑,查詢字符串。
? ? ? ? 并且,URL 中只能包含特定的字符集合,包括字母、數字、一些特殊符號(如?-、_、.、~)以及保留字符(如?:、/、?、#?等)。當 URL 中包含其他非 ASCII 字符或特殊字符(比如中文)時,就需要進行轉義(一般使用utf - 8),以確保這些字符能在網絡中正確傳輸和被服務器正確解析,避免出現歧義或錯誤。
? ? ? ? 例如我在搜索引擎輸入 “你好,世界”,在 UTF-8 編碼下,“你” 的十六進制編碼是?E4 BD A0,“好” 是?E5 A5 BD,“,” 是?EF BC 8C,“世” 是?E4 B8 96,“界” 是?E7 95 8C?。再發送 http 請求的時候,query string的會有一部分是 q =?%E4%BD%A0%E5%A5%BD%EF%BC%8C%E4%B8%96%E7%95%8C?。
版本
? ? ?表示協議的版本。最廣泛使用的版本是 HTTP /1.1??
1、(2)? 請求頭:
? ? ? ? ?每一行都是一個鍵值對,鍵與值之間用 “: ” 來分隔。由于 header 的 鍵(key)太多了,下面講解一些比較重要的。
| Host | 描述了訪問的服務器的 IP(域名) 和 端口號 |
| Content-Length | 描述了 body 的長度 |
| Content-Type | 描述了 body 的數據格式 |
| User-Agent | 標識客戶端的類型和版本信息(如瀏覽器、操作系統),服務器可據此返回適配內容。 |
| Referer | 通過這個字段,服務器可以知道用戶是從哪個頁面鏈接過來的 |
| Cookie | 本質是瀏覽器在本地存儲數據的一種機制 |
Host:
? ? ? ? 與 URL 里的服務器地址端口作校驗。因為針對 https 來說,https 是會把 header 部分加密的。
Content-Length 和?Content-Type:
? ? ? ? 請求 / 響應 中存在 body 才會有這兩個屬性。
????????Content-Length可以解決粘包問題,在 TCP 緩沖區中,會有多個 https 的請求,如果有 body ,則 header 必然會有 Content-Length,從 body 開始的位置開始讀取Content-Length個字節就可以了。
????????Content-Type 其中一種常見的格式比如 JSON ,服務器可以根據?Content-Type 決定 body 如何使用。
Referer:
? ? ? ? 不是所有的請求頭都有這個字段(比如瀏覽器直接輸入目的網址訪問),例如,用戶在百度上搜索某個關鍵詞,然后點擊搜索結果中的鏈接進入了我的網站,我的網站服務器就可以通過?Referer?字段獲取到百度的搜索頁面 URL,從而了解到用戶是通過百度搜索進入的。
Cookie:
????????由服務器生成并發送到瀏覽器保存,通常包含鍵值對形式的數據(如user_id=12345),當瀏覽器每次訪問相同域名的網頁時,會自動攜帶對應的Cookie發送給服務器。所以為什么在一些網站登錄一次后,下次登錄不用重新輸入用戶名和密碼。
1、(3)? 請求正文:
????????請求正文(Body)的格式由請求頭的 Content-Type 字段決定,下面是?JSON 格式的例子:
{"key" : "value"............
}????????
