🧑 博主簡介:CSDN博客專家,歷代文學網(PC端可以訪問:https://literature.sinhy.com/#/literature?__c=1000,移動端可微信小程序搜索“歷代文學”)總架構師,
15年工作經驗,精通Java編程,高并發設計,Springboot和微服務,熟悉Linux,ESXI虛擬化以及云原生Docker和K8s,熱衷于探索科技的邊界,并將理論知識轉化為實際應用。保持對新技術的好奇心,樂于分享所學,希望通過我的實踐經歷和見解,啟發他人的創新思維。在這里,我希望能與志同道合的朋友交流探討,共同進步,一起在技術的世界里不斷學習成長。
技術合作請加本人wx(注明來自csdn):foreast_sea


操作系統之文件系統
- 操作系統之文件系統
- 文件
- 文件命名
- 文件結構
- 文件類型
- 文件訪問
- 文件屬性
- 文件操作
- 目錄
- 一級目錄系統
- 層次目錄系統
- 路徑名
- 目錄操作
- 文件系統的實現
- 文件系統布局
- 引導塊
- 超級塊
- 空閑空間塊
- 碎片
- inode
- 文件的實現
- 連續分配
- 鏈表分配
- 使用內存表進行鏈表分配
- inode
- 目錄的實現
- 共享文件
- 日志結構文件系統
- 日志文件系統
- 虛擬文件系統
- 文件系統布局
- 文件系統的管理和優化
- 磁盤空間管理
- 塊大小
- 記錄空閑塊
- 磁盤配額
- 文件系統備份
- 物理轉儲和邏輯轉儲
- 文件系統的一致性
- 文件系統性能
- 高速緩存
- 塊提前讀
- 減少磁盤臂運動
- 磁盤碎片整理
- 磁盤空間管理
- 文件
所有的應用程序都需要存儲和檢索信息。進程運行時,它能夠在自己的存儲空間內存儲一定量的信息。然而,存儲容量受虛擬地址空間大小的限制。對于一些應用程序來說,存儲空間的大小是充足的,但是對于其他一些應用程序,比如航空訂票系統、銀行系統、企業記賬系統來說,這些容量又顯得太小了。
第二個問題是,當進程終止時信息會丟失。對于一些應用程序(例如數據庫),信息會長久保留。在這些進程終止時,相關的信息應該保留下來,是不能丟失的。甚至這些應用程序崩潰后,信息也應該保留下來。
第三個問題是,通常需要很多進程在同一時刻訪問這些信息。解決這種問題的方式是把這些信息單獨保留在各自的進程中。
因此,對于長久存儲的信息我們有三個基本需求:
-
必須要有可能存儲的大量的信息
- 信息必須能夠在進程終止時保留
-
必須能夠使多個進程同時訪問有關信息
磁盤(Magnetic disk) 一直是用來長久保存信息的設備。近些年來,固態硬盤逐漸流行起來。

固態硬盤不僅沒有易損壞的移動部件,而且能夠提供快速的隨機訪問。相比而言,雖然磁帶和光盤也被廣泛使用,但是它們的性能相對較差,通常應用于備份。我們會在后面探討磁盤,現在姑且把磁盤當作一種大小固定塊的線性序列好了,并且支持如下操作
- 讀塊 k
- 寫塊 k

事實上磁盤支持更多的操作,但是只要有了讀寫操作,原則上就能夠解決長期存儲的問題。
然而,磁盤還有一些不便于實現的操作,特別是在有很多程序或者多用戶使用的大型系統上(如服務器)。在這種情況下,很容易產生一些問題,例如
-
你如何找到這些信息?
-
你如何保證一個用戶不會讀取另外一個用戶的數據?
-
你怎么知道哪些塊是空閑的?等等問題
我們可以針對這些問題提出一個新的抽象 - 文件。進程和線程的抽象、地址空間和文件都是操作系統的重要概念。如果你能真正深入了解這三個概念,那么你就走上了成為操作系統專家的道路。
文件(Files)是由進程創建的邏輯信息單元。一個磁盤會包含幾千甚至幾百萬個文件,每個文件是獨立于其他文件的。事實上,如果你能把每個文件都看作一個獨立的地址空間,那么你就可以真正理解文件的概念了。
進程能夠讀取已經存在的文件,并在需要時重新創建他們。存儲在文件中的信息必須是持久的,這也就是說,不會因為進程的創建和終止而受影響。一個文件只能在當用戶明確刪除的時候才能消失。盡管讀取和寫入都是最基本的操作,但還有許多其他操作,我們將在下面介紹其中的一些。
文件由操作系統進行管理,有關文件的構造、命名、訪問、使用、保護、實現和管理方式都是操作系統設計的主要內容。從總體上看,操作系統中處理文件的部分稱為 文件系統(file system),這就是我們所討論的。
從用戶角度來說,用戶通常會關心文件是由什么組成的,如何給文件進行命名,如何保護文件,以及可以對文件進行哪些操作等等。盡管是用鏈表還是用位圖記錄內存空閑區并不是用戶所關心的主題,而這些對系統設計人員來說至關重要。下面我們就來探討一下這些主題
文件
文件命名
文件是一種抽象機制,它提供了一種方式用來存儲信息以及在后面進行讀取。可能任何一種機制最重要的特性就是管理對象的命名方式。在創建一個文件后,它會給文件一個命名。當進程終止時,文件會繼續存在,并且其他進程可以使用名稱訪問該文件。
文件命名規則對于不同的操作系統來說是不一樣的,但是所有現代操作系統都允許使用 1 - 8 個字母的字符串作為合法文件名。
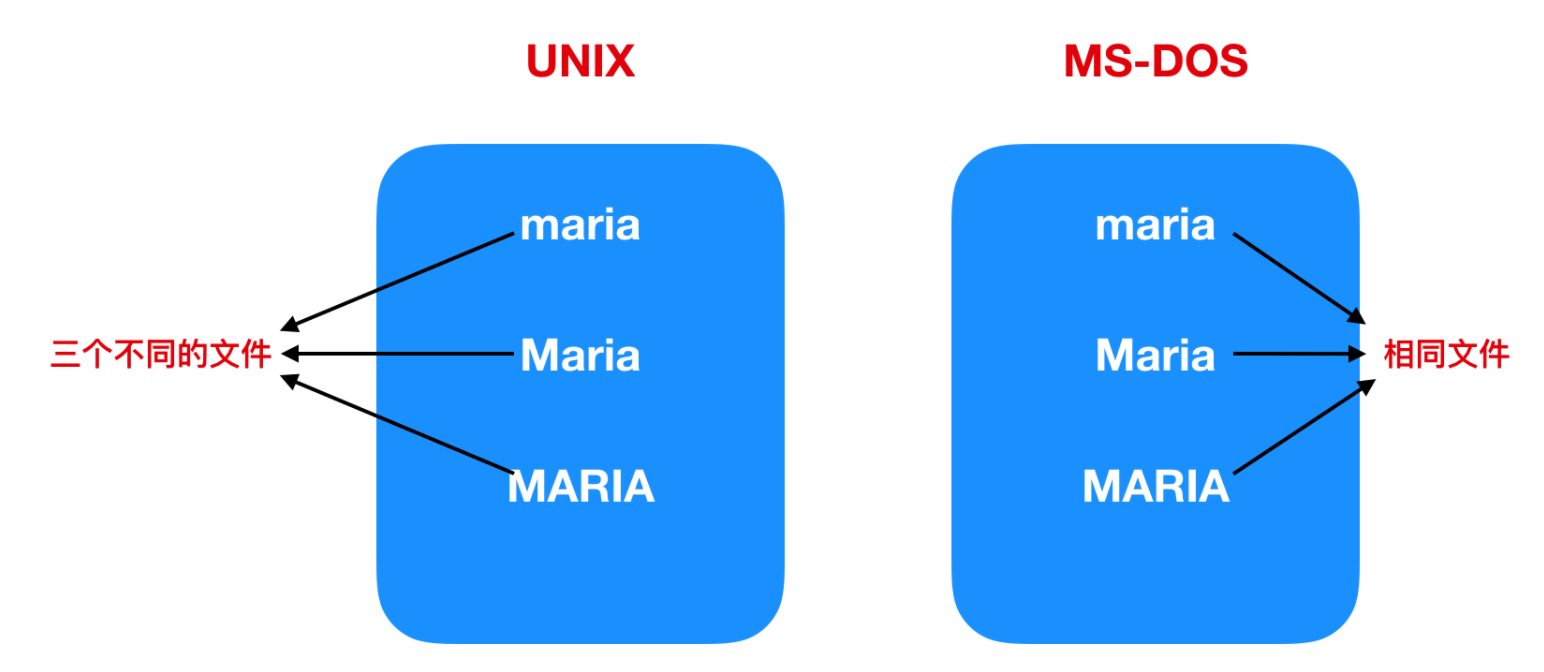
某些文件區分大小寫字母,而大多數則不區分。UNIX 屬于第一類;歷史悠久的 MS-DOS 屬于第二類(順便說一句,盡管 MS-DOS 歷史悠久,但 MS-DOS 仍在嵌入式系統中非常廣泛地使用,因此它絕不是過時的);因此,UNIX 系統會有三種不同的命名文件:maria、Maria、MARIA 。在 MS-DOS ,所有這些命名都屬于相同的文件。
這里可能需要在文件系統上預留一個位置。Windows 95 和 Windows 98 都使用了 MS-DOS 文件系統,叫做 FAT-16,因此繼承了它的一些特征,例如有關文件名的構造方法。Windows 98 引入了對 FAT-16 的一些擴展,從而導致了 FAT-32 的生成,但是這兩者很相似。另外,Windows NT,Windows 2000,Windows XP,Windows Vista,Windows 7 和 Windows 8 都支持 FAT 文件系統,這種文件系統有些過時。然而,這些較新的操作系統還具有更高級的本機文件系統(NTFS),有不同的特性,那就是基于 Unicode 編碼的文件名。事實上,Windows 8 還配備了另一種文件系統,簡稱 ReFS(Resilient File System),但這個文件系統一般應用于 Windows 8 的服務器版本。下面除非我們特殊聲明,否則我們在提到 MS-DOS 和 FAT 文件系統的時候,所指的就是 Windows 的 FAT-16 和 FAT-32。這里要說一下,有一種類似 FAT 的新型文件系統,叫做 exFAT。它是微軟公司對閃存和大文件系統開發的一種優化的 FAT 32 擴展版本。ExFAT 是現在微軟唯一能夠滿足 OS X讀寫操作的文件系統。
