??每周跟蹤AI熱點新聞動向和震撼發展 想要探索生成式人工智能的前沿進展嗎?訂閱我們的簡報,深入解析最新的技術突破、實際應用案例和未來的趨勢。與全球數同行一同,從行業內部的深度分析和實用指南中受益。不要錯過這個機會,成為AI領域的領跑者。點擊訂閱,與未來同行! 訂閱:https://rengongzhineng.io/

微軟于2025年4月30日發布了最新的開源推理模型套件“Phi-4-Reasoning”,標志著在中等規模語言模型(14B參數)中實現高效復雜推理能力的又一重大突破。盡管大型語言模型(LLM)在自然語言處理任務中已表現出顯著進步,但在數學問題求解、算法規劃與編程等推理密集型任務中,模型規模、訓練策略及推理效率仍是關鍵制約因素。許多表現優異的通用模型常常難以構建多步推理鏈或回溯中間步驟,導致在需要結構化推理的應用場景中表現不佳。同時,簡單擴大模型參數雖有助于推理能力提升,但也帶來巨大的計算與部署成本,限制其在教育、工程或決策支持等實際場景中的應用。
微軟發布Phi-4推理模型家族
此次微軟發布的Phi-4 Reasoning家族包括三個模型:Phi-4-reasoning、Phi-4-reasoning-plus與Phi-4-mini-reasoning,皆基于14B參數的Phi-4主干架構,專為數學、科學及軟件工程等領域的復雜推理任務設計。不同模型版本在計算效率與輸出精度之間提供多樣化選擇。其中,Phi-4-reasoning通過結構化監督微調優化,而Phi-4-reasoning-plus在此基礎上進一步引入基于結果的強化學習機制,特別針對高方差數學競賽類任務進行性能增強。
微軟開放了模型權重及完整訓練細節和評估日志,所有資源已發布于Hugging Face平臺,確保模型的可復現性與研究透明度。
技術構成與訓練方法革新
Phi-4-reasoning系列模型在基礎架構與訓練方法上做出了若干關鍵改進,主要包括:
- 結構化監督微調(Structured SFT):團隊精心挑選了逾140萬條提示語,重點聚焦于Phi-4基礎模型邊緣能力范圍的“邊界問題”,強調多步驟推理而非簡單事實回憶。訓練數據由“o3-mini”模型在高推理模式下合成生成。
- 思維鏈格式(Chain-of-Thought):模型輸出中采用顯式的
<think>標簽,引導模型將推理過程與最終答案分離,以實現更清晰的推理軌跡。 - 擴展上下文處理能力:通過調整旋轉位置編碼(RoPE)的基本頻率,使模型可處理最多32K token的輸入,有助于更長的推理路徑和多輪復雜問答。
