一、部署思路
1、前期設想
zookeeper集群至少需要運行3個pod集群才能夠正常運行,考慮到節點會有故障的風險這個3個pod最好分別運行在3個不同的節點上(為了實現這一需要用到親和性和反親和性概念),在部署的時候對zookeeper運行的pod打標簽加入app=zk,那么假設當zookeeper-1在node1節點上運行,那么zookeeper-2部署的時候發現node1節點上已經存在app=zk標簽就不會在再node1節點上運行(這里可能會用到硬策略 +親和性(NotIn)或者硬策略+反親和性(In))來實現。3個pod至少需要3臺機器而實驗環境只用3臺機器(一臺master節點和2臺node節點),因為污點原因master節點不參與集群節點的調度工作,所以為了完成部署可能需要引入污點與容忍概念。
2、實現思路
1、創建一個service類型的無頭服務zk-headless(因為zookeeper集群服務可能會進行銷毀創建IP不固定,所以zookeeper配置文件中不能配置IP,所以要創建一個clusterIP: None的service表示不分配ip,通過域名進行訪問)
產生的域名格式:<pod-name>.<service-name>.<namespace>.svc.cluster.local。
2、要創建一個zookeeper集群配置清單(將上述的生成的域名寫入到配置中)。
3、創建PodDisruptionBudget確保集群正常可用。
4、創建StatefulSet有狀態服務(綁定上述的無頭服務serviceName: zk-headless)配置親和性或污點容忍策略。
5、創建一個NodePort類型的service用于外部連接測試使用。
二、部署 zookeeper集群
(一)、zookeeper pod部署
1、將master上的污點設置為:PreferNoSchedule
表示 k8s 將盡量避免將 Pod 調度到具有該污點的 Node 上
#將污點設置為PreferNoSchedule表示 k8s 將盡量避免將 Pod 調度到具有該污點的 Node 上
kubectl taint node master node-role.kubernetes.io/master:PreferNoSchedule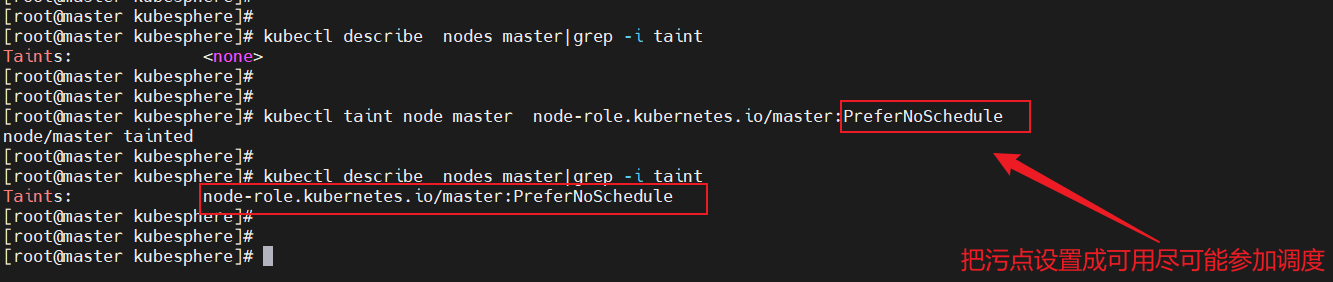
?2、創建PodDisruptionBudget資源對象
2.1、PodDisruptionBudget資源對象簡介
在 Kubernetes(K8s)里,
PodDisruptionBudget(PDB)是一種非常重要的資源對象,它主要用于保障應用的高可用性,避免因計劃內的中斷(比如節點維護、集群升級等)而導致過多的 Pod 同時被終止。下面為你詳細介紹?PodDisruptionBudget。2.1.1、核心作用
在 Kubernetes 集群中,計劃內的中斷事件是難以避免的,像節點維護、節點升級、節點驅逐等操作都可能導致 Pod 被終止。
PodDisruptionBudget?的作用就是對這些計劃內中斷進行管控,確保在任何時候都有足夠數量的 Pod 處于運行狀態,從而保障應用的正常運行和服務的穩定性。2.1.2、關鍵概念
minAvailable:該參數規定了在計劃內中斷期間,必須保持運行的最小 Pod 數量或者比例。例如,設置?minAvailable: 3?表示至少要有 3 個 Pod 處于運行狀態;設置?minAvailable: 50%?則意味著至少要有一半的 Pod 保持運行。maxUnavailable:此參數定義了在計劃內中斷期間,允許不可用的最大 Pod 數量或者比例。例如,設置?maxUnavailable: 2?表示最多允許 2 個 Pod 不可用;設置?maxUnavailable: 25%?則表示最多允許 25% 的 Pod 不可用。2.1.3、配置示例
以下是一個?
PodDisruptionBudget?的 YAML 配置示例:pod-disruption-budget-examplePodDisruptionBudget 配置示例
V1
生成 pod-disruption-budget.yaml
2.1.4、配置解釋
apiVersion:指定使用的 Kubernetes API 版本,這里使用的是?policy/v1。kind:表明資源對象的類型為?PodDisruptionBudget。metadata:包含資源對象的元數據,name?為該?PodDisruptionBudget?的名稱。spec:定義了?PodDisruptionBudget?的具體規格。
minAvailable:設置為 2,表示在計劃內中斷期間,至少要有 2 個帶有?app: my-app?標簽的 Pod 保持運行狀態。selector:用于篩選要應用該?PodDisruptionBudget?的 Pod,這里通過?matchLabels?選擇帶有?app: my-app?標簽的 Pod。2.1.5、工作機制
當計劃內中斷事件發生時,Kubernetes 會檢查?
PodDisruptionBudget?的規則。如果中斷操作會導致不符合?minAvailable?或?maxUnavailable?的要求,那么該操作將會被阻止,直到滿足?PodDisruptionBudget?的條件為止。2.1.6、使用場景
- 關鍵業務應用:對于像數據庫、緩存服務這類關鍵業務應用,使用?
PodDisruptionBudget?可以確保在集群維護或升級期間,有足夠數量的 Pod 繼續運行,避免服務中斷。- 多副本應用:對于運行多個副本的應用,
PodDisruptionBudget?可以防止過多的副本同時被終止,保證服務的穩定性和可用性。通過使用?
PodDisruptionBudget,你可以在 Kubernetes 集群中更好地管理計劃內中斷,保障應用的高可用性。分享
如何創建一個PodDisruptionBudget?
查看PodDisruptionBudget的詳細信息。
如何調整PodDisruptionBudget的配置?
