語音智能和語音轉文本 (STT) 技術已變得至關重要,因為組織每天收集數千小時的電話、會議和客戶互動。僅靠原始音頻并不能推動決策 - 組織需要智能來大規模地從語音數據中提取價值。語音智能結合了語音識別、自然語言處理 (NLP) 和機器學習 (ML),將語音數據轉化為可作的見解。現代 STT 模型可以準確地轉錄對話,并與其他工具配合使用來分析情緒、檢測關鍵主題并生成自動摘要以獲得更深入的見解。語音智能和 STT 技術服務于多個行業使用案例,包括呼叫分析和對話智能、醫療保健文檔、客戶服務、視頻內容優化、法律發現和合規性、銷售智能和輔導等。隨著生成式 AI 和改進模型的出現,這些應用程序對有效 STT 模型的需求持續增長。
AssemblyAI 是 AWS Marketplace 中的獨立軟件供應商 (ISV),是一家研究型組織,致力于為全世界推進語音 AI 技術并使其大眾化。他們成立于 2017 年,建立了一支由跨學科研究領導者、科學家和工程師組成的團隊,致力于創建超人語音 AI 模型,為語音數據應用解鎖新的可能性。 AssemblyAI 技術通過簡單、對開發人員友好的 API 為全球成千上萬的客戶和數十萬開發人員提供服務。AssemblyAI 提供全面的語音 AI 功能,包括:
- 核心語音到文本轉錄
- 揚聲器檢測
- 自動語言檢測
- 情緒分析
- 章節檢測
- 個人身份信息 (PII) 修訂
Universal-2 模型展示了 AssemblyAI 致力于突破語音 AI 可能性的界限。此模型通過解決語音識別中的關鍵挑戰、提高正確的名詞準確性、格式和大小寫以及時間戳生成來實現高準確性。AssemblyAI 采用以研究為中心的方法來構建準確、功能強大的語音 AI 模型,這些模型易于集成。 本文展示了如何從 AWS Marketplace 開始使用 AssemblyAI 的 API,并通過幾個步驟調用這些模型 API 來構建初始概念驗證 (POC)。
解決方案概述
AssemblyAI 的語音轉文本服務通過兩階段管道處理音頻。第一階段使用 Universal-2 自動語音識別 (ASR) 模型,這是一個 600M 參數的 Conformer RNN-T 模型,基于 12.5M 小時的多語言音頻數據進行訓練。此模型將語音轉換為文本,同時處理多個說話人、口音和背景噪音。第二階段采用神經模型進行文本格式化,處理標點符號、大寫和文本規范化等任務,以生成干凈、可讀的轉錄文本。 除了基本轉錄之外,客戶還可以啟用與核心 ASR 流程一起運行的其他智能模型。其中包括用于跟蹤誰說了什么的說話人識別、用于了解情感背景的情緒分析、用于自動對對話進行分類的主題檢測、用于提取關鍵點的內容摘要以及用于維護隱私合規性的 PII 編輯。所有這些模型都通過相同的 API 接口無縫地協同工作。下圖顯示了高級體系結構。?
