摘要
????????Advanced RAG 的后檢索優化,是指在檢索環節完成后、最終響應生成前,通過一系列策略與技術對檢索結果進行深度處理,旨在顯著提升生成內容的相關性與質量。在這些優化手段中,重排序優化(Reranker)作為核心技術之一,憑借其對檢索結果的二次篩選與優先級調整能力,成為提升 RAG 系統性能的關鍵。以下將圍繞重排序優化(Reranker)的理論基礎、算法原理及實踐應用展開詳細闡述。
重排序(Reranker)
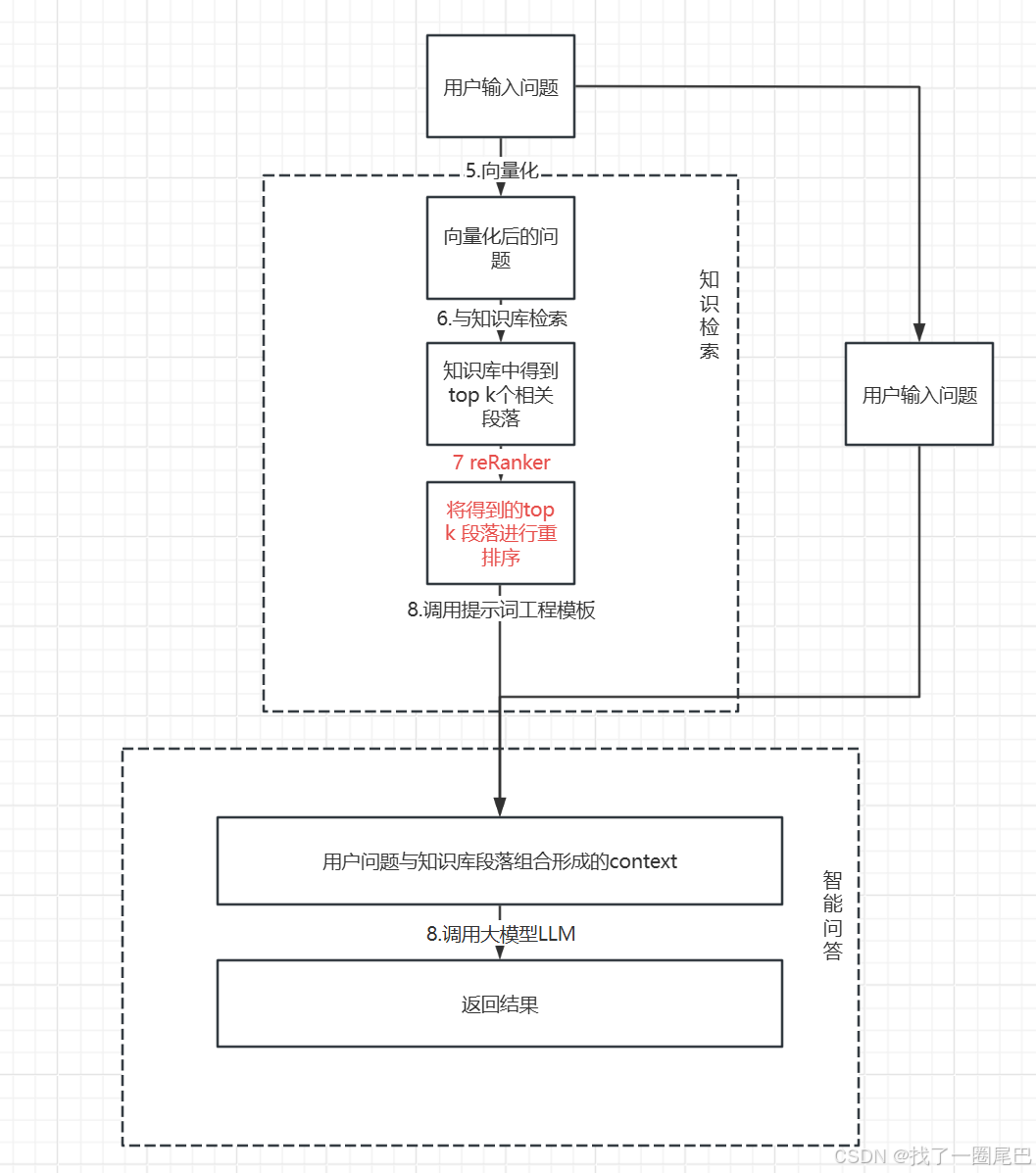
Reranker 在 RAG 中的作用位置
????????Reranker 是信息檢索(IR)生態系統中的一個重要組成部分,用于評估搜索結果,并進行重新排序,從而提升查詢結果相關性。在 RAG 應用中,主要在拿到向量查詢(ANN)的結果后使用 Reranker,能夠更有效地確定文檔和查詢之間的語義相關性,更精細地對結果重排,最終提高搜索質量。
????????目前,Reranker 類型主要有兩種——基于統計和基于深度學習模型的 Reranker:
-
基于統計的 Reranker :匯總多個來源的候選結果列表,使用多路召回的加權得分或倒數排名融合(RRF)算法來為所有結果重新算分,統一將候選結果重排。這種類型的 Reranker 的優勢是計算不復雜,效率高,因此廣泛用于對延遲較敏感的傳統搜索系統中。
-
基于深度學習模型的 Reranker:通常被稱為 Cross-encoder Reranker。由于深度學習的特性,一些經過特殊訓練的神經網絡可以非常好地分析問題和文檔之間的相關性。這類 Reranker 可以為問題和文檔之間的語義的相似度進行打分。因為打分一般只取決于問題和文檔的文本內容,不取決于文檔在召回結果中的打分或者相對位置,這種 Reranker 既適用于單路召回也適用于多路召回。
RRF 倒數排名融合
????????倒數排名融合(Reciprocal Rank Fusion,RRF)是一種用于融合多個檢索結果列表的算法,常用于信息檢索、RAG 混合檢索等領域,它將不同檢索方法得到的排名結果進行結合,生成更全面、準確的最終排名。它考慮了每個文檔在不同檢索結果列表中的排名位置,通過計算排名的倒數來賦予不同文檔相應的權重,從而綜合評估文檔的重要性。

-
計算步驟
-
最大化檢索召回率:在初始檢索階段,通過增加向量數據庫返回的文檔數量(即增加 top_k 值),可以提高檢索的召回率。這意味著盡可能多地檢索相關文檔,確保不會遺漏任何可能有助于 LLM 形成高質量回答的信息。
-
計算每個文檔的 RRF 分數:對于每個文檔,計算它在每個檢索結果列表中的排名的倒數,并將這些倒數相加。
-
重新排序:根據 RRF 分數對所有文檔進行降序排序,得到最終的融合結果。
-
-
優點
-
低門檻高效融合:RRF 具備極強的 “即插即用” 特性,無需復雜調優過程,也無需提前協調不同檢索方法相關性指標的一致性。
-
排名導向的簡潔性:RRF僅依據文檔在各檢索結果中的排名進行計算。這種簡潔的設計不僅大幅簡化了融合流程,還減少了數據處理量,使得 RRF 在計算資源有限或實時性要求高的場景下,依然能夠穩定高效運行 。
-
