
需求說明
督導檢查,各條線都要收集資料。
今天去加班,遇到家教主任,她讓我用保教主任的彩色打印機打印這套活躍度表格。(2023學年上學期下學期-2024學年上學期,就是202309-202504)
每個excle都是內容在A4一頁豎版上
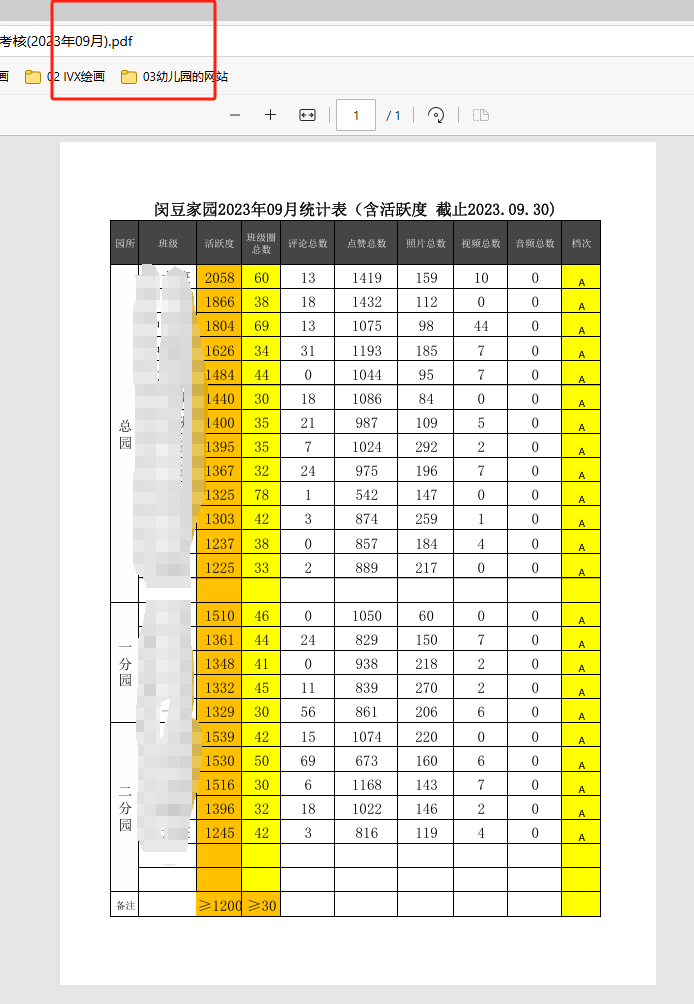
打印預覽(在A4一頁上)
存在問題:
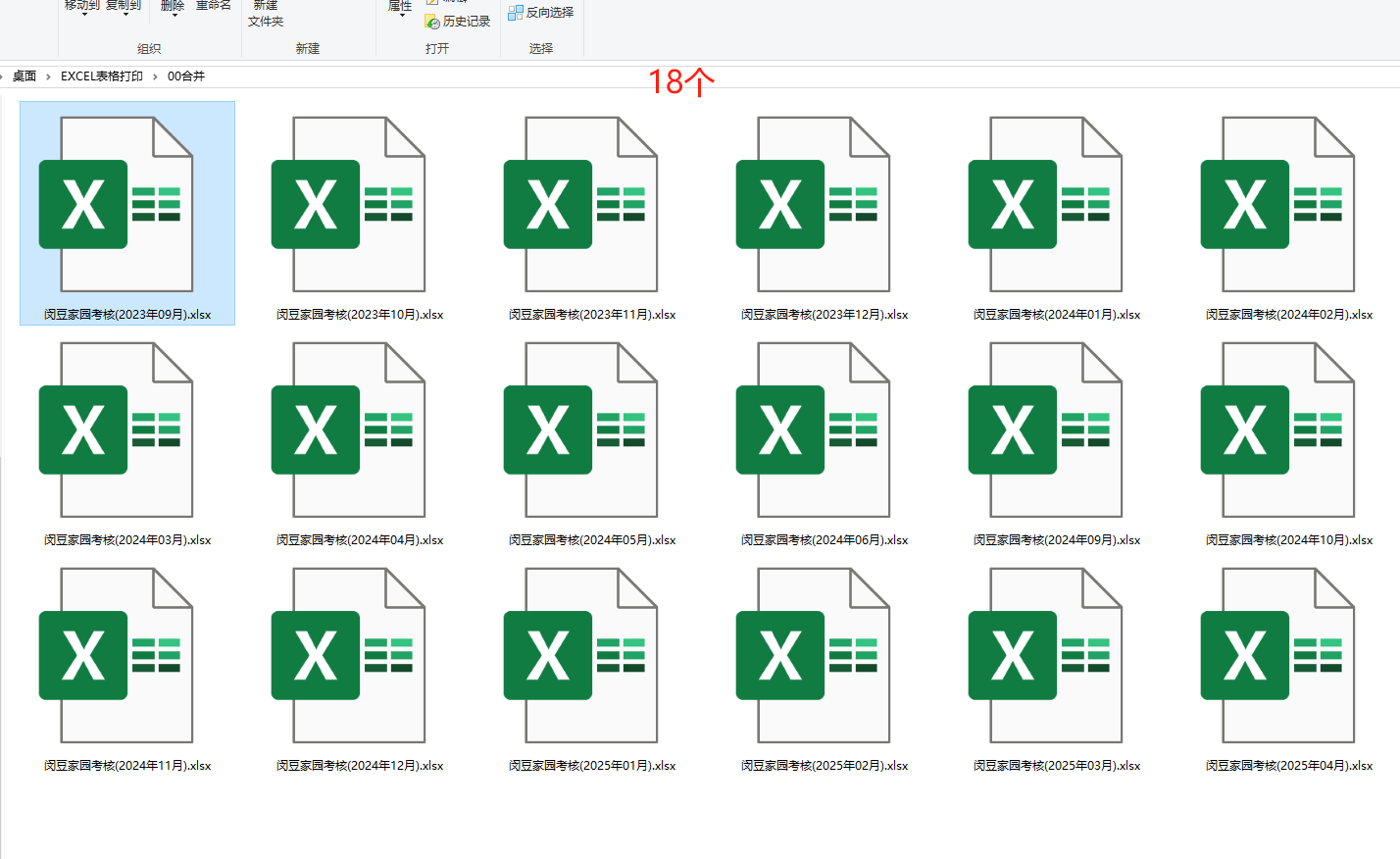
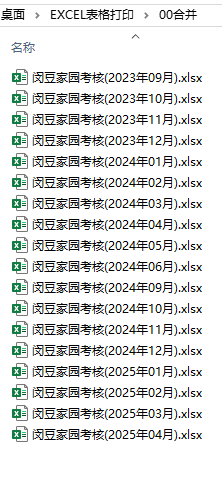
但是一共有18個表格,如果我要手動一個個打開打印,容易少打(需要檢查才能知道少打那一頁)、錯頁(需要手動排序)。還要花時間關閉。
在現在這個爭分奪秒補資料的時期,一個個表格打印實在是太煩了。
解決思路
前期我用星火訊飛問過excle是否可以保存PDF,代碼沒有運行成功。所以這次我用豆包問問excle是否可以保存PDF
問題1:excle轉PDF
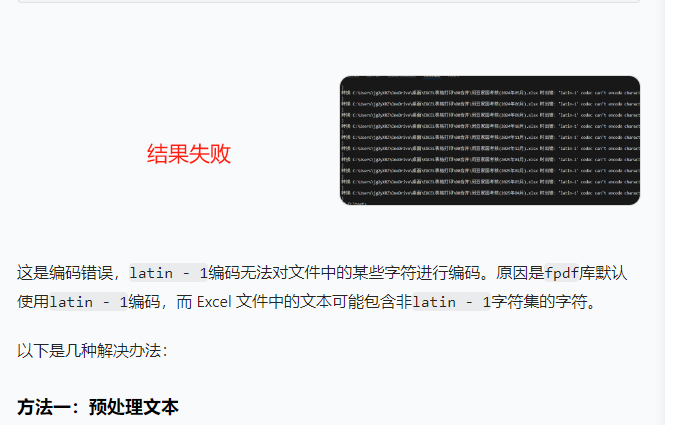
問題1的解決代碼
'''
20250504閔豆EXCLE轉pdf
豆包、阿夏
20250504
'''
import os
import win32com.client as win32def convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):try:# 創建 Excel 應用程序對象excel = win32.gencache.EnsureDispatch('Excel.Application')# 使 Excel 應用程序可見(可選,有助于調試)excel.Visible = True# 打開 Excel 文件workbook = excel.Workbooks.Open(xlsx_file_path)# 保存所有工作表為一個 PDFworkbook.ExportAsFixedFormat(0, pdf_file_path)# 關閉工作簿和 Excel 應用程序workbook.Close(SaveChanges=False)excel.Quit()print(f"成功將 {xlsx_file_path} 轉換為 {pdf_file_path}")except Exception as e:print(f"轉換 {xlsx_file_path} 時出錯: {e}")def main():path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'# 定義源文件夾路徑source_folder = path + r'\00合并'# 定義目標文件夾路徑target_folder = path + r'\01pdf'# 檢查源文件夾是否存在if not os.path.exists(source_folder):print(f"源文件夾 {source_folder} 不存在。")return# 如果目標文件夾不存在,則創建它if not os.path.exists(target_folder):os.makedirs(target_folder)# 遍歷源文件夾中的所有文件for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_file_path = os.path.join(root, file)pdf_file_name = os.path.splitext(file)[0] + '.pdf'pdf_file_path = os.path.join(target_folder, pdf_file_name)convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path)if __name__ == "__main__":main()