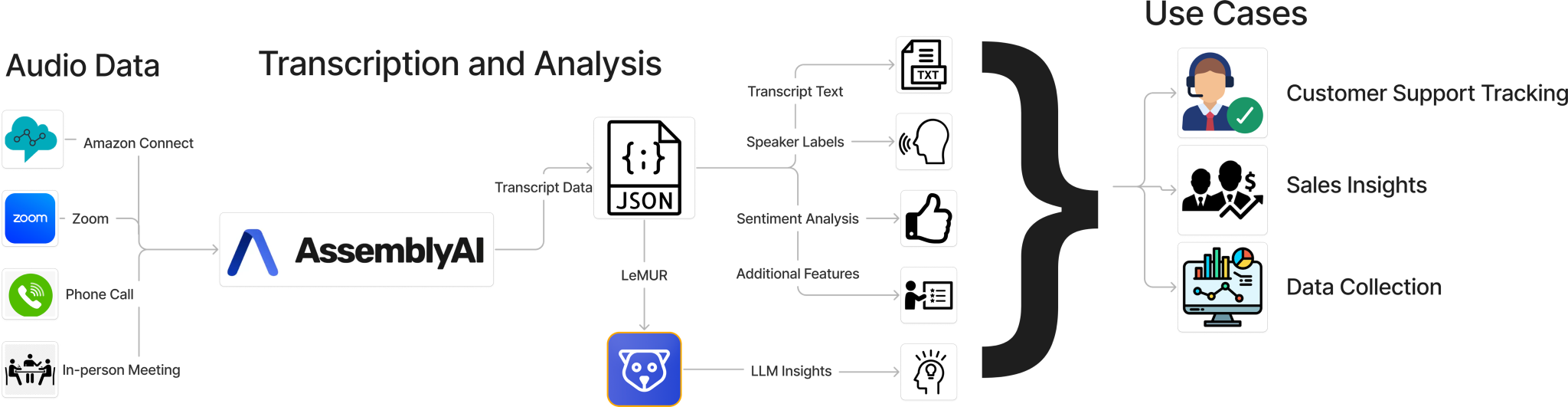
?圖 1:AssemblyAI 的 API 轉錄的高級架構圖
先決條件
在開始之前,請確保您滿足以下先決條件:
- 一個有權訪問?Amazon Simple Storage Service (Amazon S3)?的?Amazon Web Services (AWS)?賬戶。
- AssemblyAI 的 API 可以在 AWS Marketplace 中購買。您還可以訪問 AssemblyAI 的網站以申請試用帳戶。對于試用賬戶,該賬戶預加載了一些積分,客戶可以立即將其用于 POC 測試。
- 使用 AssemblyAI 成功創建帳戶后,請確保將 API 密鑰保存在安全的地方。
- 執行以下 Python 代碼,為解決方案演練中的場景做好準備:
!pip install assemblyai
import assemblyai as aai
aai.settings.api_key = "xxxxxxxx" #your AssemblyAI API key?
解決方案演練
在本節中,我們將深入探討 AssemblyAI 的 API 可以找到高價值的五種情況。每個案例都附帶一個代碼片段,讀者可以在自己的環境中進行測試。
- 從本地文件轉錄音頻
- 從 Amazon S3 轉錄音頻文件
- 說話人分類
- 自動語言檢測
- PII 修訂
從本地文件轉錄音頻 這是音頻文件駐留在執行代碼的本地存儲庫中的基本設置。AssemblyAI API 支持最常見的音頻和視頻文件格式,例如 mp3、m4a、m4p、wav 或 wma。建議您的音頻文件采用其本機格式,而無需進行額外的轉碼或文件轉換。有關音頻文件格式的更詳細討論,請參閱此 AssemblyAI 博客。從 AssemblyAI 托管的網站下載公開可用的音頻文件,并將其保存到本地文件夾。執行以下代碼片段以執行轉錄:?
# Transcribe an audio from a local audio file?
transcriber = aai.Transcriber()
transcript = transcriber.transcribe("./Audios/ford_clip_trimmed.mp3")
print(transcript.text)?
結果應類似于以下轉錄:
晚上好。去年 1 月 15 日,我向你們的國會參議員和眾議員提出了一項使我們的國家獨立于外國能源的全面計劃。到 1985 年。這樣的計劃早就應該了。我們越來越受他人擺布,因為我們整個經濟所依賴的燃料。以下是不會消失的事實和數據。美國目前約 37% 的石油需求依賴外國來源。10 年后,如果我們什么都不做,我們將以別人確定的價格進口超過一半的石油,如果他們選擇賣給我們的話。兩年半后,我們受外國石油禁運的影響將是兩個冬天前的兩倍。我們現在每年為外國石油支付 250 億美元。五年前,我們每年只支付 30 億美元。五年后,如果我們什么都不做,誰知道還會有多少數十億人從美國流出。
從 Amazon S3 轉錄音頻文件
在許多組織中,音頻數據保存在云存儲中,例如 Amazon S3。要從 S3 存儲桶轉錄音頻文件,AssemblyAI 需要臨時訪問該文件。要提供此訪問權限,您需要生成一個預簽名 URL,該 URL 內置了臨時訪問權限。有關如何生成預簽名 URL 的更多詳細信息,請參閱使用預簽名 URL 共享對象。
執行以下代碼片段以執行轉錄:
import requests
import time
p_url = "S3 pre-signed url"
assembly_key = "xxxxxxxx" #your AssemblyAI API
# Use your AssemblyAI API Key for authorization.
headers = {"authorization": assembly_key, "content-type": "application/json"}
# Specify AssemblyAI's transcription API endpoint.
upload_endpoint = "https://api.assemblyai.com/v2/transcript"?