檢索性能友好:與其他需要額外重排序步驟、可能導致響應延遲顯著增加的融合算法不同,RRF 不會對檢索系統的響應速率造成明顯影響。
-
-
缺點
-
RRF 存在明顯的 “上游依賴” 問題,其性能表現高度依賴前置檢索排序步驟的質量。若初始檢索排序因算法缺陷、數據偏差等原因出現錯誤,例如誤將相關性低的文檔排在前列,RRF 會基于錯誤的排名信息進行融合計算,不僅無法修正錯誤,反而可能進一步放大偏差,導致最終檢索結果嚴重失真,使得融合后的排序完全偏離實際相關性,難以滿足用戶真實需求。
-
-
RRF代碼實現
- RRF 算法
def rrf_rank(documents: list[list[Document]], k=60) -> list[Document]:# 初始化rrf字典(key=文檔id,value={"rrf_score":累計分數,"doc":文檔對象})rrf_scores = {}# 遍歷每個檢索結果列表(每個查詢對應的結果)for docs in documents:# 為每個文檔列表計算排名(從1開始)for rank, doc in enumerate(docs,1):# 計算當前文檔的RRF分數rrf_score = 1 / (k + rank)# 如果文檔已經在字典中,累加RRF分數if doc.id in rrf_scores:rrf_scores[doc.id]['rrf_score'] += rrf_scoreelse:rrf_scores[doc.id] = {'rrf_score': rrf_score,'doc': doc}# 將字典轉換為列表,并根據字段value:RRF分數排序sorted_docs = sorted(rrf_scores.values(),key=lambda x: x['rrf_score'],reverse=True # 降序排列:從大到小)for item in sorted_docs:print(item)result = [item['doc'] for item in sorted_docs]return resultrrf_rank(documents)-
LangChain 框架使用 RRF
from langchain.retrievers import MultiQueryRetriever
from typing import List
from langchain_core.documents import Document
from langchain_core.callbacks import CallbackManagerForRetrieverRunimport logging
# 打開日志
logging.basicConfig()
logging.getLogger("langchain.retrievers.multi_query").setLevel(logging.INFO)# 重寫MultiQueryRetriever類,取消unique_union去重,且保留每個問題檢索結果的