五分鐘就出現了excel轉pdf的效果(要用win32才保留原來的格式)
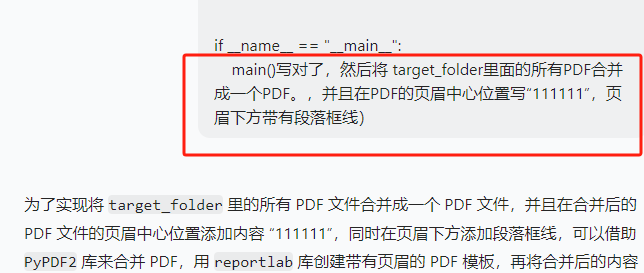
問題2:缺少頁眉
很快就發現這套excel沒有頁眉,如果要做資料,這套excle也要有“學校”的頁眉
第1次嘗試,豆包
'''
20250504閔豆EXCLE轉pdf,加頁眉
豆包、阿夏
20250504
'''import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
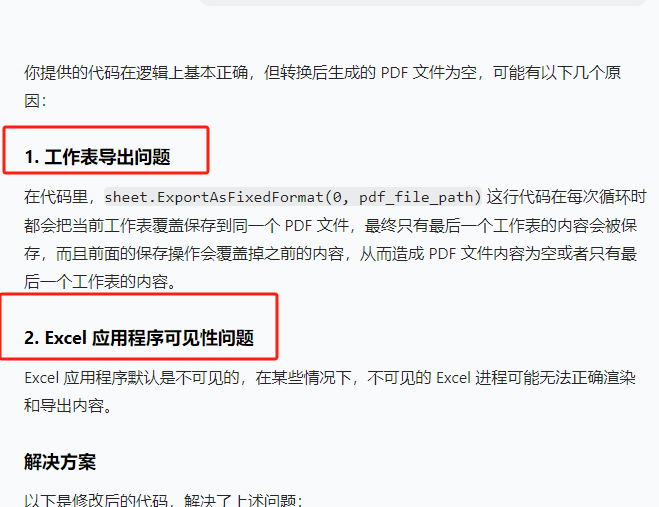
from reportlab.lib.units import inchdef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):try:# 創建 Excel 應用程序對象excel = win32.gencache.EnsureDispatch('Excel.Application')# 使 Excel 應用程序可見(可選,有助于調試)excel.Visible = True# 打開 Excel 文件workbook = excel.Workbooks.Open(xlsx_file_path)# 保存所有工作表為一個 PDFworkbook.ExportAsFixedFormat(0, pdf_file_path)# 關閉工作簿和 Excel 應用程序workbook.Close(SaveChanges=False)excel.Quit()print(f"成功將 {xlsx_file_path} 轉換為 {pdf_file_path}")except Exception as e:print(f"轉換 {xlsx_file_path} 時出錯: {e}")def create_cover_page_with_header(pdf_path):c = canvas.Canvas(pdf_path, pagesize=letter)# 設置字體和字號c.setFont('Helvetica', 12)# 頁眉文本header_text = "111111"# 計算文本寬度text_width = c.stringWidth(header_text, 'Helvetica', 12)# 頁眉位置(居中)x = (letter[0] - text_width) / 2y = letter[1] - 0.5 * inch# 繪制頁眉文本c.drawString(x, y, header_text)# 繪制頁眉下方的段落框線c.line(0.5 * inch, y - 2, letter[0] - 0.5 * inch, y - 2)c.save()def merge_pdfs(source_folder, output_pdf):pdf_writer = PdfWriter()# 遍歷源文件夾中的所有 PDF 文件for root, dirs, files in os.walk(source_folder):for file in sorted(files):if file.endswith('.pdf'):pdf_path = os.path.join(root, file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 