許多操作系統支持兩部分的文件名,它們之間用 . 分隔開,比如文件名 prog.c。原點后面的文件稱為 文件擴展名(file extension) ,文件擴展名通常表示文件的一些信息。例如在 MS-DOS 中,文件名是 1 - 8 個字符,加上 1 - 3 個字符的可選擴展名組成。在 UNIX 中,如果有擴展名,那么擴展名的長度將由用戶來決定,一個文件甚至可以包括兩個或更多的擴展名,例如 homepage.html.zip,html 表示一個 web 網頁而 .zip 表示文件homepage.html 已經采用 zip 程序壓縮完成。一些常用的文件擴展名以及含義如下圖所示
| 擴展名 | 含義 |
|---|---|
| bak | 備份文件 |
| c | c 源程序文件 |
| gif | 符合圖形交換格式的圖像文件 |
| hlp | 幫助文件 |
| html | WWW 超文本標記語言文檔 |
| jpg | 符合 JPEG 編碼標準的靜態圖片 |
| mp3 | 符合 MP3 音頻編碼格式的音樂文件 |
| mpg | 符合 MPEG 編碼標準的電影 |
| o | 目標文件(編譯器輸出格式,尚未鏈接) |
| pdf 格式的文件 | |
| ps | PostScript 文件 |
| tex | 為 TEX 格式化程序準備的輸入文件 |
| txt | 文本文件 |
| zip | 壓縮文件 |
在 UNIX 系統中,文件擴展名只是一種約定,操作系統并不強制采用。
名為 file.txt 的文件是文本文件,這個文件名更多的是提醒所有者,而不是給計算機傳遞信息。但是另一方面,C 編譯器可能要求它編譯的文件以.c 結尾,否則它會拒絕編譯。然而,操作系統并不關心這一點。
對于可以處理多種類型的程序,約定就顯得及其有用。例如 C 編譯器可以編譯、鏈接多種文件,包括 C 文件和匯編語言文件。這時擴展名就很有必要,編譯器利用它們區分哪些是 C 文件,哪些是匯編文件,哪些是其他文件。因此,擴展名對于編譯器判斷哪些是 C 文件,哪些是匯編文件以及哪些是其他文件變得至關重要。
與 UNIX 相反,Windows 就會關注擴展名并對擴展名賦予了新的含義。用戶(或進程) 可以在操作系統中注冊擴展名,并且規定哪個程序能夠擁有擴展名。當用戶雙擊某個文件名時,擁有該文件名的程序就啟動并運行文件。例如,雙擊 file.docx 啟動了 Word 程序,并以 file.docx 作為初始文件。
文件結構
文件的構造有多種方式。下圖列出了常用的三種構造方式

上圖中的 a 是一種無結構的字節序列,操作系統不關心序列的內容是什么,操作系統能看到的就是字節(bytes)。其文件內容的任何含義只在用戶程序中進行解釋。UNIX 和 Windows 都采用這種辦法。
把文件看成字節序列提供了最大的靈活性。用戶程序可以向文件中寫任何內容,并且可以通過任何方便的形式命名。操作系統不會為為用戶寫入內容提供幫助,當然也不會干擾阻塞你。對于想做特殊操作的用戶來說,后者是十分重要的。所有的 UNIX 版本(包括 Linux 和 OS X)和 Windows 都使用這種文件模型。
圖 b 表示在文件結構上的第一部改進。在這個模型中,文件是具有固定長度記錄的序列,每個記錄都有其內部結構。 把文件作為記錄序列的核心思想是:讀操作返回一個記錄,而寫操作重寫或者追加一個記錄。第三種文件結構如上圖 c 所示。在這種組織結構中,文件由一顆記錄樹構成,記錄樹的長度不一定相同,每個記錄樹都在記錄中的固定位置包含一個key 字段。這棵樹按 key 進行排序,從而可以對特定的 key 進行快速查找。
在記錄樹的結構中,可以取出下一個記錄,但是最關鍵的還是根據 key 搜索指定的記錄。如上圖 c 所示,用戶可以讀出指定的 pony 記錄,而不必關心記錄在文件中的確切位置。用戶也可以在文件中添加新的記錄。但是用戶不能決定添加到何處位置,添加到何處位置是由操作系統決定的。
文件類型
很多操作系統支持多種文件類型。例如,UNIX(同樣包括 OS X)和 Windows 都具有常規的文件和目錄。除此之外,UNIX 還具有字符特殊文件(character special file) 和 塊特殊文件(block special file)。常規文件(Regular files) 是包含有用戶信息的文件。用戶一般使用的文件大都是常規文件,常規文件一般包括 可執行文件、文本文件、圖像文件,從常規文件讀取數據或將數據寫入時,內核會根據文件系統的規則執行操作,是寫入可能被延遲,記錄日志或者接受其他操作。
字符特殊文件和輸入/輸出有關,用于串行 I/O 類設備,如終端、打印機、網絡等。塊特殊文件用于磁盤類設備。我們主要討論的是常規文件。
常規文件一般分為 ASCII 碼文件或者二進制文件。ASCII 碼文件由文本組成。在一些系統中,每行都會用回車符結束(ASCII碼是13,控制字符 CR,轉義字符\r。),另外一些則會使用換行符(ASCII碼是10,控制字符LF,轉義字符\n)。一些系統(比如 Windows)兩者都會使用。
ASCII 文件的優點在于顯示 和 打印,還可以用任何文本編輯器進行編輯。進一步來說,如果許多應用程序使用 ASCII 碼作為輸入和輸出,那么很容易就能夠把多個程序連接起來,一個程序的輸出可能是另一個程序的輸入,就像管道一樣。

其他與 ASCII 不同的是二進制文件。打印出來的二進制文件是無法理解的。下面是一個二進制文件的格式,它取自早期的 UNIX 。盡管從技術上來看這個文件只是字節序列,但是操作系統只有在文件格式正確的情況下才會執行。
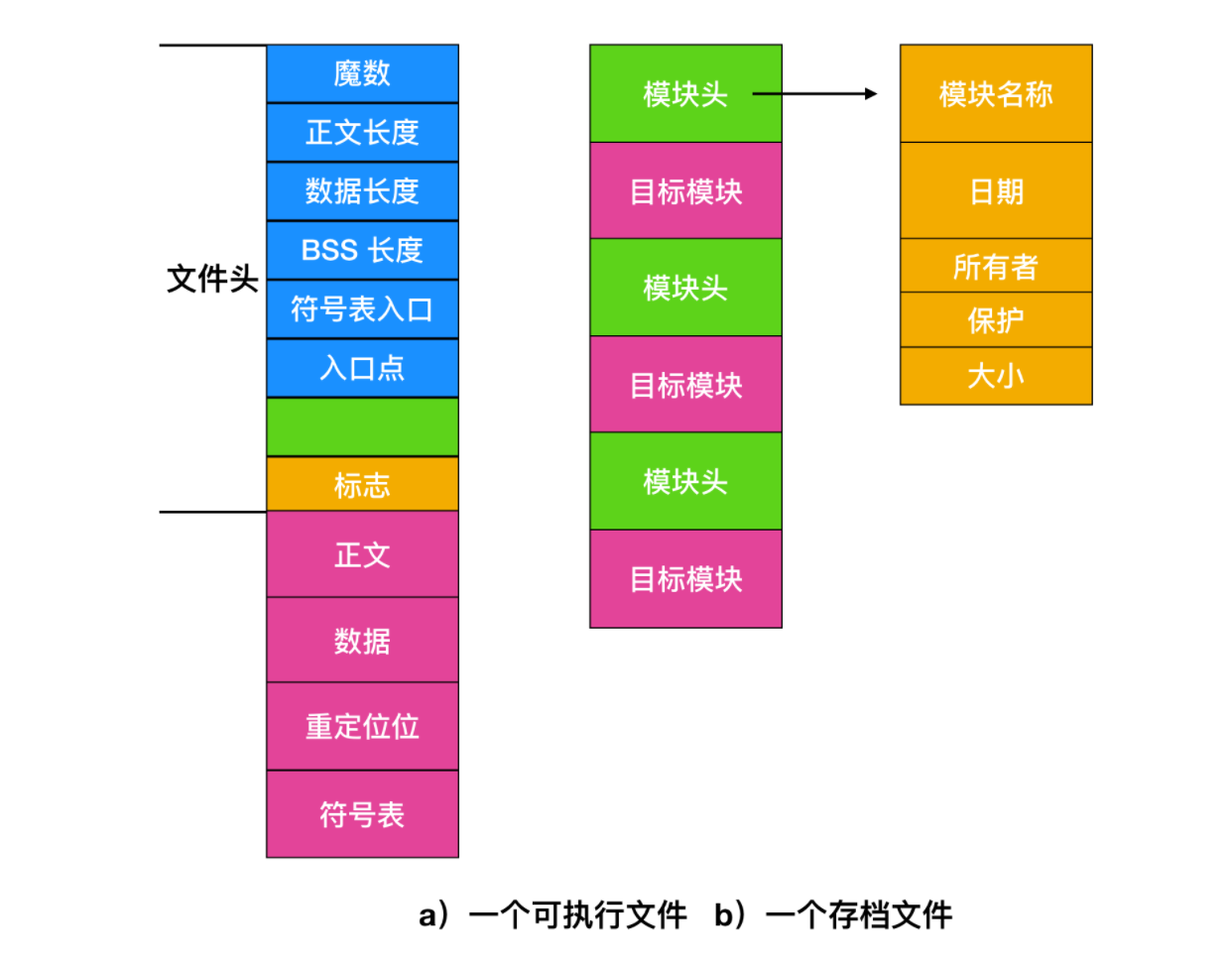
這個文件有五個段:文件頭、征文、數據、重定位位和符號表。文件頭以 魔數(magic number) 為開始,表明這個文件是一個可執行文件(以防止意外執行非此格式的文件)。然后是文件各個部分的大小,開始執行的標志以及一些標志位。程序本身的正文和數據在文件頭后面,他們被加載到內存中或者重定位會根據重定位位進行判斷。符號表則用于調試。