class RRFMultiQueryRetriever(MultiQueryRetriever):# 改寫retrieve_documents方法,返回rrf結果def retrieve_documents(self, queries: List[str], run_manager: CallbackManagerForRetrieverRun) -> List[Document]:documents = []for query in queries:docs = self.retriever.invoke(query, config={"callbacks": run_manager.get_child()})# 原代碼中extend修改為append,保持不同檢索系統的結構documents.append(docs)documents = self.rrf_documents(documents)return documentsdef rrf_documents(self,documents: list[list[Document]], k=60) -> List[Document]:# 初始化rrf字典(key=文檔id,value={"rrf_score":累計分數,"doc":文檔對象})rrf_scores = {}# 遍歷每個檢索結果列表(每個查詢對應的結果)for docs in documents:# 為每個文檔列表計算排名(從1開始)for rank, doc in enumerate(docs,1):# 計算當前文檔的RRF分數rrf_score = 1 / (k + rank)# 如果文檔已經在字典中,累加RRF分數if doc.id in rrf_scores:rrf_scores[doc.id]['rrf_score'] += rrf_scoreelse:rrf_scores[doc.id] = {'rrf_score': rrf_score,'doc': doc}# 將字典轉換為列表,并根據字段value:RRF分數排序sorted_docs = sorted(rrf_scores.values(),key=lambda x: x['rrf_score'],reverse=True # 降序排列:從大到小)result = [item['doc'] for item in sorted_docs]return resultrrf_retriever = RRFMultiQueryRetriever.from_llm(retriever=retriever,llm=llm,include_original = True #是否包含原始查詢
) rrf_docs = rrf_retriever.invoke("人工智能的應用")pretty_print_docs(rrf_docs)? ? ? ? 我們采用自定義一個RRFMultiQueryRetriever檢索器的方法。這個檢索器繼承了LangChain 的MultiQueryRetriever 檢索器,并融合了RRF 算法。
Reranker模型
????????Reranker模型又稱交叉編碼器(Cross-Encoder)模型。它是信息檢索、推薦系統等場景中的關鍵組件,用于對初步召回的候選集進行精細化排序。與召回階段的快速篩選不同,Reranker通過復雜模型捕捉細粒度特征(如語義相關性、上下文信息、用戶偏好),顯著提升最終結果的準確性和個性化。
阿里魔搭Reranker模型
? ? ? ?
