原文鏈接:tecdat.cn/?p=41693
在當今數字化浪潮席卷全球的時代,城市交通領域的海量數據如同蘊藏著無限價值的寶藏等待挖掘。作為數據科學家,我們肩負著從復雜數據中提取關鍵信息、構建有效模型以助力決策的使命(點擊文末“閱讀原文”獲取完整代碼、數據、文檔)。
我們團隊承接并完成了一項極具挑戰性的咨詢項目 —— 針對出租車出行數據的深度分析與預測研究。該項目旨在通過對出租車運營數據的全方位剖析,為城市交通資源優化配置與科學規劃提供堅實的數據支撐。
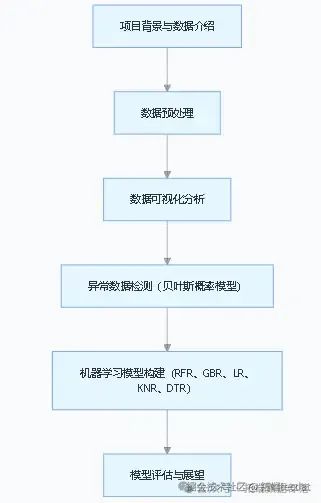
項目伊始,我們面對的是出租車出行的原始數據,這些數據包含行程標識、叫車方式、時間信息、GPS 坐標等多維度特征,然而數據缺失與異常問題也隨之而來。為此,我們運用 Python 為核心工具,開展數據預處理工作,篩選有效數據子集。緊接著,借助數據可視化手段,從時間、叫車類型等維度深入探索數據規律,發現出行活動在工作日與周末、不同叫車方式間的顯著差異。針對數據中的異常值,我們創新性地引入基于貝葉斯概率的異常檢測模型,成功識別出約 10% 存在無效 GPS 坐標的路線。最后,我們構建了包括隨機森林回歸器(RFR)、梯度提升回歸器(GBR)、線性回歸(LR)、k 近鄰回歸(KNR)、決策樹回歸(DTR)等多種機器學習模型,對出租車行程進行預測,對比各模型性能,為后續優化與實際應用奠定基礎。
專題項目文件已分享在交流社群,閱讀原文進群和 500 + 行業人士共同交流和成長。我們期待探索數據背后的無限可能,為城市交通的智能化發展貢獻力量。
文章流程圖
?
出租車出行數據分析與預測研究
在城市交通日益復雜的當下,出租車作為重要的出行方式,其運營數據蘊含著巨大價值。通過對出租車出行數據的深入分析與精準預測,不僅能夠優化出租車資源配置,還能為城市交通規劃提供有力支撐。本次研究圍繞出租車出行數據展開,旨在探索數據背后的規律,并構建有效的預測模型。
