哈嘍,我不是小upper,今天和大家聊聊基于Transformer與隨機森林的多變量時間序列預測。
不懂Transformer的小伙伴可以看我上篇文章:一文帶你徹底搞懂!Transformer !!![]() https://blog.csdn.net/qq_70350287/article/details/147404686?spm=1001.2014.3001.5501
https://blog.csdn.net/qq_70350287/article/details/147404686?spm=1001.2014.3001.5501
在多變量時間序列預測領域,我們常常需要依據歷史數據來預估多個變量在未來的取值。打個比方,在分析城市交通流量時,就涉及到多個變量,像不同路段的車流量、車速等,我們要預測這些變量未來的變化情況。
以往常用的時間序列預測方法,比如 ARIMA 和 SARIMA ,存在一定的局限性。它們一般假定數據之間呈現線性關系,可在實際的復雜系統中,數據間的關系往往并非如此簡單。現實中的數據不僅存在非線性關系,還具有長期依賴特征,就好比今天的交通流量情況可能會受到一周前特殊事件的影響,而這些傳統方法很難有效捕捉到這些復雜的關系,所以在面對復雜的多變量時間序列預測任務時,效果可能不太理想 。
在當下的技術發展進程中,基于深度學習的 Transformer 和基于機器學習的隨機森林(Random Forest,簡稱 RF)在眾多任務領域得到了極為廣泛的應用。這兩種技術各有所長,若將它們有機結合,便能夠充分發揮各自的優勢,實現更出色的效果。
Transformer 模型的核心亮點在于其獨特的自注意力機制。這一機制賦予了 Transformer 強大的能力,使其能夠精準且高效地捕捉時間序列中的長期依賴關系。在處理如自然語言文本、金融時間序列數據這類包含復雜時間依賴信息的任務時,Transformer 可以輕松關注到序列中不同位置之間的關聯,從而理解整體的語義或趨勢。例如在機器翻譯中,它能理解句子中相隔較遠詞匯之間的語法和語義聯系,提升翻譯的準確性。
而隨機森林(RF)模型則是通過構建多棵決策樹的方式來進行工作。在面對高維特征空間時,它能夠進行有效的回歸操作。并且,RF 模型具有很強的魯棒性,這使得它在處理包含噪聲的數據時表現出色。即使數據中存在一些干擾信息,它也能憑借自身的結構和算法,盡量減少噪聲對結果的影響,給出相對可靠的預測。比如在預測房屋價格時,面對包含測量誤差等噪聲的數據,隨機森林模型依然能較好地捕捉到房價與其他因素之間的關系。
接下來,讓我們一起深入了解這兩種技術結合的細節內容。
多變量時間序列預測的問題建模
- 滑動窗口與樣本構造:在多變量時間序列預測中,我們從給定的觀測序列出發,通過設定窗口長度來構建樣本。這一操作的目標是為后續的模型訓練提供合適的數據形式,使模型能夠學習到時間序列中的規律和特征。
- 歸一化與去趨勢:為了讓數據更適合模型訓練,我們對每個變量進行 Z-score 標準化處理。這種標準化方法能夠將數據轉化為均值為 0、標準差為 1 的標準形式,有助于提升模型的訓練效果和穩定性。
- 變量相關性分析:計算皮爾遜相關系數矩陣是分析變量之間相關性的重要手段。通過這個矩陣,我們可以判斷哪些變量之間關系緊密,進而選擇對預測結果有重要影響的輸入變量,去除那些相關性較低的變量,提高模型的效率和預測準確性。
模型融合策略
- 加權平均(Weighted Averaging):這是一種直觀且簡單的模型融合方法,它的優點是所需的參數較少。在融合多個模型的預測結果時,為每個模型分配一個權重,然后根據這些權重對各模型的預測值進行加權求和,得到最終的預測結果。權重的選擇可以通過交叉驗證等方式進行調優,以達到最佳的融合效果。
