文章目錄
- 機器學習中的"防過擬合神器":正則化全解析
- 1. 正則化:不只是"規矩"那么簡單
- 1.1 魯棒性案例說明
- 2. L1正則化:冷酷的特征選擇器
- 3. L2正則化:溫柔的約束者
- 4. L1 vs L2:兄弟間的較量
- 5. 正則化的超參數調優
- 6. 正則化的數學直覺
- 7. 常見誤區
- 8. 總結
機器學習中的"防過擬合神器":正則化全解析
1. 正則化:不只是"規矩"那么簡單
-
想象一下,你正在教一個特別勤奮但有點死板的學生學習數學。這個學生能把所有例題背得滾瓜爛熟,但遇到稍微變化的新題目就束手無策——這就是機器學習中的**過擬合(Overfitting)**現象。
-
正則化(Regularization)就是給這個"過于勤奮"的模型制定一些"規矩",防止它過度記憶訓練數據中的噪聲和細節,從而提高泛化能力。簡單說,正則化就是在損失函數中額外添加一個懲罰項,讓模型參數不要變得太大。
-
正則化就是防止過擬合,增加模型的魯棒性robust。魯棒性調優就是讓模型擁有更好的魯棒性,也就是讓模型的泛化能力和推廣能力更加的強大。
1.1 魯棒性案例說明
- 下面兩個式子描述同一條直線那個更好?
0.5 x 1 + 0.4 x 2 + 0.3 = 0 5 x 1 + 4 x 2 + 3 = 0 0.5x_1+0.4x_2+0.3=0 \\ 5x_1+4x_2+3=0 0.5x1?+0.4x2?+0.3=05x1?+4x2?+3=0 - 第一個更好,因為下面的公式是上面的十倍,當w越小公式的容錯的能力就越好。因為把測試集帶入公式中如果測試集原來是100在帶入的時候發生了一些偏差,比如說變成了101,第二個模型結果就會比第一個模型結果的偏差大的多。公式中