數據探索與預處理
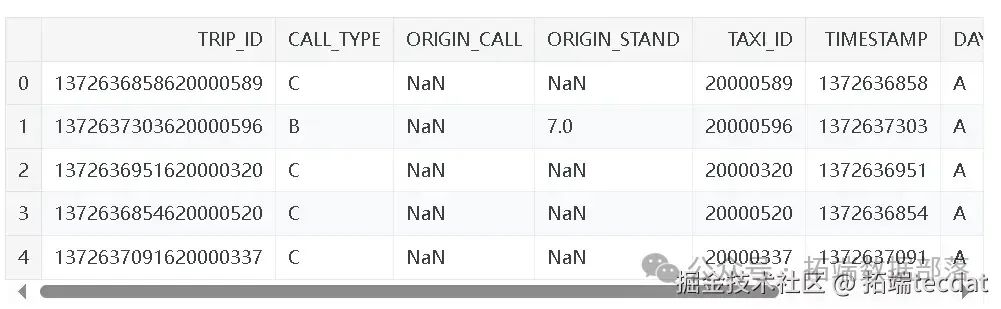
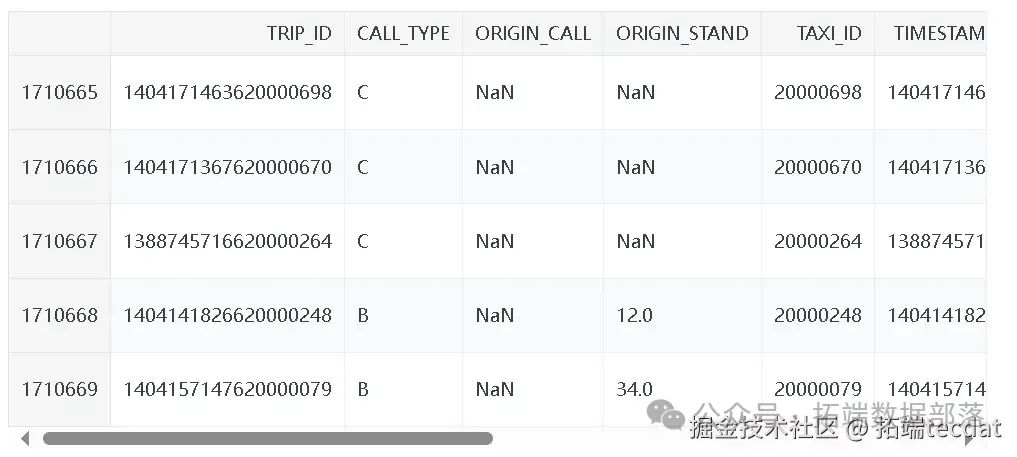
研究首先面臨的是出租車出行數據。每一條數據樣本對應一次完整的行程,包含9個特征。TRIP_ID?是每次行程的唯一標識;CALL_TYPE?標識叫車方式,分為從調度中心派單(A)、在特定站點向司機叫車(B)和其他方式(C) ;ORIGIN_CALL?在?CALL_TYPE?為?A?時標識行程客戶的電話號碼,否則為?NULL?;ORIGIN_STAND?在?CALL_TYPE?為?B?時標識出租車起始站點,否則為?NULL?;TAXI_ID?標識執行行程的出租車司機;TIMESTAMP?以Unix時間戳記錄行程開始時間;DAYTYPE?標識行程開始日期類型,分為節假日或特殊日(B)、特殊日前一天(C)和普通日(A) ;MISSING_DATA?表示GPS數據流是否完整;POLYLINE?記錄行程的GPS坐標序列。行程總時長通過?(POLYLINE中的點數 - 1) x 15?秒計算,部分行程存在數據缺失,這為研究帶來挑戰。
為了更好地分析數據,我們使用Python進行數據處理。
接著讀取數據并進行初步處理:
ini
代碼解讀
復制代碼
source?= pd.read_csv("tr.cv", sep=",", low_memory=False)
no_poly_source?= source.loc[:, source.columns!=?'POLYLINE']
miss_false_no_poly_source?= no_poly_source[no_poly_source.MISSING_DATA ==?False]通過這幾步,我們篩選出了GPS數據完整且不含?POLYLINE?列的數據子集,為后續分析做準備。
