LLMs基礎學習(七)DeepSeek專題(4)
文章目錄
- LLMs基礎學習(七)DeepSeek專題(4)
- DeepSeek-R1 訓練過程的四個階段
- 具體流程
- 小結
- “規則化獎勵”
- 具體原因
- 小結
- “自我認知”(self-cognition)數據
- 基本概念
- 小結
- RL 訓練中過度擬合
- 避免方式
- 小結
- DeepSeek 中的蒸餾
- 蒸餾基本流程
- 性能表現
- 小結
- 為何在蒸餾過程中僅使用 SFT 而非 RL?
- 蒸餾過程中是否存在知識損失?如何量化?
- 知識損失的存在性
- 量化方法
- 知識損失的關鍵因素
- 小結
圖片和視頻鏈接:https://www.bilibili.com/video/BV1gR9gYsEHY?spm_id_from=333.788.player.switch&vd_source=57e4865932ea6c6918a09b65d319a99a
DeepSeek-R1 訓練過程的四個階段
盡管 DeepSeek-R1-Zero 展示了強大的推理能力,并能夠自主發展出意想不到且強大的推理行為,但它也面臨一些問題。例如,DeepSeek-R1-Zero 存在可讀性差和語言混雜等問題。R1 旨在成為一個更易用的模型。因此,R1 并不像 R1-Zero 那樣完全依賴于強化學習過程,而是通過多個階段完成。
具體流程
訓練過程分成四個階段:
- (SFT,Supervised Fine-Tuning(監督微調)) 冷啟動:為了避免 RL 訓練從基礎模型開始的早期不穩定冷啟動階段,構建并收集少量長的 CoT(Chain of Thought,思維鏈)數據來微調 DeepSeek-V3-Base 作為 RL 的起點。
- (RL) 推理導向的強化學習:
- 在冷啟動數據上微調 DeepSeek-V3-Base 后,應用與 DeepSeek-R1-Zero 中相同的 RL 方法訓練。
- 本階段側重于增強模型的推理能力,尤其是在編碼、數學、科學和邏輯推理等推理密集型任務中,這些任務涉及具有明確解決方案的明確定義的問題。
- 當 RL 提示涉及多種語言時,CoT 經常表現出語言混合現象。為了減輕語言混合問題,在 RL 訓練過程中引入了一種語言一致性獎勵。
- 雙獎勵系統:設計了基于規則的獎勵機制,包括:
- 準確性獎勵:評估答案正確性(如數學題答案驗證或代碼編譯測試)。
- 格式獎勵:強制模型將推理過程置于特定標簽(如和)之間,提升可讀性。
- (SFT) 拒絕采樣與監督微調:
- 當 RL 過程趨于收斂時,利用訓練出的臨時模型生產用于下一輪訓練的 SFT 數據(60W 推理數據)。
- 與冷啟動數據區別在于,此階段既包含用于推理能力提升的 60W 數據,也包含 20W 推理無關的數據。使用這 80W 樣本的精選數據集對 DeepSeek-V3-Base 進行了兩個 epoch 的微調。
- (RL) 全場景強化學習:
- 在微調模型的基礎上,使用全場景的強化學習數據提升模型回復的有用性和無害性。
- 對于推理數據,遵循 DeepSeek-R1-Zero 的方法,利用基于規則的獎勵來指導數學、代碼和邏輯推理領域的學習過程。
- 對于通用數據,采用基于模型的獎勵來捕捉復雜和細微場景中的人類偏好。
小結
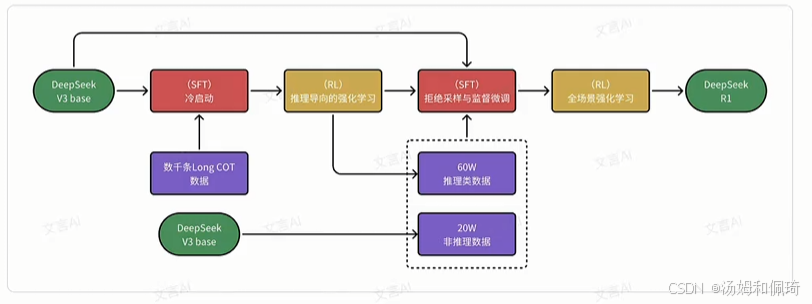
使用 (SFT) 冷啟動 -->(RL) 推理導向的強化學習 -->(SFT) 拒絕采樣與監督微調 -->(RL) 全場景強化學習四階段訓練,R1 模型達到 OpenAI-o1-1217 的水平。
“規則化獎勵”
- 規則化獎勵就像 “客觀考試評分”—— 答案對錯一目了然。
