一.聯合查詢/多表查詢
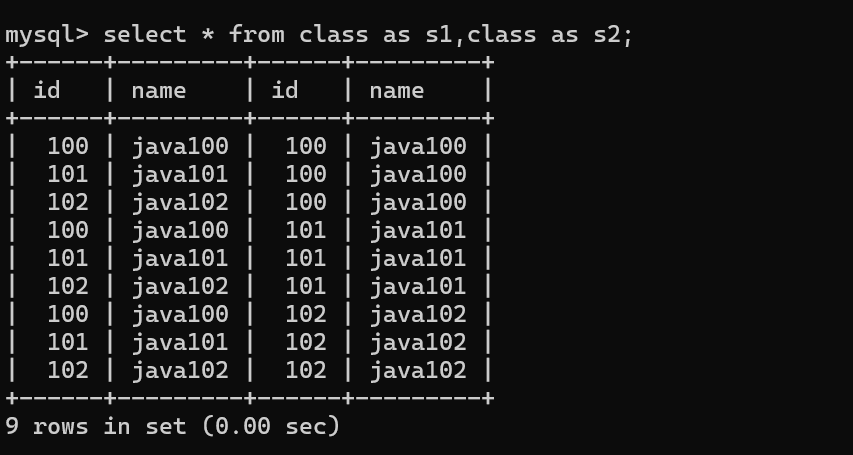
聯合查詢關鍵在于笛卡爾積的過程
笛卡爾坐標積的排列組合
首先它會將兩個表用排列組合的方式進行排列組合。
表一
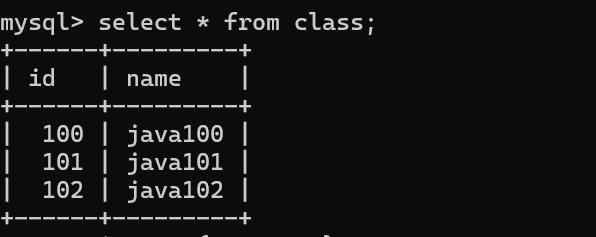
表二
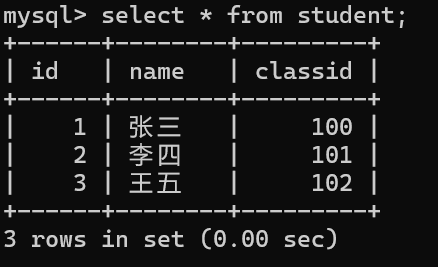
進行排列組合
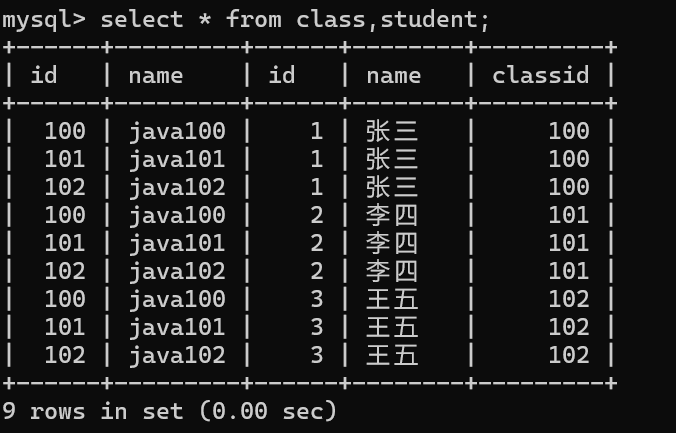
我們發現它的行是?兩個表的行相乘,列是兩表的列相加。
我們所看到的數據有合理的也有不合理的我們接下來要做的就是將這些不合法的數據剔除,另外這種方法十分不安全,因為數據量太過龐大了,就行相乘來說就足以讓服務器崩潰。
篩選
我們得找兩個表的相同項比如id這一項
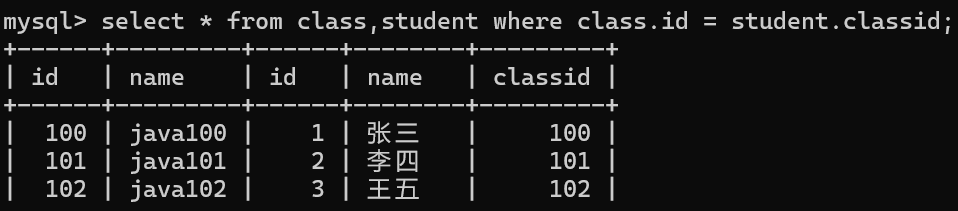
這下數據就是有效的了,都是有效信息。美化一下
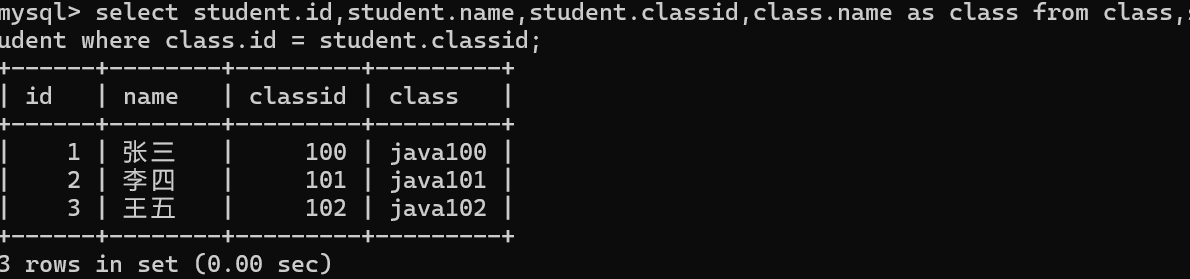
這種方法雖然方便但可讀性差,還不安全。
在兩個表之間有關聯的情況下合成的表為內連接反之為外連接
內連接

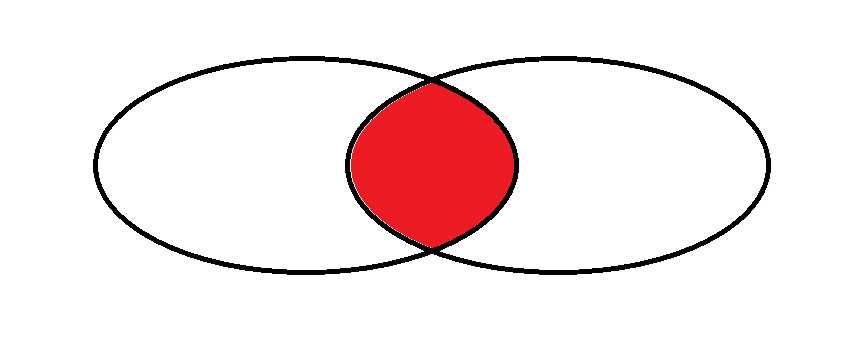
外連接
?左連接

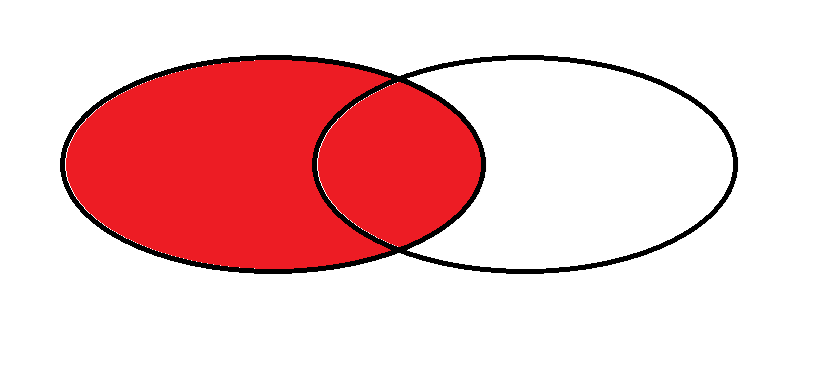
右連接
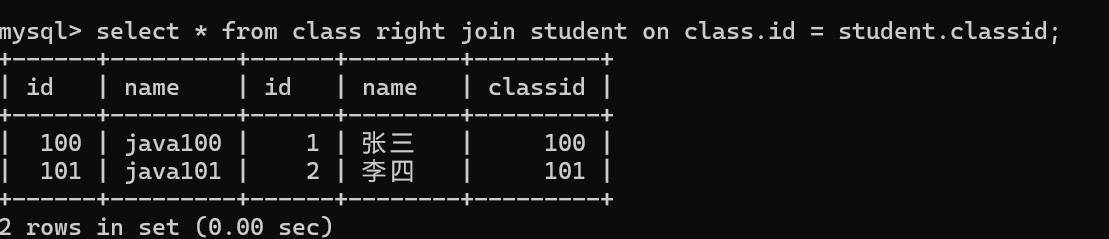
自連接
 二.聯合查詢
二.聯合查詢

