一、模型概覽:豐富的模型家族
Qwen3 系列包含了 2 款混合專家(MoE)模型與 6 款密集(Dense)模型,參數量覆蓋范圍極廣,從 0.6B 一直延伸至 235B 。其中,旗艦模型 Qwen3 - 235B - A22B 總參數量高達 2350 億,不過其激活參數僅 220 億,借助 MoE 架構實現了 “動態資源分配”,這是一個極為關鍵的特性,在后文性能表現部分會詳細闡述它如何發揮作用。而小型 MoE 模型 Qwen3 - 30B - A3B 總參數約 300 億,激活參數 30 億 。6 款 Dense 模型則分別為 Qwen3 - 0.6B、1.7B、4B、8B、14B、32B,不同的參數量可以滿足多樣化的應用場景和部署需求。

二、核心特性:混合推理模式引領新方向
創新的雙模式設計
Qwen3 作為國內首個支持 “思考模式” 與 “非思考模式” 的混合推理模型,在模型響應策略上實現了重大突破。在思考模式下,模型面對復雜邏輯、數學推理等任務時,會啟動多步驟深度推理,就像一位深思熟慮的學者,逐步剖析問題,最終輸出嚴謹的結果。例如在解決復雜的數學證明題或者邏輯推理謎題時,思考模式能夠讓模型有條不紊地梳理思路,找到問題的關鍵所在。而非思考模式則如同敏捷的短跑選手,對于簡單任務能夠迅速做出低算力 “秒級響應” 。比如回答常見的事實性問題,像 “今天天氣如何”“中國的首都是哪里” 等,非思考模式能快速給出答案,極大地提高了處理效率。這種雙模式設計,使得模型在效率與精度之間找到了完美的平衡。
推理能力大幅提升
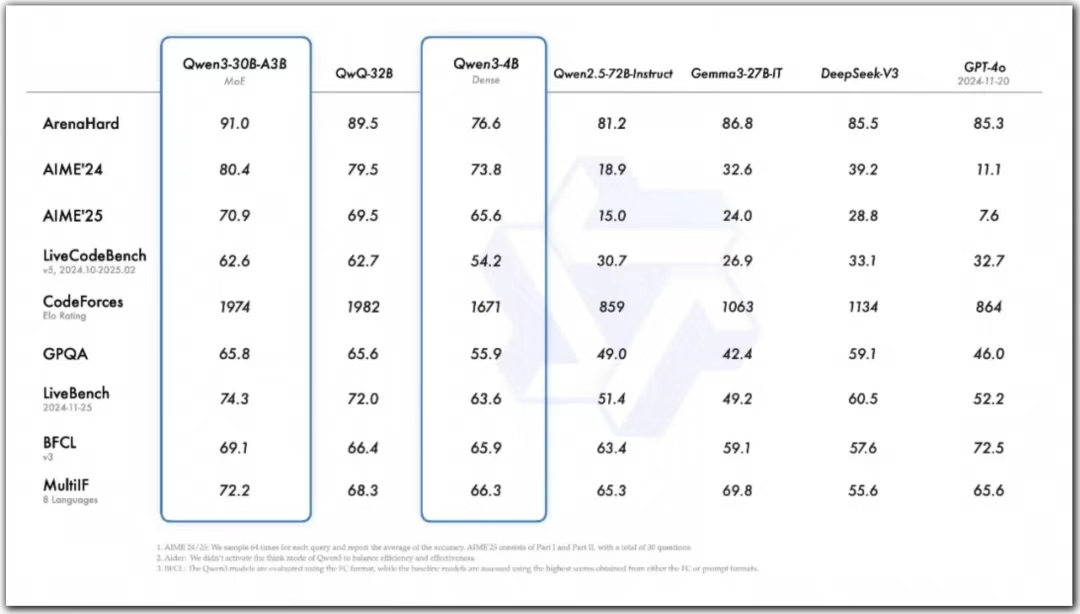
在多個權威基準測試中,Qwen3 展現出了驚人的性能。在奧數水平的 AIME25 測評中,它斬獲 81.5 分,刷新了開源模型的紀錄,這一成績充分證明了其在復雜數學推理方面的深厚功底。在代碼能力測試 LiveCodeBench 中,它突破 70 分大關,超越了 Grok3,說明其在代碼生成、理解和應用方面的能力十分卓越。在模型人類偏好對齊評估 ArenaHard 中,Qwen3 以 95.6 分的成績超越了 OpenAI - o1 和 DeepSeek - R1 。此外,在 GPQA、AIME24/25 等測試中也表現出色,全面超越了 DeepSeek - R1、OpenAI - o1 等全球頂尖模型。這些測試結果表明,Qwen3 在推理能力上已經達到了行業領先水平。
多語言支持能力強大
Qwen3 支持 119 種語言和方言,涵蓋了印歐語系、漢藏語系、亞非語系、南島語系等多個語系。這一廣泛的多語言能力為全球用戶提供了極大的便利,無論是跨國企業進行多語言文檔處理、翻譯,還是全球化的智能客服系統,Qwen3 都能輕松應對,開創了國際應用的新可能性。
三、性能優勢:小參數,大能量
小型模型的卓越表現
小型 MoE 模型 Qwen3 - 30B - A3B 的激活參數僅為 QwQ - 32B 的 10%,卻取得了更優的表現,這體現了 Qwen3 在模型架構和訓練優化上的巨大成效。甚至像 Qwen3 - 4B 這樣參數規模相對較小的模型,也能媲美 Qwen2.5 - 72B - Instruct 的性能水平 。這種高效的性能表現,使得 Qwen3 系列模型在實際應用中,尤其是在資源受限的場景下,具有顯著優勢。例如在移動端設備或者邊緣計算場景中,小參數模型能夠以較低的計算資源消耗實現較高的性能輸出。
