引入
通過前面我們對于Flink的理解,我們知道它吸收了 Dataflow 的理念,以及此前已有的流處理系統(如 S4、Storm、MillWheel)的經驗,實現了批流一體化的高效數據處理,并且通過靈活的窗口機制、事件時間與水位線機制、容錯機制和狀態管理等特性,為開發者提供了應對各種復雜的實時數據處理挑戰的能力。對于它的核心實現原理可以看我前面的Flink執行原理文章。
Flink 為流式/批式處理應用程序的開發提供了不同級別的抽象:
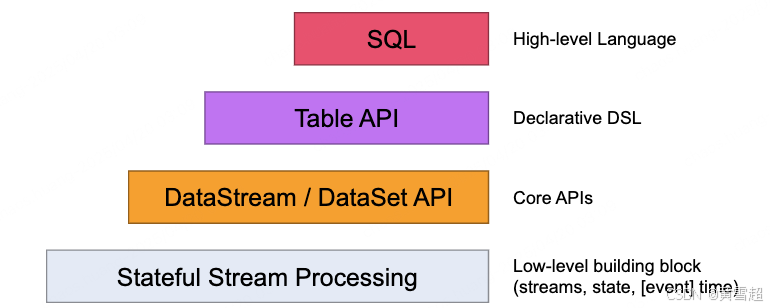
- Flink API 最底層的抽象為有狀態實時流處理。其抽象實現是 Process Function,并且 Process Function 被 Flink 框架集成到了 DataStream API 中來為我們使用。它允許用戶在應用程序中自由地處理來自單流或多流的事件(數據),并提供具有全局一致性和容錯保障的狀態。此外,用戶可以在此層抽象中注冊事件時間(event time)和處理時間(processing time)回調方法,從而允許程序可以實現復雜計算。
- Flink API 第二層抽象是 Core APIs。實際上,許多應用程序不需要使用到上述最底層抽象的 API,而是可以使用 Core APIs 進行編程:其中包含 DataStream API(應用于有界/無界數據流場景)。Core APIs 提供的流式 API(Fluent API)為數據處理提供了通用的模塊組件,例如各種形式的用戶自定義轉換(transformations)、聯接(joins)、聚合(aggregations)、窗口(windows)和狀態(state)操作等。此層 API 中處理的數據類型在每種編程語言中都有其對應的類。Process Function 這類底層抽象和 DataStream API 的相互集成使得用戶可以選擇使用更底層的抽象 API 來實現自己的需求。DataSet API 還額外提供了一些原語,比如循環/迭代(loop/iteration)操作。
- Flink API 第三層抽象是 Table API。Table API 是以表(Table)為中心的聲明式編程(DSL)API,例如在流式數據場景下,它可以表示一張正在動態改變的表。Table API 遵循(擴展)關系模型:即表擁有 schema(類似于關系型數據庫中的 schema),并且 Table API 也提供了類似于關系模型中的操作,比如 select、project、join、group-by 和 aggregate 等。Table API 程序是以聲明的方式定義應執行的邏輯操作,而不是確切地指定程序應該執行的代碼。盡管 Table API 使用起來很簡潔并且可以由各種類型的用戶自定義函數擴展功能,但還是比 Core API 的表達能力差。此外,Table API 程序在執行之前還會使用優化器中的優化規則對用戶編寫的表達式進行優化。表和 DataStream/DataSet 可以進行無縫切換,Flink 允許用戶在編寫應用程序時將 Table API 與 DataStream/DataSet API 混合使用。
- Flink API 最頂層抽象是 SQL。這層抽象在語義和程序表達式上都類似于 Table API,但是其程序實現都是 SQL 查詢表達式。SQL 抽象與 Table API 抽象之間的關聯是非常緊密的,并且 SQL 查詢語句可以在 Table API 中定義的表上執行。
DataStream API實踐原理小節的重點在于DataStream API,它主要用于構建流式類型的Flink應用,處理實時無界數據流。和Storm組合式編程接口不同,DataStream API屬于定義式編程接口,具有強大的表達力,可以構建復雜的流式應用,例如對狀態數據的操作、窗口的定義等。開發者只要調用統一的編程API,傳入具體的計算邏輯,不必太多關心底層的細節,就可以完成各種復雜的計算了,并且可以實現快速部署、資源調度、任務容錯等,大大的提高了開發效率。
下面我們先看看Flink的計算模型是如何設計的,便于后面我們基于DataStream API開發,并深入其實現原理。
Flink計算模型
DataStream是Flink流式計算編程的抽象數據集(與Spark的RDD是類似的),抽象數據集里面不裝要真正要計算的數據,而是記錄一些描述信息,例如從哪里讀取數據,掉了用了什么方法,傳入了什么計算邏輯,通過調用DataStreamTransformation(s)和Sink后,構建成執行計劃圖DataFlow Graph(類似Spark的DAG),然后生成Task提交到集群中執行真正的計算邏輯。通過前面實時計算核心論文系列文章,我們知道Flink實時計算模型主要分為數據源、轉換操作和數據輸出三部分。