y ^ = w T x \hat y=w^Tx y^?=wTx當x有一點錯誤,這個錯誤會通過w放大從而影響z。但w也不能太小,當w太小時正確率就無法保證,就沒法做分類。想要有一定的容錯率又要保證正確率就要由正則項來決定。 - 所以正則化(魯棒性調優)的本質就是犧牲模型在訓練集上的正確率來提高推廣能力,W在數值上越小越好,這樣能抵抗數值的擾動。同時為保證模型的正確率W又不能極小。故而人們將原來的損失函數加上一個懲罰項,這里面損失函數就是原來固有的損失函數,比如回歸的話通常是MSE,然后在加上一部分懲罰項來使得計算出來的模型W相對小一些來帶來泛化能力。
- 常用的懲罰項有L1正則項或者L2正則項
L 1 = ∑ i = 0 m ∣ w i ∣ L 2 = ∑ i = 0 m w i 2 L_1=\sum_{i=0}^m|w_i| \\ L_2=\sum_{i=0}^m w_{i}^{2} L1?=i=0∑m?∣wi?∣L2?=i=0∑m?wi2? - L1和L2正則的公式數學里面的意義就是范數,代表空間中向量到原點的距離
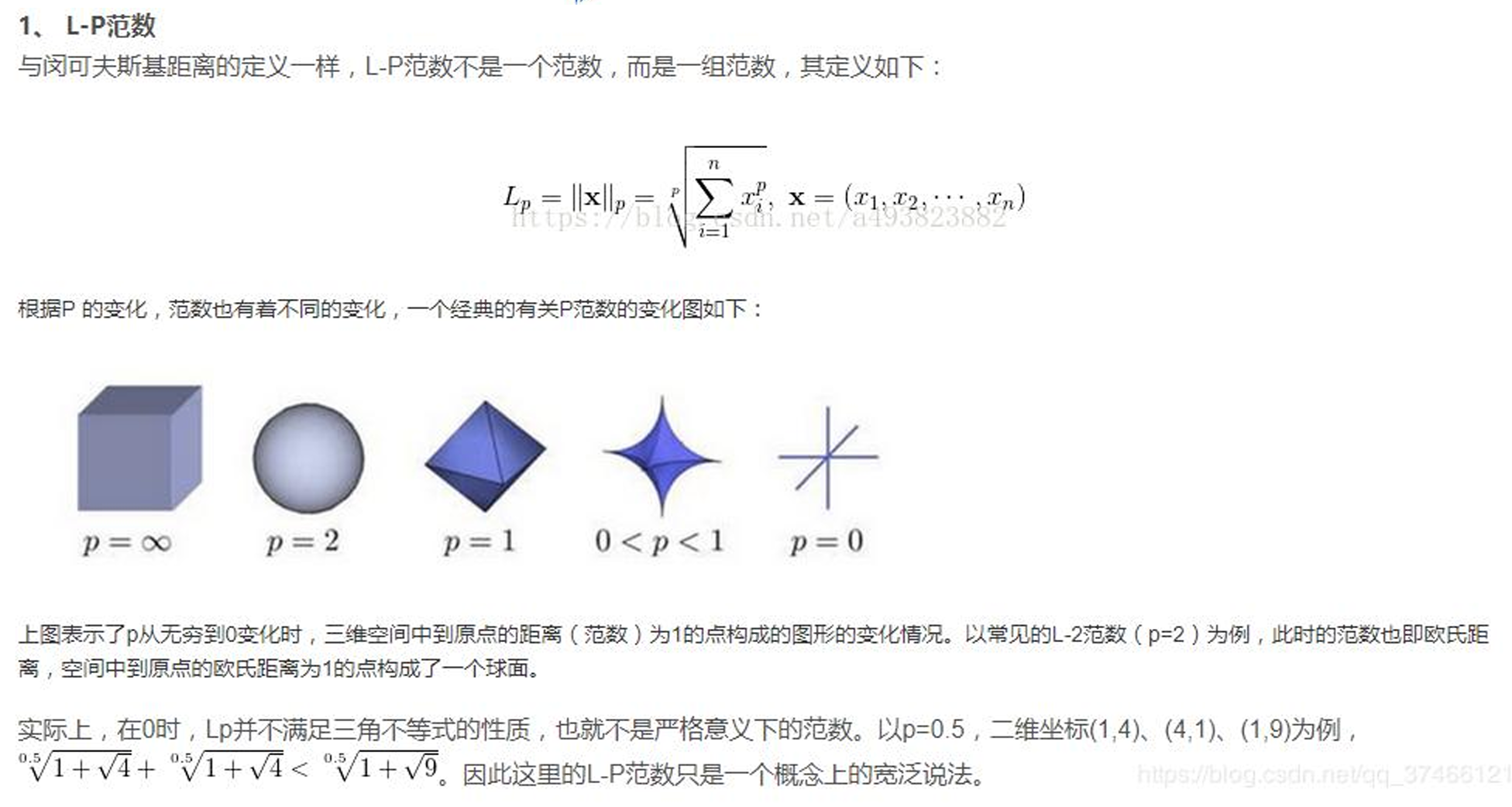
2. L1正則化:冷酷的特征選擇器
- L1正則化,又稱Lasso回歸,它在損失函數中添加的是模型權重的絕對值和:
損失函數 = 原始損失 + λ * Σ|權重|
特點:
-
傾向于產生稀疏解(許多權重精確為0)
-
自動執行特征選擇
-
對異常值敏感
-
在零點不可導
-
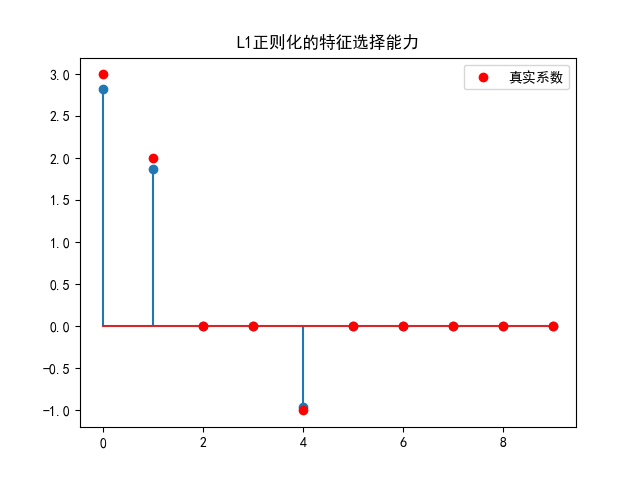
L1正則化自動選擇重要特征:
import numpy as np
import matplotlib.pyplot as plt
from sklearn.linear_model import Lasso# 設置支持中文的字體