2、http 響應:
? ? ? ? 狀態行,響應頭(header),空行,響應正文(body)。
例如:????????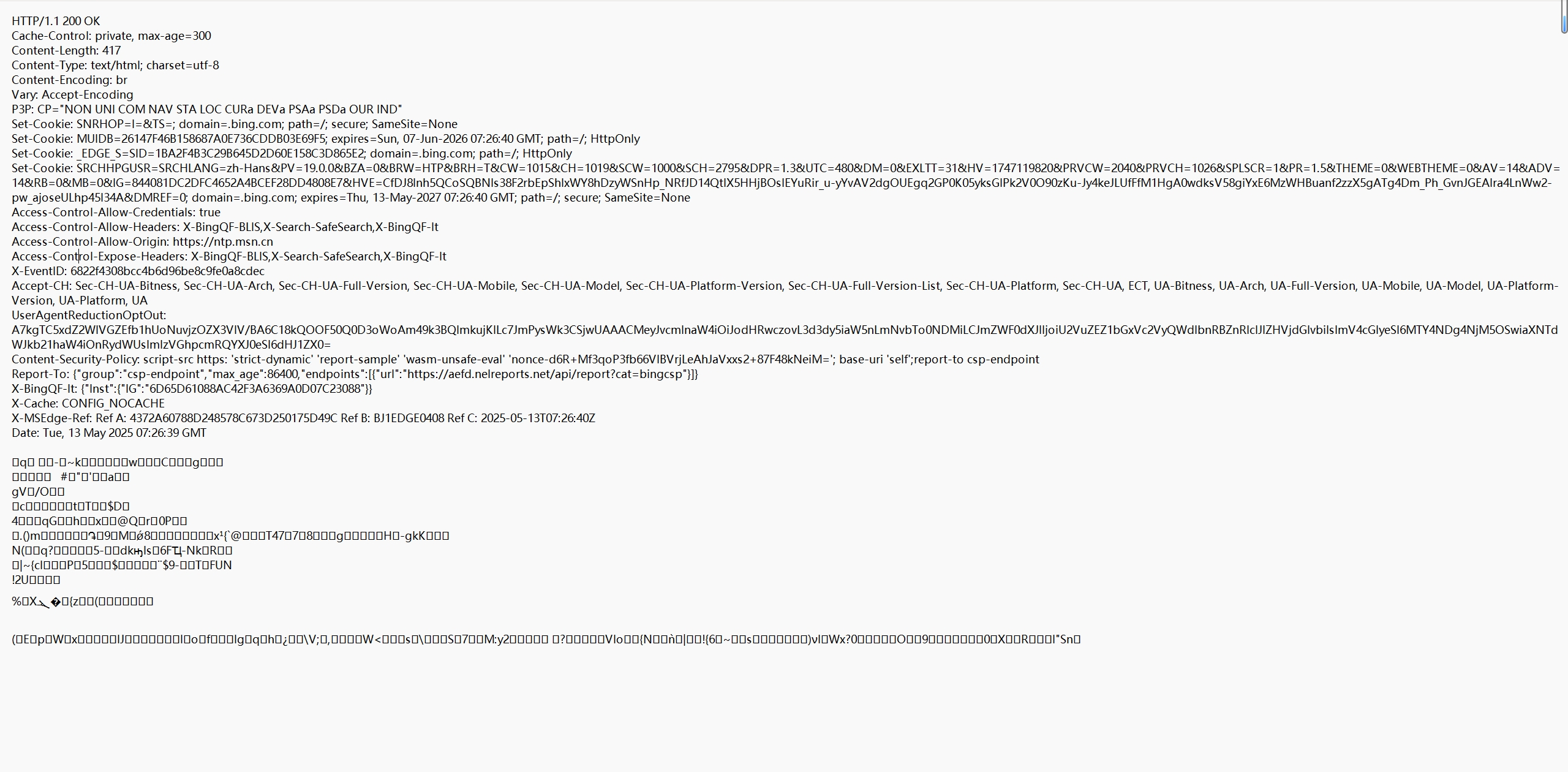
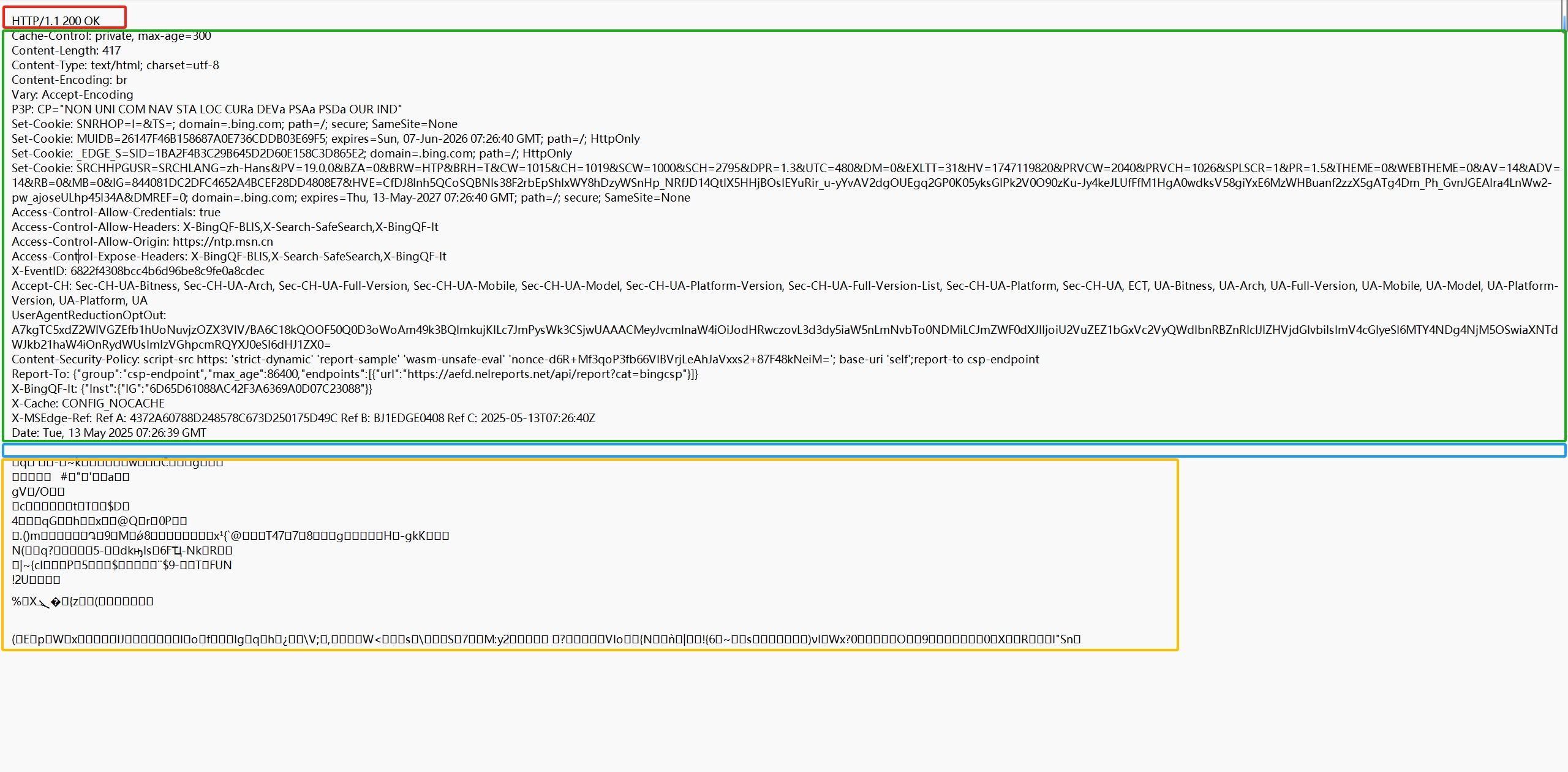
不同顏色圈起來的四個部分,從上到下分別代表,狀態碼,響應頭,空行,響應正文。
????????其中,空行是響應頭結束的標記。
2、(1)? 狀態碼:
????????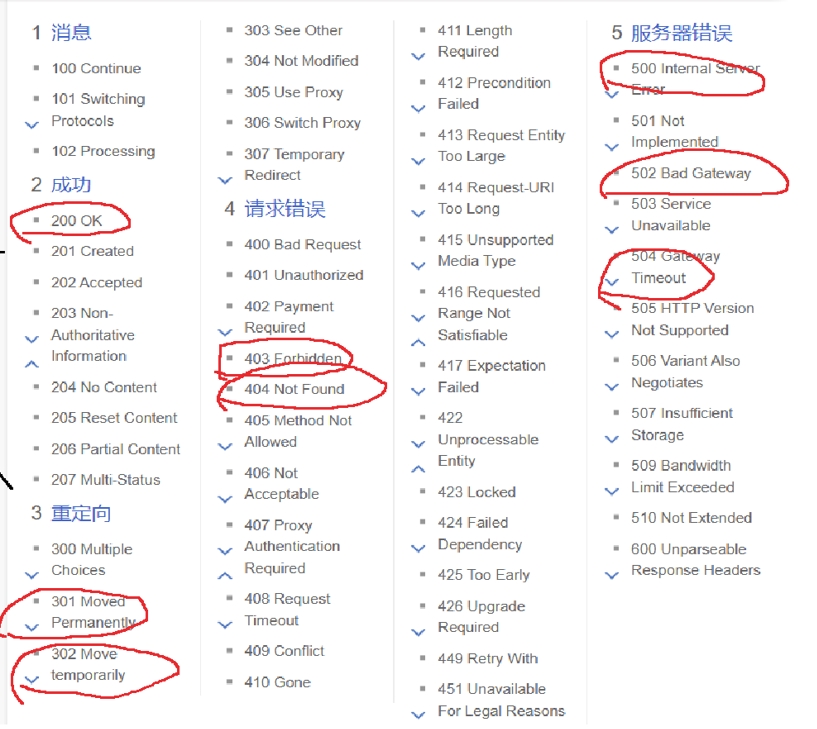
以上紅色圈起來的部分是要重要了解的狀態碼。
200:
?????狀態碼 200 代表 “OK”,??表示服務器成功處理了客戶端的請求。?
301:
? ? ? ? 永久重定向,當服務器接收到客戶端的請求,發現請求的資源已經永久性地遷移到了另一個地址時,服務器會返回 301 狀態碼,并在響應頭的?Location字段中指定新的 URL。客戶端收到這個響應后,會自動使用Location字段中的 URL 再次發起請求。簡單理解就是服務器告訴客戶端:“你要找的資源已永久搬家,以后請直接訪問新地址!”(后續的請求都會被自動改成新的地址)。
302:
? ? ? ? 臨時重定向,表明請求的資源只是臨時位于新的 URL,服務器收到請求后,指示客戶端應臨時重定向到另一個 URL,客戶端會自動向新的 URL 發送請求。
403:
? ? ? ? 表示訪問被拒絕,有的頁面通常需要用戶有一定的權限才能訪問(登陸后才能訪問),如果用戶沒有登錄直接訪問,就容易見到 403。
404:
????????表示服務器無法找到客戶端請求的資源。這意味著客戶端請求的 URL 在服務器上不存在。
500:
????????表示服務器在處理請求時發生了內部錯誤。通常是由于服務器端的出現問題導致無法正常處理請求。
504:
? ? ? ? 當服務器負載比較大的時候,服務器處理單條請求的時候消耗的時間就會很長,就可能會出現超時的情況。
2、(2)??響應頭:
? ? ? ? 與 http 的請求頭結構類似。
2、(3)? 響應正文:?
http 響應的 body 可能會包含?二進制數據,結構化數據(JSON ),文本類數據(HTML網頁)。
????????比如上面例子的黃色圈起來的就是二進制的數據,在數據量大的時候,為了提高數據傳輸效率,節省網絡帶寬和傳輸時間,服務器也經常會對二進制數據進行壓縮后再傳輸。
????????
