可變形注意力是目前transformer結構中經常使用的一種注意力機制,最近補了一下這類注意力的論文,提出可變形注意力的論文叫Deformable DETR,是在DETR的基礎上進行的改進,所以順帶著把原本的DETR也看了一下。
一、DETR
DETR本身是一個使用transformer結構進行目標檢測的模型,在相關工作這一節作者提到使用了一種叫做集合預測的方法,集合預測不同于傳統的目標檢測方法,這類方法是直接輸出固定大小的包圍框的集合,而傳統的方法是不固定的包圍框再使用極大值抑制進行后處理。使用這一結構之后,設計DETR需要解決兩個關鍵問題,如何建立一個基于集合的損失函數以及集合內部的對應關系應該如何構建。
匹配關系的建立
DETR首先約定了自己能夠檢測到的目標的數量的最大值N,如果圖像中的物體超過了這個數量也沒用,只能檢測出N個物體。對于檢測出的N個物體,如何與groundtruth建立聯系是DETR需要解決的第一個問題,這里作者使用了匈牙利算法進行解決。簡單來說,匈牙利算法就是從全局角度找出一個讓整體效果最優的一對一匹配關系。傳統的目標檢測構建的實際上是一個多對多的關系,利用正負樣本來指導模型預測的包圍框應該屬于哪個真值。使用匈牙利算法,我們需要構建一個真值與預測之間的一對一關系,讓這個關系組的誤差最小化。對于預測的N個物體,我們一般假設N要大于實際存在的物體數量,超過的部分將包圍框的類別標記為空,即無物體。之后利用下面的式子進行優化:
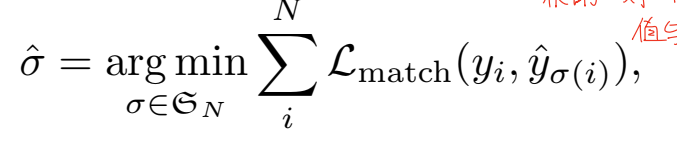
其中Lmatch可以理解為一個損失值,用于描述當我們將第i個物體與第б(i)個物體匹配時錯誤帶來的影響。這個誤差包括兩部分:類別的差異和包圍框的差異。類別的差異直接使用最簡單粗暴的負對數似然損失,我們希望預測的類別的可信度盡可能接近當前匹配的真值中的類別。而包圍框差異的部分,我們同時考慮交并比差異和包圍框邊界差異。交并比差異采用的是GIOU進行計算,它在原始 IoU 基礎上,再減去預測框與真實框在最小閉包矩形中未覆蓋區域的比重。而包圍框邊界差異指的則是包圍框的四個端點與真實值之間的差異。最終包圍框差異的計算公式為:
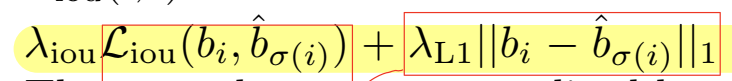
在此基礎上得到的匈牙利算法的計算公式為:
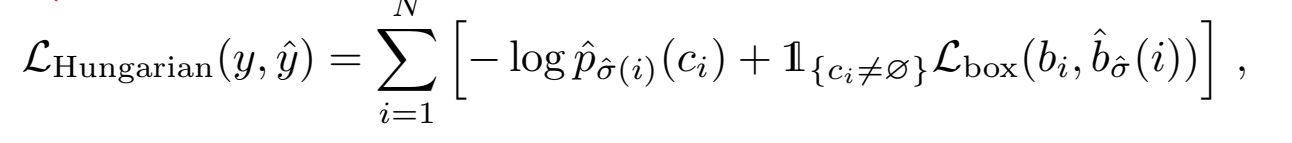
DETR模型設計
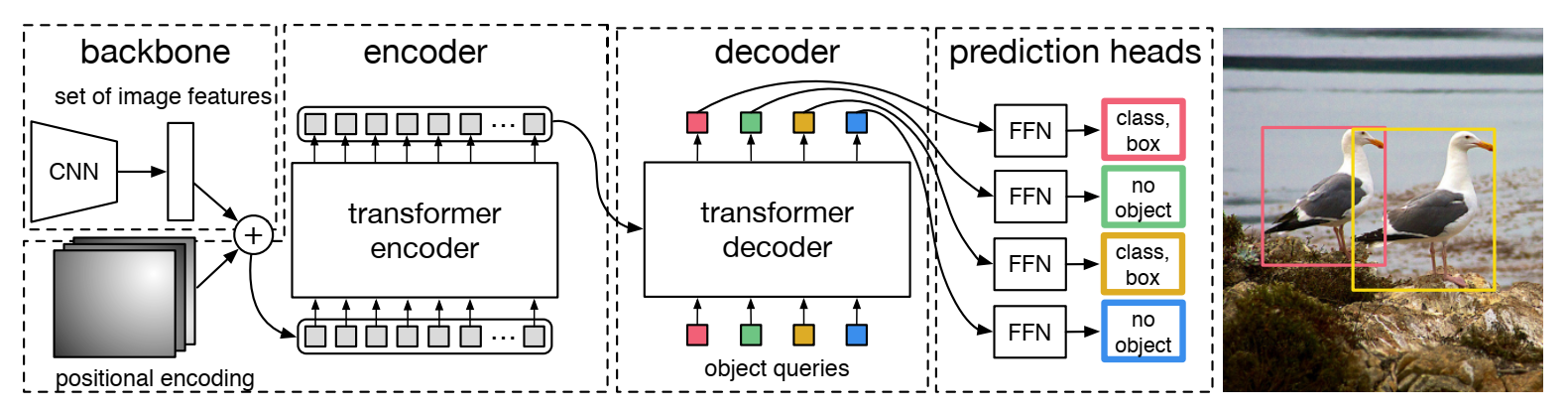
模型設計的部分,DETR首先采用一個CNN進行特征提取,提取好的特征圖送入transformer的編碼器部分進行處理,送入編碼器之前首先使用1×1卷積進行維度調整,假設原來的特征圖維度是C×H×W,調整的過程使用1×1卷積進行,從而將新的特征圖維度調整為d×H×W,之后這d張特征圖被調整為HW個d維的向量,這些向量會被作為token再加入2d位置編碼后送入編碼器。encoder的部分首先是這d個token自己之間計算自注意力,在多個編碼器塊之后得到提取結果。
解碼器的部分則是使用N個可學習query進行提取,這里的N對應的就是前面的N個物體。這N個查詢首先進行自注意力產生相互關系,之后再與encoder的輸出計算交叉注意力進行提取,這N個查詢的結果最終經過一個前饋神經網絡調整為N個預測結果。
二、Deformable DETR
Deformable DETR是對DETR的改進,針對收斂慢、小物體識別不好的問題,但是從結果來看,其提出的可變形注意力貌似比本身模型更出名。簡單來說,可變形注意力是借鑒了CNN中可變形卷積的思想,讓transformer不是平等地關注所有像素,有些像素更加重要那我就只關注那一部分就完事了。
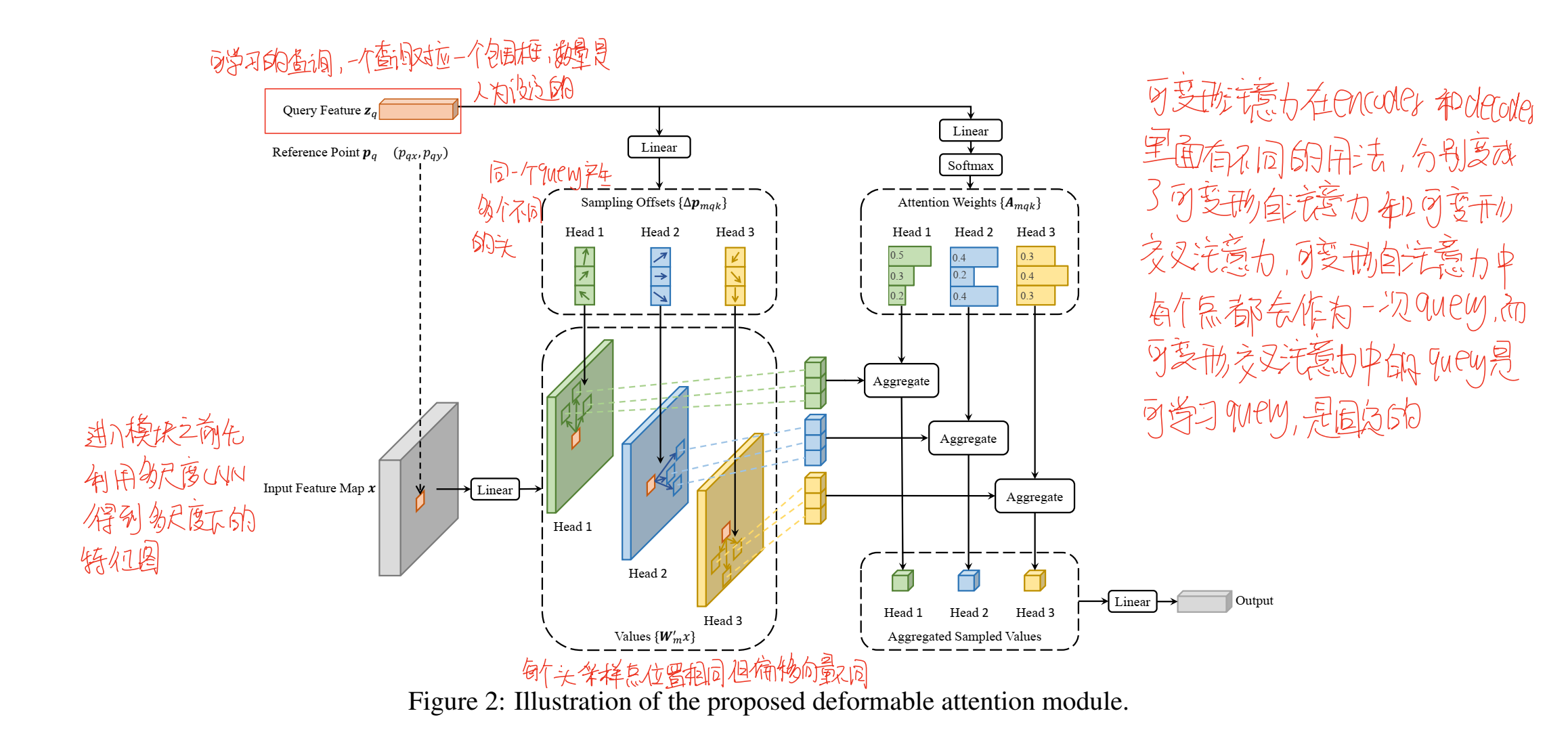
可變形注意力機制
