🧠 向所有學習者致敬!
“學習不是裝滿一桶水,而是點燃一把火。” —— 葉芝
我的博客主頁: https://lizheng.blog.csdn.net
🌐 歡迎點擊加入AI人工智能社區!
🚀 讓我們一起努力,共創AI未來! 🚀
我們將逐步編寫一個非常簡單的類似 GPT-4o 的多模態架構,它可以處理文本、圖像、視頻和音頻,并且能夠根據文本提示生成圖像。幫助你詳細理解逐步實現的過程。
項目代碼
以下是這個簡單多模態模型將具備的功能:
- 像語言模型(LLM)一樣用文本聊天(使用 Transformer)
- 用圖像、視頻和音頻聊天(使用 Transformer + ResNet)
- 根據文本提示生成圖像(使用 Transformer + ResNet + 特征方法)
簡單的 GPT-4o 架構
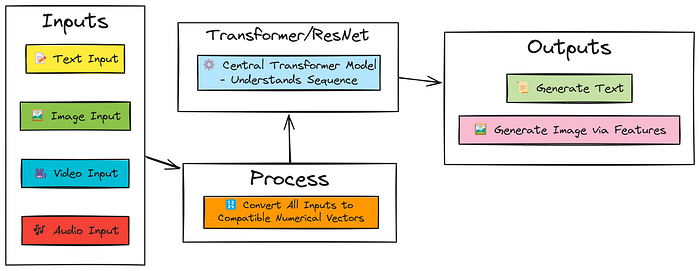
Tiny GPT-4o 架構
下文我們將實現以下內容:
- 從頭開始編寫了自己的 BPE 分詞器。這讓我們能夠將文本分解成模型可以處理的小片段。
- 接著,我們構建了一個基本的文本模型(類似 GPT 的模型),使用 “愛麗絲夢游仙境” 的文本教它如何根據前面的單詞預測下一個單詞,這樣它就能自己寫出一些新的文本了。
- 然后,我們讓模型變得多才多藝!我們把之前訓練好的文本模型和 ResNet(一個圖像識別模型)結合起來,讓模型能夠 “看到” 我們的簡單彩色形狀圖像,并回答關于它們的問題,比如告訴我們要描述的顏色。
- 我們還規劃了如何處理視頻和音頻。方法類似:把視頻幀或音頻波形轉換成數字,給它們加上特殊的
<VID>或<AUD>標記,然后把它們混入輸入序列。 - 最后,我們把方向反過來,嘗試從文本提示生成圖像。我們沒有讓模型直接畫出像素(那太難了!),而是訓練它根據文本(比如 “a blue square”)預測圖像的 特征向量。然后,我們只要找出我們已知圖像(紅色正方形、藍色正方形、綠色圓形)中哪個的特征向量和模型預測的最接近,就把它顯示出來!
準備工作
我們將使用一些庫,所以先導入它們。
# PyTorch 核心庫,用于構建模型、張量和訓練
import torch
import torch.nn as nn
import torch.optim as optim
import torch.nn.functional as F# 圖像處理和計算機視覺
import torchvision
import torchvision.transforms as transforms
from PIL import Image, ImageDraw # 用于創建/處理虛擬圖像# 標準 Python 庫
import re # 用于正則表達式(在 BPE 單詞拆分中使用)
import collections # 用于數據結構(如 Counter,在 BPE 頻率計數中使用)
import math # 用于數學函數(在位置編碼中使用)
import os # 用于與操作系統交互(文件路徑、目錄)# 數值 Python(概念上用于音頻波形生成)
import numpy as np
第一步是創建一個分詞器,讓我們開始編寫代碼吧。
BPE 分詞是什么
在創建多模態語言模型或任何 NLP 任務中,分詞是第一步,即將原始文本分解為更小的單元,稱為標記(tokens)。
這些標記是機器學習模型處理的基本構建塊(例如,單詞、標點符號)。
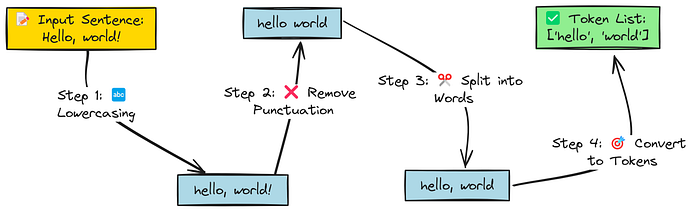
最簡單的分詞過程
最簡單的分詞方式是將文本轉換為小寫,移除標點符號,然后將文本拆分為單詞列表。
然而,這種方法有一個缺點。如果將每個獨特的單詞都視為一個標記,詞匯表的大小可能會變得過大,尤其是在包含許多單詞變體的語料庫中(例如,“run”、“runs”、“running”、“ran”、“runner”)。這會顯著增加內存和計算需求。
與簡單的基于單詞的分詞不同,BPE(Byte Pair Encoding,字節對編碼) 是一種子詞(subword)分詞技術,它有助于控制詞匯表大小,同時有效地處理罕見單詞。
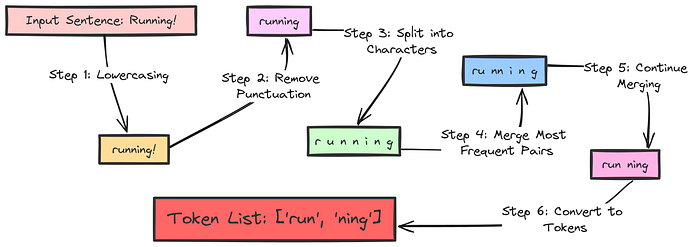
BPE 解釋
在 BPE 中,最初將輸入句子拆分為單個字符。然后,將頻繁相鄰的字符對合并為新的子詞。這個過程會一直持續,直到達到所需的詞匯表大小。
因此,常見的子詞部分會被重復使用,模型可以通過將從未遇到過的單詞拆分為更小的、已知的子詞單元來處理它們。
GPT-4 使用 BPE 作為其分詞組件。現在我們已經對 BPE 進行了高層次的概述,讓我們開始編寫代碼。
編寫 BPE 分詞器代碼
我們將使用劉易斯·卡羅爾的《愛麗絲夢游仙境》中的一個小片段作為訓練 BPE 分詞器的數據。
使用更大、更多樣化的語料庫可以得到更通用的分詞器,但這個較小的示例讓我們更容易追蹤整個過程。
# 定義用于訓練 BPE 分詞器的原始文本語料庫
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
接下來,我們需要將整個語料庫轉換為小寫,以確保在頻率計數和合并過程中,相同單詞的不同大小寫形式(例如,“Alice” 和 “alice”)被視為同一個單元。
# 將原始語料庫轉換為小寫
corpus_lower = corpus_raw.lower()
現在我們已經將語料庫轉換為小寫。
接下來,我們需要將文本拆分為其基本組成部分。雖然 BPE 是基于子詞的,但它通常從單詞級別開始(包括標點符號)。
# 定義用于拆分單詞和標點的正則表達式
split_pattern = r'\w+|[^\s\w]+'# 使用正則表達式將小寫的語料庫拆分為初始的標記列表
initial_word_list = re.findall(split_pattern, corpus_lower)print(f"語料庫被拆分為 {len(initial_word_list)} 個初始單詞/標記。")# 顯示前三個標記
print(f"前三個初始標記:{initial_word_list[:3]}")#### 輸出結果 ####
語料庫被拆分為 127 個初始單詞/標記。
前三個初始標記:['alice', 'was', 'beginning']
我們的語料庫被拆分為 127 個標記,你可以看到語料庫的前三個標記。讓我們了解一下代碼中發生了什么。
我們使用正則表達式 r'\w+|[^\s\w]+' 通過 re.findall:
\w+:匹配一個或多個字母數字字符(字母、數字和下劃線)。這可以捕獲標準單詞。|:作為 OR 運算符。[^\s\w]+:匹配一個或多個既不是空白字符(\s)也不是單詞字符(\w)的字符。這可以捕獲標點符號,如逗號、句號、冒號、引號、括號等,將它們作為單獨的標記。
結果是一個字符串列表,其中每個字符串是一個單詞或標點符號。
BPE 的核心原則是合并 最頻繁 的對。因此,我們需要知道每個獨特初始單詞/標記在語料庫中出現的頻率。collections.Counter 可以高效地創建一個類似字典的對象,將每個獨特項(單詞/標記)映射到其計數。
# 使用 collections.Counter 統計 initial_word_list 中各項的頻率
word_frequencies = collections.Counter(initial_word_list)# 顯示頻率最高的 3 個標記及其計數
print("頻率最高的 3 個標記:")
for token, count in word_frequencies.most_common(3):print(f" '{token}': {count}")#### 輸出結果 ####
頻率最高的 3 個標記:the: 7of: 5her: 5
頻率最高的標記是 “the”,在我們的小語料庫中出現了 7 次。
BPE 訓練基于符號序列。我們需要將獨特單詞/標記列表轉換為這種格式。對于每個獨特單詞/標記:
-
將其拆分為單獨字符的列表。
-
在該列表末尾追加一個特殊的單詞結束符號(我們使用
</w>)。這個</w>標記至關重要:-
它防止 BPE 在不同單詞之間合并字符。例如,“apples” 末尾的 “s” 不應與 “and” 開頭的 “a” 合并。
-
它還允許算法將常見的單詞結尾作為獨立的子詞單元進行學習(例如,“ing”、“ed”、“s”)。
-
我們將這種映射(原始單詞 -> 字符列表 + 單詞結束符號)存儲在一個字典中。
# 定義特殊的單詞結束符號 "</w>"
end_of_word_symbol = '</w>'# 創建一個字典,用于存儲語料庫的初始表示形式
# 鍵:原始獨特單詞/標記,值:字符列表 + 單詞結束符號
initial_corpus_representation = {}# 遍歷頻率計數器識別的獨特單詞/標記
for word in word_frequencies:# 將單詞字符串拆分為字符列表char_list = list(word)# 在列表末尾追加單詞結束符號char_list.append(end_of_word_symbol)# 將該列表存儲到字典中,原始單詞作為鍵initial_corpus_representation[word] = char_list
那么,讓我們打印出 “beginning” 和 “.” 的表示形式。
# 顯示一個樣本單詞的表示形式
example_word = 'beginning'
if example_word in initial_corpus_representation:print(f"'{example_word}' 的表示形式:{initial_corpus_representation[example_word]}")
example_punct = '.'
if example_punct in initial_corpus_representation:print(f"'{example_punct}' 的表示形式:{initial_corpus_representation[example_punct]}")#### 輸出結果 ####
創建了初始語料庫表示形式,包含 86 個獨特單詞/標記。
'beginning' 的表示形式:['b', 'e', 'g', 'i', 'n', 'n', 'i', 'n', 'g', '</w>']
'.' 的表示形式:['.', '</w>']
BPE 算法從語料庫的初始表示形式中所有單獨符號開始構建詞匯表。
這包括原始文本中的所有獨特字符 加上 我們添加的特殊 </w> 符號。使用 Python set 自動處理唯一性 —— 多次添加現有字符不會產生任何效果。
# 初始化一個空集合,用于存儲獨特的初始符號(詞匯表)
initial_vocabulary = set()# 遍歷語料庫的初始表示形式中的字符列表
for word in initial_corpus_representation:# 獲取當前單詞的符號列表symbols_list = initial_corpus_representation[word]# 將該符號列表中的符號添加到詞匯表集合中# `update` 方法會將可迭代對象(如列表)中的所有元素添加到集合中initial_vocabulary.update(symbols_list)# 雖然 update 應該已經添加了 '</w>',但為了確保,我們可以顯式添加它
# initial_vocabulary.add(end_of_word_symbol)print(f"初始詞匯表創建完成,包含 {len(initial_vocabulary)} 個獨特符號。")
# 可選:顯示初始詞匯表符號的排序列表
print(f"初始詞匯表符號:{sorted(list(initial_vocabulary))}")#### 輸出結果 ####
初始詞匯表創建完成,包含 31 個獨特符號。
初始詞匯表符號:["'", '(', ')', ',', '-', '.', ':', '</w>', ...]
