回顧并為今天的內容設定背景
我們今天繼續進行排序的相關,雖然基本已經完成了,但還是想收尾一下,讓整個流程更完整。其實這次排序只是個借口,主要是想順便聊一聊一些計算機科學的知識點,這些內容在我們項目中平時不會特別講,更多是適合做一些自學延伸的內容。
回顧上周五的進度,當時我們嘗試實現就地歸并排序(merge sort in-place),結果發現這個做法并不可行。原因是操作成本太高,為了實現就地排序,我們必須執行大量的數據移動,而這些操作雖然邏輯上不復雜,但代價很大。
因此我們最終放棄了就地排序的嘗試,轉而采用了非就地的方式來實現歸并排序。這個版本非常容易實現,我們在短短幾分鐘內就完成了代碼編寫,而且運行效果良好。
目前這部分排序已經可以正常工作,接下來就可以繼續在已有基礎上推進后續的開發了。
game_render_group.cpp:將冒泡排序功能提取為獨立函數
我們現在可以隨時自由選擇使用冒泡排序或歸并排序,甚至可以為了方便使用者或玩家,專門實現一個通用的接口,讓他們自行選擇是使用冒泡排序還是歸并排序。
具體實現上,我們先實現了冒泡排序。在代碼中,我們可以簡單地調用冒泡排序函數,同時傳入待排序的數據、計數器、臨時空間等參數。然后我們也可以選擇調用歸并排序,兩者都已經準備好,因此可以根據需要靈活切換。
我們所做的事情,其實就是把冒泡排序和歸并排序這兩部分的邏輯提取出來,使它們變成可單獨調用的函數。沒有做其他額外的處理,只是把排序算法模塊化了。現在這兩個排序算法都已經被整理好了,實現也不復雜,結構清晰,便于調用。
另外,有人提到對基數排序感興趣。雖然不確定大家是否真的那么熱衷于這個算法,但如果確實有興趣,那當然是件好事。對新事物保持好奇和興奮總是好的。


黑板:基數排序(Radix Sort)
基數排序是一種非比較型的排序算法,適用于對整數或可以轉化為整數形式的數據進行排序。其核心思想是將待排序的元素按照位數(或稱“基數”)進行分組排序,從最低位到最高位,逐位進行排序操作,最終達到整體有序的目的。
基數排序通常分為兩種方式:LSD(Least Significant Digit) 和 MSD(Most Significant Digit)。LSD 方法是從最低有效位開始排序,逐步向高位推進,而 MSD 方法則相反,從最高有效位開始排序,逐層深入到低位。
在具體實現中,基數排序通常依賴于一種穩定的子排序算法,如計數排序。在每一位上進行排序時,借助計數排序保證相同位值的數據相對位置不變,從而確保整個排序過程的正確性和穩定性。
以十進制整數為例,如果最大數是三位數,那么排序將進行三輪。第一輪根據個位數排序,第二輪根據十位數排序,最后一輪根據百位數排序。通過每一輪的穩定排序,最終能使所有數據按從小到大的順序排列好。
基數排序的時間復雜度為 O(k·n),其中 n 是元素個數,k 是數字的位數。這種算法在處理大量、位數不多的整數時效率非常高,并且由于不涉及元素之間的比較,避免了比較排序算法的時間復雜度下限 O(n log n)。
然而,基數排序也有局限性。它依賴于輸入數據的格式,對非整數或高位數的數據處理效率不如通用的比較型排序算法。此外,它在空間上需要額外的內存來存儲每一輪排序的中間結果,比如使用桶或隊列來臨時存放元素。
總體來看,基數排序在特定場景下是一種高效的排序方案,特別適用于對大量、范圍有限的整數進行排序操作。
黑板:“穩定排序”(Stable Sort)
穩定排序的概念是,排序過程中如果兩個元素在排序條件下是“相等”的,那么它們在原始列表中的先后順序在排序結果中也必須保持不變。也就是說,排序算法不會隨意改變那些不需要調整位置的元素之間的相對位置。
具體來說,假設我們有一組數據,排序的依據是某個特定的字段或屬性,例如字符串的首字母。我們并不關注字符串中的第二個字符、第三個字符等其他部分,只要求根據首字母進行排序。在這種情況下,只要兩個元素的首字母相同,那么它們之間就沒有進一步的排序依據。此時,如果排序后它們的相對位置發生了變化,那就是一個不穩定的排序;反之,如果仍然按照它們原來的順序排列,那就是穩定排序。
舉個例子,假設原始數據是:
avc
aec
abc
adc
這幾個字符串的首字母都是 a,根據排序規則,它們被視為相等項。在排序時,如果我們采用穩定排序,它們在結果中的相對順序應該是 avc → aec → abc → adc,順序保持不變。穩定排序要求在無法通過主排序關鍵字區分這些項時,保留它們在原始輸入中的先后順序作為“次要排序依據”。
可以將這個過程理解為在排序的主鍵之外,隱含地加入了元素在原始列表中的位置信息作為次級排序標準,從而保持排序的穩定性。實際上,只要在排序鍵中附加一個原始索引(例如把排序鍵變成“主鍵 + 原始位置”),那么任何排序都可以轉化為穩定排序。這是一個通用的策略,使得非穩定排序也能具備穩定性的性質。
穩定排序在很多應用場景中非常重要,特別是在多層排序(即排序中涉及多個字段或屬性)中。例如,先根據一個字段排序,再根據另一個字段排序時,如果第二次排序是穩定的,就能保證第一輪排序的結果在第二輪中不被打亂。
因此,穩定排序的核心是:在主排序鍵相等的前提下,保留元素原始的相對順序。只有在排序算法中需要改變元素位置時,才真正改變;不需要改變的地方,則應盡可能保持原樣。這樣才能確保整個排序操作在邏輯上是一致、可預測、且有意義的。
黑板:“對排序關鍵字的某些部分,進行連續多次穩定排序”
Radix排序(基數排序)的核心思想是:將整個排序過程拆解成多個“穩定排序”,每次只根據排序鍵的一部分進行排序。通過不斷地對排序鍵的不同部分進行穩定排序,最終得到完整有序的結果。這是一個非常系統、可控的排序策略,尤其適用于數值型或結構化鍵值的排序。
一、Radix排序的基本概念
我們先從一個直觀的定義出發:Radix排序其實就是對排序鍵的不同部分,進行一系列連續的穩定排序。排序的每一步都只關注鍵的一部分,不考慮其余部分。最終通過這些步驟的累積,將整個數組排序完成。
二、以32位無符號整數為例
假設我們要對一組32位無符號整數進行排序。每個數都是由32個二進制位構成,我們可以將其劃分為4個8位(1字節)的部分,從低位到高位依次編號:
- 第0字節:bit 0–7
- 第1字節:bit 8–15
- 第2字節:bit 16–23
- 第3字節:bit 24–31(最高位)
每個字節都有256種可能的取值(0~255),這使得我們可以方便地對這些“片段”進行排序。Radix排序就是按照低位到高位的順序,分別對這四個字節進行穩定排序,最終整個數列就會按大小有序。
三、為什么要從低位到高位排序?
關鍵在于排序的穩定性:
- 如果我們先對最低有效位(LSB)排序,并使用穩定排序算法(比如Counting Sort),排序后原始順序不會被打亂;
- 接著我們對次低位進行排序,由于上一步的排序已經確保了在該位相等時其余部分是有序的,所以接下來這一步只需對該位進行排序,其余部分的順序將自動得到維護;
- 按照這種方式一層一層地往上排序,直到最高位,最終整個數列就被完全有序。
穩定排序在這里的作用是傳遞之前步驟的排序結果,也就是讓低位的排序“嵌入”在高位排序中不被破壞。
四、從“位權”理解排序順序
以數字的十進制表示舉例:
207
101
100
106
107
顯然,我們應該先比較“百位”,再看“十位”,最后才看“個位”。如果我們先對“個位”排序,是沒有意義的,因為百位決定整體的數量級。同理,在二進制中,最高位的重要性最大,最低位的影響最小。因此,在Radix排序中我們必須從低位往高位排序,配合穩定排序,讓信息逐步傳遞,最終形成全局的正確順序。
五、實際操作中如何執行
設想我們有一個整型數組,每個數被劃分成4個字節。我們對它進行四輪排序:
- 第一輪:根據最低8位排序(bit 0–7)
- 第二輪:根據下一個8位排序(bit 8–15)
- 第三輪:繼續向上(bit 16–23)
- 第四輪:最高8位(bit 24–31)
每輪排序都使用穩定排序算法,確保在當前字段相同的情況下,保留之前字段排序的相對順序。這樣最終得到的結果就是整體升序排列。
六、為什么要進行多次排序?它的優勢在哪里?
