關鍵詞:Community Detection Algorithms
一、說明
在本教程中,我們將探討網絡分析的兩個基本方面:社區檢測和使用子圖。了解這些概念將使您能夠發現復雜網絡中隱藏的結構和關系。
二、何為社區,何為社區檢測?
2.1 關于社區檢測和相關研究
你們很多人都熟悉網絡,對吧?你可能正在使用 Facebook、Instagram、Twitter 等社交媒體網站。它們就是社交網絡。你可能正在與證券交易所打交道。你可能正在買入新股,也可能賣出現有股票等等。它們就是網絡。不僅在技術領域,而且在我們的日常社交生活中,我們都與許多網絡打交道。社區是許多網絡的屬性,特定網絡可能包含多個社區,社區內的節點緊密相連。多個社區中的節點可以重疊。想想你的 Facebook 或 Instagram 帳戶,想想你每天與誰互動。你可能與朋友、同事、家人以及生活中其他一些重要的人密切互動。他們在你的社交網絡中構成了一個非常密集的社區。
M. Girvan 和 MEJ Newman 是社群發現領域的兩位著名研究者。在他們的一項研究中,他們利用社交網絡和生物網絡研究了社群的結構屬性。他們認為,網絡節點在社群內部以緊密的群體形式緊密連接,而在社群之間則以松散的連接形式存在。
2.2 為什么要進行社區檢測?
在分析不同的網絡時,發現其中的社群可能至關重要。社群檢測技術有助于社交媒體算法發現具有共同興趣的群體,并讓他們保持緊密聯系。社群檢測技術可用于機器學習,檢測具有相似屬性的群體,并根據各種原因提取群體。例如,這項技術可用于發現社交網絡或股票市場中的操縱性群體。
2.3 社區檢測與聚類
有人可能會認為社群檢測類似于聚類。聚類是一種機器學習技術,它根據相似的數據點的屬性將其歸入同一聚類。盡管聚類可以應用于網絡,但它是無監督機器學習中一個更廣泛的領域,涉及多種屬性類型。另一方面,社群檢測專門針對網絡分析,它依賴于一種稱為“邊”的屬性類型。此外,聚類算法傾向于將單個外圍節點與其應屬于的社群分離。然而,聚類和社群檢測技術都可以應用于許多網絡分析問題,并且根據領域的不同,它們可能存在不同的優缺點。
三、關于社區檢測技術
社區發現方法大致可分為兩類:凝聚法和分裂法。凝聚法是將邊逐一添加到僅包含節點的圖中,邊的添加順序是從強邊到弱邊。分裂法與凝聚法相反,是將邊從完整的圖中逐一移除。
給定網絡中的社區數量可能不限,且規模大小不一。這些特性使得社區檢測過程非常困難。然而,在社區檢測領域已提出了許多不同的技術。以下介紹四種流行的社區檢測算法。所有這些列出的算法都可以在Python 的 cdlib 庫中找到。
3.1. 魯汶社區檢測
Louvain 社區發現算法最初于 2008 年提出,是一種適用于大型網絡的快速社區展開方法。該方法基于模塊度,試圖最大化社區中實際邊數與預期邊數之間的差異。然而,優化網絡中的模塊度是 NP 難題,因此必須使用啟發式方法。Louvain 算法分為兩個迭代重復的階段:
1 節點的局部移動
2 網絡聚合
該算法從一個由 N 個節點組成的加權網絡開始。在第一階段,該算法為網絡中的每個節點分配一個不同的社區。然后,對于每個節點,算法會考慮其鄰居,并評估其模塊化增益通過從當前社區中移除特定節點并將其放入鄰居社區中。如果增益為正且最大化,則該節點將被放入鄰居社區。如果沒有正增益,則節點將保留在同一個社區中。此過程重復應用于所有節點,直到不再有進一步的改進。當獲得模塊度的局部最大值時,Louvain 算法的第一階段停止。在第二階段中,該算法將構建一個新網絡,將在第一階段找到的社區視為節點。第二階段完成后,該算法將對生成的網絡重新應用第一階段。重復這些步驟,直到網絡不再發生變化且獲得最大模塊度。