# 使用SimHei字體,這是一種常見的中文字體,能夠正確顯示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解決負號顯示問題,確保在圖表中正確顯示負號
plt.rcParams['axes.unicode_minus'] = False# 生成一些數據,其中只有3個特征真正有用
# 設置隨機種子以確保結果可重復
np.random.seed(42)
# 生成100個樣本,每個樣本有10個特征的隨機數據
X = np.random.randn(100, 10)
# 定義真實系數,只有前3個和第5個特征有用
true_coef = [3, 2, 0, 0, -1, 0, 0, 0, 0, 0]
# 生成目標變量y,通過線性組合X和true_coef,并添加一些噪聲
y = np.dot(X, true_coef) + np.random.normal(0, 0.5, 100)# 使用L1正則化(Lasso回歸)
# 創建Lasso模型實例,設置正則化參數alpha
lasso = Lasso(alpha=0.1)
# 使用生成的數據擬合模型
lasso.fit(X, y)# 查看學到的系數
# 使用stem圖顯示Lasso模型學到的系數
plt.stem(range(10), lasso.coef_)
# 在同一圖表上繪制真實系數,用紅色圓圈標記
plt.plot(range(10), true_coef, 'ro', label='真實系數')
# 添加圖例
plt.legend()
# 設置圖表標題
plt.title('L1正則化的特征選擇能力')
# 顯示圖表
plt.show()
