目錄
1、哈希表
1.1、概念
1.2、沖突
2、哈希函數設計
3、負載因子調節
4、閉散列
5、開散列/哈希桶(重點掌握)
6、實現哈希桶
6.1、put方法
6.2、HashMap的擴容機制
6.3、get方法
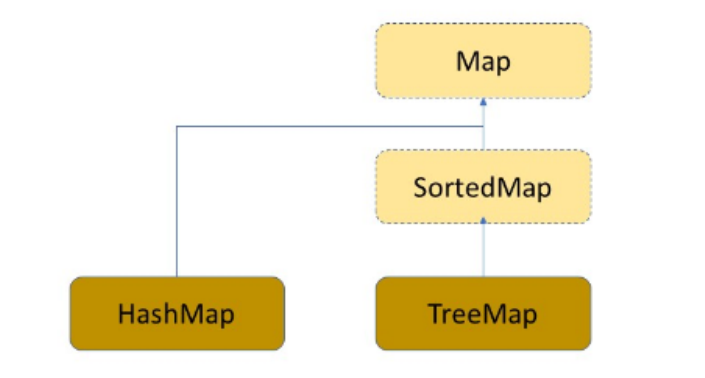
7、HashMap
8、HashSet
8.1、哈希表性能分析
9、hashcode
9.1、hashCode和equals的區別
1、哈希表
1.1、概念
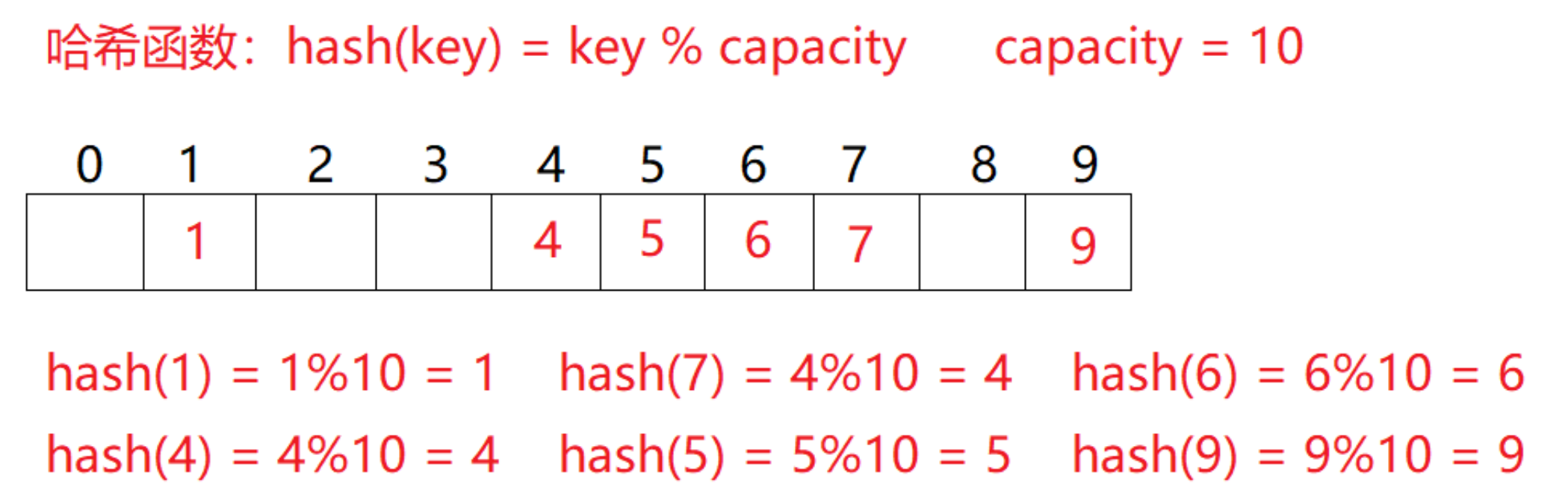
順序結構以及平衡樹中,元素關鍵碼與其存儲位置之間沒有對應的關系,因此在查找一個元素時,必須要經過關鍵碼的多次比較。
順序查找時間復雜度為O(N),平衡樹中為樹的高度,即O(logN),搜索的效率取決于搜索過程中元素的比較次數。
理想的搜索方法:可以不經過任何比較,一次直接從表中得到要搜索的元素。 如果構造一種存儲結構,通過某種函數(hashFunc)使元素的存儲位置與它的關鍵碼之間能夠建立一一映射的關系,那么在查找時通過該函數可以很快找到該元素。
當向該結構中:
插入元素:根據待插入元素的關鍵碼,以此函數計算出該元素的存儲位置并按此位置進行存放
搜索元素:對元素的關鍵碼進行同樣的計算,把求得的函數值當做元素的存儲位置,在結構中按此位置取元素比較,若關鍵碼相等,則搜索成功
該方式即為哈希(散列)方法,哈希方法中使用的轉換函數稱為哈希(散列)函數,
構造出來的結構稱為哈希表(HashTable)(或者稱散列表)
按照上述哈希方式,向集合中插入元素14,會出現沖突的現象,這種現象稱為哈希沖突
1.2、沖突
概念:
哈希沖突/哈希碰撞:不同的關鍵字KEY 通過相同的哈希函數計算出相同的哈希地址
避免:
由于哈希表底層數組的容量往往是小于實際要存儲的關鍵字的數量的,這就導致一 個問題,沖突的發生是必然的,但我們能做的應該是盡量的降低沖突率
解決哈希沖突兩種常見的方法是:閉散列和開散列
2、哈希函數設計
引起哈希沖突的一個原因可能是:哈希函數設計不夠合理。 哈希函數設計原則:
- 哈希函數的定義域必須包括需要存儲的全部關鍵碼,而如果散列表允許有m個地址時,其值域必須在0到m-1之間
