
mutex, rwmutex
在Go語言中,Mutex(互斥鎖)和RWMutex(讀寫鎖)是用于管理并發訪問共享資源的核心工具。以下是它們的常見問題、使用場景及最佳實踐總結:
1. Mutex 與 RWMutex 的區別
- Mutex:
- 互斥鎖,保證同一時刻只有一個 goroutine 訪問共享資源。
- 適用于讀寫操作都需要獨占的場景(如計數器)。
- RWMutex:
- 讀寫鎖,允許多個讀操作并行,但寫操作完全獨占。
- 適用于讀多寫少的場景(如配置信息讀取)。
2. 常見問題及解決方案
2.1 死鎖
- 原因: 未釋放鎖、重復加鎖或鎖競爭導致永久阻塞。
- 解決:
- 使用
defer mu.Unlock()確保釋放鎖。 - 避免在同一個 goroutine 中重復加鎖(不可重入)。
- 使用
2.2 數據競爭
- 原因: 未對共享資源的所有訪問路徑加鎖。
- 解決:
- 明確鎖的保護范圍,確保所有訪問共享數據的操作都被鎖覆蓋。
- 使用
go test -race檢測數據競爭。
2.3 鎖拷貝
- 原因: 復制包含鎖的結構體導致鎖狀態異常。
- 解決:
- 通過指針傳遞包含鎖的結構體。
- 避免直接復制
sync.Mutex或sync.RWMutex。
2.4 寫饑餓(RWMutex)
- 原因: 大量讀操作阻塞寫操作。
- 解決:
- 評估場景是否需要 RWMutex,或通過優先級隊列優化寫操作。
- Go 1.18+ 的 Mutex 支持饑餓模式,避免長時間等待。
3. 使用場景
- Mutex:
var counter int var mu sync.Mutexfunc increment() {mu.Lock()defer mu.Unlock()counter++ } - RWMutex:
var config map[string]string var rwmu sync.RWMutexfunc readConfig(key string) string {rwmu.RLock()defer rwmu.RUnlock()return config[key] }func updateConfig(key, value string) {rwmu.Lock()defer rwmu.Unlock()config[key] = value }
4. 最佳實踐
- 鎖的作用域:
- 鎖應保護數據而非代碼,確保所有訪問共享資源的路徑都被覆蓋。
- 優先使用
defer:- 避免忘記解鎖,尤其在復雜邏輯或異常處理中。
- 替代方案:
- 對簡單數值操作(如計數器)使用
atomic包。 - 通過 Channel 實現“通過通信共享內存”。
- 對簡單數值操作(如計數器)使用
- 性能優化:
- 減少鎖的持有時間(如僅在讀寫共享數據時加鎖)。
- 在高并發場景中,評估鎖競爭是否成為瓶頸。
5. 注意事項
- 不可重入: Go 的鎖不支持重入,同一 goroutine 重復加鎖會導致死鎖。
- 零值可用:
sync.Mutex和sync.RWMutex的零值可直接使用,無需初始化。 - 避免嵌套鎖: 多個鎖的嵌套使用可能導致復雜死鎖,需按固定順序加鎖。
通過合理選擇 Mutex 或 RWMutex,并遵循最佳實踐,可以有效避免并發問題,編寫高效且安全的 Go 代碼。
協程線程區別
