思路
不要問什么答什么 要學會擴充
比如問你go map的原理
- map 是什么
數據結構,字典,k/v 結構 - map的應用場景有哪些
快速查找、計數器、配置管理、去重、緩存實現 - map有哪些限制
無序性、非線程安全的讀寫 - map的key的訪問
v:= mp[key]
v,ok := mp[key]
for k,v:=range mp {} - map相關原理
語言層面
通用
go
Go并發原語 groutine select channel sync包
有沒有了解channel的底層結構體。
使用channel時需要注意哪些事項,以及哪些場景下會panic。
map擴容:map什么時候觸發擴容,哈希沖突的解決方案是什么
go內存分配的實現原理是什么
怎么在go中并發編程下等待多個協程的結束,Add()是什么意思。
go的slice不斷append時是如何分配內存的,擴容規則是什么。
defer是用來做什么的,應用場景有哪些。
多個defer執行順序:多個defer的執行順序是怎樣的。
map和slice哪個是線程安全的,map手動加鎖和sync.Map的區別是什么。
如何控制 goroutine 的生命周期(channel 的作用,context 的作用)
協程切換的時機?
sema鎖是什么?mutex源碼中的結構有看過嗎?
正常模式和饑餓模式?
如何檢測鎖異常?
go vet 查看是否存在拷貝鎖 race 競爭檢測
olang在1.1之后引入了競爭檢測機制,可以使用 go run -race 或者 go build -race來進行靜態檢測。
其在內部的實現是,開啟多個協程執行同一個命令, 并且記錄下每個變量的狀態.
競爭檢測器基于C/C++的ThreadSanitizer運行時庫,該庫在Google內部代碼基地和Chromium找到許多錯誤。這個技術在2012年九月集成到Go中,從那時開始,它已經在標準庫中檢測到42個競爭條件。現在,它已經是我們持續構建過程的一部分,當競爭條件出現時,它會繼續捕捉到這些錯誤。
競爭檢測器已經完全集成到Go工具鏈中,僅僅添加-race標志到命令行就使用了檢測器。
$ go test -race mypkg // 測試包
$ go run -race mysrc.go // 編譯和運行程序
$ go build -race mycmd // 構建程序
$ go install -race mypkg // 安裝程序
要想解決數據競爭的問題可以使用互斥鎖sync.Mutex,解決數據競爭(Data race),也可以使用管道解決,使用管道的效率要比互斥鎖高.
- 你知道 Go 條件編譯嗎?
Golang支持兩種條件編譯的實現方式:
編譯標簽(build tags):
編譯標簽由空格分隔的編譯選項(options)以”或”的邏輯關系組成
每個編譯選項由逗號分隔的條件項以邏輯”與”的關系組成
每個條件項的名字用字母+數字表示,在前面加!表示否定的意思
不同tag域之間用空格區分,他們是OR關系
同一tag域之內不同的tag用都好區分,他們是AND關系
每一個tag都由字母和數字構成,!開頭表示條件“非”
% head headspin.go
// Copyright 2013 Way out enterprises. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
// +build someos someotheros thirdos,!amd64
// Package headspin implements calculates numbers so large
// they will make your head spin.
package headspin
文件后綴(file postfix):
這個方法通過改變文件名的后綴來提供條件編譯,這種方案比編譯標簽要簡單,go/build可以在不讀取源文件的情況下就可以決定哪些文件不需要參與編譯。
文件命名約定可以在go/build 包里找到詳細的說明,簡單來說如果你的源文件包含后綴:_GOOS.go,那么這個源文件只會在這個平臺下編譯,_GOARCH.go也是如此。這兩個后綴可以結合在一起使用,但是要注意順序:_GOOS_GOARCH.go, 不能反過來用:_GOARCH_GOOS.go. 例子如下:
mypkg_freebsd_arm.go // only builds on freebsd/arm systems
mypkg_plan9.go // only builds on plan9
3. 如何實現交叉編譯?