數據可視化分析
數據可視化能夠幫助我們直觀地發現數據中的規律和特征。我們對數據從多個維度進行了可視化探索。
在時間維度上,通過提取數據中的年、月、日、時等信息,繪制了各類圖表。例如,繪制年份分布餅圖,觀察每年出行數據的占比:
還繪制了出行數量隨日期的變化折線圖,清晰呈現出不同日期出行量的波動趨勢:
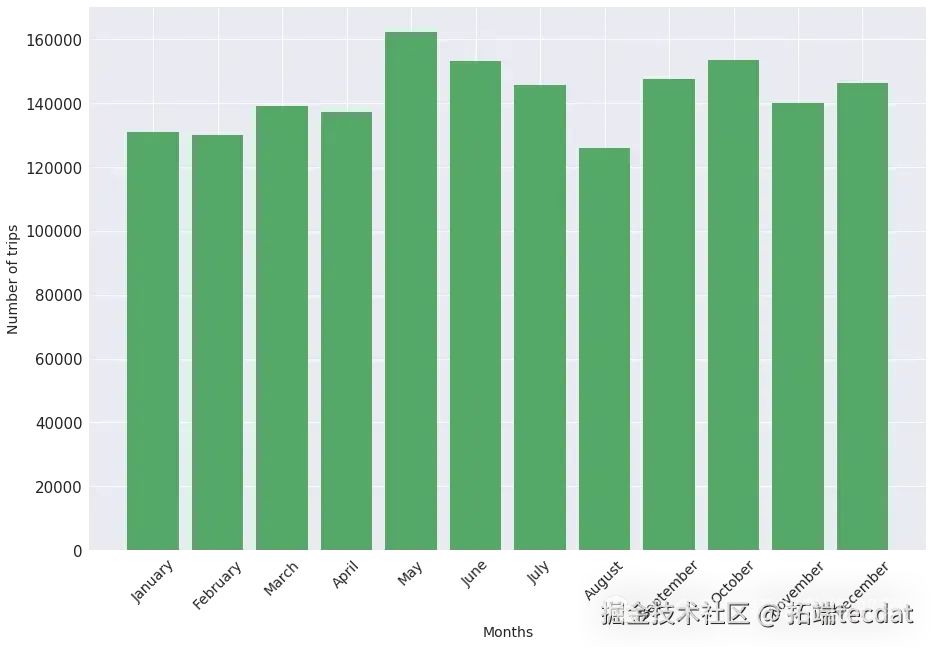
此外,還分析了每月、每月中的每一天、每周的每一天的出行數量分布情況,繪制了相應的柱狀圖。
每月出行數量柱狀圖:
每月中每天出行數量柱狀圖:
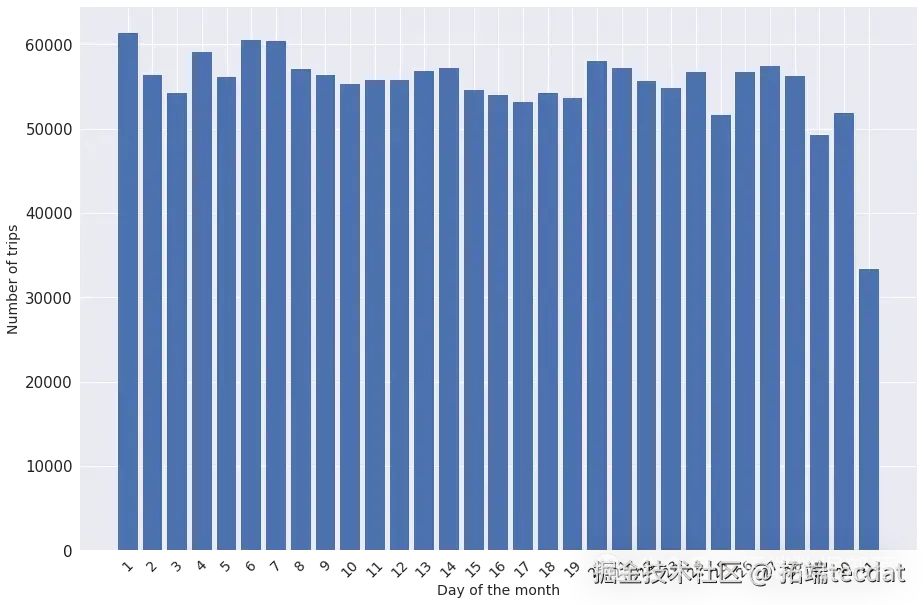
每周中每天出行數量柱狀圖:
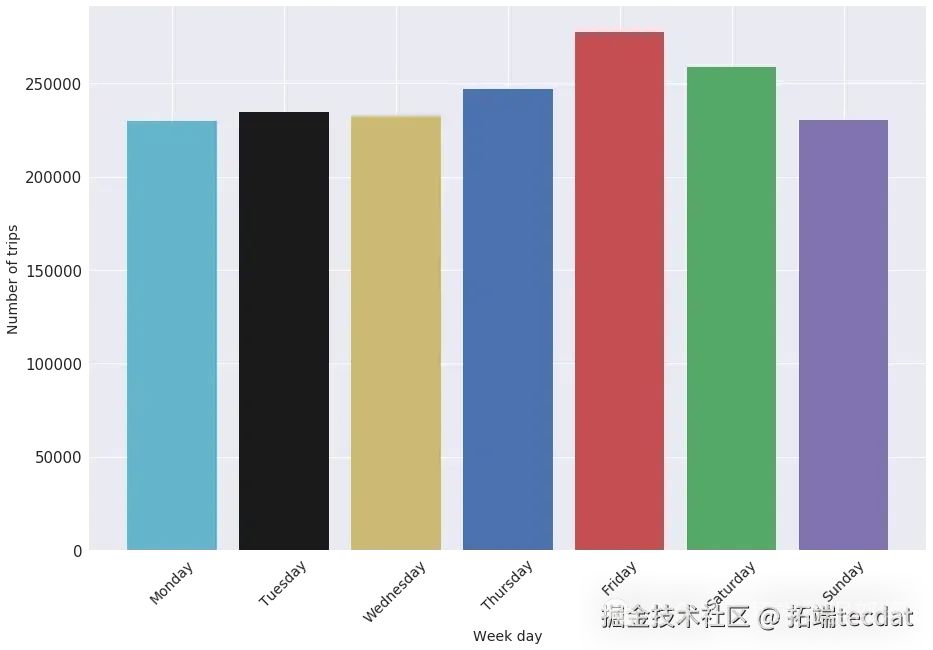
在叫車類型維度,繪制了叫車類型占比的餅圖和矩形樹圖,直觀展示不同叫車方式的比例:
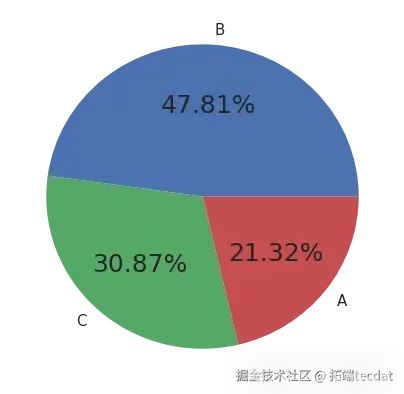
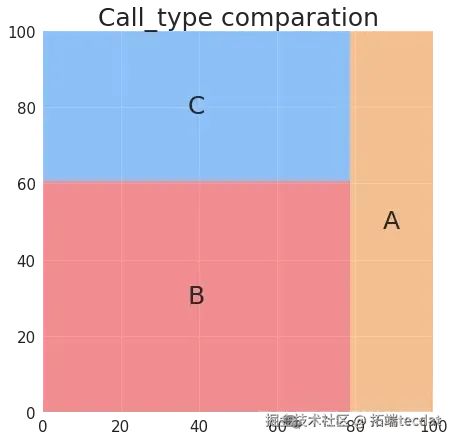
同時,分析了每周不同日期各類叫車方式的出行數量差異,繪制柱狀圖進行對比:
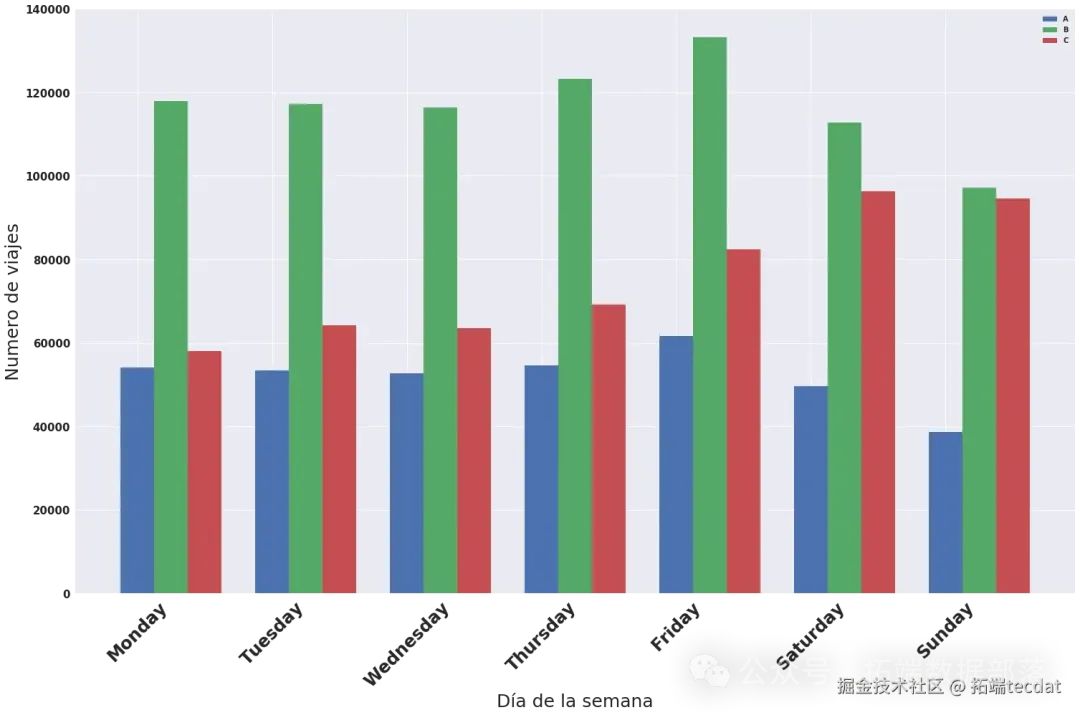
通過這些可視化圖表,我們發現出行數量在不同時間和叫車方式上存在明顯差異。例如,周末和工作日的出行高峰時間不同,某些叫車方式在特定時間段更為常見。
熱圖
點擊標題查閱往期內容

杭州出租車行駛軌跡數據空間時間可視化分析

左右滑動查看更多
01
02
03
04

出租車出行數據分析與異常檢測
AI提示詞:請編寫代碼,使用pandas讀取壓縮格式的CSV文件,文件路徑為’…/sv.zip’,分隔符為逗號,設置低內存模式為False。
ini
代碼解讀
復制代碼
taxi?= pd.read_csv('..