Louvain 社區發現算法能夠在過程中發現社區的社區。該算法因其易于實現且速度快而廣受歡迎。然而,該算法的一個主要限制在于其對網絡在主內存中的存儲的使用。
下面給出了使用 python cdlib 庫的 Louvain 社區檢測算法的使用。
1)從 cdlib 導入算法
2)導入 networkx 作為 nx
3)G = nx.karate_club_graph()
4)coms = algorithms.louvain(G, weight=‘weight’, resolution=1., randomize=False)
3.2. 意外社區檢測
由于模塊度的局限性,引入了一種基于經典概率的度量方法,稱為“意外度”(Surprise),用于評估網絡社區劃分的質量。該算法與魯汶社區檢測算法幾乎相似,只是它使用意外度而非模塊度。節點從一個社區移動到另一個社區,從而貪婪地提高意外度。這種方法考慮的是鏈接位于社區內的概率。在社區規模較小的情況下,使用意外度效果良好 ;而在社區規模較小的情況下,使用模塊度效果良好。
下面給出了使用 python cdlib 庫的 Surprise 社區檢測算法的使用方法。
1)從 cdlib 導入算法
2)導入 networkx 作為 nx
3)G = nx.karate_club_graph()
4)coms = algorithms.surprise_communities(G)
3.3. 萊頓社區檢測
在后來的研究中(2019 年),VA Traag 等人表明,Louvain 社區檢測傾向于發現內部不連通的社區(連接性較差的社區)。在 Louvain 算法中,將一個充當社區中兩個組成部分之間橋梁的節點移至新社區可能會導致舊社區的連接斷開。如果舊社區進一步分裂,則不會出現這種情況。但根據 Traag 等人的研究,情況并非如此。由于舊社區中的其他節點與社區之間的連接緊密,舊社區可以保持為一個單一社區。此外,他們還表示,Louvain 傾向于發現連接性非常差的社區。因此,他們提出了速度更快的 Leiden 算法,該算法可以保證社區的連接性良好。
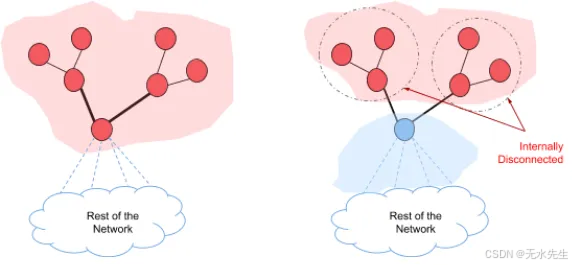
除了 Louvain 算法中使用的階段之外,Leiden 算法還使用了另一個階段,用于嘗試優化已發現的分區。Leiden 算法的三個階段如下:
1)節點的局部移動
2)分區細化
3)基于精細劃分的網絡聚合
在細化階段,算法嘗試從第一階段提出的分區中識別出細化的分區。第一階段提出的社區可能會在第二階段進一步分裂成多個分區。細化階段不遵循貪婪方法,可能會將節點與隨機選擇的社區合并,從而提高質量函數。這種隨機性允許更廣泛地發現分區空間。同樣在第一階段,萊頓采用了與魯汶不同的方法。萊頓不是在第一次訪問所有節點后訪問網絡中的所有節點,而是只訪問那些鄰域發生變化的節點。
下面給出了使用 python cdlib 庫的萊頓社區檢測算法的使用。
1)從 cdlib 導入算法
2)導入 networkx 作為 nx
3)G = nx.karate_club_graph()
4)coms = algorithms.leiden(G)
3.4. Walktrap 社區檢測
