
本篇博客給大家帶來的是網絡HTTP協議的知識點, 重點介紹HTTP的報文格式.
🐎文章專欄: JavaEE初階
🚀若有問題 評論區見
? 歡迎大家點贊 評論 收藏 分享
如果你不知道分享給誰,那就分享給薯條.
你們的支持是我不斷創作的動力 .
王子,公主請閱🚀
- 要開心
- 要快樂
- 順便進步
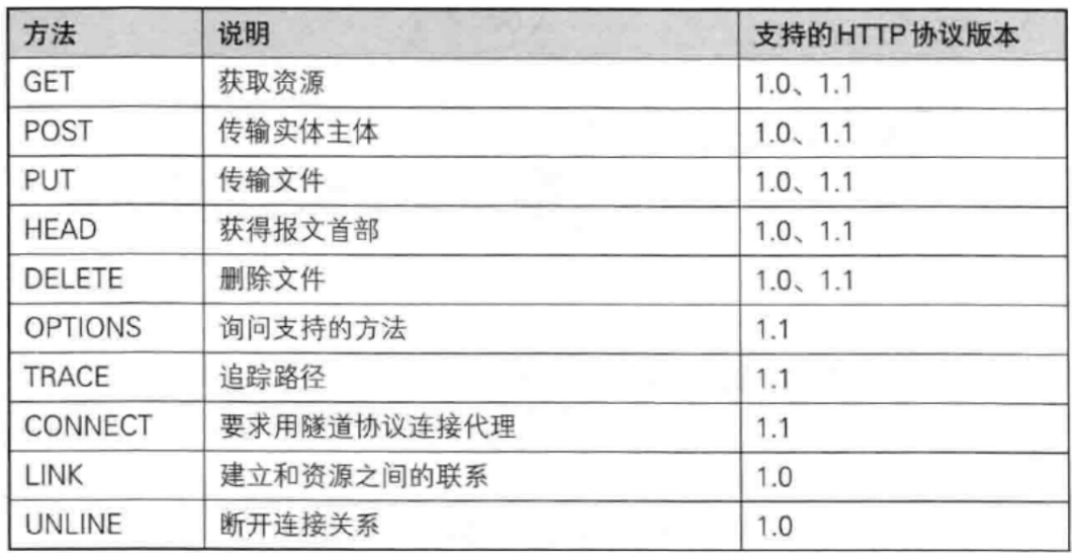
- 1. 什么是HTTP
- 2. Fiddler
- 3. HTTP 協議格式
- 4. HTTP請求
- 4.1 認識URL
- 4.2 認識 "方法" (method)
- 4.2.1 GET方法
- 4.2.2 POST方法
- 4.2.3 其他方法
- 4.3 認識請求"報頭"(header)
- 4.4 認識正文(body)
要開心
要快樂
順便進步
1. 什么是HTTP
HTTP (全稱為 “超文本傳輸協議”) 是一種應用非常廣泛的應用層協議.
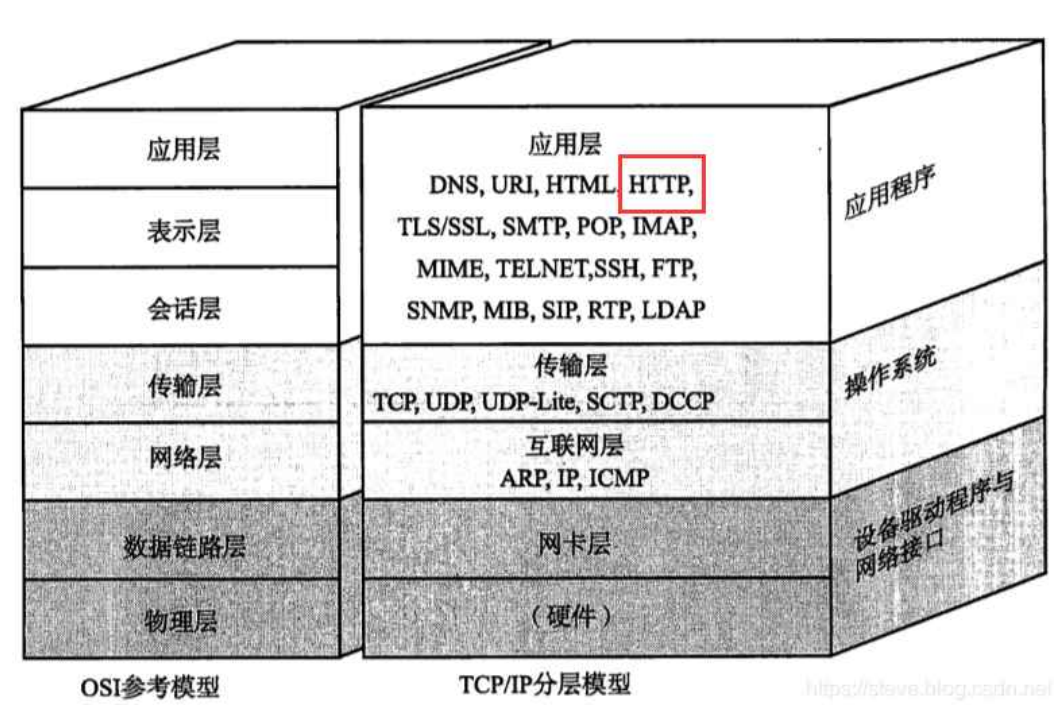
HTTP 往往是基于傳輸層的 TCP 協議實現的. (HTTP1.0, HTTP1.1, HTTP2.0 均基于TCP, HTTP3 基于UDP 實現).
目前我們主要使用的還是 HTTP1.1 和 HTTP2.0. 文章討論的 HTTP 以 1.1 版本為主.
平時打開一個網站, 就是通過 HTTP 協議來傳輸數據的.
當我們在瀏覽器中輸入一個 百度搜索的 “網址” (URL) 時, 瀏覽器就給搜狗的服務器發送了一個 HTTP請求, 搜狗的服務器返回了一個 HTTP 響應.
這個響應結果被瀏覽器解析之后, 就展示成我們看到的頁面內容. (這個過程中瀏覽器可能會給服務器發送多個 HTTP 請求, 服務器會對應返回多個響應, 這些響應里就包含了頁面 HTML, CSS, JavaScript, 圖片, 字體等信息).
“超文本” 的含義, 就是傳輸的內容不僅僅是文本(比如 html, css 這個就是文本), 還可以是一些其他的資源, 比如圖片, 視頻, 音頻等二進制的數據.
HTTP 協議是一種"一問一答"結構模型的協議.
一問一答,訪問網站.
多問一答,上傳文件.
一問多答,下載文件.
多問多答,串流/遠程桌面.
和前面的 TCP/IP/UDP 和這些不同,HTTP 的報文格式,要分兩個部分來看待:請求+響應. 學習HTTP協議就是學習HTTP的報文格式.
2. Fiddler
Fiddler工具是專門用來抓HTTP的抓包工具. Fiddler下載路徑
下載完直接一路next即可. 下完之后打開Fidder,根據以下步驟, 配置一下, 才能抓取https數據包.