- 數據源:關注與外部數據系統的打通,讀取消息、中間件等數據
- 轉換操作:關注數據的轉換,包括filter、transform和connect操作
- 數據輸出:將轉換后的數據輸出到外部數據系統,供用戶獲取
在開發Flink實時計算程序,首先學要創建StreamExecutionEnvironment,然后調用相應的Source算子創建原始的DataStream,再調用零到多次Transformation(轉換算子),每調用一次Transformation都會生成一個新的DataStream,最后調用Sink,我們寫的程序就形成一個Data Flow Graph(數據流圖),然后提交給JobManager,經過優化后生成包含有具體計算邏輯的Task實例,然后調度到TaskManager的slot中開始計算。
Data Source數據源
在實時計算DataStream API中,Source是用來獲取外部數據源的操作,按照獲取數據的方式,可以分為:基于集合的Source、基于Socket網絡端口的Source、基于文件的Source、第三方Connector Source和自定義Source五種。
前三種Source是Flink已經封裝好的方法,這些Source只要調用StreamExecutionEnvironment的對應方法就可以創建DataStream了,使用起來比較簡單,我們在學習和測試的時候會經常用到。如果以后生產環境想要從一些分布式、高可用的消息中間件中讀取數據,可以使用第三方Connector Source,比如Apache Kafka Source、AWS Kinesis Source、Google Cloud PubSub Source等(國內公司使用比較多的是Kafka這個消息中間件作為數據源),使用這些第三方的Source,需要額外引入對應消息中間件的依賴jar包。于此同時Flink允許開發者根據自己的需求,自定義各種Source,只要實現SourceFunction這個接口,然后將該實現類的實例作為參數傳入到StreamExecutionEnvironment的addSource方法就可以了,這樣大大的提高了Flink與外部數據源交互的靈活性。
從并行度的角度,Source又可以分為非并行的Source和并行的Source。非并行的Source它的并行度只能為1,即用來讀取外部數據源的Source只有一個實例,在讀取大量數據時效率比較低,通常是用來做一些實驗或測試,例如Flink的Socket網絡端口讀取數據的Source就是一個非并行的Source;并行的Source它的并行度可以是1到多個,即用來讀取外部數據源的Source可以有一個到多個實例(在分布式計算中,并行度是影響吞吐量一個非常重要的因素,在計算資源足夠的前提下,并行度越大,效率越高)。例如Kafka Source就是并行的Source。
Transformation轉換算子
Transformation翻譯成中文意為轉換,是將一個或多個DataStream調用某個轉換算子,生成一個新的DataStream,原來的DataStream不變。Flink程序可以將多個Transformation生成的DataStream組合成一個復雜的DataFlow拓撲。這里所提到的轉換算子,其實就是DataStream的轉換方法,調用轉換算子后,一定會生成一個新的DataStream。
我們前面的內容提到過,DataStream其實是一個抽象的數據集,調用了DataStream的轉換算子,并不會立即觸發任務的執行,對于Flink程序而言,僅是記錄了調用了哪個方法,傳入了具體什么處理邏輯,這些轉換操作會生成多個有著依賴關系和先后順序的DataStream,這些DataStream組成了DataFlow拓撲(類似Spark的DAG有向無環圖),這個DataFlow其實就是一個任務的邏輯執行計劃,Flink最終會將這個邏輯計劃轉成真正的物理計劃,最后提交到集群中運行。
Data Sink 數據輸出
經過一系列Transformation轉換操作后,最后一定要調用Sink操作,才會形成一個完整的DataFlow拓撲。只有調用了Sink操作,才會產生最終的計算結果,這些數據可以寫入到的文件、輸出到指定的網絡端口、消息中間件、外部的文件系統或者是打印到控制臺。




:剖析用戶價值與商業模式拼圖)




![[計算機科學#2]:從繼電器到晶體管的電子計算機發展史(龐然大物的進化)](http://pic.xiahunao.cn/[計算機科學#2]:從繼電器到晶體管的電子計算機發展史(龐然大物的進化))



)
來提高線程的復用率,減少線程創建和銷毀的開銷)


在C語言中怎么用(附帶實例))

--紅黑樹)