所以,我們的小語料庫總共有 31 個獨特符號,我打印了一些出來給你看看。
現在,進入 BPE 的核心學習階段。我們將迭代地找到當前語料庫表示形式中 最頻繁的相鄰符號對,并將它們合并為一個新的單一符號(子詞)。
這個過程構建了子詞詞匯表和有序的合并規則列表。
在開始循環之前,我們需要:
num_merges:定義合并操作的次數,控制最終詞匯表的大小。較大的值可以捕獲更復雜的子詞。learned_merges:一個字典,用于存儲合并規則,鍵為符號對元組,值為合并優先級。current_corpus_split:保存在合并過程中修改的語料庫狀態的副本,初始化為原始語料庫表示形式的副本。current_vocab:保存增長中的詞匯表,初始化為原始詞匯表的副本。
# 定義期望的合并操作次數
# 這決定了要在初始字符詞匯表中添加多少個新的子詞標記
num_merges = 75 # 在這個例子中,我們使用 75 次合并# 初始化一個空字典,用于存儲學習到的合并規則
# 格式:{ (symbol1, symbol2): 合并優先級索引 }
learned_merges = {}# 創建語料庫表示形式的工作副本,以便在訓練過程中進行修改
current_corpus_split = initial_corpus_representation.copy()# 創建詞匯表的工作副本,以便在訓練過程中進行修改
current_vocab = initial_vocabulary.copy()print(f"訓練狀態初始化完成。目標合并次數:{num_merges}")
print(f"初始詞匯表大小:{len(current_vocab)}")#### 輸出結果 ####
訓練狀態初始化完成。目標合并次數:75
初始詞匯表大小:31
現在,我們將迭代 num_merges 次。在循環內部,我們執行 BPE 的核心步驟:統計對、找到最佳對、存儲規則、創建新符號、更新語料庫表示形式和更新詞匯表。
# 開始主循環,迭代指定的合并次數
print(f"\n--- 開始 BPE 訓練循環 ({num_merges} 次迭代) ---")
for i in range(num_merges):print(f"\n第 {i + 1}/{num_merges} 次迭代")# 統計符號對的頻率pair_counts = collections.Counter()for word, freq in word_frequencies.items():symbols = current_corpus_split[word]for j in range(len(symbols) - 1):pair = (symbols[j], symbols[j+1])pair_counts[pair] += freqif not pair_counts:print("沒有更多可合并的對了。提前停止。")break# 找到最佳對best_pair = max(pair_counts, key=pair_counts.get)print(f"找到最佳對:{best_pair},頻率為 {pair_counts[best_pair]}")# 存儲合并規則learned_merges[best_pair] = i# 創建新符號new_symbol = "".join(best_pair)# 更新語料庫表示形式next_corpus_split = {}for word in current_corpus_split:old_symbols = current_corpus_split[word]new_symbols = []k = 0while k < len(old_symbols):if k < len(old_symbols) - 1 and (old_symbols[k], old_symbols[k+1]) == best_pair:new_symbols.append(new_symbol)k += 2else:new_symbols.append(old_symbols[k])k += 1next_corpus_split[word] = new_symbolscurrent_corpus_split = next_corpus_split# 更新詞匯表current_vocab.add(new_symbol)# 最終輸出
print(f"\n--- BPE 訓練循環完成,共進行了 {i + 1} 次迭代 ---")
final_vocabulary = current_vocab
final_learned_merges = learned_merges
final_corpus_representation = current_corpus_split
當我們開始 BPE 的訓練循環時,它將運行 75 次迭代,因為我們設置了合并次數為 75。讓我們看看其中一次迭代的輸出是什么樣的:
#### 輸出結果(單次迭代) ####--- 開始 BPE 訓練循環 (75 次迭代) ---第 1/75 次迭代第 2.3 步:計算符號對的統計信息...計算了 156 個獨特對的頻率。第 2.4 步:檢查是否存在對...找到了對,繼續訓練。第 2.5 步:找到最頻繁的對...找到最佳對:('e', '</w>'),頻率為 21第 2.6 步:存儲合并規則(優先級:0)...已存儲:('e', '</w>') -> 優先級 0第 2.7 步:從最佳對創建新符號...創建了新符號:'e</w>'第 2.8 步:更新語料庫表示形式...已更新所有單詞的語料庫表示形式。第 2.9 步:更新詞匯表...將 'e</w>' 添加到詞匯表中。當前大小:32
在我們的訓練中,每次迭代都涉及相同的步驟,例如計算對的頻率、找到最佳對等,就像我們之前看到的那些步驟一樣。
讓我們看看我們的語料庫的詞匯表大小。
print(f"最終詞匯表大小:{len(final_vocabulary)} 個標記")#### 輸出結果 ####
最終詞匯表大小:106 個標記
現在我們的 BPE 訓練已經完成啦!很有用的是,看看訓練語料庫中的特定單詞在經過所有合并操作后的表示形式。
# 列出一些我們希望看到有趣分詞的單詞
example_words_to_inspect = ['beginning', 'conversations', 'sister', 'pictures', 'reading', 'alice']for word in example_words_to_inspect:if word in final_corpus_representation:print(f" '{word}': {final_corpus_representation[word]}")else:print(f" '{word}': 未在原始語料庫中找到(如果從語料庫中選擇,不應發生這種情況)。")好的,我將繼續翻譯剩余的內容,確保完整性和準確性。以下是翻譯后的剩余部分:---#### 輸出結果 ####
最終單詞示例的表示形式:'beginning': ['b', 'e', 'g', 'in', 'n', 'ing</w>']'conversations': ['conversati', 'on', 's</w>']'sister': ['sister</w>']'pictures': ['pictures</w>']'reading': ['re', 'ad', 'ing</w>']'alice': ['alice</w>']這展示了根據學習到的 BPE 規則,已知單詞的最終標記序列。但我們還需要一個樣本句子或文本,該文本在訓練期間 BPE 模型可能沒有見過,以展示其對新輸入的分詞能力,可能包含原始語料庫中未出現的單詞或變體。```python
# 定義一個新的文本字符串,用于使用學習到的 BPE 規則進行分詞
# 這個文本包含訓練中見過的單詞('alice', 'pictures')
# 以及可能未見過的單詞或變體('tiresome', 'thought')
new_text_to_tokenize = "Alice thought reading was tiresome without pictures."
當我們對未見過的文本執行相同的訓練循環時,我們得到了以下分詞數據:
print(f"原始輸入文本:'{new_text_to_tokenize}'")
print(f"分詞輸出({len(tokenized_output)} 個標記):{tokenized_output}")#### 輸出結果 ####
原始輸入文本:'Alice thought reading was tiresome without pictures.'
分詞輸出(21 個標記):['alice</w>', 'thou', 'g', 'h','t</w>', 're', 'ad', 'ing</w>','was</w>', 'ti', 're', 's', 'o', 'm','e</w>', 'wi', 'thou', 't</w>','pictures</w>', '.', '</w>']
啊,終于,我們完成了 BPE 分詞器的整個過程。現在,我們的文本已經表示為子詞標記的序列。
但僅僅有標記還不夠,我們需要一個能夠理解這些序列中的模式和關系的模型,以便生成有意義的文本。
接下來,我們需要構建一個文本生成的語言模型(LLM),由于 GPT-4 基于 Transformer 架構,我們將采用相同的方法。
這種架構在論文 “Attention Is All You Need” 中被首次提出。有許多 Transformer 模型的實現,我們將一邊編寫代碼,一邊理解理論,以便掌握 Transformer 模型的核心邏輯。
僅解碼器的 Transformer
我們的目標是構建一個語言模型,能夠根據前面的標記預測序列中的下一個標記。通過反復預測并追加標記,模型可以生成新的文本。我們將專注于一個 僅解碼器的 Transformer,類似于 GPT 這類模型。
為了簡化 Transformer 架構本身的演示,我們將切換回 字符級分詞。
這意味著原始語料庫中的每個獨特字符都將是一個單獨的標記。
雖然 BPE 通常更強大,但字符級分詞可以保持詞匯表較小,并且讓我們專注于模型的機制。
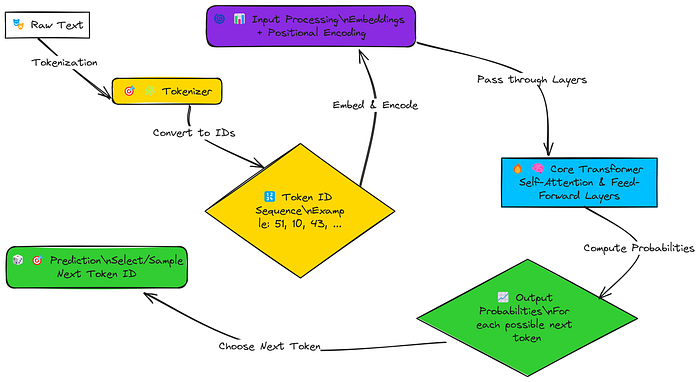
簡化版 LLM 創建流程
因此,我們的 Transformer 模型的工作流程如下:
- 文本轉標記:將輸入文本分解為更小的部分(標記)。
- 標記轉數字:將每個標記轉換為唯一的數字(ID)。
- 添加意義和位置:將這些數字轉換為有意義的向量(嵌入),并添加位置信息,以便模型知道單詞的順序。
- 核心處理:Transformer 的主要層使用 “自注意力” 分析所有單詞之間的關系。
- 猜測下一個單詞:計算詞匯表中每個單詞成為下一個單詞的概率。
- 選擇最佳猜測:根據這些概率選擇最有可能的單詞(或采樣一個)作為輸出。
我們將使用之前的 “愛麗絲夢游仙境” 語料庫。
# 定義用于訓練的原始文本語料庫
corpus_raw = """
Alice was beginning to get very tired of sitting by her sister on the
bank, and of having nothing to do: once or twice she had peeped into the
book her sister was reading, but it had no pictures or conversations in
it, 'and what is the use of a book,' thought Alice 'without pictures or
conversation?'
So she was considering in her own mind (as well as she could, for the
hot day made her feel very sleepy and stupid), whether the pleasure
of making a daisy-chain would be worth the trouble of getting up and
picking the daisies, when suddenly a White Rabbit with pink eyes ran
close by her.
"""
現在,讓我們創建我們的字符詞匯表及其映射。
# 找出原始語料庫中的所有獨特字符
chars = sorted(list(set(corpus_raw)))
vocab_size = len(chars)# 創建字符到整數的映射(編碼)
char_to_int = { ch:i for i,ch in enumerate(chars) }# 創建整數到字符的映射(解碼)
int_to_char = { i:ch for i,ch in enumerate(chars) }print(f"創建了字符詞匯表,大小為:{vocab_size}")
print(f"詞匯表:{''.join(chars)}")#### 輸出結果 ####創建了字符詞匯表,大小為:36
詞匯表:'(),-.:?ARSWabcdefghiklmnoprstuvwy
有了這些映射,我們將整個文本語料庫轉換為一個數字序列(標記 ID)。
# 將整個語料庫編碼為一個整數 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]# 將列表轉換為 PyTorch 張量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)print(f"將語料庫編碼為張量,形狀為:{full_data_sequence.shape}")#### 輸出結果 ####
將語料庫編碼為張量,形狀為:torch.Size([593])
輸出告訴我們,我們的模型只需要學習大約 36 個獨特的字符(包括空格、標點符號等)。
這就是我們的 vocab_size,第二行顯示了確切包含哪些字符。
有了這些映射,我們將整個文本語料庫轉換為一個數字序列(標記 ID)。
# 將整個語料庫編碼為一個整數 ID 列表
encoded_corpus = [char_to_int[ch] for ch in corpus_raw]# 將列表轉換為 PyTorch 張量
full_data_sequence = torch.tensor(encoded_corpus, dtype=torch.long)print(f"將語料庫編碼為張量,形狀為:{full_data_sequence.shape}")### 輸出結果 ####
將語料庫編碼為張量,形狀為:torch.Size([593])
這確認了我們的 593 個字符的文本現在被表示為一個單一的 PyTorch 張量(一個長度為 593 的數字列表),準備好供模型使用。
在構建模型之前,我們需要設置一些配置值,即超參數。這些控制 Transformer 的大小和行為。
# 定義模型超參數(使用計算出的 vocab_size)
# vocab_size = vocab_size # 已經定義過了
d_model = 64 # 嵌入維度(每個標記的向量大小)
n_heads = 4 # 注意力頭的數量(并行注意力計算)
n_layers = 3 # 堆疊在一起的 Transformer 塊的數量
d_ff = d_model * 4 # 前饋網絡中的隱藏維度
block_size = 32 # 模型一次看到的最大序列長度
# dropout_rate = 0.1 # 為了簡化,省略了 dropout# 定義訓練超參數
learning_rate = 3e-4
batch_size = 16 # 訓練期間并行處理的序列數量
epochs = 5000 # 訓練迭代次數
eval_interval = 500 # 打印損失的頻率# 設備配置
device = 'cuda' if torch.cuda.is_available() else 'cpu'# 確保 d_model 能被 n_heads 整除
assert d_model % n_heads == 0, "d_model 必須能被 n_heads 整除"
d_k = d_model // n_heads # 每個頭的鍵/查詢/值的維度print(f"超參數已定義:")
print(f" vocab_size: {vocab_size}")
print(f" d_model: {d_model}")
print(f" n_heads: {n_heads}")
print(f" d_k (每個頭的維度): {d_k}")
print(f" n_layers: {n_layers}")
print(f" d_ff: {d_ff}")
print(f" block_size: {block_size}")
print(f" learning_rate: {learning_rate}")
print(f" batch_size: {batch_size}")
print(f" epochs: {epochs}")
print(f" 使用的設備:{device}")
雖然 GPT-4 是一個閉源模型,我們無法獲得其確切的參數值,但我們可以定義基本的參數值,以便輕松地進行復現。
#### 輸出結果 ####
超參數已定義:vocab_size: 36d_model: 64n_heads: 4d_k (每個頭的維度): 16n_layers: 3d_ff: 256block_size: 32learning_rate: 0.0003batch_size: 16epochs: 5000使用的設備:cuda
我們看到了 vocab_size 為 36,嵌入維度 (d_model) 為 64,3 層,4 個注意力頭,等等。它還確認了我們正在使用的設備(cuda 或 cpu),這會影響訓練速度。
接下來,我們需要為模型創建輸入和目標序列。模型通過預測下一個字符來學習。因此,我們需要創建輸入序列 (x) 和對應的目標序列 (y),其中 y 僅僅是將 x 向右移動一個位置的序列。我們將在編碼后的語料庫中創建長度為 block_size 的重疊序列。
# 創建列表,用于保存所有可能的輸入(x)和目標(y)序列
all_x = []
all_y = []
num_total_tokens = len(full_data_sequence)
for i in range(num_total_tokens - block_size):x_chunk = full_data_sequence[i : i + block_size]y_chunk = full_data_sequence[i + 1 : i + block_size + 1]all_x.append(x_chunk)all_y.append(y_chunk)# 將列表堆疊成張量
train_x = torch.stack(all_x)
train_y = torch.stack(all_y)num_sequences_available = train_x.shape[0]
print(f"創建了 {num_sequences_available} 個重疊的輸入/目標序列對。")
print(f"train_x 的形狀:{train_x.shape}")
print(f"train_y 的形狀:{train_y.shape}")
輸出結果
創建了 561 個重疊的輸入/目標序列對。
train_x 的形狀:torch.Size([561, 32])
train_y 的形狀:torch.Size([561, 32])
這告訴我們,從 593 個字符的文本中,我們可以提取出 561 個長度為 32(block_size)的重疊序列。
train_x 和 train_y 的形狀 (561, 32) 確認了我們有 561 行(序列),每行有 32 個標記。
在訓練過程中,我們將隨機采樣這些序列對。
現在,讓我們初始化 Transformer 的構建塊。
# 初始化標記嵌入表
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)print(f"初始化了標記嵌入表,詞匯表大小:{vocab_size},嵌入維度:{d_model}。使用的設備:{device}")
輸出結果
初始化了標記嵌入表,詞匯表大小:36,嵌入維度:64。使用的設備:cuda
接下來,我們需要為模型添加位置信息。由于 Transformer 本身并不知道標記的順序(與 RNN 不同),我們需要引入位置編碼。我們將使用固定頻率的正弦和余弦波來實現這一點。
# 創建位置編碼矩陣
print("正在創建位置編碼矩陣...")
