?? ? 在人工智能領域,數學是不可或缺的基石。無論是算法的設計、模型的訓練還是結果的評估,都離不開數學的支持。接下來,我將帶大家深入了解人工智能數學基礎,包括微積分、線性代數、概率論、數理統計和最優化理論,并通過 Python 代碼示例,讓大家更加直觀地理解這些數學知識在人工智能中的應用。資源綁定附上完整資源供讀者參考學習!
1.1 微積分
? ?微積分是研究函數的微分、積分以及有關概念和應用的數學分支,在人工智能中有著廣泛的應用,如神經網絡的梯度下降法等優化算法就離不開微積分。
基本概念
-
導數 :表示函數在某一點處的變化率。例如,函數 y = f(x),導數 f’(x) 表示 x 變化時 y 的變化速度。
-
積分 :用于計算曲線與坐標軸之間的面積或體積等。例如,計算函數 y = f(x) 在區間 [a, b] 上與 x 軸圍成的面積。
在人工智能算法中的應用
-
梯度下降法 :這是機器學習中常用的一種優化算法,通過計算損失函數對模型參數的導數(即梯度),不斷調整參數,使損失函數最小化。在神經網絡訓練中,梯度下降法用于更新神經元的權重,以提高模型的準確性。
Python 求解示例
計算函數 y = x^3 - 2x^2 + 3x - 4 的導數,并繪制函數圖像及其導數圖像。
?
import numpy as np
import matplotlib.pyplot as plt
from sympy import symbols, diffplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 定義變量和函數
x = symbols('x')
y = x**3 - 2*x**2 + 3*x -4# 計算導數
dy_dx = diff(y, x)
print("導數為:", dy_dx)# 繪制函數圖像及其導數圖像
x_vals = np.linspace(-10, 10, 400)
y_vals = [val**3 - 2*val**2 + 3*val -4 for val in x_vals]
dy_dx_vals = [3*val**2 -4*val +3 for val in x_vals]plt.figure(figsize=(10, 6))
plt.plot(x_vals, y_vals, label='y = x^3 - 2x^2 + 3x -4')
plt.plot(x_vals, dy_dx_vals, label="導數:3x^2 -4x +3", linestyle='--')
plt.xlabel('x')
plt.ylabel('y')
plt.title('函數及其導數圖像')
plt.legend()
plt.grid(True)
plt.show()??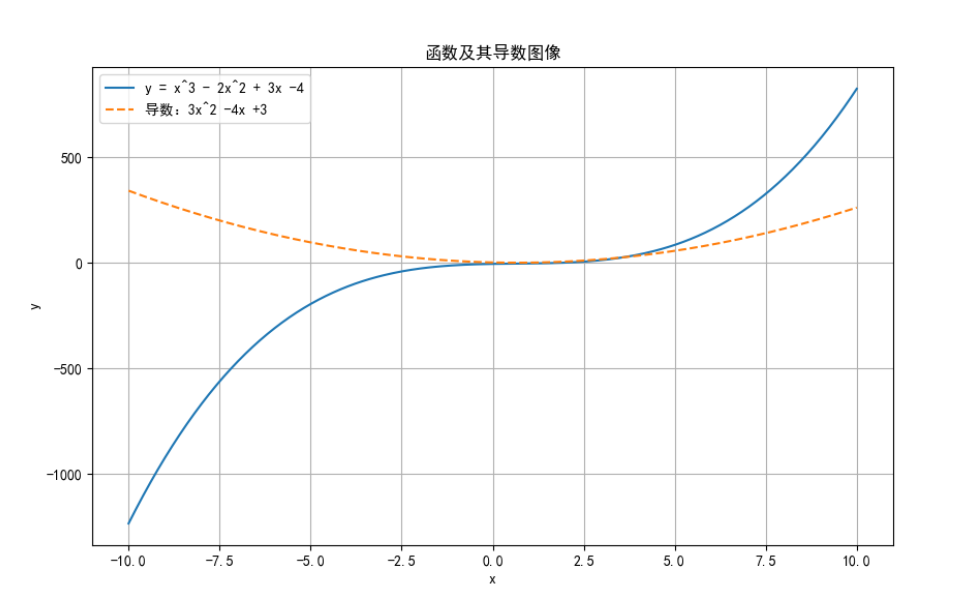