采用與DETR相同的結構,圖像的輸入首先會經過CNN進行特征的提取,在得到的特征圖的基礎上,可變形注意力會選取一部分點,這部分點的坐標是query自己學習得來的,在推理過程是固定的,除此之外,query還會提供一個偏移值,基于選擇的點的坐標,加上這個偏移值,就可以計算出采樣點周圍的幾個點,特征圖中這幾個點的特征向量被提取出來進行加權求和,從而得到可變形注意力的輸出。

這一可變形注意力機制可以很好地與多尺度卷積結合起來,多尺度卷積中特征圖的大小是不同的,所以我們不能采用固定的坐標大小來表示采樣點的位置,這里作者設計了一個歸一化機制,通過歸一化讓位置和偏移量轉換為0-1的一個比例,這樣再在每一層根據大小得到一個可能是浮點數的坐標,這個坐標可能沒有直接對應的點,需要利用臨近點插值得到這個坐標對應的值,這樣將尺度引入,我們就得到了多尺度的可變形注意力。
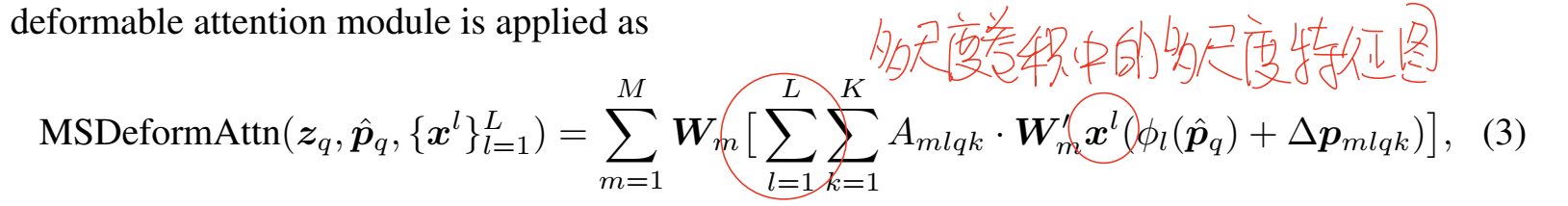
Deformable transformer 結構
使用了可變形注意力機制之后,DETR的整個輸入輸出都變了,變成了多尺度卷積產生的多尺度特征圖。在encoder的部分,編碼器的輸入和輸出都是多尺度的特征圖,并且編碼器輸出的大小和編碼器輸入的大小是一樣的,這部分使用可變形自注意力機制每個像素都會作為一個query參與到計算中,在添加尺度編碼之后參與可變形注意力的計算,也就是說這部分是對特征圖中的每個點,都計算一遍多尺度可變形注意力,最后疊加出來一個等大小的特征圖。在decoder的部分,作者使用了可變形自注意力和可變形交叉注意力。對于N個query,首先使用可變形自注意力機制進行交互,這個交互也是可變形的,主要體現在交互的過程不是一一對應的,每個query只和一部分query進行交互。雖然都叫做可變形自注意力,但是decoder部分使用的和encoder部分使用的還不一樣,decoder的部分的Deformable Self-Attention并不能很好地體現出采樣點這一概念,只保留了非全部交互這一概念。