協程(Coroutine)和線程(Thread)都是用于實現并發執行的機制,但它們在調度方式、資源消耗、通信機制等方面有顯著區別。線程是操作系統級別的并發單位,由內核調度;而協程是用戶態的輕量級線程,由程序自身調度。
- 解答思路:
- 首先明確兩者的基本定義和使用場景。
- 對比它們的調度機制:線程由操作系統調度器管理,而協程由用戶程序或運行時系統管理。
- 比較它們的開銷:線程切換代價高,需要操作系統參與;協程切換快,僅需保存寄存器狀態。
- 分析資源占用:線程擁有獨立的棧空間,內存占用較大;協程共享線程資源,更節省內存。
- 總結適用場景:CPU密集型適合多線程,IO密集型或多任務協作適合協程。
- 深度知識講解:
一、基本概念
-
線程(Thread)
線程是進程內的一個執行單元,多個線程共享同一進程的地址空間和資源。每個線程有自己獨立的棧和寄存器上下文。線程由操作系統負責創建、銷毀和調度。 -
協程(Coroutine)
協程是一種用戶態的非搶占式多任務機制,可以看作是“輕量級線程”。它不像線程那樣被操作系統調度,而是由程序員顯式控制其切換。協程之間通常是協作式的,即當前協程主動讓出控制權給下一個協程。
二、核心區別
- 調度機制不同
- 線程是搶占式的,操作系統根據優先級、時間片等策略決定哪個線程運行。
- 協程是協作式的,必須由當前協程主動 yield 控制權,才能切換到下一個協程。
- 上下文切換開銷
- 線程切換涉及內核態與用戶態的切換,需要保存/恢復更多的寄存器和狀態信息,開銷大。
- 協程切換完全在用戶態進行,只需保存少量寄存器,開銷極小。
- 資源占用
- 線程通常默認分配較大的棧空間(如1MB),因此不能大量創建。