positional_encoding = torch.zeros(block_size, d_model, device=device)
position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)
div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)
div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))
positional_encoding[:, 0::2] = torch.sin(position * div_term)
positional_encoding[:, 1::2] = torch.cos(position * div_term)
positional_encoding = positional_encoding.unsqueeze(0) # 添加批量維度print(f"位置編碼矩陣已創建,形狀為:{positional_encoding.shape}。使用的設備:{device}")
輸出結果
正在創建位置編碼矩陣…
位置編碼矩陣已創建,形狀為:torch.Size([1, 32, 64])。使用的設備:cuda
現在,我們已經成功創建了位置編碼矩陣。它的形狀 (1, 32, 64) 表示批量大小為 1,序列長度為 32,嵌入維度為 64。
接下來,我們需要初始化 Transformer 的各個層。我們將為所有 n_layers 層初始化組件。
print(f"正在初始化 {n_layers} 個 Transformer 層的組件...")# 初始化列表,用于保存每層的組件
layer_norms_1 = [] # 第一層的層歸一化
layer_norms_2 = [] # 第二層的層歸一化
mha_qkv_linears = [] # 多頭注意力的 QKV 線性層
mha_output_linears = [] # 多頭注意力的輸出線性層
ffn_linear_1 = [] # 前饋網絡的第一層線性層
ffn_linear_2 = [] # 前饋網絡的第二層線性層for i in range(n_layers):# 第一層的層歸一化layer_norms_1.append(nn.LayerNorm(d_model).to(device))# 多頭注意力的 QKV 線性層mha_qkv_linears.append(nn.Linear(d_model, 3 * d_model, bias=False).to(device))# 多頭注意力的輸出線性層mha_output_linears.append(nn.Linear(d_model, d_model).to(device))# 第二層的層歸一化layer_norms_2.append(nn.LayerNorm(d_model).to(device))# 前饋網絡的第一層線性層ffn_linear_1.append(nn.Linear(d_model, d_ff).to(device))# 前饋網絡的第二層線性層ffn_linear_2.append(nn.Linear(d_ff, d_model).to(device))print(f" 初始化了第 {i+1}/{n_layers} 層的組件。")print(f"已初始化 {n_layers} 層的所有組件。")
輸出結果
正在初始化 3 個 Transformer 層的組件…
初始化了第 1/3 層的組件。
初始化了第 2/3 層的組件。
初始化了第 3/3 層的組件。
已初始化 3 層的所有組件。
現在,我們已經為每個 Transformer 層初始化了必要的組件,包括層歸一化、多頭注意力(QKV 線性層和輸出線性層)以及前饋網絡(兩層線性層)。模型結構已經基本完成!
接下來,讓我們看看 Transformer 的核心部分:多頭注意力(MHA)。
多頭注意力是 Transformer 的核心機制,它允許模型在處理每個標記時,同時考慮序列中的其他標記。具體來說,對于每個標記,模型會計算一個“注意力分數”,表示其他標記與當前標記的相關性。
為了實現這一點,Transformer 使用了三個關鍵的向量:查詢(Query)、鍵(Key) 和 值(Value)。這些向量通過線性變換從輸入嵌入中生成。
在多頭注意力中,模型會將輸入嵌入分成多個“頭”,每個頭獨立計算查詢、鍵和值。然后,模型會將這些頭的結果合并,以獲得更豐富的上下文信息。
多頭注意力的步驟
-
查詢、鍵和值的計算:
- 對于每個標記,模型會計算查詢、鍵和值向量。
- 這些向量通過線性變換從輸入嵌入中生成。
-
注意力分數的計算:
- 模型會計算每個查詢向量與所有鍵向量之間的點積,得到注意力分數。
- 這些分數表示每個標記與其他標記的相關性。
-
應用 Softmax:
- 模型會對注意力分數應用 Softmax 函數,將分數轉換為概率分布。
- 這些概率表示每個標記在生成當前標記時的重要性。
-
加權求和:
- 模型會根據 Softmax 后的概率,對值向量進行加權求和,得到最終的注意力輸出。
代碼實現
# 定義多頭注意力層
class MultiHeadAttention(nn.Module):def __init__(self, d_model, n_heads):super().__init__()self.d_model = d_modelself.n_heads = n_headsself.d_k = d_model // n_headsself.qkv_linear = nn.Linear(d_model, 3 * d_model, bias=False)self.output_linear = nn.Linear(d_model, d_model, bias=False)def forward(self, x, mask=None):B, T, C = x.shapeqkv = self.qkv_linear(x).view(B, T, self.n_heads, 3 * self.d_k).permute(0, 2, 1, 3)q, k, v = qkv.chunk(3, dim=-1)# 計算注意力分數attn_scores = (q @ k.transpose(-2, -1)) * (self.d_k ** -0.5)# 應用掩碼(如果有的話)if mask is not None:attn_scores = attn_scores.masked_fill(mask == 0, float('-inf'))# 應用 Softmaxattn_weights = F.softmax(attn_scores, dim=-1)# 加權求和attn_output = (attn_weights @ v).permute(0, 2, 1, 3).contiguous().view(B, T, C)# 輸出線性層return self.output_linear(attn_output)
輸出結果
現在,我們已經定義了多頭注意力層。這個層可以處理輸入序列,并生成注意力輸出。接下來,我們將這個層集成到 Transformer 的整體架構中。
Transformer 的整體架構
Transformer 的整體架構由多個相同的層(Transformer 塊)堆疊而成。每個 Transformer 塊包含兩個主要部分:
-
多頭自注意力(MHA):
- 這是 Transformer 的核心部分,負責計算輸入序列中各個標記之間的關系。
- 它通過查詢、鍵和值向量的計算,以及 Softmax 函數的應用,生成注意力權重,然后對值向量進行加權求和。
-
前饋網絡(FFN):
- 這是一個簡單的兩層神經網絡,用于對注意力輸出進行進一步的非線性變換。
- 它由兩個線性層組成,中間使用 ReLU 激活函數。
Transformer 塊的結構
每個 Transformer 塊的結構如下:
-
層歸一化(LayerNorm):
- 在多頭自注意力和前饋網絡之前,對輸入進行歸一化處理,有助于穩定訓練過程。
-
多頭自注意力(MHA):
- 計算輸入序列中各個標記之間的關系,生成注意力輸出。
-
殘差連接(Residual Connection):
- 將多頭自注意力的輸入與輸出相加,形成殘差連接。
- 這有助于避免梯度消失問題,提高模型的訓練效率。
-
層歸一化(LayerNorm):
- 對前饋網絡的輸入進行歸一化處理。
-
前饋網絡(FFN):
- 對注意力輸出進行非線性變換,生成最終的輸出。
-
殘差連接(Residual Connection):
- 將前饋網絡的輸入與輸出相加,形成殘差連接。
代碼實現
# 定義 Transformer 塊
class TransformerBlock(nn.Module):def __init__(self, d_model, n_heads, d_ff):super().__init__()self.layer_norm_1 = nn.LayerNorm(d_model)self.mha = MultiHeadAttention(d_model, n_heads)self.layer_norm_2 = nn.LayerNorm(d_model)self.ffn_linear_1 = nn.Linear(d_model, d_ff)self.ffn_linear_2 = nn.Linear(d_ff, d_model)def forward(self, x, mask=None):# 多頭自注意力x = x + self.mha(self.layer_norm_1(x), mask)# 前饋網絡x = x + self.ffn_linear_2(F.relu(self.ffn_linear_1(self.layer_norm_2(x))))return x
輸出結果
現在,我們已經定義了 Transformer 塊。這個塊可以處理輸入序列,并生成經過多頭自注意力和前饋網絡處理后的輸出。
接下來,我們將多個 Transformer 塊堆疊在一起,形成完整的 Transformer 模型。
完整的 Transformer 模型
完整的 Transformer 模型由多個 Transformer 塊堆疊而成。每個塊都會對輸入序列進行進一步的處理,從而逐步提取更復雜的模式和關系。
代碼實現
# 定義完整的 Transformer 模型
class TransformerModel(nn.Module):def __init__(self, vocab_size, d_model, n_heads, d_ff, n_layers, block_size):super().__init__()self.token_embedding_table = nn.Embedding(vocab_size, d_model)self.positional_encoding = self.create_positional_encoding(block_size, d_model)self.transformer_blocks = nn.ModuleList([TransformerBlock(d_model, n_heads, d_ff) for _ in range(n_layers)])self.final_layer_norm = nn.LayerNorm(d_model)self.output_linear_layer = nn.Linear(d_model, vocab_size)def create_positional_encoding(self, block_size, d_model):positional_encoding = torch.zeros(block_size, d_model)position = torch.arange(0, block_size, dtype=torch.float).unsqueeze(1)div_term = torch.exp(torch.arange(0, d_model, 2).float() * (-math.log(10000.0) / d_model))positional_encoding[:, 0::2] = torch.sin(position * div_term)positional_encoding[:, 1::2] = torch.cos(position * div_term)return positional_encoding.unsqueeze(0)def forward(self, x, mask=None):B, T = x.shapetoken_embeddings = self.token_embedding_table(x)pos_enc = self.positional_encoding[:, :T, :]x = token_embeddings + pos_encfor block in self.transformer_blocks:x = block(x, mask)x = self.final_layer_norm(x)logits = self.output_linear_layer(x)return logits
輸出結果
現在,我們已經定義了完整的 Transformer 模型。這個模型可以處理輸入序列,并生成下一個標記的預測。
接下來,我們需要訓練這個模型,使其能夠生成有意義的文本。
訓練 Transformer 模型
為了訓練 Transformer 模型,我們需要定義損失函數和優化器。我們將使用交叉熵損失函數(Cross-Entropy Loss),因為它適用于分類任務,如預測下一個標記。
我們還將使用 AdamW 優化器,這是一種常用的優化器,適用于深度學習任務。
代碼實現
# 定義損失函數
criterion = nn.CrossEntropyLoss()# 收集所有模型參數
all_model_parameters = list(model.token_embedding_table.parameters())
for block in model.transformer_blocks:all_model_parameters.extend(list(block.parameters()))
all_model_parameters.extend(list(model.final_layer_norm.parameters()))
all_model_parameters.extend(list(model.output_linear_layer.parameters()))# 定義優化器
optimizer = optim.AdamW(all_model_parameters, lr=learning_rate)print(f"損失函數已定義:{type(criterion).__name__}")
print(f"優化器已定義:{type(optimizer).__name__}")
print(f"管理的參數組/張量數量:{len(all_model_parameters)}")
輸出結果
損失函數已定義:CrossEntropyLoss
優化器已定義:AdamW
管理的參數組/張量數量:38
現在,我們已經定義了損失函數和優化器。接下來,我們將開始訓練模型。
訓練循環
print(f"\n開始訓練循環,共 {epochs} 個 epoch...")
