文本分類 是機器學習中最基礎的任務之一,擁有悠久的研究歷史和深遠的實用價值。更重要的是,它是許多實際項目中不可或缺的組成部分,從搜索引擎到生物醫學研究都離不開它。文本分類方法被廣泛應用于科學論文分類、用戶工單分類、社交媒體情感分析、金融研究中的公司分類等領域。讓我們再拓展一下這個任務的范疇到序列分類,這個領域的應用場景和影響力會更加廣泛,從 DNA 序列分類到 RAG 管道,后者是當前聊天機器人系統中保證高質量和時效性輸出的最常用方式。
近年來,自回歸語言模型 的進步為許多 零樣本分類 任務(包括文本分類)開辟了新天地。雖然這些模型展示出了驚人的多功能性,但它們往往難以嚴格遵循指令,并且在訓練和推理方面都可能存在計算效率問題。
交叉編碼器 作為 自然語言推理(NLI)模型是另一種常用于零樣本分類和 檢索增強生成(RAG)管道的方法。該方法通過將待分類的序列作為 NLI 的前提,并為每個候選標簽構造一個假設來進行分類。總的來說,這種方法在處理大量類別時會遇到效率挑戰,因為它采用的是成對處理方式。此外,它在理解跨標簽信息方面的能力有限,這可能會影響預測質量,尤其是在復雜的場景中。
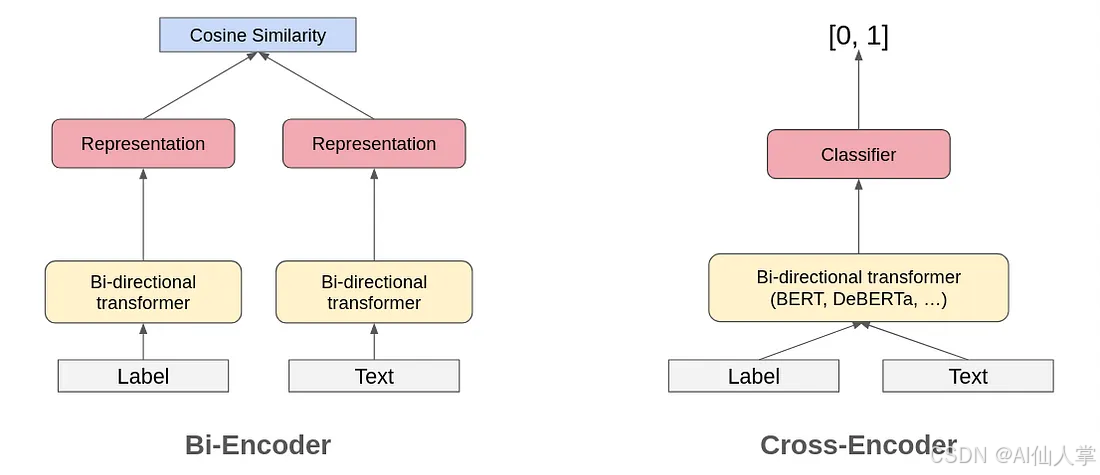
雙編碼器與交叉編碼器架構對比
Word2Vec 的嵌入式方法被認定為文本分類的一種潛在方法,特別是在零樣本設置下。使用句子編碼器能夠更好地理解句子和文本的語義,這使得使用句子嵌入進行文本分類的想法變得顯而易見。Sentence Transformers 的出現進一步提高了嵌入的質量,使得即使不進行微調也能使用它們進行分類任務成為可能。SetFit —— 一項基于 Sentence Transformers 的工作,使得即使在每個標簽只有少量示例的情況下也能獲得良好的性能。盡管基于嵌入的方法效率高且在許多語義任務中表現良好,但在涉及邏輯和語義約束的復雜場景中常常表現不佳。
本文介紹的一種新的文本分類方法,該方法基于 GLiNER 架構,特別適用于 序列分類 任務。旨在在復雜模型的準確性與嵌入式方法的效率之間取得平衡,同時保持良好的 零樣本 和 少樣本 能力。
GLiClass 架構
我們的架構引入了一種新穎的 序列分類 方法,該方法能夠在保持計算效率的同時實現標簽與輸入文本之間的豐富交互。該實現由幾個關鍵階段組成,這些階段協同工作以實現卓越的分類性能。
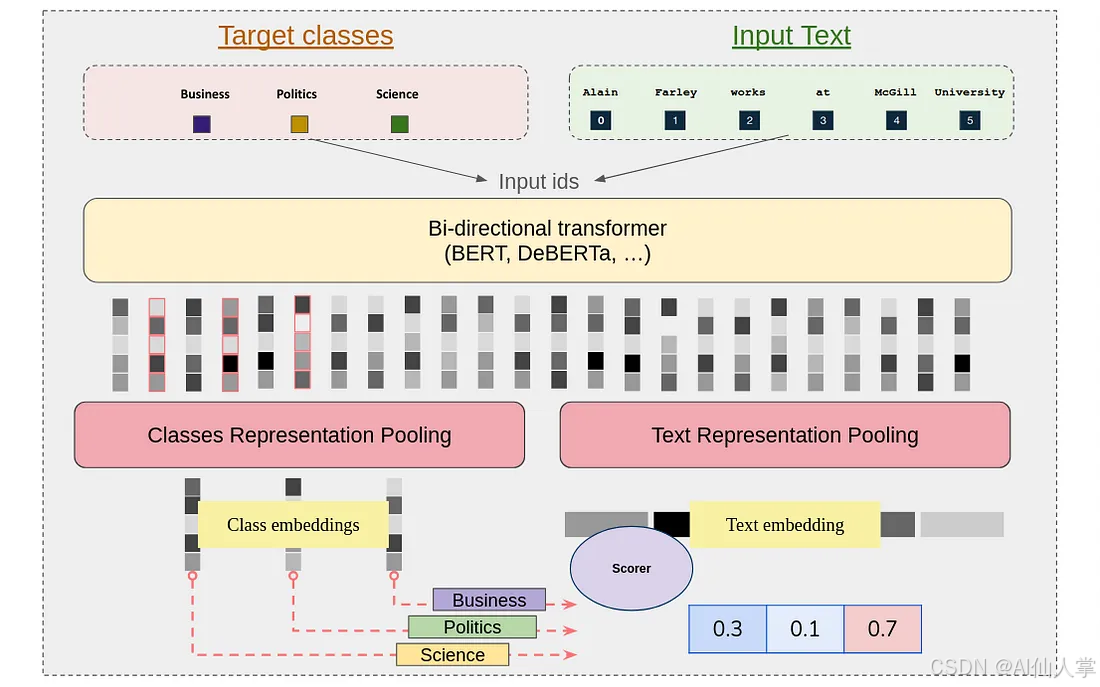
GLiClass 架構
輸入處理與標簽整合
該過程始于標簽整合機制。我們在每個類別標簽前添加一個特殊標記 <