- 協程棧空間較小(可配置為幾KB),支持同時運行成千上萬個協程。
- 同步與通信
- 線程間通信需要互斥鎖、信號量等機制,容易引發競態條件。
- 協程可以通過通道(channel)、事件循環等方式進行安全高效的通信。
- 并發模型
- 多線程屬于并行模型,適用于 CPU 密集型任務。
- 協程屬于異步/協作式并發模型,適用于 IO 密集型任務(如網絡請求、文件讀寫)。
GMP調度
Go語言的GPM調度模型是Go運行時中用于處理并發的核心機制之一,它將Goroutine(輕量級線程)有效地映射到系統線程上,以最大化并發性能。GPM模型主要由三個部分組成:G(Goroutine)、P(Processor)、M(Machine)。讓我們逐一詳細介紹:
1. G(Goroutine)
- Goroutine 是Go語言中用于并發執行的輕量級線程,每個Goroutine都有自己的棧和上下文信息。
- Goroutine相對于操作系統的線程更加輕量級,可以在同一時間內運行成千上萬的Goroutine。
2. P(Processor)
- P 是處理Goroutine的調度器的上下文,每個P包含一個本地運行隊列(Local Run Queue),用于存儲需要運行的Goroutine。
- P的數量由
GOMAXPROCS設置決定,它決定了并行執行的最大線程數。 - P不僅管理Goroutine,還負責與M協作,將Goroutine分配給M執行。
3. M(Machine)
- M 代表操作系統的線程,負責執行Goroutine。一個M一次只能執行一個Goroutine。
- M是實際執行代碼的工作單元,M與P綁定后才能執行Goroutine。