我們知道golang一份代碼可以編譯出在不同系統和cpu架構運行的二進制文件。go也提供了很多環境變量,我們可以設置環境變量的值,來編譯不同目標平臺。
GOOS: 目標平臺; GOARCH: 目標架構。
# 編譯目標平臺linux 64位
GOOS=linux GOARCH=amd64 go build main.go# 編譯目標平臺windows 64位
GOOS=windows GOARCH=amd64 go build main.go
數據結構
slice
動態數組,底層依然是數組
擴容 1024 翻倍與1.25
如果你預測到切片的增長很大,可以考慮在創建切片時預先設置合適的容量,以減少內存分配和復制的次數
slice是線程安全的么?
map
基本結構介紹
桶的集合 哈希種子 舊桶 溢出桶 遷移進度字段
桶每個存8個 根據高八位 低八位 多的溢出桶中
存儲是先key再value 類似數組 這樣存儲的好處是可以消除字節對齊帶來的空間浪費
生成map的時候會預先生成一些溢出桶 存在字段中
擴容條件
- 負載因子過高:負載因子是指map中元素數量與桶數量的比值。當負載因子超過一定閾值時,map會進行擴容。默認情況下,負載因子的閾值為6.5,即當map中的元素數量超過桶數量的6.5倍時,會觸發擴容。
- 溢出桶過多:
漸進式擴容 每次新建 刪除等操作
是線程安全的么?map是線程不安全的
sync.map
是線程安全的么?
defer
defer順序 里面如果panic
channel
是線程安全的么?
GC
GC 三色標記
-
如果 goroutine 一直占用資源怎么辦,GMP模型怎么解決這個問題
如果有一個goroutine一直占用資源的話,GMP模型會從正常模式轉為饑餓模式,通過信號協作強制處理在最前的 goroutine 去分配使用 -
如果若干個線程發生OOM,會發生什么?Goroutine中內存泄漏的發現與排查?項目出現過OOM嗎,怎么解決?
線程 如果線程發生OOM,也就是內存溢出,發生OOM的線程會被kill掉,其它線程不受影響。 -
Goroutine中內存泄漏的發現與排查
go中的內存泄漏一般都是goroutine泄露,就是goroutine沒有被關閉,或者沒有添加超時控制,讓goroutine一只處于阻塞狀態,不能被GC。在Go中內存泄露分為暫時性內存泄露和永久性內存泄露。
暫時性內存泄露,string相比切片少了一個容量的cap字段,可以把string當成一個只讀的切片類型。獲取長string或者切片中的一段內容,由于新生成的對象和老的string或者切片共用一個內存空間,會導致老的string和切片資源暫時得不到釋放,造成短暫的內存泄漏。
永久性內存泄露,主要由goroutine永久阻塞而導致泄漏以及time.Ticker未關閉導致泄漏引起。
- Go的垃圾回收算法
Go 現階段采用的是通過三色標記清除掃法與混合寫屏障GC策略。其核心優化思路就是盡量使得 STW(Stop The World) 的時間越來越短。
GC 的過程一共分為四個階段:
棧掃描(STW),所有對象開始都是白色
從 root 開始找到所有可達對象(所有可以找到的對象),標記灰色,放入待處理隊列
遍歷灰色對象隊列,將其引用對象標記為灰色放入待處理隊列,自身標記為黑色
清除(并發)循環步驟3 直到灰色隊列為空為止,此時所有引用對象都被標記為黑色,所有不可達的對象依然為白色,白色的就是需要進行回收的對象。三色標記法相對于普通標記清除,減少了 STW 時間。這主要得益于標記過程是 “on-the-fly”的,在標記過程中是不需要 STW的,它與程序是并發執行的,這就大大縮短了 STW 的時間。
寫屏障: 插入屏障, 在A對象引用B對象的時候,B對象被標記為灰色。(滿足強三色不變性)
刪除屏障,被刪除的對象,如果自身為灰色或者白色,那么被標記為灰色。(滿足弱三色不變性)
混合寫屏障: GC開始將棧上的對象全部掃描并標記為黑色(之后不再進行第二次重復掃描,無需STW), GC期間,任何在棧上創建的新對象,均為黑色。 被刪除的對象標記為灰色。 被添加的對象標記為灰色。
go內存逃逸
面試應該從以下角度回答
- 什么是逃逸?