二進制文件的另外一種形式是存檔文件,它由已編譯但沒有鏈接的庫過程(模塊)組合而成。每個文件都以模塊頭開始,其中記錄了名稱、創建日期、所有者、保護碼和文件大小。和可執行文件一樣,模塊頭也都是二進制數,將它們復制到打印機將會產生亂碼。
所有的操作系統必須至少能夠識別一種文件類型:它自己的可執行文件。以前的 TOPS-20 系統(用于DECsystem 20)甚至要檢查要執行的任何文件的創建時間,為了定位資源文件來檢查自動文件創建后是否被修改過。如果被修改過了,那么就會自動編譯文件。在 UNIX 中,就是在 shell 中嵌入 make 程序。此時操作系統要求用戶必須采用固定的文件擴展名,從而確定哪個源程序生成哪個二進制文件。
什么是 make 程序?在軟件發展過程中,make 程序是一個自動編譯的工具,它通過讀取稱為
Makefiles的文件來自動從源代碼構建可執行程序和庫,該文件指定了如何導出目標程序。盡管集成開發環境和特定于語言的編譯器功能也可以用于管理構建過程,但 Make 仍被廣泛使用,尤其是在 Unix 和類似 Unix 的操作系統中使用。
當程序從文件中讀寫數據時,請求會轉到內核處理程序(kernel driver)。如果文件是常規文件,則數據由文件系統驅動程序處理,并且通常存儲在磁盤或其他存儲介質上的某塊區域中,從文件中讀取的數據就是之前在該位置寫入的數據。
當數據讀取或寫入到設備文件時,請求會被設備驅動程序處理。每個設備文件都有一個關聯的編號,該編號標示要使用的設備驅動程序。設備處理數據的工作是它自己的事兒。
塊設備也叫做塊特殊文件,它的行為通常與普通文件相似:它們是字節數組,并且在給定位置讀取的值是最后寫入該位置的值。來自塊設備的數據可以緩存在內存中,并從緩存中讀取;寫入可以被緩沖。塊設備通常是可搜索的,塊設備的概念是,相應的硬件可以一次讀取或者寫入整個塊,例如磁盤上的一個扇區字符設備也稱為字符特殊文件,它的行為類似于管道、串行端口。將字節寫入字符設備可能會導致它在屏幕上顯示,在串行端口上輸出,轉換為聲音。
目錄(Directories) 是管理文件系統結構的系統文件。它是用于在計算機上存儲文件的位置。目錄位于分層文件系統中,例如 Linux,MS-DOS 和 UNIX。
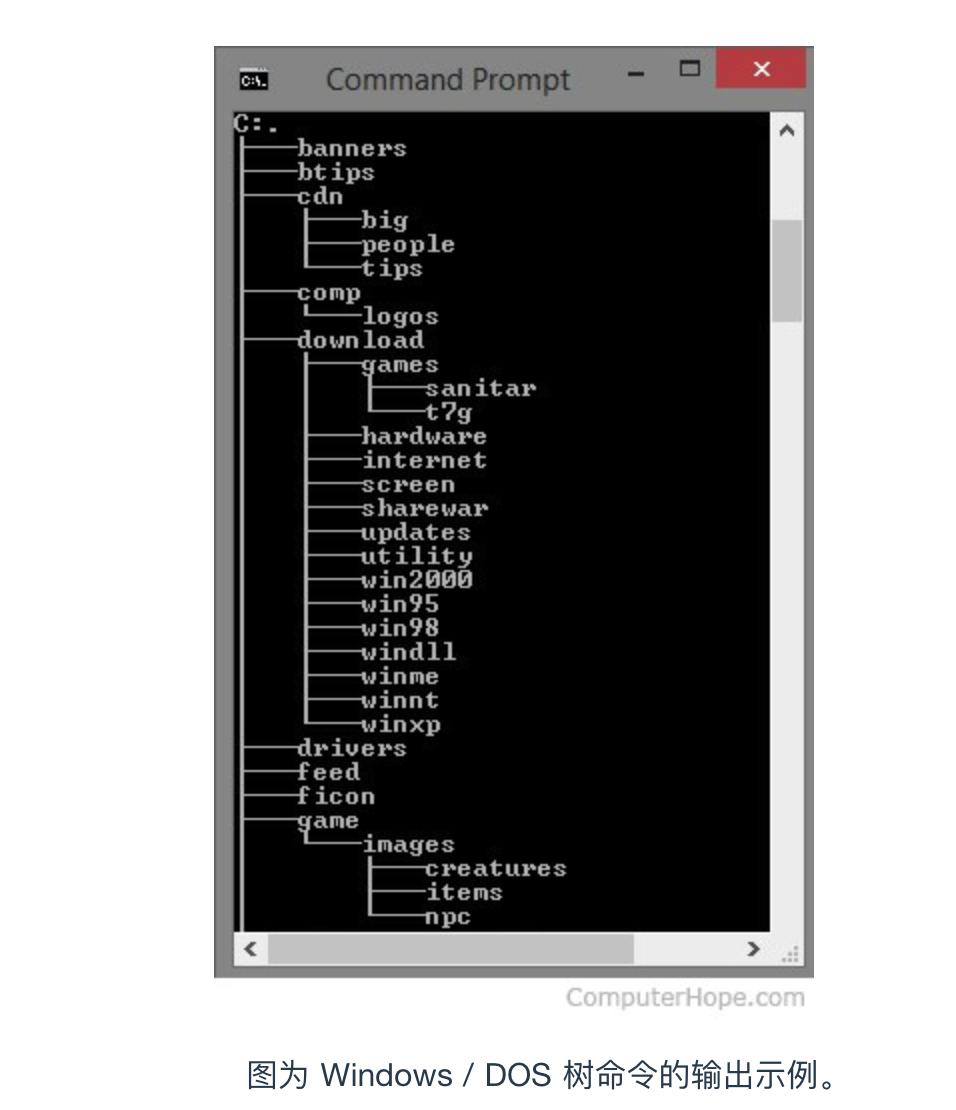
它顯示所有本地和子目錄(例如,cdn 目錄中的 big 目錄)。當前目錄是 C 盤驅動器的根目錄。之所以稱為根目錄,是因為該目錄下沒有任何內容,而其他目錄都在該目錄下分支。
文件訪問
早期的操作系統只有一種訪問方式:序列訪問(sequential access)。在這些系統中,進程可以按照順序讀取所有的字節或文件中的記錄,但是不能跳過并亂序執行它們。順序訪問文件是可以返回到起點的,需要時可以多次讀取該文件。當存儲介質是磁帶而不是磁盤時,順序訪問文件很方便。
在使用磁盤來存儲文件時,可以不按照順序讀取文件中的字節或者記錄,或者按照關鍵字而不是位置來訪問記錄。這種能夠以任意次序進行讀取的稱為隨機訪問文件(random access file)。許多應用程序都需要這種方式。
隨機訪問文件對許多應用程序來說都必不可少,例如,數據庫系統。如果乘客打電話預定某航班機票,訂票程序必須能夠直接訪問航班記錄,而不必先讀取其他航班的成千上萬條記錄。
有兩種方法可以指示從何處開始讀取文件。第一種方法是直接使用 read 從頭開始讀取。另一種是用一個特殊的 seek 操作設置當前位置,在 seek 操作后,從這個當前位置順序地開始讀文件。UNIX 和 Windows 使用的是后面一種方式。
文件屬性
文件包括文件名和數據。除此之外,所有的操作系統還會保存其他與文件相關的信息,如文件創建的日期和時間、文件大小。我們可以稱這些為文件的屬性(attributes)。有些人也喜歡把它們稱作 元數據(metadata)。文件的屬性在不同的系統中差別很大。文件的屬性只有兩種狀態:設置(set) 和 清除(clear)。下面是一些常用的屬性
| 屬性 | 含義 |
|---|---|
| 保護 | 誰可以訪問文件、以什么方式存取文件 |
| 密碼(口令) | 訪問文件所需要的密碼(口令) |
| 創建者 | 創建文件者的 ID |
| 所有者 | 當前所有者 |
| 只讀標志 | 0 表示讀/寫,1 表示只讀 |
| 隱藏標志 | 0 表示正常,1 表示不再列表中顯示 |
| 系統標志 | 0 表示普通文件,1 表示系統文件 |
| 存檔標志 | 0 表示已經備份,1 表示需要備份 |
| ASCII / 二進制標志 | 0 表示 ASCII 文件,1 表示二進制文件 |
| 隨機訪問標志 | 0 表示只允許順序訪問,1 表示隨機訪問 |
| 臨時標志 | 0 表示正常,1 表示進程退出時刪除該文件 |
| 加鎖標志 | 0 表示未加鎖,1 表示加鎖 |
| 記錄長度 | 一個記錄中的字節數 |
| 鍵的位置 | 每個記錄中的鍵的偏移量 |
| 鍵的長度 | 鍵字段的字節數 |
| 創建時間 | 創建文件的日期和時間 |
| 最后一次存取時間 | 上一次訪問文件的日期和時間 |
| 最后一次修改時間 | 上一次修改文件的日期和時間 |
| 當前大小 | 文件的字節數 |
| 最大長度 | 文件可能增長到的字節數 |
沒有一個系統能夠同時具有上面所有的屬性,但每個屬性都在某個系統中采用。
前面四個屬性(保護,口令,創建者,所有者)與文件保護有關,它們指出了誰可以訪問這個文件,誰不能訪問這個文件。
保護(File Protection): 用于保護計算機上有價值數據的方法。文件保護是通過密碼保護文件或者僅僅向特定用戶或組提供權限來實現。
在一些系統中,用戶必須給出口令才能訪問文件。標志(flags)是一些位或者短屬性能夠控制或者允許特定屬性。
隱藏文件位(hidden flag)表示該文件不在文件列表中出現。存檔標志位(archive flag)用于記錄文件是否備份過,由備份程序清除該標志位;若文件被修改,操作系統則設置該標志位。用這種方法,備份程序可以知道哪些文件需要備份。臨時標志位(temporary flag)允許文件被標記為是否允許自動刪除當進程終止時。
記錄長度(record-length)、鍵的位置(key-position)和鍵的長度(key-length)等字段只能出現在用關鍵字查找記錄的文件中。它們提供了查找關鍵字所需要的信息。