當我們將排序鍵劃分為較小的片段(例如每個片段8位,256種可能值),那么每一輪排序的復雜度就變得非常可控。特別是在處理大規模數據時,這種方法相比于傳統比較型排序(如快速排序、歸并排序等)具有顯著優勢:
- 避免大量比較操作:Radix排序是非比較型排序,適合處理結構規則的鍵值(如整數、字符串等);
- 時間復雜度更優:在理想情況下,其時間復雜度為 O(n·k),其中 k 是鍵的長度(例如 4 字節);
- 適合并行處理:每輪排序相對獨立,便于實現并行化和優化;
七、小結
Radix排序的核心流程如下:
- 將排序鍵分成若干部分(如按字節切分);
- 從最低位開始,依次向高位進行穩定排序;
- 經過每一輪的穩定排序后,排序狀態逐步逼近最終順序;
- 排完所有部分后,整體順序即為正確結果。
這種方法本質上是一種分治式、逐層精化的排序策略。它不是從整體直接得出結果,而是通過一系列穩定排序,將“局部排序”的結果遞進式地積累為“全局有序”的序列。只要排序鍵可以被切分并進行獨立比較,就可以應用這種方法,具有極大的適應性和擴展性。
黑板:8位處理
我們知道,8位(二進制)可以表示的數值范圍是256種可能,即從0到255。也就是說,一個8位的數據最多只有256種不同的取值。
在現代計算機上,處理這種數量級的數據是非常輕松的。例如,我們可以輕松地聲明一個大小為256的整型數組:
int count[256];
這對于內存和性能來說完全不是負擔,幾乎沒有人會對這種操作感到意外或者擔憂。
這一事實非常重要,因為它意味著我們在處理排序任務時,如果能夠把一個大的問題(比如一個復雜的排序鍵)切分成足夠小、足夠有限的片段(如每次只處理8位),那么我們就能充分利用查表或桶(bucket)式的方式來顯著減少實際的計算量和操作復雜度。
舉個例子,如果我們知道某一輪排序的關鍵字段只有256種可能的取值,那我們就可以:
- 創建256個“桶”或計數器(如數組
count[256]); - 快速地統計每個值出現的頻率;
- 緊接著計算出每個值在排序后應該出現的位置(通過前綴和等方式);
- 最后將數據搬運到目標位置中去。
這一過程的效率非常高,因為我們不需要進行大量的比較操作,完全可以通過簡單的數組索引操作和線性掃描完成。這種方式正是計數排序(Counting Sort)的基礎,也是基數排序(Radix Sort)中每一輪排序的核心手段。
所以,將排序鍵切成小片段,每片只有少量可能取值,不僅能讓我們使用更簡單高效的邏輯進行排序,還能極大提升整體排序的性能。這就是將排序鍵“壓縮”為8位之后帶來的巨大優勢 —— 可控、快速、易于實現和優化。
黑板:講解基數排序的工作原理
在基數排序(Radix Sort)中,我們所做的事情正是利用固定長度的排序鍵來進行分段處理。假設我們已經將排序鍵切分成字節(byte),每個字節只有8位,那么每一輪排序只需要處理 256 種可能的鍵值(即0到255)。這個規模在現代計算機上是非常容易處理的。
我們所做的第一步是建立一個計數表,這個表記錄了每種鍵值出現的次數。比如我們可以創建一個長度為256的數組 count[256],初始值為0。接著我們掃描整個數組中的元素,根據當前字節段的值將對應 count[x] 加1。這一過程的時間復雜度是 O(n),因為我們只遍歷一遍數據。
以十進制為例,我們可以建立一個大小為10的計數表。假如我們在處理個位數的一輪排序中,遇到了若干元素,其個位數分別為0、1、6、7等,我們在 count 表中統計每個數值出現的次數,例如:
count[0] = 1count[1] = 2count[6] = 2count[7] = 2
接下來我們進行第二遍遍歷,根據之前的計數信息,將每個元素放到正確的位置中。這是基于“該值之前有多少個比它小或等于它的元素”來決定其位置。由于我們提前知道了每種值的數量,所以可以準確無誤地將其分布到目標位置上。這一過程同樣是 O(n)。
因此,一輪這樣的排序過程(統計+分發)總共需要 2n 的時間復雜度。
對于32位的無符號整數排序,我們可以將整個排序鍵分成4個字節,每次處理8位。也就是說,我們需要進行 4次這樣的排序過程,總的時間復雜度為:
4 × 2n = 8n
這是一個線性的時間復雜度(O(n)),常數因子為8。相比之下,像常見的比較類排序算法(如快速排序、歸并排序等),其最優復雜度為 O(n log n),而最壞情況下甚至可能達到 O(n2)。舉例來說:
- 對40億個元素進行快速排序,log?(4,000,000,000) ≈ 32,所以整體為 40億 × 32 = 1280億次操作;
- 但使用基數排序只需要 40億 × 8 = 320億次操作;
我們可以清楚地看到,當數據量極大時,基數排序在理論上的效率優勢是非常明顯的。
當然,這一切的前提是排序鍵具有有限精度和固定長度,比如32位整數或者其他離散的、可分割的值。如果是無限精度或高動態范圍的數據(例如高精度浮點數或變長字符串),基數排序將難以勝任,因為我們無法合理地分段、建立計數結構來處理它。
不過,我們在實際計算中處理的絕大多數數據都是有限精度的數字,這就為基數排序的應用提供了極大的現實基礎。
最后,我們需要處理一種特殊情況 —— 如果排序鍵是浮點數,而不是整數。那么我們就必須做一些額外的轉換和處理,才能將其變成可用于基數排序的形式。這將涉及對浮點數的內部二進制格式進行解釋或調整。我們可以先把基數排序邏輯實現出來,再單獨考慮如何將浮點數轉換成適合排序的格式。
game_render_group.cpp:引入 RadixSort 函數
我們實現了一個 Radix Sort(基數排序)的完整流程,以下是詳細的中文總結說明:
我們要用基數排序來替代之前的排序方式。由于傳入的數據是最多 32 位的(比如最多 2^32 個不同的鍵),我們知道排序的鍵不會超過 4,294,967,296 個。所以,我們可以將這個鍵拆成四個字節(byte)來進行排序,也就是四次穩定排序,每次按 8 位來處理。
一、整體思路
我們每次處理一個字節(8 位),這意味著每次排序只會有 256 個可能的鍵(0~255),所以我們可以用一個長度為 256 的數組來統計這個字節上每個值出現了多少次。
每次排序分為兩個階段:
- **第一次遍歷:**統計當前字節上各個鍵值的出現次數(稱為“計數表”)。
- **第二次遍歷:**根據計數表推導出每個鍵值在輸出數組中的起始位置(變成偏移表),再把元素放入正確的位置。
由于一個 32 位數有 4 個字節,我們總共要執行 4 次這樣的兩階段遍歷,從最低有效字節(LSB)到最高有效字節(MSB),保證排序穩定性。