- 哈希函數計算出來的地址能均勻分布在整個空間中
- 哈希函數應該比較簡單
常見哈希函數
1. 直接定址法--(常用)
取關鍵字的某個線性函數為散列地址:Hash(Key)= A*Key + B優點:簡單、均勻
缺點:需要事先知道關鍵字的分布情況
使用場景:適合查找比較小且連續的情況
????????例如:key : 91
????????int index = key - minVal????????minVal是一組數據中最小的數據
2. 除留余數法--(常用)
設散列表中允許的地址數為m,取一個不大于m,但最接近或者等于m的質數p作為除數,按照哈希函數:Hash(key) = key% p(p<=m),將關鍵碼轉換成哈希地址
3. 平方取中法--(了解)
假設關鍵字為1234,對它平方就是1522756,抽取中間的3位227作為哈希地址; 再比如關鍵字為4321,對它平方就是18671041,抽取中間的3位671(或710)作為哈希地址 平方取中法比較適合:不知道關鍵字的分布,而位數又不是很大的情況
4. 折疊法--(了解)5. 隨機數法--(了解)
6. 數學分析法--(了解)
注意:哈希函數設計的越精妙,產生哈希沖突的可能性就越低,但是無法避免哈希沖突
3、負載因子調節
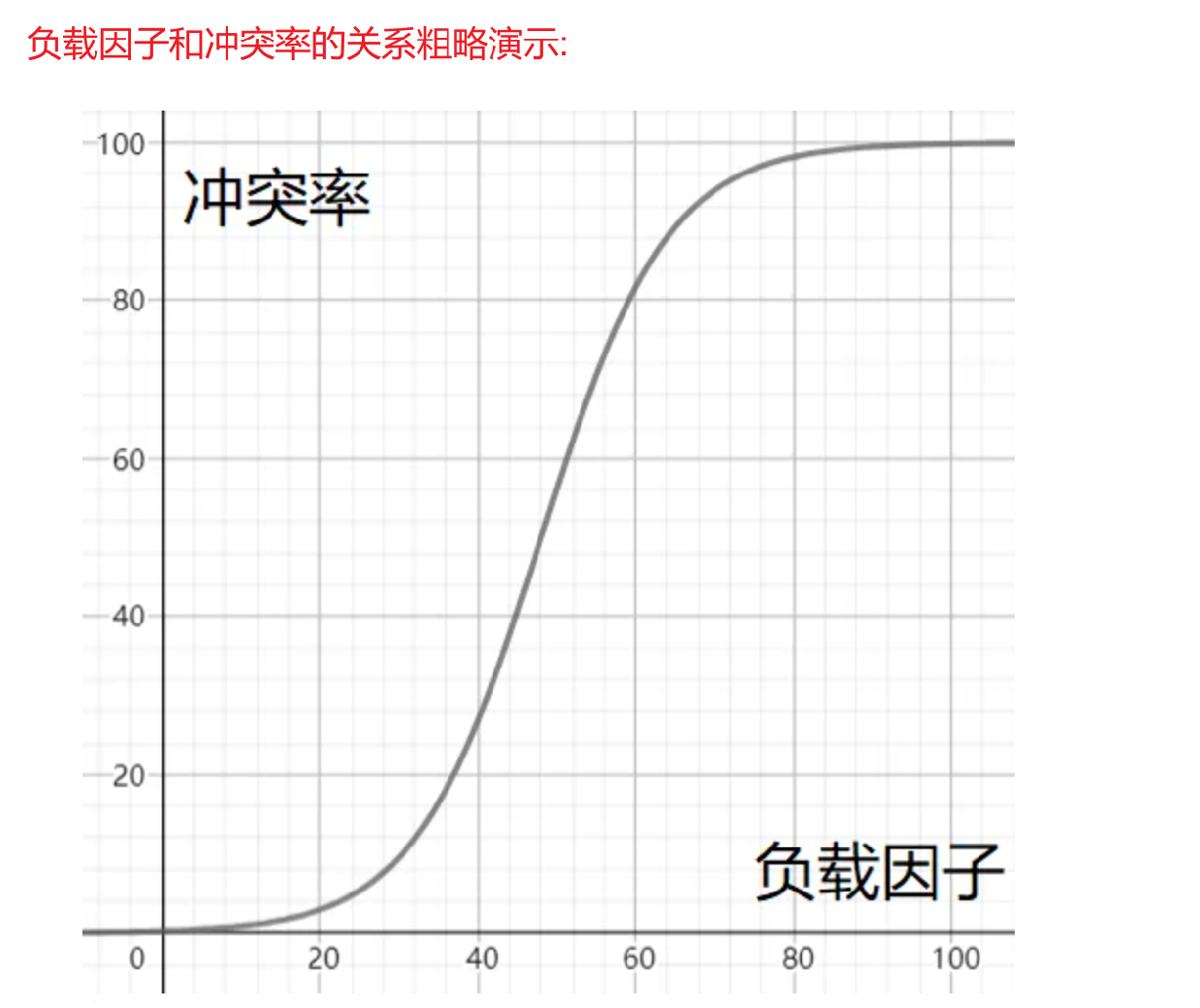
散列表的負載因子定義為:α = 填入表中的元素個數 / 散列表的長度
α 是散列表裝滿程度的標志因子。由于表長是定值,α 與“填入表中的元素個數”成正比,所以,α 越大,表明填入表中的元素越多,產生沖突的可能性就越大;反之,α 越小,表明填入表中的元素越少,產生沖突的可能性就越小。
Java的系統庫限制了負載因子為0.75,超過此值將使用擴容的方式重構散列表,將負載因子控制在 0.75 內
所以當沖突率達到一個無法忍受的程度時,我們需要通過降低負載因子來變相的降低沖突率。 已知哈希表中已有的關鍵字個數是不可變的,那我們能調整的就只有哈希表中的數組的大小
4、閉散列
閉散列:也叫開放定址法,當發生哈希沖突時,如果哈希表未被裝滿,說明在哈希表中必然還有空位置,那么可以把key存放到沖突位置中的 “下一個” 空位置中;那如何尋找下一個空位置呢?