- 你會驚訝地發現,Lasso幾乎完美地識別出了哪些特征真正重要,哪些可以忽略!
3. L2正則化:溫柔的約束者
- L2正則化,又稱權重衰減(Weight Decay)或嶺回歸(Ridge Regression),它在損失函數中添加了模型權重的平方和作為懲罰項:
損失函數 = 原始損失 + λ * Σ(權重2)
其中λ是正則化強度,控制懲罰的力度。
特點:
- 使權重趨向于小而分散的值
- 對異常值不敏感
- 數學性質良好,總是可導
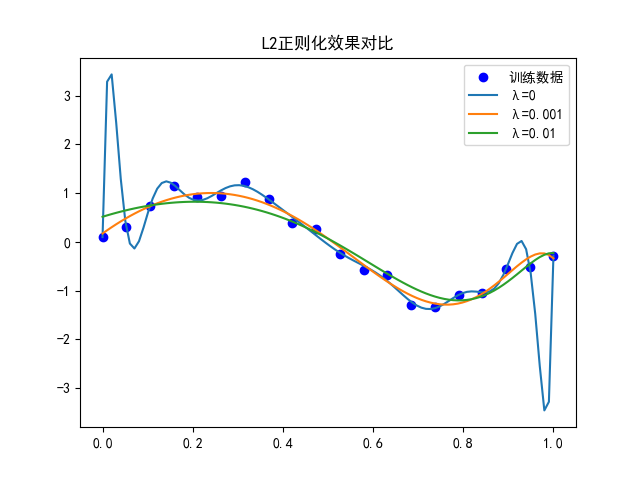
L2正則化在行動:
import numpy as np
from sklearn.linear_model import Ridge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures
import matplotlib.pyplot as plt# 設置支持中文的字體
# 使用SimHei字體,這是一種常見的中文字體,能夠正確顯示中文字符
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解決負號顯示問題,確保在圖表中正確顯示負號
plt.rcParams['axes.unicode_minus'] = False# 生成一些帶噪聲的數據
np.random.seed(42)
X = np.linspace(0, 1, 20)
y = np.sin(2 * np.pi * X) + np.random.normal(0, 0.2, 20)# 準備不同階數的多項式特征
X_test = np.linspace(0, 1, 100)
plt.scatter(X, y, color='blue', label='訓練數據')# 對比不同正則化強度