這個方法可以將兩個完全不同的表合并在一起,會自動去重,如果不想去重則須在union后加上all
?三.索引
索引能夠提高查詢速度,但是會占用更多的空間來生成索引,但是可能會降低插入修改刪除的速度,
1.查看索引? ? ?show index from 表名
2.創建索引? ? ?create index 索引名字 on 表名(列名)
3.刪除索引? ? ? drop index 索引名 on 表名
另外主鍵和外鍵會自動生成索引,而刪除索引這個操作對于自動生成的無效。
在創建索引時是一個危險操作,因為它會對現有的數據進行一次大規模的整理,如果表很大的胡,會導致服務器收到的請求量劇增。
所以我們會再搞另一個機器來部署mysql服務器,創建同樣的表,并加上索引,然后將需要的表的數據導入這個表中。
索引背后的一些事情
索引是一個改進的樹形結構,B+樹(N叉搜索樹)
B樹
1.每個結點的度都是不一樣的
2.一個結點保存N個key就劃分N+1個區間
3.雖然一個節點可以保存N個key,但是達到一定的規模會觸發節點的分裂,刪除元素達到一定規模則會觸發節點的合并
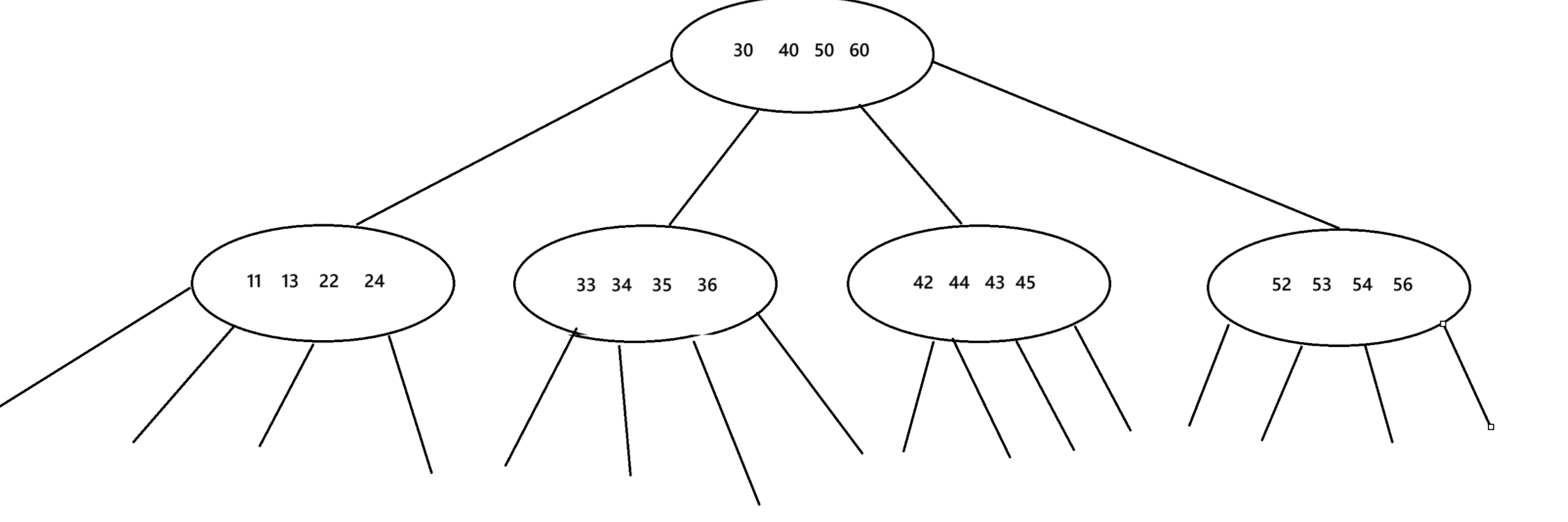
如果用B樹來查詢一個樹可能就會很麻煩,因為會涉及到這顆樹找不到就要返回到上一棵樹來找,可能還不能找到,十分麻煩。
B+樹
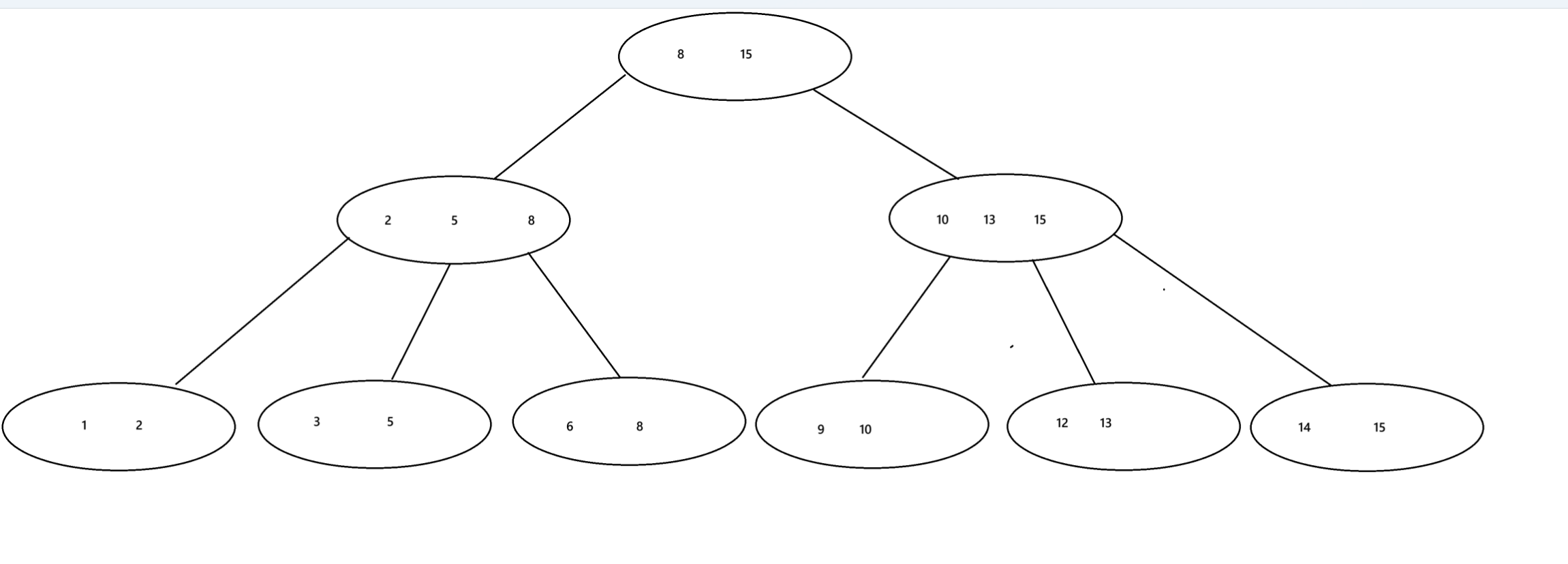
1.B+樹也是一個N叉搜索樹,一個節點上存在N個Key,劃分N個區間
2.每個節點上N個key中,最后一個就是子樹的最大值