- M可以通過調度器從全局運行隊列中拉取新的Goroutine,也可以與其他M協作完成工作。
4. GPM模型的調度過程
- 調度器工作機制:Goroutine創建后會被放入P的本地隊列,P會從該隊列中選擇Goroutine,并將其分配給M執行。如果本地隊列為空,P可以從全局運行隊列或其他P的隊列中竊取任務。
- 工作竊取機制:如果一個P的本地隊列為空,而另一個P的本地隊列中有多個Goroutine,前者可以從后者中竊取任務,從而保持系統的高效利用率。
- 阻塞與調度:當M執行的Goroutine阻塞(例如I/O操作)時,M會釋放當前的P并等待P重新分配任務,從而避免資源浪費。
5. 模型優點
- 高效的并發調度:GPM模型使得Go語言可以高效地管理數百萬個Goroutine的并發執行。
- 可伸縮性:通過P與M的動態調度,GPM模型可以充分利用多核處理器的性能。
- 輕量級:Goroutine非常輕量,創建和切換的成本比系統線程要低得多。
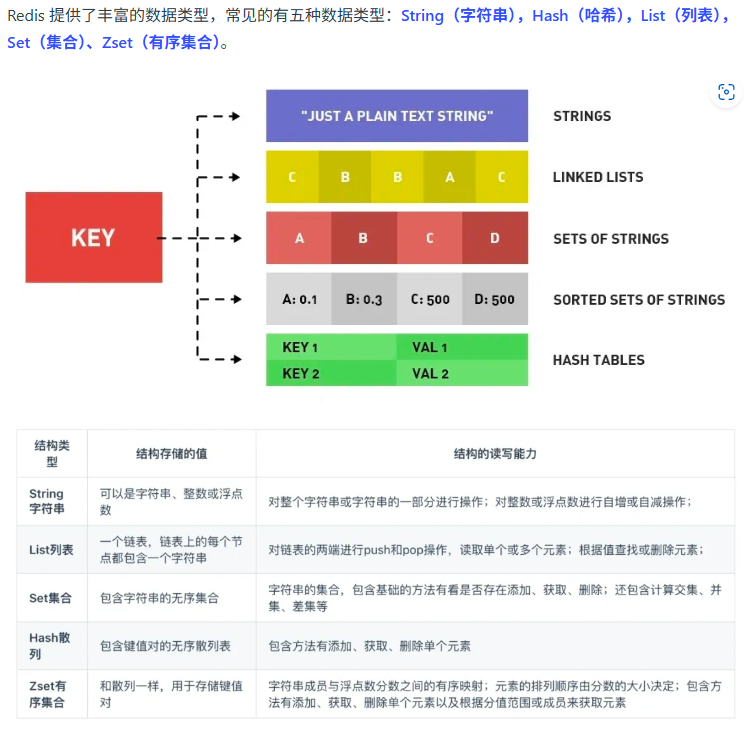
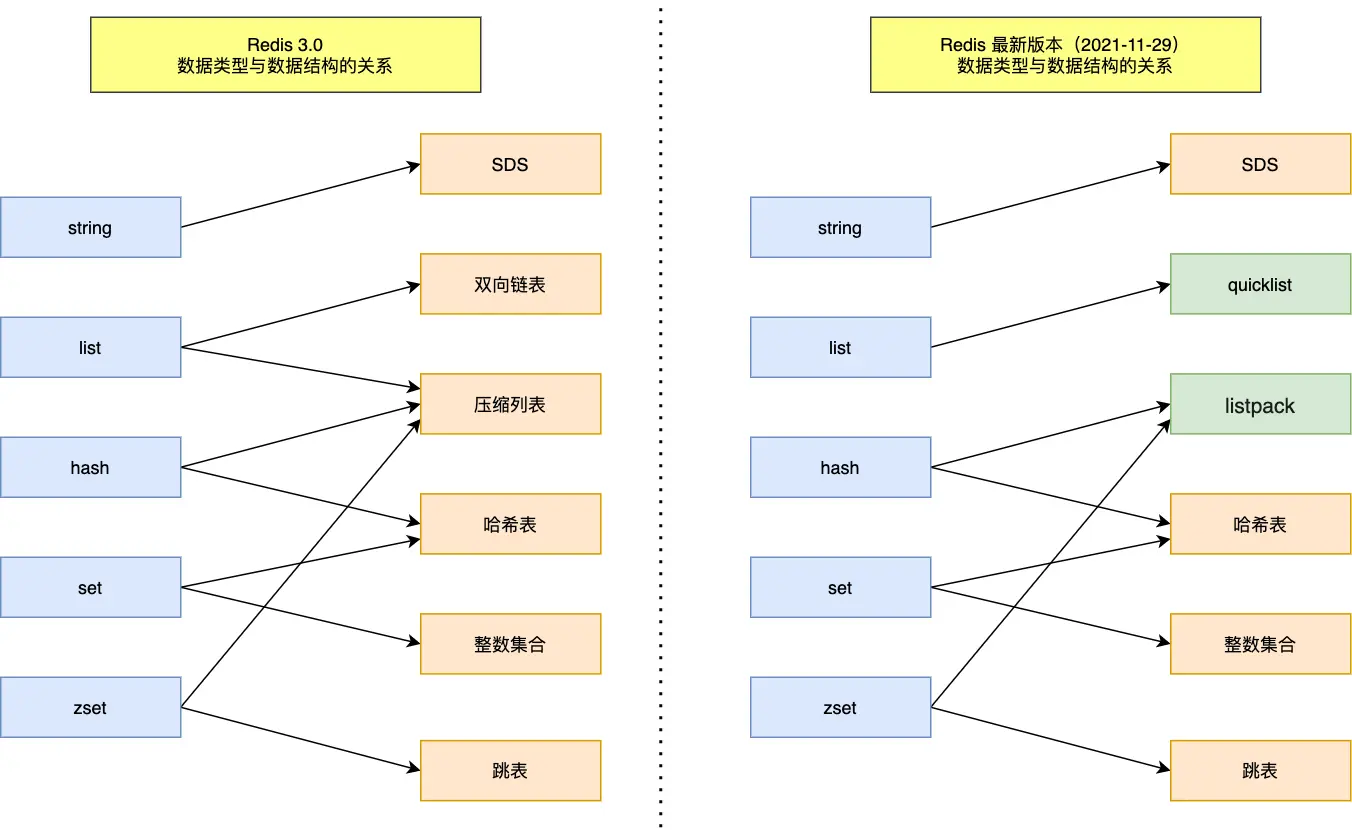
redis 常見數據類型

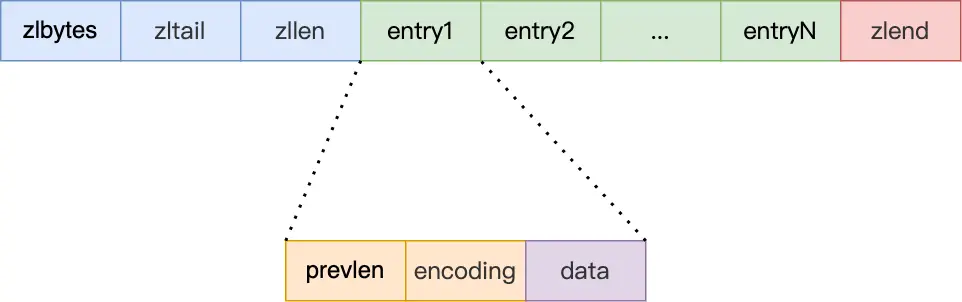
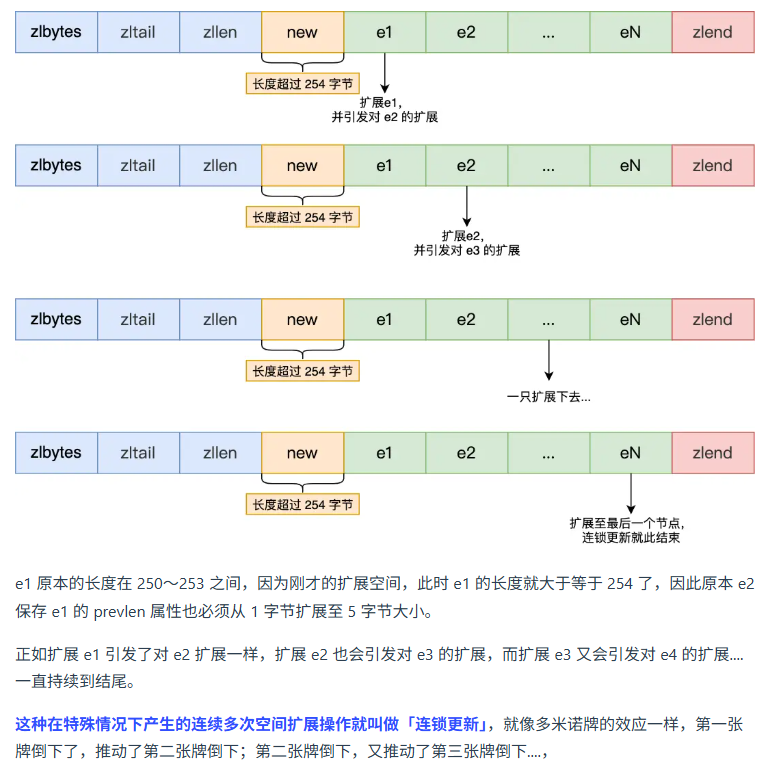
壓縮列表
連續內存塊組成的順序型數據結構

O(1)定位首尾元素,其他需要遍歷,不適合存儲太多數據。

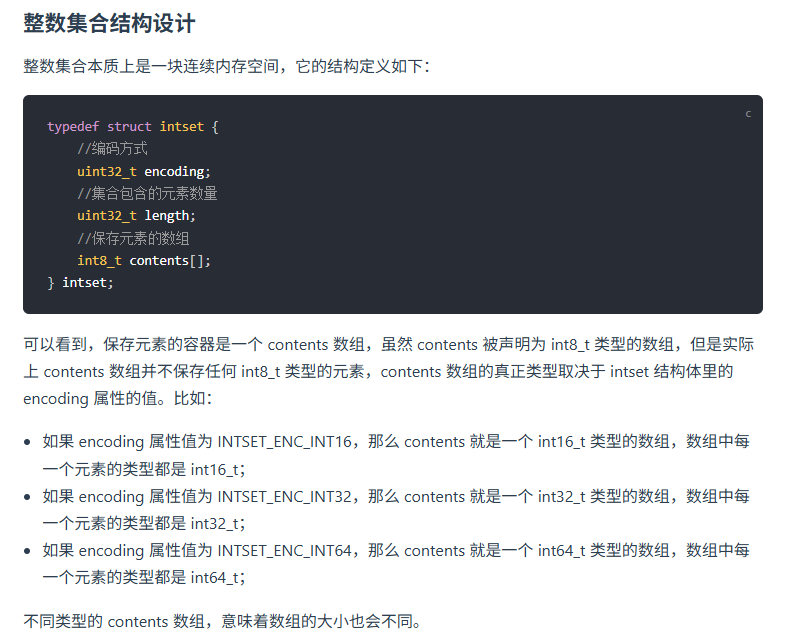
整數集合
跳表