四、請求行 GET 和 POST 方法的區別:
? ? ? ? GET 和 POST 方法其實沒有本質區別,只是 http 的兩個不同的方法,大部分情況下,使用 GET 的場景,也可以替換成 POST ,使用 POST 的場景,也可以使用 GET。只是在使用習慣上的區別而已。
? ? ? ? 如果非要講出他們兩個的區別,那就是GET 通常沒有 body ,要通過 query string 傳遞數據給服務器,POST 通常由body,不需要?query string 傳遞數據。
? ? ? ? 網絡上有個說法就是GET可以傳輸的最大數據量比 POST 小,這種說法是錯誤的,因為在 http 的官方文檔中,并沒有對 URL 的長度給出限制;網絡上還有個說法就是GET傳輸的時候,query string 只能傳輸文本,不能傳輸二進制數據,這種說法也是錯誤的,因為 query string 可以通過 URL編碼(urlencode)進行數據轉換。
五、 https 協議:
? ? ? ? 前面說到,http 協議都是按照文本的方式明文傳輸的,這就會導致一個問題,那就是在傳輸的過程中會出現數據被篡改的情況。
比如:
我想下載一個 “天天動聽音樂播放器” 。
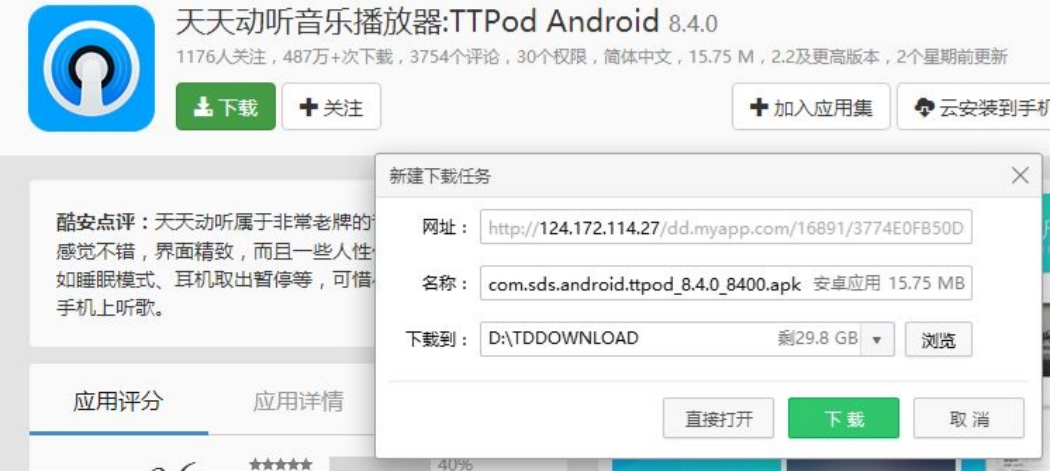
再點擊 “下載按鈕 ”:
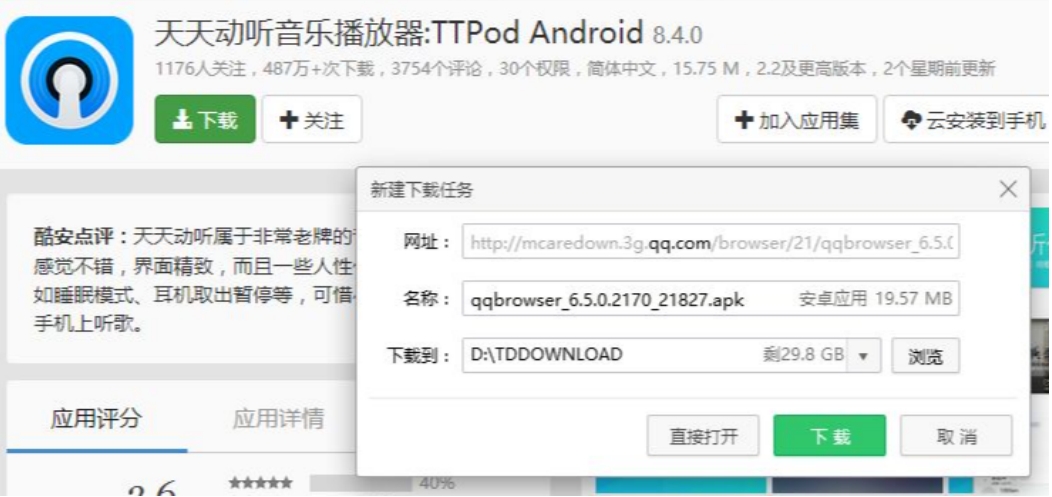
突然發現,他的這個下載名稱鏈接,是 “QQ瀏覽器”的下載地址,這是怎么回事?