不同的時間字段記錄了文件的創建時間、最近一次訪問時間以及最后一次修改時間,它們的作用不同。例如,目標文件生成后被修改的源文件需要重新編譯生成目標文件。這些字段提供了必要的信息。
當前大小字段指出了當前的文件大小,一些舊的大型機操作系統要求在創建文件時指定文件呢最大值,以便讓操作系統提前保留最大存儲值。但是一些服務器和個人計算機卻不用設置此功能。
文件操作
使用文件的目的是用來存儲信息并方便以后的檢索。對于存儲和檢索,不同的系統提供了不同的操作。以下是與文件有關的最常用的一些系統調用:
Create,創建不包含任何數據的文件。調用的目的是表示文件即將建立,并對文件設置一些屬性。Delete,當文件不再需要,必須刪除它以釋放內存空間。為此總會有一個系統調用來刪除文件。Open,在使用文件之前,必須先打開文件。這個調用的目的是允許系統將屬性和磁盤地址列表保存到主存中,用來以后的快速訪問。Close,當所有進程完成時,屬性和磁盤地址不再需要,因此應關閉文件以釋放表空間。很多系統限制進程打開文件的個數,以此達到鼓勵用戶關閉不再使用的文件。磁盤以塊為單位寫入,關閉文件時會強制寫入最后一塊,即使這個塊空間內部還不滿。Read,數據從文件中讀取。通常情況下,讀取的數據來自文件的當前位置。調用者必須指定需要讀取多少數據,并且提供存放這些數據的緩沖區。Write,向文件寫數據,寫操作一般也是從文件的當前位置開始進行。如果當前位置是文件的末尾,則會直接追加進行寫入。如果當前位置在文件中,則現有數據被覆蓋,并且永遠消失。append,使用 append 只能向文件末尾添加數據。seek,對于隨機訪問的文件,要指定從何處開始獲取數據。通常的方法是用 seek 系統調用把當前位置指針指向文件中的特定位置。seek 調用結束后,就可以從指定位置開始讀寫數據了。get attributes,進程運行時通常需要讀取文件屬性。set attributes,用戶可以自己設置一些文件屬性,甚至是在文件創建之后,實現該功能的是 set attributes 系統調用。rename,用戶可以自己更改已有文件的名字,rename 系統調用用于這一目的。
目錄
文件系統通常提供目錄(directories) 或者 文件夾(folders) 用于記錄文件的位置,在很多系統中目錄本身也是文件,下面我們會討論關于文件,他們的組織形式、屬性和可以對文件進行的操作。
一級目錄系統
目錄系統最簡單的形式是有一個能夠包含所有文件的目錄。這種目錄被稱為根目錄(root directory),由于根目錄的唯一性,所以其名稱并不重要。在最早期的個人計算機中,這種系統很常見,部分原因是因為只有一個用戶。下面是一個單層目錄系統的例子
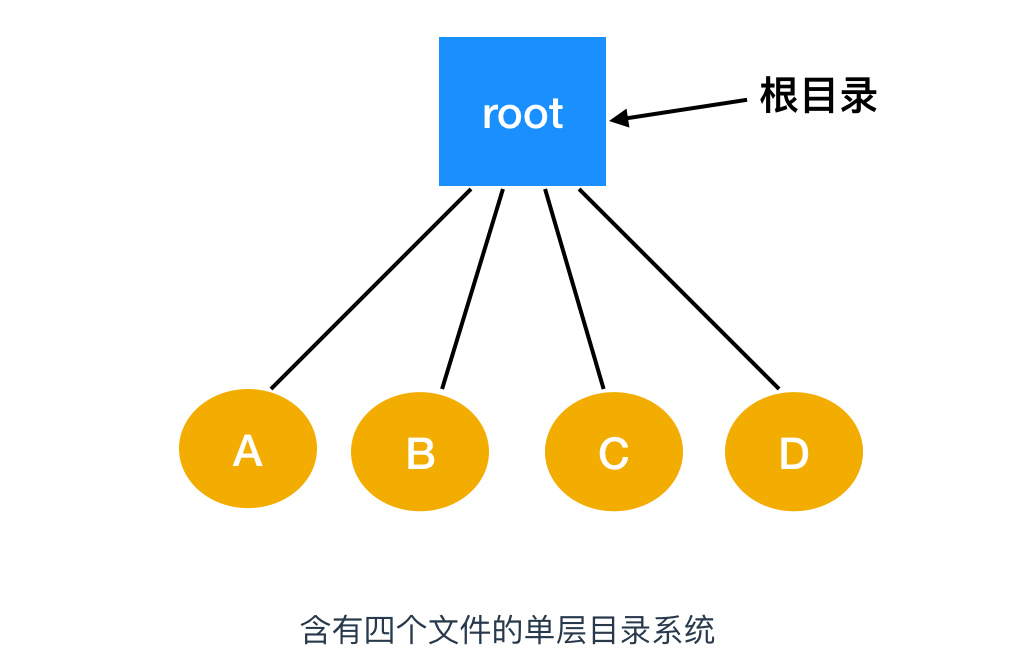
該目錄中有四個文件。這種設計的優點在于簡單,并且能夠快速定位文件,畢竟只有一個地方可以檢索。這種目錄組織形式現在一般用于簡單的嵌入式設備(如數碼相機和某些便攜式音樂播放器)上使用。
層次目錄系統
對于簡單的應用而言,一般都用單層目錄方式,但是這種組織形式并不適合于現代計算機,因為現代計算機含有成千上萬個文件和文件夾。如果都放在根目錄下,查找起來會非常困難。為了解決這一問題,出現了層次目錄系統(Hierarchical Directory Systems),也稱為目錄樹。通過這種方式,可以用很多目錄把文件進行分組。進而,如果多個用戶共享同一個文件服務器,比如公司的網絡系統,每個用戶可以為自己的目錄樹擁有自己的私人根目錄。這種方式的組織結構如下
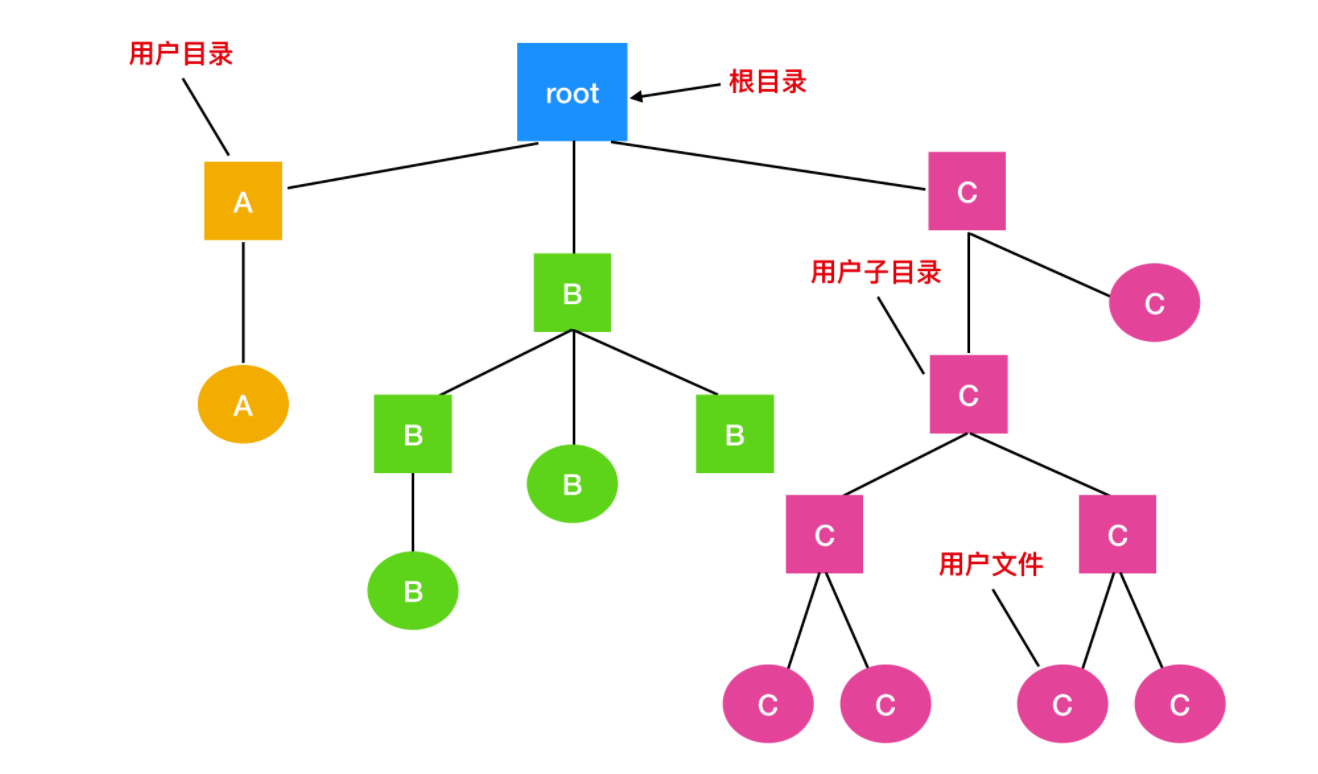
根目錄含有目錄 A、B 和 C ,分別屬于不同的用戶,其中兩個用戶個字創建了子目錄。用戶可以創建任意數量的子目錄,現代文件系統都是按照這種方式組織的。
路徑名
當目錄樹組織文件系統時,需要有某種方法指明文件名。常用的方法有兩種,第一種方式是每個文件都會用一個絕對路徑名(absolute path name),它由根目錄到文件的路徑組成。舉個例子,/usr/ast/mailbox 意味著根目錄包含一個子目錄usr,usr 下面包含了一個 mailbox。絕對路徑名總是以 / 開頭,并且是唯一的。在UNIX中,路徑的組件由/分隔。在Windows中,分隔符為\。 在 MULTICS 中,它是>。 因此,在這三個系統中,相同的路徑名將被編寫如下
Windows \usr\ast\mailbox
UNIX /usr/ast/mailbox
MULTICS >usr>ast>mailbox
不論使用哪種方式,如果路徑名的第一個字符是分隔符,那就是絕對路徑。
另外一種指定文件名的方法是 相對路徑名(relative path name)。它常常和 工作目錄(working directory) (也稱作 當前目錄(current directory))一起使用。用戶可以指定一個目錄作為當前工作目錄。例如,如果當前目錄是 /usr/ast,那么絕對路徑 /usr/ast/mailbox可以直接使用 mailbox 來引用。也就是說,如果工作目錄是 /usr/ast,則 UNIX 命令
cp /usr/ast/mailbox /usr/ast/mailbox.bak
和命令
cp mailbox mailbox.bak
具有相同的含義。相對路徑通常情況下更加方便和簡潔。而它實現的功能和絕對路徑安全相同。
一些程序需要訪問某個特定的文件而不必關心當前的工作目錄是什么。在這種情況下,應該使用絕對路徑名。
支持層次目錄結構的大多數操作系統在每個目錄中有兩個特殊的目錄項. 和 ..,長讀作 dot 和 dotdot。dot 指的是當前目錄,dotdot 指的是其父目錄(在根目錄中例外,在根目錄中指向自己)。可以參考下面的進程樹來查看如何使用。
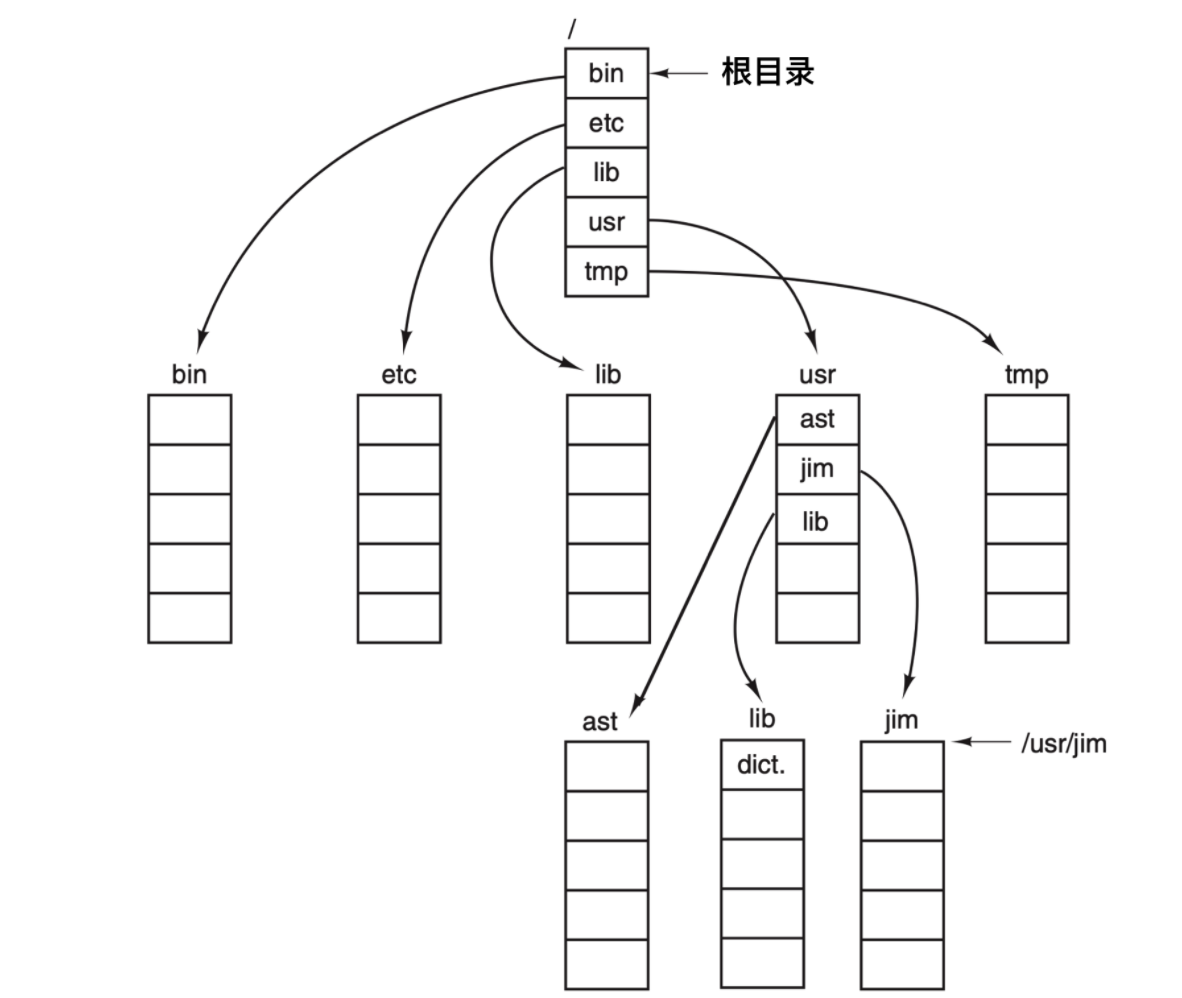
一個進程的工作目錄是 /usr/ast,它可采用 .. 沿樹向上,例如,可用命令
cp ../lib/dictionary .
把文件 usr/lib/dictionary 復制到自己的目錄下,第一個路徑告訴系統向上找(到 usr 目錄),然后向下到 lib 目錄,找到 dictionary 文件
第二個參數 . 指定當前的工作目錄,當 cp 命令用目錄名作為最后一個參數時,則把全部的文件復制到該目錄中。當然,對于上述復制,鍵入
cp /usr/lib/dictionary .