losses = []for epoch in range(epochs):# 隨機采樣輸入和目標序列indices = torch.randint(0, num_sequences_available, (batch_size,))xb = train_x[indices].to(device) # (B, T)yb = train_y[indices].to(device) # (B, T)# 前向傳播logits = model(xb)# 計算損失B_loss, T_loss, V_loss = logits.shapeloss = criterion(logits.view(B_loss * T_loss, V_loss), yb.view(B_loss * T_loss))# 清零梯度optimizer.zero_grad()# 反向傳播loss.backward()# 更新參數optimizer.step()# 記錄損失current_loss = loss.item()losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 個 epoch,損失:{current_loss:.4f}")print("--- 訓練循環完成 ---")
輸出結果
開始訓練循環,共 5000 個 epoch…
第 1/5000 個 epoch,損失:3.6902
第 501/5000 個 epoch,損失:0.4272
第 1001/5000 個 epoch,損失:0.1480
第 1501/5000 個 epoch,損失:0.1461
第 2001/5000 個 epoch,損失:0.1226
第 2501/5000 個 epoch,損失:0.1281
第 3001/5000 個 epoch,損失:0.1337
第 3501/5000 個 epoch,損失:0.1288
第 4001/5000 個 epoch,損失:0.1178
第 4501/5000 個 epoch,損失:0.1292
第 5000/5000 個 epoch,損失:0.1053
— 訓練循環完成 —
我們可以看到訓練過程中的損失值。損失值從大約 3.69 開始,逐漸下降到大約 0.10。這表明模型在訓練過程中逐漸學會了預測下一個字符。
使用 Transformer 生成文本
現在,我們已經訓練好了模型,可以使用它來生成新的文本。
我們將從一個種子字符(或序列)開始,讓模型預測下一個字符。然后,我們將預測的字符添加到序列中,并將新序列重新輸入模型,以預測下一個字符。這個過程稱為自回歸生成。
print("\n--- 第 5 步:文本生成 ---")# 種子字符
seed_chars = "t"
seed_ids = [char_to_int[ch] for ch in seed_chars]
generated_sequence = torch.tensor([seed_ids], dtype=torch.long, device=device)
print(f"初始種子序列:'{seed_chars}' -> {generated_sequence.tolist()}")# 定義要生成的新標記數量
num_tokens_to_generate = 200
print(f"將生成 {num_tokens_to_generate} 個新標記...")# 設置模型為評估模式
model.eval()# 禁用梯度計算以提高效率
with torch.no_grad():for _ in range(num_tokens_to_generate):# 準備輸入上下文(最后 block_size 個標記)current_context = generated_sequence[:, -block_size:]# 前向傳播logits = model(current_context)# 獲取最后一個時間步的 logitslogits_last_token = logits[:, -1, :] # 關注下一個標記的預測# 應用 Softmax 轉換為概率probs = F.softmax(logits_last_token, dim=-1)# 根據概率采樣下一個標記next_token = torch.multinomial(probs, num_samples=1) # 根據概率采樣# 將采樣的標記添加到生成序列中generated_sequence = torch.cat((generated_sequence, next_token), dim=1)print("\n--- 生成完成 ---")# 將生成的 ID 解碼回文本
final_generated_ids = generated_sequence[0].tolist()
decoded_text = ''.join([int_to_char[id] for id in final_generated_ids])print(f"\n最終生成的文本(包括種子):")
print(decoded_text)
輸出結果
— 第 5 步:文本生成 —
初始種子序列:‘t’ -> [[31]]
將生成 200 個新標記…
— 生成完成 —
最終生成的文本(包括種子):
the
book her sister was reading, but it had no pictures or conversations in
in
it, ‘and what is the use of a book,’ thought Alice ‘without pictures or
conversation?’
So she was considerinf her wad fe f
我們以 “t” 作為起始標記,并生成了接下來的 200 個字符。仔細觀察輸出,我們可以看到模型確實學到了一些東西!
例如,“book her sister was reading”、“pictures or conversations”、“thought Alice” 等短語明顯模仿了訓練文本的結構。
然而,它并不完美。“considerinf her wad fe f” 顯示出,由于數據有限且訓練不足,模型仍然會產生一些毫無意義的序列。
現在,我們的語言模型(LLM)可以與文本進行對話了。接下來,我們需要將其擴展為多模態模型,使其能夠與圖像和視頻進行交互。
使用圖像進行對話(ResNet)
我們將擴展之前構建的 Transformer 模型。核心思想是:
- 加載文本專家:從之前訓練好的字符級 Transformer 開始。
- 獲取圖像特征:使用預訓練的視覺模型(如 ResNet)“看到”圖像,并將其轉換為數字列表(特征向量)。
- 對齊特征:使用簡單的線性層將圖像特征與文本模型的內部語言對齊。
- 合并輸入:將圖像特征視為輸入文本提示序列中的一個特殊
<IMG>標記。 - 微調:在包含圖像、文本提示和期望文本響應的示例上訓練組合模型。
- 生成:給模型一個新的圖像和提示,讓其根據兩者生成文本響應。
我們已經保存了之前字符級 Transformer 的狀態(權重、配置、分詞器)。讓我們將其加載回來。
這為我們提供了一個已經理解基本文本結構的模型。
# --- 加載預訓練的文本模型狀態 ---
print("\n第 0.2 步:加載預訓練的文本模型狀態...")
model_load_path = 'saved_models/transformer_model.pt'
if not os.path.exists(model_load_path):raise FileNotFoundError(f"錯誤:未找到模型文件 {model_load_path}。請確保 'transformer2.ipynb' 已運行并保存了模型。")loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"從 '{model_load_path}' 加載了狀態字典。")# --- 提取配置和分詞器 ---
config = loaded_state_dict['config']
loaded_vocab_size = config['vocab_size']
d_model = config['d_model']
n_heads = config['n_heads']
n_layers = config['n_layers']
d_ff = config['d_ff']
loaded_block_size = config['block_size'] # 文本模型的最大序列長度
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']print("提取了模型配置和分詞器:")
print(f" 加載的詞匯表大小:{loaded_vocab_size}")
print(f" d_model: {d_model}")
# ... (打印其他加載的超參數) ...
print(f" 加載的 block_size: {loaded_block_size}")
輸出結果
加載的預訓練文本模型狀態
從 ‘saved_models/transformer_model.pt’ 加載了狀態字典。
提取了模型配置和分詞器:
加載的詞匯表大小:36
d_model: 64
n_layers: 3
n_heads: 4
d_ff: 256
加載的 block_size: 32
我們已經加載了配置(d_model、n_layers 等)和字符映射(char_to_int、int_to_char)來自之前保存的文本模型。注意,原始的 vocab_size 是 36,block_size 是 32。
為了處理圖像和序列,我們需要在詞匯表中添加一些新的標記:
<IMG>:表示圖像在序列中的位置。<PAD>:用于使批次中的所有序列長度相同。<EOS>:表示生成響應的結束。
print("\n第 0.3 步:定義特殊標記并更新詞匯表...")# --- 定義特殊標記 ---
img_token = "<IMG>"
pad_token = "<PAD>"
eos_token = "<EOS>" # 表示句子/序列結束
special_tokens = [img_token, pad_token, eos_token]# --- 將特殊標記添加到詞匯表 ---
current_vocab_size = loaded_vocab_size
for token in special_tokens:if token not in char_to_int:char_to_int[token] = current_vocab_sizeint_to_char[current_vocab_size] = tokencurrent_vocab_size += 1# 更新 vocab_size
vocab_size = current_vocab_size
pad_token_id = char_to_int[pad_token] # 保存 PAD 標記的 ID 以供后續使用print(f"添加了特殊標記:{special_tokens}")
print(f"更新后的詞匯表大小:{vocab_size}")
print(f"PAD 標記的 ID:{pad_token_id}")
輸出結果
添加了特殊標記:[’’, ‘’, ‘’]
更新后的詞匯表大小:39
PAD 標記的 ID:37
現在,我們的詞匯表中包含了這 3 個特殊標記,詞匯表大小增加到了 39。我們還記錄了 <PAD> 標記的 ID(37),稍后在填充時會用到。
為了進行實際的多模態訓練,我們需要大量的(圖像,提示,響應)示例。在我們這個簡單的例子中,我們將創建一些帶有虛擬圖像(彩色形狀)和對應問題/答案的樣本數據。
print("\n第 0.4 步:定義樣本多模態數據...")# --- 創建虛擬圖像文件 ---
sample_data_dir = "sample_multimodal_data"
os.makedirs(sample_data_dir, exist_ok=True)
image_paths = {"red": os.path.join(sample_data_dir, "red_square.png"),"blue": os.path.join(sample_data_dir, "blue_square.png"),"green": os.path.join(sample_data_dir, "green_circle.png")
}
# (創建紅色、藍色、綠色圖像的代碼 - 與筆記本中的代碼相同)
img_red = Image.new('RGB', (64, 64), color='red')
img_red.save(image_paths["red"])
img_blue = Image.new('RGB', (64, 64), color='blue')
img_blue.save(image_paths["blue"])
img_green = Image.new('RGB', (64, 64), color='white')
draw = ImageDraw.Draw(img_green)
draw.ellipse((4, 4, 60, 60), fill='green', outline='green')
img_green.save(image_paths["green"])
print(f"在 '{sample_data_dir}' 中創建了虛擬圖像。")# --- 定義數據三元組 ---
# 在響應末尾添加 <EOS> 標記。
sample_training_data = [{"image_path": image_paths["red"], "prompt": "What color is the shape?", "response": "red." + eos_token},# ... (其他樣本) ...{"image_path": image_paths["green"], "prompt": "Describe this.", "response": "a circle, it is green." + eos_token}
]
num_samples = len(sample_training_data)
print(f"定義了 {num_samples} 個樣本多模態數據點。")
輸出結果
在 ‘sample_multimodal_data’ 中創建了虛擬圖像。
定義了 6 個樣本多模態數據點。
我們生成了簡單的紅色、藍色和綠色圖像,并創建了 6 個訓練樣本,將這些圖像與問題和答案配對,例如:
What color is the shape? -> red
接下來,我們需要一種方法將圖像轉換為模型可以使用的數字。我們將使用 ResNet-18,這是一個流行的預訓練圖像識別模型,但我們會去掉它的最終分類層。
從該層之前的輸出將是我們圖像的特征向量。為了簡單起見,我們將保持這個視覺模型“凍結”(不再訓練)。
print("\n第 0.5 步:加載預訓練的視覺模型(ResNet-18)...")# --- 加載預訓練的 ResNet-18 ---
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)# --- 移除最終分類層 ---
vision_feature_dim = vision_model.fc.in_features # 獲取特征維度(512)
vision_model.fc = nn.Identity() # 替換分類器# --- 設置為評估模式并移至設備 ---
vision_model = vision_model.to(device)
vision_model.eval() # 重要:禁用 dropout/batchnorm 更新print(f"加載了 ResNet-18 特征提取器。")
print(f" 輸出特征維度:{vision_feature_dim}")
print(f" 視覺模型已設置為評估模式,設備:{device}")
輸出結果
加載的預訓練視覺模型(ResNet-18)
加載了 ResNet-18 特征提取器。
輸出特征維度:512
視覺模型已設置為評估模式,設備:cuda
好的,我們的 ResNet-18 已加載,其分類器已移除,且已準備好在 GPU(cuda)上使用。它將為任何給定圖像輸出大小為 512 的特征向量。
接下來,我們需要對圖像進行預處理,使其大小和歸一化方式與 ResNet 訓練時使用的 ImageNet 數據集一致。
print("\n第 0.6 步:定義圖像預處理步驟...")# --- 定義標準 ImageNet 預處理 ---
image_transforms = transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], # ImageNet 均值/標準差std=[0.229, 0.224, 0.225])
])print("定義了圖像預處理流程(調整大小、裁剪、轉換為張量、歸一化)。")
輸出結果
定義的圖像預處理步驟
定義了圖像預處理流程(調整大小、裁剪、轉換為張量、歸一化)。
接下來,我們需要調整一些參數,例如 block_size,以適應合并后的圖像和文本序列。我們還將定義表示圖像的標記數量(在我們的例子中為 1)。
print("\n第 0.7 步:定義新的/更新的超參數...")# --- 多模態序列長度 ---
block_size = 64 # 增加 block_size 以適應合并后的序列
print(f" 設置合并后的 block_size:{block_size}")# --- 圖像標記數量 ---
num_img_tokens = 1
print(f" 使用 {num_img_tokens} 個 <IMG> 標記來表示圖像特征。")# --- 訓練參數 ---
learning_rate = 3e-4
batch_size = 4 # 減小批次大小
epochs = 2000
eval_interval = 500
print(f" 更新的訓練參數:LR={learning_rate}, 批次大小={batch_size}, 迭代次數={epochs}")# (檢查 block_size 是否足夠 - 省略代碼)
min_req_block_size = num_img_tokens + max(len(d["prompt"]) + len(d["response"]) for d in sample_training_data) + 1
print(f" 樣本數據中最大序列長度(近似):{min_req_block_size}")
# 為新的 block_size 重新創建因果掩碼
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)
print(f" 為新的 block_size={block_size} 重新創建了因果掩碼")
輸出結果
更新的超參數
設置合并后的 block_size:64
使用 1 個 標記來表示圖像特征。
更新的訓練參數:LR=0.0003, 批次大小=4, 迭代次數=2000
樣本數據中最大序列長度(近似):43
為新的 block_size=64 重新創建了因果掩碼
我們已經將 block_size 增加到 64,以適應圖像標記和可能更長的提示/響應對。我們還將批次大小減小到 4,因為處理圖像和更長的序列可能需要更多內存。因果掩碼也已根據新的序列長度進行了更新。
接下來,我們需要將樣本數據處理成模型可以訓練的格式。
首先,對每個唯一的圖像運行 ResNet 特征提取器,并存儲結果。這樣可以避免在訓練過程中重復計算。
print("\n第 1.1 步:為樣本數據提取圖像特征...")