2.2、怎樣查看PodDisruptionBudget的apiVersion需要填什么
kubectl explain poddisruptionbudget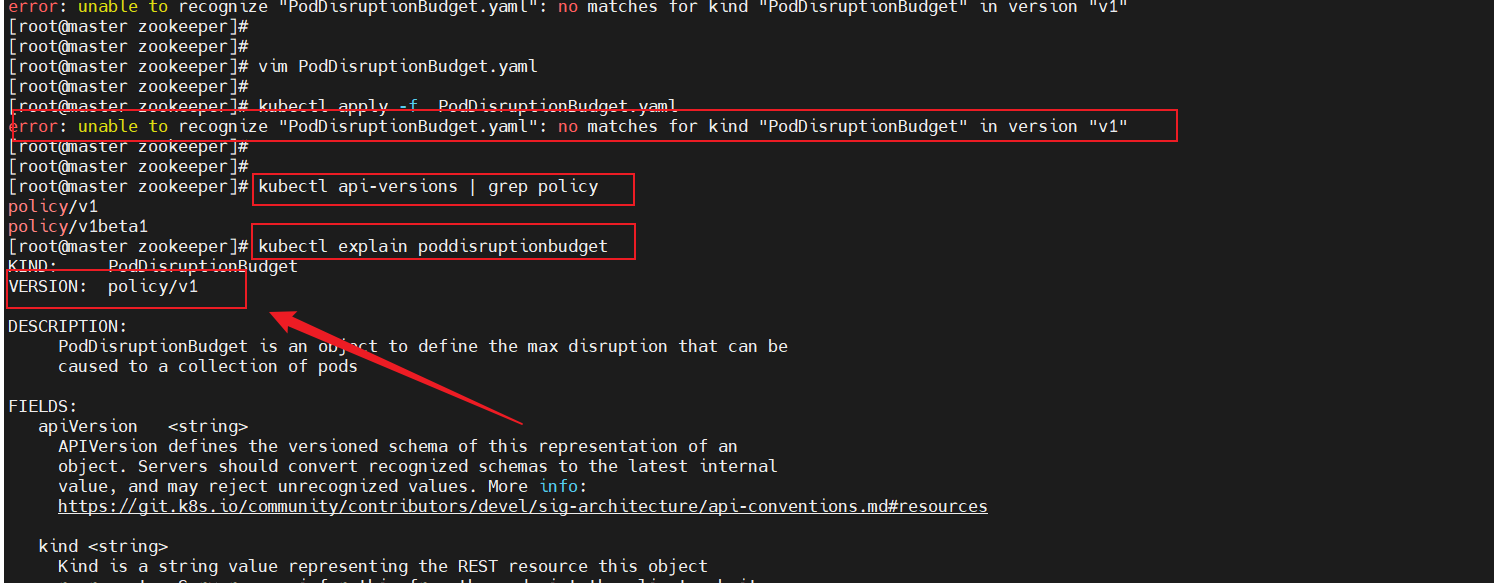
2.3、創建PodDisruptionBudget
apiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zookeepernamespace: kafka
spec:minAvailable: 2selector:matchLabels:app: zookeeper3、創建無頭服務
創建一個名為zk-headless(因為zookeeper集群服務可能會進行銷毀創建IP不固定,所以zookeeper配置文件中不能配置IP,要創建一個clusterIP: None的service表示不分配ip,通過域名進行訪問)。
產生的域名格式:<pod-name>.<service-name>.<namespace>.svc.cluster.local。
apiVersion: v1
kind: Service
metadata:name: zk-headlessnamespace: kafka
spec:clusterIP: None # Headless Service,不分配IPselector:app: zookeeperports:- name: clientport: 2181targetPort: 2181- name: peer-electionport: 3888targetPort: 3888- name: peer-communicationport: 2888targetPort: 28884、創建一個zookeeper集群配置清單
apiVersion: v1
kind: ConfigMap
metadata:name: zoo-confnamespace: kafka
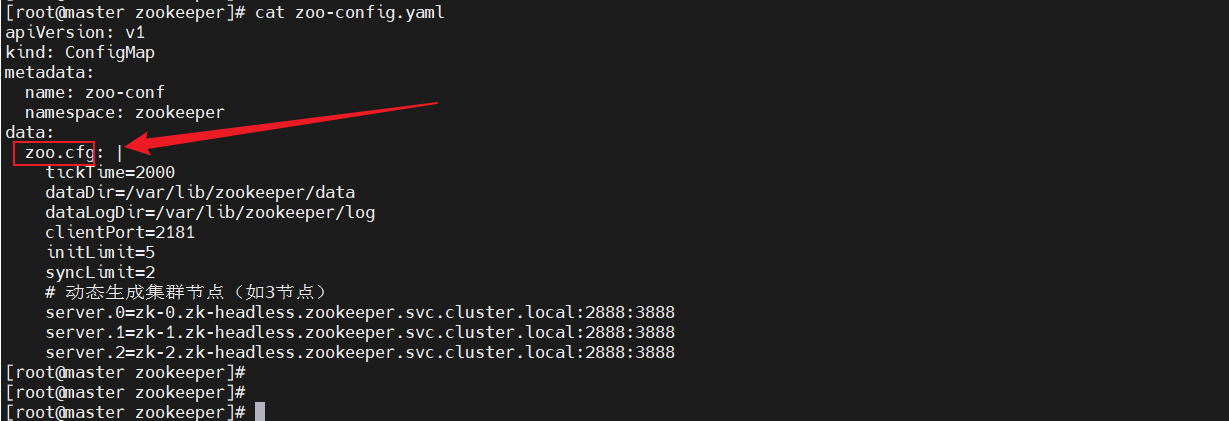
data:zoo.cfg: |tickTime=2000dataDir=/var/lib/zookeeper/datadataLogDir=/var/lib/zookeeper/logclientPort=2181initLimit=5syncLimit=2# 動態生成集群節點(如3節點)server.0=zk-0.zk-headless.kafka.svc.cluster.local:2888:3888server.1=zk-1.zk-headless.kafka.svc.cluster.local:2888:3888server.2=zk-2.zk-headless.kafka.svc.cluster.local:2888:3888
后邊部署的pod名稱是zk是所以這里填入zk-0、zk-1、zk-2 。
5、創建StatefulSet有狀態服務
apiVersion: apps/v1
kind: StatefulSet #部署服務的類型
metadata:name: zknamespace: kafka
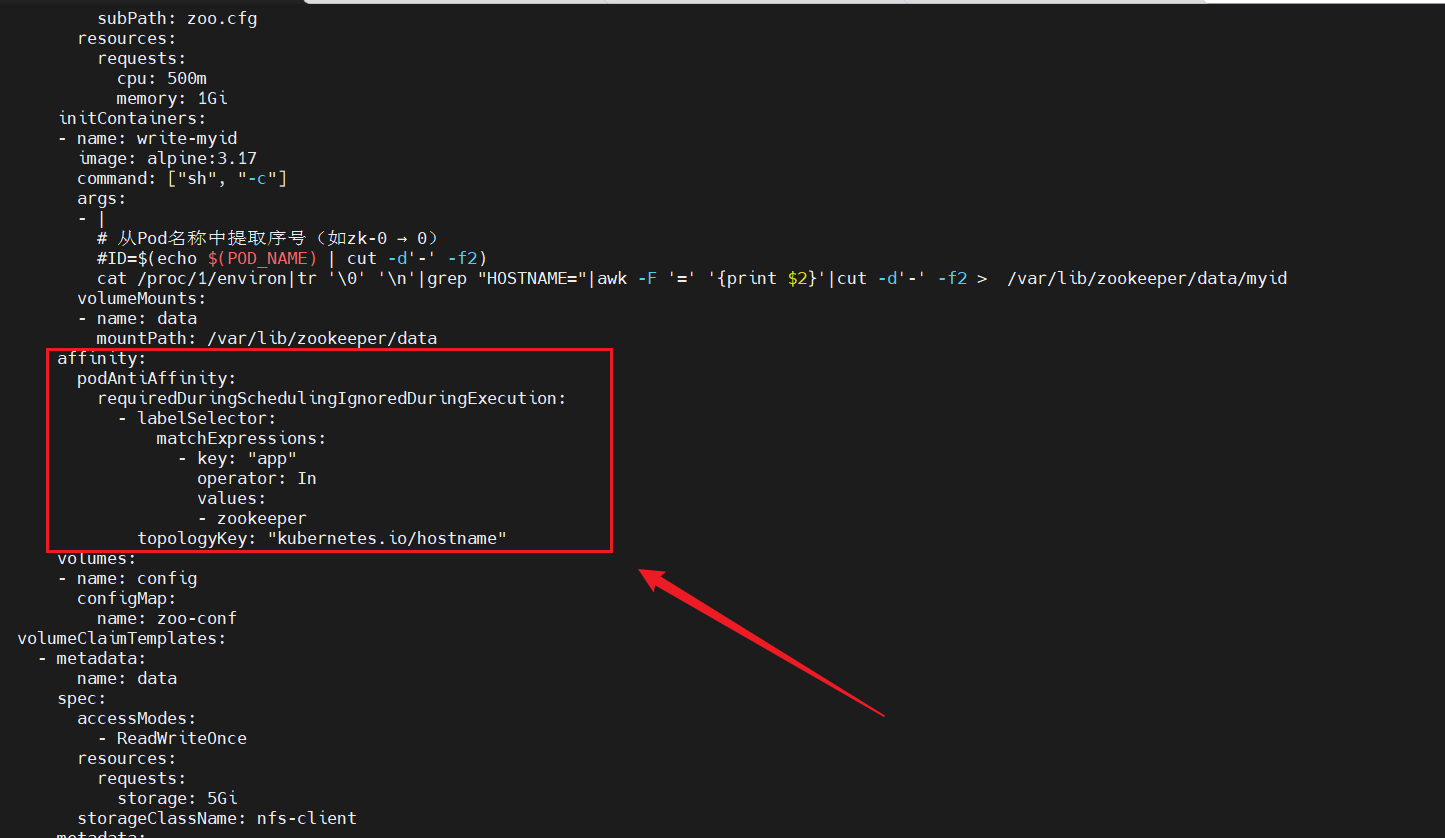
spec:replicas: 3 # 集群節點數selector:matchLabels:app: zookeeperserviceName: zk-headless #綁定的無頭服務名稱template:metadata:labels:app: zookeeperspec:containers:- name: zookeeperimage: zookeeper:3.8.0 # 官方鏡像ports:- containerPort: 2181name: client- containerPort: 3888name: zk-leader- containerPort: 2888name: zk-serverenv:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 獲取Pod名稱(如zk-0)volumeMounts:- name: datamountPath: /var/lib/zookeeper/data- name: logmountPath: /var/lib/zookeeper/log- name: configmountPath: /conf/zoo.cfgsubPath: zoo.cfgresources:requests:cpu: 500mmemory: 1GiinitContainers:- name: write-myidimage: alpine:3.17command: ["sh", "-c"]args:- |# 從Pod名稱中提取序號(如zk-0 → 0)#ID=$(echo $(POD_NAME) | cut -d'-' -f2)cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myidvolumeMounts:- name: datamountPath: /var/lib/zookeeper/dataaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zookeepertopologyKey: "kubernetes.io/hostname"volumes:- name: configconfigMap:name: zoo-confvolumeClaimTemplates:- metadata:name: dataspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client- metadata:name: logspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client
5.1、配置親和性策略
affinity:podAntiAffinity: #反親和requiredDuringSchedulingIgnoredDuringExecution: #硬策略- labelSelector:matchExpressions:- key: "app" #指定key是appoperator: In values:- zookeeper #即匹配app=zookeeper的標簽topologyKey: "kubernetes.io/hostname"
6、創建一個NodePort類型的service用于外部連接測試使用
apiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: kafka
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: NodePort # 如需外部訪問,可改為NodePort或LoadBalancer(二)、部署過程問題排查
1、pod節點沒有創建因為變量命名規則大于15個字符導致報錯問題處理
#查看描述
kubectl get statefulset -n zookeeper
kubectl describe statefulset -n zookeeper zk-cluster | tail -n 10 ?