模型性能與成本的平衡
業界分析認為,Qwen3 在參數量減少的情況下實現高性能,并非簡單的裁剪,而是通過更高效的計算方式和知識蒸餾技術實現的。例如,Qwen3 引入動態稀疏激活機制,僅在必要時調用關鍵參數,從而降低計算冗余。這一改進使其在資源受限場景(如移動端或邊緣設備)中更具部署潛力。以企業部署為例,原本需要大量計算資源和高昂成本才能運行的復雜 AI 應用,現在借助 Qwen3 的高效模型,可以在相對低成本的硬件配置下實現同樣甚至更好的效果。
四、訓練與優化:數據與方法的雙重升級
數據規模翻倍
預訓練數據量從 Qwen2.5 的 18 萬億 token 擴展至 36 萬億 token,新增 119 種語言及方言支持,涵蓋了 PDF 文檔解析、STEM 領域教材、代碼片段等高質量數據。為了構建這個龐大的數據集,團隊不僅從網絡收集數據,還利用 Qwen2.5 - VL 視覺模型輔助提取文檔文本,結合 Qwen2.5 - Math 與 Qwen2.5 - Coder 合成數學及代碼數據,通過多渠道多方式的數據整合與處理,使得模型在專業領域的理解能力顯著增強 。例如在處理專業的學術文獻、代碼項目文檔時,Qwen3 能夠憑借豐富的數據訓練基礎,更好地理解其中的專業術語、邏輯結構和語義信息。
四階段訓練流程
通過 “長思維鏈冷啟動 - 強化學習 - 模式融合 - 通用優化” 四階段后訓練,Qwen3 實現推理能力與響應速度的深度整合。在第一階段,使用多樣化的長思維鏈數據微調模型,涵蓋各種任務和領域,如數學、編程、邏輯推理和 STEM 問題,這個過程旨在使模型具備基本的推理能力。第二階段專注于擴大強化學習的計算資源,利用基于規則的獎勵來增強模型的探索和利用能力。第三階段,在一份包括長思維鏈數據和常用的指令微調數據的組合數據上對模型進行微調,將非思考模式整合到思考模型中,確保了推理和快速響應能力的無縫結合。最后,在第四階段,將強化學習應用于超過 20 個通用領域任務,包括指令遵循、格式遵循和 Agent 能力等任務,以進一步增強模型的一般能力并糾正不良行為 。通過這樣系統且精細的訓練流程,Qwen3 在性能上實現了質的飛躍。
五、開源與應用:推動大模型生態發展
阿里巴巴開源了 Qwen3 的全部 8 個模型版本,包括 2 款 MoE 模型(Qwen3 - 235B - A22B 和 Qwen3 - 30B - A3B)以及 6 款 Dense 模型(Qwen3 - 0.6B、1.7B、4B、8B、14B、32B) 。Qwen3 系列模型均采用寬松的 Apache 2.0 協議開源,全球開發者可在 Hugging Face、ModelScope 等平臺免費下載商用。這一開源舉措無疑將極大地推動大模型技術的發展,吸引全球開發者基于 Qwen3 進行二次開發和創新應用。阿里還同步推出 Qwen - Agent 框架,封裝工具調用模板,降低智能體開發門檻,推動 “模型即服務” 生態落地。在實際應用方面,Qwen3 的多語言支持和強大的推理能力使其在多個領域具有廣闊的應用前景。在金融領域,可基于 Qwen3 - 32B 構建智能投研系統,幫助分析師快速分析市場數據、挖掘投資機會;在教育領域,可用 4B 模型開發個性化學習助手,根據學生的學習情況和問題提供精準的解答和學習建議。
Qwen3 來了!
(文末有下載方式))
)

)





)

)

)





】(將三個模板放在同一個命名空間就實現 list 啦))