- 而神經獎勵模型類似 “老師主觀打分”,模型可能學會討好老師卻答錯題。
- 用規則化獎勵更公平、更直接。
具體原因
在推理任務中強調 “規則化獎勵” 而非神經獎勵模型的原因如下:
- 避免獎勵黑客(Reward Hacking)問題:原文指出:“神經獎勵模型在大規模強化學習過程中可能出現獎勵黑客”(“neural reward model may suffer from reward hacking in the large-scale reinforcement learning process”,章節 2.2.2)。神經獎勵模型可能被模型通過非預期方式(如利用模型漏洞)獲得高獎勵,而實際推理能力未真正提升。
- 降低訓練復雜性和資源消耗:使用神經獎勵模型需要額外訓練和維護,文檔提到 “重新訓練獎勵模型需要額外的訓練資源并復雜化整個流程”(“retraining the reward model needs additional training resources and it complicates the whole training pipeline”,章節 2.2.2)。而規則化獎勵(如準確性驗證、格式檢查)可直接通過預設規則計算獎勵,無需額外模型支持。
- 獎勵信號更清晰可靠:規則化獎勵基于確定性邏輯(如數學答案驗證、代碼編譯測試),文檔提到 “對于數學問題,模型需以指定格式提供最終答案,從而通過規則可靠驗證正確性”(“for math problems with deterministic results, the model is required to provide the final answer in a specified format… enabling reliable rule-based verification”,章節 2.2.2)。這種獎勵機制直接關聯任務目標,避免了神經獎勵模型可能引入的評估偏差。
Reward Modeling:獎勵是訓練信號的來源,決定了強化學習(RL)的優化方向。為訓練 DeepSeek-R1-Zero,采用基于規則的獎勵系統,主要由兩種獎勵組成:
- Accuracy rewards(準確性獎勵):準確性獎勵模型評估響應是否正確。例如,對于有確定結果的數學問題,模型需以指定格式(如在框內)提供最終答案,以便基于規則可靠驗證正確性。類似地,對于 LeetCode 問題,可使用編譯器基于預定義測試用例生成反饋。
- Format rewards(格式獎勵):除準確性獎勵模型外,采用格式獎勵模型,強制模型將其思考過程置于和標簽之間。
在開發 DeepSeek-R1-Zero 時不應用結果或過程神經獎勵模型,因為發現神經獎勵模型在大規模強化學習過程中可能出現獎勵黑客問題,且重新訓練獎勵模型需要額外訓練資源并使整個訓練流程復雜化。
小結
為何在推理任務中強調 “規則化獎勵” 而非神經獎勵模型?
- 避免獎勵黑客(Reward Hacking)問題
- 降低訓練復雜性和資源消耗
- 獎勵信號更清晰可靠
“自我認知”(self-cognition)數據
基本概念
根據文檔 2.3.3 章節 “Rejection Sampling and Supervised Fine-Tuning” 的描述:“自我認知”(self-cognition)數據具體指用于訓練模型理解并回答與自身屬性、能力邊界相關的查詢數據。例如:
- 關于模型身份的問答(如 “你是什么類型的 AI?”)
- 能力范圍的說明(如 “你能處理哪些類型的任務?”)
- 訓練數據相關詢問(如 “你的知識截止到什么時候?”)
- 倫理限制聲明(如 “為什么有些問題不能回答?”)