?
2、配置文件名稱不一致問題處理
kubectl get pod -n zookeeper -w
kubectl describe pod zk-cluster-0 -n zookeeper|tail -n10
kubectl logs zk-cluster-0 -n zookeeper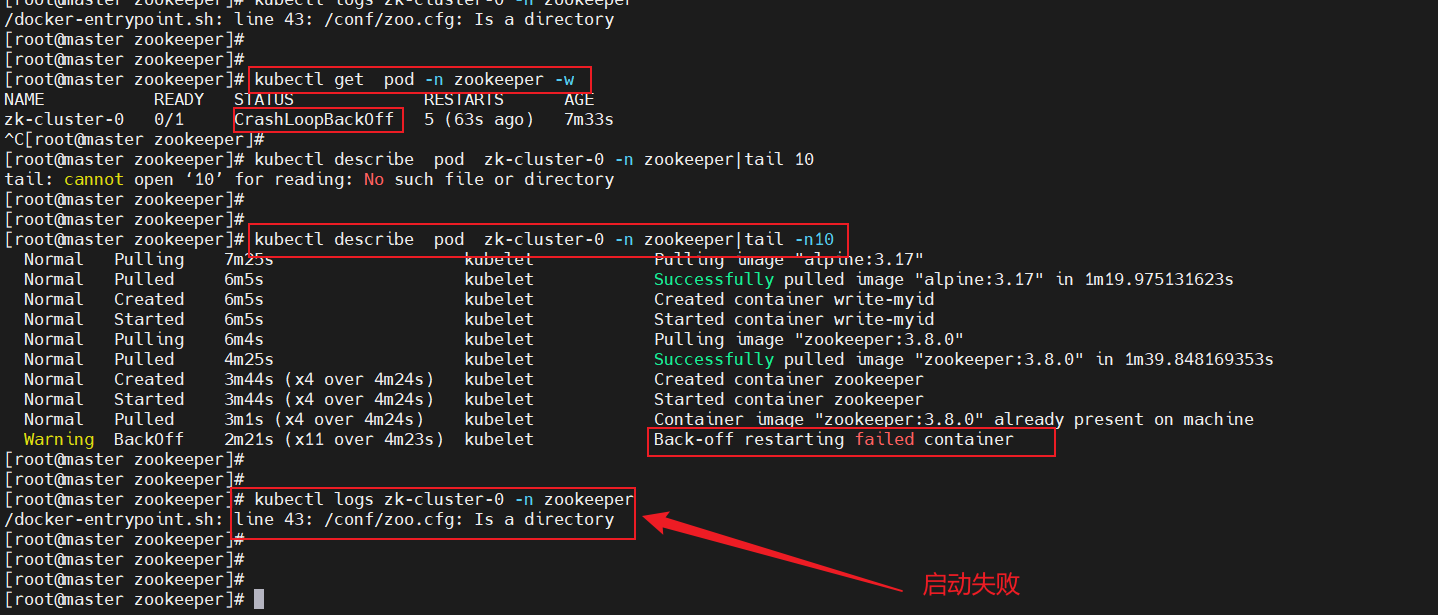
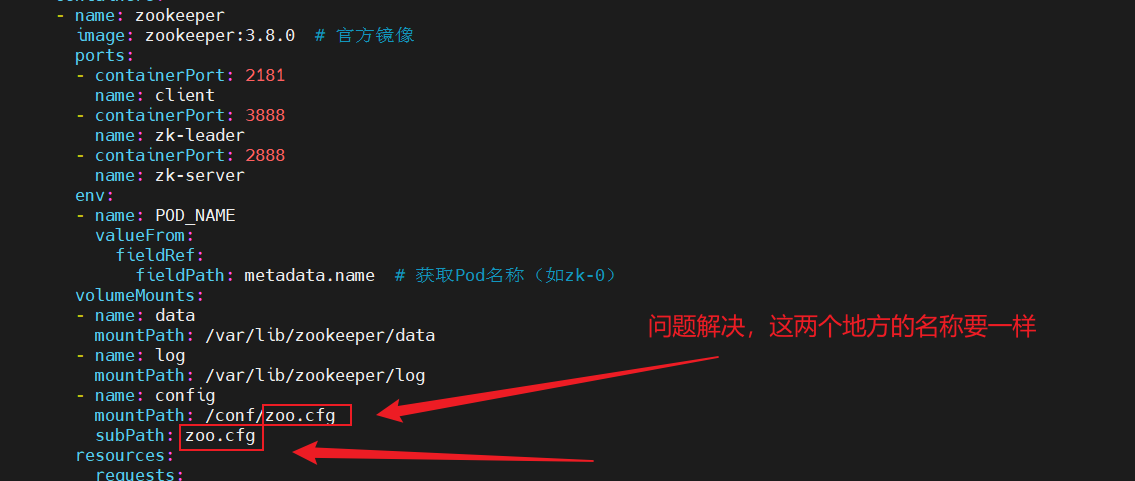
3、statefulset服務將pod信息存儲在/var/lib/kubelet/pods中刪除動態卷下的數據會導致再次部署的時候發生報錯。
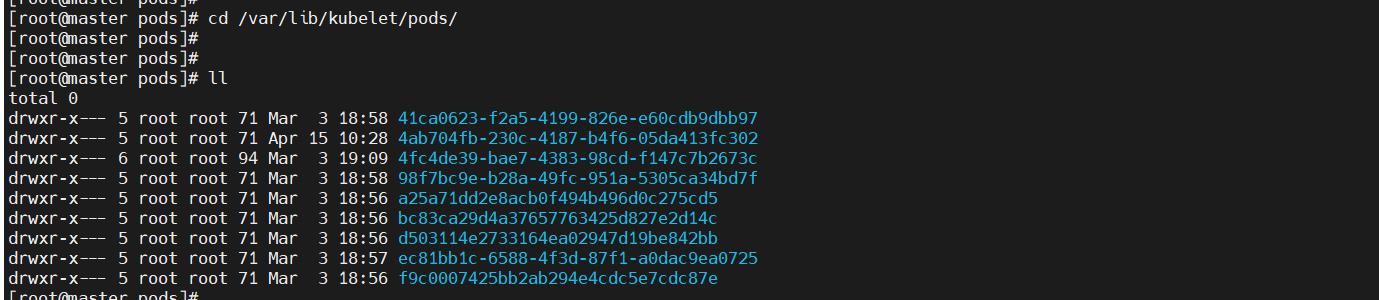
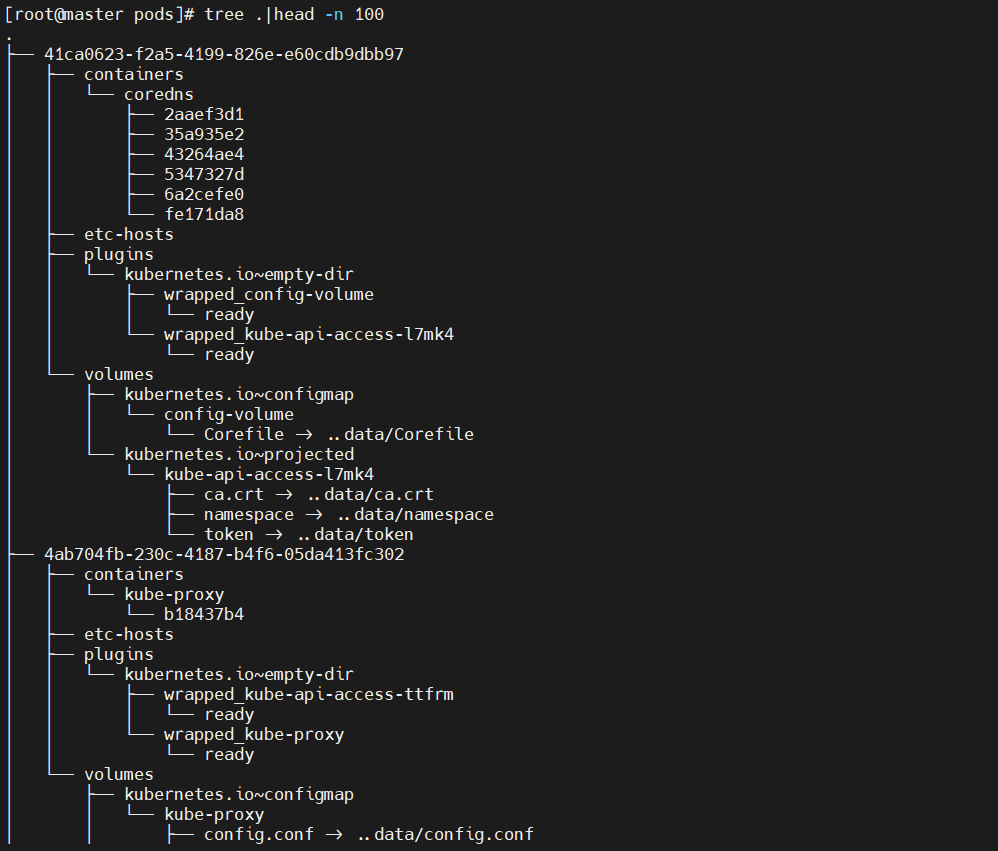
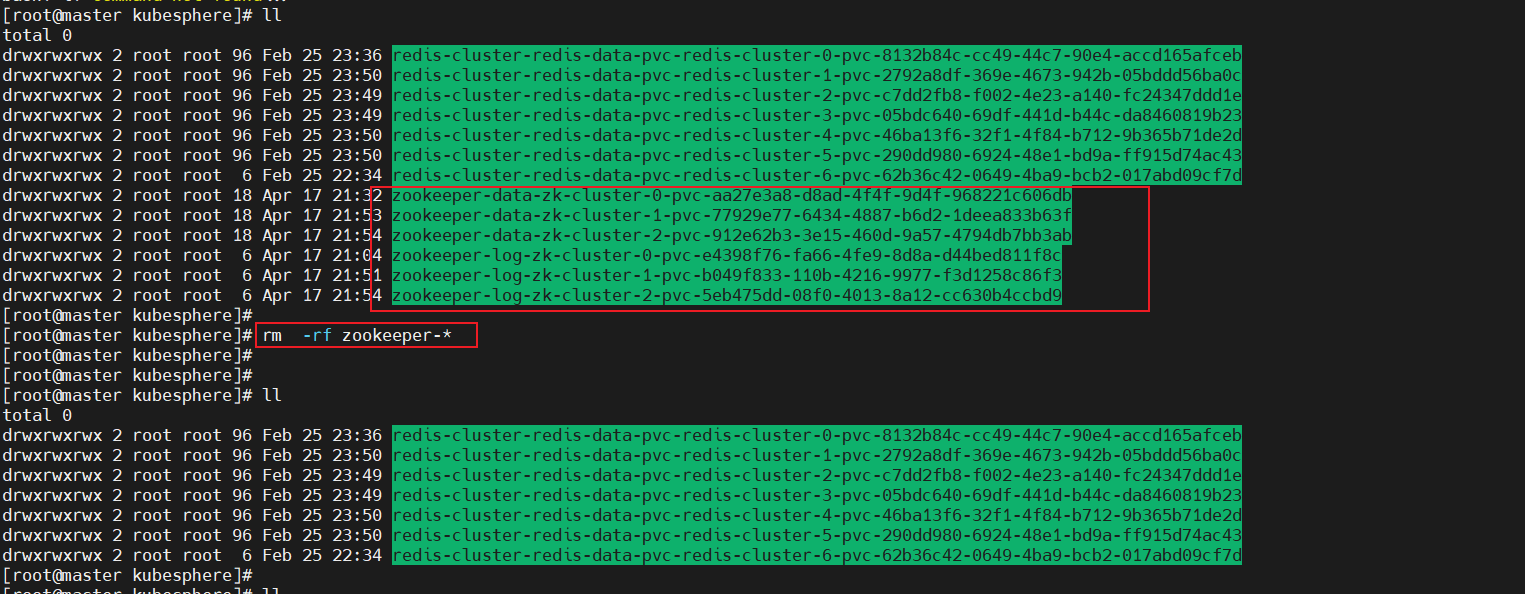 ?報錯:
?報錯:
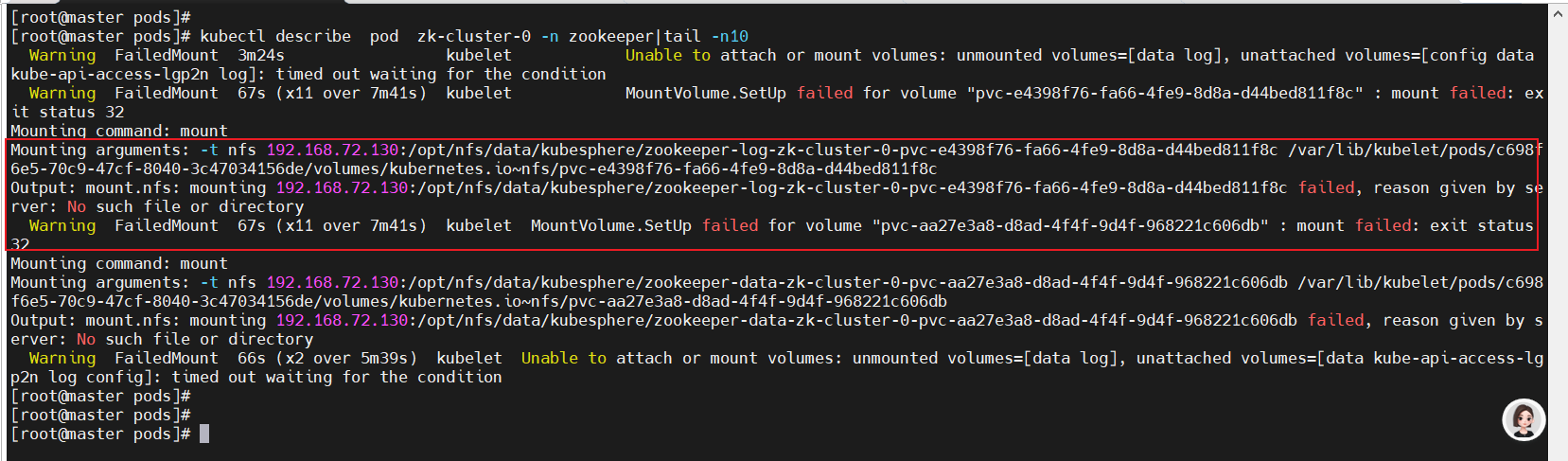
解決:執行kubectl delete -f *yaml 將之前部署到所有yaml清單全部刪除。
4、POD_NAME變量獲取不到問題處理
在部署zookeeper集群時,需要在每個zookeeper節點的myid中填入對應的值,這里直接將POD_NAME變量名后的數字寫入,但是在部署的過程中發現metadata.name值無法獲取,所以在這里使用shell獲取pod名稱編號寫入myid,方法如下:
#在實驗中POD_NAME變量的名稱獲取不到env:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 獲取Pod名稱(如zk-0)#解決方法使用如下命令獲取pod的名稱cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myid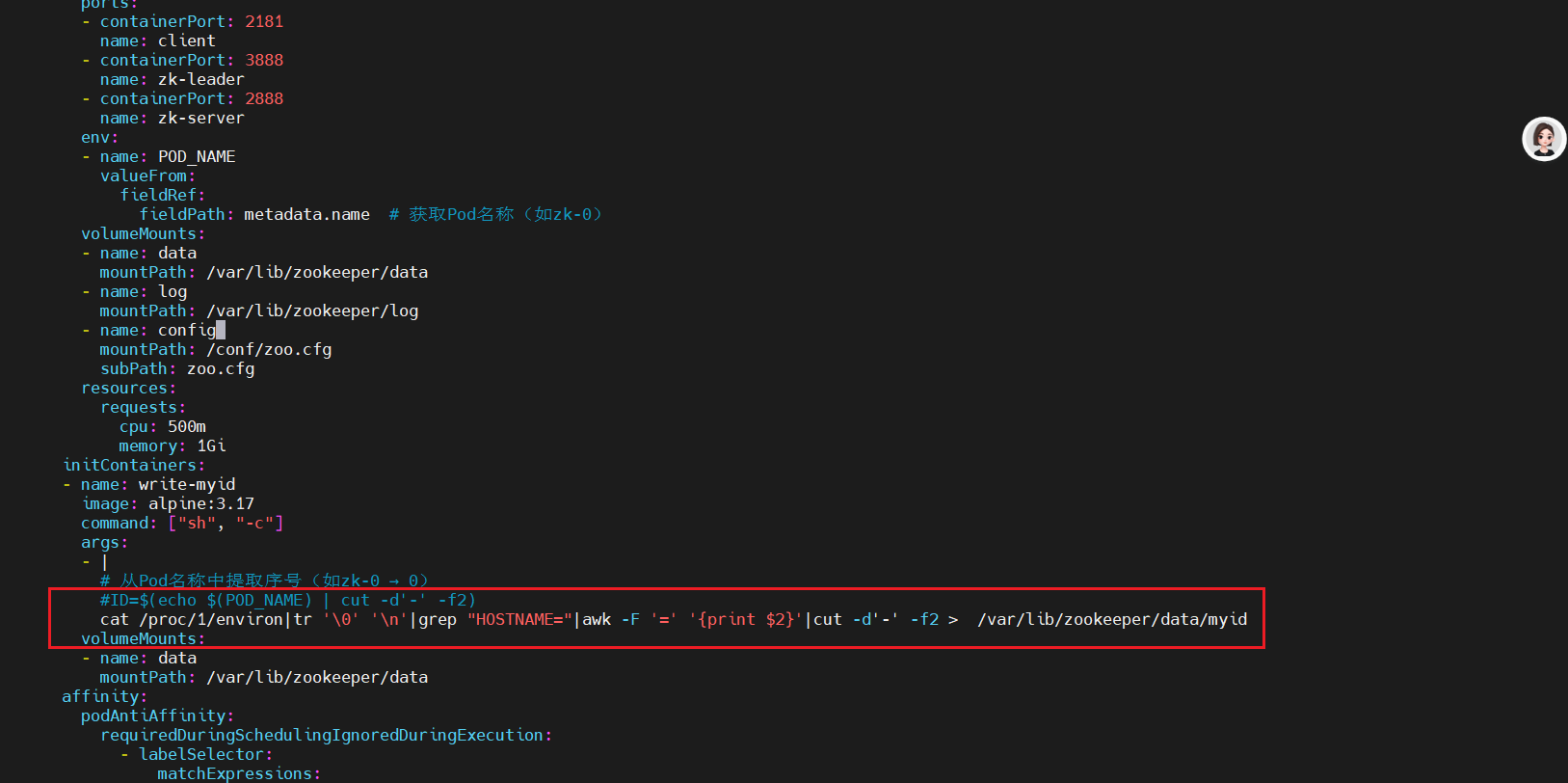
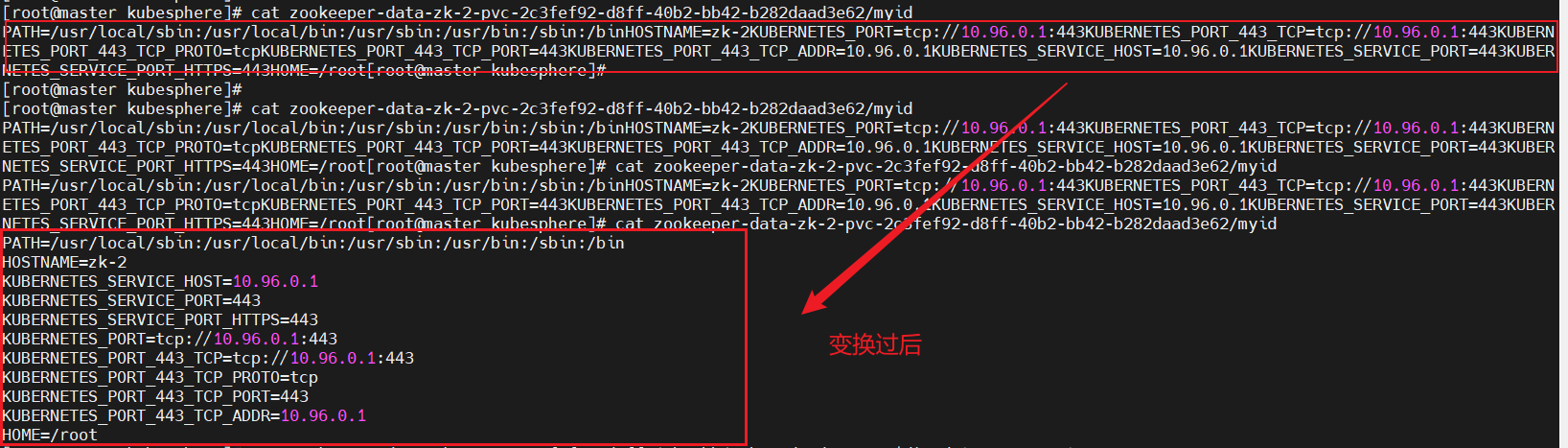
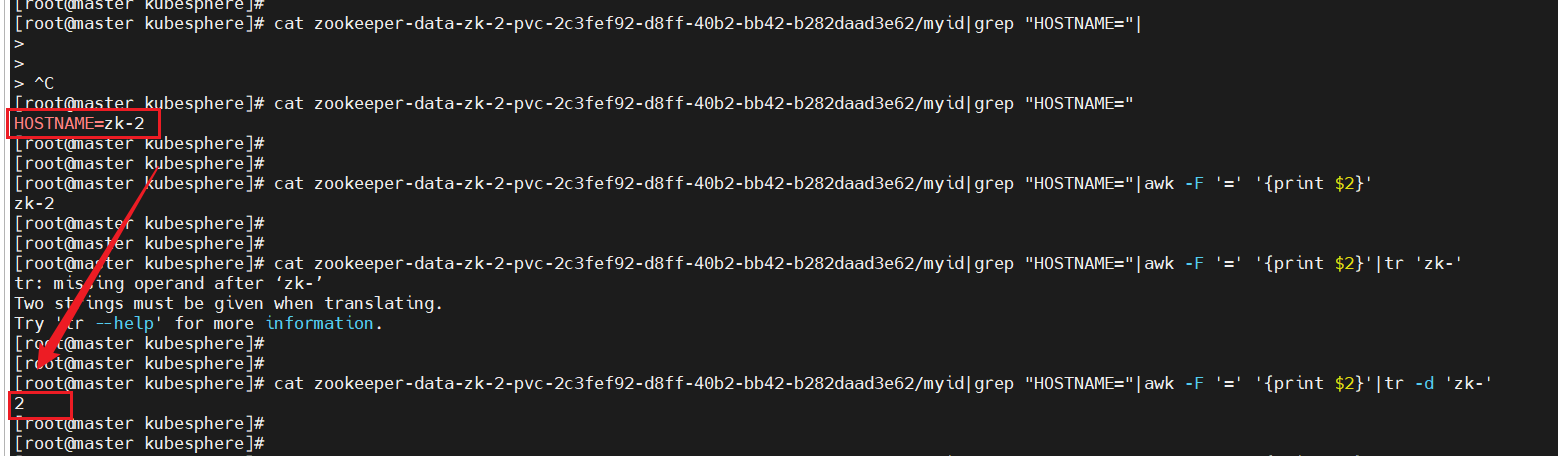 :
:
(三)、完整的zookeeper集群部署流程清單
#創建配置apiVersion: v1
kind: ConfigMap
metadata:name: zoo-confnamespace: zookeeper
data:zoo.cfg: |tickTime=2000dataDir=/var/lib/zookeeper/datadataLogDir=/var/lib/zookeeper/logclientPort=2181initLimit=5syncLimit=2# 動態生成集群節點(如3節點)server.0=zk-0.zk-headless.zookeeper.svc.cluster.local:2888:3888server.1=zk-1.zk-headless.zookeeper.svc.cluster.local:2888:3888server.2=zk-2.zk-headless.zookeeper.svc.cluster.local:2888:3888---