????????在中文 Reranker 應用場景中,我推薦選用國產 Reranker 模型。國產模型在訓練時使用了大量的中文語料,對中文語義的理解更為深刻、全面,能夠更精準地捕捉中文語境下的細微語義差別,因此在處理中文任務時可以帶來更出色的效果。
????????你可以前往阿里魔搭社區搜尋合適的 Reranker 開源模型。在該社區中,你可以重點關注那些下載量高或者喜歡數多的模型,例如 beg - reranker 相關模型,這些模型往往經過了大量用戶的實踐檢驗,具備較高的可靠性和實用性。
常見Reranker模型類型
-
基于學習排序(Learning to Rank, LTR)
-
原理:利用機器學習模型對文檔排序,分為三類:
-
Pointwise:直接預測文檔與查詢的絕對相關性(如線性回歸、GBDT)。示例:預測點擊率(CTR)作為排序依據。
-
Pairwise:比較文檔對的相對順序,最小化錯誤比較(如RankNet、RankSVM)。示例:判斷文檔A是否比文檔B更相關。
-
Listwise:優化整個排序列表的指標(如NDCG、MAP),直接端到端優化目標。示例:LambdaMART(GBDT+Listwise)、ListNet。
-
-
-
基于預訓練語言模型(PLM)的Reranker
-
核心:利用BERT、RoBERTa等預訓練模型捕捉深層語義交互。
-
典型架構:
-
Cross-Encoder:將查詢與文檔拼接輸入模型,直接計算相關性得分。
-
示例:
[CLS] Query: How to learn Python [SEP] Document: Python tutorial [SEP]?→ 輸出相關性分數。 -
優點:捕捉細粒度語義交互,精度高。
-
缺點:計算成本高(需逐對計算,適合小候選集)。
-
-
ColBERT:解耦查詢與文檔編碼,通過后期交互提升效率。
-
流程:分別編碼查詢和文檔,計算最大相似度(MaxSim)作為得分。
-
優點:比Cross-Encoder快,適合較大候選集。
-
-
-
-
多模態Reranker
-
適用場景:融合文本、圖像、視頻、用戶行為等多模態特征。
-
示例:電商場景中,結合商品標題(文本)、圖片(視覺)、用戶歷史點擊(行為)綜合排序。
-
模型:多模態Transformer(如CLIP擴展)、特征拼接+深度學習。
-
Reranker 模型代碼實現
-
本地Reranker模型
from langchain.retrievers import ContextualCompressionRetriever
from langchain.retrievers.document_compressors import CrossEncoderReranker
from langchain_community.cross_encoders import HuggingFaceCrossEncoder# reranker
model = HuggingFaceCrossEncoder(model_name=model_path, model_kwargs={'device': 'cpu'})
# 取前3個
compressor = CrossEncoderReranker(model=model, top_n=3)compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever # retriever = 混合檢索 或 multi-query
)compressed_docs = compression_retriever.invoke("人工智能的應用")
pretty_print_docs(compressed_docs)-