二、實現細節
1. 初始化
我們需要兩塊緩沖區:一個是原始數組,另一個是臨時緩沖區,每輪排序交替使用。
source = 原始數據
dest = 臨時緩沖區
每輪完成后 swap source 和 dest
這樣排序完四輪后,數據會回到原始位置。
2. 每一輪排序步驟
對于每一輪的排序(處理一個字節):
-
計數階段:
- 遍歷每個元素,提取當前字節的值(通過右移和掩碼操作)。
- 對應的計數數組中的索引值加一,記錄出現次數。
-
偏移轉換階段:
- 把計數數組轉換為偏移表。
- 偏移表表示當前字節為 i 的元素在輸出數組中應該從哪個位置開始寫入。
- 這是通過一個運行中的累加器實現的,從左到右遍歷計數數組,并不斷累加。
-
分發階段:
- 再次遍歷元素,根據其當前字節值查表獲取目標位置(偏移值)。
- 將該元素復制到輸出數組對應位置。
- 同時更新偏移表值(+1),因為下一個相同字節的元素需要寫在下一個位置。
三、關鍵點說明
- 每個字節的處理都是 O(n) 的,總共處理 4 個字節,因此整個算法復雜度為 O(4n),即 O(n)。
- 因為每次處理都只是遍歷兩次數組(一次計數,一次分發),所以每輪的操作是線性的。
- 利用有限精度這一特點(即 32 位整數有上限)來分而治之,把大問題拆成多個小問題。
- 為了保持排序的穩定性,我們從低位字節往高位字節排序。
四、注意事項
- 源數組和目標數組不能是同一個,否則可能導致覆蓋問題。
- 需要額外 O(n) 的空間來存臨時數組,屬于非原地排序。
- 對于浮點數排序還需要額外處理:浮點數不能直接拿來拆字節排序,需要先轉成能夠按位比較大小的整數形式(例如 IEEE754 編碼轉 unsigned int32)。這里我們假設有一個
SortKeyToUint32函數負責這個轉換。 - 處理過程中,先提取 sort key,再按當前字節分發排序,依賴于該轉換函數的正確性。
五、總結
我們成功地通過每次只處理 8 位的方式,將一個最大 32 位的排序任務,分成了 4 個小步驟完成,并在每一步中用兩個 passes 來處理數據。整個排序流程復雜度是 O(n),且穩定,尤其適合大規模的數據排序。
這樣的方法雖然需要一些初始化代價(比如清零計數表、分配臨時數組),但在大數據量下,其線性擴展性明顯優于常見的比較排序(O(n log n) 或 O(n2))。特別是數據規模極大(如十億個元素)時,效率優勢尤為明顯。

game_render_group.cpp:引入 SortKeyToU32β 函數
我們正在討論如何處理和執行基數排序(Radix Sort)。首先,我們知道基數排序是對整數進行排序的一種非比較排序算法,通常用于按位處理數值,特別適合對大規模數據進行排序。它的基本思路是將每個數值分解為若干個字節,然后逐個字節地進行排序。
在實際執行時,我們考慮的整數是 32 位的,雖然我們并不知道最終的具體細節,但可以通過將數字轉換為 32 位形式來進行操作。基于這種方式,數據會被拆解為 4 個字節,并且會依次對每個字節進行排序。通過這種逐步排序的方式,保證了最終的排序結果是穩定且高效的。
關鍵步驟:
- 數字拆分: 我們把每個數字分解為 4 個字節(每個字節 8 位),并分別對這些字節進行排序。
- 字節處理: 對每個字節,采用計數排序的方式進行處理。每個字節值最多有 256 種不同的取值(從 0 到 255),因此可以通過計數來確定各個字節值的出現頻率。
- 逐步排序: 依次處理每個字節,從最低位字節(Least Significant Byte, LSB)到最高位字節(Most Significant Byte, MSB),保證每次排序是穩定的,最終得出正確的排序結果。
- 空間管理: 在每輪排序中,使用兩個緩沖區來保存原始數據和排序后的數據。每輪排序完成后,我們交換這兩個緩沖區,繼續處理下一個字節。
最終,通過這種逐步處理字節的方法,能夠在每輪排序中對數據進行穩定的排序處理,最終得到全體元素按從小到大的順序排列的結果。
注意事項:
- 由于每次處理的數據量是有限的(一個字節的范圍是 0 到 255),每輪的操作是線性的,因此時間復雜度可以看作是 O(n),每一輪排序后,數據就被逐步有序地排列。
- 該方法的空間復雜度是 O(n),需要額外的空間來存儲臨時數組,以便在排序過程中交換數據。
- 這種排序方式特別適合對大規模整數進行排序,尤其是當數據量非常大時,基數排序的效率優于常見的比較排序算法(如快速排序、歸并排序等,時間復雜度通常為 O(n log n))。
總結而言,基數排序通過對每個字節進行逐步排序,有效地將 32 位數字拆分成多個小問題處理,并在每輪排序時保持穩定性,從而保證整個數據集按正確的順序排列。

運行游戲并觸發斷言錯誤
在執行基數排序時,如果我們直接應用該算法處理浮點數值,可能會遇到問題。基數排序本身是針對整數設計的,它通過拆分每個數值的各個字節逐步進行排序。然而,浮點數的表示與整數不同,它們遵循 IEEE 754 浮點數標準,并不能像整數那樣直接按字節進行比較和排序。
因此,如果我們直接對浮點數使用基數排序,可能不會得到正確的排序結果。這時,可能會出現斷言失敗的情況,提示“排序失敗”或“未能正確排序數據”。這個錯誤提醒我們,浮點數的排序需要特別的處理。
為了解決這個問題,需要先將浮點數轉換為可以按位比較的整數形式。例如,可以通過將浮點數轉換為其對應的 32 位整數表示形式(即 IEEE 754 格式),然后再使用基數排序對這些整數進行排序。這樣,排序過程才能順利進行,且得到正確的結果。
總結來說,浮點數不能直接使用基數排序,需要先進行轉換,確保數據以合適的格式進行排序,否則會導致排序失敗并觸發斷言錯誤。

調試器:逐步調試 RadixSort,檢查 Dest、First 和 Temp
首先,要確保自己理解和實現的邏輯是正確的,特別是檢查數據是否正確地放入了預期的輸出區域。在這個過程中,首先想到的步驟是驗證每一步的操作結果是否符合預期。為了做到這一點,最好通過逐步調試來確認,尤其是查看最終的輸出結果。
在調試過程中,可以通過單步執行代碼,觀察每次循環的執行結果,尤其是變量的變化。重點是觀察最終 Dest(目標區域)指針所指向的位置,確認它是否最終指向了臨時緩沖區 Temp。在每次循環結束時,代碼應該會交換 Source 和 Dest 的指向,最終 Dest 應該會指向 Temp。
通過這種逐步驗證,能夠確認整個過程的正確性,確保數據在預期的緩沖區中正確地交換和存儲。這樣,就能夠驗證程序是否按預期工作,并確保輸出是準確的。