#創建PodDisruptionBudgetapiVersion: policy/v1
kind: PodDisruptionBudget
metadata:name: zookeepernamespace: zookeeper
spec:minAvailable: 2selector:matchLabels:app: zookeeper---
apiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: zookeeper
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: ClusterIP # 如需外部訪問,可改為NodePort或LoadBalancer---#創建無頭服務
apiVersion: v1
kind: Service
metadata:name: zk-headlessnamespace: zookeeper
spec:clusterIP: None # Headless Service,不分配IPselector:app: zookeeperports:- name: clientport: 2181targetPort: 2181- name: peer-electionport: 3888targetPort: 3888- name: peer-communicationport: 2888targetPort: 2888---#創建有狀態副本集apiVersion: apps/v1
kind: StatefulSet
metadata:name: zknamespace: zookeeper
spec:replicas: 3 # 集群節點數selector:matchLabels:app: zookeeperserviceName: zk-headlesstemplate:metadata:labels:app: zookeeperspec:containers:- name: zookeeperimage: zookeeper:3.8.0 # 官方鏡像ports:- containerPort: 2181name: client- containerPort: 3888name: zk-leader- containerPort: 2888name: zk-serverenv:- name: POD_NAMEvalueFrom:fieldRef:fieldPath: metadata.name # 獲取Pod名稱(如zk-0)volumeMounts:- name: datamountPath: /var/lib/zookeeper/data- name: logmountPath: /var/lib/zookeeper/log- name: configmountPath: /conf/zoo.cfgsubPath: zoo.cfgresources:requests:cpu: 500mmemory: 1GiinitContainers:- name: write-myidimage: alpine:3.17command: ["sh", "-c"]args:- |# 從Pod名稱中提取序號(如zk-0 → 0)#ID=$(echo $(POD_NAME) | cut -d'-' -f2)cat /proc/1/environ|tr '\0' '\n'|grep "HOSTNAME="|awk -F '=' '{print $2}'|cut -d'-' -f2 > /var/lib/zookeeper/data/myidvolumeMounts:- name: datamountPath: /var/lib/zookeeper/dataaffinity:podAntiAffinity:requiredDuringSchedulingIgnoredDuringExecution:- labelSelector:matchExpressions:- key: "app"operator: Invalues:- zookeepertopologyKey: "kubernetes.io/hostname"volumes:- name: configconfigMap:name: zoo-confvolumeClaimTemplates:- metadata:name: dataspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client- metadata:name: logspec:accessModes:- ReadWriteOnceresources:requests:storage: 5GistorageClassName: nfs-client---
#創建與外部連接的serviceapiVersion: v1
kind: Service
metadata:name: zk-clientnamespace: zookeeper
spec:selector:app: zookeeperports:- name: clientport: 2181targetPort: 2181type: ClusterIP # 如需外部訪問,可改為NodePort或LoadBalancer
[root@master zookeeper]#
(四)、集群訪問測試
1、查看集群狀態是否正常
#進入集群內部
kubectl exec -it zk-0 -n kafka -- /bin/bash#查看zk-0的狀態
echo srvr|nc zk-0.zk-headless.kafka.svc.cluster.local 2181#查看zk-1的狀態
echo srvr|nc zk-1.zk-headless.kafka.svc.cluster.local 2181#查看zk-2的狀態
echo srvr|nc zk-2.zk-headless.kafka.svc.cluster.local 2181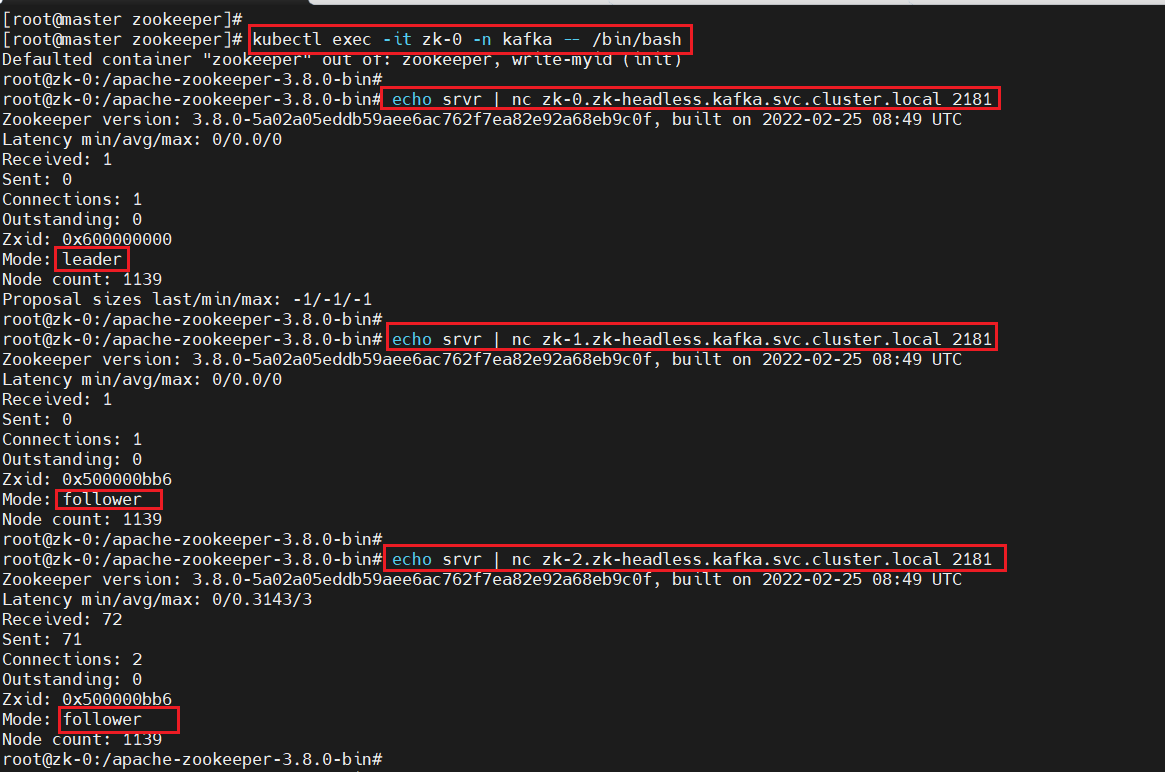
2、在zookeeper集群中寫入數據
編寫python代碼往zookeeper集群中寫入1000個數據