1. 線性探測
比如上面的場景,現在需要插入元素14,先通過哈希函數計算哈希地址,下標為4,因此44理論上應該插在該 位置,但是該位置已經放了值為4的元素,即發生哈希沖突。
線性探測:從發生沖突的位置開始,依次向后探測,直到尋找到下一個空位置為止。
插入:
- 通過哈希函數獲取待插入元素在哈希表中的位置
- 如果該位置中沒有元素則直接插入新元素,如果該位置中有元素發生哈希沖突,使用線性探測找到下一個空位置,插入新元素
- 采用閉散列處理哈希沖突時,不能隨便物理刪除哈希表中已有的元素,若直接刪除元素會影響其他元素的搜索。比如刪除元素4,如果直接刪除掉,44查找起來可能會受影響。因此線性探測采用標記的偽刪除法來刪除一個元素

2. 二次探測
二次探測法指采用前后跳躍式探測的方法,發生沖突時,向后1位探測,向前1位探測,向后2^2 位探測,向前2^2 位探測……以跳躍式探測,避免堆積。
二次探測的增量序列為di =1^2 , -1^2 , 2^2 , -2^2 , …, k^2 , -k^2(k ≤m /2),對應哈希函數中的 i = 1,2,3,4, …
研究表明:當表的長度為質數且表裝載因子 α 不超過0.5?時,新的表項一定能夠插入,而且任何一個位置都不會被探查兩次。
因此只要表中有一半的空位置,就不會存在表滿的問題。
在搜索時可以不考慮表裝滿的情況,但在插入時必須確保表的裝載因子a不超過0.5,如果超出必須考慮增容。
因此:閉散列最大的缺陷就是空間利用率比較低,這也是哈希的缺陷