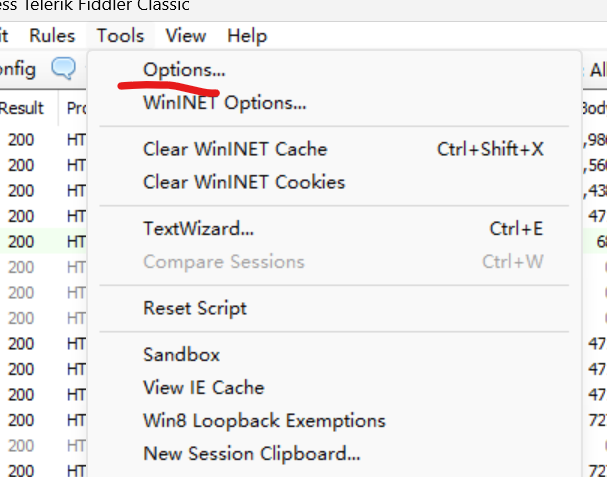
點HTTPS的時候, 會彈出一個窗口, 點擊yes即可. 然后按下圖把能勾的全部勾選.
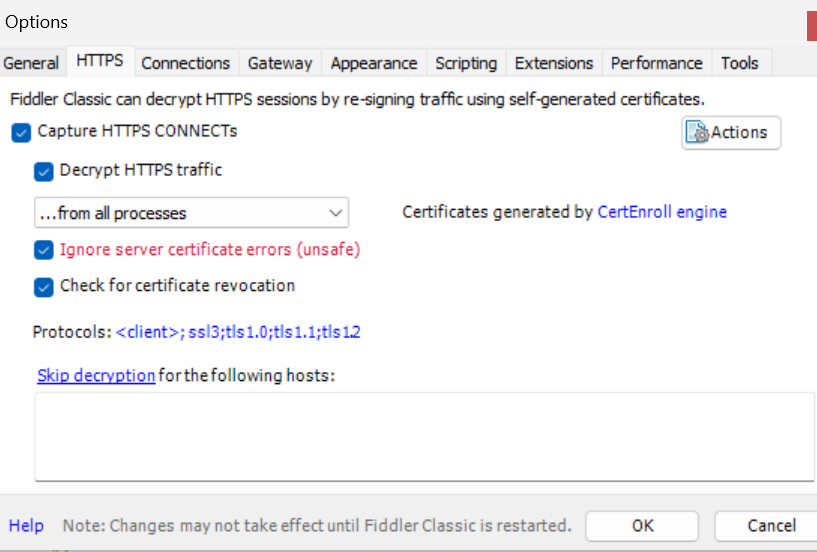
注意: 使用Fiddler的時候, 加速器和VPN都不要開. 代理程序之間可能會沖突.
3. HTTP 協議格式
Ⅰ 抓取一個包
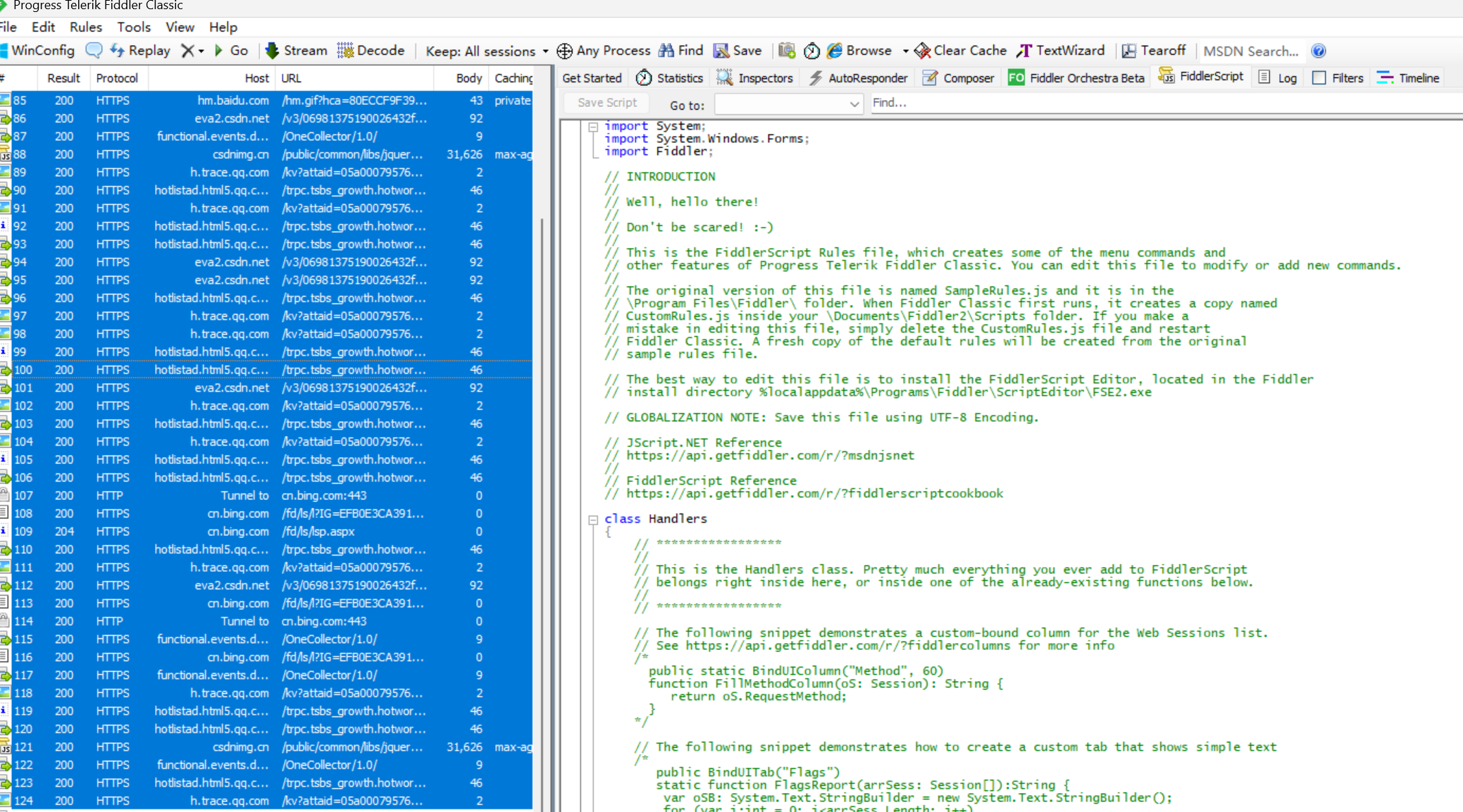
使用 ctrl + a 全選左側的抓包結果, delete 鍵清除所有被選中的結果.
刷新搜狗搜索頁面:

左側藍色那一條響應就是html(網頁)需要重點關注. 灰色的可以直接忽略.
右側點擊Raw, (raw表示原始的), 上方的數據表示請求, 下方的數據表示響應.