3.父節點上的每個key都會以最大值的身份再子節點的對應區間中存在
所以我們看到在葉子節點上包含著樹的所有元素
4.B+樹會使用鏈表這樣的結構,把葉子節點串起來
 ?B樹與B+樹的比較
?B樹與B+樹的比較
對于B樹來說查詢速度往往是不穩定的,因為如果查詢的元素層數高的話就很快,反之,對于B+樹來說最終都會在葉子節點來進行查詢整體時間差距不大,是穩定的。
B+樹的優點
1.N叉搜索樹,樹的高度受限,降低IO次數
2.非常擅長范圍查詢
3.所有查詢最終都是要落到葉子節點上,查詢與查詢之間的花銷都是穩定的。
4.由于葉子節點是全集,會把數據只存儲在葉子節點上,非葉子節點只是存儲一個用來排序的key,這樣使得非葉子節點并不會占用多少空間,葉子節點會非常占用空間,將非葉子節點緩存在內存中,整體的查詢速度又減少了。
四.事務
在轉賬過程中如果A轉賬給B而A的余額減少了,但發生了一些不可避免的意外,使得A的錢扣了,但B的錢卻沒有增加,這就是個很嚴重的錯誤。
而事務可以避免上面問題,且聽我說
1.事務就可以把多個sql打包成一個整體
2.可以保證這些sql要么全部執行,要么一個都沒執行成功。
我們將把多個sql打包在一起作為一個整體來執行,成為“原子性”。
有這么一個過程就是
開啟事務
執行sql
結束事務
主動觸發回滾
回滾
它通過日志的方式,記錄事務中的關鍵操作,這樣記錄的數據就是回滾的依據(一旦發生重啟等操作,就會發現回滾日志有一些需要進行回滾的操作,于是就可以完成這里的回滾)。
事務的一些其他特性
1.原子性
回滾的方式,保證這一系列操作,都能執行正確,或者恢復如初