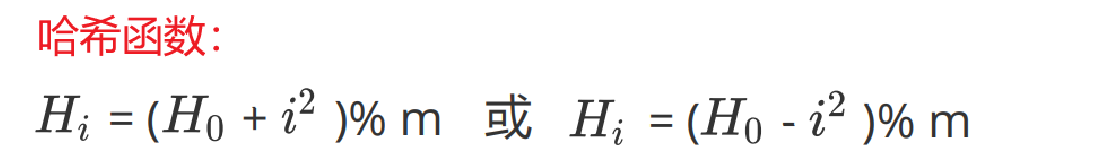
5、開散列/哈希桶(重點掌握)
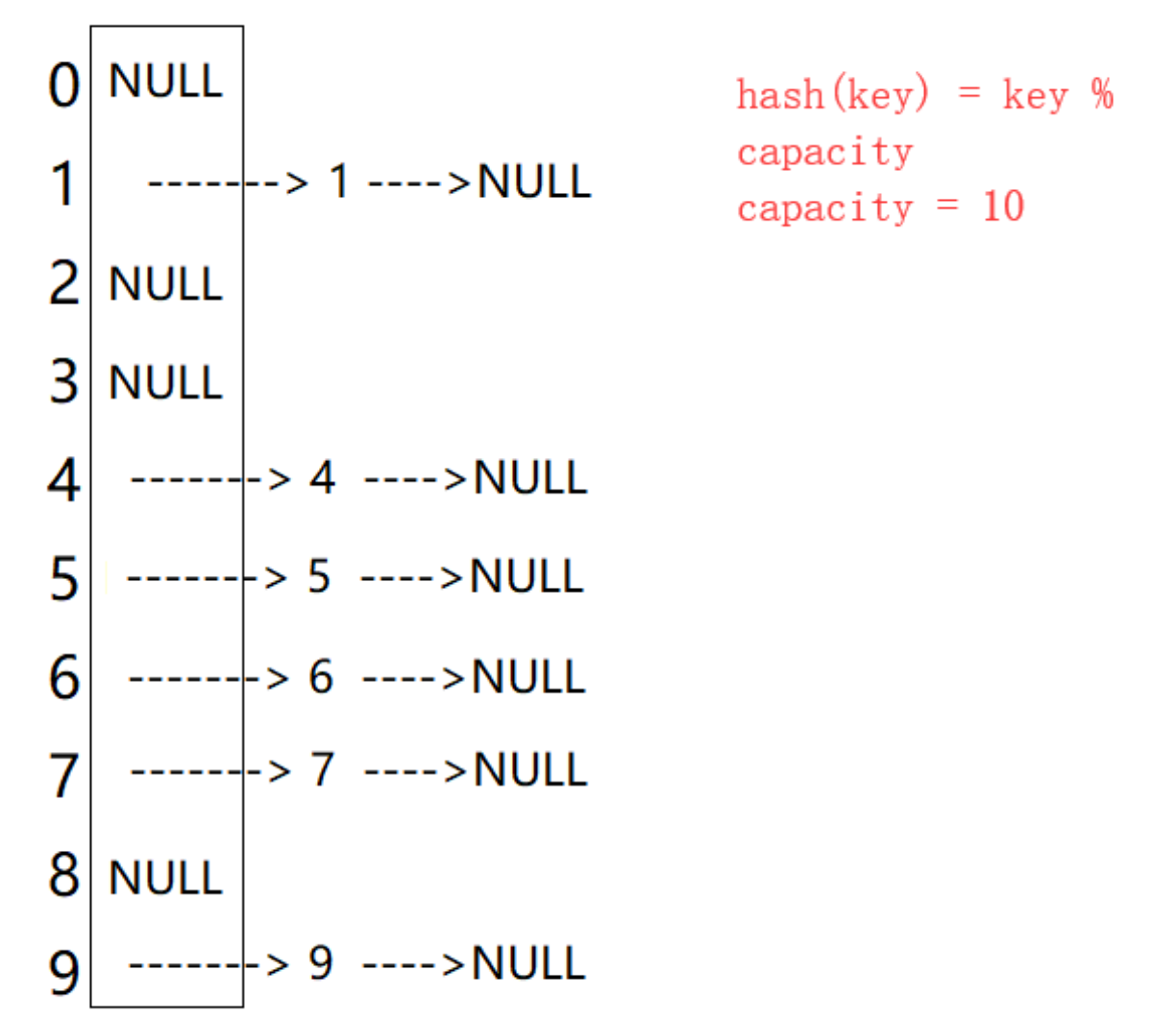
開散列法又叫鏈地址法(開鏈法)
核心思想:將所有元素存儲在一個鏈表中,每個鏈表的頭指針存儲在哈希表的相應槽位中。當發生哈希沖突時,新的元素會被添加到對應鏈表的末尾,哈希表的每個元素就是各鏈表的頭節點
插入鏈表的時,JDK1.7及以前采用的是頭插法,1.8 開始采用尾插法
從上圖可以看出,開散列中每個桶中放的都是發生哈希沖突的元素。
開散列,可以認為是把一個在大集合中的搜索問題轉化為在小集合中做搜索了
如果沖突嚴重,就意味著小集合的搜索性能其實也時不佳的,這個時候我們就可以將這個所謂的小集合搜索問題繼續進行轉化,例如:
1. 每個桶的背后是另一個哈希表
2. 每個桶的背后改變成一棵搜索樹,比如說變成紅黑樹
Java的HashMap就是就是采用開散列的方式來解決哈希沖突的
數組+鏈表+紅黑樹(當數組長度 >= 64 && 鏈表長度 >=8 以后,就會把鏈表變成紅黑樹)
6、實現哈希桶
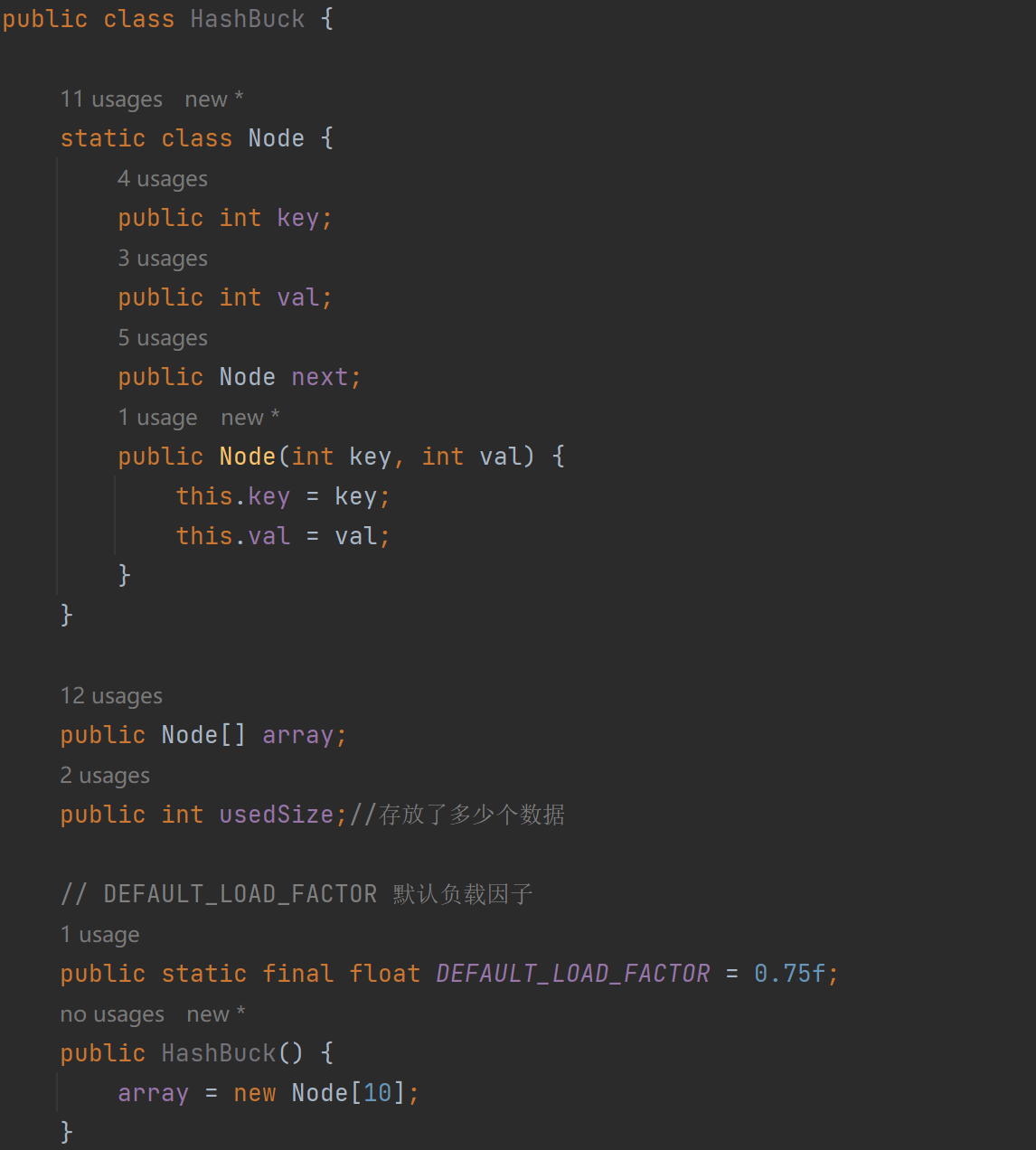
6.1、put方法
面試問題:
1.上圖的這種擴容方式可不可行
答:不可以,因為數組長度變了,原來位置沖突的元素可能要放到新的數組的其他位置去
2. 擴容需要注意的是什么?