- 強化學習優化(Phi-4-reasoning-plus):該版本模型引入“群體相對策略優化”(Group Relative Policy Optimization,GRPO),基于約6400條精挑細選的數學問題進行微調。獎勵函數設計上,鼓勵模型生成正確、簡潔、結構良好的輸出,同時懲罰冗長、重復或格式錯誤的回答。
這種以數據為核心、關注輸出結構的訓練方法顯著提升了模型在推理過程中的泛化能力,能有效應對未見過的符號推理任務。
評估結果與性能表現
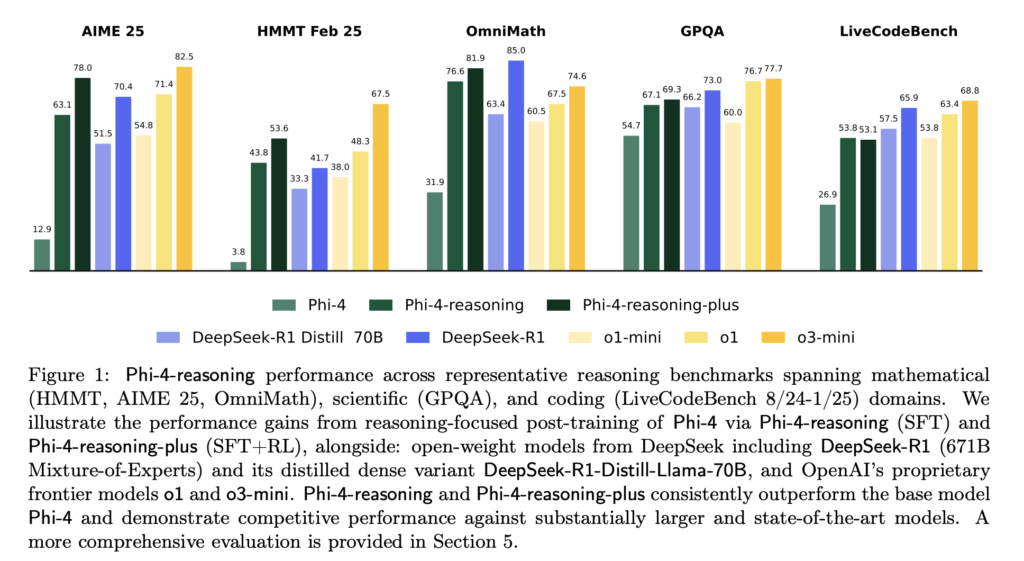
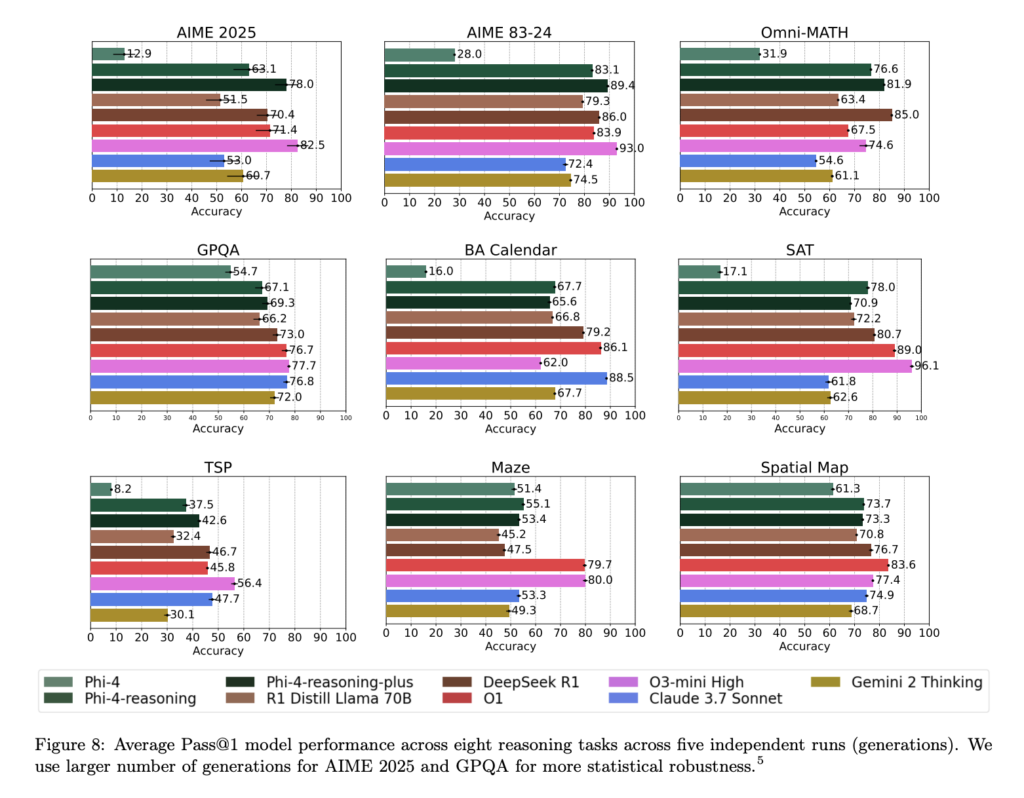
Phi-4-reasoning系列在多個推理評估基準上展現出卓越表現,性能甚至可與顯著更大的開源模型媲美:
- Phi-4-reasoning-plus在特定領域任務上取得優異成績,同時也展現出良好的跨領域泛化能力,如在旅行商問題(TSP)與三滿足問題(3SAT)等組合優化任務中表現穩定,盡管其訓練數據中并未包含相關樣例。
- 在指令遵循評估(IFEval)與長上下文問答(FlenQA)任務中的出色表現,也證明“思維鏈”訓練格式有助于拓展模型在通用場景中的實用性。
- 特別是在對高敏感性數據集如AIME 2025進行測試時,微軟公開了50次生成結果的方差分布,結果顯示Phi-4-reasoning-plus在一致性方面可與o3-mini匹敵,顯著優于較小模型如DeepSeek-R1-Distill。
研究結論與未來展望
Phi-4 Reasoning系列模型展現出一種方法上高度嚴謹、規模上適中的小模型推理范式。通過精準的數據選型、結構調參與少量但關鍵的強化學習干預,微軟驗證了14B規模模型在多步驟推理任務中的出色能力,不僅實現了對更大模型的性能追平,甚至在部分任務中實現超越。
模型權重的開放與透明的基準測試也為未來小型LLM的發展設定了新標準。此類模型尤其適合應用于對解釋性、成本與穩定性要求高的領域,如教育、工程及決策支持系統。微軟預計后續將繼續拓展模型在更多STEM學科的適應能力,優化解碼策略,并探索更大規模的長期強化學習方案,以進一步增強模型的復雜推理能力與實用價值。

:關于angular里面的響應式數據入門使用)

詳解)






-Reranker)








![[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載](http://pic.xiahunao.cn/[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載)