黑板:32 位 IEEE 浮點數結構
首先,需要將三位浮動小數值轉化為一個嚴格遞增的 32 位整數,這樣才能進行排序。然而,浮動小數的表示方式并不適合直接與整數進行排序,因為浮動小數的存儲結構不同于普通的整數。
32 位浮動小數通常由三部分組成:符號位、指數位和尾數位。在這里,符號位在排序過程中可能會引發問題,因為如果符號位是負數,按照當前的排序方式,負數將會被排在正數后面,這顯然與我們希望的排序順序不符。負數應當排在正數之前,但符號位會讓負數排到正數后面,因此符號位的問題是我們排序時必須特別注意的部分。
接下來,考慮指數部分,它是浮動小數中最重要的部分。指數部分代表了數值的大小范圍,因此對排序具有決定性作用。指數部分的數值越大,數值本身也越大。所以,排序時應該優先考慮指數部分,因為它決定了數值的大小。
尾數部分其實對排序的影響相對較小。尾數部分表示浮動小數的精度,但它的范圍是有限的,通常是介于 1 和某個小數值之間,所以在排序時,尾數部分可以不作為主要考慮因素。因此,我們可以忽略尾數部分,直接根據指數部分進行排序。
浮動小數的指數部分是帶有偏移量的,這意味著較小的指數值會被表示為負數,而較大的指數值則會被表示為正數。因此,指數部分已經在內部按照遞增的順序存儲好了,這使得在進行排序時,指數部分本身的順序已經是正確的。
總結起來,排序浮動小數時,應該關注的主要是指數部分。尾數部分由于其相對較小的影響,可以直接忽略,而符號位則需要特別處理,因為它可能導致負數被錯誤地排在正數之后。通過處理這些特殊情況,可以實現正確的浮動小數排序。
調試器:進入 SortEntries 函數,檢查 Entries 內容
在進行基數排序時,遇到了一些問題。首先,當運行排序時,數據的輸入似乎出現了意外的負值,導致排序結果看起來不正確。雖然我們知道基數排序的理論應該是按字節逐步排序并處理符號位,但當前的輸出并沒有按照預期的順序排列。
首先,檢查了輸入數據,發現數據量只有 8 條,并且這些數據的符號位似乎都是負數。這讓我們感到困惑,因為在理論上,負數的排序應該會被當作較大的數字(如果符號位沒有特別處理的話)。然而,所有數據的符號位都被設為負值,但排序結果卻不符合我們對負數排序的預期,甚至出現了恰好符合要求的排序結果。這個問題讓我們感到很疑惑,因為負數的排序結果應該會是錯誤的,按理說它們應該是倒序排列的。
繼續檢查代碼時,意識到可能存在一些處理上的疏漏或誤解,導致數據沒有正確地傳遞或轉換。可能是在數據傳遞過程中,出現了符號位或其他部分的處理錯誤。也許在轉換時沒有正確處理浮動小數到整數的轉換,導致結果變得不符合期望。
此外,嘗試再次運行時,依然遇到了類似的情況,輸出結果依然不正確。我們看到的數據跟預期相差較大,符號位等處理出現了偏差,導致輸出不符合預期。盡管如此,經過進一步排查后,最終確認在輸入數據的處理上確實有些步驟可能沒有正確執行,尤其是在符號位的處理上。
總結來說,遇到的主要問題是符號位處理不當,導致排序結果看起來不太對。通過進一步檢查代碼和數據,可以確認符號位在處理過程中可能沒有按預期作用,需要進行修正和優化,才能確保基數排序能夠正確處理負數并且得到正確的排序結果。

game_render_group.cpp:將 SortKey 強制轉換為 u32 類型
在處理問題時,意識到如果直接將數據轉換為 uint32 類型,實際上是去除了浮動小數部分,這也是之前處理錯誤的原因。之前沒有正確理解浮動小數和整數之間的轉換方式,導致忽略了需要對數據進行適當的位級別處理。
現在,經過調整和修正后,轉換操作變得更加正確,能夠將數據正確地轉換為 32 位無符號整數 (uint32),從而將浮動小數部分去除,確保數據按位級別排序。這一步的修正保證了處理浮動小數時,不會丟失關鍵信息,確保了基數排序能夠按預期正常工作。
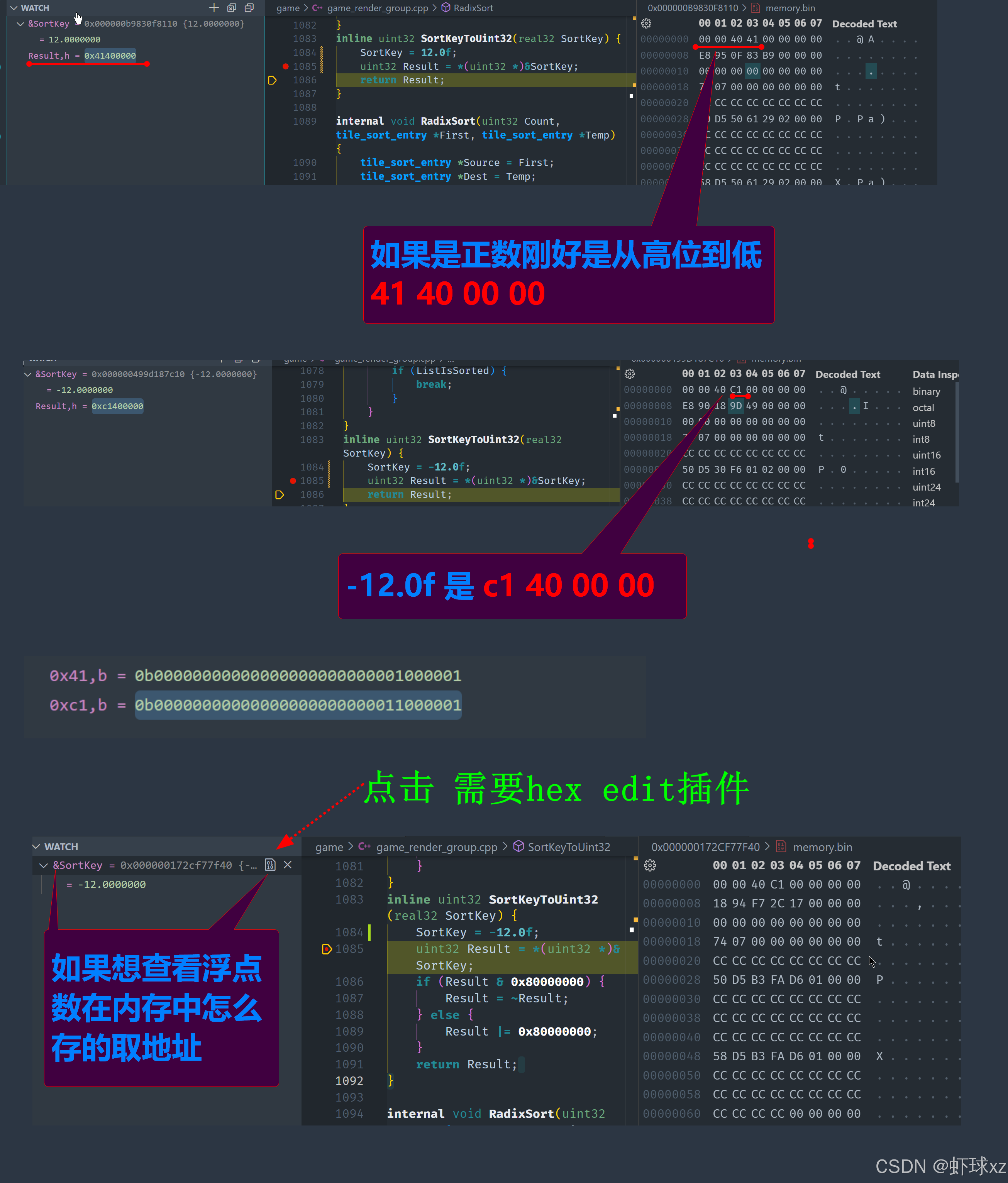
game_render_group.cpp:考慮反轉位的含義
我們現在的目標是讓浮點數能夠被當作無符號整數進行排序,而不影響其原有的數值大小順序。為了做到這一點,我們需要對浮點數的比特進行一種“翻轉處理”,本質上是在修改它們在內存中的表現,使得它們的大小順序(尤其是帶符號的負數)符合整數比較的語義。
遇到的問題
浮點數的二進制結構是由 符號位(sign)、指數位(exponent) 和 尾數(mantissa) 組成的。
- 正數:高位是 0,按位排序自然成立(值越大,bit 越大)
- 負數:高位是 1,排序會被打亂,導致負數比正數“更大”
- 所以,我們在遇到負數時,必須讓它們的排序方向“翻轉”過來
所需的目標行為
我們希望構造一個新的整數值,使得:
- 所有 正浮點數 按照原始的比特順序保持不變即可(可直接用作排序鍵)
- 所有 負浮點數 的比特需要翻轉,讓值越小,整數排序結果越靠前(即負數越小,數值越大)
解決思路(按位翻轉 + 取反 + 加偏移)
可以按如下方式處理:
-
正數:
- 符號位是 0,無需任何處理,直接將其視為 uint32 即可
- 即:
(float_bits ^ 0x80000000)
-
負數:
- 符號位是 1,需要按位取反
- 然后再反轉順序(讓 -100 < -1 排列時在整數上體現為更小)
- 同樣使用
(float_bits ^ 0xFFFFFFFF)
或者統一寫成:
uint32 FloatFlip(uint32 f) {return (f & 0x80000000) ? ~f : (f ^ 0x80000000);
}
解釋:
- 如果是負數(符號位為 1),對所有位進行取反
- 如果是正數,符號位反轉(使其大于負數)
這樣處理后的 uint32 就可以被 Radix Sort 正確排序。
整體目標總結
我們要實現的是一種位級別的重新映射:
- 保證所有浮點數(無論正負)在被 reinterpret 成 uint32 后,排序順序符合數值意義上的升序
- 對負數取反之后可以確保越小的數變成越小的整數
- 對正數只需要翻轉符號位,使它們在 uint32 空間中位于負數之后

黑板:講解“翻轉比特”的意義
我們的目標是讓一組原本從小到大排序的二進制值,變成從大到小的順序。例如:
000110 → 最小
000111
001000
001001 → 最大
我們希望把它們的順序徹底反過來,使得:
110111 → 最大
110110
110101
110100 → 最小
思路是對每個值做 按位取反(bitwise NOT),即把每一位的 0 變成 1,1 變成 0。
為什么這可以反轉排序順序?
