kafka與flume的整合
?前期配置完畢,開啟集群
需求1:
利用flume監控某目錄中新生成的文件,將監控到的變更數據發送給kafka,kafka將收到的數據打印到控制臺(三個node01中運行)
1.在kafka中建立topic
kafka-topics.sh --create --zookeeper node01:2181,node02:2181,node03:2181 --topic testTopic --partitions 3 --replication-factor 3

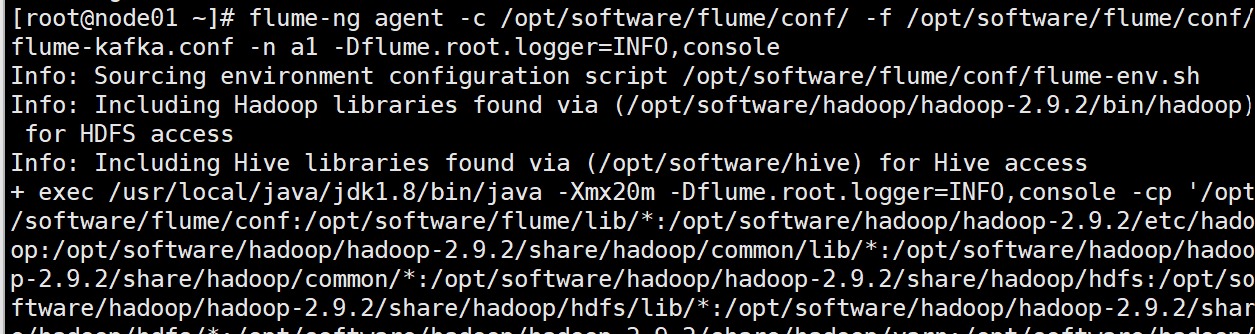
2.啟動flume(第一個nide01)
flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/flume-kafka.conf -n a1
3.啟動kafka消費者(第二個node01)
kafka-console-consumer.sh --topic testTopic --bootstrap-server node01:9092,node02:9092,node03:9092 --from-beginning

4.測試(第三個node01)
進入到指定路徑下(cd /root/flume-kafka/),輸入測試數據
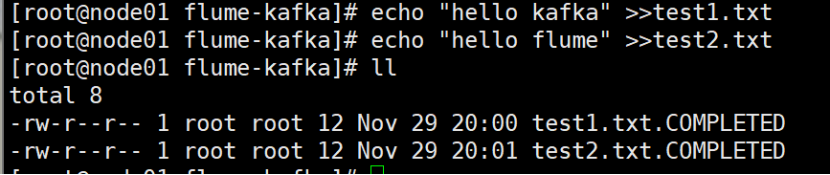
返回到kafka消費者,可以看到數據產生

需求2:
Kafka生產者生成的數據利用Flume進行采集,將采集到的數據打印到Flume的控制臺上
1.啟動kafka生產者
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic testTopic
2.啟動flume
flume-ng agent -c /opt/software/flume/conf/ -f /opt/software/flume/conf/kafka-flume.conf -n a1 -Dflume.root.logger=INFO,console
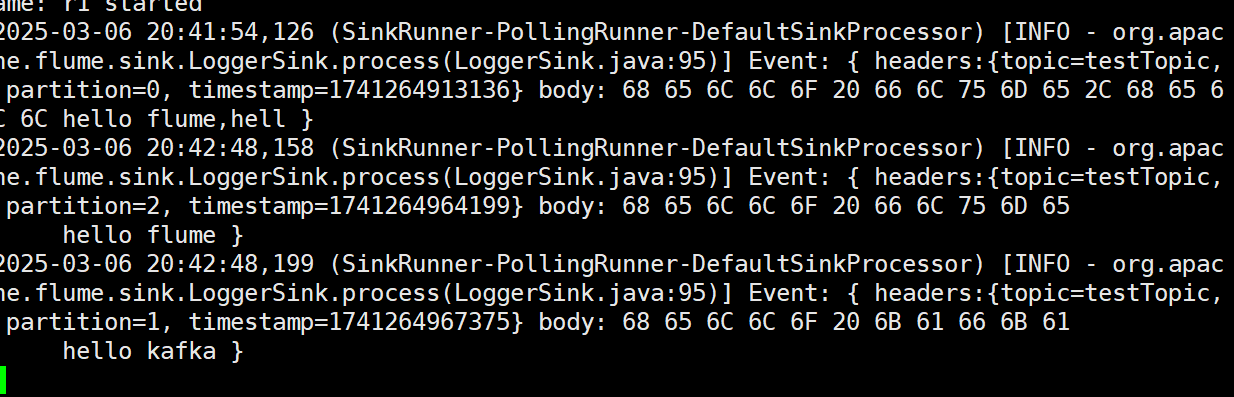
3.在生產者中寫入數據