這類數據屬于非推理類數據(Non-Reasoning data),與寫作、事實問答、翻譯等任務并列,在監督微調階段用于塑造模型的自我認知能力。文檔特別指出,對于這類簡單查詢(如 “hello”),模型不需要生成思維鏈(CoT),直接給出簡潔回應即可。(“For simpler queries, such as ‘hello’ we do not provide a CoT in response.”,章節 2.3.3)
小結
“自我認知”(self-cognition)數據具體指用于訓練模型理解并回答與自身屬性、能力邊界相關的查詢數據。
RL 訓練中過度擬合
防止模型成為 “考試機器”,除模擬考(評測任務)外,還需定期抽查其他科目(多樣化任務),確保全面發展。
避免方式
- 采用多樣化的訓練數據分布:
- 混合推理與非推理數據。在監督微調(SFT)階段,收集涵蓋推理任務(如數學、編碼 )和通用任務(寫作、事實問答等)的多樣化數據,結合約 60 萬推理相關樣本和 20 萬非推理樣本,共約 80 萬訓練樣本。這種數據多樣性促使模型適應不同場景,降低對單一評測任務的依賴。
- 多階段訓練流程:
- 采用 (SFT) 冷啟動→(RL) 推理導向的強化學習→(SFT) 拒絕采樣與監督微調→(RL) 全場景強化學習四階段訓練。在接近 RL 收斂時,通過拒絕采樣生成新 SFT 數據,結合通用數據重新微調模型,最后進行二次 RL 訓練 。分階段訓練逐步擴展模型能力,避免過早過擬合。
- 組合多類型獎勵信號:
- 將規則化獎勵與人類偏好獎勵結合 。
- 在最終 RL 階段,對推理任務使用規則化獎勵(如答案準確性、格式要求),對通用任務引入人類偏好獎勵模型 。這種混合獎勵機制平衡了任務目標與泛化性。
- 拒絕采樣篩選高質量響應:
- 過濾低質量與重復內容 。在生成 SFT 數據時,通過拒絕采樣排除語言混雜、冗長或重復的推理過程 ,確保訓練數據的多樣性和可讀性,減少模型對噪聲或特定模式的依賴。
- 全場景提示分布訓練:
- 覆蓋廣泛用戶需求場景 。在最終 RL 階段,使用涵蓋數學、編碼、寫作、問答等多場景的提示分布 。通過多樣化數據優化模型,防止模型過度適配單一評測任務。
小結
避免模型在 RL 訓練中過度擬合評測任務的方法:
- 采用多樣化的訓練數據分布
- 多階段訓練流程
- 組合多類型獎勵信號
- 拒絕采樣篩選高質量響應
- 全場景提示分布訓練
DeepSeek 中的蒸餾
DeepSeek 團隊探索將 R1 的推理能力蒸餾到更小規模模型的潛力,利用 DeepSeek - R1 生成的 80W 數據對 Qwen 和 Llama 系列的多個小模型進行微調,發布了 DeepSeek - R1 - Distill 系列模型。
蒸餾基本流程
- 數據準備:DeepSeek - R1 生成 80W 高質量訓練數據,包含豐富推理鏈(Chain of Thought, CoT)和多種任務類型。
- 模型選擇:選擇 Qwen 和 Llama 系列多個小模型作為學生模型,參數規模分別為 1.5B、7B、8B、14B、32B 和 70B。
- 蒸餾訓練:使用 DeepSeek - R1 生成的數據對小模型微調,優化蒸餾損失函數,使小模型輸出接近 DeepSeek - R1 的輸出。
- 性能評估:對蒸餾后的小模型進行性能評估,驗證推理能力提升效果。
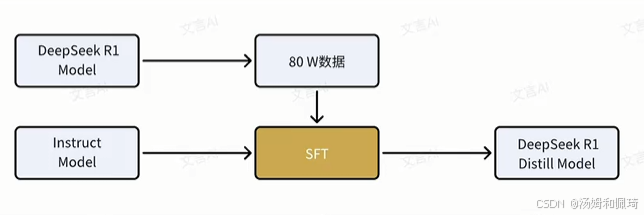
性能表現
| Model | AIME 2024 | MATH-500 | GPQA Diamond | LiveCode Bench | CodeForces | |
|---|---|---|---|---|---|---|
| pass@1 | cons@64 | pass@1 | pass@1 | pass@1 | rating | |
| GPT-4-0513 | 9.3 | 13.4 | 74.6 | 49.9 | 32.9 | 759 |
| Claude-3.5-Sonnet-1022 | 16.0 | 26.7 | 78.3 | 65.0 | 38.9 | 717 |
| OpenAI-o1-mini | 63.6 | 80.0 | 90.0 | 60.0 | 53.8 | 1820 |
| QwQ-32B-Preview | 50.0 | 60.0 | 90.6 | 54.5 | 41.9 | 1316 |