from kazoo.client import KazooClientdef xixi(path, data):hosts = "192.168.72.130:30459"# 創建 KazooClient 實例zk = KazooClient(hosts=hosts)try:# 連接到 ZooKeeper 集群zk.start()print("成功連接到 ZooKeeper 集群")# 要寫入的路徑# path = "/test_node"# # 要寫入的數據# data = b"Hello, ZooKeeper!"# 檢查路徑是否存在,如果不存在則創建if not zk.exists(path):zk.create(path, data)print(f"成功在路徑 {path} 創建節點并寫入數據")else:# 如果節點已存在,更新數據zk.set(path, data)print(f"成功更新路徑 {path} 下的數據")except Exception as e:print(f"發生錯誤: {e}")finally:# 關閉連接if zk.connected:zk.stop()print("已斷開與 ZooKeeper 集群的連接")if __name__ == '__main__':# ZooKeeper 集群地址hosts = "192.168.72.130:30459"# 創建 KazooClient 實例zk = KazooClient(hosts=hosts)for i in range(1,1000):print(i)path = f"/test_{i}"data_1 = f'zookeeper-{i}'data = data_1.encode('utf-8')xixi(path, data)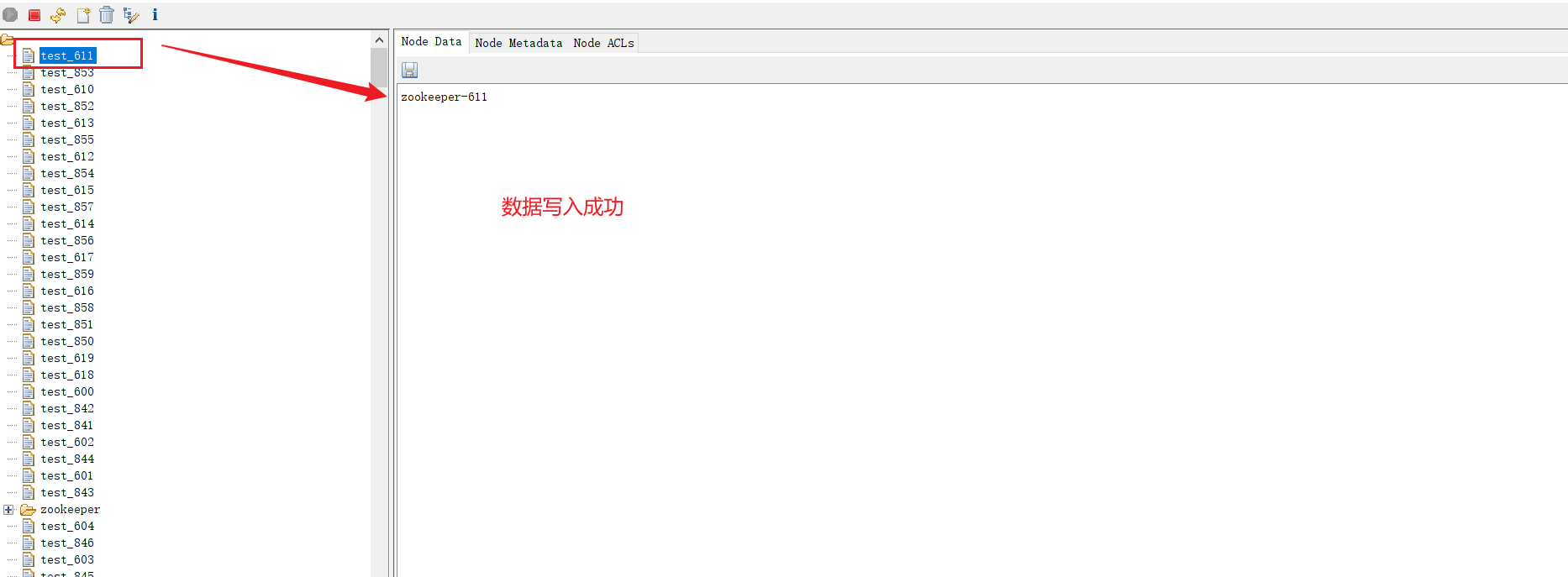
三、污點與容忍
(一)、不設置污點容忍master節點無法參與調度
將master主節點上的污點修改成NoSchedule (修改之后zookeeper pod將不能再調度到master節點上,這意味著剩下兩個節點中的有一個節點要運行兩個pod,而我們在yaml中配置了親和性所以已經存在zookeeper標簽的節點不能再運行,因此3個副本中只有兩個副本是正常的,還有一個處于異常狀態)
為了驗證上述的說法,我開始以下測試
步驟一:將之前部署的zookeeper集群刪除掉(環境清理)
執行腳本:?sh deploy.sh delete
deploy.sh腳本內容如下:
##創建命名空間
#kubectl create namespace zookeeper
#
##根據配置文件創建configmapx
#kubectl create configmap zoo.cfg --from-file=zoo.conf
#
##創建PodDisruptionBudget只能指定集群運行節點的最小數
#kubectl apply -f podDisruptionBudget.yaml
#
##創建一個service使得pod之間產生一個可用互相訪問的域名用于 StatefulSet 的穩定 DNS 解析,格式為 pod-name.service-name.namespace.svc.cluster.local
#
apply ()
{kubectl apply -f podDisruptionBudget.yamlkubectl apply -f zk-client-service.yamlkubectl apply -f zk-headless-service.yamlkubectl apply -f zoo-config.yamlkubectl apply -f zk-statefulset.yaml