4.在flume中采集到數據
spark-streaming
DStream轉換
DStream 上的操作與 RDD 的類似,分為 Transformations(轉換)和 Output Operations(輸出)兩種
Transform
Transform 允許 DStream 上執行任意的 RDD-to-RDD 函數。即使這些函數并沒有在 DStream的?API 中暴露出來,通過該函數可以方便的擴展 Spark API。該函數每一批次調度一次。其實也就是對?DStream 中的 RDD 應用轉換。
idea中的
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
// 導入 RDD 類型
import org.apache.spark.rdd.RDDobject Transform {def main(args: Array[String]): Unit = {val sparkConf = new SparkConf().setMaster("local[*]").setAppName("transform")val ssc = new StreamingContext(sparkConf, Seconds(3))val lineDStream: ReceiverInputDStream[String] = ssc.socketTextStream("node01", 9999)val wordAndCountDStream: DStream[(String, Int)] = lineDStream.transform(rdd => {val words: RDD[String] = rdd.flatMap(_.split(" "))val wordAndOne: RDD[(String, Int)] = words.map((_, 1))val value: RDD[(String, Int)] = wordAndOne.reduceByKey(_ + _)value})wordAndCountDStream.print()ssc.start()ssc.awaitTermination()}
}虛擬機中的

join
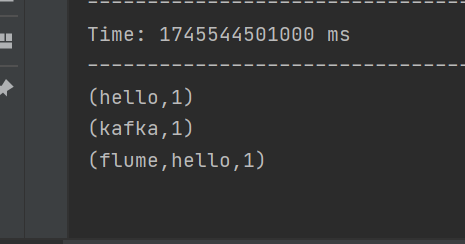
兩個流之間的?join 需要兩個流的批次大小一致,這樣才能做到同時觸發計算。計算過程就是對當前批次的兩個流中各自的?RDD 進行 join,與兩個 RDD 的 join 效果相同
idea中的
import org.apache.spark.SparkConf
import org.apache.spark.streaming.{Seconds, StreamingContext}
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
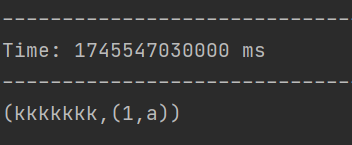