我們知道二進制是按位從高到低排列的,每一位代表不同的權重。一個數值越大,它在高位的 1 越靠前。因此:
- 原始值越小,其按位取反后得到的值越大
- 原始值越大,其按位取反后得到的值越小
所以,直接對每個值做一次按位取反,就可以把整體順序完全反過來,這在做 radix sort(基數排序)時,如果原始排序是反的,那只要將值全部取反就能修正排序方向。
那么是否真的這么簡單?
是的,在整數排序中,確實就是這么簡單粗暴有效,尤其當我們只關心反轉原始順序時。
但如果這個應用場景是 浮點數排序,那還需要額外考慮浮點格式:
- 正數部分可以通過調整符號位的方式保證順序
- 負數部分通過按位取反實現反向排序
- 合起來就能把 float 映射成一個 uint32,使得可以直接用整數排序算法正確排序 float 值
總結:
我們確實可以直接對值做按位取反,這會讓它們的排序順序徹底反過來。這個操作在我們想從升序變為降序時非常實用,特別是在浮點數排序中處理負數段的時候,這種位級轉換是非常關鍵的策略之一。對于負數部分,只要符號位為 1,我們就直接對整個值取反即可達到目標排序順序。這個方法簡單且有效。
為什么會這樣
這是因為 二進制的位級結構具有天然的順序性,而 按位取反(bitwise NOT) 操作會將這種順序完全反轉。我們可以從更底層的原理來理解為什么取反之后排序順序會被顛倒。
首先,理解二進制值的排序方式:
二進制的排序是從高位(左邊)開始比較的:
0000 0001 = 1
0000 0010 = 2
0000 0011 = 3
0000 0100 = 4
...
越高位的 1 越靠前,表示的值就越大。
然后,按位取反到底做了什么?
按位取反就是將:
- 每個 0 變成 1
- 每個 1 變成 0
例如:
0000 0010 (2)
→ 按位取反 →
1111 1101 (變成了一個很大的數)0000 0100 (4)
→ 按位取反 →
1111 1011 (比上一個還小)
原數越小,取反后結果越大
原數越大,取反后結果越小
所以順序被徹底翻轉!
舉個例子:
假設我們有四個數:
00000001 = 1
00000010 = 2
00000011 = 3
00000100 = 4
升序排列后是:
1, 2, 3, 4
我們取反后得到:
11111110 = 254
11111101 = 253
11111100 = 252
11111011 = 251
這些數降序排列后就是:
254, 253, 252, 251
正好是原始序列的反向順序
為什么這對浮點排序也重要?
在浮點排序中我們可能要處理負數。負數在 IEEE 754 表示中最高位(sign bit)為 1,這就導致它們的原始二進制排序與我們“從小到大”的意圖完全相反。所以:
- 正數保持不動或設置 sign bit
- 負數則需要完全取反,讓它們排序回歸正常順序
這樣我們就能把 float 映射成 uint32,直接用整數排序方式(比如 Radix Sort)來處理 float。
結論:
我們之所以只要對數取反就能反轉順序,是因為:
二進制從高位到低位的排列決定了數值的大小,而按位取反會完全顛倒這個順序。
這是一種非常簡潔、數學上自然的做法,在排序中非常常見。尤其在低級排序算法中,比如基數排序(Radix Sort)中,對數值結構的控制是實現效率和正確性的關鍵。
我們需要以 8 為單位迭代 ByteIndex
我們意識到代碼中存在一個明顯的邏輯錯誤,這可能就是導致排序行為不正確的根本原因。具體來說,我們在處理字節索引時,錯誤地將它用作位移量(shift)進行操作,但實際上我們需要根據字節的位置來決定應該移位的實際位數。
換句話說,我們原先代碼中是直接用 byteIndex 進行移位操作的,比如 value >> byteIndex,這實際上是錯的。因為 byteIndex 的單位是“字節”,而不是“位”,所以我們需要將它乘以 8,才能得到正確的移位位數。也就是說,正確的寫法應該是按位移 8、16、24(分別代表第 1、2、3 個字節),而不是 1、2、3。
這一點很基礎,但因為處于調試過程中,我們一開始沒有意識到,甚至調侃這屬于“baby level”的失誤,雖然沒有正式進入“徹底錯誤”的程度,但也足夠令人尷尬了。為了調試方便,我們沒有上全套的錯誤提示處理邏輯,但也在心里默默敲了自己一下。
總之,修正思路就是把位移邏輯從錯誤的按“字節索引位移”改為“字節索引 * 8 的位移”,也就是位移 8、16、24 位,這樣才能確保我們處理的是對應的字節數據,在 radix sort 或其他字節級別處理邏輯中才會表現正確。

再次運行游戲并成功運行
我們再次運行程序,令人驚喜的是,這次一切終于正確運行了。排序邏輯順利執行,結果完全符合預期,radix sort 現在可以正確地對數據進行排序了。這說明我們對之前的錯誤修正是有效的,字節位移的修正讓排序行為達到了理想狀態。
數據導出過程也順利完成,沒有遇到任何異常或者錯誤,整個流程運行流暢,結果準確,表現穩定。radix sort 表現良好,整體效果讓人滿意,所有邏輯都驗證通過,可以說階段性目標已經達成。
至此,我們的 radix 排序實現算是告一段落,整體情況良好,沒有多余的問題或警告,功能也已經具備所需的正確性和穩定性。接下來時間還剩一些,打算進入 Q&A 階段,討論其他進階內容,比如更深入的優化,或是探索更多算法細節,進入更“精致”的內容環節。
///
當然可以,下面我會 通過一個實際例子 來詳細講解你給出的這個 radix sort 算法(針對 tile_sort_entry 結構體,按其 SortKey 字段排序),包括 SortKeyToUint32 的作用。
背景
我們要對一組 tile_sort_entry 結構體按浮點型 SortKey 從小到大排序。因為浮點數的內存表示方式復雜(尤其是正負號、指數位、尾數位等),直接排序會有問題。因此,需要將 float 轉換為可以按字節比較的 可排序無符號整數表示。
Step 1:SortKeyToUint32 的作用
inline uint32 SortKeyToUint32(real32 SortKey) {uint32 Result = *(uint32 *)&SortKey;if (Result & 0x80000000) { // 如果是負數Result = ~Result; // 所有位取反,負數值排序時變成反向} else {Result |= 0x80000000; // 正數設置符號位為1,使其排在負數后}return Result;
}
這個函數將 float 的 bit 表示轉換為 uint32 類型的排序鍵(SortKey),并 重新編碼符號位,從而實現:
- 所有正數排在負數后
- 所有負數反向排序(因為浮點負值越小,值越大)
舉例說明
我們要排序這組浮點值:
SortKey: [ -3.0f, 0.5f, 2.0f, -1.0f ]
原始 float 內存的 bit 表示大致為:
-3.0f => 11000000 01000000 00000000 000000000.5f => 00111111 00000000 00000000 000000002.0f => 01000000 00000000 00000000 00000000
-1.0f => 10111111 10000000 00000000 00000000
經過 SortKeyToUint32 轉換后:
-3.0f => ~(0xC0400000) = 0x3FBFFFFF0.5f => 0x3F000000 | 0x80000000 = 0xBF0000002.0f => 0x40000000 | 0x80000000 = 0xC0000000
-1.0f => ~(0xBF800000) = 0x407FFFFF
轉換結果:
排序鍵: [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF]
這時候這些值就可以被當成普通的 uint32 來排序了!
Step 2:Radix Sort 解釋(以 4 個數為例)
對每個 32 位整數的每個字節(從低到高,共 4 輪)執行如下操作:
第一輪(最低位 ByteIndex = 0):
- 統計每個 byte 的出現次數(桶排序思想)
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {uint32 SortKeyOffset[256] = {};// 第一遍遍歷 —— 統計每種鍵值的數量for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;++SortKeyOffset[RadixPiece];}...