Ⅱ 分析請求
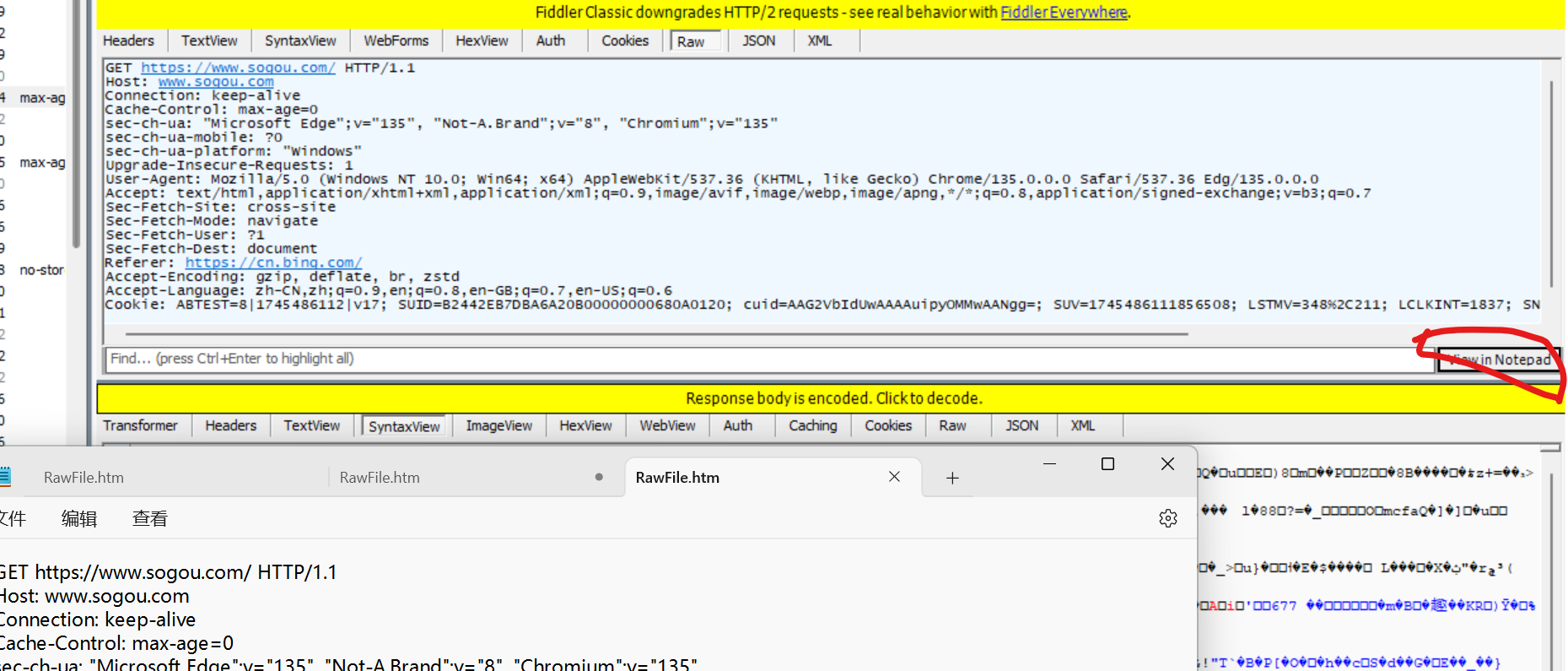
點擊紅圈處, 將請求以文本形式呈現. 關閉文本的自動換行.
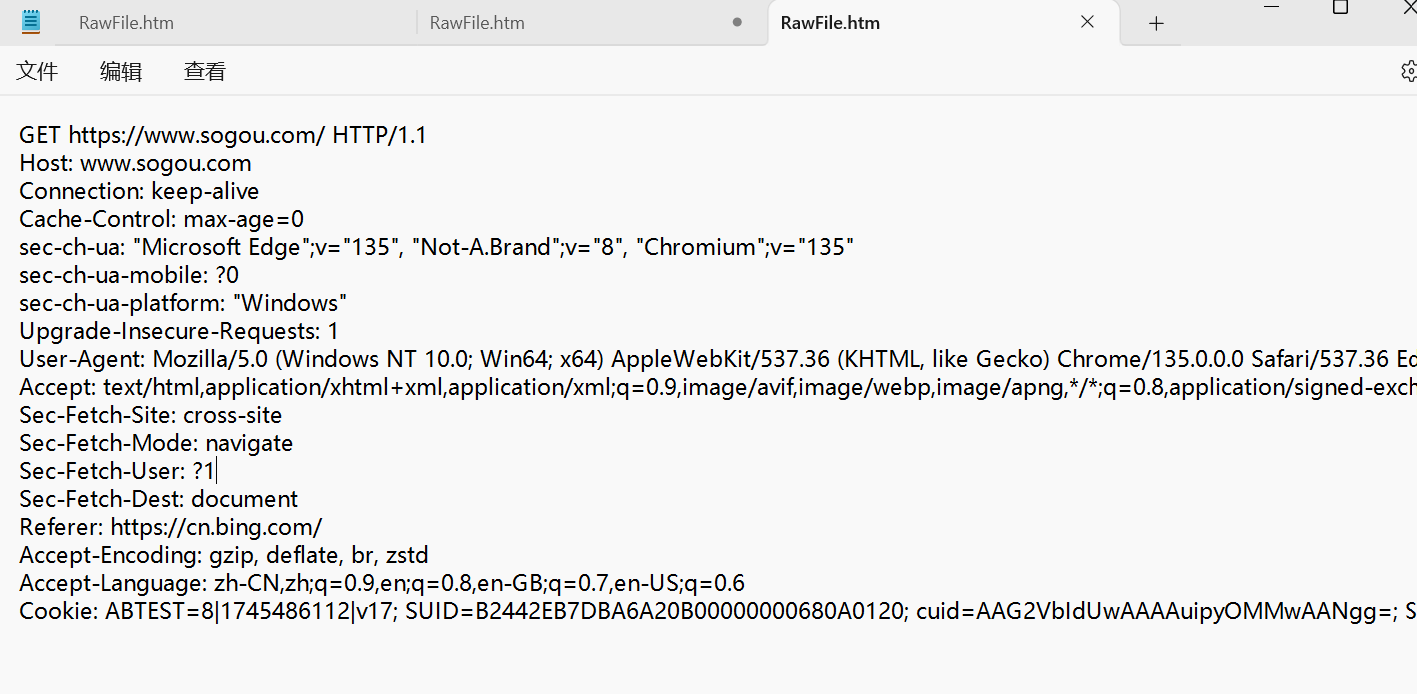
HTTP 協議是文本格式的協議, 協議里的內容都是字符串.
TCP,UDP,IP. 都是二進制格式的協議.
① 首行
首行有三個部分信息, 三個部分使用空格分割.
1.GET, HTTP請求的"方法"(method)
2.URL 唯一資源定位符,描述一個資源在網絡上的位置.

3.版本號(HTTP/1.1)
② 請求頭(header)
請求頭是一個鍵值對結構的數據.(有很多鍵值對)每個鍵值對,都是獨占一行的.
鍵和值之間,使用 :空格 來區分
這里的鍵值對都是屬于"標準規定"的.
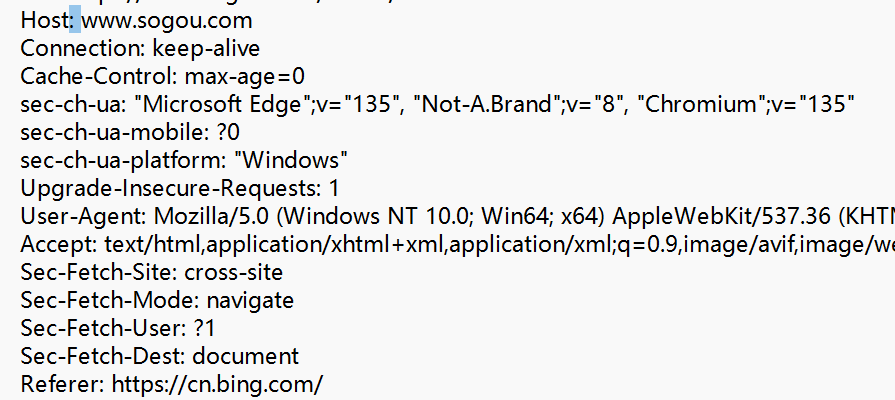
③ 空行, 請求頭的結束標記.