2.一致性
事務執行之前和之后數據都不能太離譜
3.持久性
事務做出的修改都是在硬盤上持久保存的,重啟服務器,數據仍然存在,事務執行的修改依舊是有效的
4.隔離性
數據庫并發執行多個事務的時候,涉及到的問題
數據庫并發執行
mysql是一個客戶端服務器結構的程序
一個服務器可以為多個客戶端提供服務
多個客戶端都會讓數據庫執行事務。
我們希望數據庫服務器執行效率高,就希望提高并發程度,但是提高了并發程度后一些問題就會顯現出來。
隔離級別就是在“數據正確”和“效率”之間做權衡
往往提升了效率,就會犧牲正確性,提升了正確性就會犧牲效率
問題的展現
1.臟讀問題
假設A是一個寫數據的事務,B是一個讀數據的事務,當A出現的修改數據的情況機會使得B讀取的數據有誤,這些數據是無效數據(臟數據)。
這倆事務一個接一個串的執行,沒事,但并發執行就容易出現臟讀。
我們可以加一個約定或者說是鎖,A寫數據的時候,B不能讀,但是這種方法使得并發性降低了,隔離性提高了,效率降低了,數據準確性提高了。
2.不可重復讀
還是那個假設,這次A寫完了,輪到B來讀了,但在B讀的過程中,A又覺得可以優化,就進行了修改,這使得B又讀到東西又突然變了,這又是無效數據,這次漲記性了,我們又加一個約束,A寫了之后就不能改了,加上前面的約束,使得并發性又進一步降低了,隔離性提高了,效率降低了,數據的準確性提高了。
如果兩個事務之間的影響越大,隔離性就越低,反之。
3.幻讀
還是那個假設,這次A在寫,B閑下來了,B想著總得做點啥吧,所以它也開始寫了,在最后讀的時候把結果集一對發現問題了,這稱為幻讀。