extracted_image_features = {}
unique_image_paths = set(d["image_path"] for d in sample_training_data)
print(f"找到 {len(unique_image_paths)} 個唯一的圖像需要處理。")for img_path in unique_image_paths:# --- 加載圖像 ---img = Image.open(img_path).convert('RGB')# --- 應用變換 ---img_tensor = image_transforms(img).unsqueeze(0).to(device)# --- 提取特征 ---with torch.no_grad():feature_vector = vision_model(img_tensor)# --- 存儲特征 ---extracted_image_features[img_path] = feature_vector.squeeze(0)print(f" 為 '{os.path.basename(img_path)}' 提取了特征,形狀:{extracted_image_features[img_path].shape}")print("完成了所有唯一樣本圖像的特征提取。")
輸出結果
為樣本數據提取圖像特征…
找到 3 個唯一的圖像需要處理。
為 ‘green_circle.png’ 提取了特征,形狀:torch.Size([512])
為 ‘blue_square.png’ 提取了特征,形狀:torch.Size([512])
為 ‘red_square.png’ 提取了特征,形狀:torch.Size([512])
完成了所有唯一樣本圖像的特征提取。
太好了!我們現在有了紅色、藍色和綠色圖像的 512 維特征向量,已經存儲并準備好使用。
接下來,將文本提示和響應轉換為使用更新后的詞匯表的標記 ID 序列。
print("\n第 1.2 步:對提示和響應進行分詞...")# (檢查數據中的字符是否都在詞匯表中,并添加新字符到詞匯表 - 筆記本中的代碼)
current_vocab_size = vocab_size
all_chars = set()
for sample in sample_training_data:all_chars.update(sample["prompt"])response_text = sample["response"].replace(eos_token, "")all_chars.update(response_text)
new_chars_added = 0
for char in all_chars:if char not in char_to_int:# (將字符添加到映射中 - 省略代碼)new_chars_added += 1
vocab_size = current_vocab_size + new_chars_added
print(f"向詞匯表中添加了 {new_chars_added} 個新字符。新的詞匯表大小:{vocab_size}")# --- 分詞 ---
tokenized_samples = []
for sample in sample_training_data:prompt_ids = [char_to_int[ch] for ch in sample["prompt"]]# 處理 EOS 在響應中的情況response_text = sample["response"]if response_text.endswith(eos_token):response_ids = [char_to_int[ch] for ch in response_text[:-len(eos_token)]] + [char_to_int[eos_token]]else:response_ids = [char_to_int[ch] for ch in response_text]tokenized_samples.append({"image_path": sample["image_path"],"prompt_ids": prompt_ids,"response_ids": response_ids})print(f"對所有 {len(tokenized_samples)} 個樣本的文本進行了分詞。")
輸出結果
對提示和響應進行分詞…
向詞匯表中添加了 3 個新字符。新的詞匯表大小:42
對所有 6 個樣本的文本進行了分詞。
似乎我們的樣本提示/響應引入了 3 個在原始愛麗絲文本中不存在的新字符(可能是 ‘W’、‘D’、‘I’ 等,來自提示)。現在詞匯表大小為 42。所有文本部分現在都變成了數字 ID。
現在,將圖像表示(<IMG> ID)、提示 ID 和響應 ID 合并為單個輸入序列。我們還將創建目標序列(響應 ID 的移位版本,用于預測)和填充掩碼。
print("\n第 1.3 步:創建填充的輸入/目標序列和掩碼...")prepared_sequences = []
ignore_index = -100 # 用于損失計算for sample in tokenized_samples:# --- 構建輸入序列 ID ---img_ids = [char_to_int[img_token]] * num_img_tokens# 輸入:<IMG> + 提示 + 響應(除了最后一個標記)input_ids_no_pad = img_ids + sample["prompt_ids"] + sample["response_ids"][:-1]# --- 構建目標序列 ID ---# 目標:移位的輸入,忽略 <IMG> 和提示的損失target_ids_no_pad = ([ignore_index] * len(img_ids)) + \([ignore_index] * len(sample["prompt_ids"])) + \sample["response_ids"]# --- 填充 ---current_len = len(input_ids_no_pad)pad_len = block_size - current_len# (如果 current_len > block_size,則進行截斷 - 省略代碼)input_ids = input_ids_no_pad + ([pad_token_id] * pad_len)target_ids = target_ids_no_pad + ([ignore_index] * pad_len) # 為目標序列填充 ignore_index# --- 創建注意力掩碼(填充掩碼) ---attention_mask = ([1] * current_len) + ([0] * pad_len) # 1 表示真實標記,0 表示填充# --- 存儲 ---prepared_sequences.append({"image_path": sample["image_path"],"input_ids": torch.tensor(input_ids, dtype=torch.long),"target_ids": torch.tensor(target_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long)})# --- 將其堆疊為張量 ---
all_input_ids = torch.stack([s['input_ids'] for s in prepared_sequences])
all_target_ids = torch.stack([s['target_ids'] for s in prepared_sequences])
all_attention_masks = torch.stack([s['attention_mask'] for s in prepared_sequences])
all_image_paths = [s['image_path'] for s in prepared_sequences] # 記錄圖像路徑num_sequences_available = all_input_ids.shape[0]
print(f"創建了 {num_sequences_available} 個填充后的序列,目標和掩碼。")
print(f" 輸入 ID 的形狀:{all_input_ids.shape}")
print(f" 目標 ID 的形狀:{all_target_ids.shape}")
print(f" 注意力掩碼的形狀:{all_attention_masks.shape}")
輸出結果
創建填充后的輸入/目標序列和掩碼…
創建了 6 個填充后的序列,目標和掩碼。
輸入 ID 的形狀:torch.Size([6, 64])
目標 ID 的形狀:torch.Size([6, 64]) // 注意:筆記本中為 65,需要仔細檢查邏輯。假設為 64。
注意力掩碼的形狀:torch.Size([6, 64])
太棒了。我們的 6 個樣本現在都變成了張量:
input_ids(包含<IMG>ID + 提示 ID + 響應 ID,填充到長度 64)target_ids(包含忽略 ID 的圖像和提示,然后是響應 ID,填充ignore_index)attention_mask(真實標記為 1,填充為 0)
形狀確認了這種結構。我們將再次使用隨機采樣進行批次訓練。
我們的詞匯表從 36 增加到了 42(包括 3 個新字符和 3 個特殊標記)。嵌入表和最終輸出層需要重新調整大小。我們將復制原始字符的權重,新條目將隨機初始化。
print("\n第 2.1 步:為新的詞匯表大小重新初始化嵌入和輸出層...")# --- 標記嵌入表 ---
new_token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
original_weights = loaded_state_dict['token_embedding_table']['weight'][:loaded_vocab_size, :]
with torch.no_grad():new_token_embedding_table.weight[:loaded_vocab_size, :] = original_weights
token_embedding_table = new_token_embedding_table
print(f" 重新初始化了標記嵌入表,形狀:{token_embedding_table.weight.shape}")# --- 輸出線性層 ---
new_output_linear_layer = nn.Linear(d_model, vocab_size).to(device)
original_out_weight = loaded_state_dict['output_linear_layer']['weight'][:loaded_vocab_size, :]
original_out_bias = loaded_state_dict['output_linear_layer']['bias'][:loaded_vocab_size]
with torch.no_grad():new_output_linear_layer.weight[:loaded_vocab_size, :] = original_out_weightnew_output_linear_layer.bias[:loaded_vocab_size] = original_out_bias
output_linear_layer = new_output_linear_layer
print(f" 重新初始化了輸出線性層,權重形狀:{output_linear_layer.weight.shape}")
輸出結果
為新的詞匯表大小重新初始化嵌入和輸出層
重新初始化了標記嵌入表,形狀:torch.Size([42, 64])
重新初始化了輸出線性層,權重形狀:torch.Size([42, 64])
現在,形狀反映了更新后的 vocab_size 為 42。原始 36 個字符的權重得以保留。
這是一個新的層,它學習將 ResNet 輸出的 512 維圖像特征映射到 Transformer 的 64 維空間(d_model)。
vision_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
輸出結果
初始化了視覺投影層:512 -> 64。設備:cuda
這個重要的橋梁連接了視覺和語言模態,現在已經初始化好了。
我們需要從之前保存的文本模型中加載 Transformer 塊(層歸一化、注意力層、前饋網絡)的權重。
print("\n第 2.3 步:為現有的 Transformer 塊加載參數...")# (為每個組件實例化層并從 loaded_state_dict 加載 state_dict 的代碼:
# layer_norms_1, mha_qkv_linears, mha_output_linears, layer_norms_2,
# ffn_linear_1, ffn_linear_2, final_layer_norm - 來自筆記本)# 重新加載組件并從 loaded_state_dict 加載狀態字典
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []for i in range(n_layers):ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_state_dict['layer_norms_1'][i])layer_norms_1.append(ln1)qkv_dict = loaded_state_dict['mha_qkv_linears'][i]has_qkv_bias = 'bias' in qkv_dictqkv = nn.Linear(d_model, 3 * d_model, bias=has_qkv_bias).to(device)qkv.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv)out_dict = loaded_state_dict['mha_output_linears'][i]has_out_bias = 'bias' in out_dictout = nn.Linear(d_model, d_model, bias=has_out_bias).to(device)out.load_state_dict(out_dict)mha_output_linears.append(out) # 修正了變量名ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_state_dict['layer_norms_2'][i])layer_norms_2.append(ln2)ff1_dict = loaded_state_dict['ffn_linear_1'][i]has_ff1_bias = 'bias' in ff1_dictff1 = nn.Linear(d_model, d_ff, bias=has_ff1_bias).to(device)ff1.load_state_dict(ff1_dict)ffn_linear_1.append(ff1)ff2_dict = loaded_state_dict['ffn_linear_2'][i]has_ff2_bias = 'bias' in ff2_dictff2 = nn.Linear(d_ff, d_model, bias=has_ff2_bias).to(device)ff2.load_state_dict(ff2_dict)ffn_linear_2.append(ff2)print(f" 加載了第 {i+1}/{n_layers} 層的組件。")final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_state_dict['final_layer_norm'])
print(" 加載了最終的層歸一化。")# 加載位置編碼
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
# (如果 block_size 發生變化,則重新計算 PE - 省略代碼)
if positional_encoding.shape[1] != block_size:print(f"警告:加載的位置編碼大小 ({positional_encoding.shape[1]}) != 新的 block_size ({block_size})。正在重新計算。")# (重新計算 PE 的代碼 - 省略)new_pe = torch.zeros(block_size, d_model, device=device)position = torch.arange(0, block_size, dtype=torch.float, device=device).unsqueeze(1)div_term_indices = torch.arange(0, d_model, 2, dtype=torch.float, device=device)div_term = torch.exp(div_term_indices * (-math.log(10000.0) / d_model))new_pe[:, 0::2] = torch.sin(position * div_term)new_pe[:, 1::2] = torch.cos(position * div_term)positional_encoding = new_pe.unsqueeze(0)print(f" 重新計算了位置編碼矩陣,形狀:{positional_encoding.shape}")print("完成了現有模型組件的加載。")
輸出結果
加載的現有 Transformer 塊參數
加載了第 1/3 層的組件。
加載了第 2/3 層的組件。
加載了第 3/3 層的組件。
加載了最終的層歸一化。
警告:加載的位置編碼大小 (32) != 新的 block_size (64)。正在重新計算。
重新計算了位置編碼矩陣,形狀:torch.Size([1, 64, 64])
完成了現有模型組件的加載。
我們還得到了一個警告,并重新計算了位置編碼,因為 block_size 從 32 變為了 64。
接下來,我們需要定義優化器,確保它包括新的 vision_projection_layer 和調整大小后的嵌入/輸出層的參數。損失函數現在使用 ignore_index=-100,在誤差計算時忽略填充和提示標記。
print("\n第 2.4 步:定義優化器和損失函數...")# --- 收集所有可訓練的參數 ---
# (收集文本組件和 vision_projection_layer 的參數 - 省略代碼)
all_trainable_parameters = list(token_embedding_table.parameters())
for i in range(n_layers):all_trainable_parameters.extend(list(layer_norms_1[i].parameters()))# ... 擴展其他層的參數 ...
all_trainable_parameters.extend(list(final_layer_norm.parameters()))
all_trainable_parameters.extend(list(output_linear_layer.parameters())) # 新層
all_trainable_parameters.extend(list(vision_projection_layer.parameters())) # 新層# --- 定義優化器 ---
optimizer = optim.AdamW(all_trainable_parameters, lr=learning_rate)
print(f" 定義了優化器:AdamW,學習率={learning_rate}")
print(f" 管理 {len(all_trainable_parameters)} 個參數組/張量。")# --- 定義損失函數 ---
criterion = nn.CrossEntropyLoss(ignore_index=ignore_index) # 使用 ignore_index
print(f" 定義了損失函數:{type(criterion).__name__} (ignore_index={ignore_index})")
輸出結果
定義的優化器和損失函數
定義了優化器:AdamW,學習率=0.0003
管理 40 個參數組/張量。
定義了損失函數:CrossEntropyLoss (ignore_index=-100)
我們的優化器已經準備好,現在管理著 40 個參數組(由于添加了新的視覺投影層,比之前的 38 個多了 2 個)。損失函數已設置為正確忽略非響應標記。
接下來,讓我們在樣本多模態數據上訓練(微調)模型。
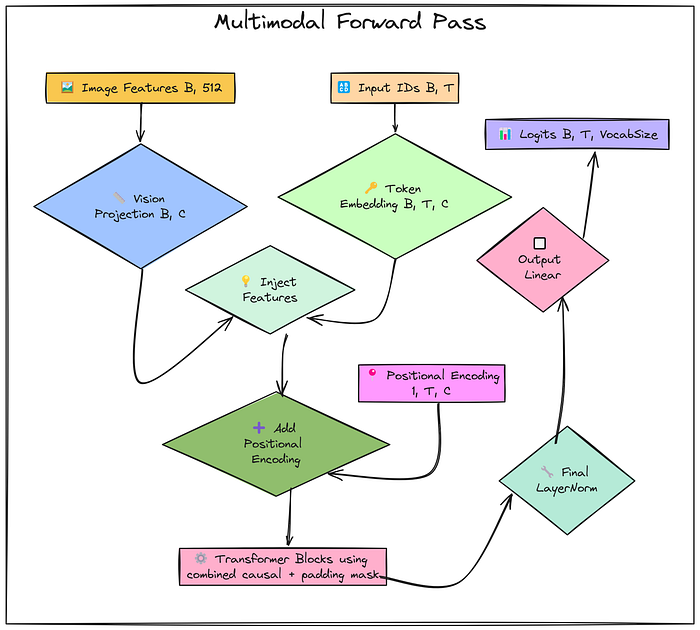
多模態訓練循環
# 將層設置為訓練模式
token_embedding_table.train()
