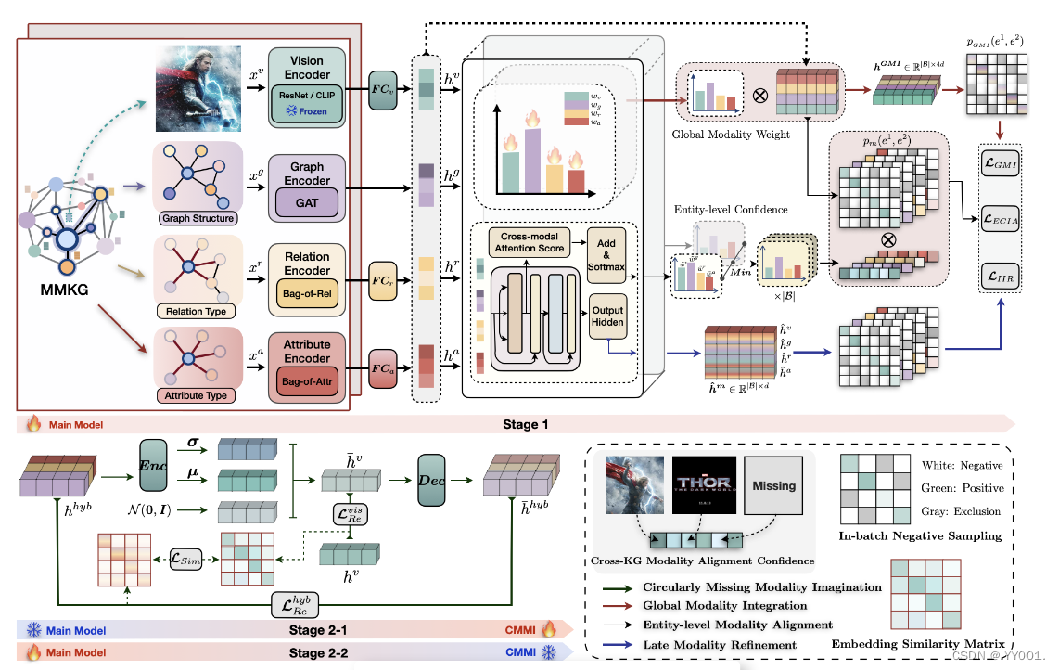
Preliminaries
MMKG為一個五元組G={E, R, A, V, T},其中E、R、A和V分別表示實體集、關系集、屬性集和圖像集。
T?E×R×E是關系三元組集。
給定兩個MMKG???G1 = {E1, R1, A1, V1, T1} 和 G2 = {E2, R2, A2, V2, T2},
MMEA旨在識別每個實體對(e1i,e2i),其中 e1i ∈ E1,e2i ∈ E2,且 e1i 和 e2i 對應于一個相同的現實世界實體 ei。
M = {g, r, a, v}表示為可用模態的集合
Multi-modal Knowledge Embedding
Graph Structure Embedding
![]() 表示實體 ei 的隨機初始化圖嵌入,其中 d 是預定的隱藏維度
表示實體 ei 的隨機初始化圖嵌入,其中 d 是預定的隱藏維度
![]() 對角權重矩陣,進行線性變換
對角權重矩陣,進行線性變換
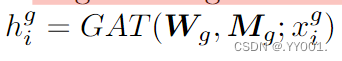 Mg表示圖鄰接矩陣。GAT是圖注意力網絡
Mg表示圖鄰接矩陣。GAT是圖注意力網絡
Relation, Attribute, and Visual Embedding
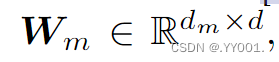
![]()

對于沒有圖像數據的實體,我們使用由其他可用圖像的均值和標準差參數化的正態分布來生成隨機圖像特征[30,7,29,10]
Multi-scale Modality Hybrid
Entity-level Modality Alignment
在知識圖譜對齊的過程中經常會使用一個手工對齊好的實體或關系謂詞集合做為引子,我們把這個叫做種子對齊集合(seed alignments)

)






)

DeepSeek專題(4))





)
)