}delete ()
{kubectl delete -f podDisruptionBudget.yamlkubectl delete -f zk-client-service.yamlkubectl delete -f zk-headless-service.yamlkubectl delete -f zoo-config.yamlkubectl delete -f zk-statefulset.yaml
}main ()
{case $1 inapply)apply;;delete)deleteesac
}main $1步驟二:將master污點設置成:NoSchedule
#將污點設置為:NoSchedule
kubectl taint node master node-role.kubernetes.io/master:NoSchedule#查看污點是否設置成功
kubectl describe nodes master|grep -i taint
步驟三:執行腳本sh deploy.sh apply (重新部署zookeeper集群)
測試結果:master節點無法參與調度
只有兩個pod成功運行,一個pod處于Pending狀態
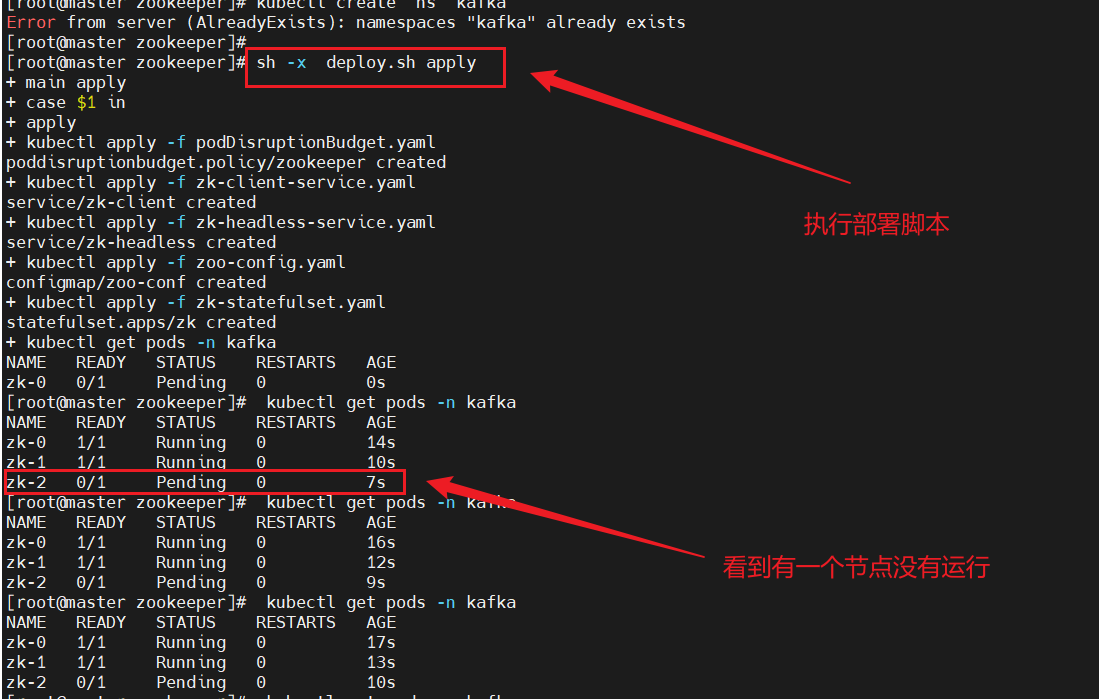
報錯信息與設想的結果一致?
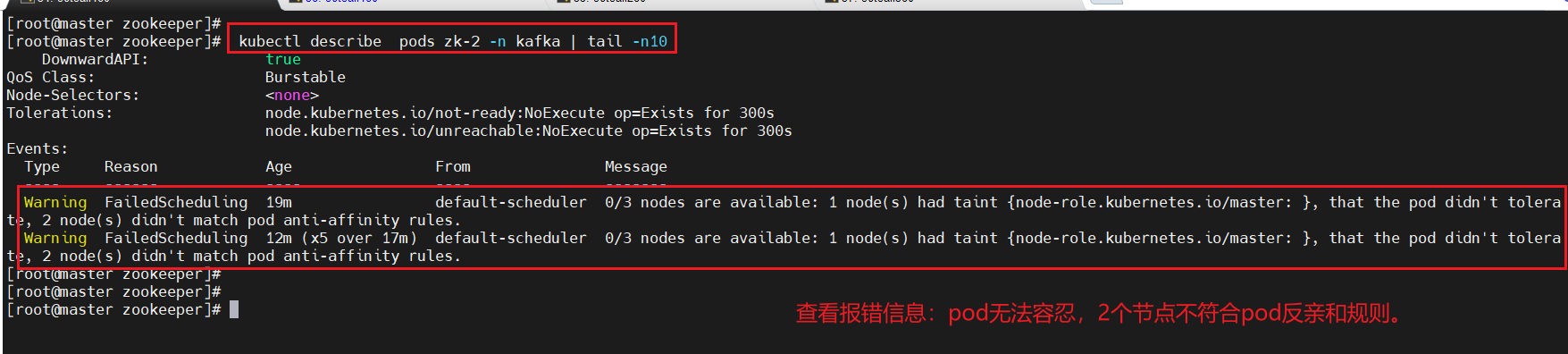

(二)、設置污點容忍master上可以參與調度
假設將zookeeper集群的yaml文件中配置污點容忍,那么master節點也可以參與調度(之前3個副本只能運行兩個,如果添加了污點容忍那么master節點上也可以參與調度,即3個pod都能正常運行)
1、污點容忍配置
在 Kubernetes(k8s)里,污點(Taints)和容忍度(Tolerations)是用來控制 Pod 調度到特定節點的機制。污點應用于節點,而容忍度則設置在 Pod 上,允許 Pod 調度到帶有特定污點的節點。下面詳細介紹如何設置污點和容忍度。
1.1. 設置節點污點
可以使用?
kubectl taint?命令為節點添加污點。污點的格式為?key=value:effect,其中?effect?有三種類型:
NoSchedule:新的 Pod 不會被調度到帶有該污點的節點,但已在該節點上運行的 Pod 不受影響。PreferNoSchedule:系統會盡量避免將新的 Pod 調度到帶有該污點的節點,但不是強制的。NoExecute:新的 Pod 不會被調度到帶有該污點的節點,并且如果已在該節點上運行的 Pod 沒有相應的容忍度,它們會被驅逐。以下是添加污點的示例命令:
# 添加一個 NoSchedule 類型的污點 kubectl taint nodes <node-name> key1=value1:NoSchedule# 添加一個 PreferNoSchedule 類型的污點 kubectl taint nodes <node-name> key2=value2:PreferNoSchedule# 添加一個 NoExecute 類型的污點 kubectl taint nodes <node-name> key3=value3:NoExecute要將?