這些問題因為并發而存在,所以我們要想去避免這些問題最好的辦法就是不去并發,即使串行化,這與我們的初衷相違背了,雖然數據是最為準確的,但并發程度最低,隔離性最高,效率最低。
讀未提交并發程度最高, 速度最快, 隔離性最低,準確性最低
臟讀
讀已提交引入了寫加鎖,只能讀寫完之后提交的版本并發程度降低了,速度降低了:隔離性提高了,準確性提高了
不可重復讀
可重復讀引入了寫加鎖和讀加鎖. 寫的時候不能讀,讀的時候也不能寫并發程度又進一步降低了,速度降低了;隔離性提高了,準確性提高了
幻讀
串行化嚴格的按照 串行 的方式,一個一個的執行事務.并發程度最低(沒有并發),速度最低:隔離性最高,準確性最高。
五.數據庫編程(java)(JDBC)
數據庫編程,需要數據庫服務器,提供一些API(Application Programming Interface)應用程序編程接口,提供給一組類/函數進行調用來完成一些功能。
在導入了jar之后我們就可以開始操作了。
1.先創建DataSoure


URL是網絡上資源的位置,給jdbc操作mysql用的,我們在這里進行了向下調整,mysqldatabase這個類名不去擴散到其他地方,降低耦合性。
需要注意的是127.0.0.1是一個環回IP,一般是jdbc和mysql在同一個主機上使用環回IP就可以。

在設置了用戶名與密碼之后我們就要建立于服務器之間的連接
2.建立數據庫于服務器之間的連接

我們得提前拋出一個異常才不會爆紅

3.構造一個sql


我們構造了sql語句后會進行解析檢查,減輕服務器的負擔。?
