消息隊列(Message Queue, MQ)作為現代分布式系統的基礎組件,極大提升了系統的解耦、異步處理和削峰能力。本文以Kafka為例,系統梳理消息隊列的核心原理、架構細節及實際應用。
Kafka 基礎架構及術語關系圖
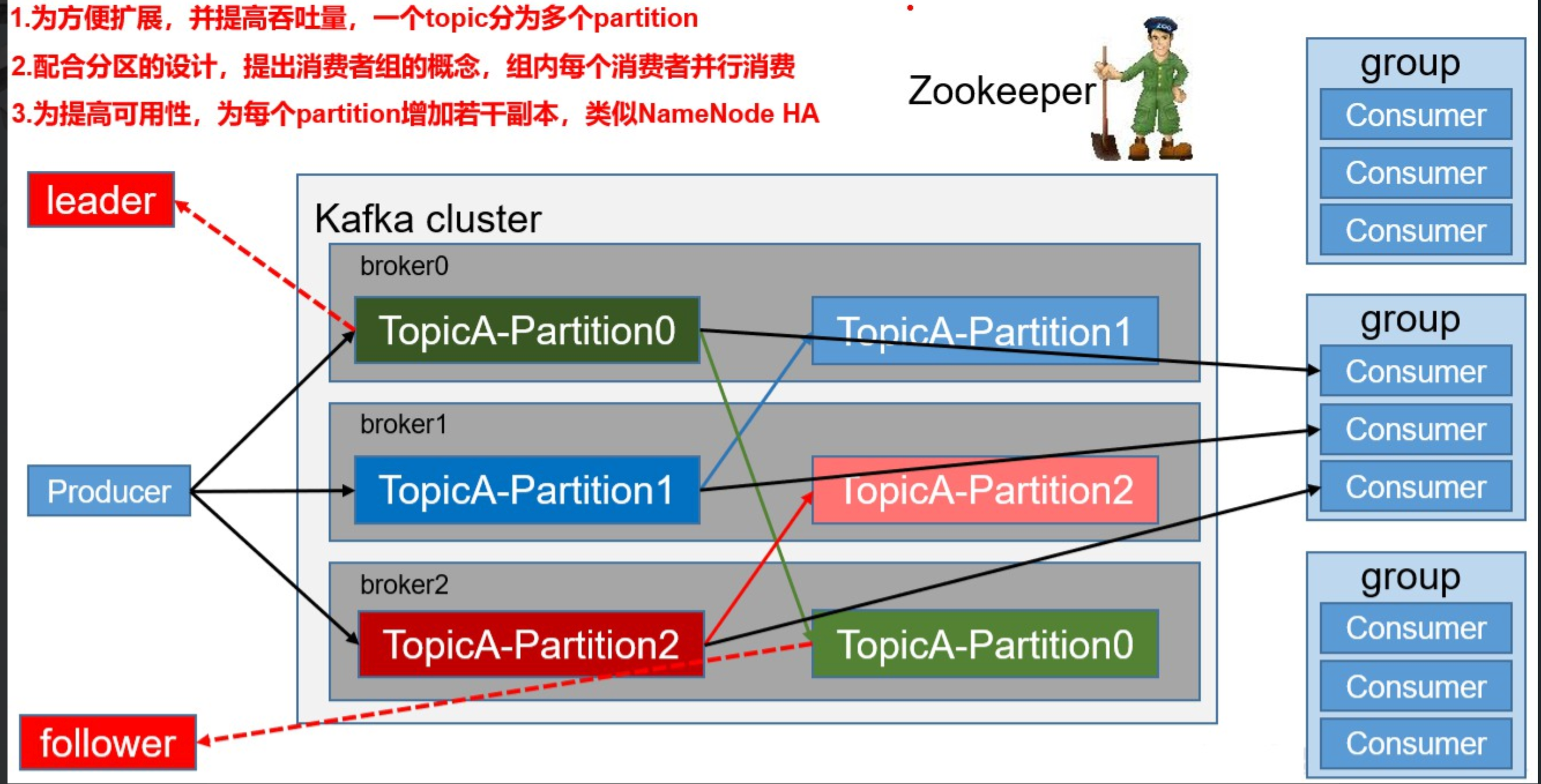
術語簡要說明
- Producer:消息生產者,負責發送消息到 Topic。
- Broker:Kafka 實例,每臺服務器可有一個或多個 Broker,負責存儲和轉發消息。
- Topic:消息主題,邏輯分類,數據以 Topic 組織。
- Partition:Topic 的分區,提升并發和吞吐量,每個分區的數據互不重復。
- Replication:分區副本,提升容錯性,分為 Leader 和 Follower。
- Message:每條發送的消息主體。
- Consumer:消息消費者,負責消費 Topic 中的數據。
- Consumer Group:消費者組,組內消費者協作消費分區數據,提升吞吐量。
- Zookeeper:Kafka 集群依賴 Zookeeper 存儲元信息,保證系統可用性。
為什么需要消息隊列?