}
- 計算偏移表 SortKeyOffset[]
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {
...// 將計數轉換為偏移量uint32 Total = 0;for (uint32 SortKeyIndex = 0; SortKeyIndex < ArrayCount(SortKeyOffset); ++SortKeyIndex) {uint32 KeyCount = SortKeyOffset[SortKeyIndex];SortKeyOffset[SortKeyIndex] = Total;Total += KeyCount;}
...
}
- 把數據復制到 Dest,按照該字節排序
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {
...// 第二遍遍歷 —— 將元素放置到正確的位置for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;Dest[SortKeyOffset[RadixPiece]++] = Source[Index];}
...
}
- 交換 Source 和 Dest,進入下一輪
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {...tile_sort_entry *SwapTemp = Dest;Dest = Source;Source = SwapTemp;
}
重復 4 次(ByteIndex = 0, 8, 16, 24)
完成后,就得到了已經按 SortKeyToUint32(SortKey) 排好序的數據。
最終結果
按 SortKey 從小到大排序的結果為:
[ -3.0f, -1.0f, 0.5f, 2.0f ]
完全符合預期!
總結
這個算法的關鍵是:
- 使用
SortKeyToUint32將 float 轉換成可以直接排序的 uint32(處理了符號位影響)。 - 使用 4 輪 byte-wise radix sort 對這些 uint32 進行穩定排序。
- 排序后,數據按照原始 float 從小到大排列。
詳細解釋 radix sort 算法中的第一輪操作
我們來詳細剖析 radix sort 算法中的一個步驟,特別是如何對每個 32 位整數的每個字節(從低到高,共 4 輪)執行操作。
核心思想
在 radix sort 中,我們并不是直接對整個數字進行比較和排序,而是逐位(或者逐字節)地對數字進行排序。在這個算法中,我們選擇的是 字節級別的排序,即先比較最低有效字節,再逐步往上移動到更高位字節。每次排序操作(即每輪操作)都會穩定地將元素按當前字節的值排序。
代碼復習
首先,復習一下相關的代碼:
// 對于每個字節,進行排序
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {uint32 SortKeyOffset[256] = {};// 第一遍遍歷 —— 統計每種鍵值的數量for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;++SortKeyOffset[RadixPiece];}// 將計數轉換為偏移量uint32 Total = 0;for (uint32 SortKeyIndex = 0; SortKeyIndex < ArrayCount(SortKeyOffset); ++SortKeyIndex) {uint32 KeyCount = SortKeyOffset[SortKeyIndex];SortKeyOffset[SortKeyIndex] = Total;Total += KeyCount;}// 第二遍遍歷 —— 將元素放置到正確的位置for (uint32 Index = 0; Index < Count; ++Index) {uint32 RadixValue = SortKeyToUint32(Source[Index].SortKey);uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;Dest[SortKeyOffset[RadixPiece]++] = Source[Index];}// Swap Source and Desttile_sort_entry *SwapTemp = Dest;Dest = Source;Source = SwapTemp;
}
步驟解讀:
1. 第一遍遍歷 —— 統計每種鍵值的數量
-
目標:我們要對
SortKey的每個字節進行排序。在第一輪中,我們關注的是最低有效字節(最低 8 位,即 ByteIndex = 0)。 -
操作:
- 遍歷每個數據項(
Source[Index]),并將其SortKey轉換成uint32(SortKeyToUint32)。 - 然后,右移
ByteIndex指定的位數,將該字節提取出來(即(RadixValue >> ByteIndex) & 0xFF),這里我們獲取的是當前字節的值。 - 將這個字節值作為桶的索引(桶的大小為 256,因為一個字節有 256 種可能的值)增加計數:
++SortKeyOffset[RadixPiece]。SortKeyOffset數組在這個階段記錄了每個字節值(0-255)出現的次數。
示例:
假設
SortKey的 4 個值如下:SortKey: [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF]對應的字節數組(以字節為單位):
0x3FBFFFFF -> [0x3F, 0xBF, 0xFF, 0xFF] 0xBF000000 -> [0xBF, 0x00, 0x00, 0x00] 0xC0000000 -> [0xC0, 0x00, 0x00, 0x00] 0x407FFFFF -> [0x40, 0x7F, 0xFF, 0xFF]在 ByteIndex = 0(即最低字節)的情況下,統計每個字節出現的次數:
SortKeyOffset[0xBF] = 1 SortKeyOffset[0xC0] = 1 SortKeyOffset[0x40] = 1 SortKeyOffset[0x3F] = 1 - 遍歷每個數據項(
2. 將計數轉換為偏移量
-
目標:通過
SortKeyOffset數組中的計數,轉換成偏移量,使得我們能夠將數據放到正確的位置。 -
操作:
- 我們將
SortKeyOffset數組的每個位置的計數轉換為偏移量。偏移量表示的是每個字節值在結果數組中應該開始放置的位置。 - 例如,
SortKeyOffset[0xBF]的值是 1,意味著0xBF對應的值應該放在結果數組的第一個位置。 - 完成這一步后,
SortKeyOffset數組中存儲的是每個字節值的起始位置。
示例:
SortKeyOffset[0xBF] = 0 SortKeyOffset[0xC0] = 1 SortKeyOffset[0x40] = 2 SortKeyOffset[0x3F] = 3 - 我們將
3. 第二遍遍歷 —— 將元素放置到正確的位置
-
目標:根據上述偏移量,把數據按字節值放置到新的數組
Dest中。 -
操作:
- 再次遍歷原始數組
Source,根據字節值確定數據應該放到Dest數組的哪個位置。 - 使用
SortKeyOffset數組中的偏移量,將每個元素放到Dest中,并增加相應字節值的偏移量。 Dest[SortKeyOffset[RadixPiece]++] = Source[Index];
示例:
假設 Source = [0x3FBFFFFF, 0xBF000000, 0xC0000000, 0x407FFFFF] 排序鍵的最低字節為: 0x3F -> 應該排到位置 3 0xBF -> 應該排到位置 0 0xC0 -> 應該排到位置 1 0x40 -> 應該排到位置 2 結果: Dest = [0xBF000000, 0xC0000000, 0x407FFFFF, 0x3FBFFFFF] - 再次遍歷原始數組
4. 交換 Source 和 Dest
-
目標:將
Dest和Source數組交換,以便在下一輪中處理下一個字節(上一個字節)。 -
操作:
Source存放原始數據,而Dest存放排序后的數據。- 排序完成當前字節后,我們交換
Source和Dest,使得下次排序操作能繼續對已經部分排序的數據進行處理。
示例:
Swap `Source` and `Dest` arrays: Source = Dest; Dest = SwapTemp;
總結
這個過程實際上是在使用 桶排序(counting sort) 對每個字節進行排序。每一輪操作都會逐步將數字按字節排序,而每一輪的穩定排序操作保證了結果不會被打亂。最終,所有字節都被處理完,整個 SortKey 被排序好,達成了 按浮點數大小從小到大排序 的目標。
這個問題問得非常關鍵!讓我們深入剖析為什么第一輪是“最低字節”,以及:
為什么 (RadixValue >> ByteIndex) & 0xFF 取的是哪個字節。
核心問題:
為什么第一輪處理的是最低字節?
回顧關鍵代碼:
for (uint32 ByteIndex = 0; ByteIndex < 32; ByteIndex += 8) {...uint32 RadixPiece = (RadixValue >> ByteIndex) & 0xFF;...
