24年10月來自紐約大學的論文“Bridging the Human to Robot Dexterity Gap through Object-Oriented Rewards”。
直接通過人類視頻訓練機器人是機器人技術和計算機視覺領域的一個新興領域。盡管雙指機械手在雙指夾持器方面取得了顯著進展,但以這種方式讓多指機械手學習自主任務仍然充滿挑戰。造成這一困難的一個關鍵原因是,由于形態差異,在人手上訓練的策略可能無法直接遷移到機械手上。本研究提出 HUDOR 技術,它能夠通過直接從人類視頻中計算獎勵來在線微調策略。重要的是,該獎勵函數基于從現成的點跟蹤器中獲取的面向目標軌跡構建,即使人手和機械手之間存在形態差異和視覺差異,也能提供有意義的學習信號。給定一段人類解決任務(例如輕輕打開音樂盒)的視頻,HUDOR 能夠讓四指 Allegro 機械手僅通過一小時的在線交互就能學會該任務。在四項任務中的實驗表明,HUDOR 的性能比基線提升 4 倍。
人類在日常生活中能夠毫不費力地完成各種靈巧的任務 [1]。讓機器人具備類似的能力對于它們在現實世界中的有效部署至關重要。為此,最近的進展使得雙指夾持器 [2, 3, 4, 5] 能夠利用從遙控機器人數據中進行的模仿學習 (IL) 來學習多模態、長視界和靈巧的行為。然而,事實證明,將此類方法擴展到多指手的復雜任務具有挑戰性。
將基于遙控操作的學習應用于多指手的挑戰源于兩個關鍵問題。首先,即使是通過這種方式實現中等程度的魯棒性也需要大量數據。涉及雙指夾持器 [6, 7, 8, 9] 的任務通常需要數千次演示來訓練魯棒策略。對于動作維度更大的手以及需要更高精度和靈巧性的任務,這種數據需求可能甚至更大。其次,由于在控制多個自由度時需要低延遲和持續反饋,遙操作多指手提出一個具有挑戰性的系統問題 [10, 11, 12]。這使得收集完成靈巧任務所需的大量數據變得更加困難。
一種繞過遙操作的替代方法,是使用人類執行任務的視頻來為機器人制定策略 [13, 14, 15]。然而,之前的大多數方法都需要額外的遙機器人演示 [16] 或人為干預學習 [17] 來進行微調。這些額外的信息通常是必要的,以彌合人手(如在人類視頻數據中看到的那樣)和機器人手(在機器人交互中觀察的那樣)之間的形態和視覺差異。