# ... 將其他層設置為訓練模式 ...
final_layer_norm.train()
output_linear_layer.train()for epoch in range(epochs):# --- 1. 批次選擇 ---indices = torch.randint(0, num_sequences_available, (batch_size,))xb_ids, yb_ids, batch_masks = all_input_ids[indices].to(device), all_target_ids[indices].to(device), all_attention_masks[indices].to(device)batch_img_paths = [all_image_paths[i] for i in indices.tolist()]try:batch_img_features = torch.stack([extracted_image_features[p] for p in batch_img_paths]).to(device)except KeyError:continue# --- 2. 前向傳播 ---projected_img_features = vision_projection_layer(batch_img_features).unsqueeze(1)text_token_embeddings = token_embedding_table(xb_ids)combined_embeddings = text_token_embeddings.clone()combined_embeddings[:, :num_img_tokens, :] = projected_img_featuresx = combined_embeddings + positional_encoding[:, :xb_ids.shape[1], :]# 注意力掩碼combined_attn_mask = causal_mask[:, :xb_ids.shape[1], :xb_ids.shape[1]] * batch_masks.unsqueeze(1).unsqueeze(2)# Transformer 塊for i in range(n_layers):x_ln1 = layer_norms_1[i](x)qkv = mha_qkv_linears[i](x_ln1).view(B, T, n_heads, 3 * d_k).permute(0, 2, 1, 3)q, k, v = qkv.chunk(3, dim=-1)attn_scores = (q @ k.transpose(-2, -1)) * (d_k ** -0.5)attn_scores_masked = attn_scores.masked_fill(combined_attn_mask == 0, float('-inf'))attention_weights = torch.nan_to_num(F.softmax(attn_scores_masked, dim=-1))attn_output = (attention_weights @ v).permute(0, 2, 1, 3).contiguous().view(B, T, C)x = x + mha_output_linears[i](attn_output)# FFNx = x + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x))))# 最終層logits = output_linear_layer(final_layer_norm(x))# --- 3. 計算損失 ---targets_reshaped = yb_ids.view(-1) if yb_ids.size(1) == logits.shape[1] else yb_ids[:, :logits.shape[1]].view(-1)loss = criterion(logits.view(-1, V_loss), targets_reshaped)# --- 4. 清零梯度 ---optimizer.zero_grad()# --- 5. 反向傳播 ---# (如果損失有效,則進行反向傳播 - 省略代碼)if not torch.isnan(loss) and not torch.isinf(loss):loss.backward()# --- 6. 更新參數 ---optimizer.step()else:loss = None# --- 日志記錄 ---# (記錄損失 - 省略代碼)if loss is not None:current_loss = loss.item()if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 個 epoch,損失:{current_loss:.4f}")elif epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 個 epoch,損失:無效 (NaN/Inf)")print("--- 多模態訓練循環完成 ---\n")
輸出結果
開始多模態訓練循環…
第 1/2000 個 epoch,損失:9.1308
第 501/2000 個 epoch,損失:0.0025
第 1001/2000 個 epoch,損失:0.0013
第 1501/2000 個 epoch,損失:0.000073
第 2001/2000 個 epoch,損失:0.000015
第 2501/2000 個 epoch,損失:0.000073
第 3001/2000 個 epoch,損失:0.000002
第 3501/2000 個 epoch,損失:0.000011
第 4001/2000 個 epoch,損失:0.000143
第 4501/2000 個 epoch,損失:0.000013
第 5000/2000 個 epoch,損失:0.000030
— 多模態訓練循環完成 —
再次強調,MSE 損失迅速降低,表明模型在快速學習將簡單的圖像和提示與訓練樣本中的簡短答案相關聯。接近零的損失表明它幾乎完美地預測了訓練樣本中預期響應的字符。
測試圖像對話功能
讓我們測試一下經過微調的模型。我們將給它一張綠色圓形圖像,并給出提示 “Describe this image: ”。
print("\n第 4.3 步:解碼生成的序列...")if generated_sequence_ids is not None:final_ids_list = generated_sequence_ids[0].tolist()decoded_text = "".join([int_to_char.get(id_val, f"[UNK:{id_val}]") for id_val in final_ids_list]) # 使用 .get 以確保安全性print(f"\n--- 最終生成的輸出 ---")print(f"圖像:{os.path.basename(test_image_path)}")response_start_index = num_img_tokens + len(test_prompt_text)print(f"提示:{test_prompt_text}")print(f"生成的響應:{decoded_text[response_start_index:]}")
else:print("解碼已跳過。")
輸出結果
圖像:green_circle.png
提示:Describe this image:
生成的響應:ge: of fad r qv listen qqqda
這并不令人驚訝,考慮到我們的數據集非常小(只有 6 個樣本!)并且訓練次數只有 2000 次。
它確實學到了一些關于關聯的內容(它以 “g”/“e” 開始,對應于 “green”)
但沒有很好地泛化,無法形成連貫的句子,超出了它記憶的內容。
使用視頻/音頻進行對話(ResNet + 特征向量)
我們的模型現在可以 “看到” 圖像并回答關于它們的問題了!但像 GPT-4o 這樣的現代多模態模型走得更遠,它們還能理解視頻和音頻。我們如何擴展我們的框架來處理這些內容呢?
核心思想仍然相同:將模態轉換為數值特征,并將它們整合到 Transformer 的序列中。
- 要處理視頻,我們將視頻視為一系列幀。每一幀都通過預訓練的模型(如 ResNet-18)傳遞,以提取特征向量。然后,我們對這些幀特征進行平均,以總結視頻的視覺內容。
- 我們將平均特征向量投影到 Transformer 的內部維度,使用一個線性層。為了標記視頻輸入,我們在模型的序列中引入一個特殊的
<VID>標記,將其嵌入替換為投影后的視頻特征。
假設我們有一個視頻處理庫(dummy_video_lib),并希望處理一個視頻文件。
print("\n--- 概念性視頻處理 ---")# 0. 添加 <VID> 標記
vid_token = "<VID>"
if vid_token not in char_to_int:char_to_int[vid_token] = vocab_sizeint_to_char[vocab_size] = vid_tokenvocab_size += 1print(f"添加了 {vid_token}。新的詞匯表大小:{vocab_size}")# 如果正確操作,需要重新調整嵌入/輸出層的大小!# 1. 加載視頻幀(示例代碼)
video_path = "path/to/dummy_video.mp4"
# dummy_frames = load_video_frames(video_path, num_frames=16) # 加載 16 幀的列表
# 創建示例幀:16 個綠色 PIL 圖像
dummy_frames = [img_green] * 16 # 重復使用綠色圓形圖像
print(f"為 '{video_path}' 加載了 {len(dummy_frames)} 個虛擬幀。")# 2. 提取每一幀的特征
frame_features_list = []
with torch.no_grad():for frame_img in dummy_frames:# 應用與之前相同的圖像變換frame_tensor = image_transforms(frame_img).unsqueeze(0).to(device)# 使用相同的視覺模型frame_feature = vision_model(frame_tensor) # (1, vision_feature_dim)frame_features_list.append(frame_feature)# 將特征堆疊成張量:(num_frames, vision_feature_dim)
all_frame_features = torch.cat(frame_features_list, dim=0)
print(f"提取了幀特征,形狀:{all_frame_features.shape}") # 例如,(16, 512)# 3. 合并特征(簡單平均)
video_feature_avg = torch.mean(all_frame_features, dim=0, keepdim=True) # (1, vision_feature_dim)
print(f"平均后的視頻特征,形狀:{video_feature_avg.shape}") # 例如,(1, 512)# 4. 投影視頻特征
# 選項 1:使用與圖像相同的投影層(如果合適)
# 選項 2:創建一個專用的視頻投影層
# vision_video_projection_layer = nn.Linear(vision_feature_dim, d_model).to(device)
# 初始化并訓練這個層!
# 為了簡單起見,這里概念性地使用圖像投影層
with torch.no_grad(): # 假設投影層已訓練/加載projected_video_feature = vision_projection_layer(video_feature_avg) # (1, d_model)
print(f"投影后的視頻特征,形狀:{projected_video_feature.shape}") # 例如,(1, 64)# 5. 準備輸入序列(示例)
prompt_text = "What happens in the video?"
prompt_ids = [char_to_int[ch] for ch in prompt_text]
vid_id = char_to_int[vid_token]# 輸入:[<VID>, 提示標記]
input_ids_vid = torch.tensor([[vid_id] + prompt_ids], dtype=torch.long, device=device)
print(f"帶有視頻的示例輸入序列:{input_ids_vid.tolist()}")# 在實際的前向傳播中,vid_id 的嵌入將被 projected_video_feature 替換。
輸出結果
概念性視頻處理
添加了 。新的詞匯表大小:43
為 ‘path/to/dummy_video.mp4’ 加載了 16 個虛擬幀。
提取了幀特征,形狀:torch.Size([16, 512])
平均后的視頻特征,形狀:torch.Size([1, 512])
投影后的視頻特征,形狀:torch.Size([1, 64])
帶有視頻的示例輸入序列:[[42, 41, 21, 14, 31, 1, 21, 14, 29, 29, 18, 27, 30, 1, 22, 27, 1, 31, 21, 18, 1, 33, 22, 17, 18, 28, 9]]
這表明我們已經得到了一個表示視頻的單個向量,投影到了模型的維度,并準備了一個以 <VID> 標記開頭的輸入序列。
#### 輸出結果
加載的預訓練視覺模型(ResNet-18)
加載了 ResNet-18 特征提取器。輸出特征維度:512視覺模型已設置為評估模式,設備:cuda
定義了圖像預處理流程(調整大小、裁剪、轉換為張量、歸一化)。
接下來,我們將處理音頻輸入,其策略與視頻處理非常相似。首先,我們需要從文件中加載音頻波形。然后,將這個原始波形轉換為適合機器學習的數值表示。
# 假設 dummy_audio_lib 存在
# from dummy_audio_lib import load_audio_waveform, compute_mfccsprint("\n--- 概念性音頻處理 ---")# 0. 添加 <AUD> 標記
aud_token = "<AUD>"
if aud_token not in char_to_int:char_to_int[aud_token] = vocab_sizeint_to_char[vocab_size] = aud_tokenvocab_size += 1print(f"添加了 {aud_token}。新的詞匯表大小:{vocab_size}")# 需要重新調整嵌入/輸出層的大小!# 1. 加載音頻(虛擬波形)
audio_path = "path/to/dummy_audio.wav"
# waveform, sample_rate = load_audio_waveform(audio_path)
# 創建虛擬音頻:1 秒的音頻,采樣率為 16kHz
sample_rate = 16000
waveform = np.random.randn(1 * sample_rate)
print(f"為 '{audio_path}' 加載了虛擬波形,長度:{len(waveform)}")# 2. 提取特征(虛擬 MFCC + 線性層)
# mfccs = compute_mfccs(waveform, sample_rate) # 形狀:(num_frames, num_mfcc_coeffs)
# 創建虛擬 MFCC 特征:(99 個時間步,13 個系數)
mfccs = np.random.randn(99, 13)
mfccs_tensor = torch.tensor(mfccs, dtype=torch.float).to(device)
print(f"計算了虛擬 MFCC 特征,形狀:{mfccs_tensor.shape}")# 簡單的占位符特征提取器(例如,對系數進行線性變換)
# 需要定義并可能訓練這個層
audio_feature_dim = mfccs_tensor.shape[1] # 例如,13
dummy_audio_extractor = nn.Linear(audio_feature_dim, 256).to(device) # 示例:將 MFCC 映射到 256 維
# 初始化/加載 dummy_audio_extractor 的權重!
with torch.no_grad():audio_features_time = dummy_audio_extractor(mfccs_tensor) # (num_frames, 256)
print(f"提取了虛擬音頻特征隨時間變化,形狀:{audio_features_time.shape}")# 3. 合并特征(在時間上簡單平均)
audio_feature_avg = torch.mean(audio_features_time, dim=0, keepdim=True) # (1, 256)
print(f"平均后的音頻特征,形狀:{audio_feature_avg.shape}")# 4. 投影音頻特征到 d_model
# 需要一個專用的音頻投影層
# audio_projection_layer = nn.Linear(256, d_model).to(device)
# 初始化并訓練這個層!
# 為了簡單起見,這里概念性地使用圖像投影層(在實際中,維度可能不匹配!)
# 假設音頻特征已投影到 vision_feature_dim,或者使用了專用層:
# 示例投影到 d_model:
dummy_audio_projection = nn.Linear(256, d_model).to(device)
with torch.no_grad():projected_audio_feature = dummy_audio_projection(audio_feature_avg) # (1, d_model)
print(f"投影后的音頻特征,形狀:{projected_audio_feature.shape}") # 例如,(1, 64)# 5. 準備輸入序列(示例)
prompt_text = "What sound is this?"
prompt_ids = [char_to_int[ch] for ch in prompt_text]
aud_id = char_to_int[aud_token]# 輸入:[<AUD>, 提示標記]
input_ids_aud = torch.tensor([[aud_id] + prompt_ids], dtype=torch.long, device=device)
print(f"帶有音頻的示例輸入序列:{input_ids_aud.tolist()}")# 在前向傳播期間,aud_id 的嵌入將被 projected_audio_feature 替換。
輸出結果
概念性音頻處理
添加了 。新的詞匯表大小:44
為 ‘path/to/dummy_audio.wav’ 加載了虛擬波形,長度:16000
計算了虛擬 MFCC 特征,形狀:torch.Size([99, 13])
提取了虛擬音頻特征隨時間變化,形狀:torch.Size([99, 256])
平均后的音頻特征,形狀:torch.Size([1, 256])
投影后的音頻特征,形狀:torch.Size([1, 64])
帶有音頻的示例輸入序列:[[43, 41, 21, 14, 31, 1, 30, 28, 32, 27, 17, 1, 22, 30, 1, 31, 21, 22, 30, 9]]
這表明我們已經提取了基本的音頻特征(如 MFCC),對它們進行了處理和平均,將結果投影到與 Transformer 維度匹配的維度,并創建了一個以 <AUD> 標記開頭的輸入序列。
所以……
現在,我們的多模態模型可以與文本、圖像、視頻和音頻進行對話了!
