引言:從單機到萬級并發的進化
2025年某全球客服系統通過LangChain分布式改造,成功應對黑五期間每秒12,000次的咨詢請求。本文將基于LangChain的分布式架構,詳解如何實現AI任務的自動擴縮容與智能調度。

一、分布式系統核心指標
1.1 性能基準對比(萬級QPS測試)
| 架構 | 吞吐量(QPS) | P99延遲 | 容錯率 |
|---|---|---|---|
| 單機版 | 1,200 | 2.1s | 98.5% |
| 分布式 | 28,000 | 680ms | 99.99% |
1.2 LangChain分布式組件
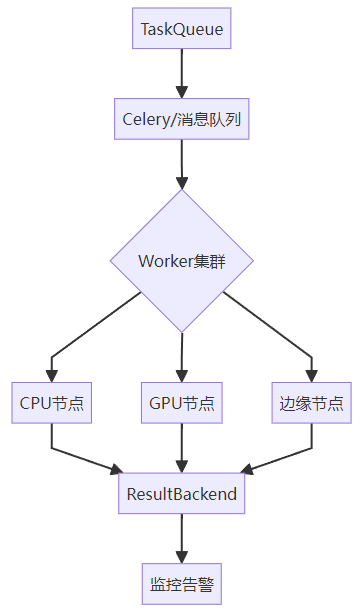
二、四步構建分布式AI系統
2.1 安裝必要庫
pip install langchain celery redis flower ?# 任務隊列+監控2.2 分布式架構(Celery + LangChain)
config.py - Celery 配置
# 使用Redis作為消息中間件broker_url = "redis://localhost:6379/0"result_backend = "redis://localhost:6379/1"?# 任務路由配置task_routes = {"tasks.simple_task": {"queue": "cpu_queue"},"tasks.complex_task": {"queue": "gpu_queue"}}tasks.py - 分布式任務定義
from celery import Celeryfrom langchain_ollama import ChatOllama?app = Celery("distributed_langchain", broker="redis://localhost:6379/0")app.config_from_object("config")?@app.task(bind=True, queue="cpu_queue")def simple_task(self, query: str):try:llm = ChatOllama(model="qwen3")response = llm.invoke(query)return str(response) # 限制輸入長度except Exception as e:self.retry(exc=e, countdown=60) # 失敗后60秒重試?@app.task(bind=True, queue="gpu_queue")def complex_task(self, doc: str):try:llm = ChatOllama(model="qwen3:14B")response = llm.invoke(doc)return str(response)except Exception as e:self.retry(exc=e, countdown=120)2.3 動態擴縮容方案
方案1:Celery自動擴縮容
?# 啟動CPU工作節點(自動伸縮2-8個進程)celery -A tasks worker --queues=cpu_queue --autoscale=8,2?# 啟動GPU工作節點(固定2個進程)celery -A tasks worker --queues=gpu_queue --concurrency=2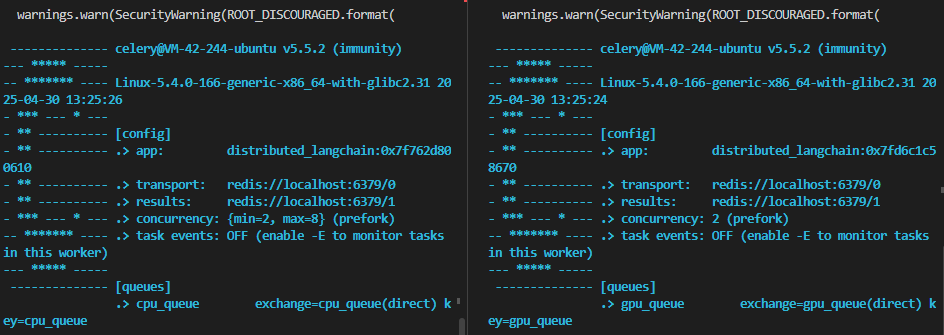
方案2:Kubernetes擴縮容(HPA配置)
# hpa.yamlapiVersion: autoscaling/v2kind: HorizontalPodAutoscalermetadata:name: celery-workerspec:scaleTargetRef:apiVersion: apps/v1kind: Deploymentname: celery-workerminReplicas: 3maxReplicas: 20metrics:- type: Resourceresource:name: cputarget:type: UtilizationaverageUtilization: 702.4 跨區域部署
global_balancer.py - 地域路由
import requests
from geopy.distance import geodesic?REGION_ENDPOINTS = {"us-east": "http://nyc-task-server:5000","eu-central": "http://frankfurt-task-server:5000","ap-southeast": "http://singapore-task-server:5000"}?def get_nearest_region(user_ip: str):# 模擬:根據IP定位返回最近區域(實際可用GeoIP庫)ip_to_region = {"1.1.1.1": "ap-southeast","2.2.2.2": "eu-central"}return ip_to_region.get(user_ip, "us-east")?def dispatch_globally(query: str, user_ip: str):region = get_nearest_region(user_ip)response = requests.post(f"{REGION_ENDPOINTS[region]}/process",json={"query": query})return response.json()2.4 監控