)出行時間分析
接下來,我們從出行時間的角度對數據進行分析。通過繪制熱力圖,我們可以直觀地看到不同時間段的出行情況。
AI提示詞:請使用Python和seaborn庫,繪制一個熱力圖,展示出租車在不同小時和工作日的出行次數分布。需要對數據進行透視表處理,將結果列名設置為中文星期幾,使用’coolwarm’顏色映射。
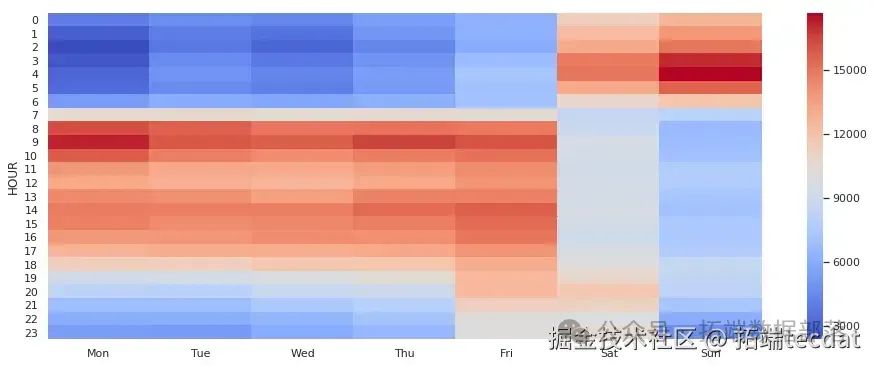
從這個熱力圖中,我們可以明顯看出工作日和周末的出行情況有很大差異。工作日的出行活動主要集中在8點到18點之間,周一的首個小時出現出行高峰。而周五和周六的晚上出行活動也非常活躍,尤其是周六。這表明出行活動主要有兩個來源:工作和休閑。工作出行集中在工作日的工作時間,而休閑出行則在周五晚上和周六晚上較為頻繁。
我們還可以進一步按照叫車類型對數據進行分組,分析不同叫車類型在不同時間段的出行情況。
AI提示詞:請編寫一個函數,用于繪制不同叫車類型下,出租車在不同小時和工作日的出行次數熱力圖。需要對數據進行透視表處理,將結果列名設置為中文星期幾,使用’coolwarm’顏色映射。然后使用seaborn的FacetGrid函數按照叫車類型進行分組繪制。
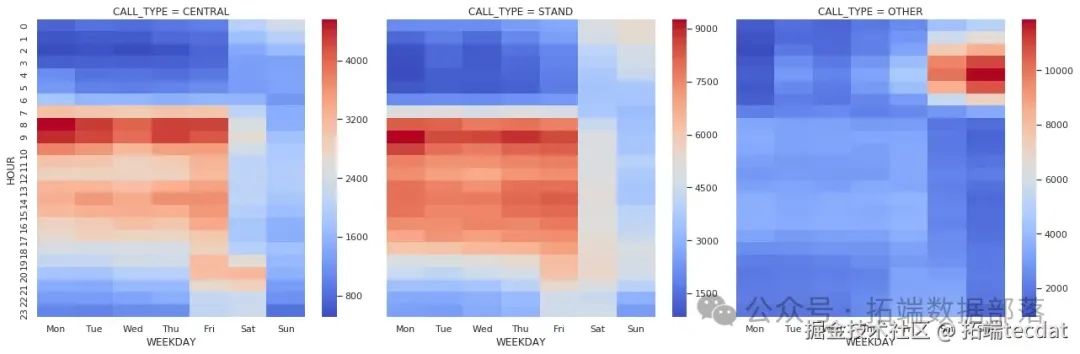
從這個分析中我們發現,不同叫車類型的出行時間分布有明顯差異。“其他”叫車類型主要集中在周五和周六晚上,可能是因為出租車司機在這些時間段前往休閑區域接客。而從調度中心派單的出行,在早上首個小時和其他時間段有較大反差,周五和周六晚上有一個小高峰。在站點叫車的出行情況則相對平穩,有特定的活動水平和時間。這說明叫車類型與出行活動有很大的相關性。
我們繼續探究一年中不同周、不同工作日的出行次數分布情況。
AI提示詞:編寫代碼處理數據,去除重疊日期數據,提取周數信息,通過透視表計算不同周、不同工作日的出行次數,設置中文星期幾為索引,反轉星期順序后繪制熱力圖。
ini
代碼解讀
復制代碼
# 去除最后一天(6月30日,2014年),因其存在數據重疊問題
taxi?= taxi[(taxi.YEAR !=?2014) | (taxi.MONTH !=?6) | (taxi.DAY !=?30)]
taxi["WEEK_NUMBER"]?= taxi.TIMESTAMP.apply(lambda x: datetime.fromtimestamp(x).isocalendar()[1])
data?= taxi.pivot_table(
從這張圖中,我們能發現一些特殊日期出行次數的變化,像1月1日、12月25日等節假日,以及某些特定時間段,出行次數明顯不同,背后可能有著各種社會活動或特殊事件的影響 。
行程距離與時長分析
行程的距離和時長也是重要的分析維度。
AI提示詞:編寫代碼,先篩選去除距離和時長的極端值數據,分別通過透視表計算不同小時和工作日的平均行程距離與平均行程時長,然后繪制兩張熱力圖展示結果。
ini
代碼解讀
復制代碼