④ 正文(body)
有的 HTTP 請求有,有的HTTP沒有, 如上圖的例子中就沒有.
Ⅱ 分析響應
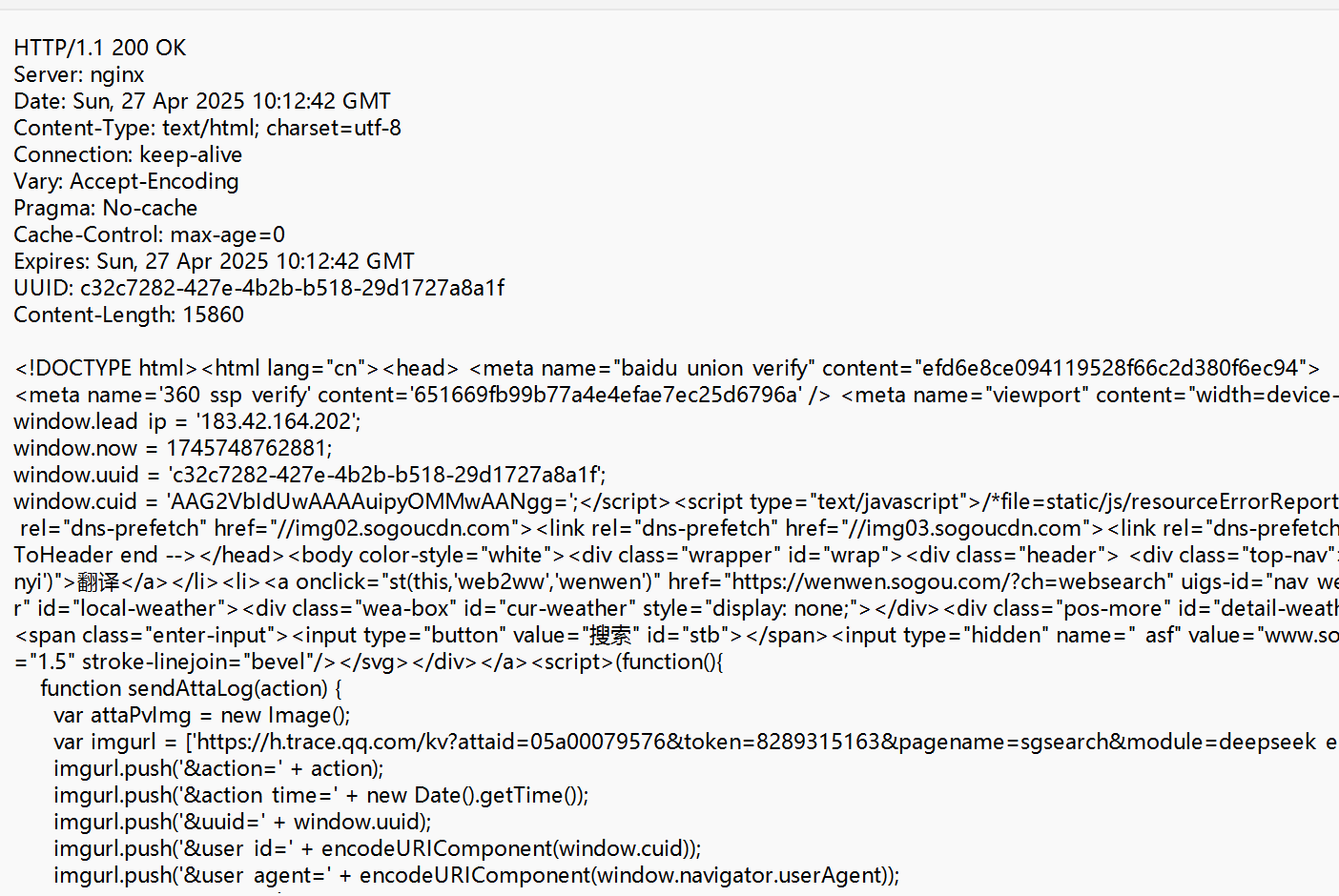
① 首行
首行同樣分為三個部分:
1.版本號 HTTP/1.1
2.狀態碼(200) 描述了請求的結果.
3.狀態碼描述(OK)
② 響應頭
也是鍵值對結構(有多個鍵值對)每個鍵值對獨占一行.鍵和值之間使用 :空格 來區分鍵值對也是"標準規定”的.
③ 空行
響應頭的結束標記.
④ 正文 (body)
正文里的內容可能比較長,可能是多種格式,HTML, CSS, JS, JSON, XML, 圖片, 字體, 視頻,音頻.
4. HTTP請求
了解了HTTP協議格式之后, 我們來看看請求中某些重要部分的的具體細節.
4.1 認識URL
平時我們俗稱的 “網址” 其實就是說的 URL (Uniform Resource Locator 統一資源定位符).
互聯網上的每個問文件都有一個唯一的URL,它包含的信息指出文件的位置以及瀏覽器應該怎么處理它. URL 的詳細規則由 因特網標準RFC1738 進行了約定.
文檔鏈接
Ⅰ URL 基本格式
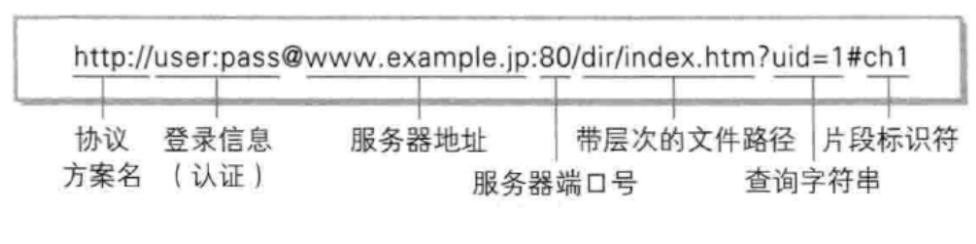
一個具體的 URL:
https://v.bitedu.vip/personInf/student?userId=10000&classId=100
在這個 URL 中有些信息被省略了.
① https : 協議方案名. 常見的有 http 和 https, 也有其他的類型. (例如訪問 mysql 時用的jdbc:mysql)
② user:pass : 登陸信息. 一般都會省略.
③ v.bitedu.vip : 服務器地址. 此處是一個 “域名”, 域名會通過 DNS 系統解析成一個具體的 IP 地址. 這個位置可以是域名也可以是IP地址.
④端口號: 上面的 URL 中端口號被省略了. 當端口號省略的時候, 瀏覽器會根據協議類型自動決定使用哪個端口. 例如 http 協議默認使用 80 端口, https 協議默認使用 443 端口.
⑤ /personInf/student : 帶層次的文件路徑.
⑥ userId=10000&classId=100 : 查詢字符串(query string). 本質是一個鍵值對結構. 鍵值對之間使用 & 分隔. 鍵和值之間使用 = 分隔.
⑦ 片段標識: 此 URL 中省略了片段標識. 片段標識主要用于頁面內跳轉.例如 Vue 官方文檔:鏈接: Vue 通過不同的片段標識跳轉到文檔的不同章節
使用 ping 命令查看域名對應的 IP 地址. 以如下鏈接為例
https://cn.vuejs.org/guide/essentials/application.html
① 在開始菜單中輸入 cmd , 打開 命令提示符.
② 在 cmd 中輸入 ping cn.vuejs.org , 即可看到域名解析的結果.