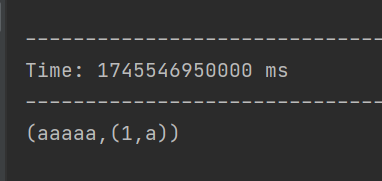
import org.apache.spark.rdd.RDDobject join {def main(args: Array[String]): Unit = {// 創建 SparkConf 對象,設置運行模式為本地多線程,應用名為 joinval sparkConf = new SparkConf().setMaster("local[*]").setAppName("join")// 創建 StreamingContext 對象,設置批處理間隔為 3 秒val ssc = new StreamingContext(sparkConf, Seconds(3))// 從 node01 的 9999 端口接收文本流val lineDStream1: ReceiverInputDStream[String] = ssc.socketTextStream("node01", 9999)// 從 node02 的 8888 端口接收文本流val lineDStream2: ReceiverInputDStream[String] = ssc.socketTextStream("node02", 8888)// 將 lineDStream1 中的每行文本拆分為單詞,并映射為 (單詞, 1) 的鍵值對val wordToOneDStream: DStream[(String, Int)] = lineDStream1.flatMap(_.split(" ")).map((_, 1))// 將 lineDStream2 中的每行文本拆分為單詞,并映射為 (單詞, "a") 的鍵值對val wordToADstream: DStream[(String, String)] = lineDStream2.flatMap(_.split(" ")).map((_, "a"))// 對兩個 DStream 進行 join 操作,結果為 (單詞, (1, "a")) 的鍵值對val joinDStream: DStream[(String, (Int, String))] = wordToOneDStream.join(wordToADstream)// 打印 join 操作后的結果joinDStream.print()// 啟動 StreamingContextssc.start()// 等待計算終止ssc.awaitTermination()}
}
虛擬機中的
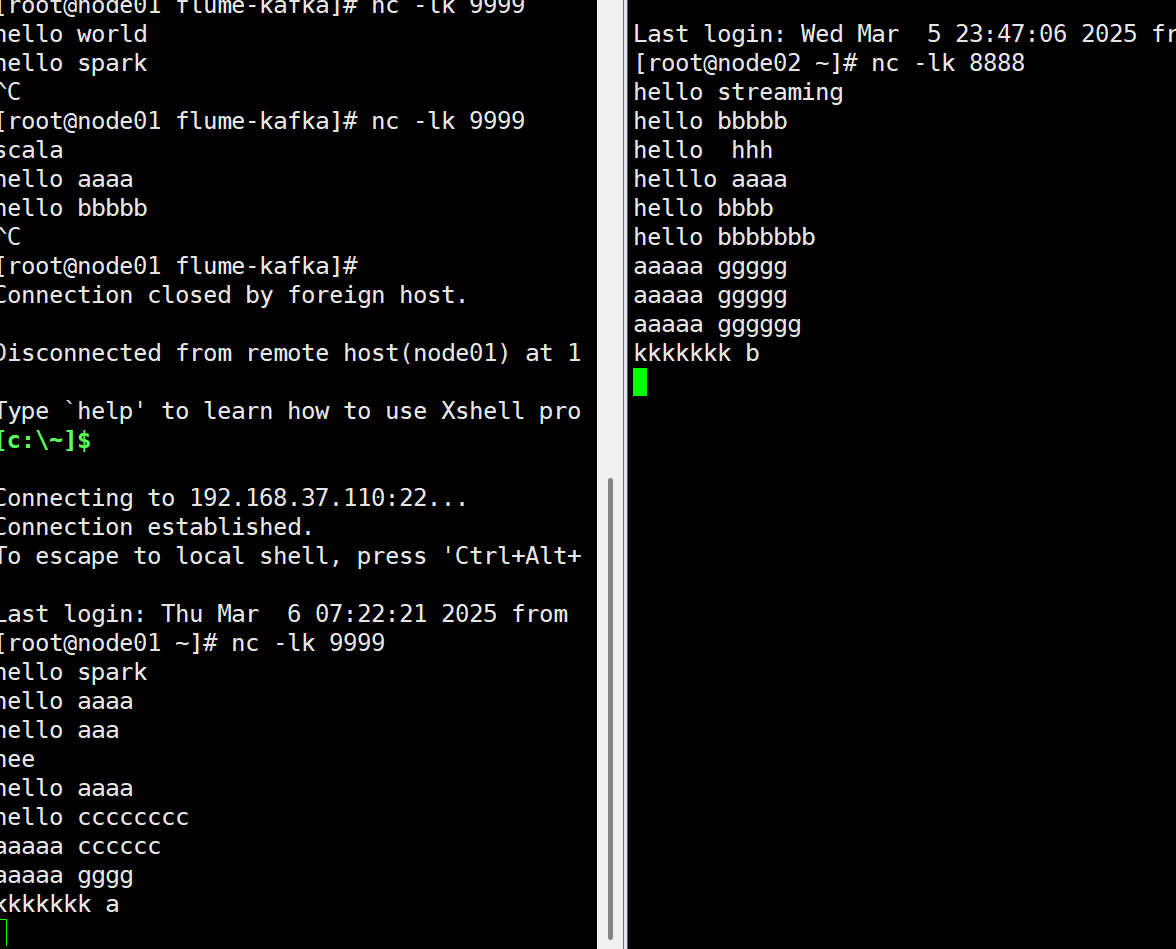
node01
????????nc -lk 9999
node02
????????nc -lk 8888

的使用)

)
機器學習---聚類與K-means)
)

)







(?????? 重點章節!!!))
 加速python數據分析腳本)