sns.set(rc={"figure.figsize": (16,?6)})
# 去除行程距離的極端值
taxi?= taxi[(taxi.TRIP_DISTANCE < taxi.TRIP_DISTANCE.quantile(0.99))]
distance?= taxi.pivot_table(
index="HOUR", columns="WEEKDAY", values=["TRIP_DISTANCE"], aggfunc=np.mean
)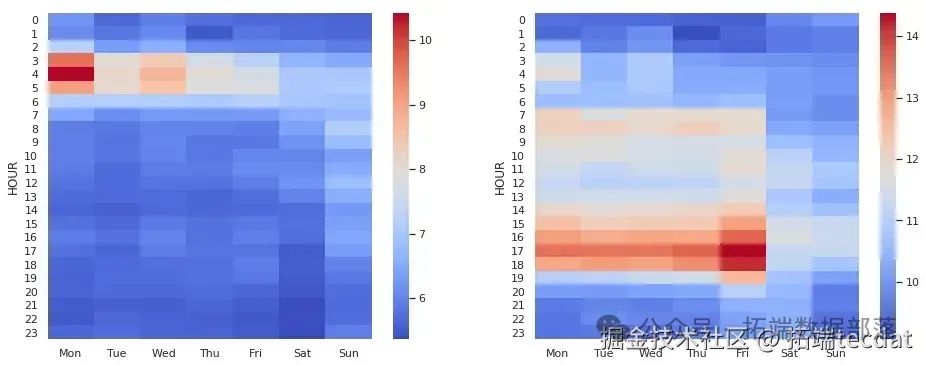
雖然距離和時長高度相關,但它們的均值表現卻有所不同。在距離方面,工作日深夜有大量較長距離的行程,周一尤為明顯,推測可能是前往機場趕早班機的行程。在時長方面,夜間和周末行程時間低于平均水平,而傍晚尤其是周五,行程時間較長,很可能是交通擁堵導致。
進一步按照叫車類型分組,分析不同叫車類型下行程距離和時長在不同時間段的分布。
AI提示詞:編寫繪制熱力圖的通用函數,對數據進行處理和類型轉換,使用FacetGrid按叫車類型分組,分別繪制不同叫車類型下行程距離和時長在不同小時和工作日的熱力圖。
ini
代碼解讀
復制代碼
def draw_heatmap(*args, **kwargs):
data?= kwargs.pop("data")
d?= data.pivot_table(
index=args[0], columns=args[1], values=args[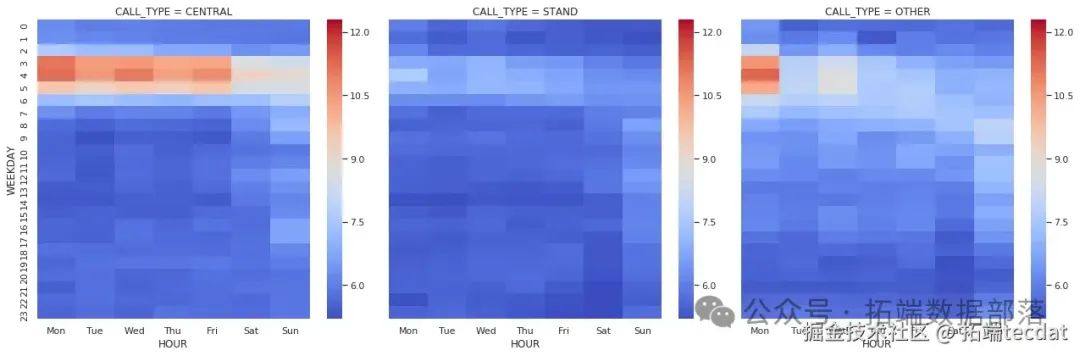
ini
代碼解讀
復制代碼
# 繪制行程時長熱力圖
g?= sns.FacetGrid(data, co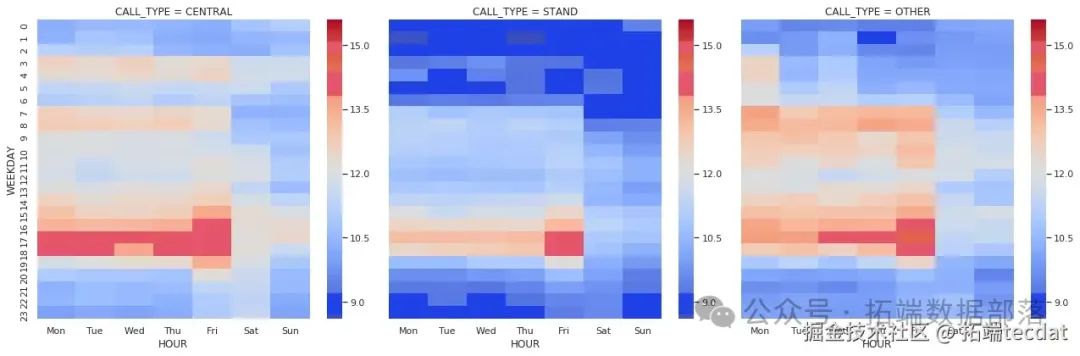
同時,我們也分析了一年中不同周、不同工作日的平均行程距離和時長情況。
AI提示詞:編寫代碼處理數據,去除重疊日期數據,提取周數信息,分別通過透視表計算不同周、不同工作日的平均行程距離和平均行程時長,設置中文星期幾為索引,反轉星期順序后繪制熱力圖。
ini
代碼解讀
復制代碼
# 去除最后一天(6月30日,2014年),因其存在數據重疊問題
taxi?= taxi[(taxi.YEAR !=?2014) | (taxi.MONTH !=?6) | (taxi.DAY !=?30)]
taxi["WEEK_NUMBER"]?= taxi.TIMESTAMP.apply(lambda x: datetime.fromtimestamp(x).isocalendar()[1])
# 計算平均行程距離
data?= taxi.pivot_table(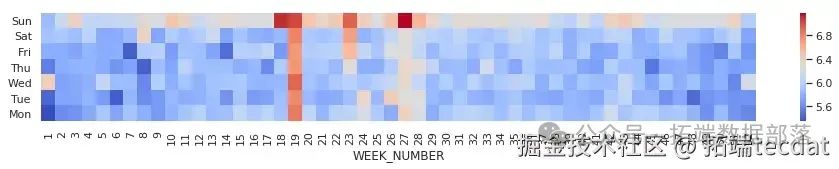
ini
代碼解讀
復制代碼
# 計算平均行程時長
data?= taxi.pivot_table(