創建帶有頁眉的封面頁cover_pdf_path = 'cover_with_header.pdf'create_cover_page_with_header(cover_pdf_path)cover_pdf_reader = PdfReader(cover_pdf_path)# 將封面頁添加到合并后的 PDF 開頭pdf_writer.insert_page(cover_pdf_reader.pages[0], 0)# 保存合并后的 PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功將 {source_folder} 中的所有 PDF 合并為 {output_pdf}")# 刪除臨時封面頁 PDFos.remove(cover_pdf_path)def main():path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'# 定義源文件夾路徑source_folder = path + r'\00合并'# 定義目標文件夾路徑target_folder = path + r'\01pdf'# 定義合并后的 PDF 輸出路徑merged_pdf_path = path + r'\merged_pdfs.pdf'# 檢查源文件夾是否存在if not os.path.exists(source_folder):print(f"源文件夾 {source_folder} 不存在。")return# 如果目標文件夾不存在,則創建它if not os.path.exists(target_folder):os.makedirs(target_folder)# 遍歷源文件夾中的所有文件for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_file_path = os.path.join(root, file)pdf_file_name = os.path.splitext(file)[0] + '.pdf'pdf_file_path = os.path.join(target_folder, pdf_file_name)convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path)# 合并目標文件夾中的所有 PDF 文件merge_pdfs(target_folder, merged_pdf_path)if __name__ == "__main__":main()結果:新建一頁空白,添加了頁眉,后面的每頁統計表pdf都沒有加到頁眉

換了一個思路問豆包,結果還是一樣的,只有第一頁加了頁眉
第2次嘗試,deepseek
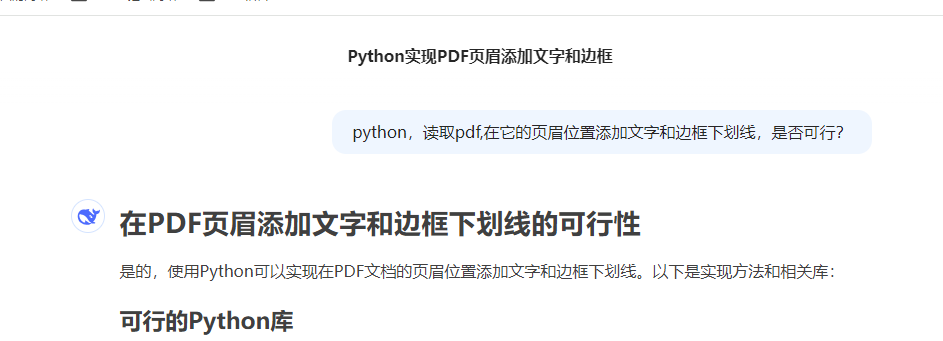
import fitz # PyMuPDFdef add_header_with_border(input_pdf, output_pdf, header_text):doc = fitz.open(input_pdf)for page in doc:# 獲取頁面尺寸page_rect = page.rectwidth = page_rect.width# 創建頁眉矩形區域 (頂部2cm高)header_rect = fitz.Rect(0, 0, width, 50)# 添加下劃線邊框 (1pt粗)page.draw_rect(header_rect, color=(0, 0, 0), width=1)# 在邊框下方添加一條細線作為下劃線page.draw_line(fitz.Point(0, 