上下文表示學習
在分詞之后,合并后的輸入 ID 會通過雙向 Transformer 架構(如 BERT 或 DeBERTa)進行處理。這個階段至關重要,因為它能夠實現三種不同的上下文理解:
- 標簽間交互:標簽之間可以共享信息,使模型能夠理解標簽關系和層次結構
- 文本-標簽交互:輸入文本可以直接影響標簽表示
- 標簽-文本交互:標簽信息可以指導文本的解讀
這種多向信息流動代表了對傳統交叉編碼器架構的重大優勢,后者通常僅限于文本-標簽對交互,而忽略了寶貴的標簽間關系。
表示池化
在獲得上下文化表示后,我們采用不同的池化機制來分別處理標簽和文本,以提取變壓器輸出中的基本信息。我們的實現支持多種池化策略:
- 首個 token 池化:利用首個 token 的表示
- 平均池化:對所有 token 進行平均
- 注意力加權池化:應用學習到的注意力權重
- 自定義池化策略:針對特定分類需求進行調整
池化策略的選擇可以根據分類任務的具體要求和輸入數據的性質進行優化。
評分機制
最后階段涉及計算合并表示之間的兼容性分數。我們通過靈活的評分框架實現這一點,該框架可以適應各種方法:
- 簡單點積評分:對于許多應用來說既高效又有效
- 神經網絡評分:用于具有挑戰性的場景的更復雜評分函數
- 任務特定評分模塊:針對特定分類需求進行定制
這種模塊化評分方法使架構能夠適應不同的分類場景,同時保持計算效率。
如何使用模型
Hugging Face 上開源了這個模型。
要使用它們,首先安裝 gliclass 包:
pip install gliclass
然后你需要初始化一個模型和一個管道:
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from transformers import AutoTokenizermodel = GLiClassModel.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")
tokenizer = AutoTokenizer.from_pretrained("knowledgator/gliclass-modern-base-v2.0-init")pipeline = ZeroShotClassificationPipeline(model, tokenizer, classification_type='multi-label', device='cuda:0')
這是如何執行推理:
text = "One day I will see the world!"