答:HashMap 擴容時,原來 HashMap 中數組下的每一個結點都要重新計算它在新數組中的位置(重新哈希)
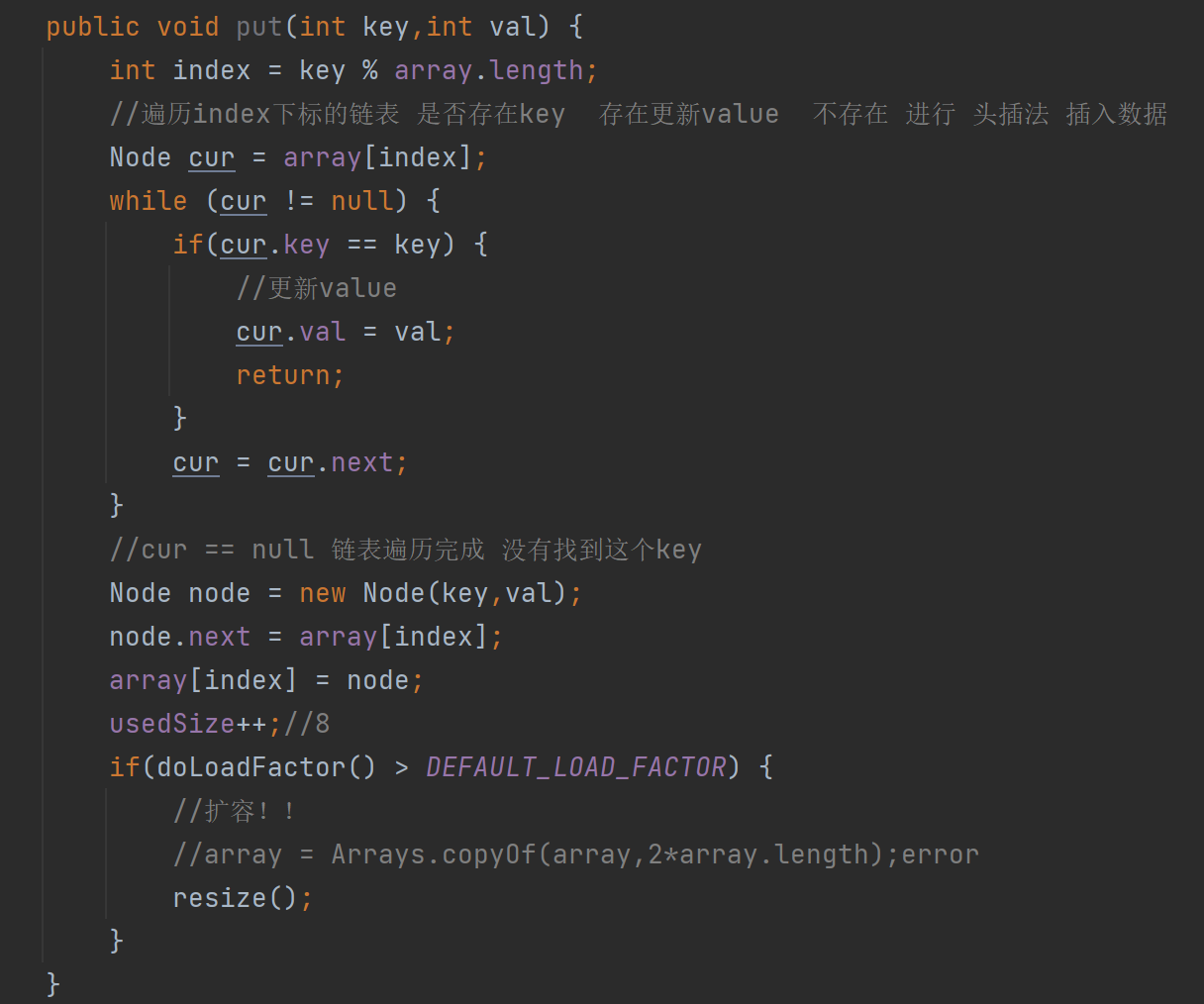
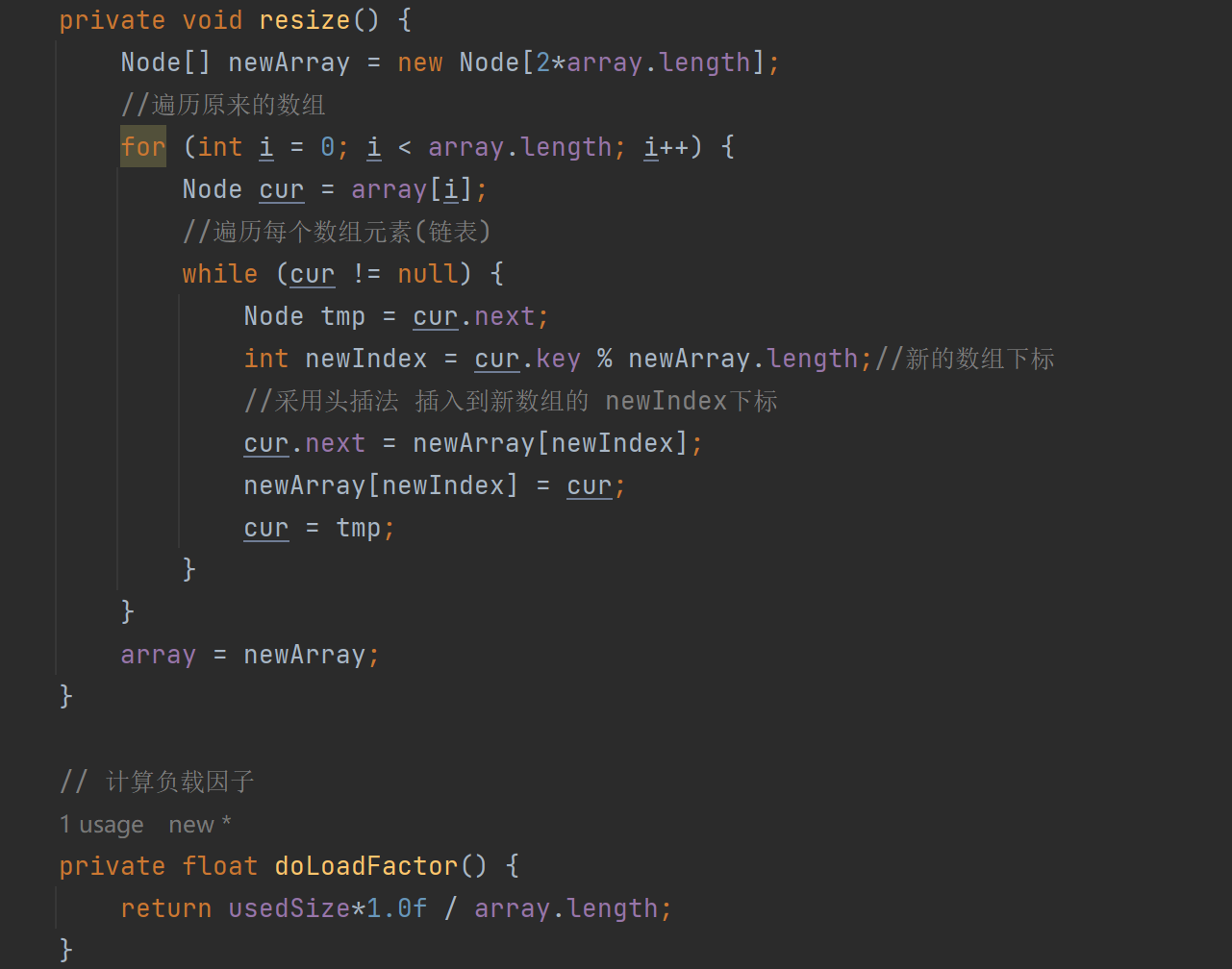

6.2、HashMap的擴容機制
為什么需要擴容?
????????隨著哈希表中存儲的元素不斷增加,哈希沖突的概率也會越來越高,這會導致哈希表的性能下降,查找、插入和刪除操作的時間復雜度可能會接近O(n)。為了保證哈希表的性能,當哈希表中的元素數量達到一定閾值時,就需要對哈希表進行擴容。
擴容的觸發條件:
在 HashMap 中,有兩個重要的參數:容量(capacity)和負載因子(loadFactor)。容量指的是哈希表中數組的長度,負載因子是一個介于 0 到 1 之間的浮點數,默認值為 0.75。當哈希表中的負載因子大小超過 0.75 時,就會觸發擴容操作。
擴容的過程:
- 創建新數組:將原數組的容量擴大為原來的 2 倍。
- 重新哈希:遍歷原數組中的每個元素,重新計算它們在新數組中的位置,并將元素插入到新數組中。
6.3、get方法
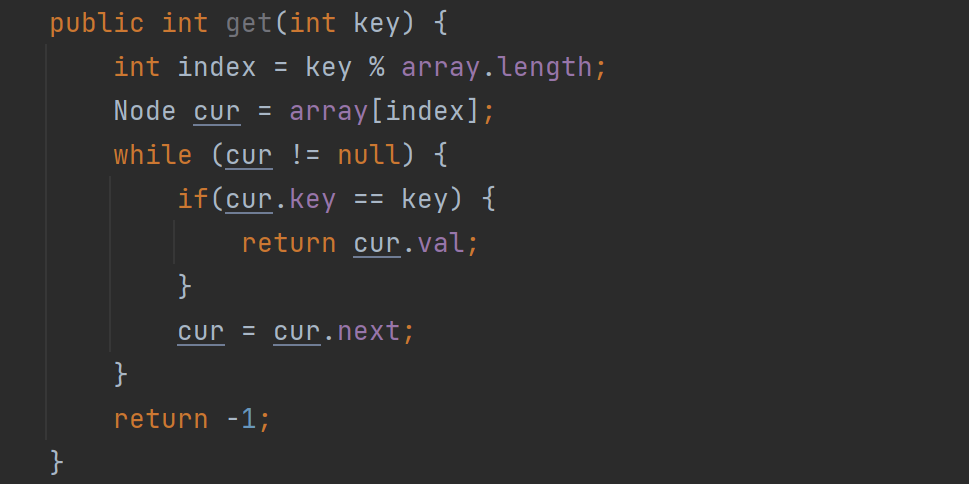
7、HashMap
? ? HashMap<String,Integer> map = new HashMap<>();
? ? map.put("hello",2);
? ? map.put("abcd",10);
? ? map.put("zhang",3);
????Integer val = map.get("abcd");
? ? System.out.println(val); // 10
? ? // 不是按順序輸出的,因為HashMap底層是哈希桶,是通過某種哈希函數確定的位置的
? ? System.out.println(map);
? ? // 遍歷方式
? ? for(Map.Entry<String,Integer> entry :map.entrySet()){