機器人靈巧操作學習。學習多指手的靈巧策略一直是一個長期存在的挑戰,并引起機器人學習社區的廣泛關注 [18, 19, 10]。一些研究通過在模擬環境中訓練策略并將其部署到現實世界中來解決這個問題 [20, 19]。盡管這種方法在手部操作方面取得了深刻的成果 [21, 22],但在操作場景中的物體時,縮小模擬與現實之間的差距變得十分困難。其他研究則側重于開發不同的遙操作框架 [23, 24, 11, 25],并使用通過這些框架收集的機器人數據訓練離線策略。雖然這些框架響應速度很快,但由于當前機械手形態不匹配,且遠程操作員缺乏觸覺反饋,在不直接與物體交互的情況下遠程操作靈巧手對用戶來說仍然很困難。
從人類視頻中學習。為了利用更容易獲取的來源擴大數據收集,視覺和機器人社區一直致力于從人類視頻中學習有意義的行為和模式 [31, 32, 33, 34]。一些研究側重于學習模擬器,這些模擬器使用生成模型 [32, 35, 31] 從人類視頻中緊密模擬機器人的真實環境,并使用這些模擬器訓練策略,通過預測潛在的未來結果來做出決策。其他研究則使用互聯網規模的人類視頻來學習更高級的技能或 affordance [33, 36]。然而,這些研究要么需要低級策略來學習與物體交互的動作原語 [33],要么只關注單個接觸點即可完成操作的簡單任務 [36]。還有一些方法利用現場人類視頻來學習多階段規劃 [16, 14],但需要額外的機器人數據來學習低級物體交互。值得注意的是,所有這些研究都集中在雙夾持機器人上,其操縱能力有限,物體的關節較少。一些研究[17, 37, 38]利用多臺攝像機結合手部運動捕捉系統采集的場景內人體視頻,解決靈巧手的這一問題。這些研究要么側重于簡單的抓取任務[38, 37],要么需要針對靈巧任務設置一個帶有人工反饋的在線微調階段[17]。此外,這些方法的離線學習過程需要大量的預處理,以便從環境點云中屏蔽人手。
這項工作提出 HUDOR,一種通過在線模仿學習來彌合人類視頻和機器人策略之間差距的新方法。HUDOR 引入了一個框架,用于從單個場景中的人類任務執行視頻中學習靈巧策略。其方法包含三個步驟:(1)使用 VR 頭戴設備和 RGB 攝像頭錄制人類視頻及其對應的手勢軌跡;(2)使用姿勢變換和全-機器人逆運動學 (IK) 將手勢傳輸到機器人上并執行;(3)使用強化學習 (RL) 成功模仿專家軌跡。如圖所示:
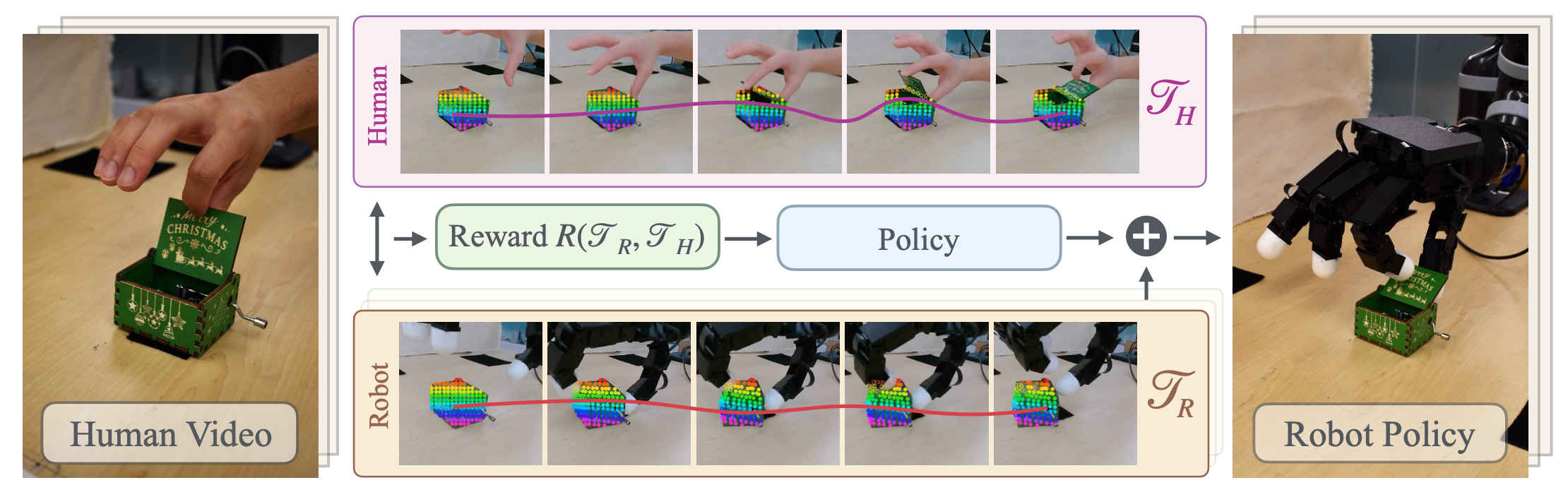
機器人設置和人體數據采集