- 堆疊泛化(Stacking):該方法分為兩層進行模型融合。在第一層,使用 Transformer、隨機森林(RF)等不同模型分別對數據進行處理并輸出預測結果。然后,在第二層使用元學習器,例如線性回歸模型或小型多層感知機(MLP)。具體操作是,先通過交叉驗證的方式獲得第一層各個模型對驗證集的預測結果,再利用這些結果來訓練元學習器,使元學習器能夠學習到不同模型預測結果之間的關系,從而更好地融合這些結果,提升整體的預測性能。
- 誤差協方差分析:誤差協方差分析用于評估不同模型之間的互補性。如果兩個模型的誤差相關性較低,說明它們在預測過程中犯錯誤的情況有所不同,這種情況下將它們融合,往往能獲得更好的預測效果。因為不同模型可以在不同方面發揮優勢,相互補充,減少整體的預測誤差。
小結
| 模塊 | 關鍵組件 | 細節要點 |
|---|---|---|
| 序列預處理 | 滑動窗口、歸一化、相關性分析 | 利用滑動窗口構造樣本,通過 Z-score 進行標準化,借助皮爾遜相關矩陣篩選特征 |
| Transformer 編碼器 | 位置編碼(PosEnc)、多頭注意力、前饋神經網絡(FFN)、層歸一化(LayerNorm) | 采用正余弦位置編碼,利用防未來信息掩碼避免信息泄露,結合殘差連接和歸一化;多頭注意力并行捕捉多尺度依賴關系;逐位置前饋網絡增強模型的非線性表達能力 |
| 隨機森林回歸 | 自助采樣(Bootstrap)、分類與回歸樹(CART)分裂、子特征隨機選擇 | 樹間差異源于有放回采樣和特征隨機子集;回歸樹依據最小化節點內均方誤差(MSE)進行分裂;通過平均化減少預測方差 |
| 融合策略 | 加權平均、堆疊泛化、誤差協方差分析 | 加權平均的系數可通過交叉驗證調優;堆疊泛化借助元學習器捕獲二級特征;誤差協方差分析揭示模型間的互補性 |
| 評估指標 | 均方誤差(MSE)、均方根誤差(RMSE)、平均絕對誤差(MAE)、平均絕對百分比誤差(MAPE)、多變量加權評估 | MSE 對大誤差較為敏感,MAE 更穩健,MAPE 以百分比形式呈現便于解讀,多變量加權評估可綜合考慮不同變量的重要性進行全面評估 |
在這里,我們將基于 Transformer 與隨機森林的集成方法,開展多變量時間序列的預測任務。為了更便捷地展示整個過程,我們使用虛擬數據集來完成數據生成、模型訓練、預測、評估等環節,同時還會生成多種可視化圖形,以此深入分析模型的表現,最后給出算法的優化要點和調參流程。
1. 數據集 & 預處理
為構建一個多變量時間序列數據集,我們生成包含三個變量的虛擬時間序列數據。其中一個變量是呈周期性變化的正弦波,一個是余弦波,還有一個是添加了噪聲的隨機信號。具體代碼如下:
# 生成虛擬多變量時間序列數據:3個變量,長度為T
import numpy as np
T = 1200 # 時間步數
t = np.arange(T)
x1 = np.sin(0.02 * t) # 正弦波
x2 = np.cos(0.02 * t) # 余弦波
x3 = 0.1 * np.random.randn(T) # 高斯噪聲# 數據合并,形狀為(T, 3)
data = np.stack([x1, x2, x3], axis=1)接下來,對生成的數據進行標準化處理(Z-score),使數據具有統一的尺度,便于后續模型訓練。
from sklearn.preprocessing import StandardScaler
# 標準化處理(Z-score)
scaler = StandardScaler()
data_norm = scaler.fit_transform(data) # 標準化后的數據數據集拆分與窗口化