關于 query string
query string 中的內容是鍵值對結構. 其中的 key 和 value 的取值和個數, 完全都是程序猿自己約定的. 我們可以通過這樣的方式來自定制傳輸我們需要的信息給服務器.
URL 中的可省略部分
① 協議名: 可以省略, 省略后默認為 http://
② ip 地址 / 域名: 在 HTML 中可以省略(比如 img, link, script, a 標簽的 src 或者 href 屬性). 省略后表示服務器的 ip / 域名與當前 HTML 所屬的 ip / 域名一致.
③ 端口號: 可以省略. 省略后如果是 http 協議, 端口號自動設為 80; 如果是 https 協議, 端口號自動設為443.
④ 帶層次的文件路徑: 可以省略. 省略后相當于 / . 有些服務器會在發現 / 路徑的時候自動訪問/index.html.
⑤ 查詢字符串: 可以省略.
⑥ 片段標識: 可以省略.
關于 urlencode
urlencode 本質上是一種轉義字符. 像 / ? : 等這樣的字符, 已經被url當做特殊意義理解了. 因此這些字符不能隨意出現.
比如, 某個參數中需要帶有這些特殊字符, 就必須先對特殊字符進行轉義. 像中文,漢字也需要轉義. urlencode工具
怎么轉義呢?
比如: + 的十六進制是 2B.那么 + 轉義后的結果就是 %2B.
后面使用 url 的時候, 要記得針對 query string 的內容進行好urlencode 工作. 如果不處理好,有些瀏覽器就可能會解析失敗,導致請求無法正常進行.
4.2 認識 “方法” (method)
4.2.1 GET方法
GET 是最常用的 HTTP 方法. 常用于獲取服務器上的某個資源.
在瀏覽器中直接輸入 URL, 此時瀏覽器就會發送出一個 GET 請求.
另外, HTML 中的 link, img, script 等標簽, 也會觸發 GET 請求.
使用 JavaScript 中的 ajax 也能構造 GET 請求.
Ⅰ 使用 Fiddler 觀察 GET 請求
打開搜狗主頁,觀察抓包結果.
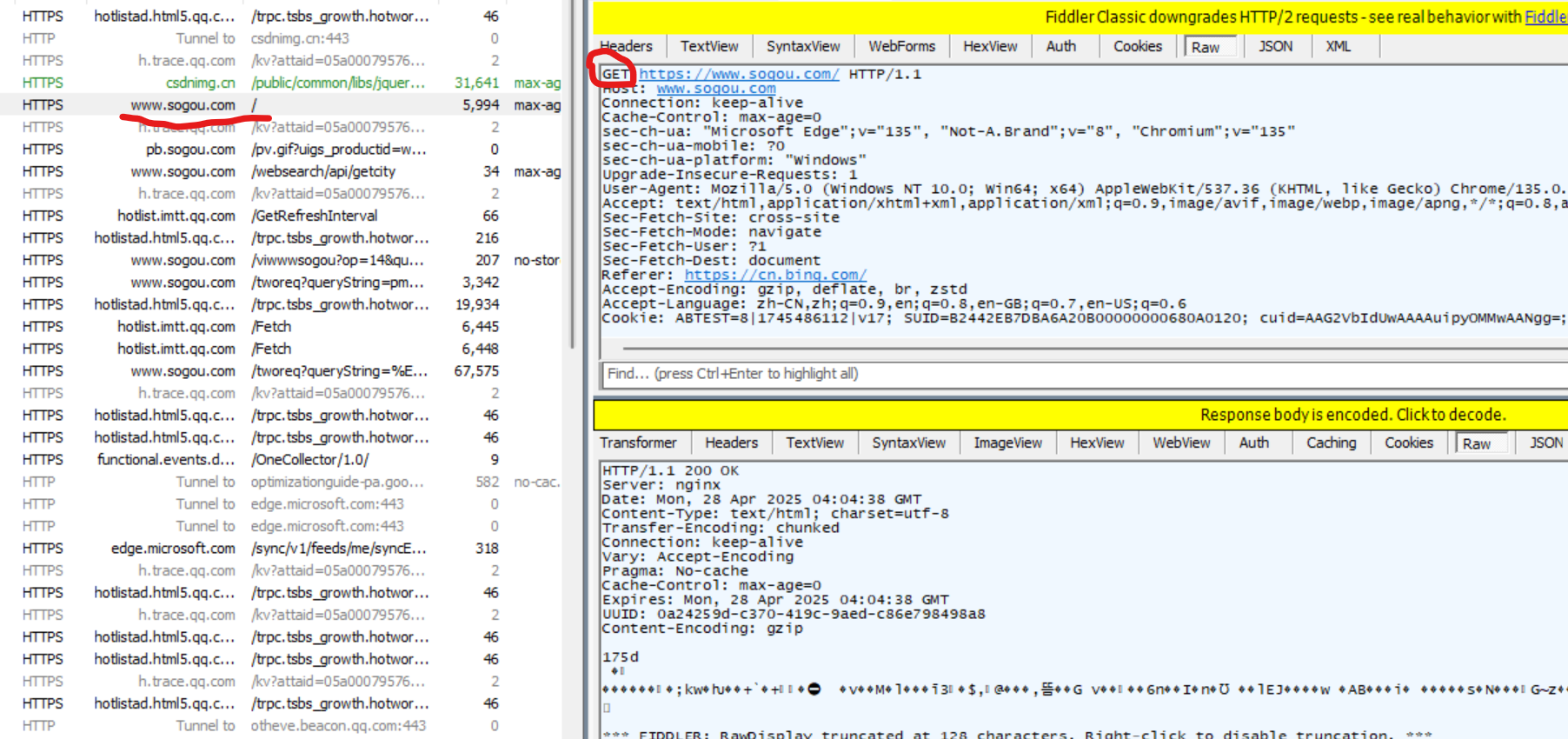
在上圖中可以看到,紅線上的HTTPS發送GET請求.
Ⅱ GET請求的特點
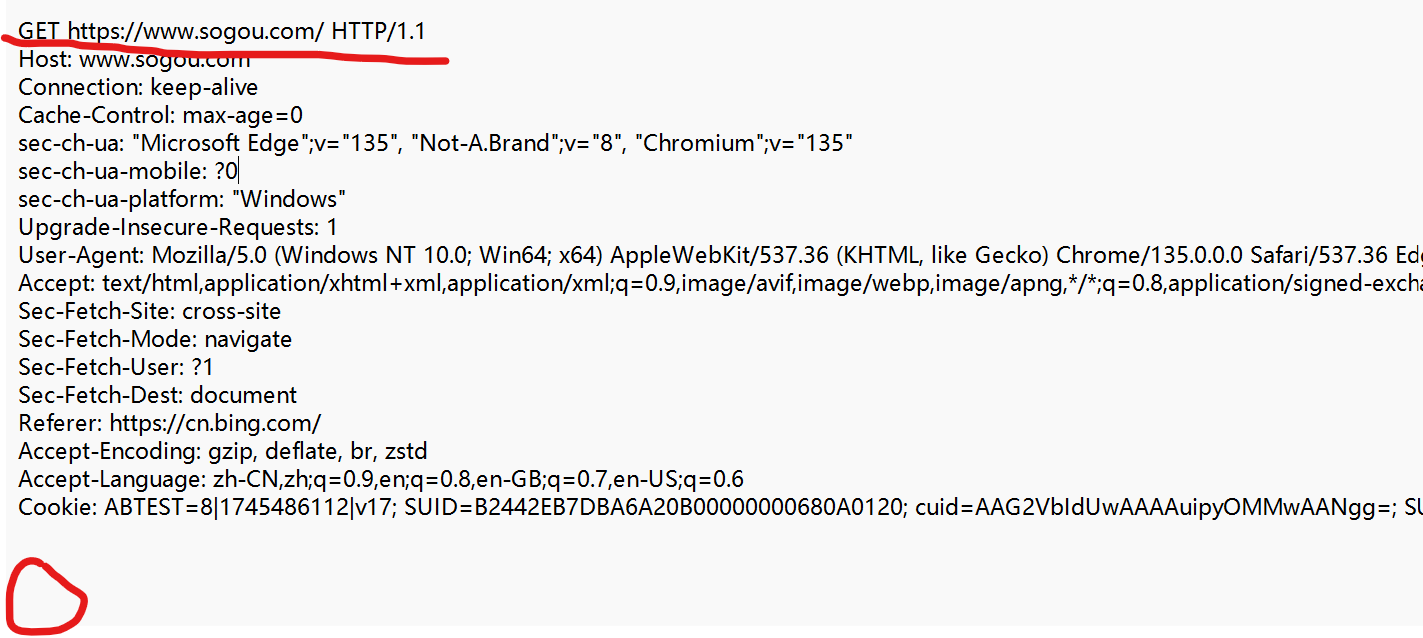
① 首行的第一部分為 GET.