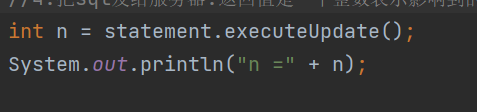
4.把sql發送給服務器,返回值是一個整數表示影響到的整數
只針對于增刪改,查有另一套
?
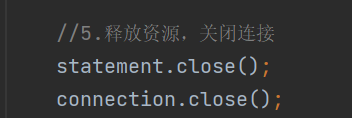
5.釋放資源,關閉連接
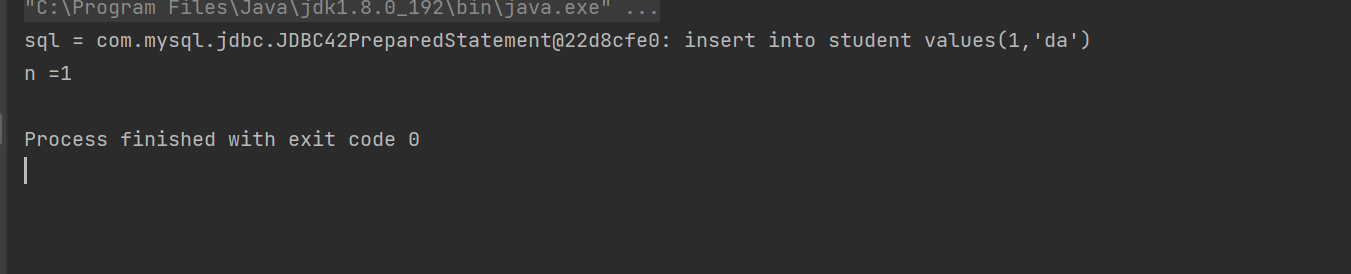 ?
?
我們用jdbc操作服務器成功了?
當然還可以執行其他語句?

?
或者自己輸入

 ?我們來看看查詢這方面
?我們來看看查詢這方面
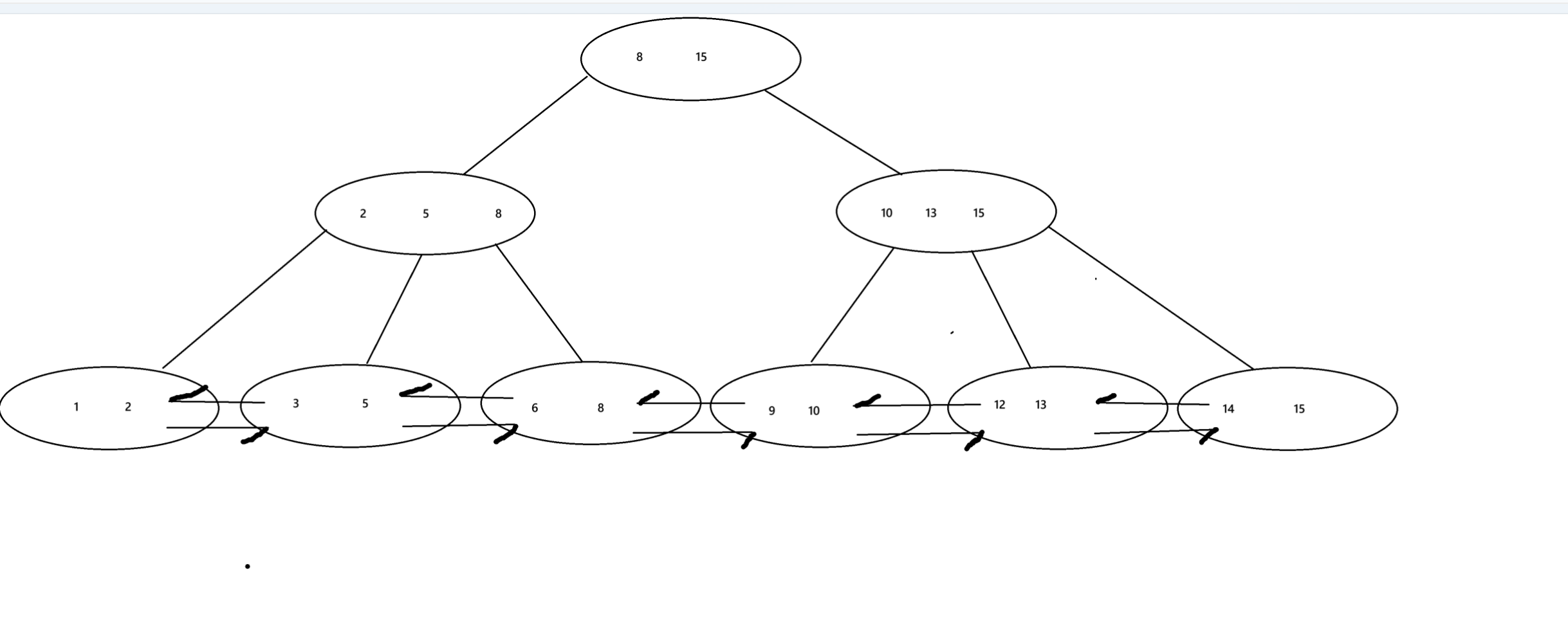
public static void main(String[] args) throws SQLException {//1.創建DataSoureDataSource dataSource = new MysqlDataSource();((MysqlDataSource) dataSource).setUrl("jdbc:mysql://127.0.0.1:3306/java109?characterEncoding=utf8&useSSL=false");((MysqlDataSource) dataSource).setUser("root");((MysqlDataSource) dataSource).setPassword("1793334060qq.");//2.