我們把時間序列數據拆分成滑動窗口樣本,進而生成訓練集和測試集。在這個過程中,我們構建特征數據X和目標數據Y:
window_size = 30 # 假設窗口大小為30
horizon = 1 # 預測步長為1
X, Y = [], []
for i in range(T - window_size - horizon + 1):X.append(data_norm[i:i + window_size]) # 選擇窗口內的數據Y.append(data_norm[i + window_size:i + window_size + horizon]) # 預測窗口后的數據
X = np.array(X) # shape: (samples, window_size, features)
Y = np.array(Y).squeeze(axis=1) # shape: (samples, features)# 劃分訓練集與測試集
train_ratio = 0.8
n_train = int(len(X) * train_ratio)
X_train, X_test = X[:n_train], X[n_train:]
Y_train, Y_test = Y[:n_train], Y[n_train:]# 轉換為PyTorch Tensor
import torch
from torch.utils.data import TensorDataset, DataLoader
X_train_t = torch.tensor(X_train, dtype=torch.float32)
Y_train_t = torch.tensor(Y_train, dtype=torch.float32)
X_test_t = torch.tensor(X_test, dtype=torch.float32)
Y_test_t = torch.tensor(Y_test, dtype=torch.float32)train_dataset = TensorDataset(X_train_t, Y_train_t)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True)可視化數據
我們先繪制數據集的原始圖形,以此清晰展示三個變量的時間序列變化情況。
import matplotlib.pyplot as plt
# 可視化原始數據
plt.figure(figsize=(12, 6))
plt.plot(t, data_norm[:, 0], label='Var1', color='magenta')
plt.plot(t, data_norm[:, 1], label='Var2', color='cyan')
plt.plot(t, data_norm[:, 2], label='Var3', color='lime')
plt.title("Raw Multivariate Time Series")
plt.xlabel("Time")
plt.ylabel("Normalized Value")
plt.legend()
plt.show()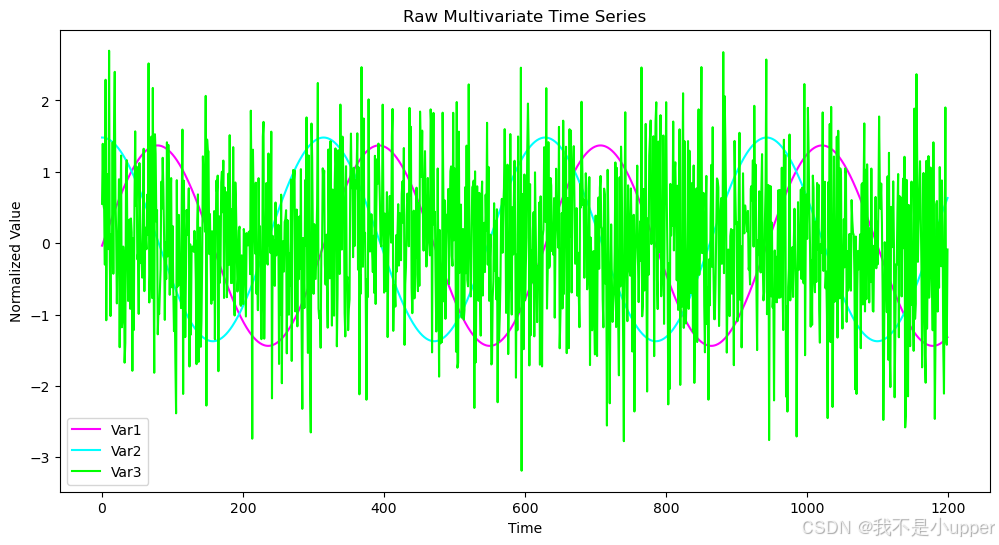
可視化展示的橫坐標是時間(Time),從 0 到 1200,代表時間步數;縱坐標是標準化后的值(Normalized Value) ,范圍從 - 3 到 2 。圖中有三條線,紫色線代表 Var1,是一條正弦波曲線,呈現周期性波動;藍色線代表 Var2,是余弦波曲線,也呈周期性波動,但和正弦波有相位差;綠色線代表 Var3,是加了高斯噪聲的隨機信號,波動非常劇烈且雜亂無章,不像前兩條線那樣有明顯規律 。?