<node-name>?替換成實際的節點名稱。1.2. 刪除節點污點
若要刪除節點上的污點,可以使用以下命令:
kubectl taint nodes <node-name> key1:NoSchedule-這里的?
-?表示刪除該污點。1.3. 設置 Pod 容忍度
在 Pod 的 YAML 文件中添加容忍度設置,以下是一個示例:
pod-with-tolerations帶有容忍度設置的 Pod YAML 文件
生成 pod-with-tolerations.yaml
apiVersion: v1 kind: Pod metadata:name: pod-with-tolerations spec:containers:- name: nginximage: nginx:1.14.2ports:- containerPort: 80tolerations:- key: "key1"operator: "Equal"value: "value1"effect: "NoSchedule"- key: "key2"operator: "Equal"value: "value2"effect: "PreferNoSchedule"- key: "key3"operator: "Equal"value: "value3"effect: "NoExecute"tolerationSeconds: 3600 # 表示在節點添加該污點后,Pod 還能繼續運行 3600 秒在這個示例中:
key:對應節點上污點的鍵。operator:有?Equal?和?Exists?兩種取值。Equal?表示容忍度的?key?和?value?必須與污點的?key?和?value?完全匹配;Exists?表示只要節點上存在該?key?的污點,不管?value?是什么,都能容忍。value:對應節點上污點的值。effect:對應節點上污點的效果。tolerationSeconds:僅在?effect?為?NoExecute?時有效,表示在節點添加該污點后,Pod 還能繼續運行的時間。1.4. 部署帶有容忍度的 Pod
將上述 YAML 文件保存為?
pod-with-tolerations.yaml,然后使用以下命令部署 Pod:kubectl apply -f pod-with-tolerations.yaml通過上述步驟,你就可以設置節點的污點和 Pod 的容忍度,從而控制 Pod 的調度。
2、在zookeeper部署的yaml中配置污點容忍
步驟一:查看污點所對應的key值
#查看污點所對應的key
kubectl get nodes master -o yaml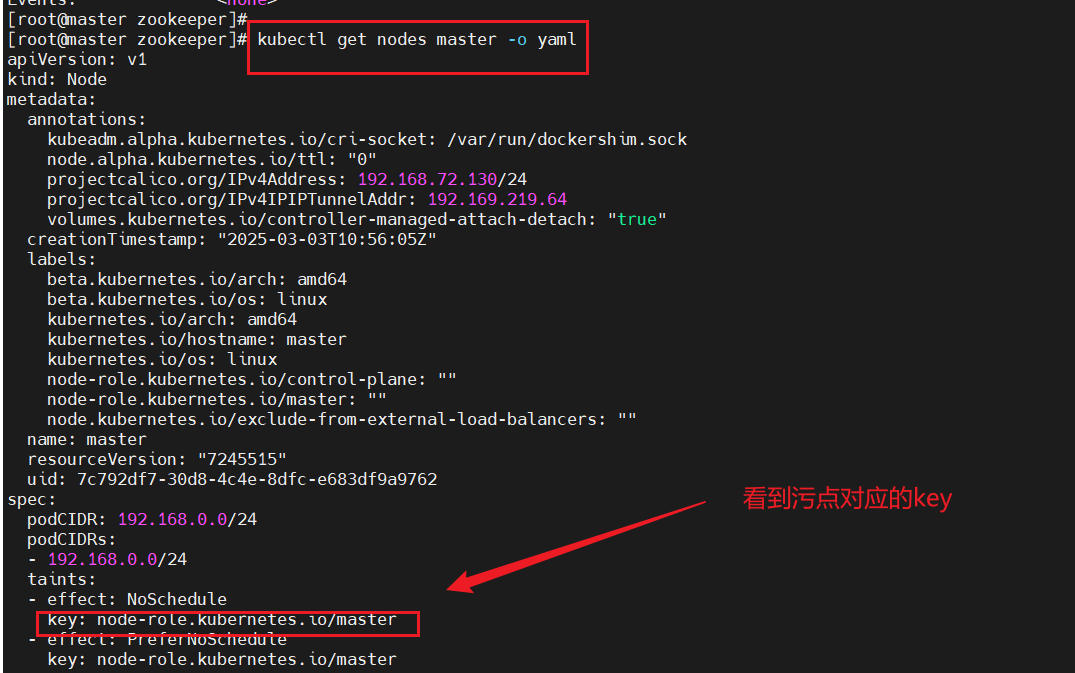
步驟二:在yaml中加入污點容忍
#在pod的spec下加入tolerations:- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "NoSchedule"- key: "node-role.kubernetes.io/master"operator: "Exists"effect: "PreferNoSchedule"
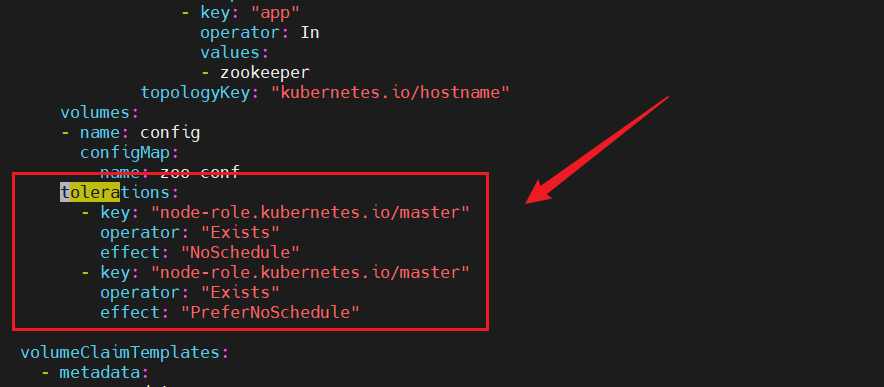
步驟三:部署3個pod的zookeeper集群
sh -x deploy.sh apply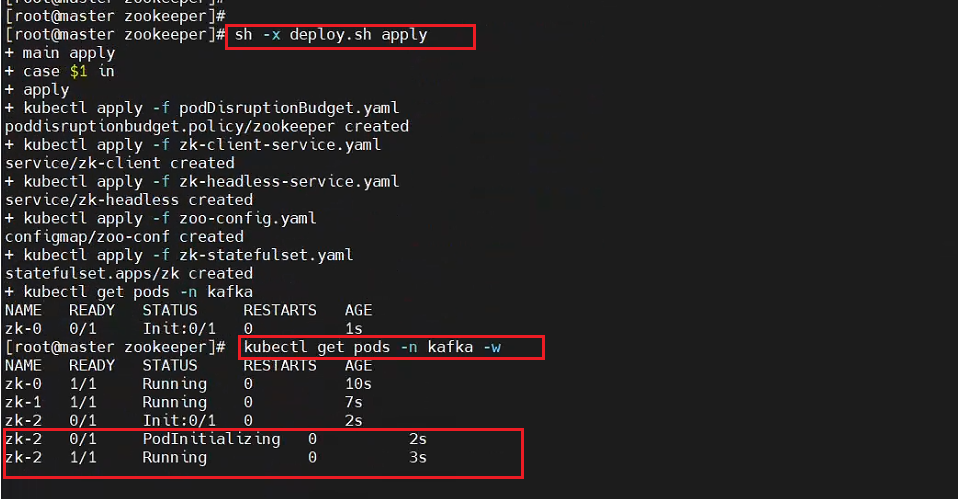
測試結果:master節點參與調度,污點容忍策略生效

參考博客鏈接:k8s設置容器環境變量&service服務無法獲取到環境變量的解決方法_yaml <podname> 變量-CSDN博客






:人工智能與數學)



)





)