? ? ? ? ?System.out.println("key: "+entry.getKey()+" val: "+entry.getValue());
????}
Map不支持迭代器遍歷,因為支持迭代器遍歷的都實現了 Iterable 接口,HashMap和TreeMap 都沒有實現 Iterable 接口;要想用迭代器遍歷,只能將Map轉換為Set,再通過迭代器遍歷Set
Map的一個注意事項:HashMap的key可以是對象,也可以是null,TreeMap則不行,因為TreeMap的key必須是可以比較的
? ? ?HashMap<Student,Integer> map2 = new HashMap<>();
? ? ?map2.put(new Student(),2); // hashcode
? ? ?map2.put(new Student(),2);?? ? ?map2.put(null,2);
? ? ?// 上述代碼均能通過
8、HashSet
1. Set不能存儲相同的key,天然可以去重的
????????HashSet<String> set = new HashSet<>();
????????set.add("hello");
????????set.add("abcd");
????????set.add("hello");????????System.out.println(set); // 打印結果:[hello, abcd]
2. 不是按順序輸出的,因為HashSet底層是哈希桶,是通過某種哈希函數確定的位置的
3.?底層是一個HashMap 每次存儲元素時,默認的value是一個Objcet對象

8.1、哈希表性能分析
雖然哈希表一直在和沖突做斗爭,但在實際使用過程中,我們認為哈希表的沖突率是不高的,沖突個數是可控的, 也就是每個桶中的鏈表的長度是一個常數,所以,通常意義下,我們認為哈希表的插入/刪除/查找時間復雜度是 O(1) 。
9、hashcode
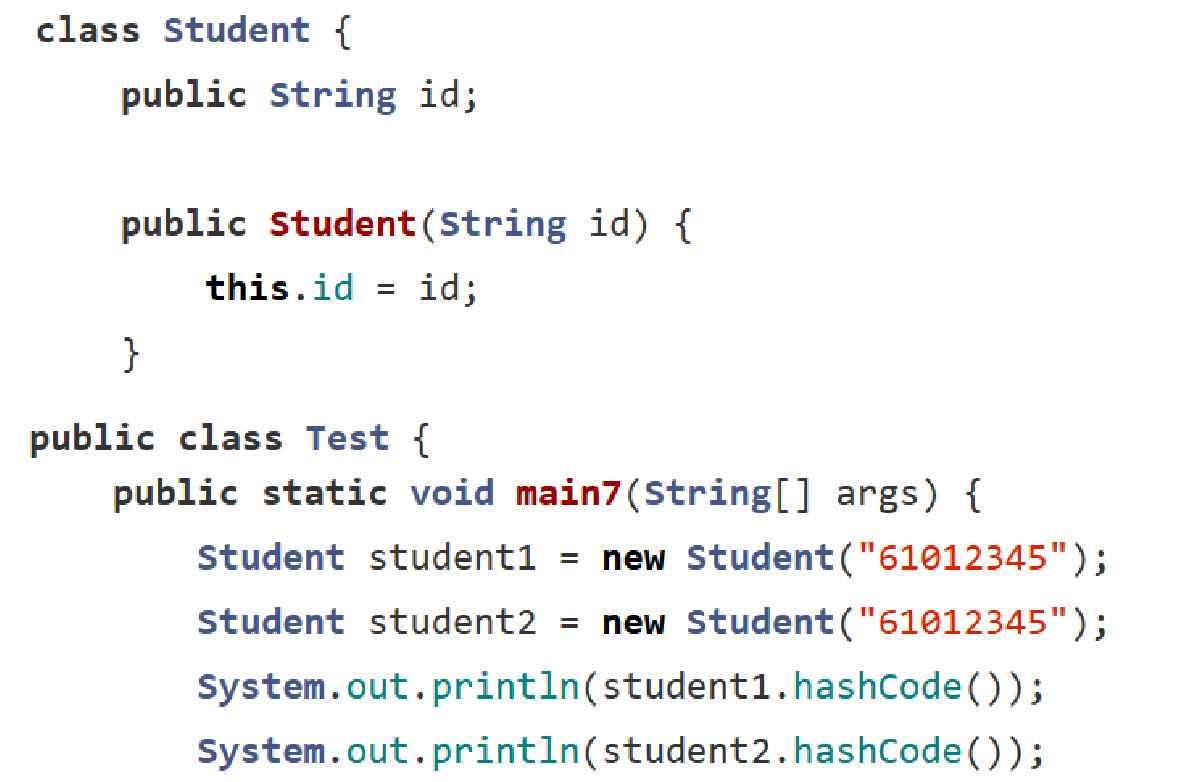