② URL 的 query string 可以為空, 也可以不為空.
③ header 部分有若干個鍵值對結構.
④ body 部分為空.
⑤ GET 請求的 URL 長度問題,RFC 2616 標準文檔中沒有對URL的長度有任何限制,實際 URL 的長度取決于瀏覽器的實現和 HTTP 服務器端的實現.
4.2.2 POST方法
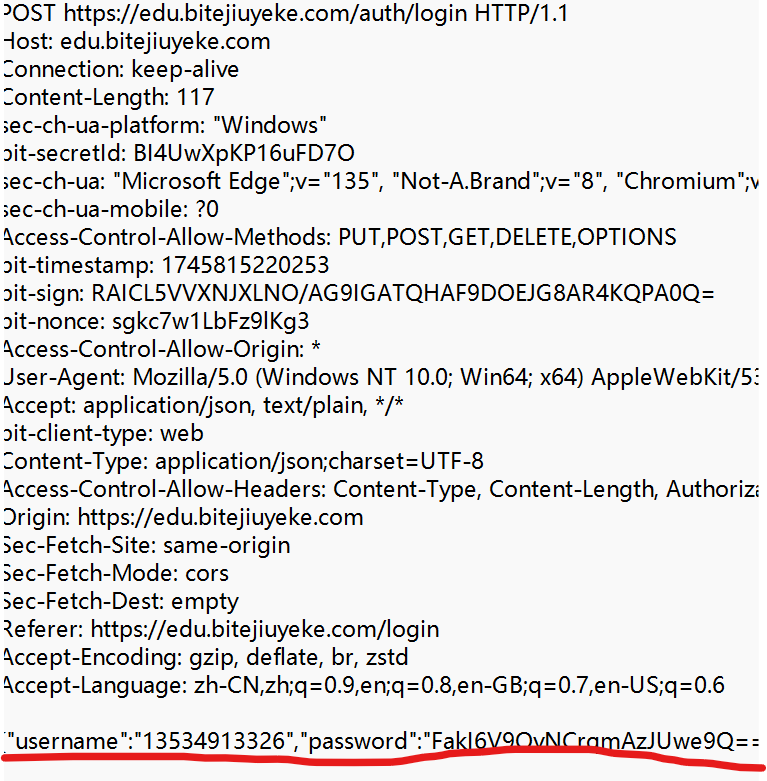
POST 方法也是一種常見的方法. 多用于提交用戶輸入的數據給服務器(例如登陸頁面,上傳文件等).
Ⅰ 使用Fiddler觀察POST方法.
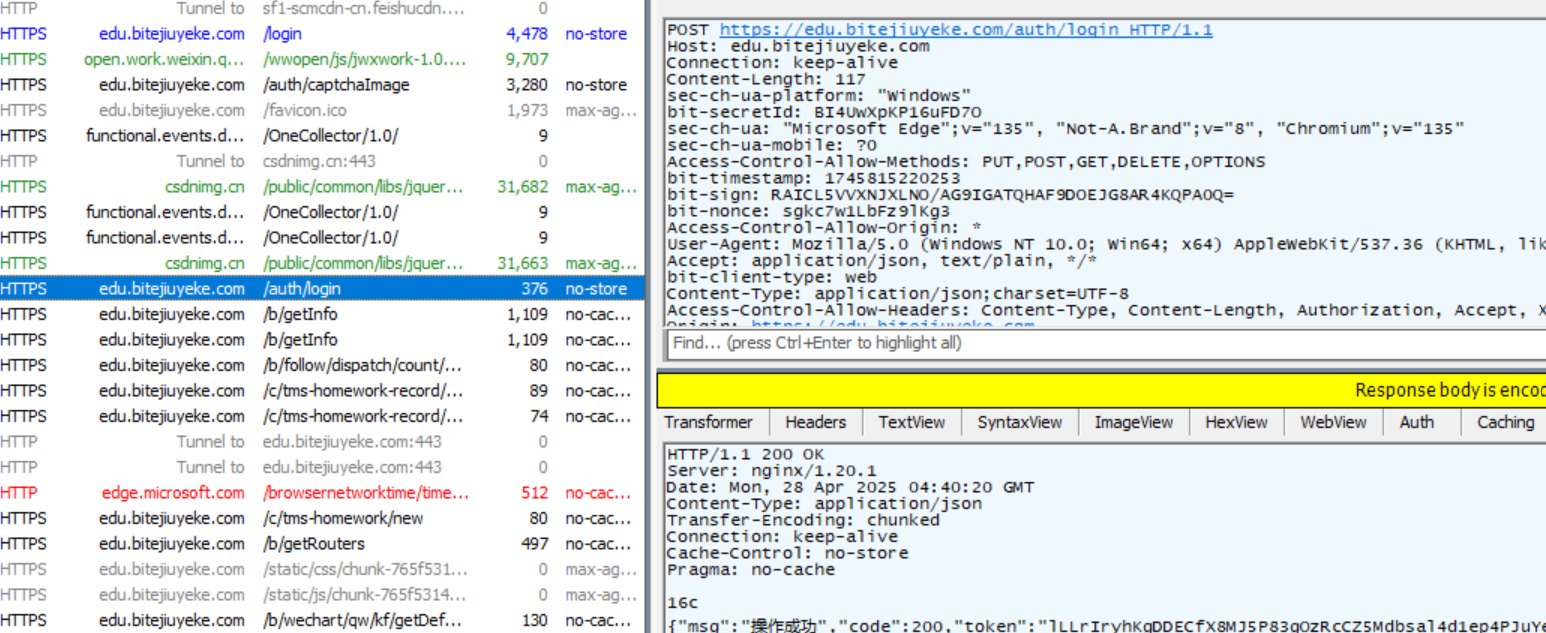
點擊請求,查看請求詳情.