- 導致內存逃逸的原因是什么
- 常見的發生逃逸的情況與逃逸分析
- 如何避免
Go程序啟動時發生什么
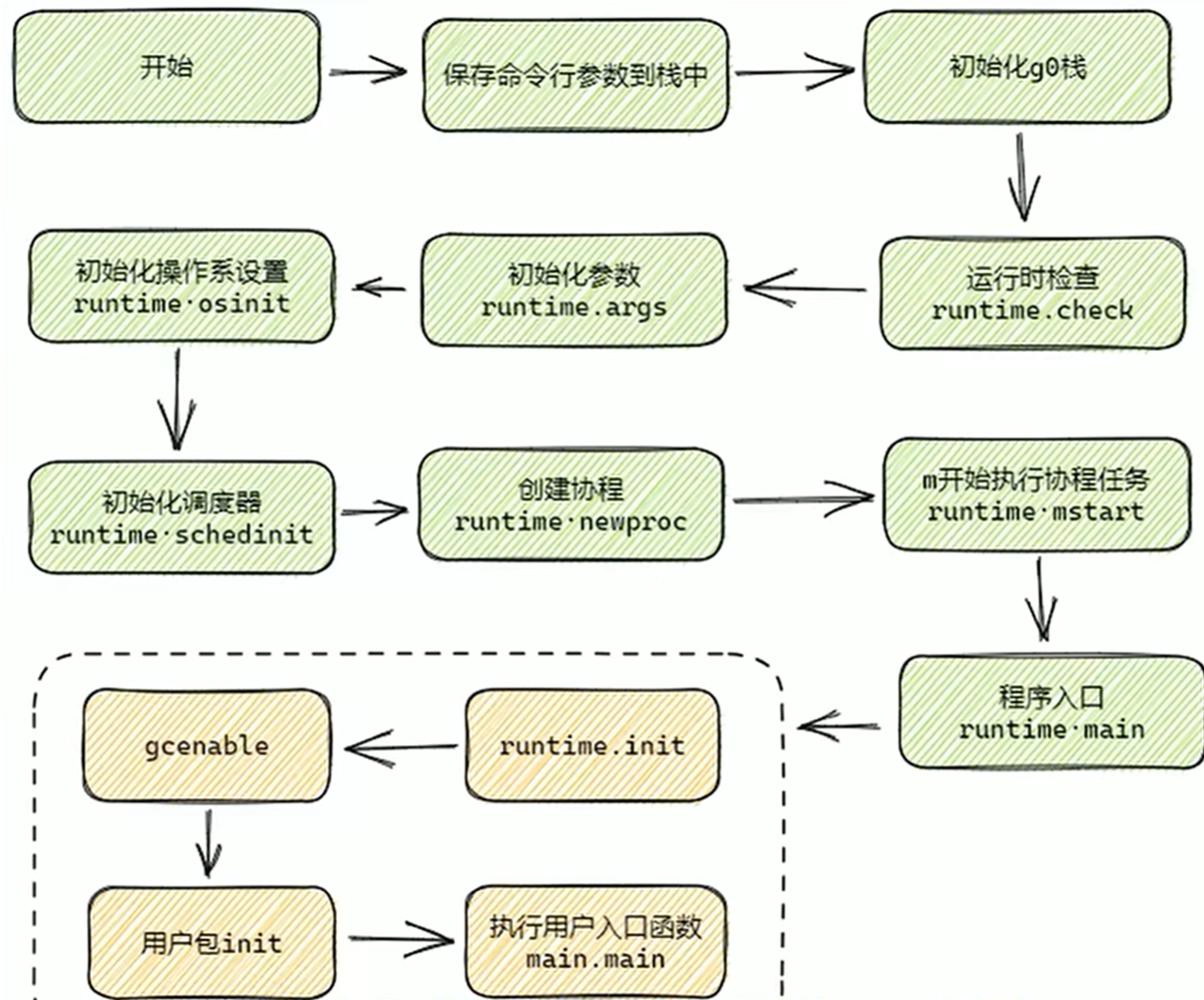
Golang 程序的運行入口是 runtime 定義的一個匯編函數。這個函數核心有三個邏輯:
第一、通過 runtime 中的 osinit、schedinit 等函數對 golang 運行時進行關鍵的初始化。在這里我們將看到 GMP 的初始化,與調度邏輯。
第二、創建一個主協程,并指明 runtime.main 函數是其入口函數。因為操作系統加載的時候只創建好了主線程,協程這種東西還是得用戶態的 golang 自己來管理。golang 在這里創建出了自己的第一個協程。
第三、調用 runtime·mstart 真正開啟調度器進行運行。
當調度器開始執行后,其中主協程會進入 runtime.main 函數中運行。在這個函數中進行幾件初始化后,最后后真正進入用戶的 main 中運行。
第一、新建一個線程來執行 sysmon。sysmon的工作是系統后臺監控(定期垃圾回收和調度搶占)。
第二、啟動 gc 清掃的 goroutine。
第三、執行 runtime init,用戶 init。
第四、執行用戶 main 函數。