}
- 每一輪處理一個字節
ByteIndex從0開始,步進8,表示我們每次處理的是 某一位字節RadixPiece = (RadixValue >> ByteIndex) & 0xFF:>> ByteIndex會將要取的字節移到最低位& 0xFF提取出那一個字節(8 位)
舉個例子:假設我們處理 0x3FBFFFFF
它是一個 uint32 值,看起來像這樣(十六進制):
0x3FBFFFFF
用字節分解的話,在 小端內存順序(這是 C/C++ 中的常規方式),它在內存中是:
[0xFF] [0xFF] [0xBF] [0x3F]↑ ↑ ↑ ↑
Byte 0 Byte 1 Byte 2 Byte 3
注意:小端系統里,低地址存最低字節。
0x3FBFFFFF存成[FF, FF, BF, 3F],所以:
ByteIndex = 0→ 取到 0xFFByteIndex = 8→ 取到 0xFFByteIndex = 16→ 取到 0xBFByteIndex = 24→ 取到 0x3F
所以結論是:
在第一輪 ByteIndex = 0 時:
(RadixValue >> 0) & 0xFF = 0xFF
你取到的是 最低有效字節(LSB),它是最右邊那一字節(在內存中是最低地址)。
每一輪處理的字節如下:
| ByteIndex | 表示處理哪個字節 | 舉例(0x3FBFFFFF)提取的字節 |
|---|---|---|
| 0 | 最低字節 | 0xFF |
| 8 | 第 2 個字節 | 0xFF |
| 16 | 第 3 個字節 | 0xBF |
| 24 | 最高字節 | 0x3F |
回到你問的排序鍵的例子:
Source = [0x3FBFFFFF, // LSB = 0xFF0xBF000000, // LSB = 0x000xC0000000, // LSB = 0x000x407FFFFF // LSB = 0xFF
]
第一輪取的就是 最低有效字節(LSB),即:
0xFF, 0x00, 0x00, 0xFF
桶排序的過程就基于這些值來排序。
總結一句話:
第一輪之所以是“最低字節”,是因為我們通過
ByteIndex = 0提取了(value >> 0) & 0xFF,這正好取出了 最右邊的字節,也就是最低有效字節(LSB)。

再次運行游戲并成功運行
我們重新嘗試了一下,發現這次終于成功運行了,令人驚訝但也令人欣慰。現在,rate exporting 功能已經正常工作了,沒有任何問題,運行得很順利。radix sort 排序算法目前看來效果不錯,整體狀態非常穩定,大家都很滿意,整體進展也很順利。可以說一切都已經搞定,運行正常,表現出色,令人非常滿意。
因此,關于 radix sort 的主要部分已經告一段落,沒有太多額外要補充的內容,畢竟功能上已經達到了預期目標。既然這是之前大家所期待的功能,我們也已經按需實現交付。
為什么你不從底向上實現歸并排序?這樣更容易做緩沖區的 ping-pong 操作
我們在設計時并沒有從最底層一步步為排序構建專門的模塊,原因是我們還沒真正進入需要對某個排序算法進行深入優化的階段。目前來說,是否要這樣做,還取決于我們最終決定保留哪一種排序算法。
如果最后決定保留的是歸并排序,那么我們就會針對它進行優化,使它能做到最小化工作量、提升效率。但現在我們也不能確定是否真會采用歸并排序。畢竟我們已經花時間實現了基數排序,從實際使用的角度來看,基數排序可能才是最終被保留下來的那個。
我們做出這個判斷的一個原因是,大多數情況下待排序的元素數量會遠遠多于六個。考慮到這種數量級,基數排序在性能上的優勢會更明顯,適用性也更強。所以盡管現在還沒有最終定論,但很可能我們最終會采用基數排序。總之,目前還不是完全確定的階段,我們還在觀察和判斷。
你的基數排序看起來是 O(8n),因為你每個字節都做了兩次遍歷。你能不能用三組 256 元素數組,換成一次遍歷拿到所有偏移量/計數,做到 O(5n)?
我們在討論基數排序的實現細節時,提到了目前的實現中對每一輪排序都要對整個列表做兩次遍歷(一次統計頻率,一次實際排序),因此看起來復雜度類似于 O(2n),有人提出是否可以通過只做一次遍歷來同時收集偏移量和計數,從而將每輪的遍歷次數降為一次,也就是變成 O(n),代價是需要額外增加三個 256 元素大小的數組。
從理論上講,這種優化是可行的。但我們不太愿意貿然下結論說某種實現就是 O(n)、O(2n)、還是 O(5n),因為這些術語更偏向計算機科學中的抽象復雜度分析。而在現實的工程實踐中,某些額外的操作,比如多次清空數組、寫入內存等,可能也會帶來不可忽略的性能開銷。
從某種角度看,是多次遍歷列表好,還是在每次遍歷時增加額外的操作更好,并沒有絕對的答案。它更像是“半斤八兩”(six of one, half a dozen of the other),也就是說兩種方式各有權衡,最終在性能上可能差異不大。
不過如果從我們當前項目的性能目標出發,為了提高效率,合并為單次遍歷可能是值得一試的優化方向。是否值得做這樣的優化,最終要依賴時間和測試去驗證。
總結來說,不管是哪種方式,本質上算法的復雜度仍是線性的 O(n),只是具體實現上的優化手段不同,對性能的影響也需要在實際運行中才能確定。
【題外話】:我對軸-角旋轉和四元數旋轉有點困惑。我以為四元數本來就是角度和軸的表示,它們有什么不同?
我們討論了一個關于旋轉表示的“題外話”問題,核心在于澄清軸-角(Axis-Angle)旋轉和四元數(Quaternion)旋轉之間的區別。
首先,需要明確的是:所有旋轉的數學表示形式本質上都在表達“旋轉軸”和“旋轉角度”。因為從幾何上講,任意一個三維空間中的旋轉都可以被完全描述為“繞某個軸轉某個角度”。
換句話說,不管使用哪種表示方式——矩陣、歐拉角、軸-角、四元數,本質上它們都在描述同樣的事情:一個旋轉軸 + 一個旋轉角度,只不過是表達方式不同。
所以,問題的關鍵不在于“是否包含軸和角”,而是**“怎樣”包含軸和角**:
- 軸-角表示 是最直接的:顯式地給出一個單位向量作為旋轉軸,一個標量作為旋轉角度。
- 四元數表示 雖然看起來是四個數,但內部仍然隱含了旋轉軸和角度。一個單位四元數可以被分解為:
- 實部(w)表示角度的一部分:cos(θ/2)
- 虛部(x, y, z)構成軸向量(乘上 sin(θ/2))
因此,四元數確實間接地表示了軸和角,只是方式不同,不如軸-角那么直觀。我們理解四元數時,重點是它的內部結構正好與軸-角的三維表示具有一種數學上的緊密聯系。
總結來說:
- 旋轉本質都是由“軸 + 角度”組成。
- 所有的旋轉表示法都在描述這個概念。
- 它們之間的區別,僅僅在于編碼方式的不同,而不是是否包含旋轉軸和角度這個信息本身。
黑板:歐拉角(Euler Angles)
我們進一步分析了幾種常見的旋轉表示方法,并澄清了它們的本質差異。
首先看歐拉角(Euler Angles),這是比較常見的一種旋轉表示方式。歐拉角通常由三個角度組成,分別表示物體依次繞三個不同的坐標軸旋轉的角度。比如,可以先繞 X 軸旋轉,再繞 Y 軸旋轉,最后繞 Z 軸旋轉。每一步的旋轉順序對最終結果有顯著影響,因此歐拉角在實際使用中可能會帶來一些混淆,尤其是在理解方向變化或處理萬向節鎖(Gimbal Lock)問題時。
這里特別強調一點,“歐拉角”和“歐拉參數”并不是一回事。歐拉參數更偏向于四元數或指數映射這類的旋轉表示方法,屬于更抽象和數學化的體系,因此我們先不深入探討歐拉參數。
回到歐拉角的角度來看,雖然它通過三個順序旋轉構建出最終的旋轉狀態,但最終的結果仍然可以被理解為繞某個軸轉某個角度而達到的狀態。換句話說,不論使用怎樣的組合旋轉去表達,所有的空間方向變化最終都可以歸結為“繞某個軸轉某個角度”這一種形式。這是旋轉在三維空間中的基本性質。