是更常用的方法。用戶這里采用 . 可以避免鍵入兩次 dictionary 。無論如何,鍵入
cp /usr/lib/dictionary dictionary
也可正常工作,就像鍵入
cp /usr/lib/dictionary /usr/lib/dictionary
一樣。所有這些命令都能夠完成同樣的工作。
目錄操作
不同文件中管理目錄的系統調用的差別比管理文件的系統調用差別大。為了了解這些系統調用有哪些以及它們怎樣工作,下面給出一個例子(取自 UNIX)。
Create,創建目錄,除了目錄項.和..外,目錄內容為空。Delete,刪除目錄,只有空目錄可以刪除。只包含.和..的目錄被認為是空目錄,這兩個目錄項通常不能刪除opendir,目錄內容可被讀取。例如,未列出目錄中的全部文件,程序必須先打開該目錄,然后讀其中全部文件的文件名。與打開和讀文件相同,在讀目錄前,必須先打開文件。closedir,讀目錄結束后,應該關閉目錄用于釋放內部表空間。readdir,系統調用 readdir 返回打開目錄的下一個目錄項。以前也采用 read 系統調用來讀取目錄,但是這種方法有一個缺點:程序員必須了解和處理目錄的內部結構。相反,不論采用哪一種目錄結構,readdir 總是以標準格式返回一個目錄項。rename,在很多方面目錄和文件都相似。文件可以更換名稱,目錄也可以。link,鏈接技術允許在多個目錄中出現同一個文件。這個系統調用指定一個存在的文件和一個路徑名,并建立從該文件到路徑所指名字的鏈接。這樣,可以在多個目錄中出現同一個文件。有時也被稱為硬鏈接(hard link)。unlink,刪除目錄項。如果被解除鏈接的文件只出現在一個目錄中,則將它從文件中刪除。如果它出現在多個目錄中,則只刪除指定路徑名的鏈接,依然保留其他路徑名的鏈接。在 UNIX 中,用于刪除文件的系統調用就是 unlink。
文件系統的實現
在對文件有了基本認識之后,現在是時候把目光轉移到文件系統的實現上了。之前用戶關心的一直都是文件是怎樣命名的、可以進行哪些操作、目錄樹是什么,如何找到正確的文件路徑等問題。而設計人員關心的是文件和目錄是怎樣存儲的、磁盤空間是如何管理的、如何使文件系統得以流暢運行的問題,下面我們就來一起討論一下這些問題。
文件系統布局
文件系統存儲在磁盤中。大部分的磁盤能夠劃分出一到多個分區,叫做磁盤分區(disk partitioning) 或者是磁盤分片(disk slicing)。每個分區都有獨立的文件系統,每塊分區的文件系統可以不同。磁盤的 0 號分區稱為 主引導記錄(Master Boot Record, MBR),用來引導(boot) 計算機。在 MBR 的結尾是分區表(partition table)。每個分區表給出每個分區由開始到結束的地址。系統管理員使用一個稱為分區編輯器的程序來創建,調整大小,刪除和操作分區。這種方式的一個缺點是很難適當調整分區的大小,導致一個分區具有很多可用空間,而另一個分區幾乎完全被分配。
MBR 可以用在 DOS 、Microsoft Windows 和 Linux 操作系統中。從 2010 年代中期開始,大多數新計算機都改用 GUID 分區表(GPT)分區方案。
下面是一個用 GParted 進行分區的磁盤,表中的分區都被認為是 活動的(active)。
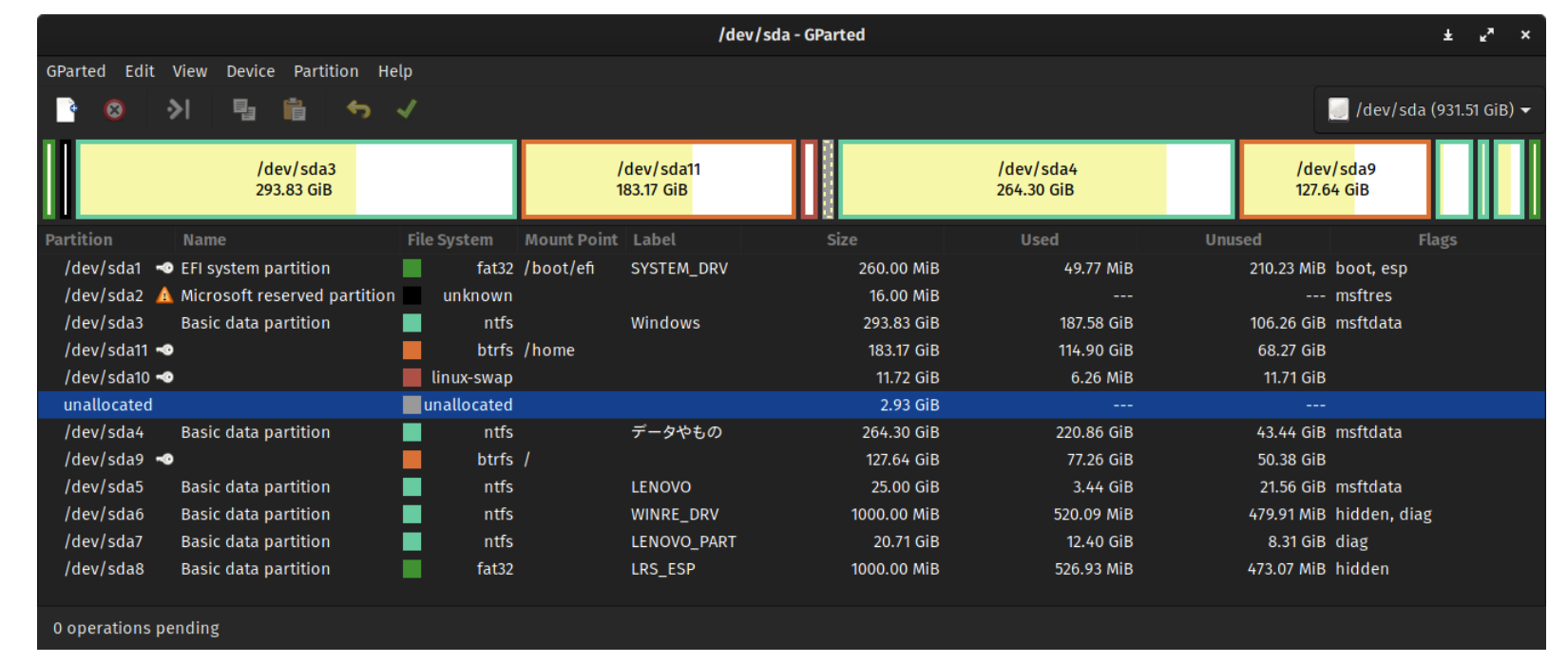
當計算機開始引 boot 時,BIOS 讀入并執行 MBR。
引導塊
MBR 做的第一件事就是確定活動分區,讀入它的第一個塊,稱為引導塊(boot block) 并執行。引導塊中的程序將加載分區中的操作系統。為了一致性,每個分區都會從引導塊開始,即使引導塊不包含操作系統。引導塊占據文件系統的前 4096 個字節,從磁盤上的字節偏移量 0 開始。引導塊可用于啟動操作系統。
在計算機中,引導就是啟動計算機的過程,它可以通過硬件(例如按下電源按鈕)或者軟件命令的方式來啟動。開機后,電腦的 CPU 還不能執行指令,因為此時沒有軟件在主存中,所以一些軟件必須先被加載到內存中,然后才能讓 CPU 開始執行。也就是計算機開機后,首先會進行軟件的裝載過程。
重啟電腦的過程稱為
重新引導(rebooting),從休眠或睡眠狀態返回計算機的過程不涉及啟動。
除了從引導塊開始之外,磁盤分區的布局是隨著文件系統的不同而變化的。通常文件系統會包含一些屬性,如下
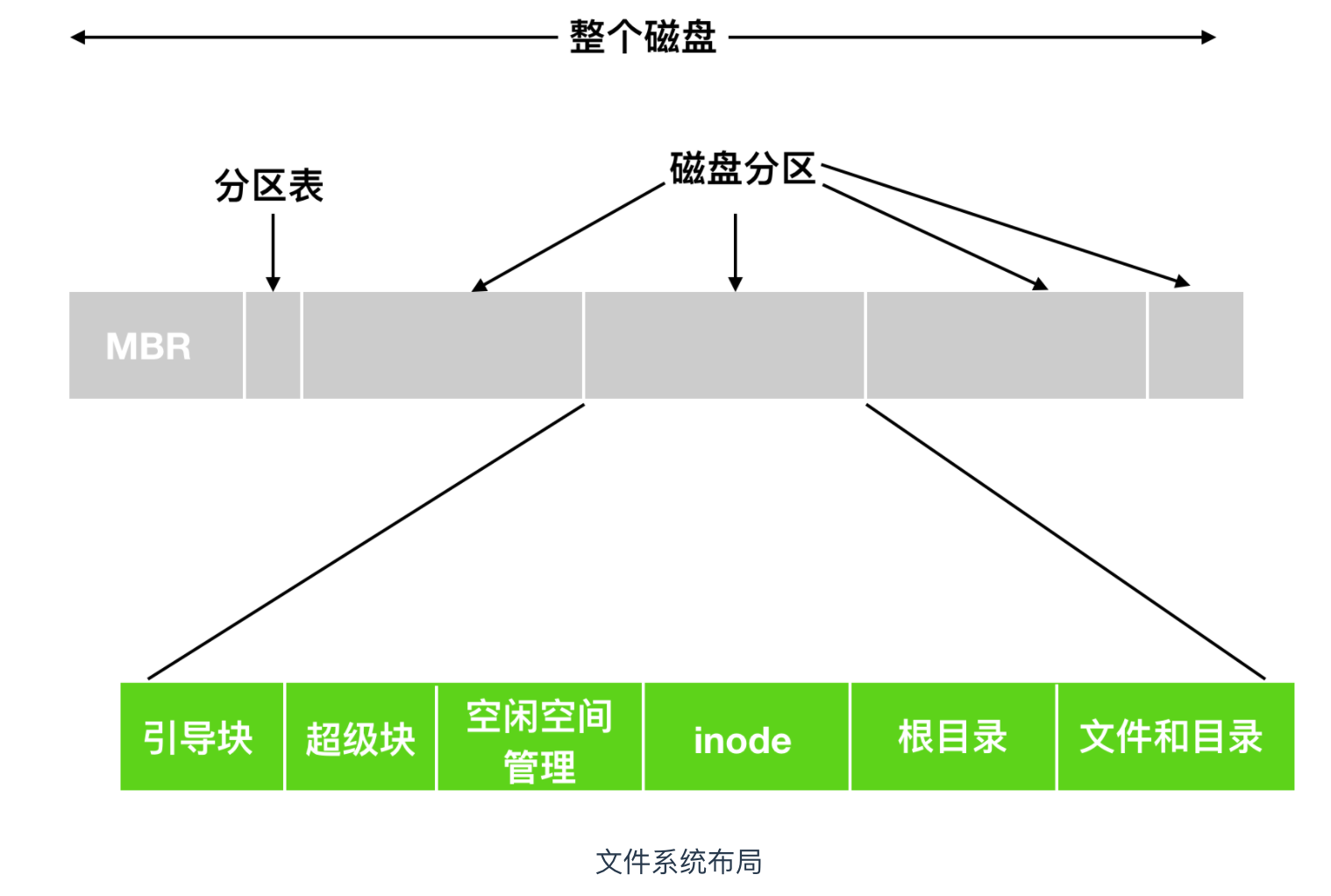
超級塊
緊跟在引導塊后面的是 超級塊(Superblock),超級塊 的大小為 4096 字節,從磁盤上的字節偏移 4096 開始。超級塊包含文件系統的所有關鍵參數
- 文件系統的大小
- 文件系統中的數據塊數
- 指示文件系統狀態的標志
- 分配組大小
在計算機啟動或者文件系統首次使用時,超級塊會被讀入內存。
空閑空間塊
接著是文件系統中空閑塊的信息,例如,可以用位圖或者指針列表的形式給出。