建立連接Connection connection = dataSource.getConnection();//3.構造sqlString sql = "select * from student where id = ?";PreparedStatement statement = connection.prepareStatement(sql);statement.setInt(1,100);//4.執行 sql// ResultSet 表示查詢的結果集合ResultSet resultSet = statement.executeQuery();//5.遍歷結果集合//通過next方法就可以獲得臨時表中的每一行數據,如果獲取到最后一行之后,再執行next 返回false,循環結束while(resultSet.next()){//針對這一行進行處理//取出列的數據int id = resultSet.getInt("id");String name = resultSet.getString("name");System.out.println("id = " + id + ",name = " + name);}//6.釋放資源resultSet.close();statement.close();connection.close();}?最大的不同在于ResuSet,resultset光標的指向不是有效數據所以要看next()。
自增id
B+樹
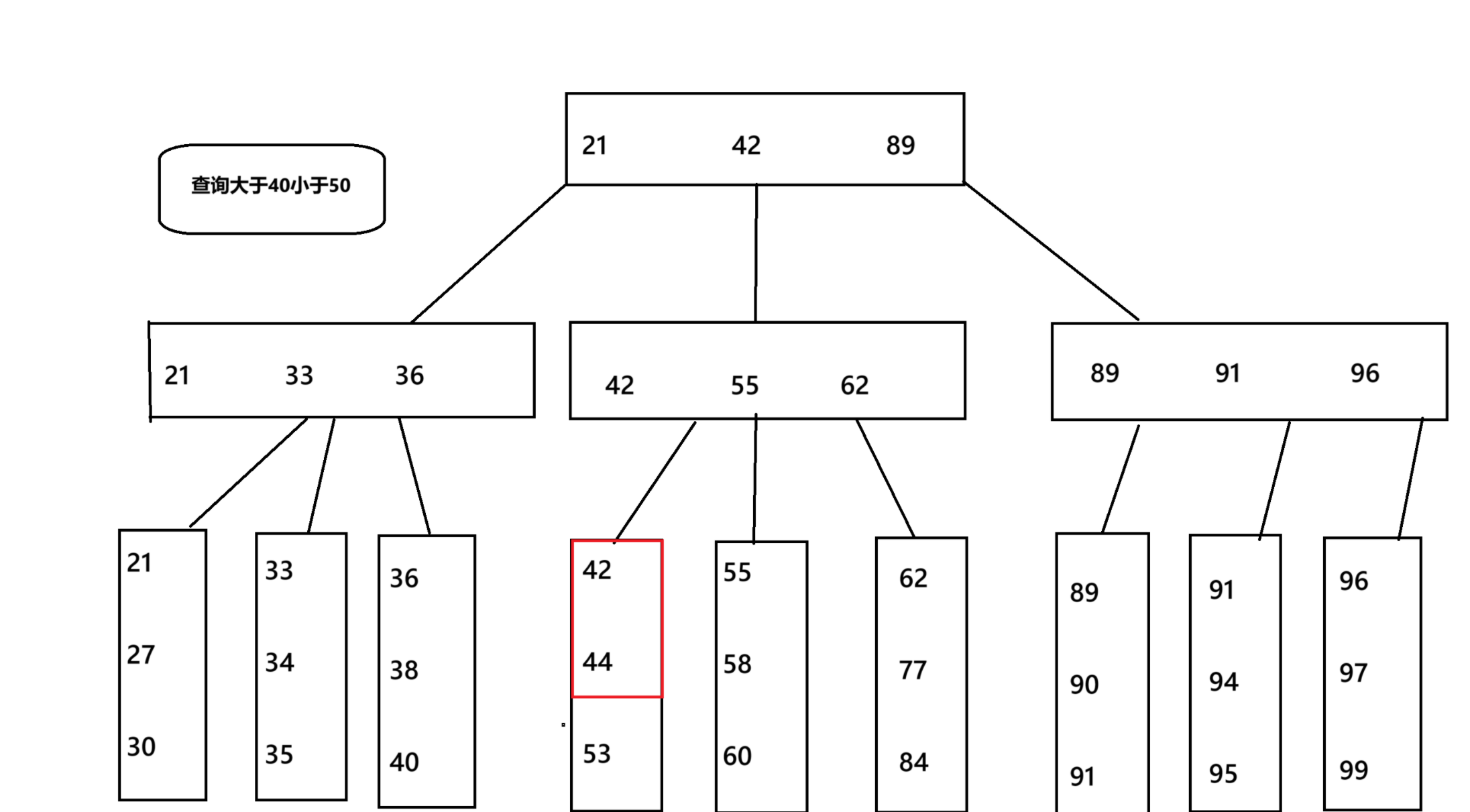
?
對于B+樹來說,我們在查找到大于40小于50的數,我們就會來到42和55這兩列,把這兩列加載到內存中,然后按照順序應該是找到了42,44,當我們想插入43,也是一樣,我們會找找到我們要插入的位置,但當我們接下來要插入45時,如果說是id自增,則會在當前的列查找并插入,但如果不是自增,跑到了89這一列,我們就要先將原來的緩存置換出去,在緩存中加載89這一列,然后加載到磁盤,沒找到位置就又去緩存置換找到42這一列,這一列顯然這是浪費時間的。?
全表遍歷
比如對于1000條數據進行遍歷,默認按照id自增遍歷的話,我們就可以進行分條遍歷,因為id時自增,則只需要考慮邊界條件即可,以100個數據為一條進行遍歷。
缺點
可預測性,id自增以為這別人可以輕易知道你的數據總數。
可能用盡,id時整形總有用完的一天。
分庫分表困難,如果兩個庫都用自增id,id就重復了。
?


![[C++] 小游戲 決戰蒼穹](http://pic.xiahunao.cn/[C++] 小游戲 決戰蒼穹)










(第2版)學習筆記 02.OpenGL圖像管線)



)