48), fitz.Point(width, 48), color=(0, 0, 0), width=0.5)# 添加頁眉文本 (居中)text = header_textfont_size = 12text_rect = fitz.Rect(0, 10, width, 30)page.insert_textbox(text_rect,text,fontsize=font_size,fontname="helv",color=(0, 0, 0),align=1 # 1=居中)doc.save(output_pdf)doc.close()# 使用示例
add_header_with_border("input.pdf", "output.pdf", "這是頁眉文字")把這個代碼和之前的excle轉PDF 合并一起
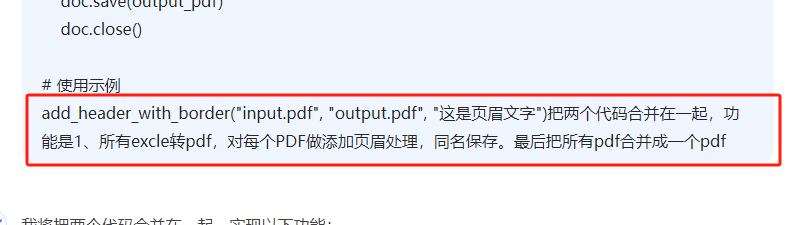
很幸運這個寫出來代碼運行成功了,但是頁眉是?號(非漢字),而且畫了一整個黑框。

繼續調整問題
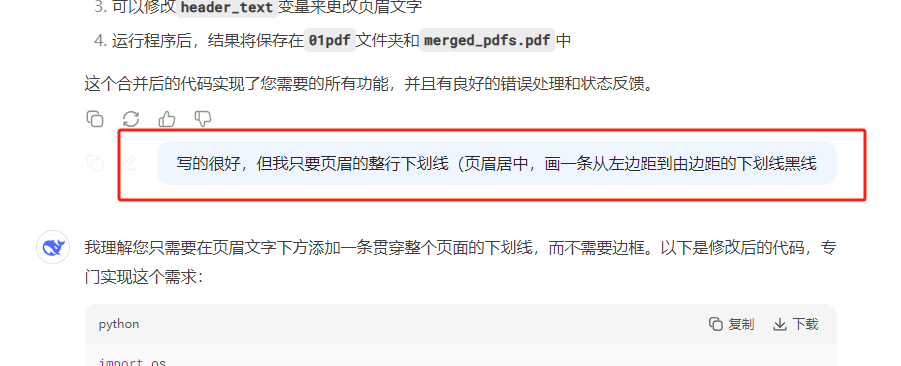 、
、
這次每頁PDF都有頁碼了,不過下劃線在頁眉的上面

最后問一次


正確代碼
'''
20250504閔豆EXCLE轉pdf,加頁眉+下劃線
豆包、阿夏
20250504
'''
import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
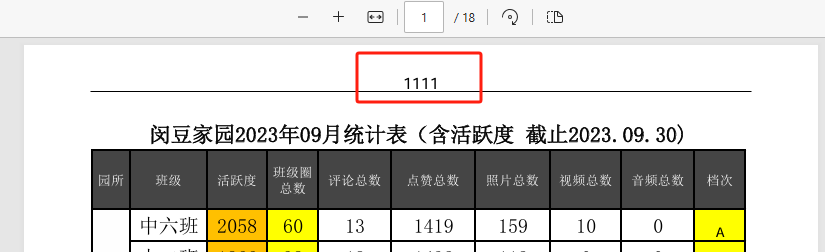
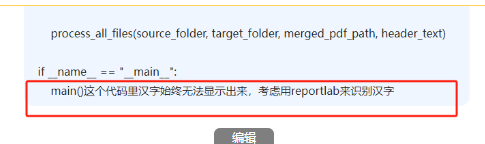
import fitz # PyMuPDFdef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):"""將Excel文件轉換為PDF"""try:excel = win32.gencache.EnsureDispatch('Excel.Application')excel.Visible = Falseworkbook = excel.Workbooks.Open(xlsx_file_path)workbook.ExportAsFixedFormat(0, pdf_file_path)workbook.Close(SaveChanges=False)excel.Quit()print(f"成功將 {xlsx_file_path} 轉換為 {pdf_file_path}")return Trueexcept Exception as e:print(f"轉換 {xlsx_file_path} 時出錯: {e}")return Falsedef add_header_to_pdf(input_pdf, output_pdf, header_text):"""為PDF添加頁眉(文字+下方下劃線)"""try:doc = fitz.open(input_pdf)for page in doc:# 獲取頁面尺寸page_rect = page.rectwidth = page_rect.widthleft_margin = 50 # 左邊距right_margin = width - 50 # 右邊距# 先添加頁眉文本 (居中)text = header_textfont_size = 12text_rect = fitz.Rect(0, 20, width, 40) # 文本區域# 插入文本并獲取文本高度text_height = page.insert_textbox(text_rect,text,fontsize=font_size,fontname="helv",color=(0, 0, 0),align=1 # 1=居中)# 在文本下方添加下劃線# 計算下劃線位置(文本底部+2pt)underline_y = 20 + (40 - 20 - text_height) + 2page.draw_line(fitz.Point(left_margin, underline_y),fitz.Point(right_margin, underline_y),color=(0, 0, 0),width=0.8 # 線寬)doc.save(output_pdf)doc.close()print(f"成功為 {input_pdf} 添加頁眉")return Trueexcept Exception as e:print(f"為 {input_pdf} 添加頁眉時出錯: {e}")return Falsedef merge_pdfs(source_folder, output_pdf):"""合并所有PDF文件"""try:pdf_writer = PdfWriter()# 按文件名排序添加所有PDF文件pdf_files = sorted([f for f in os.listdir(source_folder) if f.endswith('.pdf')])for pdf_file in pdf_files:pdf_path = os.path.join(source_folder, pdf_file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 保存合并后的PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功合并所有PDF為 {output_pdf}")return Trueexcept Exception as e:print(f"合并PDF時出錯: {e}")return Falsedef process_all_files(source_folder, target_folder, merged_pdf_path, header_text):"""處理所有文件:轉換、添加頁眉、合并"""if not os.path.exists(source_folder):print(f"源文件夾 {source_folder} 不存在。")return Falseos.makedirs(target_folder, exist_ok=True)for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_path = os.path.join(root, file)pdf_name = os.path.splitext(file)[0] + '.pdf'pdf_path = os.path.join(target_folder, pdf_name)if convert_xlsx_to_pdf(xlsx_path, pdf_path):temp_pdf = os.path.join(target_folder, f"temp_{pdf_name}")if add_header_to_pdf(pdf_path, temp_pdf, header_text):os.remove(pdf_path)os.rename(temp_pdf, pdf_path)return merge_pdfs(target_folder, merged_pdf_path)def