for alpha in [0, 0.001, 0.01]:model = make_pipeline(PolynomialFeatures(15),Ridge(alpha=alpha))model.fit(X[:, np.newaxis], y)y_test = model.predict(X_test[:, np.newaxis])plt.plot(X_test, y_test, label=f'λ={alpha}')plt.legend()
plt.title('L2正則化效果對比')
plt.show()
- 運行這段代碼,你會看到隨著λ增大,曲線從過擬合(完美擬合噪聲)逐漸變得平滑,更接近真實的sin函數形狀。
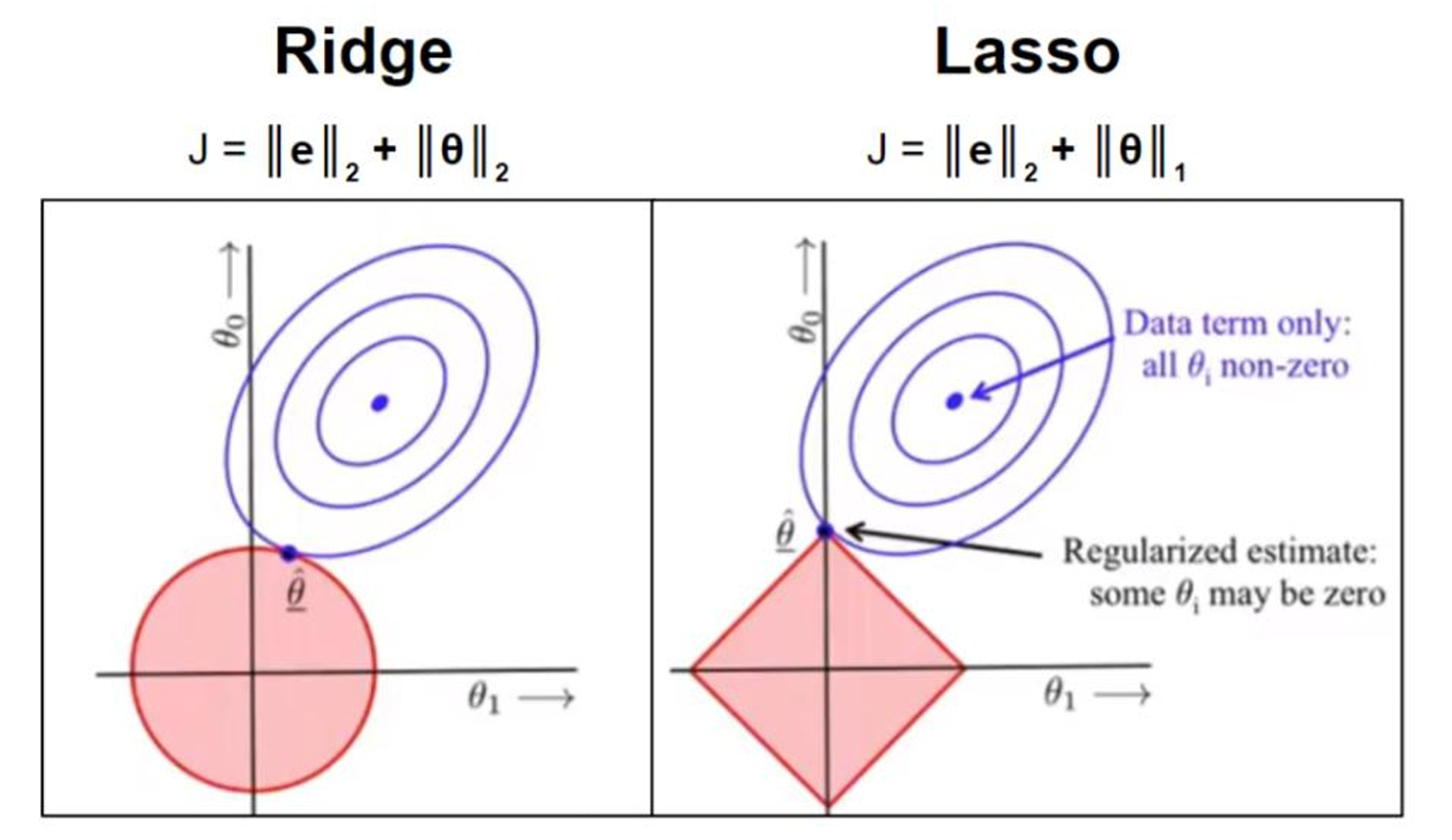
4. L1 vs L2:兄弟間的較量
| 特性 | L1正則化 | L2正則化 |
|---|---|---|
| 懲罰項 | Σ | w |
| 解的性質 | 稀疏 | 非稀疏 |
| 特征選擇 | 是 | 否 |
| 計算復雜度 | 高(需特殊優化) | 低 |
| 對異常值 | 敏感 | 不敏感 |
經驗法則:
- 當特征很多且認為只有少數重要時 → 用L1
- 當所有特征都可能相關且重要性相當時 → 用L2
- 不確定時 → 用ElasticNet(兩者結合)
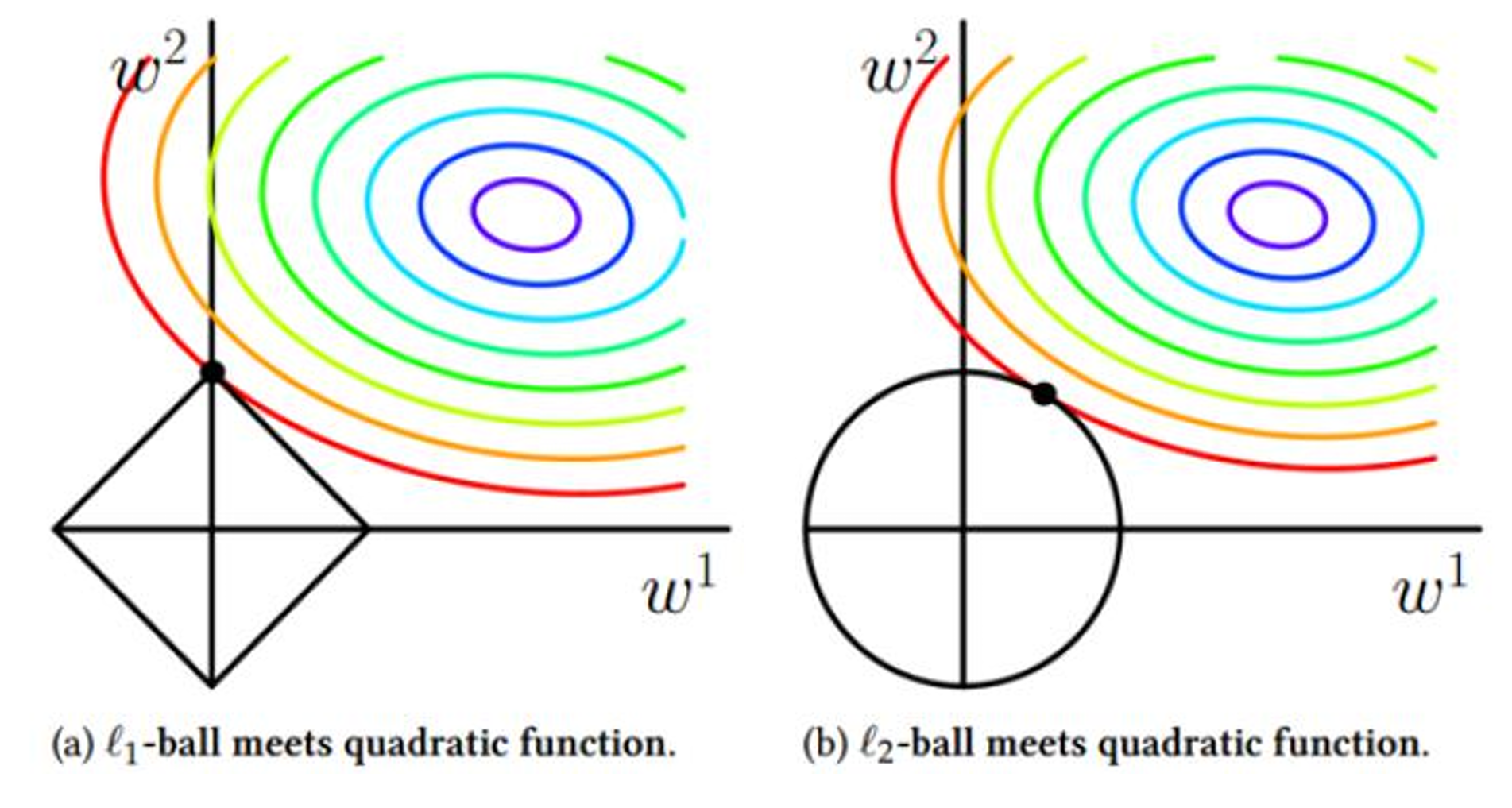