硬件設置包括一個 Kinova JACO 6 自由度機械臂,以及一個 16 自由度四指 Allegro 手 [10]。兩臺 RealSense RGBD 攝像頭 [39] 放置在手術臺周圍,用于標定和視覺數據采集。Meta Quest 3 VR 頭戴設備用于收集手部姿勢估計值。第一步是計算 VR 框架和機器人框架之間的相對變換,以便將記錄的手部姿勢軌跡從人體視頻直接傳輸到機器人,如圖所示。使用兩個 ArUco 標記點(一個在手術臺上,另一個在 Allegro 手的頂部)來計算相對變換。第一個標記點??用于定義世界框架并將指尖位置從 VR 框架轉換到世界框架,而第二個標記點用于確定機器人底座和世界框架之間的變換。
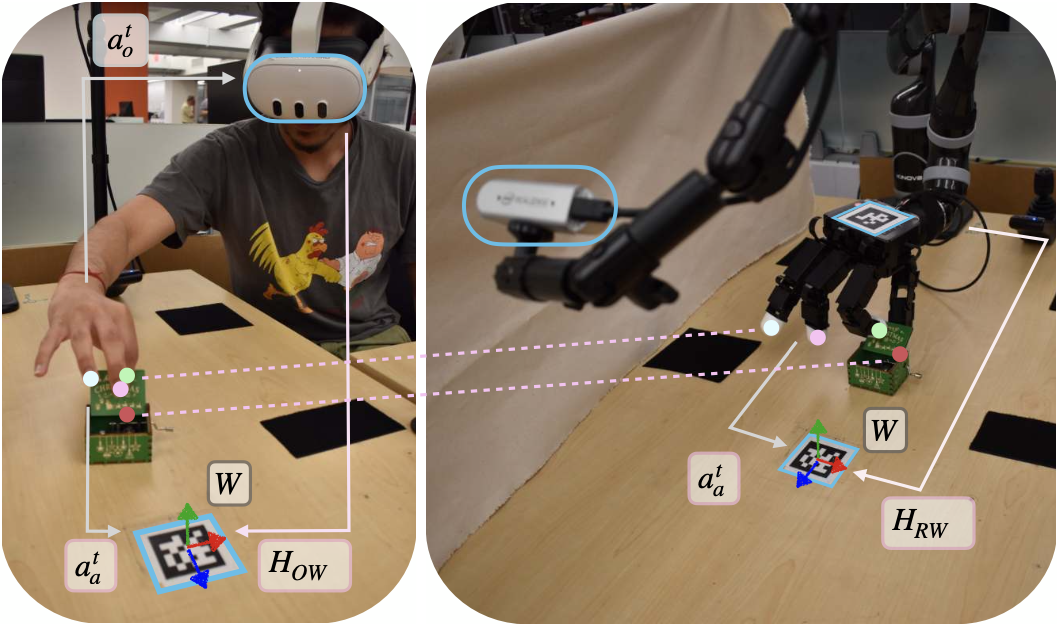
使用 Quest 3 VR 頭戴設備上現有的手勢檢測器收集人類手勢估計值,并使用 RGBD 攝像頭捕捉視覺數據。
使用開發的 VR 應用,用戶可以捏住右手的食指和拇指,開始用自己的手直接與物體交互。收集演示數據后,用戶可以再次捏住手指,表示演示結束。計算演示開始時相對于世界坐標系的手腕姿勢,并在部署過程中將機器人手臂初始化到該初始手腕姿勢。這使得機器人能夠從合適的起始位置開始探索。
在數據收集過程中,會記錄所有 t = 1 … T 的指尖位置 a_rt 和圖像數據 ot,其中 T 是軌跡長度。由于這些分量是以不同的頻率收集的,因此會根據收集的時間戳將它們對齊,從而為每個時間 t 生成同步的三元組 (a_rt, o^t)。然后將數據下采樣至 5 Hz。
為了確保機器人的指尖相對于其底座遵循所需的位置,為整個機器人手臂系統實現一個自定義的逆運動學 (IK) 模塊。該模塊對關節角度使用梯度下降法,利用機器人指尖相對于關節角度的雅可比矩陣,最小化所需指尖位置與當前指尖位置之間的距離 [41]。對于 IK 優化器,對手部和手臂關節應用不同的學習率,使其能夠優先處理手部運動。手部學習率設置為手臂學習率的 50 倍,從而實現更自然、更精確的手指控制。總而言之,IK 模塊將所需的指尖位置 a_rt 以及手部和手臂的當前關節位置 jt 作為輸入,并輸出達到目標所需的下一個關節位置 j?t+1 = I(a_rt, j^t)。
使用上述標定和 IK 程序,機器人手臂系統可以直接從場景中的人體視頻中跟蹤指尖軌跡。如圖展示使用的人類演示。

殘差策略學習