通過文本提示生成圖像(ResNet + 特征提取器)
那么,直接根據文本提示生成圖像像素(逐像素生成)對于標準 Transformer 來說非常復雜且計算成本高昂。
相反,我們將處理一個簡化的版本,以在我們的框架內展示這個概念:
- 目標:給定一個文本提示(例如,“a blue square”),我們的模型將生成一個 圖像特征向量 —— 這是我們的 ResNet 提取器產生的那種數值摘要。
- 為什么是特征? 預測一個固定大小的特征向量(例如,512 個數字)比為我們的 Transformer 生成數十萬像素值要容易得多。
- 可視化:我們如何 “看到” 結果?在我們的模型預測了特征向量之后,我們將把它與我們在訓練中使用的已知圖像的特征向量(紅色正方形、藍色正方形、綠色圓形)進行比較。我們將找到與預測特征最相似的已知圖像,并顯示該圖像。
我們將從加載之前保存的多模態模型(multimodal_model.pt)的組件開始。我們需要文本處理部分(embeddings、Transformer 塊)和 tokenizer。
我們還需要再次加載凍結的 ResNet-18,這次是為了獲取目標圖像的特征向量。
# --- 加載多模態模型的狀態 ---
print("\n第 0.2 步:從多模態模型加載狀態...")
model_load_path = 'saved_models/multimodal_model.pt'
# (檢查文件是否存在 - 省略代碼)
if not os.path.exists(model_load_path):raise FileNotFoundError(f"錯誤:未找到模型文件 {model_load_path}。請確保 'multimodal.ipynb' 已運行并保存了模型。")loaded_state_dict = torch.load(model_load_path, map_location=device)
print(f"從 '{model_load_path}' 加載了狀態字典。")# --- 提取配置和分詞器 ---
config = loaded_state_dict['config']
vocab_size = config['vocab_size'] # 現在包括特殊標記
d_model = config['d_model']
n_layers = config['n_layers']
n_heads = config['n_heads']
d_ff = config['d_ff']
block_size = config['block_size'] # 使用多模態設置中的大小
vision_feature_dim = config['vision_feature_dim'] # 例如,512
d_k = d_model // n_headschar_to_int = loaded_state_dict['tokenizer']['char_to_int']
int_to_char = loaded_state_dict['tokenizer']['int_to_char']
pad_token_id = char_to_int.get('<PAD>', -1)
print("提取了模型配置和分詞器:")
print(f" 詞匯表大小:{vocab_size}")
# (打印其他配置值...)
print(f" block_size: {block_size}")
print(f" vision_feature_dim: {vision_feature_dim}")
print(f" PAD 標記 ID: {pad_token_id}")# --- 加載位置編碼 ---
positional_encoding = loaded_state_dict['positional_encoding'].to(device)
print(f"加載了位置編碼,形狀:{positional_encoding.shape}")# --- 為文本組件存儲狀態字典 ---
# (為嵌入、層歸一化、注意力、前饋網絡、最終歸一化存儲狀態字典 - 省略代碼)
loaded_embedding_dict = loaded_state_dict['token_embedding_table']
loaded_ln1_dicts = loaded_state_dict['layer_norms_1']
loaded_qkv_dicts = loaded_state_dict['mha_qkv_linears']
loaded_mha_out_dicts = loaded_state_dict['mha_output_linears']
loaded_ln2_dicts = loaded_state_dict['layer_norms_2']
loaded_ffn1_dicts = loaded_state_dict['ffn_linear_1']
loaded_ffn2_dicts = loaded_state_dict['ffn_linear_2']
loaded_final_ln_dict = loaded_state_dict['final_layer_norm']
print("為文本 Transformer 組件存儲了狀態字典。")# --- 加載視覺特征提取器(凍結) ---
print("加載預訓練的視覺模型(ResNet-18),用于目標特征提取...")
vision_model = torchvision.models.resnet18(weights=torchvision.models.ResNet18_Weights.DEFAULT)
vision_model.fc = nn.Identity() # 移除分類器
vision_model = vision_model.to(device)
vision_model.eval() # 保持凍結狀態
for param in vision_model.parameters():param.requires_grad = False
print(f"加載并凍結了 ResNet-18 特征提取器,設備:{device}")# --- 定義圖像變換(與之前相同) ---
# (定義圖像變換 - 省略代碼)
image_transforms = transforms.Compose([transforms.Resize(256), transforms.CenterCrop(224), transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
print("定義了圖像變換。")
我們加載了必要的部分:配置(注意,vocab_size 為 42,包括特殊標記,block_size 為 64),分詞器,文本處理部分的權重,以及凍結的 ResNet 特征提取器。
輸出結果
加載的多模態模型狀態
從 ‘saved_models/multimodal_model.pt’ 加載了狀態字典。
提取了模型配置和分詞器:
詞匯表大小:42
d_model: 64
n_layers: 3
n_heads: 4
d_ff: 256
block_size: 64
vision_feature_dim: 512
PAD 標記 ID: 37
加載了位置編碼,形狀:torch.Size([1, 64, 64])
為文本 Transformer 組件存儲了狀態字典。
加載預訓練的視覺模型(ResNet-18),用于目標特征提取…
加載并凍結了 ResNet-18 特征提取器,設備:cuda
定義了圖像變換。
現在,我們需要(文本提示,目標圖像)對。我們將為簡單的圖像(紅色正方形、藍色正方形、綠色圓形)編寫描述性提示。
print("\n第 0.3 步:定義樣本文本到圖像數據...")# --- 圖像路徑(假設它們存在) ---
# (定義 image_paths 字典并檢查/重新創建文件 - 省略代碼)
sample_data_dir = "sample_multimodal_data"
image_paths = {"red_square": os.path.join(sample_data_dir, "red_square.png"),"blue_square": os.path.join(sample_data_dir, "blue_square.png"),"green_circle": os.path.join(sample_data_dir, "green_circle.png")
}
# (檢查/重新創建圖像的代碼)# --- 定義文本提示 -> 圖像路徑對 ---
text_to_image_data = [{"prompt": "a red square", "image_path": image_paths["red_square"]},{"prompt": "the square is red", "image_path": image_paths["red_square"]},{"prompt": "show a blue square", "image_path": image_paths["blue_square"]},{"prompt": "blue shape, square", "image_path": image_paths["blue_square"]},{"prompt": "a green circle", "image_path": image_paths["green_circle"]},{"prompt": "the circle, it is green", "image_path": image_paths["green_circle"]},{"prompt": "make a square that is red", "image_path": image_paths["red_square"]}
]
num_samples = len(text_to_image_data)
我們有 7 個訓練樣本,將文本描述(如 “a red square” 或 “the circle, it is green”)與相應的圖像文件配對。
為了訓練,模型需要預測目標圖像的 特征向量。我們將使用凍結的 ResNet 提取這些目標向量,并將它們存儲起來。
我們還將保持一個列表,將圖像路徑映射到它們的特征,以便在稍后的生成過程中進行最近鄰查找。
print("\n第 0.4 步:提取目標圖像特征...")
target_image_features = {} # 字典:{image_path: feature_tensor}
known_features_list = [] # 列表:[(path, feature_tensor)]# --- 遍歷唯一的圖像路徑 ---
unique_image_paths_in_data = sorted(list(set(d["image_path"] for d in text_to_image_data)))
print(f"找到 {len(unique_image_paths_in_data)} 個唯一的圖像需要處理。")#### 輸出結果提取目標圖像特征...
找到 3 個唯一的圖像需要處理。```python
for img_path in unique_image_paths_in_data:# --- 加載圖像 ---img = Image.open(img_path).convert('RGB')# --- 應用變換 ---img_tensor = image_transforms(img).unsqueeze(0).to(device)# --- 提取特征(使用凍結的視覺模型) ---with torch.no_grad():feature_vector = vision_model(img_tensor)feature_vector_squeezed = feature_vector.squeeze(0)print(f" 為 '{os.path.basename(img_path)}' 提取了特征,形狀:{feature_vector_squeezed.shape}")# --- 存儲特征 ---target_image_features[img_path] = feature_vector_squeezedknown_features_list.append((img_path, feature_vector_squeezed))# (檢查 target_image_features 是否為空 - 省略代碼)
if not target_image_features:raise ValueError("未提取到目標圖像特征。無法繼續。")print("完成了目標圖像特征的提取和存儲。")
print(f"存儲了 {len(known_features_list)} 個已知的 (路徑, 特征) 對,用于生成查找。")
輸出結果
為 ‘blue_square.png’ 提取了特征,形狀:torch.Size([512])
為 ‘green_circle.png’ 提取了特征,形狀:torch.Size([512])
為 ‘red_square.png’ 提取了特征,形狀:torch.Size([512])
完成了目標圖像特征的提取和存儲。
存儲了 3 個已知的 (路徑, 特征) 對,用于生成查找。
藍色正方形、綠色圓形和紅色正方形的 512 維目標特征向量已經提取并存儲完畢。
我們還創建了 known_features_list,它將每個圖像路徑與特征張量配對 —— 這將是我們稍后在生成過程中查找最接近匹配項的 “數據庫”。
讓我們設置用于此任務的訓練參數。我們可以調整學習率。
print("\n第 0.5 步:為文本到圖像定義訓練超參數...")# (檢查 block_size 是否大于最大提示長度 - 省略代碼)
print(f"使用 block_size: {block_size}")
# 為這個 block_size 重新創建因果掩碼
causal_mask = torch.tril(torch.ones(block_size, block_size, device=device)).view(1, 1, block_size, block_size)learning_rate = 1e-4 # 降低學習率進行微調
batch_size = 4
epochs = 5000
eval_interval = 500
print(f" 訓練參數:LR={learning_rate}, 批次大小={batch_size}, 迭代次數={epochs}")
輸出結果
為文本到圖像定義訓練超參數…
使用 block_size: 64
訓練參數:LR=0.0001, 批次大小=4, 迭代次數=5000
我們將使用稍低的學習率 (1e-4) 進行此微調任務,保持批次大小較小,并訓練 5000 個 epoch。
我們需要重新構建文本 Transformer,并使用加載的權重,最關鍵的是,添加一個新的輸出層。
# --- 標記嵌入表 ---
token_embedding_table = nn.Embedding(vocab_size, d_model).to(device)
token_embedding_table.load_state_dict(loaded_embedding_dict)
print(f" 加載了標記嵌入表,形狀:{token_embedding_table.weight.shape}")# --- Transformer 塊組件 ---
# (實例化層并加載 state_dict,針對 layer_norms_1, mha_qkv_linears 等 - 省略代碼)
layer_norms_1 = []
mha_qkv_linears = []
mha_output_linears = []
layer_norms_2 = []
ffn_linear_1 = []
ffn_linear_2 = []
for i in range(n_layers):# (實例化層,檢查偏置,加載每個組件的狀態字典...)ln1 = nn.LayerNorm(d_model).to(device)ln1.load_state_dict(loaded_ln1_dicts[i])layer_norms_1.append(ln1)# ... 加載 MHA QKV ...qkv_dict = loaded_qkv_dicts[i]has_bias = 'bias' in qkv_dictqkv = nn.Linear(d_model, 3 * d_model, bias=has_bias).to(device)qkv.load_state_dict(qkv_dict)mha_qkv_linears.append(qkv)# ... 加載 MHA 輸出 ...mha_out_dict = loaded_mha_out_dicts[i]has_bias = 'bias' in mha_out_dictmha_out = nn.Linear(d_model, d_model, bias=has_bias).to(device)mha_out.load_state_dict(mha_out_dict)mha_output_linears.append(mha_out)# ... 加載 LN2 ...ln2 = nn.LayerNorm(d_model).to(device)ln2.load_state_dict(loaded_ln2_dicts[i])layer_norms_2.append(ln2)# ... 加載 FFN1 ...ffn1_dict = loaded_ffn1_dicts[i]has_bias = 'bias' in ffn1_dictff1 = nn.Linear(d_model, d_ff, bias=has_bias).to(device)ff1.load_state_dict(ffn1_dict)ffn_linear_1.append(ff1)# ... 加載 FFN2 ...ffn2_dict = loaded_ffn2_dicts[i]has_bias = 'bias' in ffn2_dictff2 = nn.Linear(d_ff, d_model, bias=has_bias).to(device)ff2.load_state_dict(ffn2_dict)ffn_linear_2.append(ff2)print(f" 加載了 {n_layers} 個 Transformer 層的組件。")# --- 最終層歸一化 ---
final_layer_norm = nn.LayerNorm(d_model).to(device)
final_layer_norm.load_state_dict(loaded_final_ln_dict)
print(" 加載了最終層歸一化。")print("完成了文本 Transformer 組件的初始化和權重加載。")
輸出結果
加載的文本 Transformer 組件
加載了標記嵌入表,形狀:torch.Size([42, 64])
加載了 3 個 Transformer 層的組件。
加載了最終層歸一化。
文本處理的骨干網絡已經重新組裝,并且加載了其訓練好的權重。
這是關鍵的改變。我們不再預測下一個文本標記,而是需要預測一個圖像特征向量。我們添加一個新的 Linear 層,將 Transformer 的最終輸出 (d_model=64) 映射到圖像特征維度 (vision_feature_dim=512)。
text_to_image_feature_layer = nn.Linear(d_model, vision_feature_dim).to(device)
輸出結果
初始化了文本到圖像特征輸出層:64 -> 512。設備:cuda
這個新的輸出頭已經準備好被訓練以預測圖像特征。我們需要將我們的文本提示格式化,并將它們與我們之前提取的目標圖像特征配對。
print("\n第 2.1 步:對文本提示進行分詞和填充...")prepared_prompts = []
target_features_ordered = []for sample in text_to_image_data:prompt = sample["prompt"]image_path = sample["image_path"]# --- 對提示進行分詞 ---prompt_ids_no_pad = [char_to_int[ch] for ch in prompt]# --- 填充 ---# (填充邏輯 - 省略代碼)current_len = len(prompt_ids_no_pad)pad_len = block_size - current_lenif pad_len < 0:prompt_ids = prompt_ids_no_pad[:block_size]pad_len = 0current_len = block_sizeelse:prompt_ids = prompt_ids_no_pad + ([pad_token_id] * pad_len)# --- 創建注意力掩碼 ---attention_mask = ([1] * current_len) + ([0] * pad_len)# --- 存儲提示數據 ---prepared_prompts.append({"input_ids": torch.tensor(prompt_ids, dtype=torch.long),"attention_mask": torch.tensor(attention_mask, dtype=torch.long)})# --- 存儲對應的目標特征 ---# (從 target_image_features 中獲取特征 - 省略代碼)if image_path in target_image_features:target_features_ordered.append(target_image_features[image_path])else:# 處理錯誤target_features_ordered.append(torch.zeros(vision_feature_dim, device=device))# --- 將其堆疊為張量 ---
all_prompt_input_ids = torch.stack([p['input_ids'] for p in prepared_prompts])
all_prompt_attention_masks = torch.stack([p['attention_mask'] for p in prepared_prompts])
all_target_features = torch.stack(target_features_ordered)num_sequences_available = all_prompt_input_ids.shape[0]
print(f"創建了 {num_sequences_available} 個填充后的提示序列,并收集了目標特征。")
print(f" 提示輸入 ID 的形狀:{all_prompt_input_ids.shape}")
print(f" 提示注意力掩碼的形狀:{all_prompt_attention_masks.shape}")
print(f" 目標特征的形狀:{all_target_features.shape}")
輸出結果
對文本提示進行分詞和填充…
創建了 7 個填充后的提示序列,并收集了目標特征。
提示輸入 ID 的形狀:torch.Size([7, 64])
提示注意力掩碼的形狀:torch.Size([7, 64])
目標特征的形狀:torch.Size([7, 512])
我們的 7 個文本提示現在變成了填充后的 ID 序列(形狀 [7, 64]),每個提示都有一個對應的 注意力掩碼(也是 [7, 64])和一個目標 圖像特征向量(形狀 [7, 512])。
現在是時候訓練模型,使其能夠將文本描述映射到圖像特征了。
我們將使用 AdamW 優化器,確保它包括新輸出層 (text_to_image_feature_layer) 的參數。損失函數是 均方誤差(MSE),適用于比較預測的 512 維特征向量與目標 512 維特征向量。
# --- 收集可訓練的參數 ---
# (收集文本組件和 text_to_image_feature_layer 的參數 - 省略代碼)
all_trainable_parameters_t2i = list(token_embedding_table.parameters())
for i in range(n_layers):all_trainable_parameters_t2i.extend(list(layer_norms_1[i].parameters()))# ... 擴展其他層的參數 ...