? ? ? ? 由于我們通過網絡傳輸的任何數據包都會經過網絡設備(路由器,交換機等),那么運營商的網絡設備就可以解析出你傳輸的數據內容,并進行篡改,這種情況也就是運營商劫持。
? ? ? ? 點擊“下載按鈕”,其實就是在給服務器發送了一個 http 請求,獲取到的 http 響應其實就是包含了該 APP 的下載鏈接。被運營商劫持后,發現這個請求是要下載 “天天動聽音樂播放器” ,那么就自動把交給用戶的響應給篡改成 “ QQ瀏覽器”的下載地址了。
畫圖解釋:
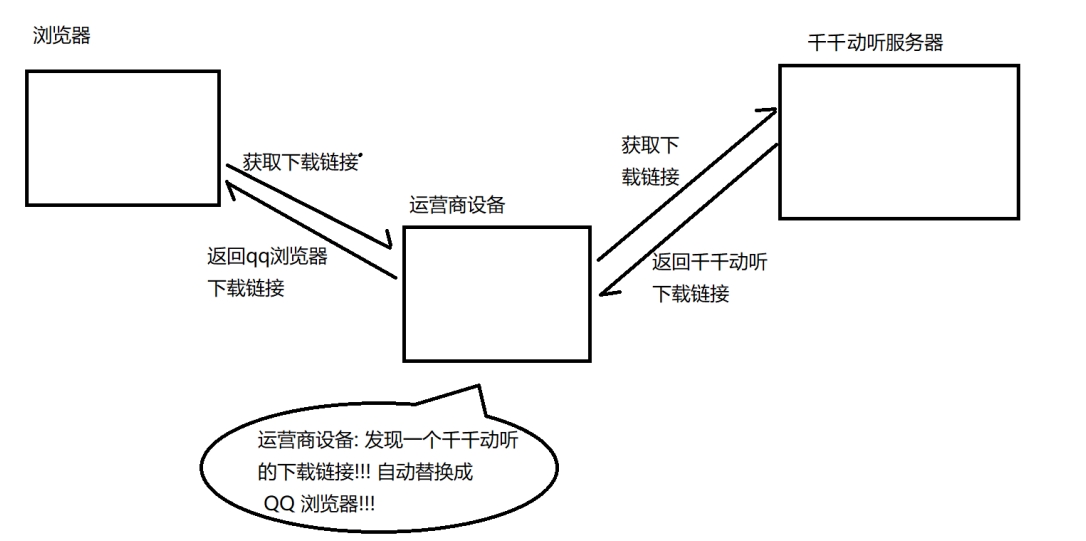
運營商為什么要劫持?主要是利益關系,這里不細說。
現在運營商劫持的情況大幅減少,https 協議的廣泛使用就是一個重要原因!
1、https 工作過程:
1、(1)對稱加密:
? ? ? ? 生成一個密鑰,明文到密文 和 密文到明文,都需要這個密鑰來進行。對于 http 來說,對整個請求(首行,header,body)和響應(狀態行,header,body)都進行加密。至于首行,雖然header的 Host 字段可以進行一定的校驗,但攻擊者仍然可能通過篡改首行的其他部分(如請求方法等)來進行惡意操作,無法保證整個請求的完整性和真實性。
? ? ? ? 一個服務器要給多個客戶端提供服務,那么他們通信之間使用的密鑰,不能都一樣。所以,既然每個客戶端的密鑰都不一樣,那么,就得有一方生成一個 “隨機密鑰”,這一方可以是服務器,也可以是客戶端。生成密鑰的一方需要通知另一方密鑰是什么,就也得在網絡通信中把密鑰傳輸過去。這也就會有個問題,如果網絡傳輸中間有黑客入侵了某個設備,黑客把密鑰獲取到了,也不行,有沒有什么辦法?