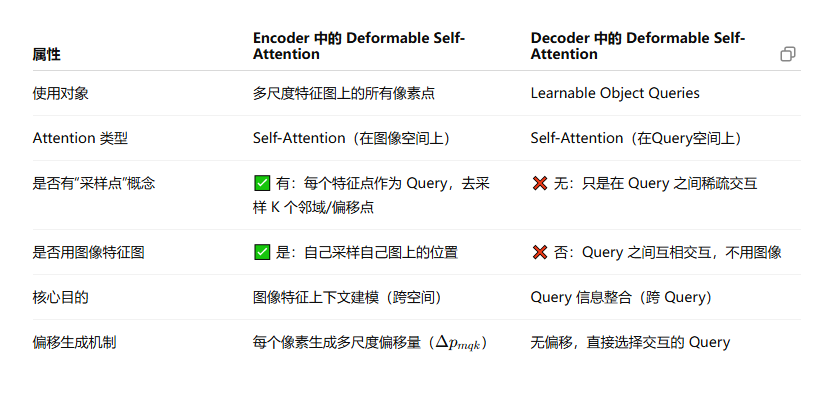
而可變形交叉注意力則是將每個query與encoder的輸出進行交互,得到交叉注意力結果,最終得到N個query查詢的結果。
整體理順一下可變形注意力在DETR中的機制。首先模型利用多尺度卷積得到不同尺度下的特征圖P3P4P5,之后這些特征圖會被先送入encoder的部分,編碼器中使用多尺度可變形自注意力機制,對于每一個尺度,每個點都是一個query與周圍的小部分點進行加權求和,同時不同尺度之間也會相互參與計算,比如說P3尺度下,同尺度采樣點直接參與計算,不同尺度的采樣點則是使用歸一化進行處理然后參與計算,由于加權求和并不改變向量長度,所以自注意力計算過程完全不改變輸入輸出的大小。經過處理,encoder部分使用多尺度可變形自注意力機制將特征圖進行了處理,輸出的是一個等大小但是特征更加豐富的特征圖。之后decoder的部分輸入是N個可學習的object query,這部分query首先進行可變形自注意力機制,每個query和小部分query進行加權求和,之后所有的object query都作為query與encoder輸出的多尺度特征圖進行可變形多尺度交叉注意力計算,每個query會得到一個向量,這個向量的長度等于特征圖的深度,最后所有的query都掃一遍,就可以拼成一個二維矩陣,這個二維矩陣再經過后續計算送入不同的head完成不同的下游任務。
可以看到,雖然打著可變形注意力的幌子,但是扣細節的話可以發現,可變形注意力幾乎是重寫了傳統transformer中qkv的結構,我們很難找到真正意義上的qkv三個內容,可變形這個詞,主要針對的就是讓點不是和全部剩余點進行交互,而是讓點和小部分點進行交互,圖像中并不是所有的內容都是完全有意義的,我只需要關注真正有價值的東西即可,剩余的是在徒增開銷。



的CT重建算法)
)








: 數據集-語料庫(Corpus))