BitMap 位圖或者 Bit vector 位向量
位圖或位向量是一系列位或位的集合,其中每個位對應一個磁盤塊,該位可以采用兩個值:0和1,0表示已分配該塊,而1表示一個空閑塊。下圖中的磁盤上給定的磁盤塊實例(分配了綠色塊)可以用16位的位圖表示為:0000111000000110。
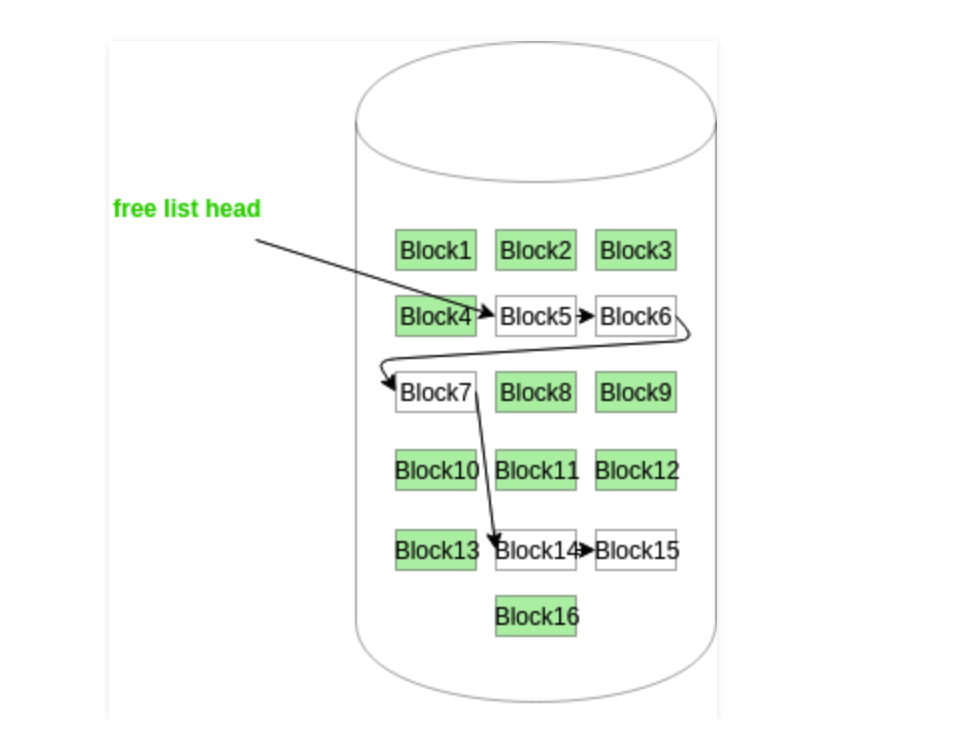
使用鏈表進行管理
在這種方法中,空閑磁盤塊鏈接在一起,即一個空閑塊包含指向下一個空閑塊的指針。第一個磁盤塊的塊號存儲在磁盤上的單獨位置,也緩存在內存中。
碎片
這里不得不提一個叫做碎片(fragment)的概念,也稱為片段。一般零散的單個數據通常稱為片段。 磁盤塊可以進一步分為固定大小的分配單元,片段只是在驅動器上彼此不相鄰的文件片段。如果你不理解這個概念就給你舉個例子。比如你用 Windows 電腦創建了一個文件,你會發現這個文件可以存儲在任何地方,比如存在桌面上,存在磁盤中的文件夾中或者其他地方。你可以打開文件,編輯文件,刪除文件等等。你可能以為這些都在一個地方發生,但是實際上并不是,你的硬盤驅動器可能會將文件中的一部分存儲在一個區域內,另一部分存儲在另外一個區域,在你打開文件時,硬盤驅動器會迅速的將文件的所有部分匯總在一起,以便其他計算機系統可以使用它。
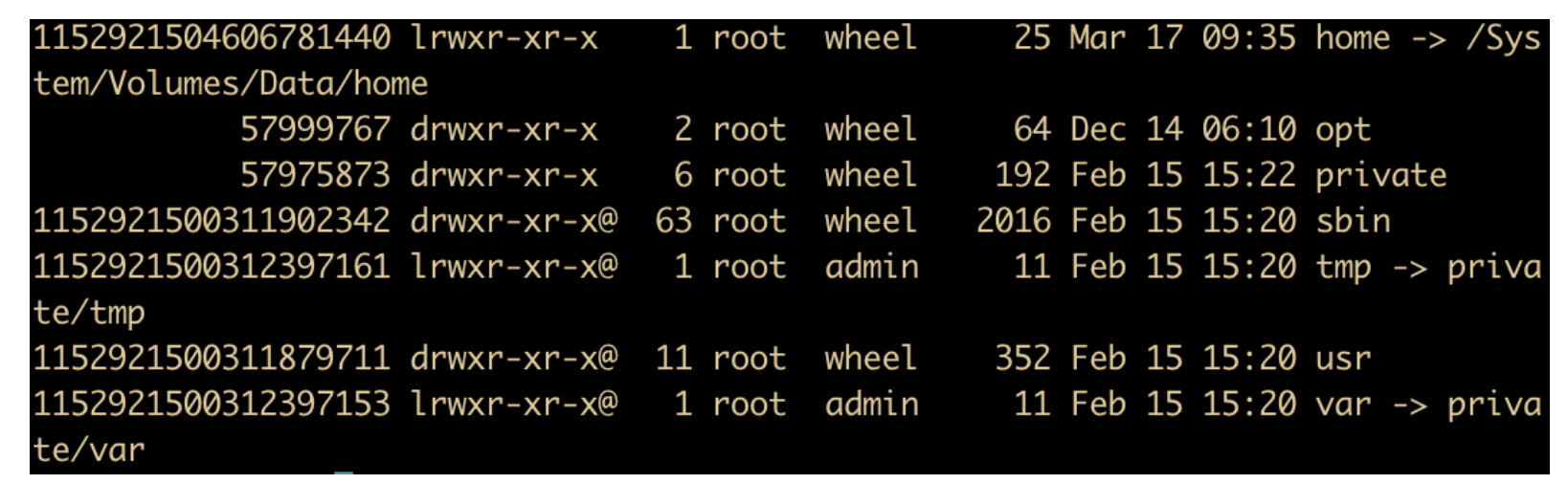
inode
然后在后面是一個 inode(index node),也稱作索引節點。它是一個數組的結構,每個文件有一個 inode,inode 非常重要,它說明了文件的方方面面。每個索引節點都存儲對象數據的屬性和磁盤塊位置
有一種簡單的方法可以找到它們 ls -lai 命令。讓我們看一下根文件系統:
inode 節點主要包括了以下信息
- 模式/權限(保護)
- 所有者 ID
- 組 ID
- 文件大小
- 文件的硬鏈接數
- 上次訪問時間
- 最后修改時間
- inode 上次修改時間
文件分為兩部分,索引節點和塊。一旦創建后,每種類型的塊數是固定的。你不能增加分區上 inode 的數量,也不能增加磁盤塊的數量。
緊跟在 inode 后面的是根目錄,它存放的是文件系統目錄樹的根部。最后,磁盤的其他部分存放了其他所有的目錄和文件。
文件的實現
最重要的問題是記錄各個文件分別用到了哪些磁盤塊。不同的系統采用了不同的方法。下面我們會探討一下這些方式。分配背后的主要思想是有效利用文件空間和快速訪問文件 ,主要有三種分配方案
- 連續分配
- 鏈表分配
- 索引分配
連續分配
最簡單的分配方案是把每個文件作為一連串連續數據塊存儲在磁盤上。因此,在具有 1KB 塊的磁盤上,將為 50 KB 文件分配 50 個連續塊。
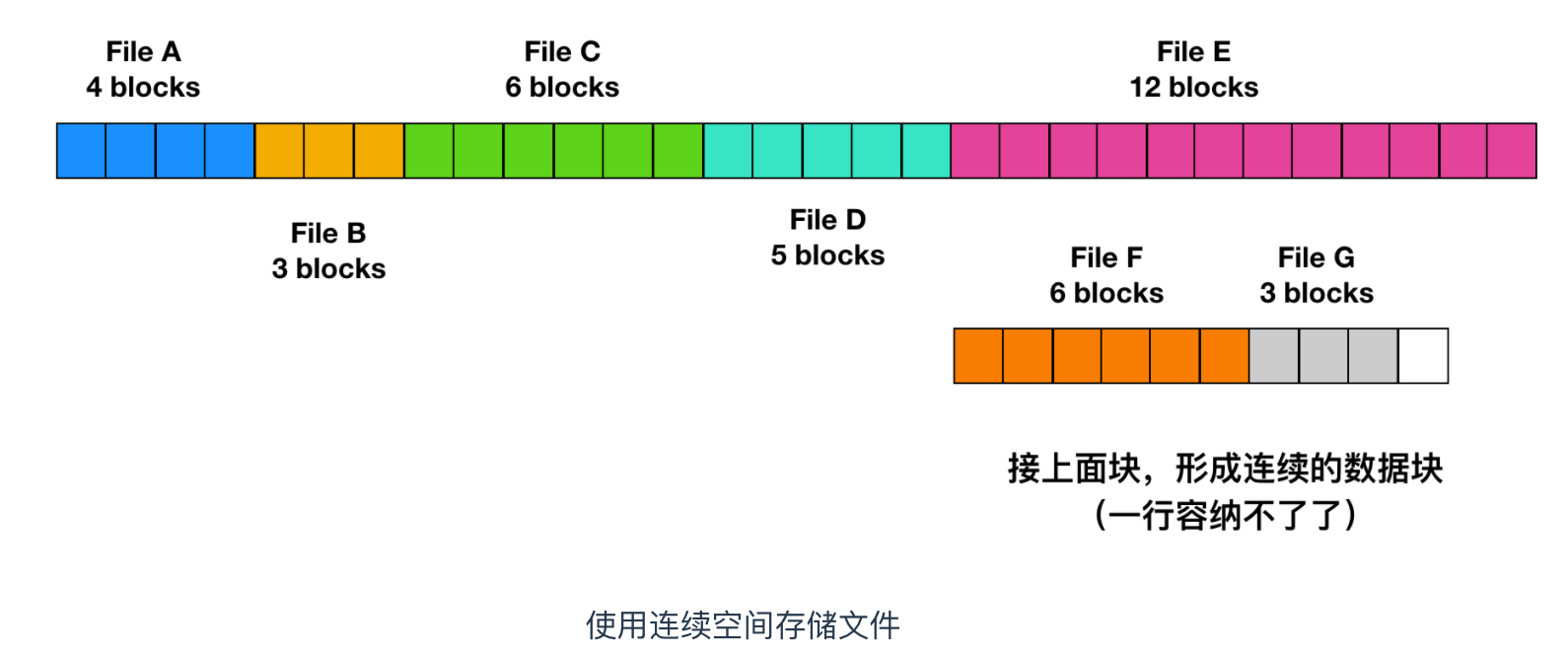
上面展示了 40 個連續的內存塊。從最左側的 0 塊開始。初始狀態下,還沒有裝載文件,因此磁盤是空的。接著,從磁盤開始處(塊 0 )處開始寫入占用 4 塊長度的內存 A 。然后是一個占用 6 塊長度的內存 B,會直接在 A 的末尾開始寫。
注意每個文件都會在新的文件塊開始寫,所以如果文件 A 只占用了 3 又 1/2 個塊,那么最后一個塊的部分內存會被浪費。在上面這幅圖中,總共展示了 7 個文件,每個文件都會從上個文件的末尾塊開始寫新的文件塊。
連續的磁盤空間分配有兩個優點。
-
第一,連續文件存儲實現起來比較簡單,只需要記住兩個數字就可以:一個是第一個塊的文件地址和文件的塊數量。給定第一個塊的編號,可以通過簡單的加法找到任何其他塊的編號。
-
第二點是讀取性能比較強,可以通過一次操作從文件中讀取整個文件。只需要一次尋找第一個塊。后面就不再需要尋道時間和旋轉延遲,所以數據會以全帶寬進入磁盤。
因此,連續的空間分配具有實現簡單、高性能的特點。
不幸的是,連續空間分配也有很明顯的不足。隨著時間的推移,磁盤會變得很零碎。下圖解釋了這種現象
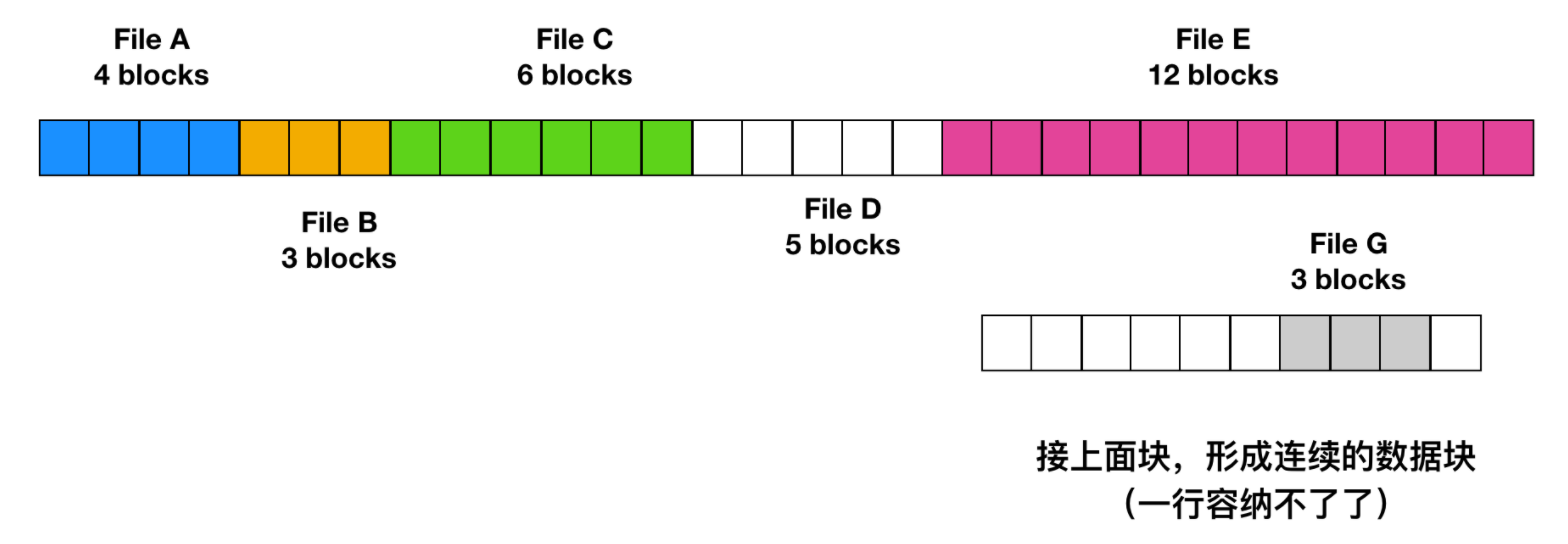
這里有兩個文件 D 和 F 被刪除了。當刪除一個文件時,此文件所占用的塊也隨之釋放,就會在磁盤空間中留下一些空閑塊。磁盤并不會在這個位置擠壓掉空閑塊,因為這會復制空閑塊之后的所有文件,可能會有上百萬的塊,這個量級就太大了。
剛開始的時候,這個碎片不是問題,因為每個新文件都會在之前文件的結尾處進行寫入。然而,磁盤最終會被填滿,因此要么壓縮磁盤、要么重新使用空閑塊的空間。壓縮磁盤的開銷太大,因此不可行;后者會維護一個空閑列表,這個是可行的。但是這種情況又存在一個問題,為空閑塊匹配合適大小的文件,需要知道該文件的最終大小。
想象一下這種設計的結果會是怎樣的。用戶啟動 word 進程創建文檔。應用程序首先會詢問最終創建的文檔會有多大。這個問題必須回答,否則應用程序就不會繼續執行。如果空閑塊的大小要比文件的大小小,程序就會終止。因為所使用的磁盤空間已經滿了。那么現實生活中,有沒有使用連續分配內存的介質出現呢?