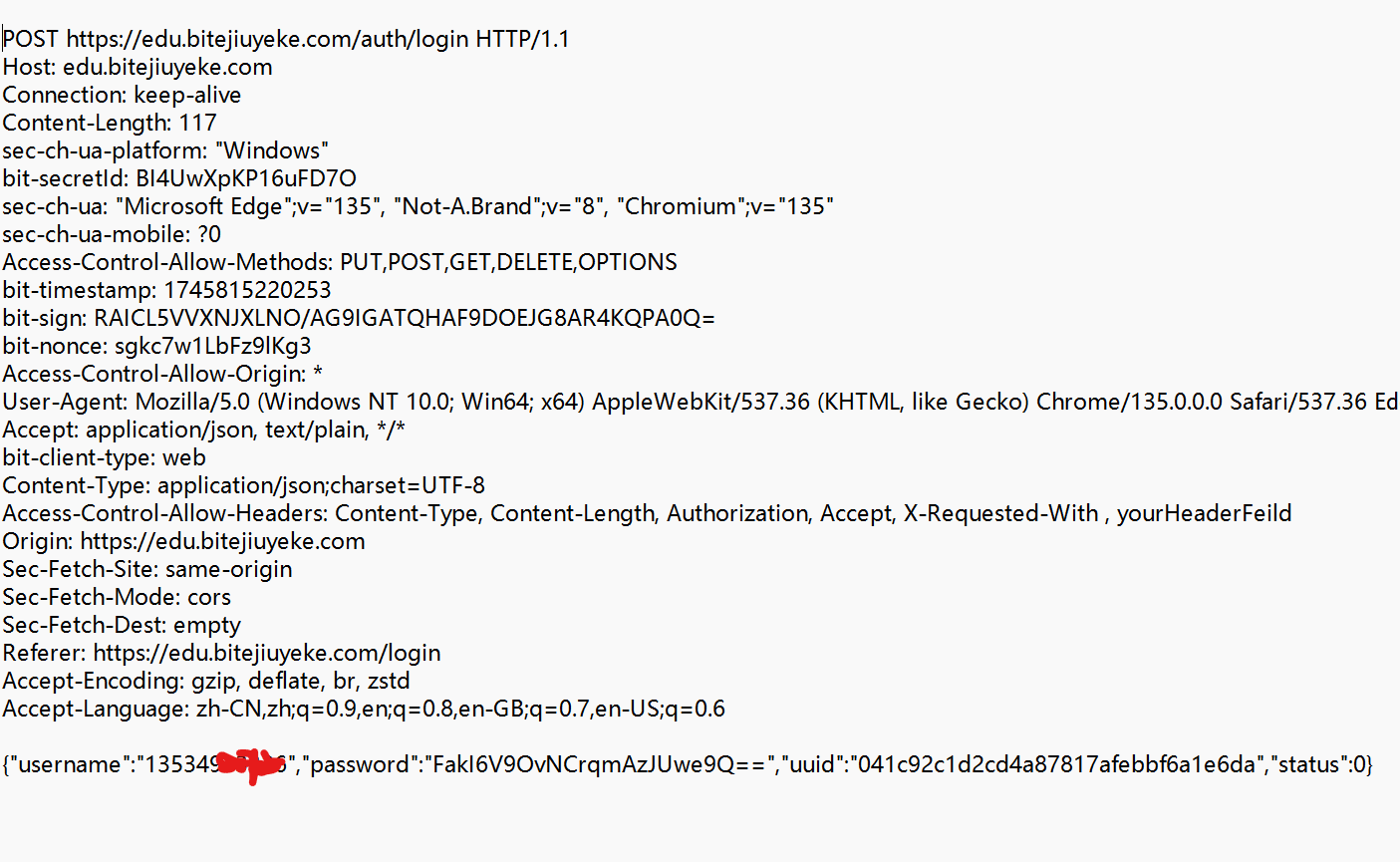
Ⅱ POST請求的特點
① 首行的第一部分為 POST.
② URL 的 query string 一般為空 (也可以不為空).
③ header 部分有若干個鍵值對結構.
④ body 部分一般不為空. body 內的數據格式通過 header 中的 Content-Type 指定. body 的長度由 header 中的 Content-Length 指定.
Ⅲ 經典面試題: GET和POST的區別
GET和POST沒有本質區別, 雙方各自應用的場景可以替換. 雖然沒有本質區別,但是使用習慣上還是存在一些差異.
① GET 經常是把傳遞給服務器的數據放到 query string 中; POST則是經常放到 body 中. 當然這種情況也并非絕對, GET 也可以使用 body, POST 也可以使用query string.
② GET 大多數還是用來獲取數據;
POST 大多數還是用來提交數據(登錄 + 上傳);
③ GET 請求一般是冪等的, POST 請求一般是不冪等的.(如果多次請求得到的結果一樣, 就視為請求是冪等的). 這一條也不絕對,具體取決于代碼的實現;
④ GET 請求一般可以被瀏覽器緩存,POST 一般不可以被緩存(冪等性的延續.如果請求是冪等,自然就可以緩存);
Ⅳ 補充說明
① 關于安全性
有些資料上說 “POST 比 GET 請安全”. 這樣的說法是不科學的. 是否安全取決于前端在傳輸密碼等敏感信息時是否進行加密, 和 GET POST 無關.
就像上圖POST 請求確實會給出登錄名和密碼,但那通常都是加密后的結果, 就算被黑客獲取到, 想要解密也絕非易事, 對安全性來說, 如果黑客解密的成本高于賬號本身的價值, 那就是安全的. 就像造假鈔, 如果造一張一百的紙幣成本需要一百一十,那就不怕別人造假鈔.
② 關于傳輸數據量
有的資料上說 “GET 傳輸的數據量小, POST 傳輸數據量大”. 這個也是不科學的, 標準沒有規定 GET 的 URL 的長度, 也沒有規定 POST 的 body 的長度. 傳輸數據量多少, 完全取決于不同瀏覽器和不同服務器之間的實現區別.
③ 關于傳輸數據類型
有的資料上說 “GET 只能傳輸文本數據, POST 可以傳輸二進制數據”. 這個也是不科學的. GET 的 query string 雖然無法直接傳輸二進制數據, 但是可以針對二進制數據進行 base64轉碼.
4.2.3 其他方法
① PUT 與 POST 相似,只是具有冪等特性,一般用于更新;
② DELETE 刪除服務器指定資源;
③ OPTIONS 返回服務器所支持的請求放法;
④ HEAD 類似于GET,只不過響應體不返回,只返回響應頭;
⑤ TRACE 回顯服務器端收到的請求,測試的時候會用到這個;
⑥ CONNECT 預留,暫無使用;
4.3 認識請求"報頭"(header)
header 的整體的格式也是 “鍵值對” 結構.
每個鍵值對占一行. 鍵和值之間使用分號分割.
報頭的種類有很多, 本文僅介紹幾個常見的
① Host
表示服務器主機的地址和端口.
② Content-Length
表示 body 中的數據長度.