阿里Reranker模型
from langchain_community.document_compressors.dashscope_rerank import DashScopeRerank# https://bailian.console.aliyun.com/?tab=api#/api/?type=model&url=https%3A%2F%2Fhelp.aliyun.com%2Fdocument_detail%2F2780056.html
# gte-rerank
compressor = DashScopeRerank()compression_retriever = ContextualCompressionRetriever(base_compressor=compressor, base_retriever=retriever
)compressed_docs = compression_retriever.invoke("人工智能的應用")
pretty_print_docs(compressed_docs)LongContextReorder
-
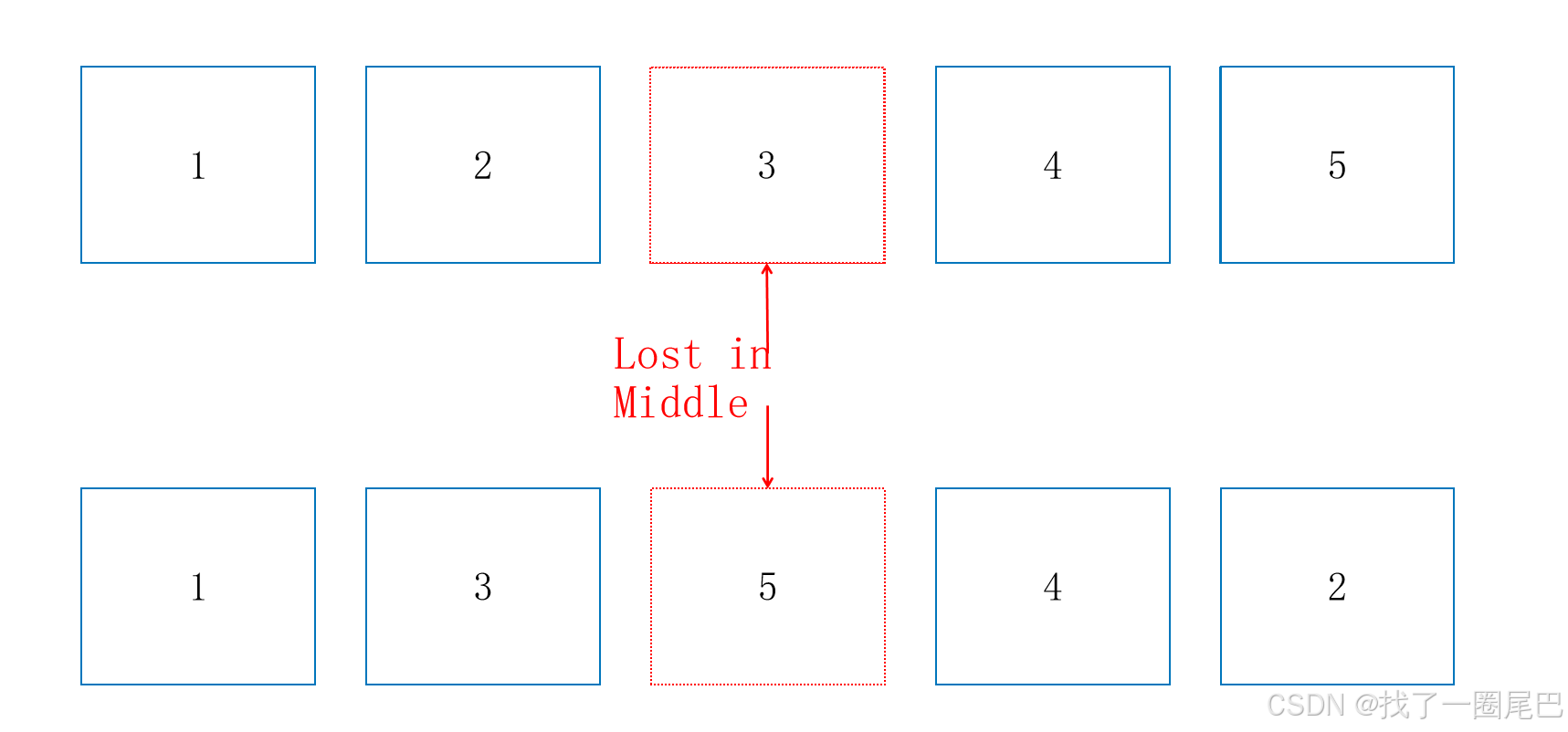
論文基礎:Lost in the Middle: How Language Models Use Long Contexts
[2307.03172] Lost in the Middle: How Language Models Use Long Contexts
? ? ? ? 根據論文描述,當關鍵數據位于輸入上下文的開頭或者結尾時,大模型的回答通常會獲得最佳的效果。為了減輕"lost in the middle"的影響,我們可以在檢索后重新排序文檔,使最相關的文檔位于最佳位置(如上下文的第一和最后部分),將不相關的文檔置于中間。
代碼實現
????????LangChain 框架提供了LongContextReorder思想的代碼封裝:
from langchain_community.document_transformers import LongContextReorder
# 5,4,3,2,1
# 倒排:1,2,3,4,5
# index%2=0: 往第一個放,index%2=1 往最后放documents = ["相關性:5","相關性:4","相關性:3","相關性:2","相關性:1",
]reordering = LongContextReorder()
reordered_docs = reordering.transform_documents(documents)print(reordered_docs)總結
| 排序方法 | 說明 | 案例 |
|---|---|---|
| RRF | 根據文檔在不同列表排名重排序 | 優點:計算簡單、處理大數據快;無需大量訓練數據; 缺點:僅依排名,忽略文檔內容與語義,精準度欠佳; |
| Reranker | 基于深度學習,根據查詢與文檔語義重排序 | 優點:能深入理解語義,精準重排提升檢索精度; 缺點:對新查詢和文檔泛化能力有限,易出現過擬合情況 |
| Lost in the Middle | 根據相關性降序排列后的文檔再次排序,將相關的文檔置于極值(開頭與結尾) | 依賴重排精準度 |








![[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載](http://pic.xiahunao.cn/[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載)





)




)