2. Transformer 模型實現
Transformer 回歸模型
Transformer 模型借助自注意力機制,能有效捕捉序列中的長期依賴關系。我們使用 PyTorch 搭建一個簡潔的 Transformer Encoder 架構。代碼如下:
# Transformer回歸模型
import torch
import torch.nn as nn
import mathclass TransformerRegressor(nn.Module):def __init__(self, input_dim, d_model, nhead, num_layers, dim_feedforward):super().__init__()# 輸入映射層self.input_linear = nn.Linear(input_dim, d_model)# Transformer編碼器層encoder_layer = nn.TransformerEncoderLayer(d_model=d_model, nhead=nhead, dim_feedforward=dim_feedforward)self.transformer = nn.TransformerEncoder(encoder_layer, num_layers=num_layers)# 輸出映射層self.output_linear = nn.Linear(d_model, input_dim)def forward(self, src):x = self.input_linear(src) * math.sqrt(self.input_linear.out_features) # 線性變換x = x.permute(1, 0, 2) # 轉置為 (seq_len, batch, d_model)x = self.transformer(x) # Transformer編碼x = x.mean(dim=0) # 平均池化 (batch, d_model)return self.output_linear(x) # 預測輸出 (batch, input_dim)在這個模型中,input_linear負責將輸入數據映射到指定維度,transformer進行核心的編碼操作,output_linear則輸出預測結果。
模型訓練
接下來定義訓練所需參數并開始訓練模型:
# 定義訓練參數
input_dim = 3
model = TransformerRegressor(input_dim, d_model=64, nhead=4, num_layers=2, dim_feedforward=128)
optimizer = torch.optim.Adam(model.parameters(), lr=0.001)
criterion = nn.MSELoss()# 訓練模型
num_epochs = 50
loss_list = []model.train()
for epoch in range(1, num_epochs+1):epoch_loss = 0.0for xb, yb in train_loader:optimizer.zero_grad()pred = model(xb)loss = criterion(pred, yb)loss.backward()optimizer.step()epoch_loss += loss.item() * xb.size(0)epoch_loss /= len(train_loader.dataset)loss_list.append(epoch_loss)if epoch % 10 == 0:print(f"Epoch {epoch}/{num_epochs}, Loss: {epoch_loss:.4f}")
這里,我們設置了模型的具體參數,選用 Adam 優化器和均方誤差損失函數(MSELoss) 。在訓練循環中,每個 epoch 都會計算平均損失,并記錄下來,方便后續觀察模型訓練情況。
3. 隨機森林模型實現
隨機森林回歸器
對于隨機森林模型,我們先對數據進行預處理,然后訓練和預測:
# 隨機森林訓練與預測
from sklearn.ensemble import RandomForestRegressor
from sklearn.metrics import mean_squared_error, mean_absolute_error
import numpy as npX_rf_train = X_train.reshape(n_train, -1)
X_rf_test = X_test.reshape(len(X_test), -1)rf = RandomForestRegressor(n_estimators=200, max_depth=12, random_state=42)
rf.fit(X_rf_train, Y_train)
rf_pred = rf.predict(X_rf_test)這里將訓練數據和測試數據調整為適合隨機森林模型輸入的形狀,然后使用指定參數訓練隨機森林回歸器,并得到測試集上的預測結果。
評估模型性能
通過計算均方誤差(MSE)和平均絕對誤差(MAE)來衡量 Transformer 模型和隨機森林模型在測試集上的表現:
# model是已經訓練好的TransformerRegressor模型,X_test_t是測試集數據
model.eval() # 將模型設置為評估模式
with torch.no_grad(): # 不計算梯度,節省內存并加快計算tf_pred_test = model(X_test_t).cpu().numpy() # 對測試集進行預測并轉換為numpy數組mse_tf = mean_squared_error(Y_test, tf_pred_test)
mae_tf = mean_absolute_error(Y_test, tf_pred_test)
mse_rf = mean_squared_error(Y_test, rf_pred)
mae_rf = mean_absolute_error(Y_test, rf_pred)print(f"Transformer -> MSE: {mse_tf:.4f}, MAE: {mae_tf:.4f}")
print(f"Random Forest -> MSE: {mse_rf:.4f}, MAE: {mae_rf:.4f}")通過調整加權系數alpha,綜合兩個模型的優勢,得到集成模型的預測結果,并再次計算評估指標,判斷融合效果。?