main():base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'source_folder = os.path.join(base_path, '00合并')target_folder = os.path.join(base_path, '01pdf')merged_pdf_path = os.path.join(base_path, 'merged_pdfs.pdf')header_text = "上海市XX區XX幼兒園" # 頁眉文本process_all_files(source_folder, target_folder, merged_pdf_path, header_text)if __name__ == "__main__":main()漢字不顯示
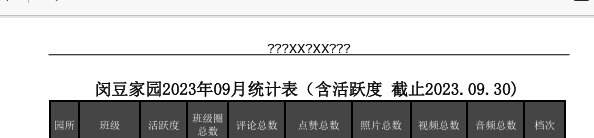

如果是數字、字母,可以顯示

繼續修改
中間又用豆包、智譜清言寫了十幾次都不成功。其中提到
-
替代方案:
- 如果fitz庫無法解決問題,可以考慮使用其他庫,如
ReportLab或WeasyPrint,這些庫對中文支持較好。
- 如果fitz庫無法解決問題,可以考慮使用其他庫,如
感覺fitz識別漢字很差。考慮試試reportlab和WeasyPrint識別漢字能力好。
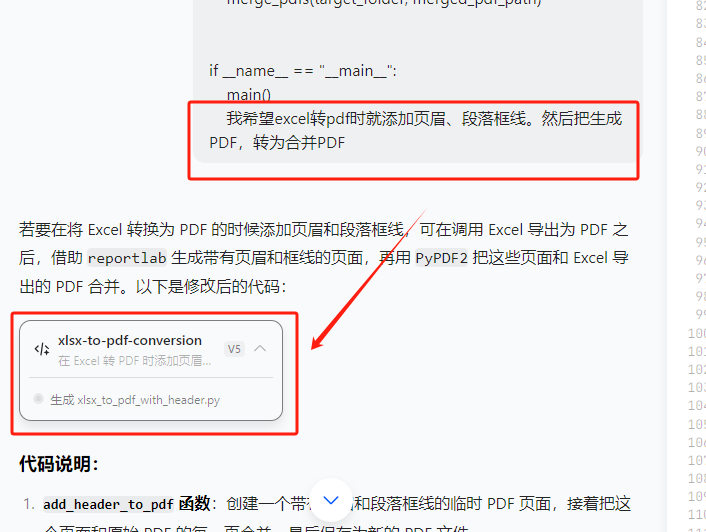
最后把可以顯示數字頁眉的代碼貼入deepseek,加了ReportLab的提示,就像xlsx轉pdf時要求必須用win32轉
終于成功了
'''
20250504 閔豆EXCEL轉PDF,加頁眉(漢字中文、英文、字母+下劃線)
豆包、智譜清言、deepseek、阿夏
20250504
'''import os
import win32com.client as win32
from PyPDF2 import PdfReader, PdfWriter
import fitz # PyMuPDF
from reportlab.pdfgen import canvas
from reportlab.lib.pagesizes import letter
from reportlab.pdfbase import pdfmetrics
from reportlab.pdfbase.ttfonts import TTFont
import iodef convert_xlsx_to_pdf(xlsx_file_path, pdf_file_path):"""將Excel文件轉換為PDF"""try:excel = win32.gencache.EnsureDispatch('Excel.Application')excel.Visible = Falseworkbook = excel.Workbooks.Open(xlsx_file_path)workbook.ExportAsFixedFormat(0, pdf_file_path)workbook.Close(SaveChanges=False)excel.Quit()print(f"成功將 {xlsx_file_path} 轉換為 {pdf_file_path}")return Trueexcept Exception as e:print(f"轉換 {xlsx_file_path} 時出錯: {e}")return Falsedef add_header_to_pdf(input_pdf, output_pdf, header_text):"""為PDF添加頁眉(使用reportlab生成帶漢字的頁眉)"""try:# 注冊中文字體(確保字體文件存在)font_path = r'C:\Windows\Fonts\simsun.ttc' # 宋體if not os.path.exists(font_path):font_path = r'C:\Windows\Fonts\STSONG.TTF' # 備用路徑if not os.path.exists(font_path):print("? 