③ Content-Type
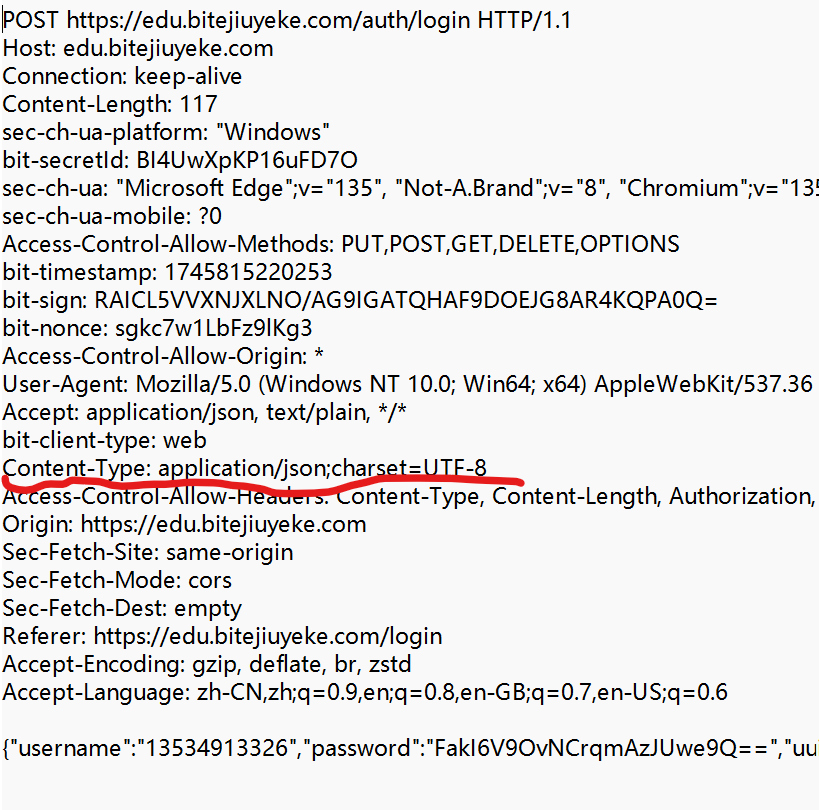
表示請求的 body 中的數據格式.
②和③ 有這兩個屬性的前提示請求里有body.
TCP 涉及到 粘包 問題.
HTTP 在傳輸層就是基于 TCP 的.
這兩個屬性就可以解決粘包問題.
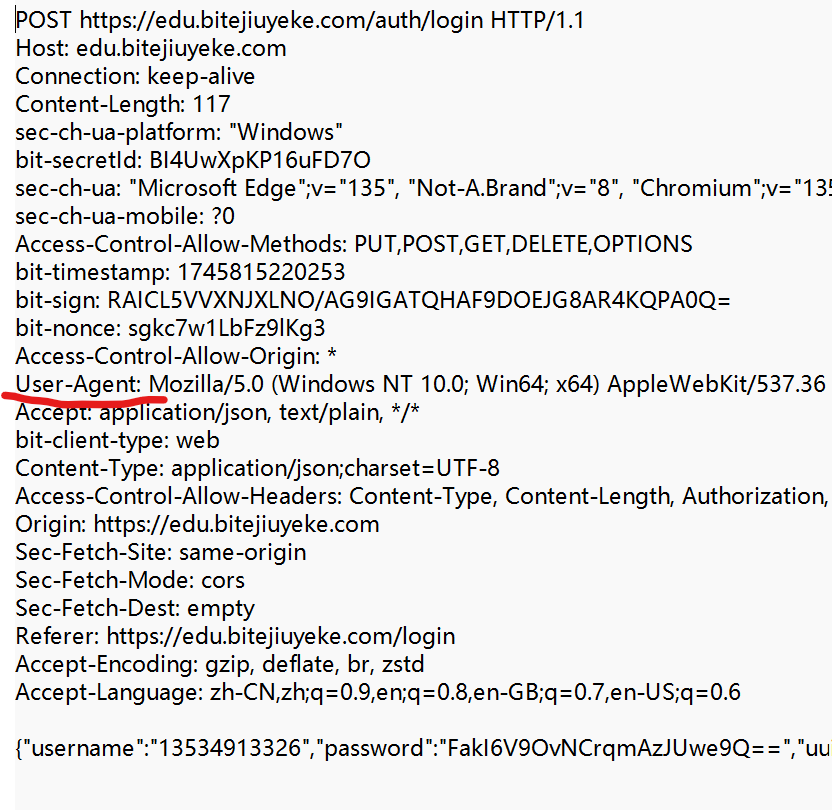
④ User-Agent (簡稱 UA)
表示瀏覽器/操作系統的屬性.
⑤ Referer
表示這個頁面是從哪個頁面跳轉過來的. 形如
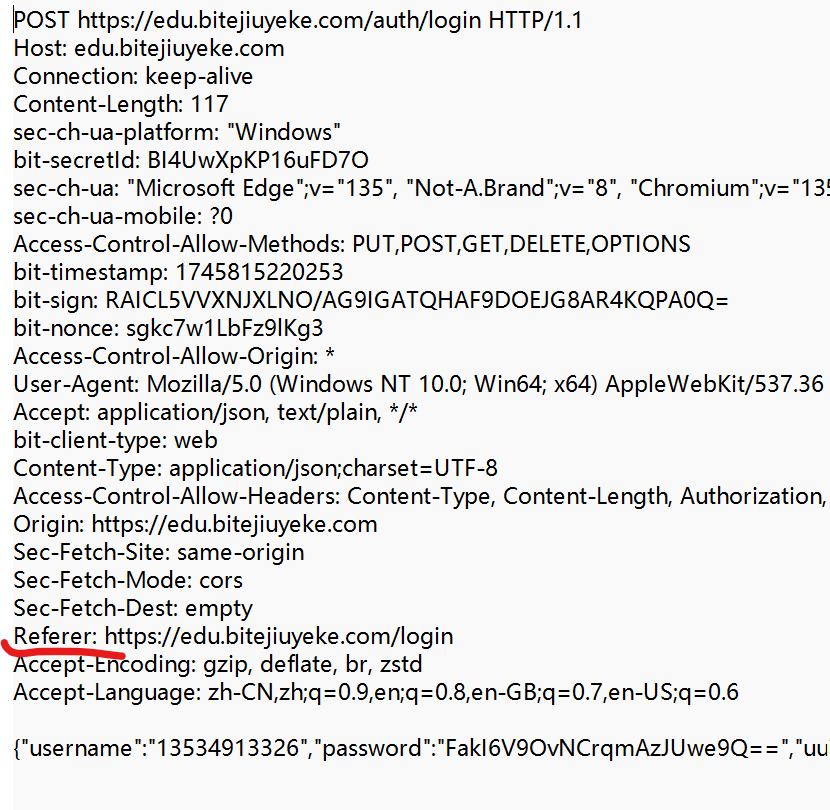
如果直接在瀏覽器中輸入URL, 或者直接通過收藏夾訪問頁面時是沒有 Referer 的.
⑥ Cookie
Cookie 中存儲了一個字符串, 這個數據可能是客戶端(網頁)自行通過 JS 寫入的, 也可能來自于服務器
(服務器在 HTTP 響應的 header 中通過 Set-Cookie 字段給瀏覽器返回數據).
每個不同的域名下都可以有不同的 Cookie, 不同網站之間的 Cookie 并不沖突.
往往可以通過這個字段實現 “身份標識” 的功能.
4.4 認識正文(body)
如下圖所示, 前面抓取過的包, 不再多說.
本篇博客到這里就結束啦, 感謝觀看, 下篇揭曉HTTP響應的具體組成部分.🐱?🚀 ???
🐎期待與你的下一次相遇😊😊😊
:Object、Nested、Flattened類型)


--vue3基礎知識(二)計算屬性(computed)、監聽屬性(Watch))
![[預備知識] 5. 優化理論(一)](http://pic.xiahunao.cn/[預備知識] 5. 優化理論(一))

)
![洛谷P12238 [藍橋杯 2023 國 Java A] 單詞分類](http://pic.xiahunao.cn/洛谷P12238 [藍橋杯 2023 國 Java A] 單詞分類)




)