Walktrap 是另一種基于隨機游動的社區檢測方法,其中通過網絡中的隨機游動來測量頂點之間的距離。Walktrap 是一種高效的算法,在最壞的情況下,時間復雜度為 O(mn2),空間復雜度為 O(n2)。但在大多數實際場景中,walktrap 的時間復雜度為 O((n2) log n),空間復雜度為 O(n2)。該算法的基本原理是,圖 / 網絡上的隨機游動往往會陷入與社區相對應的緊密連接部分。Walktrap 使用隨機游動的結果以自下而上的方式合??并單獨的社區。可以使用任何可用的質量標準來評估分區的質量。它可以是像 Louvain 社區檢測中的模塊化,也可以是任何其他度量。
下面給出了使用 python cdlib 庫的 Walktrap 社區檢測算法的使用方法。
1)從 cdlib 導入算法
2)導入 networkx 作為 nx
3)G = nx.karate_club_graph()
4)coms = algorithms.walktrap(G)
3.5 小結
社群檢測非常適用于理解和評估大型復雜網絡的結構。這種方法利用圖或網絡中邊的屬性,因此比聚類方法更適合網絡分析。聚類算法傾向于將單個外圍節點與其應歸屬的社群分離。目前已提出并實現了多種不同的網絡社群檢測算法。每種算法都有各自的優缺點,具體取決于網絡的性質以及應用問題領域。
四、實驗進行識別社區
社區檢測算法旨在將網絡劃分為多個社區。有幾種算法可用,但我們將重點介紹 Girvan-Newman 算法和 Louvain 方法。
4.1 社區檢測與聚類
有人可能會爭辯說,社區檢測類似于聚類。聚類是一種機器學習技術,其中相似的數據點根據其屬性分組到同一集群中。盡管聚類可以應用于網絡,但它是無監督機器學習中一個更廣泛的領域,涉及多種屬性類型。另一方面,社區檢測是專門為網絡分析量身定制的,該網絡分析依賴于稱為 edges 的單個屬性類型。此外,聚類算法傾向于將單個外圍節點與它應該屬于的社區分開。但是,聚類和社區檢測技術都可以應用于許多網絡分析問題,并且可能會根據域的不同而產生不同的優缺點。
4.2 使用 NetworkX 進行社區檢測
NetworkX 提供了應用各種社區檢測算法的工具。讓我們從 Girvan-Newman 算法開始。
社區檢測技術
- Girvan-Newman 算法
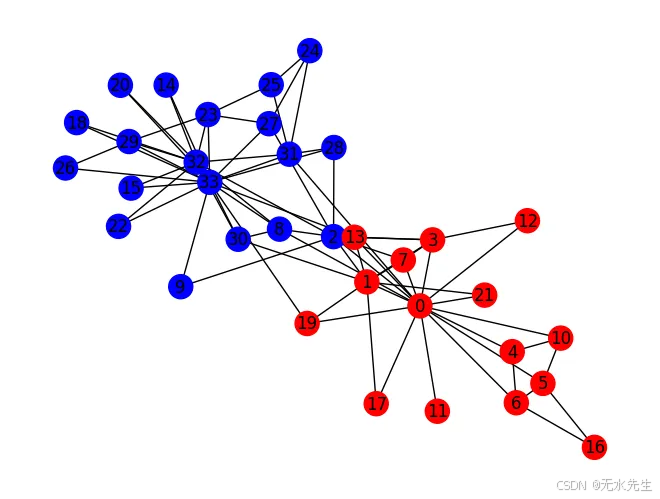
Girvan-Newman 算法通過逐步刪除具有最高中介中心性的邊來識別社區。以下是在 NetworkX 中實現 Girvan-Newman 算法的方法:
import networkx as nx
from networkx.algorithms.community import girvan_newman
import matplotlib.pyplot as pltG = nx.karate_club_graph()# Apply Girvan-Newman algorithm
communities = girvan_newman(G)# Get the first set of communities (you can iterate further for more levels)
node_groups = list(next(communities))# Assign colors to nodes based on their community
node_colors = []
for node in G.nodes():if node in node_groups[0]:node_colors.append('red')else:node_colors.append('blue')# Draw the graph with nodes colored by community