通過上述可以知道,HashMap的key可以是對象,也可以是null,使用哈希函數的key一定得轉化為整數,那么如何把對象轉化為整數呢?? -- 使用hashcode方法可以把對象轉化為整數
hashcode方法是Object類中的方法,所以可以直接調用
兩個相同id的學生,正常情況下在HashMap中在同一個位置,但上圖的運行結果得到的整數是不一樣的;想要得到正確的結果,需要重寫hashcode方法
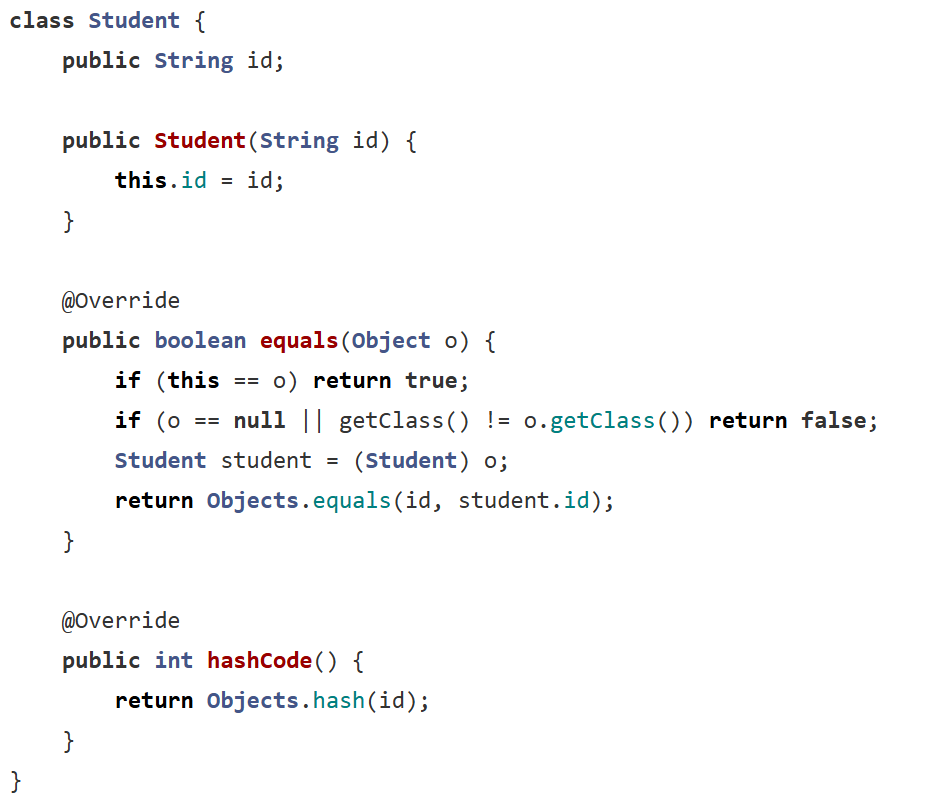
在IDEA中直接生成,會根據id生成重寫的 equals() 和 hashCode() 方法
重寫后,再運行相同id的學生會輸出相同的整數,這樣再通過哈希之后就會在相同的位置;
使用HashMap可以用關鍵字student2拿到student1的值,說明這里的HashMap調用的是自己重寫后的hashcode,如果沒有重寫則找不到
所以,當以后在寫一個自定義類型的時候,最好把equals() 和 hashCode() 方法都進行重寫,這樣就不會出現一些意料之外的事情;拓展:建議把toString也寫一下

9.1、hashCode和equals的區別
1. 如果兩個對象相等,那么它們的hashCode()值一定相同。這里的相等是指,通過equals()比較兩個對象時返回true。
2. 如果兩個對象hashCode()相等,它們不一定相等。因為在散列表中,hashCode()相等,即兩個鍵值對的哈希值相等。然而哈希值相等,并不一定能得出鍵值對相等,此時就出現所謂的哈希沖突場景。3.?hashCode和equals的最大區別就是:hashCode 用于找到關鍵字在哈希表中的位置,這個位置的關鍵字的hashCode都是相同的;找到位置后,從該位置下的所有關鍵字中找到某個關鍵字用 equals
總結:equals方法用于判斷兩個對象是否相等,hashCode方法用于生成對象的哈希碼。equals方法要求兩個對象相等時hashCode值也相等,而hashCode方法要求hashCode值相等時兩個對象不一定是相等的
10、實現哈希桶<K,V>
public class HashBuck2<K,V> {static class Node<K,V> {public K key;public V val;public Node<K,V> next;public Node(K key,V val) {this.key = key;this.val = val;}}public Node<K,V>[] array;public int usedSize;public static final float DEFAULT_LOAD_FACTOR = 0.75f;public HashBuck2() {array = (Node<K,V>[])new Node[10];}public void put(K key,V val) {int hash = key.hashCode();int index = hash % array.length;Node<K,V> cur = array[index];while (cur != null) {if(cur.key.equals(key)) {//更新valuecur.val = val;return;}cur = cur.next;}Node<K,V> node = new Node(key,val);node.next = array[index];array[index] = node;usedSize++;}public V getValue(K key) {int hash = key.hashCode();int index = hash % array.length;Node<K,V> cur = array[index];while (cur != null) {if(cur.key.equals(key)) {return cur.val;}cur = cur.next;}return null;}
}




)






)

DeepSeek專題(4))