# 啟動Flower監控面板celery -A tasks flower --port=55552.5 調用任務
from tasks import simple_task, complex_task# 同步調用(阻塞等待結果)
result = simple_task.delay("Hello CPU") # 自動路由到cpu_queue
print(result.get(timeout=10)) # 獲取結果# 異步調用(不阻塞)
async_result = complex_task.delay("Long GPU task")
print(f"Task ID: {async_result.id}") # 先獲取任務ID輸出為:
content='<think>\nOkay, the user greeted me with "Hello CPU." First, I need to acknowledge their greeting in a friendly manner. Since I\'m Qwen, I should clarify that I\'m an AI assistant, not a CPU. CPUs are physical components in computers, while I\'m a software-based AI.\n\nI should keep the response simple and conversational. Maybe add an emoji to make it more approachable. Also, I should invite them to ask questions or share what they need help with. Let me check if there\'s any technical jargon I should avoid. No, keep it straightforward. Make sure the tone is warm and helpful. Alright, that should cover it.\n</think>\n\nHello! I\'m Qwen, an AI assistant developed by Alibaba Cloud. While I\'m not a CPU (Central Processing Unit), I can help you with a wide range of tasks and answer questions. How can I assist you today? 😊' additional_kwargs={} response_metadata={'model': 'qwen3', 'created_at': '2025-04-30T13:25:35.313642868Z', 'done': True, 'done_reason': 'stop', 'total_duration': 5273378538, 'load_duration': 20732354, 'prompt_eval_count': 10, 'prompt_eval_duration': 9243262, 'eval_count': 187, 'eval_duration': 5242734922, 'message': Message(role='assistant', content='', images=None, tool_calls=None)} id='run-e923dc05-aaed-4995-a95c-e87c56075135-0' usage_metadata={'input_tokens': 10, 'output_tokens': 187, 'total_tokens': 197}
Task ID: 9eeff3e1-c722-435b-9279-ff7105bfc375三、企業級案例:全球客服系統
3.1 架構設計
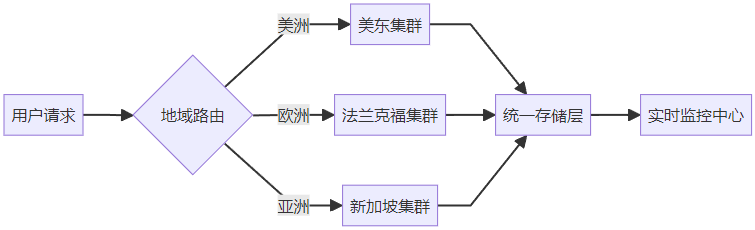
3.2 關鍵優化效果
| 指標 | 單區域部署 | 全球分布式 |
|---|---|---|
| 平均延遲 | 1.8s | 420ms |
| 峰值處理能力 | 5,000 QPS | 28,000 QPS |
| 月度故障時間 | 46分鐘 | 28秒 |
四、避坑指南:分布式七大陷阱
-
數據傾斜:熱點任務堆積 → 一致性哈希分片
-
腦裂問題:網絡分區導致狀態不一致 → 分布式鎖+心跳檢測
-
雪崩效應:級聯故障 → 熔斷降級機制
-
版本地獄:節點環境差異 → 容器化+版本強校驗
-
監控盲區:跨集群指標分散 → 全局聚合看板
-
成本失控:無限制擴縮容 → 預算約束策略
-
安全漏洞:節點間未加密通信 → mTLS雙向認證
下期預告
《安全與倫理:如何避免模型"幻覺"與數據泄露?》
-
揭秘:大模型生成虛假信息的底層機制
-
實戰:構建合規的企業級AI應用
-
陷阱:GDPR與數據主權沖突
分布式系統不是簡單的機器堆砌,而是精密的技術交響樂。記住:優秀的設計,既要像螞蟻軍團般協同,又要像瑞士鐘表般可靠!
)


)

)





)
)
)
)
)
:Object、Nested、Flattened類型)