CD-ROM 就廣泛的使用了連續分配方式。
CD-ROM(Compact Disc Read-Only Memory)即只讀光盤,也稱作只讀存儲器。是一種在電腦上使用的光碟。這種光碟只能寫入數據一次,信息將永久保存在光碟上,使用時通過光碟驅動器讀出信息。

然而 DVD 的情況會更加復雜一些。原則上,一個 90分鐘 的電影能夠被編碼成一個獨立的、大約 4.5 GB 的文件。但是文件系統所使用的 UDF(Universal Disk Format) 格式,使用一個 30 位的數來代表文件長度,從而把文件大小限制在 1 GB。所以,DVD 電影一般存儲在 3、4個連續的 1 GB 空間內。這些構成單個電影中的文件塊稱為擴展區(extends)。
就像我們反復提到的,歷史總是驚人的相似,許多年前,連續分配由于其簡單和高性能被實際使用在磁盤文件系統中。后來由于用戶不希望在創建文件時指定文件的大小,于是放棄了這種想法。但是隨著 CD-ROM 、DVD、藍光光盤等光學介質的出現,連續分配又流行起來。從而得出結論,技術永遠沒有過時性,現在看似很老的技術,在未來某個階段可能又會流行起來。
鏈表分配
第二種存儲文件的方式是為每個文件構造磁盤塊鏈表,每個文件都是磁盤塊的鏈接列表,就像下面所示
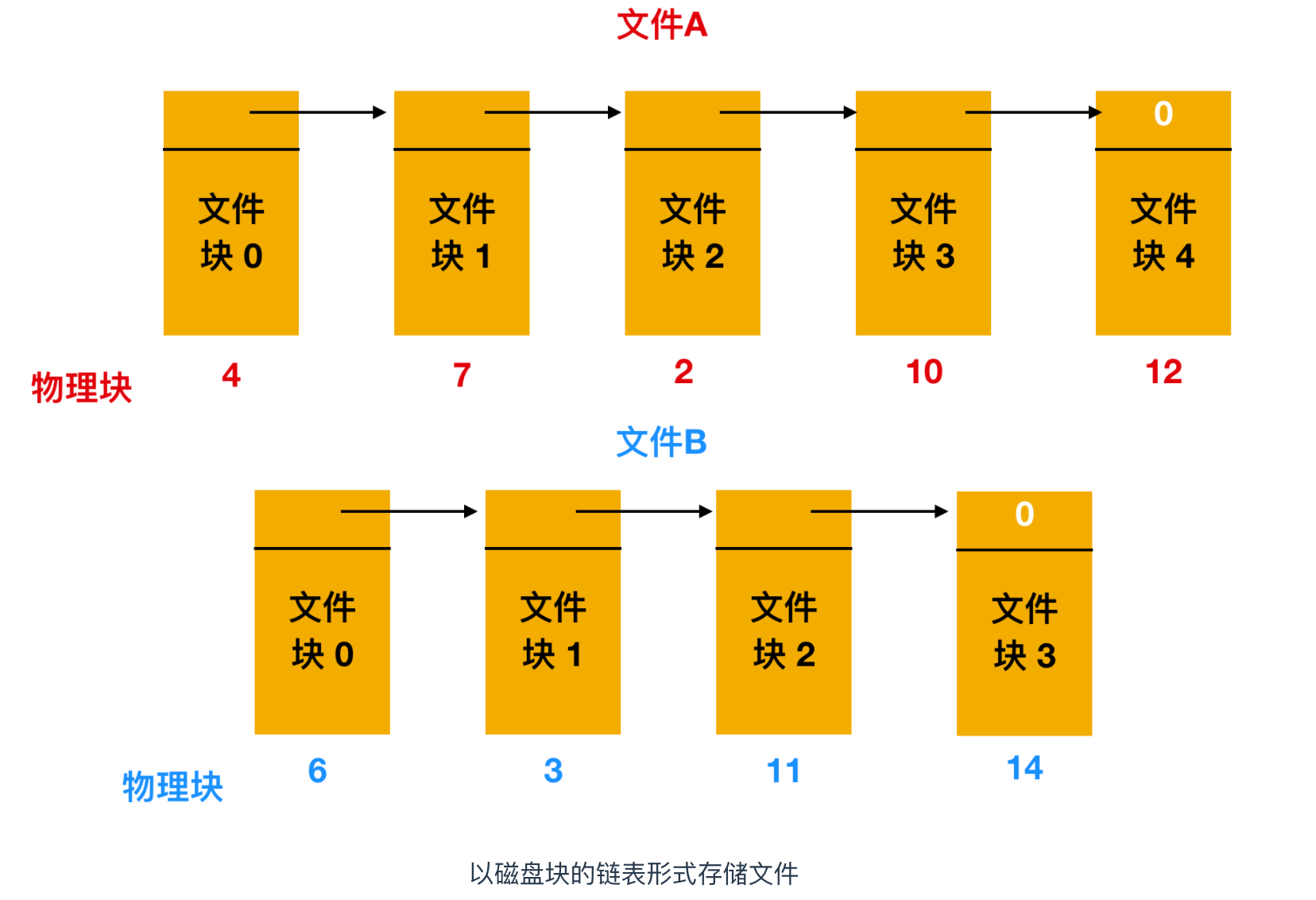
每個塊的第一個字作為指向下一塊的指針,塊的其他部分存放數據。如果上面這張圖你看的不是很清楚的話,可以看看整個的鏈表分配方案
與連續分配方案不同,這一方法可以充分利用每個磁盤塊。除了最后一個磁盤塊外,不會因為磁盤碎片而浪費存儲空間。同樣,在目錄項中,只要存儲了第一個文件塊,那么其他文件塊也能夠被找到。
另一方面,在鏈表的分配方案中,盡管順序讀取非常方便,但是隨機訪問卻很困難(這也是數組和鏈表數據結構的一大區別)。
還有一個問題是,由于指針會占用一些字節,每個磁盤塊實際存儲數據的字節數并不再是 2 的整數次冪。雖然這個問題并不會很嚴重,但是這種方式降低了程序運行效率。許多程序都是以長度為 2 的整數次冪來讀寫磁盤,由于每個塊的前幾個字節被指針所使用,所以要讀出一個完成的塊大小信息,就需要當前塊的信息和下一塊的信息拼湊而成,因此就引發了查找和拼接的開銷。
使用內存表進行鏈表分配
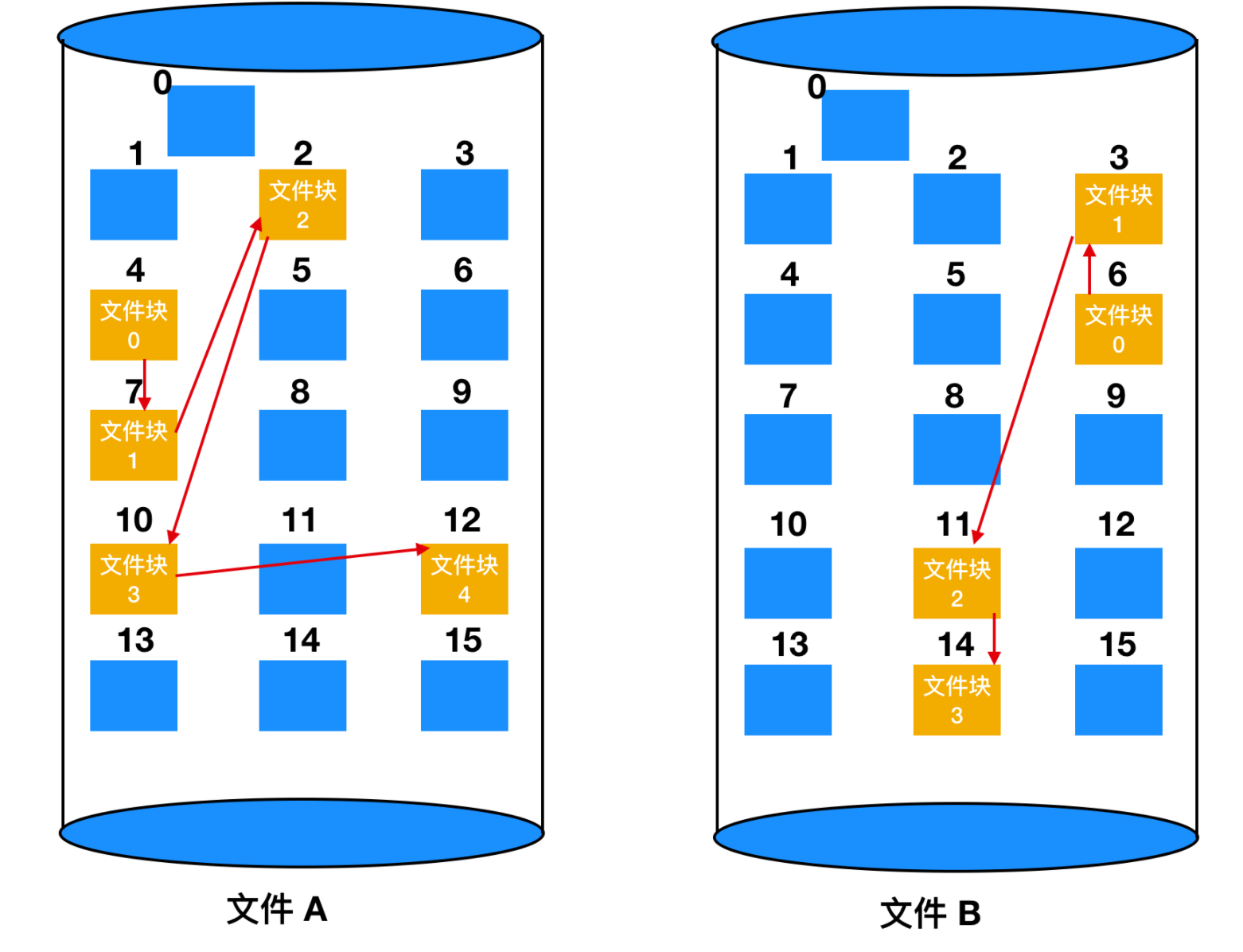
由于連續分配和鏈表分配都有其不可忽視的缺點。所以提出了使用內存中的表來解決分配問題。取出每個磁盤塊的指針字,把它們放在內存的一個表中,就可以解決上述鏈表的兩個不足之處。下面是一個例子
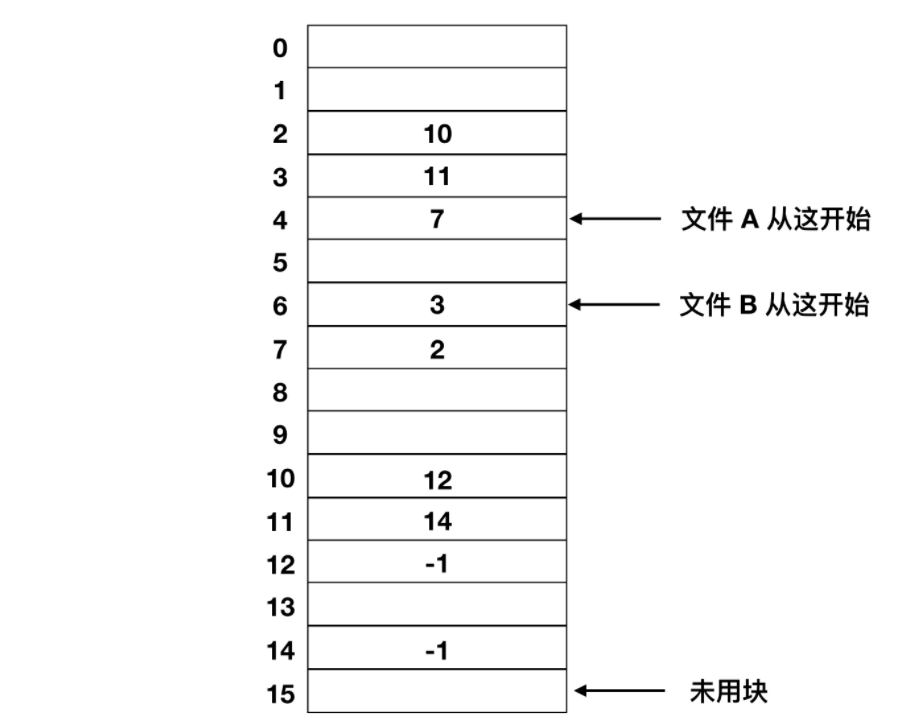
上圖表示了鏈表形成的磁盤塊的內容。這兩個圖中都有兩個文件,文件 A 依次使用了磁盤塊地址 4、7、 2、 10、 12,文件 B 使用了6、3、11 和 14。也就是說,文件 A 從地址 4 處開始,順著鏈表走就能找到文件 A 的全部磁盤塊。同樣,從第 6 塊開始,順著鏈走到最后,也能夠找到文件 B 的全部磁盤塊。你會發現,這兩個鏈表都以不屬于有效磁盤編號的特殊標記(-1)結束。內存中的這種表格稱為 文件分配表(File Application Table,FAT)。
使用這種組織方式,整個塊都可以存放數據。進而,隨機訪問也容易很多。雖然仍要順著鏈在內存中查找給定的偏移量,但是整個鏈都存放在內存中,所以不需要任何磁盤引用。與前面的方法相同,不管文件有多大,在目錄項中只需記錄一個整數(起始塊號),按照它就可以找到文件的全部塊。
這種方式存在缺點,那就是必須要把整個鏈表放在內存中。對于 1TB 的磁盤和 1KB 的大小的塊,那么這張表需要有 10 億項。。。每一項對應于這 10 億個磁盤塊中的一塊。每項至少 3 個字節,為了提高查找速度,有時需要 4 個字節。根據系統對空間或時間的優化方案,這張表要占用 3GB 或 2.4GB 的內存。FAT 的管理方式不能較好地擴展并應用于大型磁盤中。而這正是最初 MS-DOS 文件比較實用,并仍被各個 Windows 版本所安全支持。
inode
最后一個記錄各個文件分別包含哪些磁盤塊的方法是給每個文件賦予一個稱為 inode(索引節點) 的數據結構,每個文件都與一個 inode 進行關聯,inode 由整數進行標識。
下面是一個簡單例子的描述。