本題:感覺只要答出來M0的創建和M0的G0是怎么初始化 runtime 環境、goroutine的生命周期的就好,再往深的地方走面試就不用面了,時間能都砸這個上面
GMP
P的數量怎么設置:在程序中通過runtime.GOMAXPROCS() 來設置
M的數量怎么設置:runtime/debug包中的SetMaxThreads函數來設置
最高能有多少個P:應該是內核數量
最高多少M:最?量一般默認是10000 但是內核很難支持這么多的線程數
GMP模型中協程的最長運行時間是多久:10ms??
Work Stealing偷多少:
M 優先執行其所綁定的 P 的本地運行隊列中的 G,如果本地隊列沒有 G,則會從全局隊列獲取,為了提高效率和負載均衡,會從全局隊列獲取多個 G,而不是只取一個,個數是自己應該從全局隊列中承擔的,globrunqsize / nprocs + 1;同樣,當全局隊列沒有時,會從其他 M 的 P 上偷取 G 來運行,偷取的個數通常是其他 P 運行隊列的一半;
groutine生命周期
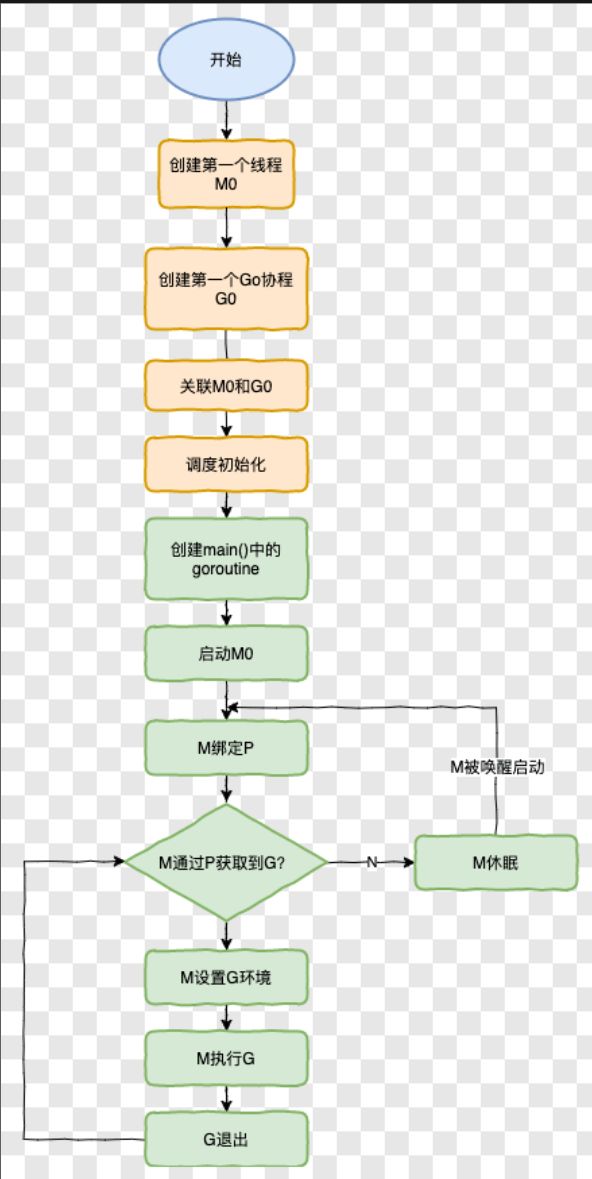
其實就是回答gmp模型
java
除了 clone() 還有哪些方式可以對對象進行深拷貝?