由于人機形態差異以及 VR 手勢估計的誤差,即使物體位于同一位置,單純地在機器人上重放重定位的指尖軌跡通常也無法成功完成任務。為了緩解這個問題,利用強化學習 (RL) 來學習一種在線殘差策略,以增強軌跡重放。傳統的現實世界機器人強化學習算法,依賴于基于圖像的匹配獎勵 [42, 30, 29] 等簡單方法,并使用領域內演示數據得出的獎勵函數。然而,由于人手和機器人手的視覺外觀存在顯著差異,這些方法無法提供有效的獎勵信號。為了彌補這一域差距,提出了一種以目標為中心的軌跡匹配獎勵算法。
a) 目標點跟蹤和軌跡匹配:獎勵計算涉及使用現成的計算機視覺模型來跟蹤感興趣物體上點的運動。計算人類專家視頻中這些點的二維軌跡與機器人策略展開之間的均方誤差,并將其作為在線學習框架中每個時間步的獎勵。
目標狀態提取:給定一條軌跡 τ = [o1, … , oT],其中 T 是軌跡長度,ot 是時刻 t 的 RGB 圖像。將第一幀 o1 作為基于語言的“SAM”[43, 44] – langSAM 的輸入。langSAM 使用文本提示和 GroundingDINO [45]提取物體的邊框,然后將其輸入到SAM [44]生成掩碼。langSAM對應于 o1 的輸出,是初始物體位置 P1 的分割掩碼,P^1表示為物體上N個檢測點的集合,其中N是超參。參數 N 決定目標追蹤的密度,并根據目標在攝像機視圖中的大小進行調整。
點跟蹤:掩碼 P1 用于初始化基于 Transformer 的點跟蹤算法 Co-Tracker [46]。給定 RGB 圖像的軌跡 τ 和第一幀分割掩碼 P1,Co-Tracker 會在整個軌跡 τ 上跟蹤圖像中的點 p_it = (x_it, y_it),其中 t ∈ {1…T},P1 = [p_11,…p_N1]。使用 τp = [P1,…P^T] 表示由跟蹤點集組成的點軌跡。如圖所示說明了人類和機器人軌跡的目標跟蹤情況。
匹配軌跡:首先,定義兩個附加量:檢測點的質心 ?Pt 和時間 t 時的平均平移 δ_transt。 δ_transt 定義為 Pt 中所有點相對于 P1 的平均位移。給定時間 t 的兩個獨立目標運動,一個對應于機器人 T_Rt,另一個對應于人類 T_H^t,獎勵通過計算它們之間的負均方根誤差來計算。
b) 探索策略:選擇動作維度子的一個集進行探索和學習。例如,在卡片滑動任務中,只關注拇指的 X 軸和 Y 軸,而不是探索所有手指的所有軸。這種方法加快學習過程并實現快速適應。對于探索策略,使用預定的加性 Ornstein-Uhlenbeck (OU) 噪聲 [47, 48] 來確保機器人動作流暢。