index="WEEKDAY", columns="WEEK_NUMBER", values="TRIP_TIME", aggfunc=np.mean
)
異常數據檢測
在查看出租車行駛路線時,我們發現部分路線存在巨大的不連續性,這可能是異常值或數據采集問題導致的。為了檢測這些異常數據,我們先從速度和距離的角度進行分析。
AI提示詞:請編寫代碼,使用sklearn庫中的DistanceMetric計算經緯度之間的距離,定義函數計算兩點之間的速度,并繪制速度的經驗分布函數圖。
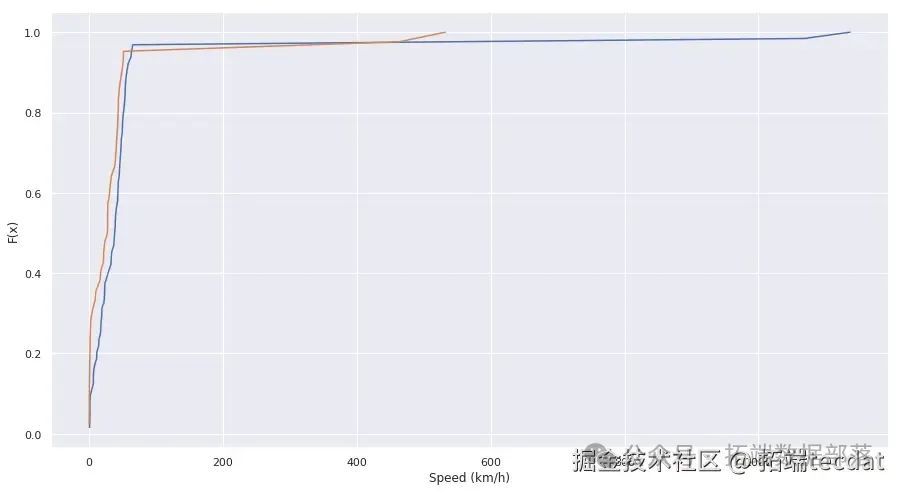
從速度的經驗分布函數圖中可以看出,異常點的速度與行程中的其他速度明顯不同。接下來,我們繪制點間速度隨距離變化的熱力圖,進一步分析異常數據的特征。
AI提示詞:請編寫代碼,定義一個函數用于繪制點間速度隨距離變化的熱力圖,然后繪制兩條軌跡的熱力圖。
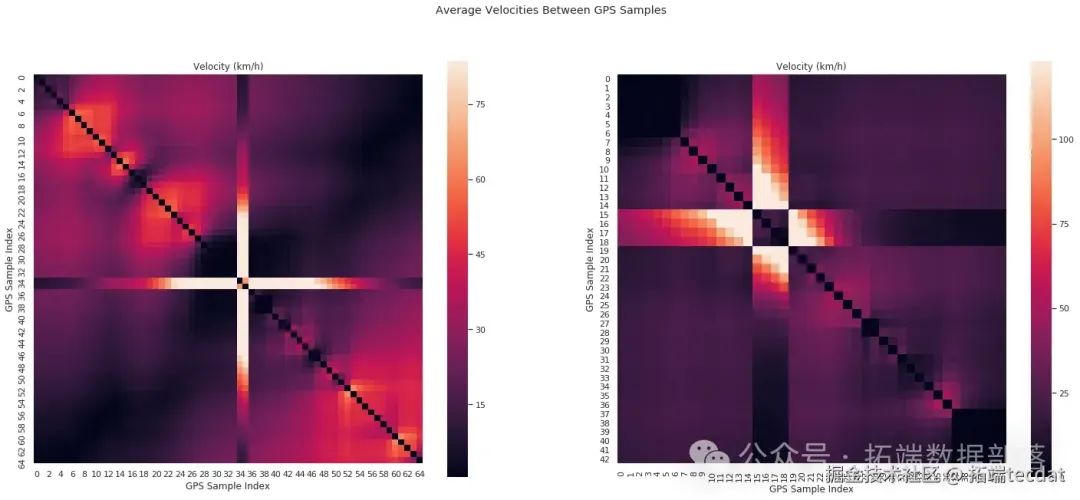
通過這些可視化分析,我們可以直觀地看到異常點的存在。為了更系統地檢測異常點,我們進一步分析GPS坐標點間距離的分布,發現其符合一定規律。我們利用這個規律,構建了基于貝葉斯概率的異常點檢測模型。
AI提示詞:請編寫代碼,定義一個函數計算GPS坐標點的似然值,一個函數對似然值進行歸一化處理,一個函數繪制似然值曲線,然后繪制四條軌跡的似然值曲線。
python
代碼解讀
復制代碼
deflikelihood(coords, ab):n =?len(coords)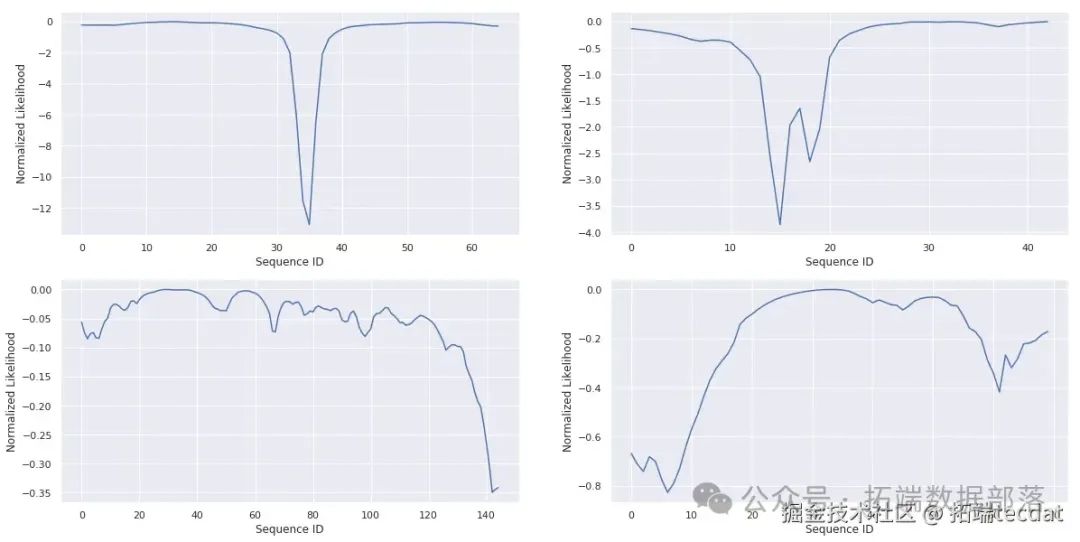
通過計算每個點在路線中的對數似然比,我們設定一個閾值,以此判斷該點是否為異常點。
AI提示詞:編寫代碼確定檢測參數,包括取軌跡長度的90%分位數作為長度標準,設定似然比閾值;然后應用異常檢測方法標記可能存在異常點的軌跡,繪制熱力圖展示結果;最后統計存在無效GPS坐標的路線數量。
通過上述操作,我們成功檢測出約10%的存在無效GPS坐標的路線。
css
代碼解讀
復制代碼
bad_routes = df.traj.apply(lambda t: (norm_lr(likelihood(t,coeffs)) < thresh).any()).values
print("存在無效點的路線: {} / 總路線數".format(bad_routes.sum()))為了驗證檢測結果的可靠性,我們隨機抽取一些被標記為存在異常的路線進行可視化檢查。
AI提示詞:編寫函數對指定路線進行可視化檢查,在軌跡圖上標記出檢測到的異常點;然后調用函數對多條路線進行檢查。
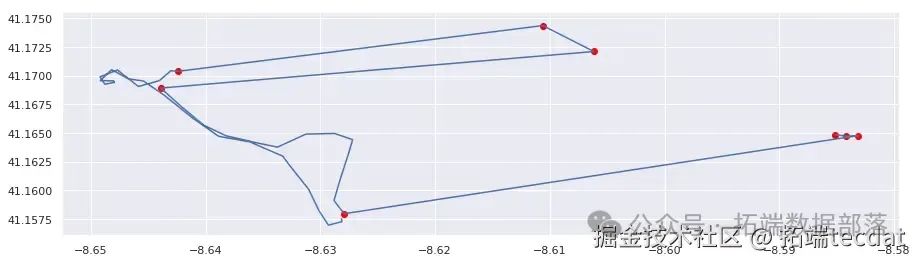
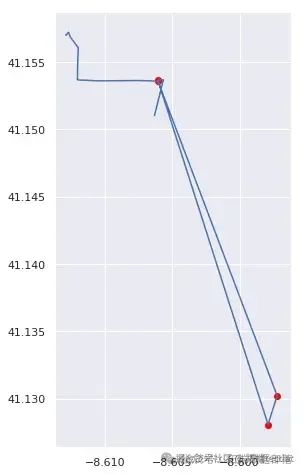
最后,我們繪制未檢測出異常點的路線圖,與之前的結果進行對比。
ini
代碼解讀
復制代碼
df[~bad_routes].lines.plot(figsize=[15,15])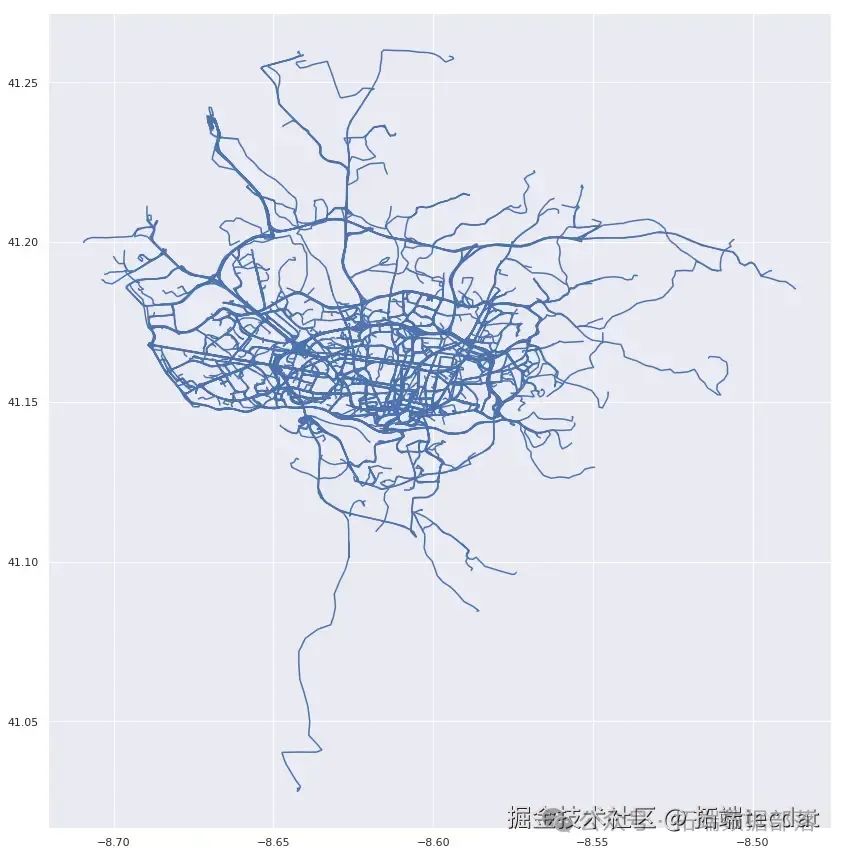
