一、Elasticsearch 是什么?
一句話定義:
開源分布式搜索引擎,擅長處理海量數據的實時存儲、搜索與分析,是ELK技術棧(Elasticsearch+Kibana+Beats+Logstash)的核心組件。
核心能力:
- 近實時搜索:數據寫入后1秒內可查
- 水平擴展:單機→集群,支持PB級數據處理
- 多場景適配:日志分析、商品搜索、輿情監控
二、為什么需要 Elasticsearch?
傳統數據庫的困境:
| 場景 | 傳統數據庫表現 | Elasticsearch解決方案 |
|---|---|---|
| 模糊搜索「周杰倫」 | 只能精確匹配「周杰倫」 | 支持諧音/錯別字糾錯 |
| 分析1億條日志 | 導致數據庫卡頓甚至崩潰 | 分布式并行處理,流暢響應 |
| 多字段混合查詢 | 需多次關聯查詢 | 單次查詢實現多維度關聯分析 |
典型應用場景:
- 非結構化數據處理:日志、郵件、社交媒體文本等數據
- 復雜搜索需求:電商商品搜索、新聞資訊聚合
- 實時數據分析:業務指標監控、安全事件預警
三、Elasticsearch vs Solr:如何選擇?
決策流程圖:
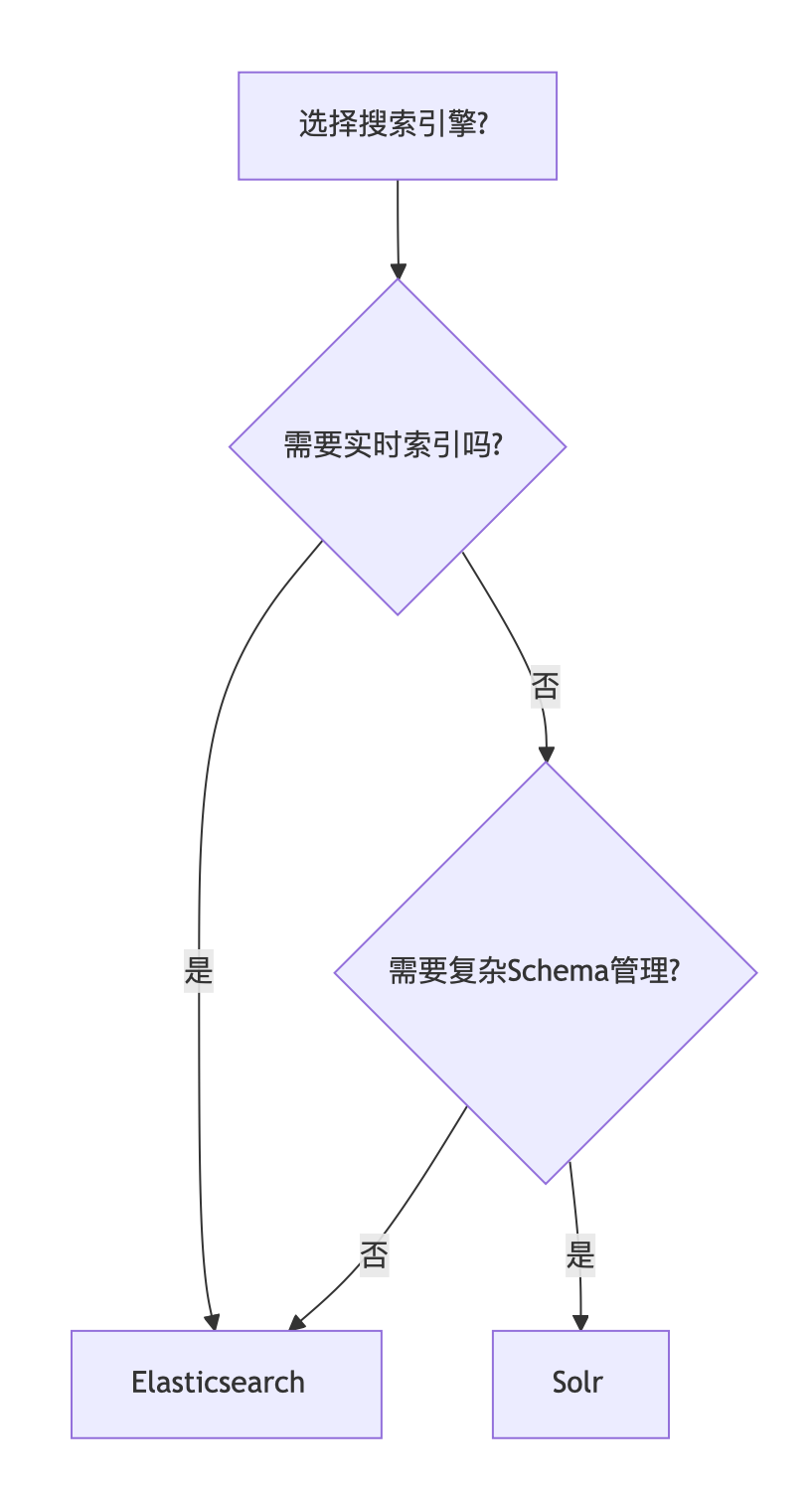
關鍵差異對比:
| 特性 | Elasticsearch | Solr |
|---|---|---|
| 部署復雜度 | 5分鐘快速啟動(JSON配置) | 需XML配置,學習成本較高 |
| 實時索引性能 | 寫入無阻塞,查詢響應快 | 批量寫入快,實時索引有延遲 |
| 數據格式支持 | 僅JSON | JSON/XML/CSV |
| 適用場景 | 日志分析、實時搜索 | 企業級復雜搜索 |
| 社區生態 | 活躍但文檔較技術化 | 成熟文檔豐富 |
四、Elasticsearch 核心概念解析
索引(Index)——數據倉庫分區
-
類比:圖書館的「科幻書架區」、[人文書架區]
-
規則:
-
- 名稱必須全小寫(
user_logs合法,UserLogs報錯) - 一個索引存一類數據(訂單索引、用戶索引)
- 名稱必須全小寫(
4.2 文檔(Document)——數據基本單元
- 形式:JSON格式(相等于關系型數據庫表的行數據)
{"title": "Elasticsearch入門","content": "全文搜索引擎的最佳實踐","author": "技術小王","date": "2023-08-20"
}
4.3 分片(Shard)——數據分塊存儲
-
作用:水平擴容+并行計算
-
類比:將1TB書籍拆成10層書架存放
-
特性:
-
- 主分片(處理寫入)
- 副本分片(容災+讀請求分流)
4.4 副本(Replica)——數據雙保險
-
意義:
-
- 防止節點宕機導致數據丟失
- 提升查詢吞吐量(主分片+副本并行響應)
五、Elasticsearch 應用圖譜
典型行業案例:
| 公司 | 應用場景 | 數據規模 |
|---|---|---|
| GitHub | 代碼/日志檢索 | 20TB數據/1300億行 |
| 百度 | 用戶行為分析 | 單集群日處理30TB+ |
| 阿里云 | 日志服務LaaS | 100節點集群 |
:關于angular里面的響應式數據入門使用)

詳解)






-Reranker)








![[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載](http://pic.xiahunao.cn/[Windows] Kazumi番劇采集v1.6.9:支持自定義規則+在線觀看+彈幕,跨平臺下載)