1.2 線性代數
? ?線性代數是研究向量、向量空間(或稱線性空間)、線性變換和有限維線性方程組的理論,在人工智能中,數據通常以向量或矩陣的形式表示,因此線性代數的應用非常廣泛。
1.2.1 向量和矩陣
-
向量 :一個有序的數值序列,可以表示數據的特征。例如,在圖像識別中,一張圖片可以表示為一個向量,其中每個元素代表一個像素的灰度值。
-
矩陣 :由 m×n 個數排列成的 m 行 n 列的數表。在機器學習中,數據集通常可以表示為一個矩陣,其中每一行代表一個樣本,每一列代表一個特征。
1.2.2 范數和內積
-
范數 :用于衡量向量的大小或長度。常見的范數有 L1 范數(曼哈頓距離)和 L2 范數(歐幾里得距離)。在機器學習中,范數常用于正則化,以防止模型過擬合。
-
內積 :兩個向量之間的點積,用于衡量向量之間的相似性。如果兩個向量的內積為零,則它們正交。在自然語言處理中,通過計算詞向量之間的內積,可以判斷詞義的相似性。
1.2.3 線性變換
? ?線性變換是指將一個向量空間映射到另一個向量空間的變換,且保持向量的加法和數乘運算。例如,矩陣乘法可以表示一種線性變換,在圖像處理中,通過矩陣乘法可以實現圖像的旋轉、縮放等變換。
1.2.4 特征值和特征向量
? ? 對于一個矩陣 A,如果存在一個非零向量 x 和一個標量 λ,使得 Ax = λx,則 λ 稱為矩陣 A 的特征值,x 稱為對應的特征向量。在主成分分析(PCA)等降維算法中,通過求矩陣的特征值和特征向量,可以找出數據的主要特征方向,從而降低數據的維度。
1.2.5 奇異值分解
? ? 奇異值分解(SVD)是一種矩陣分解方法,將一個矩陣分解為三個矩陣的乘積。它在推薦系統、圖像壓縮等領域能夠廣泛應用。例如,在推薦系統中,通過 SVD 可以對用戶 - 物品矩陣進行分解,挖掘用戶的潛在興趣,從而實現個性化推薦。
Python 求解示例
對矩陣 A=[[1, 2], [3, 4]] 進行奇異值分解。
?
import numpy as np# 定義矩陣
A = np.array([[1, 2], [3, 4]])# 奇異值分解
U, sigma, VT = np.linalg.svd(A)print("矩陣 U:\n", U)
print("\n奇異值 sigma:\n", sigma)
print("\n矩陣 VT:\n", VT)?
1.3 概率論
? ?概率論是研究隨機現象數量規律的數學分支,在人工智能中,許多問題都涉及到不確定性,如數據噪聲、模型預測的不確定性等,概率論為我們提供了處理這些問題的工具。
基本概念
-
概率 :表示一個事件發生的可能性大小,取值范圍在 0 到 1 之間。
-
概率分布 :描述隨機變量取值的概率規律。常見的概率分布有二項分布、正態分布等。在機器學習中,數據通常假設服從某種概率分布,通過估計分布的參數,可以對數據進行建模。
應用
-