labels = ["travel", "dreams", "sport", "science", "politics"]
results = pipeline(text, labels, threshold=0.5)[0]
for result in results:print(result["label"], "=>", result["score"])
如何微調
首先,你需要準備如下格式的訓練數據:
[{"text": "Some text here!","all_labels": ["sport", "science", "business", …],"true_labels": ["other"]}, …
]
下面是你需要的導入需求:
import os
os.environ["TOKENIZERS_PARALLELISM"] = "true"from datasets import load_dataset, Dataset, DatasetDict
from sklearn.metrics import classification_report, f1_score, precision_recall_fscore_support, accuracy_score
import numpy as np
import random
from transformers import AutoTokenizer
import torch
from gliclass import GLiClassModel, ZeroShotClassificationPipeline
from gliclass.data_processing import GLiClassDataset, DataCollatorWithPadding
from gliclass.training import TrainingArguments, Trainer
然后,我們初始化模型和分詞器:
device = torch.device('cuda:0') if torch.cuda.is_available else torch.device('cpu')
model_name = 'knowledgator/gliclass-base-v1.0'
model = GLiClassModel.from_pretrained(model_name).to(device)
tokenizer = AutoTokenizer.from_pretrained(model_name)
然后,我們指定訓練參數:
max_length = 1024
problem_type = "multi_label_classification"
architecture_type = model.config.architecture_type