所以,歐拉角只是編碼方式復雜一點,它將一個最終的旋轉分解成三個順序的旋轉動作。但無論怎么分解,最終這個旋轉都等價于某個旋轉軸 + 一個旋轉角度,也就是我們前面提到的“軸-角”本質。
總結幾點:
- 歐拉角用三個角度描述三個順序旋轉,雖然形式上是三個步驟,但本質上對應的最終姿態可以簡化為繞一個軸轉一個角度。
- 所有三維旋轉都可以被表示為“軸 + 角度”。
- 旋轉的各種表示方法(歐拉角、四元數、旋轉矩陣等)只是不同的編碼方式,核心描述的幾何行為是相同的。
- 歐拉參數雖然名稱相似,但其實屬于另一類更接近四元數的數學結構,不應與歐拉角混淆。
黑板:軸 / 角度(Axis / Angle)
在進一步探討旋轉表示方法時,我們引入了軸-角(Axis-Angle)表示方式。
軸-角是一種非常直接、清晰的旋轉表示方法,它不再像歐拉角那樣用三個角度來分步驟表達旋轉,而是明確地使用一個旋轉軸和一個旋轉角度來完整描述一次旋轉操作。
在這種表示中,通常有兩個部分組成:
- 一個單位向量,表示旋轉軸的方向;
- 一個標量值,表示繞該軸旋轉的角度。
這種表示方式可以寫成一個組合結構,比如:
旋轉 = (axis, angle)
即:繞指定軸 axis 旋轉 angle 弧度或角度。
在表達中,也可能使用一些希臘字母來表示,例如:
- 角度可能記作 θ(theta)、φ(phi)等;
- 旋轉軸可能記作 ω(omega)或者是一個具體的向量(x, y, z)。
軸-角的優點在于,它準確地反映了三維空間中旋轉的本質——所有三維旋轉都可以被表示為“繞某一條軸旋轉某一角度”。
對比來看:
- 歐拉角:通過三個連續的旋轉操作(例如繞 X、Y、Z),間接表達出一個最終方向;
- 軸-角:直接以最簡形式表示“我就是繞這條軸轉了這個角度”,邏輯清晰,幾何意義明確。
雖然任何空間旋轉最終都等價于一個軸-角旋轉,但軸-角的表示方式是顯式的、直觀的,它明確寫出了那個旋轉軸和旋轉角度,沒有中間步驟的干擾。
因此,軸-角不僅在理論上具備完整性,在一些需要明確可視化、動畫插值、旋轉構造的應用場景中也很實用。這個表示方法把旋轉的核心信息——“繞哪兒轉”和“轉多少”——直接呈現出來。
黑板:四元數(Quaternion)
四元數(quaternion)是一種旋轉的編碼方式,和軸-角表示法本質是相同的,只不過表達方式不同。
在軸-角表示中,我們直接用一個單位向量表示旋轉軸,用一個角度表示旋轉幅度,表達非常直接。而在四元數中,我們將這兩個信息“編碼”進了四個數值里——這四個數值包含了旋轉軸的信息和旋轉角度的信息,但形式上更抽象一些,不是直接寫出軸和角度本身,而是它們的組合結果。
具體來說,四元數由四個分量組成:
- 向量部分(x, y, z):
- 它們是旋轉軸向量乘以
sin(θ/2),也就是說旋轉軸被縮放了;
- 它們是旋轉軸向量乘以
- 標量部分(w):
- 是**
cos(θ/2)**,表示和旋轉角度的一種關系。
- 是**
所以,一個四元數可以寫成:
q = [x * sin(θ/2), y * sin(θ/2), z * sin(θ/2), cos(θ/2)]
也就是說,它把“旋轉軸 + 角度”這樣的信息,用三角函數處理之后塞進了一個四維向量里。相比軸-角,這種編碼方式更復雜一些,不是那么直觀,但是它與軸-角完全等價,只是換了一種編碼方式而已。
我們之所以使用這種編碼方式,是因為四元數在實際應用中有很多優勢,比如:
- 沒有萬向鎖問題(Euler angle 的主要缺陷);
- 更適合用于插值(如 Slerp);
- 在組合多個旋轉時性能更高;
- 數學運算中更穩定;
當然,這種編碼方式并不是隨意發明的,它背后有很多數學動機和優勢,不只是看起來“炫”或者“好玩”。它的出現是為了解決具體的問題,比如數值穩定性、效率、插值連貫性等。
總結來說:
- 四元數和軸-角在本質上是一樣的,都是表達一次旋轉;
- 四元數是將軸和角度通過三角函數(sin/cos)編碼后表達;
- 這種編碼雖然間接,但在數學運算中更強大、更穩定;
- 四元數的四個分量中,有三個來自旋轉軸乘以
sin(θ/2),一個是cos(θ/2); - 實際使用中,這種方式在很多場景下更實用,尤其在 3D 圖形、動畫、游戲物理等領域。
黑板:指數映射(Exp Map)
指數映射(Exponential Map)也是一種旋轉表示方式,它本質上仍然是軸-角(Axis-Angle)表示的另一種編碼手段。
在這種表示中,我們將旋轉軸直接乘以旋轉角度,形成一個向量。這個向量本身就表示了旋轉的信息:
- 方向是旋轉軸;
- 長度是旋轉角度。
也就是說,指數映射就是把“旋轉軸 + 角度”這個信息,合并成了一個三維向量。我們可以直觀地理解為:
exp_map = 旋轉角度 × 單位旋轉軸向量
這個表示方式和角速度(Angular Velocity)非常類似,因為瞬時角速度也是用一個向量表示,其中方向代表旋轉的軸,大小代表旋轉的速率。所以指數映射也常被用于旋轉插值、動態模擬等場景。
實際上,指數映射、四元數、軸-角本質上都在表達同樣的旋轉信息,區別只是數學上是如何編碼和處理這個信息的:
- 軸-角直接表示旋轉軸和角度;
- 四元數通過
sin(θ/2)和cos(θ/2)把旋轉軸和角度編碼進四維向量; - 指數映射把旋轉角度直接乘進旋轉軸,變成一個三維向量。
它們之間的關系是:
- 四元數可以從指數映射轉換而來;
- 指數映射可以從軸-角轉換而來;
- 它們在數學形式上不同,但表達的結果完全一致——都是一次繞某個軸的旋轉。
可以說,所有這些旋轉表示的方式,雖然表現形式不同,但核心思想完全一致:描述一個物體圍繞某個軸以一定角度旋轉的狀態。
最終可以總結為:
- 所有旋轉本質上都可以看作是繞某條軸旋轉一定角度;
- 軸-角、四元數、指數映射等只是不同的編碼手段;
- 它們在用途和性能方面有差別,選擇哪一種取決于具體需求;
- 本質邏輯是一致的,只是表現方式不同。
我注意到幀時間越來越長了,你打算進一步優化軟件渲染器,還是考慮轉向硬件加速?
目前的幀時間已經變得相當大了,不過整體上仍然處于可接受的范圍,在開發階段依然是完全可用的狀態,所以暫時并沒有特別在意優化的問題。對于是否要進一步對軟件進行優化,或者轉向硬件加速方案,目前還沒有明確的決定。
現在的情況是,即便幀時間變長了,也沒有嚴重影響正常的使用流程,因此還沒有急迫地去處理這部分性能問題。至于幀率是否會因為切換到低分辨率模式而有所改善,目前沒有精確的數據,也不太記得降低分辨率后的具體性能表現到底如何了。
所以現在暫時還沒采取措施去調整渲染方式或者性能結構,不過未來是否會做出改變,還要看后續使用中幀率的表現以及整體需求的變化。只要當前性能還能支撐開發流程,就不會特別優先處理這塊。
win32_game.cpp:將分辨率降到 960x540,關閉調試系統并運行游戲
如果決定將游戲運行在半分辨率或四分之一分辨率模式下,并關閉調試功能,性能可能會有所改善。不過,當前的開發階段并不急于優化更多,因為這些調整已經足夠快速,并且對于制作游戲來說是完全可以接受的。
關于調試系統對性能的影響,它可能會消耗一定的時間,但并沒有造成嚴重的性能問題。實際上,調試系統對性能的影響已經不那么明顯,因此當前的性能狀況并不需要做更多優化。如果決定繼續按照目前的設置進行開發,應該不會遇到太大的問題。
總結來說,只要能夠忍受當前的開發設置,完全可以繼續保持現狀,不需要額外的優化。對于開發進程來說,現有的性能已經足夠用來推進工作,所以可以暫時不做進一步優化,專注于游戲的其他部分。






)



 / 字符串分類(字符串哈希) / 城市群數量(dfs))

之條件語句)

:基于多尺度注意力TCN-KAN與小波變換的時間序列預測模型)



)