- L 1 L_1 L1?更容易相交于坐標軸上,而 L 2 L_2 L2?更容易相交于非坐標軸上。如果相交于坐標軸上,如圖 L 1 L_1 L1?就使得是 W 2 W_2 W2?非0, W 1 W_1 W1?是0,這個就體現出 L 1 L_1 L1?的稀疏性。如果沒相交于坐標軸,那 L 2 L_2 L2?就使得W整體變小。通常為去提高模型的泛化能力 L 1 L_1 L1?和 L 2 L_2 L2?都可以使用。 L 1 L_1 L1?的稀疏性在做機器學習的時候,可以幫忙去做特征的選擇。
5. 正則化的超參數調優
選擇正確的λ值至關重要:
- λ太大 → 欠擬合(模型太簡單)
- λ太小 → 過擬合(模型太復雜)
可以使用交叉驗證來尋找最佳λ:
from sklearn.linear_model import LassoCV# 使用LassoCV自動選擇最佳alpha
lasso_cv = LassoCV(alphas=np.logspace(-4, 0, 20), cv=5)
lasso_cv.fit(X, y)print(f"最佳alpha值: {lasso_cv.alpha_}")
6. 正則化的數學直覺
為什么限制權重大小能防止過擬合?想象模型是一個畫家:
- 沒有正則化:畫家可以用極其精細的筆觸(大權重)來完美復制訓練數據中的每個細節(包括噪聲)
- 有正則化:畫家被迫用更粗的筆觸(小權重),不得不忽略一些細節,從而捕捉更一般的模式
7. 常見誤區
誤區:
- 認為正則化可以完全替代更多的訓練數據
- 在所有特征上使用相同的正則化強度
- 忽略特征縮放(正則化對尺度敏感!
8. 總結
- 正則化就像給模型戴上的"緊箍咒",看似限制了模型的自由,實則讓它更加專注和高效。記住,在機器學習中,有時候"約束"反而能帶來"解放"——解放模型從訓練數據的桎梏中解脫出來,獲得更好的泛化能力。


)



:從源碼出發,探索多模態VL模型的推理全流程)




 | GmaGIS V0.0.1a3 更新日志)







