FFN Fusion: Rethinking Sequential Computation in Large Language Models
代表模型:Llama-3.1-Nemotron-Ultra-253B-v1
1. 摘要
本文介紹了一種名為 FFN Fusion 的架構優化技術,旨在通過識別和利用自然并行化機會來減少大型語言模型(LLMs)中的順序計算。研究發現,移除特定注意力層后剩余的前饋網絡(FFN)層序列通常可以并行化,且對準確性影響最小。通過將這些序列轉換為并行操作,顯著降低了推理延遲,同時保留了模型行為。作者將這種技術應用于 Llama-3.1-405B-Instruct,創建了一個名為 Llama-Nemotron-Ultra-253B-Base 的高效模型,該模型在推理延遲上實現了 1.71 倍的速度提升,每令牌成本降低了 35 倍,同時在多個基準測試中保持了強大的性能。
2. 引言
大型語言模型(LLMs)已成為變革性技術,但其計算需求已成為部署成本和資源需求的根本瓶頸。現有的優化技術如量化、剪枝和專家混合(MoE)各自面臨挑戰。本文提出 FFN Fusion,通過識別 FFN 層中的計算獨立性模式,實現多 GPU 上的并行執行,提高硬件利用率。
3. 預備知識
Transformer 基礎
LLMs 通常基于 Transformer 架構,由一系列順序塊組成,每個塊包含注意力層和 FFN 層。FFN 層使用 SwiGLU 模塊,定義為: 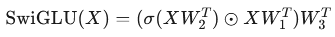
其中,σ 是 SiLU 激活函數,
Puzzle 框架
Puzzle 是一種神經架構搜索(NAS)框架,通過剪枝或重新配置每個 Transformer 塊來優化訓練后的 LLM 的推理效率。Puzzle 通常會移除許多注意力層,留下連續的 FFN 層序列。
4. FFN Fusion 方法
關鍵洞察
FFN Fusion 的核心思想是,移除注意力層后,連續的 FFN 層序列可以被并行化。具體來說,多個順序 FFN 層可以融合成一個更寬的層,從而實現簡單的并行執行。
理論基礎
定理 3.1 表明,多個 FFN 函數的和等價于一個單一的 FFN 函數,其權重矩陣是原始 FFN 權重矩陣的拼接。這使得多個 FFN 層可以融合為一個更寬的層。
效率動機與分析
LLMs 的設計通常是順序塊,隨著模型規模的增大,塊的大小和數量增加。通過減少計算圖的深度,可以減少同步時間,提高硬件利用率。
塊依賴分析
通過計算塊之間的依賴關系,識別出適合并行化的 FFN 序列。依賴矩陣 M 的構造基于塊 j 在移除塊 i 后的貢獻變化,量化塊之間的依賴關系。
5. 大規模模型的 FFN Fusion 應用
從 Llama-405B 到 Ultra-253B-Base
通過 Puzzle 搜索結果,作者從 Llama-405B 派生出一個 253B 參數的基線模型,該模型移除了許多注意力層,留下 50 個連續的 FFN 層塊。應用 FFN Fusion 后,這些層被融合為更少的層,顯著減少了模型深度。
額外訓練
為了恢復性能,作者使用知識蒸餾(KD)對融合后的模型進行微調。結果顯示,融合后的模型在 MMLU 和 MT-Bench 等基準測試中的性能得到了恢復甚至提升。
效率提升
Ultra-253B-Base 在推理延遲上實現了 1.71 倍的速度提升,每令牌成本降低了 35 倍,同時在多個基準測試中匹配或超過了原始 Llama-405B 的性能。
6. 額外的實驗研究
FFN Fusion 在 70B 規模模型中的應用
作者在 Llama-3.1-70B-Instruct 的派生模型上應用 FFN Fusion,結果表明,隨著融合強度的增加,模型深度減少,準確性略有下降,但通過知識蒸餾可以恢復性能。
移除 FFN 層與 FFN Fusion 的比較
與直接移除 FFN 層相比,FFN Fusion 在保持模型質量方面具有明顯優勢。移除 FFN 層會導致顯著的準確性下降,而融合則通過保留所有參數在一個并行模塊中,最小化了性能損失。
FFN 序列中最后一層的敏感性
實驗表明,融合 FFN 序列中的最后一層往往會導致更大的準確性下降,因此通常選擇跳過這些層以實現高效的融合。
融合可解釋性
通過分析層輸入和輸出之間的關系,作者解釋了 FFN Fusion 的可行性,并指出融合區域的層間依賴性較低,使得融合對模型行為的影響較小。
7. 塊并行化
方法
作者擴展了塊依賴分析,識別出適合并行化的完整 Transformer 塊序列。通過貪心算法選擇依賴性較低的塊序列進行并行化。
結果
實驗結果表明,完整塊并行化比 FFN Fusion 更具挑戰性,因為完整塊之間的依賴性更強。盡管如此,某些塊序列仍然可以并行化,從而提高推理吞吐量。
8. 結論
FFN Fusion 是一種有效的優化技術,可以顯著減少 LLMs 的順序計算,提高推理效率。通過在不同規模的模型上進行廣泛實驗,作者證明了 FFN Fusion 的有效性,并指出了未來研究方向,包括模型可解釋性、新架構設計和擴展到 MoE 模型等。
整理
技術關系圖:

核心技術表
| 技術名稱 | 描述 | 優勢 | 應用場景 |
|---|---|---|---|
| FFN Fusion | 通過識別 FFN 層中的計算獨立性模式,將多個順序 FFN 層融合為一個更寬的層,實現并行化。 | 顯著降低推理延遲,減少模型深度,提高硬件利用率,保持模型性能。 | 優化大型語言模型(LLMs),特別是在移除注意力層后的 FFN 序列。 |
| Puzzle 框架 | 一種神經架構搜索(NAS)方法,用于優化推理效率,通過剪枝或重新配置 Transformer 塊。 | 移除冗余的注意力層,生成適合 FFN Fusion 的模型結構。 | 作為 FFN Fusion 的前置步驟,優化模型架構。 |
| 注意力剪枝 | 移除模型中的注意力層,減少模型深度,生成連續的 FFN 層序列。 | 降低計算復雜度,提高硬件利用率,為 FFN Fusion 提供基礎。 | 為 FFN Fusion 提供連續的 FFN 層序列。 |
| 塊依賴分析 | 通過量化塊之間的依賴關系,識別適合并行化的區域。 | 提供模型中適合并行化的區域的可視化和量化依據。 | 模型架構優化,識別適合 FFN Fusion 或完整塊并行化的區域。 |
| 知識蒸餾(KD) | 使用知識蒸餾從原始模型中恢復或提升融合后的模型性能。 | 提高模型準確性,尤其是在融合或剪枝后。 | 模型微調,特別是在應用 FFN Fusion 后恢復性能。 |
| 完整塊并行化 | 嘗試將完整的 Transformer 塊(包含注意力和 FFN)并行化。 | 進一步提高推理吞吐量,特別是在大規模模型部署中。 | 大規模模型部署,探索更高的并行化潛力。 |










)
)







)