prompt_first = model.config.prompt_firsttraining_args = TrainingArguments(output_dir='models/test',learning_rate=1e-5,weight_decay=0.01,others_lr=1e-5,others_weight_decay=0.01,lr_scheduler_type='linear',warmup_ratio=0.0,per_device_train_batch_size=8,per_device_eval_batch_size=8,num_train_epochs=8,evaluation_strategy="epoch",save_steps = 1000,save_total_limit=10,dataloader_num_workers=8,logging_steps=10,use_cpu = False,report_to="none",fp16=False,
)
當你以正確的格式準備好了數據集后,我們需要初始化 GLiClass 數據集和數據收集器:
train_dataset = GLiClassDataset(train_data, tokenizer, max_length, problem_type, architecture_type, prompt_first)
test_dataset = GLiClassDataset(train_data[:int(len(train_data)*0.1)], tokenizer, max_length, problem_type, architecture_type, prompt_first)data_collator = DataCollatorWithPadding(device=device)
當一切就緒后,我們可以開始訓練:
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=test_dataset,tokenizer=tokenizer,data_collator=data_collator,
)
trainer.train()
在倉庫中查看更多示例:https://github.com/Knowledgator/GLiClass/blob/main/finetuning.ipynb
關鍵應用場景
GLiClass 在廣泛的自然語言處理任務中展示了卓越的多功能性,使其在研究和實際應用中都具有極高的價值。
多類分類
該架構高效地處理大規模分類任務,單次處理最多可處理 100 個不同類別。這一能力對于文檔分類、產品分類和內容標簽系統等需要多個詳細類別的應用特別有價值。
主題分類
GLiClass 在識別和分類文本主題方面表現出色,特別適用于:
- 學術論文分類
- 新聞文章分類
- 內容推薦系統
- 研究文檔組織
情感分析
該架構有效捕捉細微的情感和觀點內容,支持:
- 社交媒體情感跟蹤