通過對出租車出行數據抽絲剝繭般的分析,我們像偵探破案一樣,發現了出行活動在時間和叫車類型上的規律。從熱力圖中,我們能清晰看到工作日和周末出行高峰的差異,也了解到不同叫車類型在不同時間段的活躍程度。同時,我們還找到了一種有效的異常數據檢測方法,利用貝葉斯概率模型,成功揪出了約10%存在無效GPS坐標的路線。
然而,這只是探索城市交通數據寶藏的開始。我們雖然發現了異常數據,但還不清楚它們產生的具體原因。是高樓大廈影響了信號接收?還是數據采集設備出了問題?此外,檢測出異常數據后,如何用更準確的數據替換這些無效數據段,也是一個亟待解決的問題。
在對出租車出行數據進行了詳細的探索性分析和異常數據檢測后,我們進一步深入研究,嘗試構建多種機器學習模型來對出租車的行程進行預測,以便更精準地把握出租車出行的規律,為城市交通規劃和運營提供更有力的支持。
機器學習模型的構建
為了構建合適的機器學習模型,我們首先對數據進行了必要的預處理和特征工程,將數據劃分為訓練集和測試集,分別用于模型的訓練和評估。以下是我們構建的幾種常見的機器學習模型及其實現過程。
隨機森林回歸器
AI提示詞:請使用Python編寫代碼,構建一個多輸出的隨機森林回歸模型,設置隨機森林的估計器數量為100,隨機種子為1。然后使用訓練數據對模型進行訓練,并分別對訓練集和測試集進行預測,最后計算并輸出訓練集和測試集上的均方誤差以及R2分數。
python
代碼解讀
復制代碼
from?sklearn.ensemble?import?RandomForestRegressor
from?sklearn.multioutput?import?MultiOutputRegressor
from?sklearn.metrics?import?mean_squared_error, r2_score
# 構建多輸出隨機森林回歸器
forest = MultiOutputRegressor(RandomForestRegressor(n_estimators=100, random_state=1))
# 模型訓練
forest = forest.fit(X_train, y_train)
# 對訓練集和測試集進行預測
隨機森林回歸器通過集成多個決策樹來進行預測,能夠有效地處理復雜的非線性關系。從結果中我們可以看到,它在訓練集和測試集上都取得了一定的性能表現。
梯度提升回歸器
AI提示詞:編寫Python代碼,構建一個多輸出的梯度提升回歸模型,設置隨機種子為0。使用訓練數據進行模型訓練,然后對訓練集和測試集進行預測,最后計算并輸出在訓練集和測試集上的均方誤差以及R2分數。

梯度提升回歸器通過迭代地擬合弱學習器來逐步提升模型的性能,對于一些具有復雜模式的數據往往能有較好的表現。從其性能指標來看,它在訓練集和測試集上的表現也各有特點。
多輸出線性回歸