 ?從輸出結果看,Transformer 模型的均方誤差(MSE)為 0.3988 ,平均絕對誤差(MAE)為 0.3221 ;隨機森林模型的 MSE 是 0.3889 ,MAE 是 0.3071 。這表明在這個多變量時間序列預測任務中,隨機森林模型在衡量預測值與真實值偏離程度的 MSE 和 MAE 指標上,表現略優于 Transformer 模型 ,即隨機森林模型的預測值相對更接近真實值 。
?從輸出結果看,Transformer 模型的均方誤差(MSE)為 0.3988 ,平均絕對誤差(MAE)為 0.3221 ;隨機森林模型的 MSE 是 0.3889 ,MAE 是 0.3071 。這表明在這個多變量時間序列預測任務中,隨機森林模型在衡量預測值與真實值偏離程度的 MSE 和 MAE 指標上,表現略優于 Transformer 模型 ,即隨機森林模型的預測值相對更接近真實值 。
5. 可視化分析
原始數據可視化
為了更好地理解數據的變化趨勢,我們再次展示標準化后的多變量時間序列:
import matplotlib.pyplot as pltplt.figure(figsize=(12, 6))
plt.plot(t, data_norm[:, 0], label='Var1', color='magenta')
plt.plot(t, data_norm[:, 1], label='Var2', color='cyan')
plt.plot(t, data_norm[:, 2], label='Var3', color='lime')
plt.title("Raw Multivariate Time Series")
plt.xlabel("Time")
plt.ylabel("Normalized Value")
plt.legend()
plt.show()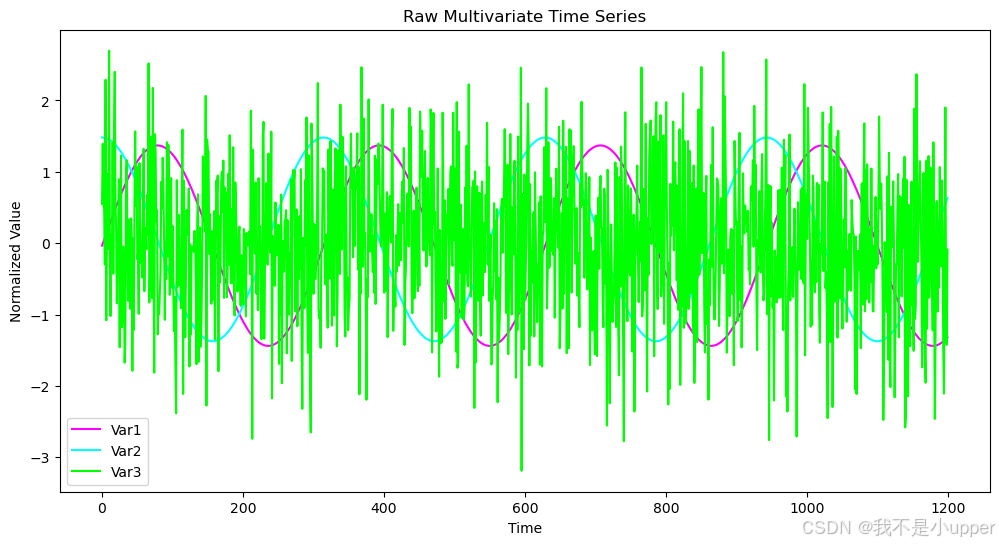
這張圖展示了標準化后的多變量時間序列,橫坐標為時間,從 0 到 1200,縱坐標是標準化值。紫色線代表 Var1,是正弦波,呈現周期性起伏;藍色線是 Var2,為余弦波,同樣周期性波動,和正弦波有相位差異;綠色線的 Var3 是加了高斯噪聲的隨機信號,波動劇烈且無明顯規律。通過該圖能直觀看到各變量的變化特征,Var1 和 Var2 的周期性可幫助預測,而 Var3 的隨機性增加了預測難度 。?