在分布式系統中,服務之間往往需要解耦、異步和高效通信。以快遞和便利店的類比,消息隊列就像"中轉站",讓生產者和消費者解耦:
- 解耦:生產者和消費者無需直接通信,通過隊列中轉,降低系統耦合度,便于獨立擴展和維護。
- 異步:生產者無需等待消費者處理完畢,提升整體響應速度和系統吞吐量。
- 削峰填谷:高峰期消息先入隊,消費者按能力慢慢處理,平滑流量壓力,防止系統被突發流量壓垮。
- 容錯與可靠性:消息隊列可持久化消息,防止數據丟失,提升系統健壯性。
消息隊列的兩種通信模式
- 點對點模式(P2P):
- 每條消息只被一個消費者消費。
- 適合任務分發、工作隊列等場景。
- 消息有明確的發送者和接收者,消費后即被移除。
- 發布/訂閱模式(Pub/Sub):
- 一條消息可被多個訂閱者消費。
- 適合廣播、通知、日志收集等場景。
- 生產者將消息發布到主題,所有訂閱該主題的消費者都能收到消息。
Kafka簡介
核心概念與機制
- Segment(段文件):分區的物理存儲單元,便于管理和查找。
- Offset:消息在分區內的唯一編號,消費者通過offset定位消費進度。
- 副本機制:每個分區可配置多個副本(Replica),提升數據可靠性和高可用性。
- Leader-Follower:每個分區有一個Leader,負責讀寫請求,Follower同步Leader數據。
消息存儲與高效查找
Kafka 在數據持久化方面采用了高效的順序寫入機制。Producer 將數據寫入 Kafka 后,Kafka 會將數據直接順序寫入磁盤,避免了隨機寫入的低效問題。Kafka 啟動時會單獨開辟一塊磁盤空間用于順序寫入,這也是其高并發高吞吐的關鍵。
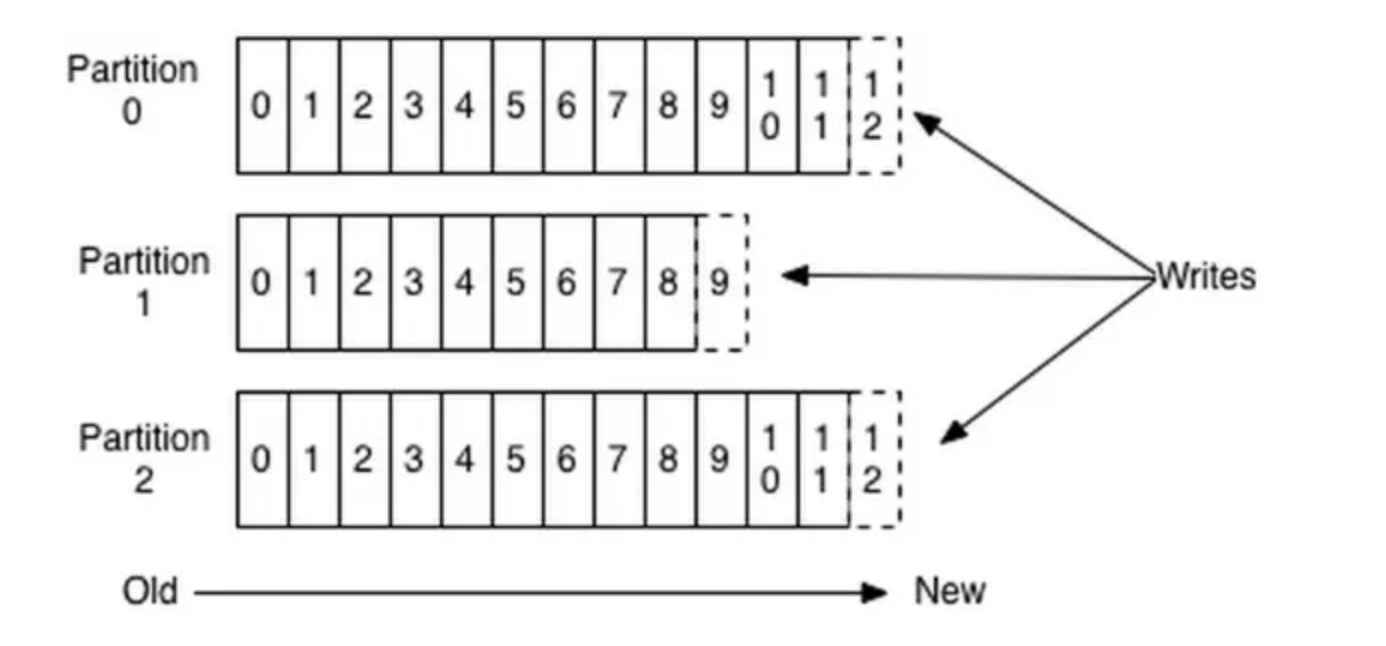
Partition 結構
每個 Topic 可以分為一個或多個 Partition。Partition 在服務器上的表現形式就是一個個文件夾,每個 Partition 文件夾下包含多組 segment 文件。每組 segment 文件又包含 .index 文件、.log 文件、.timeindex 文件(早期版本中沒有)。
.log文件:實際存儲消息(message)的地方。.index和.timeindex文件:為索引文件,用于高效檢索消息。
如:
- 一個 Partition 可能有三組 segment 文件,每個 log 文件的大小相同,但存儲的 message 數量可能不同(因每條 message 大小不一)。
- 文件命名以該 segment 最小 offset 命名,如
000.index存儲 offset 為 0~368795 的消息。 - Kafka 通過分段(segment)+ 索引的方式,實現高效查找。
Message 結構
每條消息(message)在 log 文件中的結構主要包括:
- offset:8 字節有序 id,唯一標識消息在 partition 內的位置。
- 消息大小:4 字節,描述消息體的大小。
- 消息體:實際存放的數據(通常已壓縮),大小不定。
存儲策略
Kafka 無論消息是否被消費,都會保存所有消息。對于舊數據,Kafka 提供兩種刪除策略:
- 基于時間:如默認 168 小時(7 天)后自動刪除。
- 基于大小:如默認 1GB,超出后刪除最早的數據。
需要注意:Kafka 讀取特定消息的時間復雜度為 O(1),刪除過期文件并不會提升查找性能。
- 消息即使被消費也不會立即刪除,便于多消費者組獨立消費。
- 這種分段+索引+順序寫入的設計,是 Kafka 能夠兼顧高吞吐與高效檢索的核心。
消費機制與消費組
消息存儲在 log 文件后,消費者即可進行消費。與生產消息類似,消費者在拉取消息時也是直接向分區的 leader 拉取數據。
Kafka 支持多個消費者組成一個消費者組(Consumer Group),每個組有唯一的 group id。組內的每個消費者可以消費同一 topic 下不同分區的數據,但同一分區的數據不會被組內多個消費者重復消費。
- 當消費者組內的消費者數量小于分區數量時,部分消費者會消費多個分區的數據,導致這些消費者的負載較重。
- 當消費者數量多于分區數量時,多出來的消費者不會分配到任何分區,不參與消費。
- 實際應用中,建議消費者組的 consumer 數量與 partition 數量一致,以充分利用并發能力。
offset 查找與高效檢索
Kafka 通過 segment + offset + 稀疏索引 + 二分查找 + 順序查找等機制,實現高效的數據定位。查找某個 offset 的消息流程如下:
- 先定位 offset 所在的 segment 文件(利用二分法查找)。
- 打開該 segment 的 .index 文件,查找小于或等于目標 offset 的最大相對 offset 條目,獲取其物理偏移量。
- 從該物理位置開始順序掃描 log 文件,直到找到目標 offset 的消息。
這種機制依賴 offset 的有序性和稀疏索引,極大提升了查找效率。
offset 管理
每個消費者需要記錄自己消費到的位置(offset)。
- 早期 Kafka 版本將 offset 存儲在 Zookeeper 中,易導致重復消費且性能有限。
- 新版本中,offset 已直接存儲在 Kafka 集群的
__consumer_offsets這個特殊 topic 中,支持斷點續傳和高效管理。
應用場景
- 日志收集與分析:集中采集應用日志,實時分析與監控。
- 流式數據處理:與Spark、Flink等流處理框架集成,實現實時大數據分析。
- 消息驅動架構:微服務間異步通信,解耦業務模塊。
- 事件溯源與審計:持久化事件流,便于追蹤和回溯。
優缺點分析
優點:
- 高吞吐、低延遲,適合大規模數據流轉。
- 分布式架構,易于橫向擴展。
- 支持消息持久化和多副本,數據可靠性高。
- 靈活的消費模型,適應多種業務場景。
缺點:
- 依賴Zookeeper(或KRaft),運維復雜度較高。
- 消息順序只在分區內保證,跨分區無序。
- 不適合極端低延遲、強事務場景。
總結
消息隊列通過解耦、異步和削峰,極大提升了系統的彈性和可維護性。Kafka作為業界主流消息中間件,憑借高吞吐、分布式和高可用特性,成為大規模數據流轉的首選。理解其原理和架構,有助于更好地設計和優化分布式系統。

 服務器惡意軟件分析及防御)

——802.11n)








的CT重建算法)
)