? ? ? ? 解決辦法就是下面的非對稱加密了。
1、(2)非對稱加密:
? ? ? ? 非對稱加密有兩個密鑰對,一個專門用來加密的,另一個專門用來解密的,公鑰是所有人都知道。而私鑰只有一方是知道的。引入非對稱加密,就是為了解決傳輸對稱密鑰的問題,通過公鑰對密鑰加密,通過私鑰對密鑰解密。
圖解:
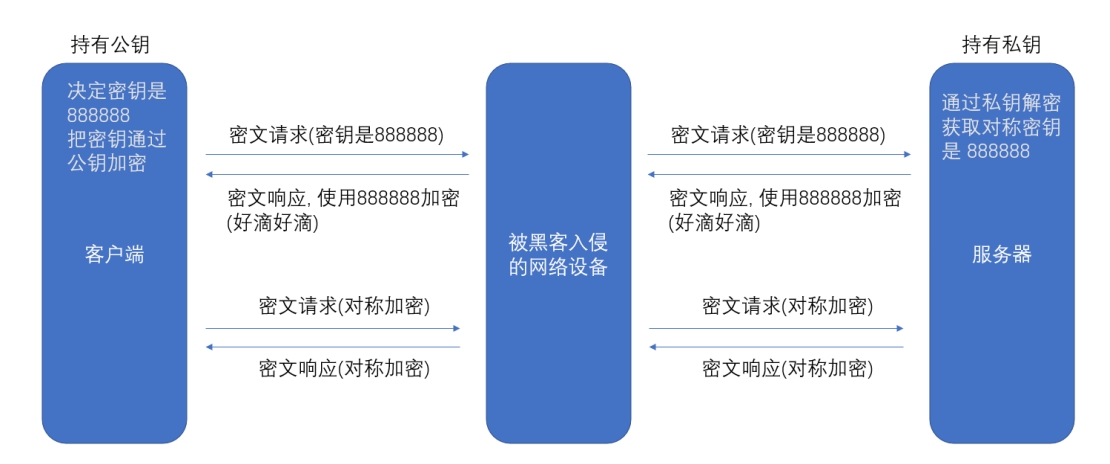
? ? ? ? 公鑰和私鑰,是服務器生成的一個密鑰對,私鑰服務器自己持有,而公鑰是公開的,所有人都可以知道。
? ? ? ? 上述圖的流程,公鑰把對稱密鑰加密后,傳輸給服務器,服務器通過私鑰解密,得到密鑰具體內容是 “888888”。這樣,由于客戶端和服務器雙方都知道密鑰的具體內容,之后的通信就可以使用密鑰加密數據傳輸了。
? ? ? ? 由于上面的對稱密鑰傳輸的過程,黑客只能拿到公開的公鑰,公鑰只能用來解密,就無法知道加密后的具體對稱密鑰是什么了。
? ? ? ? 到這里,安全性還并不完美,還會有“中間人”攻擊。
1、(3)中間人攻擊:
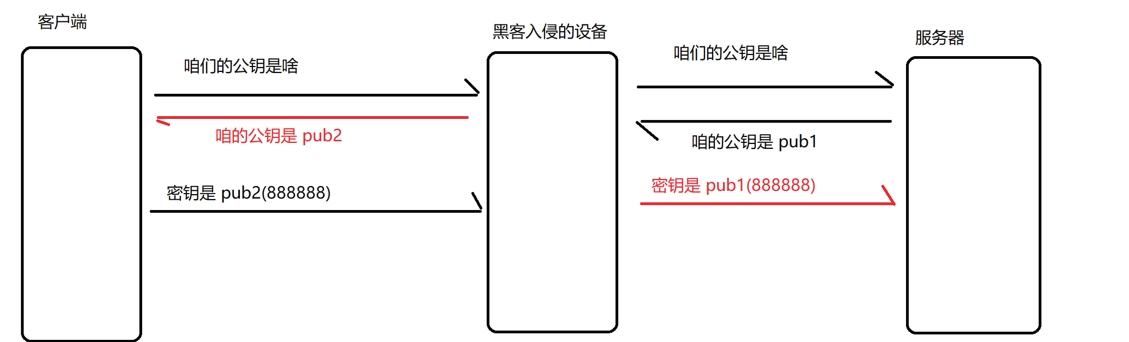
? ? ? ? 首先,客戶端向服務器詢問公鑰,服務器返回的公鑰經過黑客入侵的設備,黑客自己生成一對公鑰和私鑰,黑客再把自己生成的 公鑰 pub2 返回給客戶端。
????????之后,客戶端拿著 pub2 公鑰對密鑰進行加密,經過黑客入侵的設備,由于密鑰是通過?pub2 來加密的,所以黑客拿著自己生成的私鑰來對密鑰進行解密,得到了對稱密鑰的具體內容,再通過pub1 加密密鑰返回給服務器。服務器再通過自己的私鑰解密獲取到對稱密鑰具體內容。
? ? ? ? 上述可以看到,由于黑客在此過程中,得到了對稱密鑰,還是會有安全問題,怎么辦?下面,引入證書就能解決“中間人”攻擊的問題。
1、(4)通過證書解決“中間人”攻擊:
? ? ? ? 引入證書,就是為了解決“中間人”攻擊的問題,證書解決的核心問題,就是讓客戶端識別當前返回的公鑰是服務器本身的,還是黑客偽造的。服務器一方的運營者會向公正機構獲取證書,證書會包含的字段有:證書的發布機構,證書的有效期,證書的所有者,服務器的 ip/域名,服務器使用的公鑰和私鑰,數字簽名。(數字簽名可以理解公正機構對上面包含的內容計算的一個校驗和,再使用自己的私鑰加密)。
? ? ? ? 網絡通信的時候,客戶端詢問服務器返回的就是證書,返回的證書,客戶端會對證書的字段通過同樣計算校驗和的算法,計算得到一個校驗和 check1 (客戶端自己計算的),再使用公正機構的公鑰來對證書的數字簽名字段解密。得到 check2 (公證機構計算的)。
????????如果 check1 == check2 ,說明證書沒有被篡改過,證書的公鑰就是科學的(服務器的公鑰)。
????????如果 check1 != check2,說明證書被篡改了(有可能篡改了證書里服務器的公鑰),此時瀏覽器 / 客戶端會彈出警告,顯示說網站存在風險 / 證書不受信任。
????????
注意:
? ? ? ? 1.上述的流程中,黑客如果篡改公鑰,那么客戶端計算的 check1 與 證書帶有的 check2 會對不上,客戶端 / 瀏覽器就會識別出來。
? ? ? ? 2.上述流程中,黑客能否自己搞一個證書,替換服務器的返回的整個證書?
? ? ? ? 答案是不能,證書包含了服務器的 ip / 域名,假如客戶端想要訪問百度,返回的證書卻是其他的 ip / 域名,瀏覽器 / 客戶端很容易識別出來。
? ? ? ? 3.黑客是否篡改公鑰的同時,也把數字簽名改了?
? ? ? ? 答案是不能,因為數字簽名是通過公正機構的私鑰來加密的,這個私鑰只能用來加密,而黑客很難獲取對應的公鑰解密。因為公正機構公鑰不是通過網絡獲取的,是內置在操作系統中的。?







 后加 .strip()?)
)







)


文件)