nx.draw(G, with_labels=True, node_color=node_colors)
plt.show()
Output:
4.3 . 魯汶法
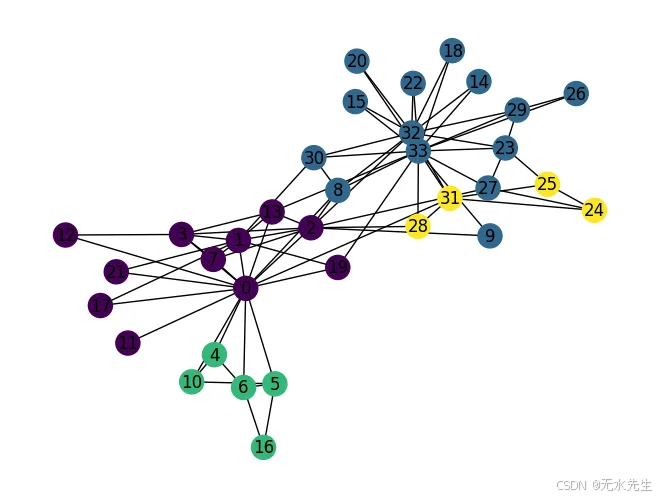
魯汶方法是一種通過優化模塊化來檢測網絡中社區的有效算法,模塊化是一種評估網絡內社區強度的度量。它的工作原理是在社區之間迭代移動節點,以最大限度地提高模塊化,從而突出顯示緊密連接的組。該方法快速、可擴展,并廣泛用于各個領域,以揭示復雜網絡中隱藏的結構。
魯汶法的計算代碼:
import networkx as nx
from community import community_louvain
import matplotlib.pyplot as plt# Assuming you have your graph G defined# Apply Louvain algorithm
partition = community_louvain.best_partition(G)# Get the community assignments for each node
node_colors = [partition[node] for node in G.nodes()]# Draw the graph with nodes colored by community
nx.draw(G, with_labels=True, node_color=node_colors)
plt.show()
輸出:
4.4 圖論中的子圖
子圖是由其頂點(節點)的子集和連接這些頂點的邊形成的圖形的一部分。分析子圖有助于識別較大圖中的關系、社區或特定特征。在 NetworkX 中,我們可以根據各種標準(例如特定節點、邊或屬性)輕松提取子圖。
提取子圖
可以根據特定節點或特定邊提取子圖。
import networkx as nx
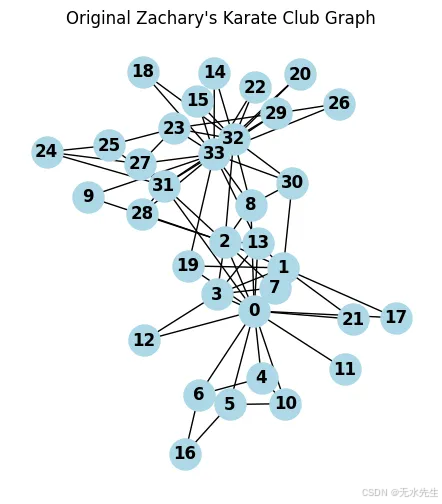
import matplotlib.pyplot as plt # Load Zachary's Karate Club graph
G_karate = nx.karate_club_graph() plt.figure(figsize=(12, 6))
plt.subplot(1, 2, 1) # Visualize the original graph
nx.draw(G_karate, with_labels=True, node_color='lightblue', node_size=500, font_weight='bold') plt.title("Original Zachary's Karate Club Graph")
輸出:
按節點提取:
您可以通過指定要包含的節點列表來創建子圖。當您想要研究較大圖形中一組特定節點之間的連接和關系時,這尤其有用。
例: 如何根據特定節點從圖中提取子圖:
# Specify a list of nodes for the subgraph
subgraph_nodes = [0, 1, 2, 3, 4, 5] """Extract the subgraph from Zachary's Karate