跳表的優勢是能支持平均O(logN)復雜度的節點查找
zset存儲member和score


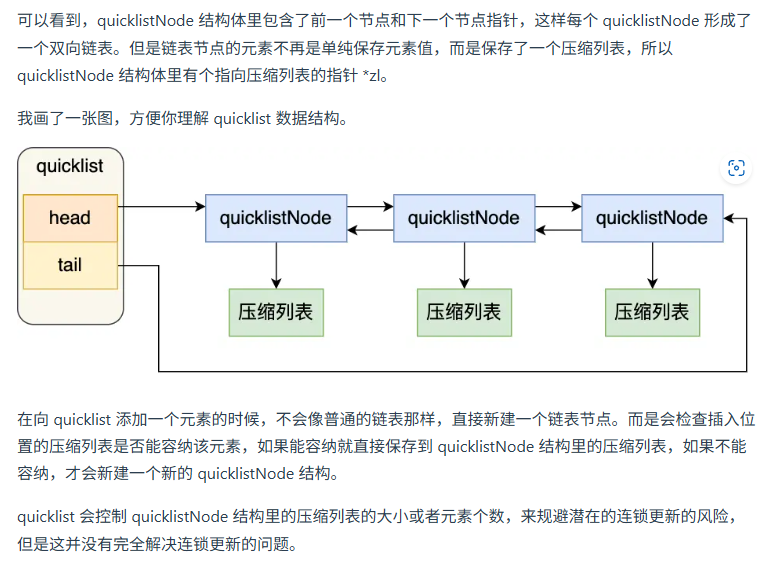
quicklist代替雙向鏈表

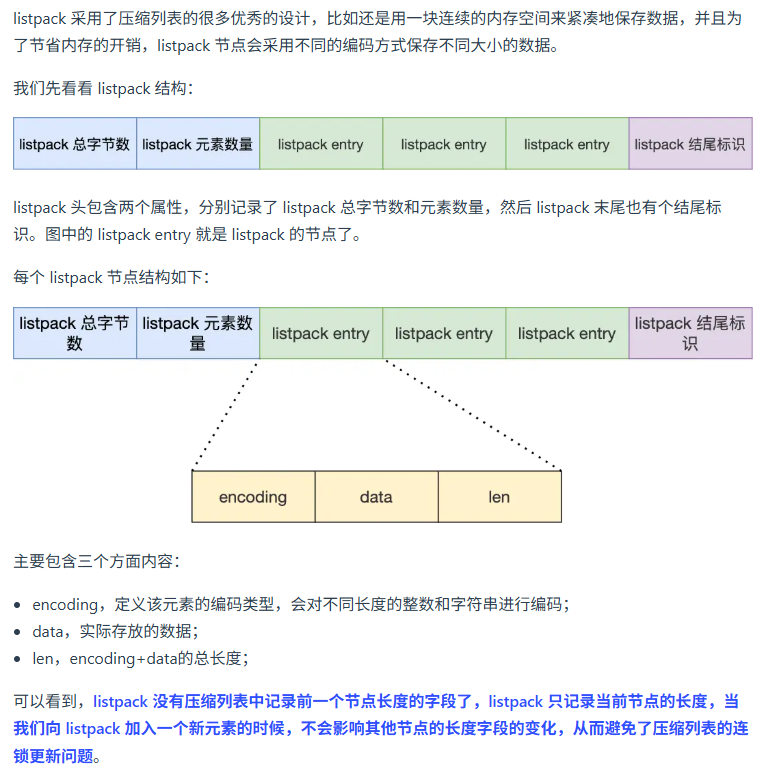
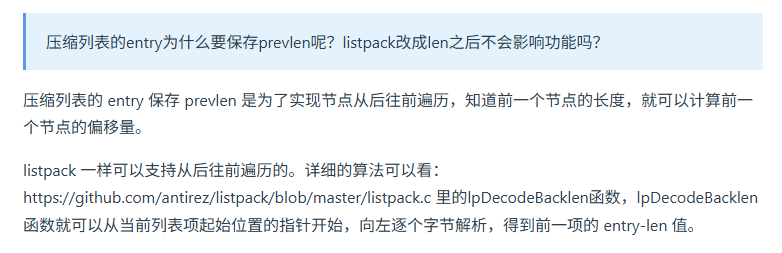
listpack代替壓縮列表
redis跳表的增刪改查復雜度
O(logN)
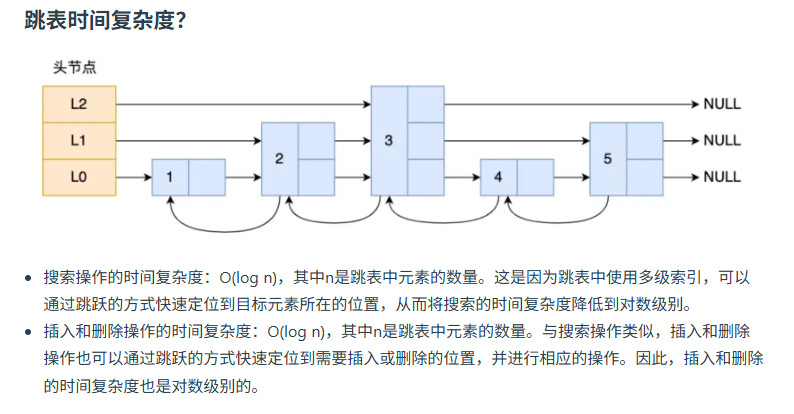
redis跳表數據結構,高度創建,怎么刪改

跳躍表(Skip List)的刪除和修改操作需要結合其多層鏈表結構的特點進行調整,以下是具體實現步驟和原理:
一、刪除操作
刪除節點的核心步驟是:找到目標節點在所有層的引用,并更新這些層的指針以跳過該節點。
1. 刪除流程
-
查找目標節點:
- 從最高層開始,向右遍歷,直到找到等于或大于目標值的節點。
- 如果當前層的下一個節點等于目標值,記錄該層的前驅節點(即指向目標節點的節點)。
- 逐層向下重復此過程,直到最底層(Level 0)。
- 時間復雜度:O(log n),與查找操作相同。
-
調整指針:
- 對每一層(從最高層到最底層):
- 如果該層存在指向目標節點的前驅節點,將其指針指向目標節點的下一個節點。
- 例如,若前驅節點在 Level 2 指向目標節點,則將前驅節點的 Level 2 指針指向目標節點的 Level 2 后繼節點。
- 操作示例:
原結構(刪除節點 30): Level 2: 10 --------------------------> 50 Level 1: 10 -------> 30 -------> 50 Level 0: 10 -> 20 -> 30 -> 40 -> 50刪除后: Level 2: 10 --------------------------> 50 Level 1: 10 -------> 50 Level 0: 10 -> 20 -> 40 -> 50
- 對每一層(從最高層到最底層):
-
釋放內存:
- 刪除節點后,釋放該節點的內存(在 Redis 等語言中可能由 GC 自動處理)。
2. 關鍵注意事項
- 多線程安全:如果跳躍表支持并發操作,刪除時需加鎖(如 Redis 單線程模型無需考慮)。
- 更新最大層高:若刪除的節點是最高層的唯一節點,需降低跳躍表的最大層高。
二、修改操作
修改操作分為兩種情況:僅修改值(Value) 或 修改鍵(Score)。
1. 僅修改值(Value)
- 流程:
- 查找目標節點:時間復雜度 O(log n)。
- 直接更新值:無需調整指針,直接修改節點的值字段。
- 時間復雜度:O(log n)(僅查找時間)。
2. 修改鍵(Score)
由于跳躍表是按鍵(Score)有序排列的,修改鍵后需保證順序性,因此需要先刪除舊節點,再插入新節點。
-
流程:
- 刪除舊節點:O(log n)。
- 插入新節點:按新鍵值插入,O(log n)。
-
總時間復雜度:O(log n) + O(log n) = O(log n).
-
示例:
原結構(修改節點 30 的 Score 為 35): Level 1: 10 -------> 30 -------> 50 Level 0: 10 -> 20 -> 30 -> 40 -> 50修改后: Level 1: 10 --------------------------> 50 Level 0: 10 -> 20 -> 40 -> 50 新插入節點 35: Level 1: 10 ----------> 35 -------> 50 Level 0: 10 -> 20 -> 35 -> 40 -> 50
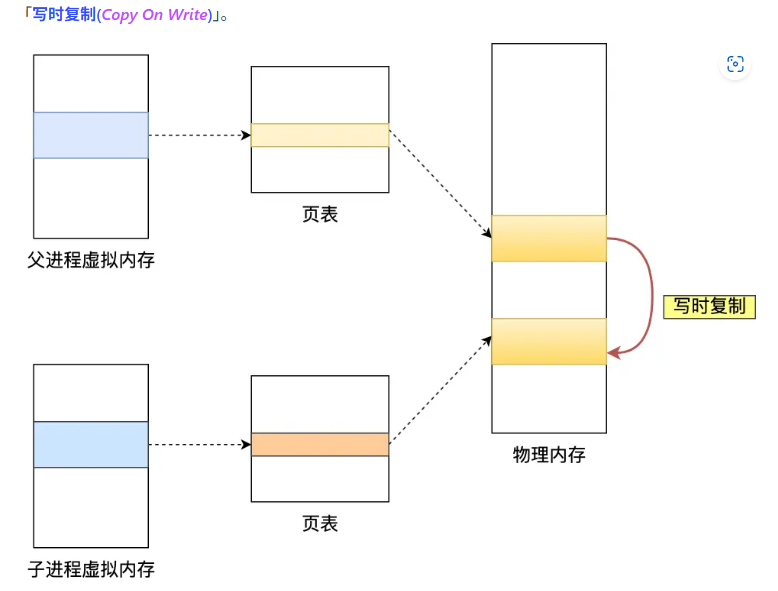
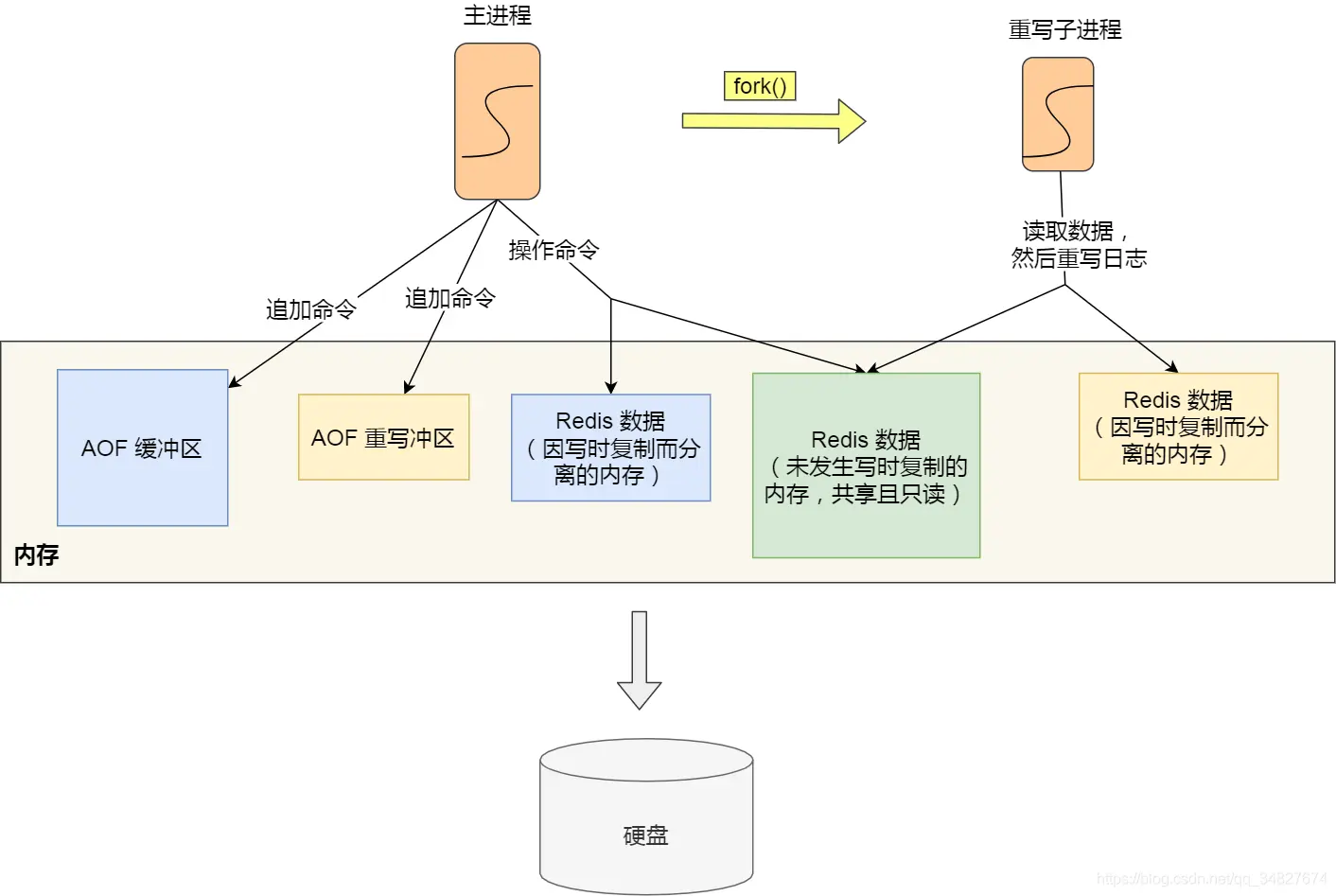
redis持久化AOF怎么做


數組中重復的數據
https://leetcode.cn/problems/find-all-duplicates-in-an-array/description/
func findDuplicates(nums []int) []int {n := len(nums)ans := []int{}for i:=0;i<n;i++{x := nums[i]if x<0{x = -x}if nums[x-1]<0{ans = append(ans, x)}else{nums[x-1] = -nums[x-1]}}return ans
}










)






![[Python開發] 如何用 VSCode 編寫和管理 Python 項目(從 PyCharm 轉向)](http://pic.xiahunao.cn/[Python開發] 如何用 VSCode 編寫和管理 Python 項目(從 PyCharm 轉向))
)