在提取有意義的獎勵函數并確定動作空間的相關子集后,通過使用 DrQv2 [49] 最大化中每個 episode 的獎勵函數,在該子集上學習殘差策略 π_r(·)。
殘差策略 a_+^t = π_r() 在時間 t 的輸入包括:(a) 人類重定位的指尖相對于機器人基座 a_r^t 的位置,(b) 當前機器人指尖位置的變化 ?s^t = s^t ? s^t?1,? 機器人軌跡 P?_R^t 上追蹤點的質心,以及 (d) 在 t 時刻的目標運動 T_Rt。最后,計算執行的動作:at = a_r^t + a_+^t。
動作 a^t 被發送到 IK 模塊,該模塊將其轉換為機器人的關節命令。隨著機器人與目標交互的經驗不斷積累,該策略會使用 DrQv2 進行改進。
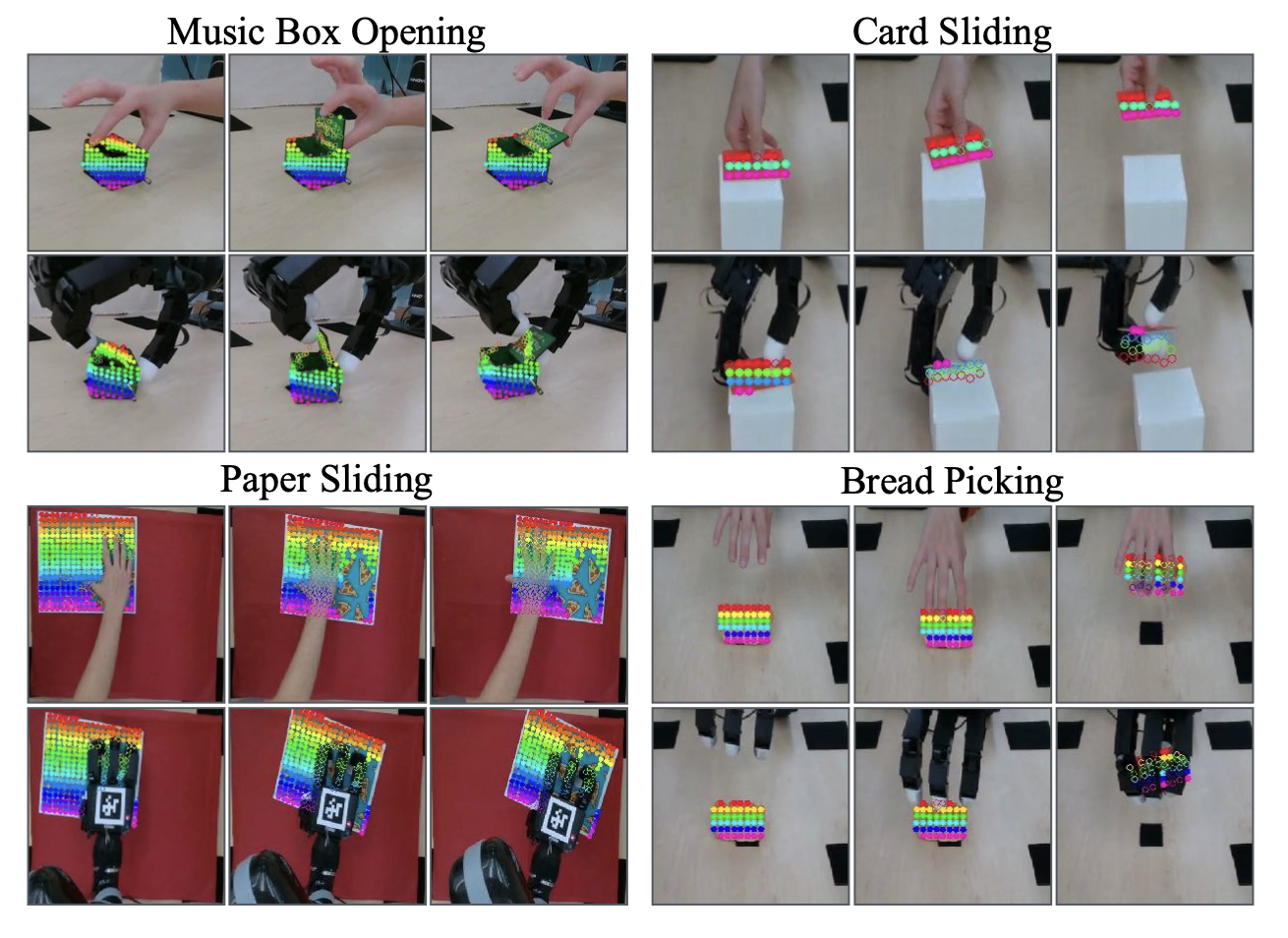
本文實驗四項靈巧任務,如圖所示。圖中提到的探索軸均相對于機器人底座。

a) 拾取面包:機器人必須找到一塊橙色面包,將其拾起并保持一段時間。在驗證過程中,面包的定位和方向應在 15cm × 10cm 的空間內。在此任務中探索所有手指的 X 軸。用于檢索遮罩的文本提示是“橙色面包”。
b) 滑動卡片:機器人必須用拇指找到并滑動一張薄卡片,然后用其余手指支撐卡片將其拾起。在驗證過程中,卡片的定位和方向應在 10cm × 10cm 的空間內。用于檢索物體掩碼的文本提示是“橙色卡片”。僅探索拇指的 X 軸和 Y 軸。
c) 打開音樂盒:機器人必須找到并打開一個小音樂盒。它用拇指穩定盒子,同時用食指打開盒蓋。驗證過程中,盒子被放置在10cm×10cm的空間內并定向。探索拇指和食指的所有軸,使用的文本提示是綠色音樂盒。
d) 紙張滑動:機器人必須將給定的紙張向右滑動。在驗證過程中,紙張被放置在 15 厘米 × 15 厘米的空間內并定向。用于檢索面具的文本提示是一張印有披薩圖案的藍色紙張。紙張向右移動的距離越遠,獎勵就越高。此任務的成功程度以紙張向右移動的距離(以厘米為單位)來衡量。探索所有手指的 X 軸和 Z 軸。
)
 PyTorch 實現)







![高級java每日一道面試題-2025年4月13日-微服務篇[Nacos篇]-Nacos如何處理網絡分區情況下的服務可用性問題?](http://pic.xiahunao.cn/高級java每日一道面試題-2025年4月13日-微服務篇[Nacos篇]-Nacos如何處理網絡分區情況下的服務可用性問題?)

)


)

)