AI提示詞:請用Python實現一個多輸出的線性回歸模型,設置線程數為1。使用劃分好的訓練數據對模型進行訓練,接著分別對訓練集和測試集進行預測,最后計算并輸出訓練集和測試集上的均方誤差以及R2分數。

線性回歸是一種簡單而經典的回歸模型,假設自變量和因變量之間存在線性關系。通過計算性能指標,我們可以評估它在出租車行程預測任務中的適用性。
多輸出k近鄰回歸
AI提示詞:編寫Python代碼構建多輸出的k近鄰回歸模型。使用訓練數據對模型進行訓練,然后分別對訓練集和測試集進行預測,最后計算并輸出在訓練集和測試集上的均方誤差以及R2分數。

k近鄰回歸算法基于樣本之間的距離來進行預測,簡單直觀。通過在訓練集和測試集上的評估,我們可以了解它在出租車行程數據上的表現。
多輸出決策樹回歸
AI提示詞:請使用Python構建一個多輸出的決策樹回歸模型,設置最大深度為50,隨機種子為1。使用訓練數據訓練模型,然后分別對訓練集和測試集進行預測,最后計算并輸出訓練集和測試集上的均方誤差以及R2分數。

決策樹回歸通過對數據進行遞歸劃分來構建模型,能夠處理非線性關系。通過性能指標的計算,我們可以判斷它在出租車行程預測中的效果。
模型評估與展望
通過對以上多種機器學習模型的構建和訓練,以及在訓練集和測試集上的性能評估,我們得到了各個模型的均方誤差和R2分數等指標。這些指標反映了不同模型在出租車行程預測任務中的表現差異。
從結果來看,不同的模型各有優劣。例如,隨機森林回歸器和梯度提升回歸器在處理復雜數據關系時可能具有更好的性能,但計算成本相對較高;而線性回歸模型簡單直觀,但對于非線性數據的擬合能力可能有限。
在未來的研究中,我們可以進一步優化這些模型,比如調整模型的超參數、嘗試更多的特征工程方法,或者結合多個模型的預測結果,以提高預測的準確性和可靠性。同時,我們還可以將這些模型應用到實際的城市交通場景中,為出租車調度、交通流量優化等提供更有效的支持,真正實現數據驅動的城市交通管理和決策。

本文中分析的完整數據、代碼、文檔分享到會員群,掃描下面二維碼即可加群!?

資料獲取
在公眾號后臺回復“領資料”,可免費獲取數據分析、機器學習、深度學習等學習資料。

點擊文末“閱讀原文”
獲取完整代碼、數據、文檔。
本文選自《Python+AI提示詞出租車出行軌跡:梯度提升GBR、KNN、LR回歸、隨機森林融合預測及貝葉斯概率異常檢測研究》。
點擊標題查閱往期內容
基于出租車GPS軌跡數據的研究:出租車行程的數據分析
用數據告訴你出租車資源配置是否合理
把握出租車行駛的數據脈搏 :出租車軌跡數據給你答案!
基于出租車GPS軌跡數據的研究:出租車行程的數據分析
用數據告訴你出租車資源配置是否合理
共享單車大數據報告
R語言用泊松Poisson回歸、GAM樣條曲線模型預測騎自行車者的數量
消費者共享汽車使用情況調查
新能源車主數據圖鑒
python研究汽車傳感器數據統計可視化分析
R語言ggmap空間可視化機動車交通事故地圖
R語言ggmap空間可視化機動車碰撞–街道地圖熱力圖



![]()






--應用層協議原理)






)