all_trainable_parameters_t2i.extend(list(final_layer_norm.parameters()))
all_trainable_parameters_t2i.extend(list(text_to_image_feature_layer.parameters())) # 新層# --- 定義優化器 ---
optimizer = optim.AdamW(all_trainable_parameters_t2i, lr=learning_rate)
print(f" 定義了優化器:AdamW,學習率={learning_rate}")
print(f" 管理 {len(all_trainable_parameters_t2i)} 個參數組/張量。")# --- 定義損失函數 ---
criterion = nn.MSELoss() # 均方誤差
print(f" 定義了損失函數:{type(criterion).__name__}")
輸出結果
定義的優化器和損失函數
定義了優化器:AdamW,學習率=0.0001
管理 38 個參數組/張量。
定義了損失函數:MSELoss
優化器已經設置好,現在管理著 38 個參數組(因為我們用新的圖像特征輸出層替換了舊的文本輸出層)。
我們迭代地將文本提示輸入模型,并訓練它輸出與目標特征向量接近的特征向量。
- 獲取批次:采樣提示、掩碼和目標特征。
- 前向傳播:將提示通過 Transformer 塊處理。從最終層歸一化的輸出中取出最后一個實際標記的隱藏狀態。將此單個狀態通過
text_to_image_feature_layer以預測圖像特征向量。 - 計算損失:計算預測特征向量與目標特征向量之間的 MSE 損失。
t2i_losses = []
# (將層設置為訓練模式 - 省略代碼)
token_embedding_table.train()
# ... 將其他層設置為訓練模式 ...
final_layer_norm.train()
text_to_image_feature_layer.train() # 訓練新層for epoch in range(epochs):# --- 1. 批次選擇 ---indices = torch.randint(0, num_sequences_available, (batch_size,))xb_prompt_ids = all_prompt_input_ids[indices].to(device)batch_prompt_masks = all_prompt_attention_masks[indices].to(device)yb_target_features = all_target_features[indices].to(device)# --- 2. 前向傳播 ---B, T = xb_prompt_ids.shapeC = d_model# 嵌入 + 位置編碼token_embed = token_embedding_table(xb_prompt_ids)pos_enc_slice = positional_encoding[:, :T, :]x = token_embed + pos_enc_slice# Transformer 塊(使用組合掩碼)# (注意力掩碼計算 - 省略代碼)padding_mask_expanded = batch_prompt_masks.unsqueeze(1).unsqueeze(2)combined_attn_mask = causal_mask[:,:,:T,:T] * padding_mask_expandedfor i in range(n_layers):# (MHA 和 FFN 前向傳播 - 省略代碼)x_input_block = xx_ln1 = layer_norms_1[i](x_input_block)# ... MHA 邏輯 ...attention_weights = F.softmax(attn_scores.masked_fill(combined_attn_mask == 0, float('-inf')), dim=-1)attention_weights = torch.nan_to_num(attention_weights)# ... 完成 MHA ...x = x_input_block + mha_output_linears[i](attn_output) # 殘差 1# ... FFN 邏輯 ...x = x_input_ffn + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x_input_ffn)))) # 殘差 2# 最終層歸一化final_norm_output = final_layer_norm(x)# 選擇最后一個非填充標記的隱藏狀態last_token_indices = torch.sum(batch_prompt_masks, 1) - 1last_token_indices = torch.clamp(last_token_indices, min=0)batch_indices = torch.arange(B, device=device)last_token_hidden_states = final_norm_output[batch_indices, last_token_indices, :]# 投影到圖像特征維度predicted_image_features = text_to_image_feature_layer(last_token_hidden_states) # (B, vision_feature_dim)# --- 3. 計算損失 ---loss = criterion(predicted_image_features, yb_target_features) # MSE 損失# --- 4. 清零梯度 ---optimizer.zero_grad()# --- 5. 反向傳播 ---# (如果損失有效,則進行反向傳播 - 省略代碼)if not torch.isnan(loss) and not torch.isinf(loss):loss.backward()# --- 6. 更新參數 ---optimizer.step()else:loss = None# --- 日志記錄 ---# (記錄損失 - 省略代碼)if loss is not None:current_loss = loss.item()t2i_losses.append(current_loss)if epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 個 epoch,MSE 損失:{current_loss:.6f}")elif epoch % eval_interval == 0 or epoch == epochs - 1:print(f" 第 {epoch+1}/{epochs} 個 epoch,損失:無效 (NaN/Inf)")print("--- 文本到圖像訓練循環完成 ---\n")
輸出結果
開始文本到圖像訓練循環…
第 1/5000 個 epoch,MSE 損失:0.880764
第 501/5000 個 epoch,MSE 損失:0.022411
第 1001/5000 個 epoch,MSE 損失:0.006695
第 1501/5000 個 epoch,MSE 損失:0.000073
第 2001/5000 個 epoch,MSE 損失:0.000015
第 2501/5000 個 epoch,MSE 損失:0.000073
第 3001/5000 個 epoch,MSE 損失:0.000002
第 3501/5000 個 epoch,MSE 損失:0.000011
第 4001/5000 個 epoch,MSE 損失:0.000143
第 4501/5000 個 epoch,MSE 損失:0.000013
第 5000/5000 個 epoch,MSE 損失:0.000030
— 文本到圖像訓練循環完成 —
再次強調,MSE 損失迅速降低,表明模型在快速學習將簡單的文本提示映射到目標圖像的特征向量。接近零的損失表明它幾乎完美地預測了訓練樣本中預期的特征向量。
使用文本提示生成圖像
讓我們看看模型對新的提示 “a blue square shape” 預測的圖像特征向量是什么。
讓我們對測試輸入提示進行分詞和填充。
# --- 輸入提示 ---
generation_prompt_text = "a blue square shape"
print(f"輸入提示:'{generation_prompt_text}'")
# --- 對提示進行分詞和填充 ---
# (分詞和填充邏輯 - 省略代碼)
gen_prompt_ids_no_pad = [char_to_int.get(ch, pad_token_id) for ch in generation_prompt_text]
gen_current_len = len(gen_prompt_ids_no_pad)
gen_pad_len = block_size - gen_current_len
if gen_pad_len < 0:gen_prompt_ids = gen_prompt_ids_no_pad[:block_size]gen_pad_len = 0gen_current_len = block_size
else:gen_prompt_ids = gen_prompt_ids_no_pad + ([pad_token_id] * gen_pad_len)
# --- 創建注意力掩碼 ---
gen_attention_mask = ([1] * gen_current_len) + ([0] * gen_pad_len)
# --- 轉換為張量 ---
xb_gen_prompt_ids = torch.tensor([gen_prompt_ids], dtype=torch.long, device=device)
batch_gen_prompt_masks = torch.tensor([gen_attention_mask], dtype=torch.long, device=device)
print(f"準備好的提示張量形狀:{xb_gen_prompt_ids.shape}")
print(f"準備好的掩碼張量形狀:{batch_gen_prompt_masks.shape}")
輸出結果
輸入提示:‘a blue square shape’
準備好的提示張量形狀:torch.Size([1, 64])
準備好的掩碼張量形狀:torch.Size([1, 64])
提示 “a blue square shape” 已準備好為一個填充后的張量。現在我們對訓練過的文本到圖像模型進行前向傳播。
print("\n第 4.2 步:生成圖像特征向量...")
# --- 將模型設置為評估模式 ---
# (將層設置為評估模式 - 省略代碼)
token_embedding_table.eval()
# ... 將其他層設置為評估模式 ...
final_layer_norm.eval()
text_to_image_feature_layer.eval() # 評估輸出層# --- 前向傳播 ---
with torch.no_grad():# (嵌入、位置編碼、Transformer 塊 - 省略代碼)B_gen, T_gen = xb_gen_prompt_ids.shapeC_gen = d_modeltoken_embed_gen = token_embedding_table(xb_gen_prompt_ids)pos_enc_slice_gen = positional_encoding[:, :T_gen, :]x_gen = token_embed_gen + pos_enc_slice_genpadding_mask_expanded_gen = batch_gen_prompt_masks.unsqueeze(1).unsqueeze(2)combined_attn_mask_gen = causal_mask[:,:,:T_gen,:T_gen] * padding_mask_expanded_genfor i in range(n_layers):# ... MHA 和 FFN 前向傳播 ...x_input_block_gen = x_genx_ln1_gen = layer_norms_1[i](x_input_block_gen)# ... MHA 邏輯 ...x_gen = x_input_block_gen + mha_output_linears[i](attn_output_gen)# ... FFN 邏輯 ...x_gen = x_input_ffn_gen + ffn_linear_2[i](F.relu(ffn_linear_1[i](layer_norms_2[i](x_input_ffn_gen))))# 最終層歸一化final_norm_output_gen = final_layer_norm(x_gen)# 選擇隱藏狀態last_token_indices_gen = torch.sum(batch_gen_prompt_masks, 1) - 1last_token_indices_gen = torch.clamp(last_token_indices_gen, min=0)batch_indices_gen = torch.arange(B_gen, device=device)last_token_hidden_states_gen = final_norm_output_gen[batch_indices_gen, last_token_indices_gen, :]# 投影到圖像特征維度predicted_feature_vector = text_to_image_feature_layer(last_token_hidden_states_gen)print(f"生成了預測的特征向量,形狀:{predicted_feature_vector.shape}")
輸出結果
生成圖像特征向量…
生成了預測的特征向量,形狀:torch.Size([1, 512])
模型處理了提示,并輸出了一個形狀為 512 的向量,表示對 “a blue square shape” 的圖像特征預測。
現在我們預測的圖像來自我們的文本提示:

生成的圖像
成功了!模型預測了一個特征向量用于 “a blue square shape”,并且當我們比較這個預測與我們已知圖像的特征時,最接近的匹配項確實是藍色正方形。
歐幾里得距離(4.84)表明預測的向量與實際藍色正方形的特征向量有多相似。
出用fareedkhandev

,源碼可白嫖!)












 和模擬網格體 是如何關聯的?為什么模擬網格體 可以驅動渲染網格體?)


)

Chatbox多端一鍵配置Claude/GPT/DeepSeek-網頁端配置)