Club graph based on the specified nodes"""
subgraph = G_karate.subgraph(subgraph_nodes) # Visualize the subgraph
nx.draw(subgraph, with_labels=True, node_color='lightgreen', node_size=500, font_weight='bold') plt.title("Subgraph of Zachary's Karate Club based on nodes")
plt.show()
輸出:
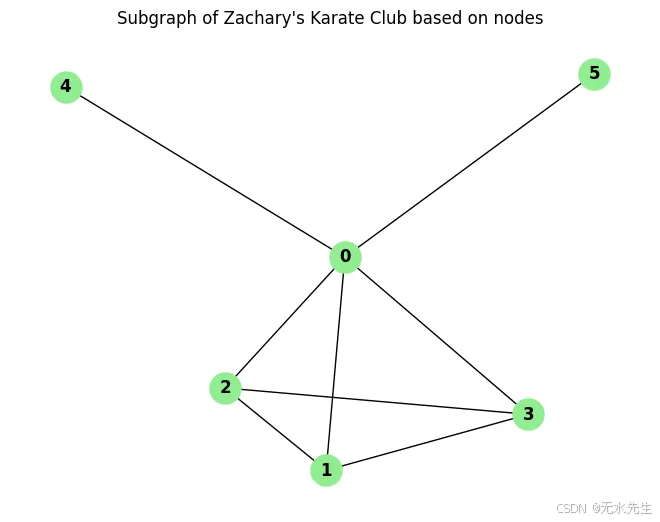
我們可以通過以下命令打印子圖的節點和邊:
# Print nodes and edges of the subgraph
print("Nodes in subgraph:", subgraph.nodes())
print("Edges in subgraph:", subgraph.edges())Nodes in subgraph: [0, 1, 2, 3, 4, 5]
Edges in subgraph: [(0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 2), (1, 3), (2, 3)]
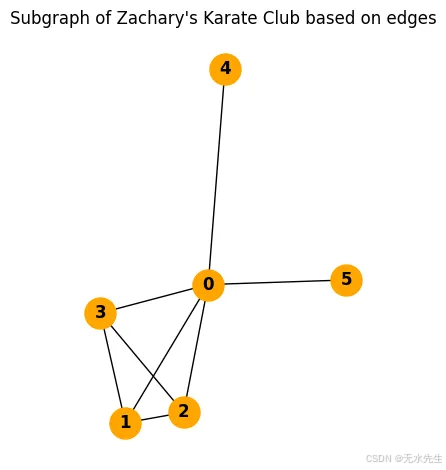
按邊提取:
或者,您可以使用一組特定的邊提取子圖。此方法側重于節點之間的關系,當邊表示重要的交互或連接時,此方法可能很有用。
示例:這是一個示例代碼,演示了如何根據特定邊緣在 NetworkX 中提取子圖:
# Specify a list of edges for the subgraph
subgraph_edges = [(0, 1), (0, 2), (0, 3), (0, 4), (0, 5), (1, 2), (1, 3), (2, 3)] """Extract the subgraph from Zachary's Karate
Club graph based on the specified edges"""
subgraph_edges_extracted = G_karate.edge_subgraph(subgraph_edges) # Visualize the subgraph
plt.subplot(1, 2, 2)
nx.draw(subgraph_edges_extracted, with_labels=True, node_color='orange', node_size=500, font_weight='bold') plt.title("Subgraph of Zachary's Karate Club based on edges")
plt.tight_layout()
plt.show()
輸出:
五、結論
在本教程中,我們探索了使用 NetworkX 的社區檢測和子圖。我們討論了如何使用 Girvan-Newman 算法和 Louvain 方法識別社區,以及如何提取和可視化具有節點或邊的子圖。我們將在復雜網絡系列:第 6 部分中深入探討 PageRank 和 HITS 算法等高級主題,該主題衡量了網絡中節點的重要性,并研究了與網絡健壯性和彈性相關的概念。這些技術共同為分析和理解復雜網絡提供了強大的工具。



)