錯誤:未找到宋體字體文件!")return Falsepdfmetrics.registerFont(TTFont('SimSun', font_path))# 讀取原始PDForiginal_pdf = PdfReader(input_pdf)pdf_writer = PdfWriter()for page in original_pdf.pages:# 獲取頁面尺寸media_box = page.mediaboxwidth = float(media_box[2])height = float(media_box[3])# 創建一個臨時PDF用于頁眉packet = io.BytesIO()can = canvas.Canvas(packet, pagesize=(width, height))# 設置字體和大小can.setFont('SimSun', 12)# 計算文本寬度以居中text_width = can.stringWidth(header_text, 'SimSun', 12)# 繪制頁眉文本(居中)can.drawString((width - text_width) / 2, height - 20, header_text)# 繪制下劃線can.line(50, height - 25, width - 50, height - 25)can.save()# 將頁眉合并到原始頁面packet.seek(0)header_pdf = PdfReader(packet)page.merge_page(header_pdf.pages[0])pdf_writer.add_page(page)# 保存結果with open(output_pdf, 'wb') as output_file:pdf_writer.write(output_file)print(f"? 成功為 {input_pdf} 添加頁眉")return Trueexcept Exception as e:print(f"? 添加頁眉時出錯: {e}")return Falsedef merge_pdfs(source_folder, output_pdf):"""合并所有PDF文件"""try:pdf_writer = PdfWriter()# 按文件名排序添加所有PDF文件pdf_files = sorted([f for f in os.listdir(source_folder) if f.endswith('.pdf')])for pdf_file in pdf_files:pdf_path = os.path.join(source_folder, pdf_file)pdf_reader = PdfReader(pdf_path)for page in pdf_reader.pages:pdf_writer.add_page(page)# 保存合并后的PDFwith open(output_pdf, 'wb') as out:pdf_writer.write(out)print(f"成功合并所有PDF為 {output_pdf}")return Trueexcept Exception as e:print(f"合并PDF時出錯: {e}")return Falsedef process_all_files(source_folder, target_folder, merged_pdf_path, header_text):"""處理所有文件:轉換、添加頁眉、合并"""if not os.path.exists(source_folder):print(f"源文件夾 {source_folder} 不存在。")