2、java 對象的內存結構?標記字是做什么的?
3、寫個單例?為何靜態內部類實現的單例可以做到線程安全且可延遲加載?
4、new Hashmap<1000> 和 new Hashmap<10000> 在數據都塞滿的時候有什么區別?(提示 擴容相關)
5、java 弱引用和虛引用的區別?
6、垃圾回收時標記存活對象的三色標記法原理,以及在出現漏標、錯標情況時是如何解決的?
7、jvm 調優你如何做的?現象->排查過程->解決方式->不同解決方案的對比與選擇
8、為何引入 JIT 編譯?逃逸分析是什么?
9、多線程中的三大問題 java 是如何解決的?
10、synchronized 底層實現原理?釋放鎖之后如何通知其他線程獲取鎖?
11、講講 AQS?
12、synchronized 做了哪些優化?(偏向鎖、輕量級鎖、自旋鎖、鎖粗化、鎖消除等)
13、LongAdder 實現原理?
Spring 啟動類的注解,介紹一下
因為我項目中用到了,所以被提問了 Spring 二次開發常用的擴展點,還涉及到了 Bean 的生命周期。 BeanPostProcessor,在你項目中如何使用的
Spring 中你常用哪些注解? Autowired 實現原理
看你項目中用到了 Netty,簡單介紹下吧。這里還有個 問題是問到 Netty 和 SpringBoot 整合的,但我一直都沒理解她想問什么
粘包拆包問題,Netty 解決粘包拆包的 Decoder
Spring 事務了解嗎,Spring 事務的注解不生效,是什么原因
Java 引用類型,強軟弱虛
Java 是引用傳遞還是值傳遞
Object 類你了解哪些方法
常用 GC 算法,常用的垃圾收集器, G1 了解嗎
場景題: cpu 打滿且頻繁 full GC,怎么解決?
有 jvm 調優的經驗嗎?實際工作中遇到過內存相關的問題嗎?用過哪些堆棧工具調試?
Mysql 索引,數據結構為什么使用 B+ 樹
索引覆蓋了解嗎
索引失效的場景
簡單描述一下數據庫的四種隔離級別以及對應的三種相關問題
MVCC + 鎖 保證隔離性
造成幻讀的原因了解嗎,快照讀、當前讀。
數據庫自增 ID 和 UUID 對比
HashMap 源碼,數據結構,如何避免哈希沖突,對比 HashTable
HashMap 源碼中,計算 hash 值為什么有一個 高 16 位 和 低 16 位異或的過程?
為什么重寫 equals 還要重寫 hashCode,不重寫會有什么問題
ConcurrentHashMap 底層實現,擴容問題。
計算機網絡
tcp和udp區別
tcp的可靠傳輸
網絡中的三張表——ARP表、MAC表、路由表
覽器尋址url過程?
dns作用 解析流程
下一跳路由轉發數據包的過程?
講講http協議
- 特性 無狀態 無連接 媒體獨立 進一步到cookie seesion
- 請求響應報文:
- 請求行:方法、 url、協議版本、
- 請求頭:(connection、connection-type、user-agent、content-type、gzip、encoding)
- 請求攜帶數據:比如page:1
- 響應報文 對比多了一個狀態碼
- 更進一步細化
- 不同版本的區別
0.9 get和純網頁
1.0 新增方法 mime cache
1.1 管道,keepalve
2.0 幀 二進制 頭壓縮(gzip和維持一個表) 多工復用 服務器主動主動推送 - post和get 以及其他方法
- 端口號
- keep-alive
- content-type
- gzip
- 不同狀態碼的含義
200 - 請求成功
301- 資源(網頁等)被永久轉移到其它URL
302-臨時移動 以后客戶端應該繼續使用原URL
305-必須使用代理訪問
400-語法錯誤 服務器無法理解
401-要求身份認證
403-拒絕 服務器端理解需求 但是拒絕執行
404 - 請求的資源(網頁等)不存在
405-客戶端請求中的方法被禁止
500 - 內部服務器錯誤
- 不同版本的區別
數據庫
隔離級別有幾種,分別會產生什么樣的問題
mysql
慢查詢優化
MySQL數據是怎么寫的,寫入的底層原理是什么,涉及到哪些主鍵的交互,比如innodb寫入時是先寫入buffer pool。
binlog同步:MySQL主節點的binlog是同步的還是異步的。
主節點崩潰:如果MySQL主節點崩潰了,數據會不會丟失。
從節點寫入:主節點掛了但向客戶端返回成功,怎么保證從節點數據寫入進去。
innodb索引:為什么innodb索引使用B+樹。
數據量很大:數據量很大達到內存放不下時怎么解決。
1、索引(為何使用 b+樹而不是使用別的數據結構? 索引下推?倒排索引?)