Transformer 訓練損失曲線
為了觀察 Transformer 模型的收斂情況,我們繪制其訓練損失曲線。具體代碼如下:
import matplotlib.pyplot as pltplt.figure(figsize=(8, 4))
plt.plot(range(1, num_epochs+1), loss_list, color='orange', label='Train Loss')
plt.title("Transformer Training Loss")
plt.xlabel("Epoch")
plt.ylabel("MSE Loss")
plt.legend()
plt.show()運行后得到一張直方圖,橫坐標是預測誤差,縱坐標是誤差出現的頻率。通過觀察直方圖的形狀和分布,我們可以了解融合模型預測誤差的集中程度和離散情況。比如,如果直方圖呈現近似正態分布,說明誤差分布相對穩定;若存在長尾或異常值,可能表示模型在某些情況下預測效果不佳,需要進一步分析和改進。?
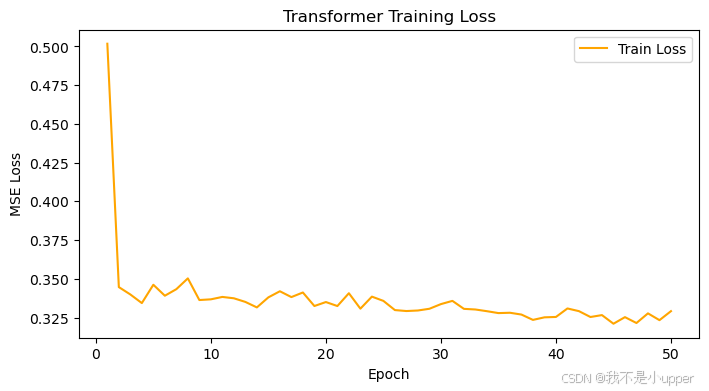
圖中輸出的是 Transformer 模型的訓練損失曲線。橫坐標是訓練輪次(Epoch),從 0 到 50 ,縱坐標是均方誤差損失(MSE Loss) 。可以看到,在訓練初期,損失值從接近 0.5 迅速下降,隨后在不同輪次間有小幅度波動。整體趨勢是逐漸降低并趨于平穩,說明 Transformer 模型在訓練過程中不斷學習,盡管過程中有起伏,但最終損失穩定在一定范圍內,模型在朝著收斂方向發展。?
?
真實與預測值對比(融合模型)
我們來展示融合模型(Transformer 和隨機森林融合)的預測結果與真實值的對比情況。代碼如下:
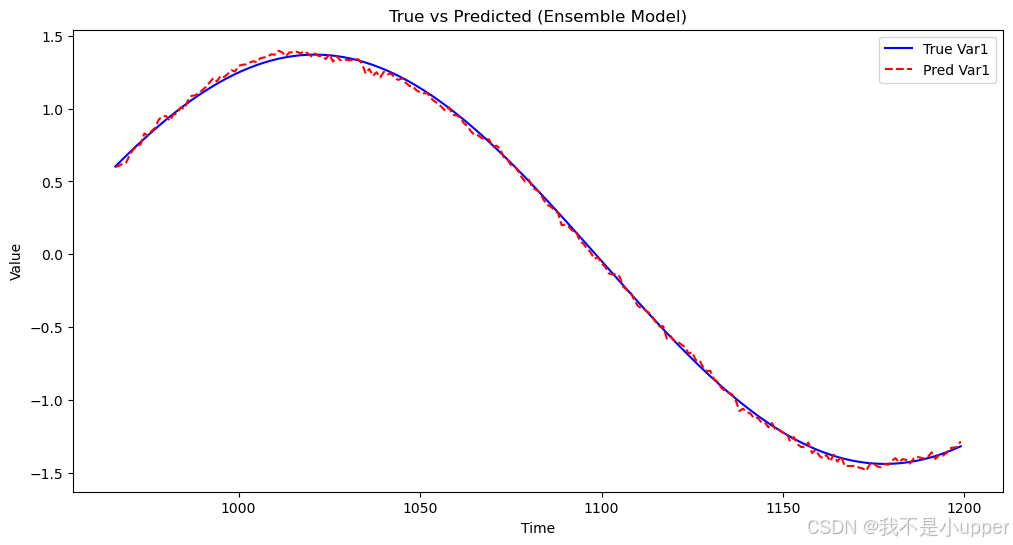
plt.figure(figsize=(12, 6))
plt.plot(np.arange(n_train+window_size, T-horizon+1), Y_test[:, 0], color='blue', label='True Var1')
plt.plot(np.arange(n_train+window_size, T-horizon+1), ensemble_pred[:, 0], color='red', linestyle='--', label='Pred Var1')