貝葉斯定理 :在機器學習中,貝葉斯定理用于計算后驗概率,是貝葉斯分類器等算法的基礎。例如,在垃圾郵件分類中,通過貝葉斯定理計算一封郵件是垃圾郵件的概率,從而實現分類。
Python 求解示例
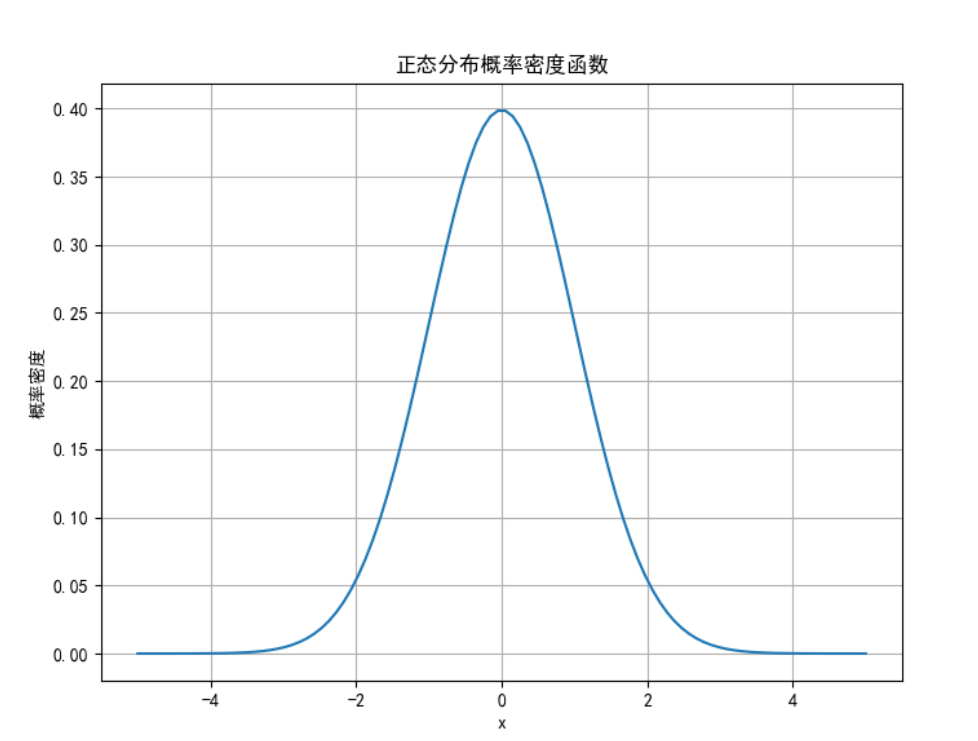
計算正態分布的概率密度函數,并繪制圖像。
import numpy as np
import matplotlib.pyplot as plt
from scipy.stats import normplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 定義正態分布參數
mu = 0 # 均值
sigma = 1 # 標準差# 計算概率密度函數
x = np.linspace(-5, 5, 100)
y = norm.pdf(x, mu, sigma)# 繪制圖像
plt.figure(figsize=(8, 6))
plt.plot(x, y)
plt.xlabel('x')
plt.ylabel('概率密度')
plt.title('正態分布概率密度函數')
plt.grid(True)
plt.show()
1.4 數理統計
? ?數理統計是研究如何通過對隨機樣本的觀察和分析,來推斷總體的分布和特征的數學分支。在人工智能中,我們通常只有有限的樣本數據,通過數理統計方法,可以從樣本推斷總體,從而對數據進行建模和分析。
基本概念
-
樣本均值 :樣本數據的平均值,用于估計總體均值。
-
樣本方差 :衡量樣本數據的離散程度,用于估計總體方差。
應用
-
假設檢驗 :在模型評估中,通過假設檢驗可以判斷模型的性能是否顯著優于基線模型。例如,比較兩種不同機器學習算法在測試集上的準確率,判斷是否存在顯著差異。
-
置信區間估計 :用于估計模型參數的取值范圍。例如,在線性回歸中,通過置信區間估計回歸系數的取值范圍,了解模型參數的不確定性。
Python 求解示例
計算一組樣本數據的均值和方差,并進行 t 檢驗(假設總體均值為 0)。
?
import numpy as np
from scipy import stats# 生成樣本數據
np.random.seed(0)
data = np.random.randn(100) # 生成 100 個服從標準正態分布的隨機數# 計算樣本均值和方差
mean = np.mean(data)
var = np.var(data, ddof=1) # ddof=1 表示無偏估計print("樣本均值:", mean)
print("樣本方差:", var)# t 檢驗(假設總體均值為 0)
t_stat, p_val = stats.ttest_1samp(data, 0)print("\nt 檢驗統計量:", t_stat)
print("p 值:", p_val)?