return Falseos.makedirs(target_folder, exist_ok=True)for root, dirs, files in os.walk(source_folder):for file in files:if file.endswith(('.xlsx', '.xls')):xlsx_path = os.path.join(root, file)pdf_name = os.path.splitext(file)[0] + '.pdf'pdf_path = os.path.join(target_folder, pdf_name)if convert_xlsx_to_pdf(xlsx_path, pdf_path):temp_pdf = os.path.join(target_folder, f"temp_{pdf_name}")if add_header_to_pdf(pdf_path, temp_pdf, header_text):os.remove(pdf_path)os.rename(temp_pdf, pdf_path)return merge_pdfs(target_folder, merged_pdf_path)def main():base_path = r'C:\Users\jg2yXRZ\OneDrive\桌面\EXCEL表格打印'source_folder = os.path.join(base_path, '00合并')target_folder = os.path.join(base_path, '01pdf')merged_pdf_path = os.path.join(base_path, 'merged_pdfs.pdf')header_text = "上海市CY區abc123幼兒園" # 頁眉文本(支持中文)process_all_files(source_folder, target_folder, merged_pdf_path, header_text)if __name__ == "__main__":main()最后效果:
漢字中文、英文大寫、英文小寫、數字、符號都可以顯示成頁眉。整段下框線(下劃線)也有
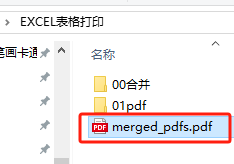
單頁PDF的頁眉

所有PDF都有頁眉了
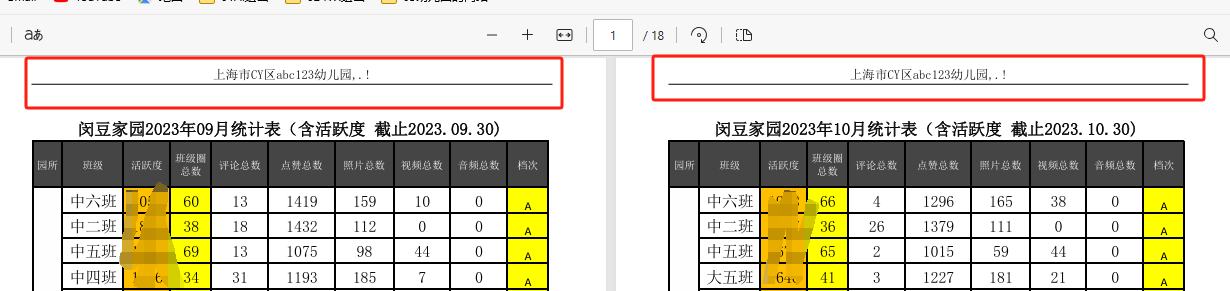
合并打印
感悟:
為了添加pdf的漢字頁眉,四個AI工具,花了4個小時,太累了。還是乖乖的把EXCEL模版里面添加好頁眉吧!

但是EXCEL頁眉左中右,如果我設置居中顯示,最多只能中間部分有下劃線,不能畫出左邊距到右邊距地一根橫線

我從左邊的頁眉區輸入學校,然后按了很多空格,的確頁眉邊長,有下劃線了,
但是保存時提示太長,不給保存
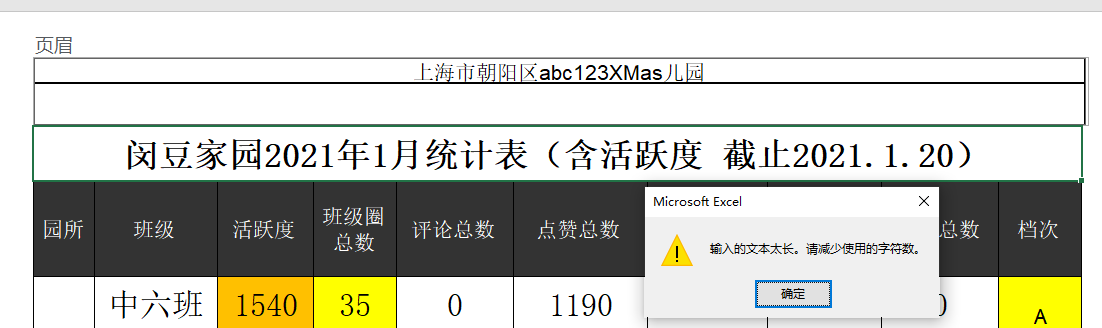
調到正好長度(下劃線不超過兩端)

預覽時顯示制作右側中策有下劃線
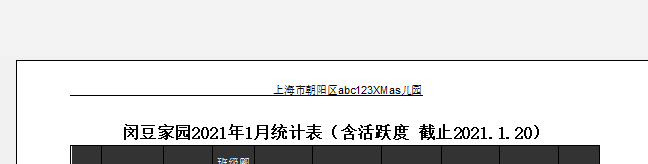
在最后加一個逗號,改成白色逗號

打印時,勉強可以算左右整段下劃線



)
