- 客戶反饋分析
- 產品評論分類
- 品牌感知監控
事件分類
GLiClass 在識別和分類文本中的事件方面表現出強大的能力,支持:
- 新聞事件分類
- 社交媒體事件檢測
- 歷史事件分類
- 時間線分析和組織
基于提示的約束分類
該系統提供靈活的基于提示的分類與自定義約束,支持:
- 引導分類任務
- 上下文感知分類
- 自定義分類規則
- 動態類別適配
自然語言推理
GLiClass 支持關于文本關系的復雜推理,促進:
- 文本蘊含檢測
- 矛盾識別
- 語義相似性評估
- 邏輯關系分析
檢索增強生成 (RAG)
良好的架構泛化性以及對自然語言推理任務的支持使其成為 RAG 管道中重排序的理想選擇。此外,GLiClass 的效率使其更具競爭力,尤其是與交叉編碼器相比。
這一全面的應用范圍使 GLiClass 成為現代自然語言處理挑戰的多功能工具,在各種分類任務中提供靈活性和精確性。
基準測試結果
我們發布了一個基于 ModernBERT 的新 GLiClass 模型,與舊模型如 DeBERTa 相比,它提供了更長的上下文長度支持(高達 8k 個 token)和更快的推理速度。我們在多個 文本分類數據集 上對我們的 GLiClass 模型進行了基準測試。
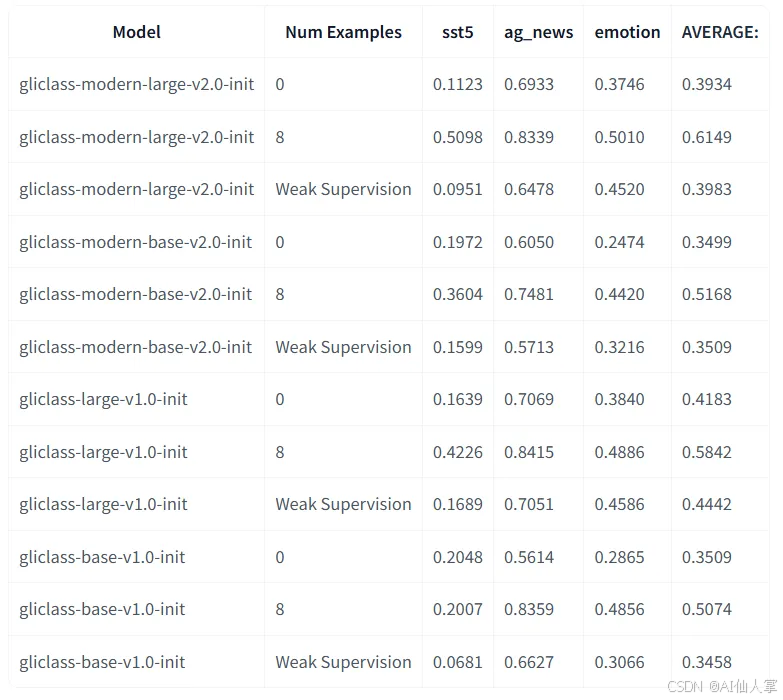
以下是 F1 分數在幾個 文本分類數據集 上的表現。所有測試模型都沒有在這些數據集上進行微調,并且在 零樣本設置 下進行了測試。
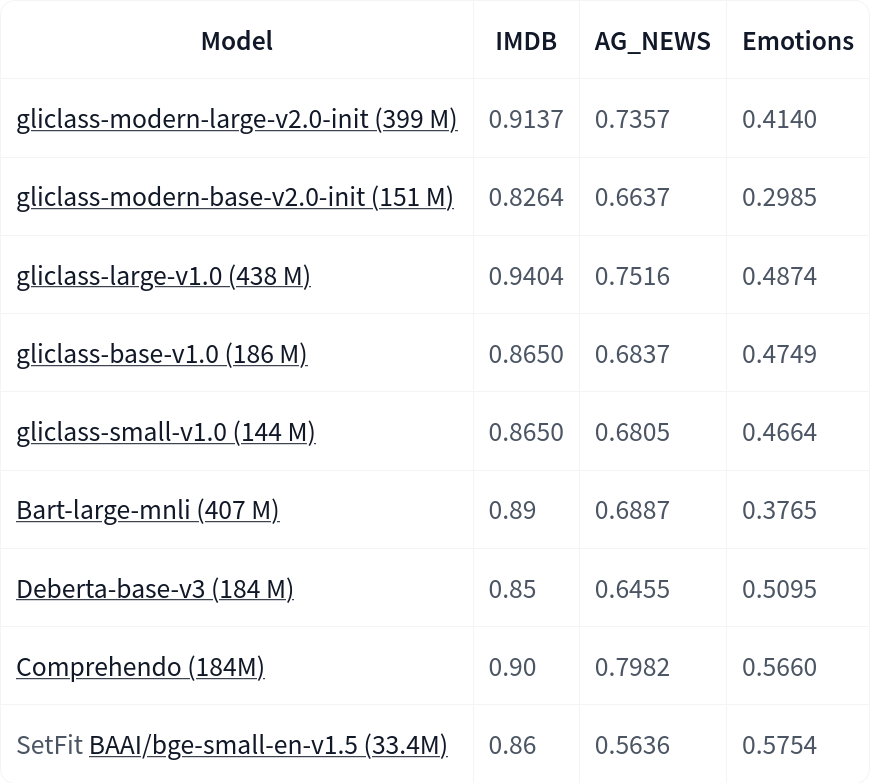
以下是對 ModernBERT GLiClass 與其他 GLiClass 模型的更全面比較:
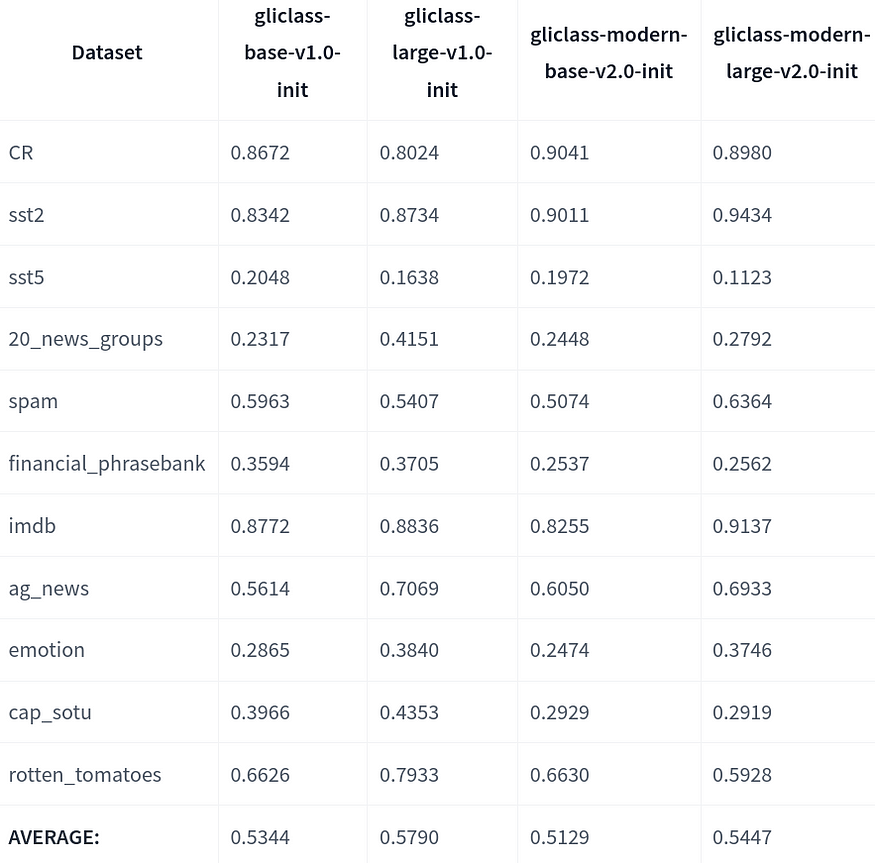
我們研究了如果我們對少量 每個標簽的示例 進行 微調,性能會如何增長。此外,我們測試了一種簡單的方法,當我們不提供真實文本而是提供給定文本主題的通用短描述時,我們稱之為 弱監督。令人驚訝的是,對于像“emotion”這樣的某些數據集,它顯著提高了性能。
結論
GLiClass 代表了文本分類領域的重大進步,提供了一種強大而高效的解決方案,彌合了復雜 Transformer 模型的準確性與嵌入式方法的簡單性之間的差距。通過利用一種新穎的架構,該架構促進了輸入文本和標簽之間的豐富交互,GLiClass 在零樣本和少樣本分類任務中實現了卓越的性能,同時保持了計算效率,即使面對大型標簽集也是如此。它能夠捕捉跨標簽依賴關系,適應各種分類場景,并與現有的 NLP 管道無縫集成,使其成為從情感分析和主題分類到檢索增強生成和自然語言推理等各種應用的多功能工具。
使用生成式語言模型進行零樣本分類:https://github.com/Knowledgator/unlimited_classifier




: 數據集-語料庫(Corpus))









)