plt.title("True vs Predicted (Ensemble Model)")
plt.xlabel("Time")
plt.ylabel("Value")
plt.legend()
plt.show()執行后得到一張折線圖,橫坐標是時間,縱坐標是變量的值。藍色實線代表真實值(True Var1),紅色虛線代表融合模型的預測值(Pred Var1) 。通過對比這兩條線,我們可以直觀地看出融合模型的預測效果。如果兩條線貼合度高,說明模型預測準確;若偏差較大,則表明模型在預測該變量時存在一定誤差。?
 ?
?
隨機森林特征重要性
為了了解隨機森林模型中各個特征的貢獻情況,也就是哪些歷史數據對預測最重要,我們繪制特征重要性圖,代碼如下:
importances = rf.feature_importances_
indices = np.argsort(importances)[-10:]
plt.figure(figsize=(8, 6))
plt.barh(range(len(indices)), importances[indices], color='teal')
plt.yticks(range(len(indices)), [f"Feature {i}" for i in indices])
plt.title("Random Forest Feature Importances")
plt.xlabel("Importance")
plt.ylabel("Feature")
plt.show()這會生成下圖的橫向條形圖,橫坐標是特征的重要性程度,縱坐標是特征編號。條形的長度代表對應特征的重要性,越長說明該特征對隨機森林模型的預測越關鍵。通過這張圖,我們可以清晰地看到不同特征在模型中的重要程度,有助于進一步優化模型和理解數據。?
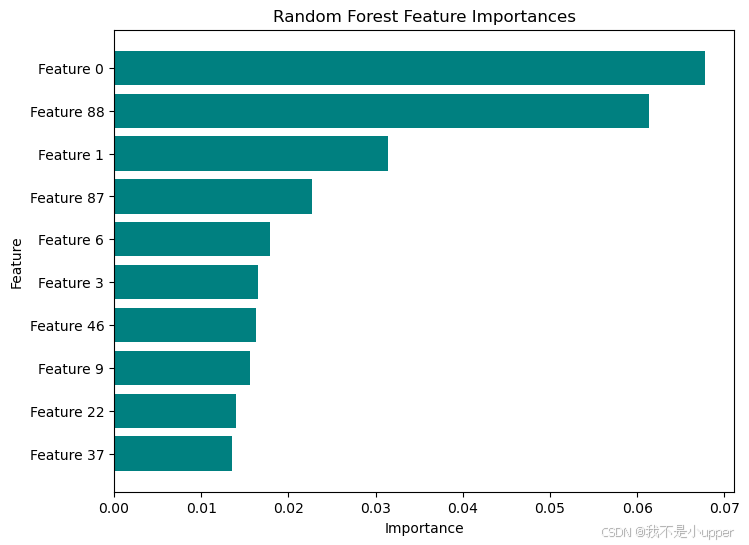 可以看出上圖展示了不同特征對模型預測的貢獻。橫坐標是重要性數值,縱坐標是特征編號。可見,Feature 0 和 Feature 88 重要性較高,對預測影響大;其余特征重要性相對較低。?
可以看出上圖展示了不同特征對模型預測的貢獻。橫坐標是重要性數值,縱坐標是特征編號。可見,Feature 0 和 Feature 88 重要性較高,對預測影響大;其余特征重要性相對較低。?