| DeepSeek-R1-Distill-Qwen-1.5B | 28.9 | 52.7 | 83.9 | 33.8 | 16.9 | 954 |
| DeepSeek-R1-Distill-Qwen-7B | 55.5 | 83.3 | 92.8 | 49.1 | 37.6 | 1189 |
| DeepSeek-R1-Distill-Qwen-14B | 69.7 | 80.0 | 93.9 | 59.1 | 53.1 | 1481 |
| DeepSeek-R1-Distill-Qwen-32B | 72.6 | 83.3 | 94.3 | 62.1 | 57.2 | 1691 |
| DeepSeek-R1-Distill-Llama-8B | 50.4 | 80.0 | 89.1 | 49.0 | 39.6 | 1205 |
| DeepSeek-R1-Distill-Llama-70B | 70.0 | 86.7 | 94.5 | 65.2 | 57.5 | 1633 |
- AIME 2024:基于 2024 年美國數學邀請賽(高中競賽級別)題目集,評估大模型多步驟數學推理能力。
- MATH-500:OpenAI 精選 500 道數學題評測集,覆蓋代數、幾何等領域,檢驗模型數學解題能力。
- GPQA Diamond:專家設計 198 道高難度 STEM 領域問題集,測試模型專業學科深度推理和抗搜索作弊能力。
- LiveCodeBench:聚焦真實世界代碼工程任務評測集,基于 GitHub 倉庫提煉 500 個 Python 問題,評估模型解決實際編程問題能力。
- CodeForces:知名編程競賽平臺動態題庫,含算法與數據結構等高難度題目,衡量模型代碼生成和復雜邏輯推理水平,根據解題正確性、速度、代碼質量等計算用戶評分(Rating) 。
小結
為使小模型具備 DeepSeek - R1 的推理能力:
- 首先通過 DeepSeek - R1 推理得到 800k 個樣本。
- 然后對 6 個不同參數量的開源模型進行直接有監督微調,即直接的數據蒸餾。
為何在蒸餾過程中僅使用 SFT 而非 RL?
蒸餾像 “臨摹大師畫作”,直接復現效果;RL 像 “自己創作”,雖可能更好但費時費力,對小模型來說,先臨摹更劃算。
主要目標驗證蒸餾有效性。在蒸餾過程中僅使用監督微調(SFT)而非強化學習(RL)的原因如下:
- 成本限制:小模型 RL 需大量計算資源,而 SFT 僅需單輪微調。
- 知識保留:SFT 直接模仿大模型輸出,避免 RL 探索中的知識遺忘。
探索:結合 SFT 與輕量 RL(如離線 RL)是否可能進一步突破?
蒸餾過程中是否存在知識損失?如何量化?
知識損失像 “壓縮圖片”,大模型(高分辨率原圖)縮成小模型(小圖)后細節模糊,主體保留但清晰度下降。
知識損失的存在性
- 蒸餾模型性能(如 32B 模型 AIME 72.6% )仍明顯低于原模型 DeepSeek - R1(AIME 79.8% ),說明存在知識損失。
- 文檔指出蒸餾模型僅 “接近 o1 - mini” 而原模型 “匹配 o1 - 1217”,佐證性能差距。
量化方法
- 標準基準測試分數對比
- 數學推理:AIME 2024 pass@1(蒸餾 32B:72.6% vs 原模型:79.8%)
- 代碼能力:Codeforces Rating(蒸餾 32B:1691 vs 原模型:2029)
- 綜合知識:GPQA Diamond(蒸餾 32B:62.1% vs 原模型:71.5%)
- 任務類型敏感性分析:需要長鏈推理的任務(如 LiveCodeBench)蒸餾模型性能下降更顯著(57.5% vs 原模型 65.9%) ,結構化任務(如 MATH - 500)損失較小(94.5% vs 97.3%) 。
知識損失的關鍵因素
- 規模效應:蒸餾 1.5B 模型 AIME 僅 28.9%,32B 模型達 72.6%,小模型因容量限制損失更多知識。
- 推理深度依賴:深層推理行為(如反思、驗證)難被小模型完全復現,導致 Codeforces 等復雜任務評分差距更大。
小結
蒸餾必然導致知識損失,其程度可通過標準基準分數差異量化,損失幅度與模型規模成反比、與任務復雜度成正比。文檔通過對比蒸餾模型與原模型的 pass@1、cons@64 評分等指標驗證了該現象。





)
)







安裝與使用---實踐)