# Use the presigned URL as the `audio_url` in the POST request.?
json = {"audio_url": p_url}?
# Queue the audio file for transcription with a POST request.?
post_response = requests.post(upload_endpoint, json=json, headers=headers)
# Specify the endpoint of the transaction.?
get_endpoint = upload_endpoint + "/" + post_response.json()["id"]?
# GET request the transcription.</p><p>get_response = requests.get(get_endpoint, headers=headers)?
# If the transcription has not finished, wait util it has.
while get_response.json()["status"] != "completed":
??get_response = requests.get(get_endpoint, headers=headers)
? time.sleep(5)
# Once the transcription is complete, print it out.
print(get_response.json()["text"])
說話人分類
說話人分類是音頻中的一個重要組成部分,因為它解決了確定說話人身份以及他們在錄音中說話時間的挑戰。此功能對于各種任務都至關重要,例如提高轉錄文本的清晰度和結構、啟用高級分析以及啟用個性化和自定義。
Speaker diarization
Speaker diarization is a critical component in audio because it addresses the challenge of establishing the identity of speakers and when they spoke in an audio recording. This capability is essential for a wide range of tasks such as enhancing clarity and structure in transcripts, enabling advanced analytics, and enabling personalization and customization.
執行以下代碼片段以執行轉錄:
config = aai.TranscriptionConfig(speaker_labels=True)
transcriber = aai.Transcriber(config=config)
FILE_URL = "https://github.com/AssemblyAI-Examples/audio-examples/raw/main/20230607_me_canadian_wildfires.mp3"
transcript = transcriber.transcribe(FILE_URL)
# Extract all utterances from the response
utterances = transcript.utterances?
# For each utterance, print its speaker and what was said?
for utterance in utterances:
? speaker = utterance.speaker
? text = utterance.text
? print(f"Speaker {speaker}: {text}")?
?以下腳本顯示了此示例的部分結果:
演講者 A:加拿大數百場野火產生的煙霧正在觸發美國各地的空氣質量警報從緬因州到馬里蘭州再到明尼蘇達州的天際線都是灰色和煙霧繚繞的。在一些地方,空氣質量警告包括待在室內的警告。我們想更好地了解這里發生的事情以及原因,因此我們致電約翰霍普金斯大學環境健康與工程系的副教授 Peter DeCarlo。早上好,教授。
發言者 B:早上好。
演講者 A:那么,現在的情況是什么導致這一輪野火影響了這么多遙遠的人?
發言者 B:嗯,有幾件事。這個季節已經相當干燥了,然后我們在美國受到打擊的事實是,有幾個天氣系統基本上是將加拿大野火的煙霧通過賓夕法尼亞州引導到大西洋中部和東北部,然后只是在那里投放煙霧。
演講者 A:那么,這種霧霾中是什么讓它有害呢?我假設它是有害的。
注:因版權問題,(自動語言檢測?PII 修訂)請瀏覽官方原稿
從 AWS Marketplace 開始使用 AssemblyAI 的語音轉文本模型構建語音智能 |AWS 市場![]() https://aws.amazon.com/cn/blogs/awsmarketplace/start-building-voice-intelligence-with-assemblyais-speech-to-text-model-from-aws-marketplace/
https://aws.amazon.com/cn/blogs/awsmarketplace/start-building-voice-intelligence-with-assemblyais-speech-to-text-model-from-aws-marketplace/
結論
AssemblyAI 致力于為開發人員構建一個高質量的 API 平臺,以使用 AI 轉換和理解語音數據,從而創造創新的產品和服務。他們的語音轉文本模型解決了關鍵的轉錄挑戰。AssemblyAI 最新的 Universal-2 模型專注于解決影響現實世界語音 AI 工作流程的最后一英里問題,例如提高字母數字和生僻詞的準確性。
注冊AWS賬號:
AWS云服務器:中國企業出海的“全球化加速器”,為何成為海外業務首選?![]() https://mp.weixin.qq.com/s/m7lGmI02munGklnZVKdl6w
https://mp.weixin.qq.com/s/m7lGmI02munGklnZVKdl6w











)


)




![[C++] 小游戲 決戰蒼穹](http://pic.xiahunao.cn/[C++] 小游戲 決戰蒼穹)