融合模型誤差分布
我們通過繪制誤差的直方圖來分析融合模型預測誤差的分布情況,代碼如下:
errors = ensemble_pred.flatten() - Y_test.flatten()
plt.figure(figsize=(8, 6))
plt.hist(errors, bins=30, color='violet', edgecolor='black')
plt.title("Error Distribution (Ensemble)")
plt.xlabel("Prediction Error")
plt.ylabel("Frequency")
plt.show()本代碼運行后輸出一張直方圖,橫坐標是預測誤差,縱坐標是誤差出現的頻率。通過觀察直方圖的形狀和分布,我們可以了解融合模型預測誤差的集中程度和離散情況。比如,如果直方圖呈現近似正態分布,說明誤差分布相對穩定;若存在長尾或異常值,可能表示模型在某些情況下預測效果不佳,需要進一步分析和改進。?
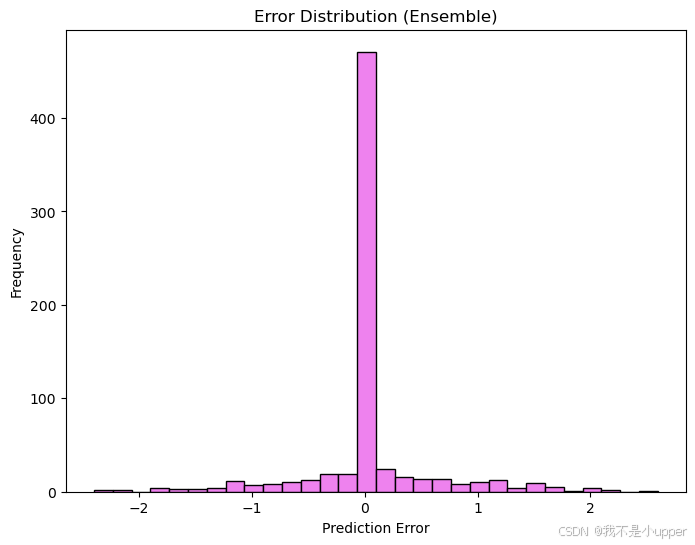
橫坐標為預測誤差,縱坐標是誤差出現的頻率。圖中顯示,大部分誤差集中在 0 附近,說明融合模型的預測值與真實值較為接近,模型預測效果較好 ,僅有少量誤差分布在遠離 0 的兩側,表明模型在少數情況下會出現較大偏差 。?
6. 算法優化點與調參流程
融合策略優化
- 加權系數調優:可運用網格搜索或交叉驗證等方法,對加權系數
alpha進行精細調節,以找出能使融合模型性能最優的取值。 - 堆疊(Stacking):在融合模型中,嘗試采用更復雜的回歸器,如 XGBoost、Lasso 等,取代簡單的線性回歸或小型 MLP,從而更精準地學習不同模型間的最優組合方式。
調參流程
- 基線評估:率先針對單獨的 Transformer 模型和隨機森林(RF)模型進行調參,確定它們各自的基礎性能表現,為后續融合模型的優化提供參照。
- 組合調參:在明確基線模型性能的前提下,對加權系數
alpha進行調節,優化加權平均融合效果;或者引入堆疊模型,進一步挖掘提升模型整體性能的潛力。 - 交叉驗證:在模型訓練階段,采用 k 折交叉驗證法,全面評估模型的泛化能力,確保模型在不同數據子集上都能有穩定的表現。
- 模型監控與調整:密切關注訓練過程中損失值的變化情況,依據變化趨勢,及時、適當地調整模型結構或超參數,使模型始終保持良好的訓練狀態。
本案例完整呈現了基于 Transformer 與隨機森林的多變量時間序列預測過程,涵蓋數據生成、模型訓練、評估以及優化等各個環節。通過數據可視化和模型分析,我們能夠深入理解模型的實際表現,并據此對模型進行針對性的調整與優化。











)






 -part8)
 和 逐字字符串(@) 功能)