1.5 最優化理論
? ? 最優化理論是研究如何尋找函數的最小值或最大值的數學分支。在人工智能中,最優化方法用于訓練模型,通過最小化損失函數,使模型的預測結果盡可能接近真實值。
1.5.1 目標函數
? ? 目標函數是我們希望優化的函數,通常是損失函數,如均方誤差(MSE)、交叉熵損失等。在機器學習中,通過調整模型參數,使目標函數達到最小值,從而得到最優的模型。
1.5.2 線性規劃
? ? 線性規劃是一種最優化方法,用于在滿足線性約束條件下,求線性目標函數的最小值或最大值。在資源分配、生產調度等領域有廣泛應用。在人工智能中,線性規劃可以用于解決一些簡單的分類問題,如線性可分支持向量機。
1.5.3 梯度下降法
? ? 梯度下降法是一種基于梯度的最優化算法,通過沿著梯度方向更新參數,逐步逼近目標函數的最小值。在深度學習中,梯度下降法及其變種(如隨機梯度下降、Adam 等)是訓練神經網絡的核心算法。
Python 求解示例
使用梯度下降法優化函數 f(x) = x^2 + 2x +1,并繪制優化過程。
import numpy as np
import matplotlib.pyplot as pltplt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False# 定義函數及其導數
def f(x):return x**2 + 2*x +1def df(x):return 2*x +2# 梯度下降法
x = 5 # 初始點
learning_rate = 0.1
iterations = 20
x_history = [x]for _ in range(iterations):grad = df(x)x = x - learning_rate * gradx_history.append(x)# 繪制圖像
x_vals = np.linspace(-5, 5, 400)
y_vals = f(x_vals)plt.figure(figsize=(10, 6))
plt.plot(x_vals, y_vals, label='f(x) = x^2 + 2x +1')
plt.scatter(x_history, [f(x) for x in x_history], color='red', zorder=5)
plt.xlabel('x')
plt.ylabel('f(x)')
plt.title('梯度下降法優化過程')
plt.legend()
plt.grid(True)
plt.show()print("優化后的 x 值:", x)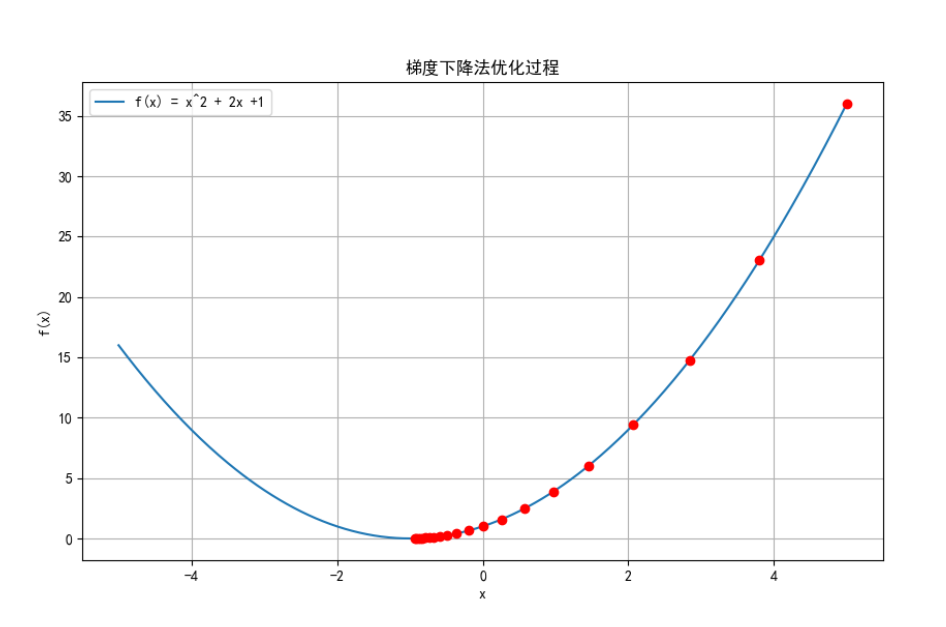
? ? 通過以上對人工智能數學基礎的介紹和 Python 求解示例,我們可以看到數學在人工智能中的重要性。掌握這些數學知識,有助于我們更好地理解和應用人工智能算法。在實際學習和工作中,我們可以多進行代碼實踐,加深對數學知識的理解和應用能力。資源綁定附上完整資源供讀者參考學習!



)





)




:讓機器決策透明化)
庫)