2、事務(ACID 隔離級別 幻讀如何出現的 又是如何解決?)
3、鎖(給一個 sql 問這條 sql 在不同隔離級別下是如何加鎖的?)
4、mvcc 機制(實現原理以及 rr 和 rc 隔離級別下實現的區別?)
5、redolog undolog binlog(會問分別是用來做什么的 有什么共同點 區別?)
6、sql 優化(選擇一個適合自己業務的 sql 場景 描述清楚自己如何通過 explain 命令來分析和優化的?)
redis
redis緩存:對redis作為緩存的理解是什么,用redis緩存和本地緩存,可以用本地緩存么(答了可以但不建議,然后面試官反問維護redis的成本呢)。
redis使用場景:redis的set和list的使用場景是什么。
redis set原理:redis set的原理是什么。
4、工作中,你們的ES和Mysql之間是怎么用的;
底層數據結構有哪些?跳表實現原理?為何不用紅黑樹?
2、Redis 的過期策略?
3、Redis 的持久化?
4、Redis 主從、哨兵、集群工作原理?三種部署方式的區別?
5、緩存穿透、擊穿、打滿、雪崩出現的原因與常用解決辦法
6、熱 key 的解決方案(如何發現 如何優化)
消息隊列
2、項目里用了Kafka,那聊一下RocketMQ和Kafka的區別;
3、介紹一下Kafka集群、副本、選舉;
、Kafka 基本工作原理?
2、Kafka 為何高吞吐?
3、Kafka 消息的可靠性、順序性是如何實現的的?
4、Kafka 的 ISR 機制?
5、Kafka 與其他 MQ 的對比與選擇
分布式
分布式就不多說了,什么 base 理論,raft 協議都需要知道。另外就是分布式鎖、分布式事務相關的一些知識,大家用到過的可以講講,比較加分,沒用到過的面試官一般也不會問到。
.go-micro微服務架構的水平部署及代碼實現。
如何使用micro.
如何進行服務發現。
Rpc 遠程調用的流程
為什么選用 Zookeeper 作為注冊中心,注冊中心作用是什么
項目中的 SPI 機制,介紹一下原理以及你做了哪些改進
一致性哈希的原理,虛擬結點
項目中的序列化方案,為什么序列化,你都了解哪些常用的序列化方法。
Zookeeper 作為注冊中心,假如崩潰了怎么辦?這里開始連環問了
你提到了 Zookeeper 的一致性,它是如何保證的?
ZAB 協議,選舉的過程,這里問的很詳細
Zookeeper 是強一致性嗎?
網絡分區了解嗎,CAP 理論
Zookeeper 如何應對網絡分區的,腦裂問題了解嗎,如何解決?
假如我同一時間有大量服務發布,你提到了 Zookeeper 只有主節點負責寫, 怎么解決?假如主節點崩潰了,新選舉出的主節點仍然沒辦法面對我的大流量,也崩潰了,如何解決?
MQ 的原理,你知道哪些 MQ,各自有什么特點,什么時候需要用 MQ
后端接口通用
RESTful 風格API設計規范
比如返回值 動作 等待
項目
項目困難:在項目中遇到哪些困難的問題,項目的難點是什么。
迭代器 生成器







)




、except(差集)、intersect(交集))




)

)