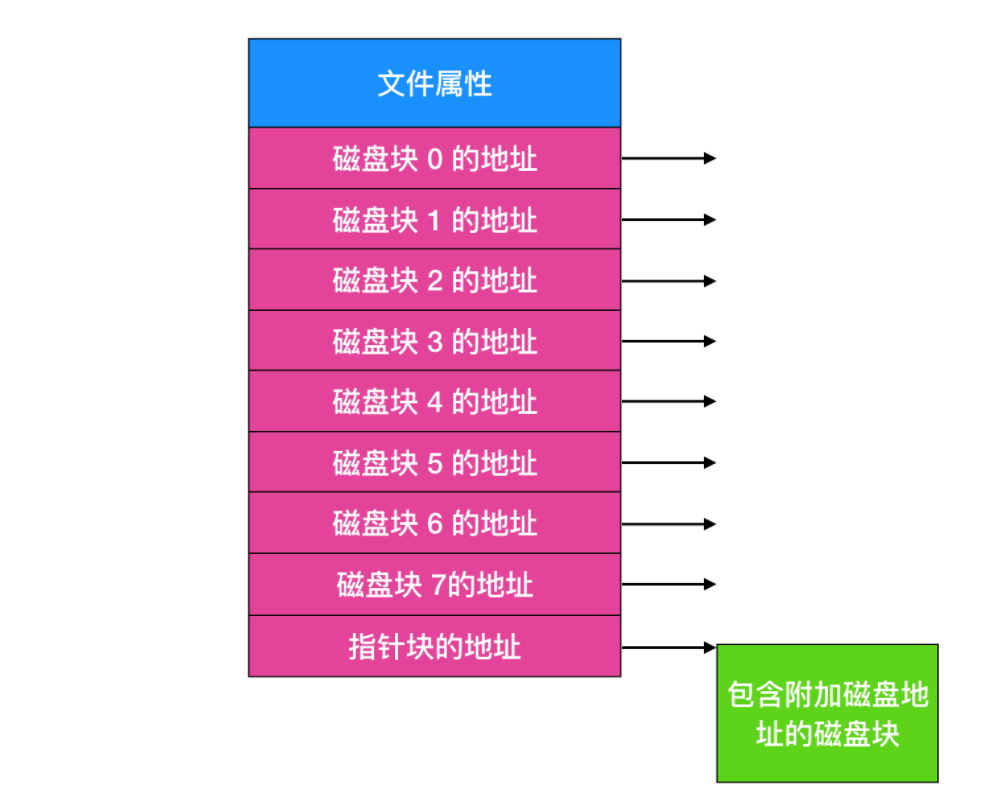
給出 inode 的長度,就能夠找到文件中的所有塊。
相對于在內存中使用表的方式而言,這種機制具有很大的優勢。即只有在文件打開時,其 inode 才會在內存中。如果每個 inode 需要 n 個字節,最多 k 個文件同時打開,那么 inode 占有總共打開的文件是 kn 字節。僅需預留這么多空間。
這個數組要比我們上面描述的 FAT(文件分配表) 占用的空間小的多。原因是用于保存所有磁盤塊的鏈接列表的表的大小與磁盤本身成正比。如果磁盤有 n 個塊,那么這個表也需要 n 項。隨著磁盤空間的變大,那么該表也隨之線性增長。相反,inode 需要節點中的數組,其大小和可能需要打開的最大文件個數成正比。它與磁盤是 100GB、4000GB 還是 10000GB 無關。
inode 的一個問題是如果每個節點都會有固定大小的磁盤地址,那么文件增長到所能允許的最大容量外會發生什么?一個解決方案是最后一個磁盤地址不指向數據塊,而是指向一個包含額外磁盤塊地址的地址,如上圖所示。一個更高級的解決方案是:有兩個或者更多包含磁盤地址的塊,或者指向其他存放地址的磁盤塊的磁盤塊。Windows 的 NTFS 文件系統采用了相似的方法,所不同的僅僅是大的 inode 也可以表示小的文件。
NTFS 的全稱是
New Technology File System,是微軟公司開發的專用系統文件,NTFS 取代 FAT(文件分配表) 和HPFS(高性能文件系統),并在此基礎上進一步改進。例如增強對元數據的支持,使用更高級的數據結構以提升性能、可靠性和磁盤空間利用率等。
目錄的實現
文件只有打開后才能夠被讀取。在文件打開后,操作系統會使用用戶提供的路徑名來定位磁盤中的目錄。目錄項提供了查找文件磁盤塊所需要的信息。根據系統的不同,提供的信息也不同,可能提供的信息是整個文件的磁盤地址,或者是第一個塊的數量(兩個鏈表方案)或 inode的數量。不過不管用那種情況,目錄系統的主要功能就是 將文件的 ASCII 碼的名稱映射到定位數據所需的信息上。
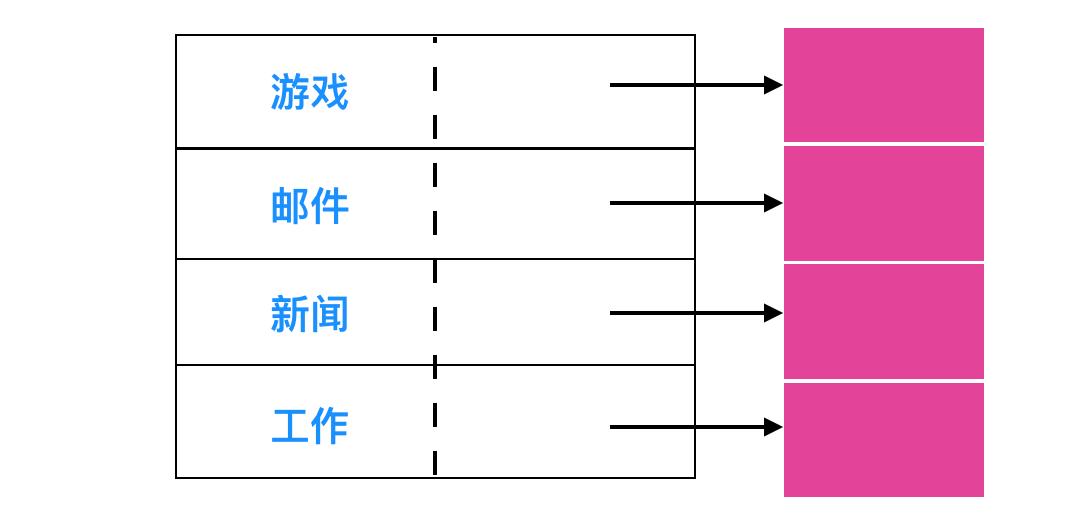
與此關系密切的問題是屬性應該存放在哪里。每個文件系統包含不同的文件屬性,例如文件的所有者和創建時間,需要存儲的位置。一種顯而易見的方法是直接把文件屬性存放在目錄中。有一些系統恰好是這么做的,如下。

在這種簡單的設計中,目錄有一個固定大小的目錄項列表,每個文件對應一項,其中包含一個固定長度的文件名,文件屬性的結構體以及用以說明磁盤塊位置的一個或多個磁盤地址。
對于采用 inode 的系統,會把 inode 存儲在屬性中而不是目錄項中。在這種情況下,目錄項會更短:僅僅只有文件名稱和 inode 數量。這種方式如下所示
到目前為止,我們已經假設文件具有較短的、固定長度的名字。在 MS-DOS 中,具有 1 - 8 個字符的基本名稱和 1 - 3 個字符的可拓展名稱。在 UNIX 版本 7 中,文件有 1 - 14 個字符,包括任何拓展。然而,幾乎所有的現代操作系統都支持可變長度的擴展名。這是如何實現的呢?
最簡單的方式是給予文件名一個長度限制,比如 255 個字符,然后使用上圖中的設計,并為每個文件名保留 255 個字符空間。這種處理很簡單,但是浪費了大量的目錄空間,因為只有很少的文件會有那么長的文件名稱。所以,需要一種其他的結構來處理。
一種可選擇的方式是放棄所有目錄項大小相同的想法。在這種方法中,每個目錄項都包含一個固定部分,這個固定部分通常以目錄項的長度開始,后面是固定格式的數據,通常包括所有者、創建時間、保護信息和其他屬性。這個固定長度的頭的后面是一個任意長度的實際文件名,如下圖所示
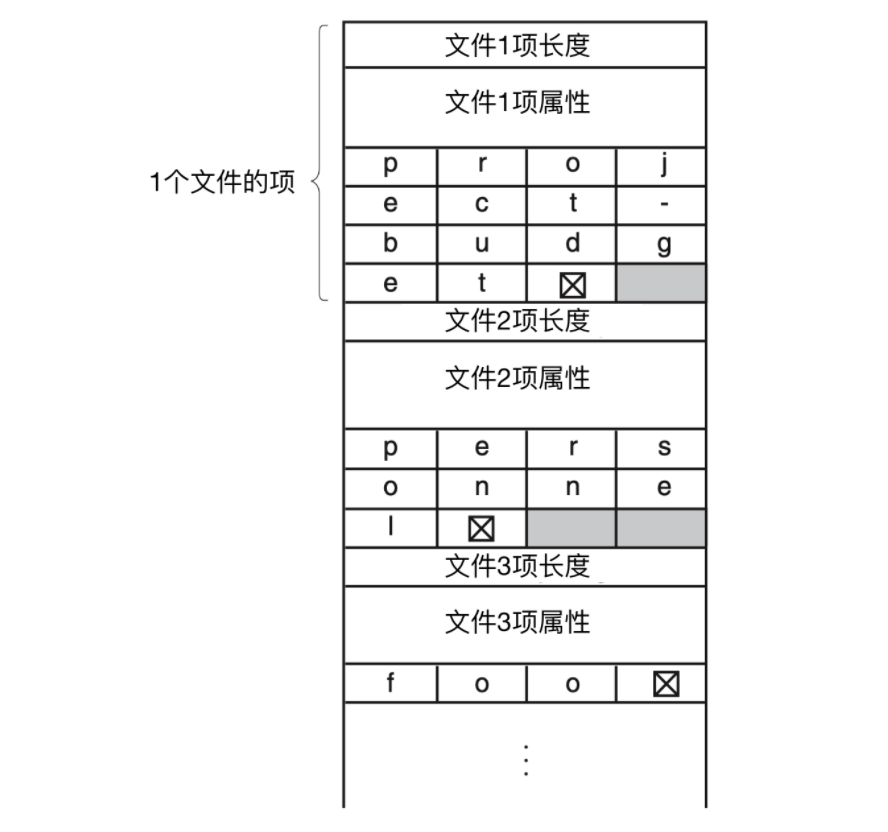
上圖是 SPARC 機器使用正序放置。
處理機中的一串字符存放的順序有
正序(big-endian)和逆序(little-endian)之分。正序存放的就是高字節在前低字節在后,而逆序存放的就是低字節在前高字節在后。
這個例子中,有三個文件,分別是 project-budget、personnel 和 foo。每個文件名以一個特殊字符(通常是 0 )結束,用矩形中的叉進行表示。為了使每個目錄項從字的邊界開始,每個文件名被填充成整數個字,如下圖所示
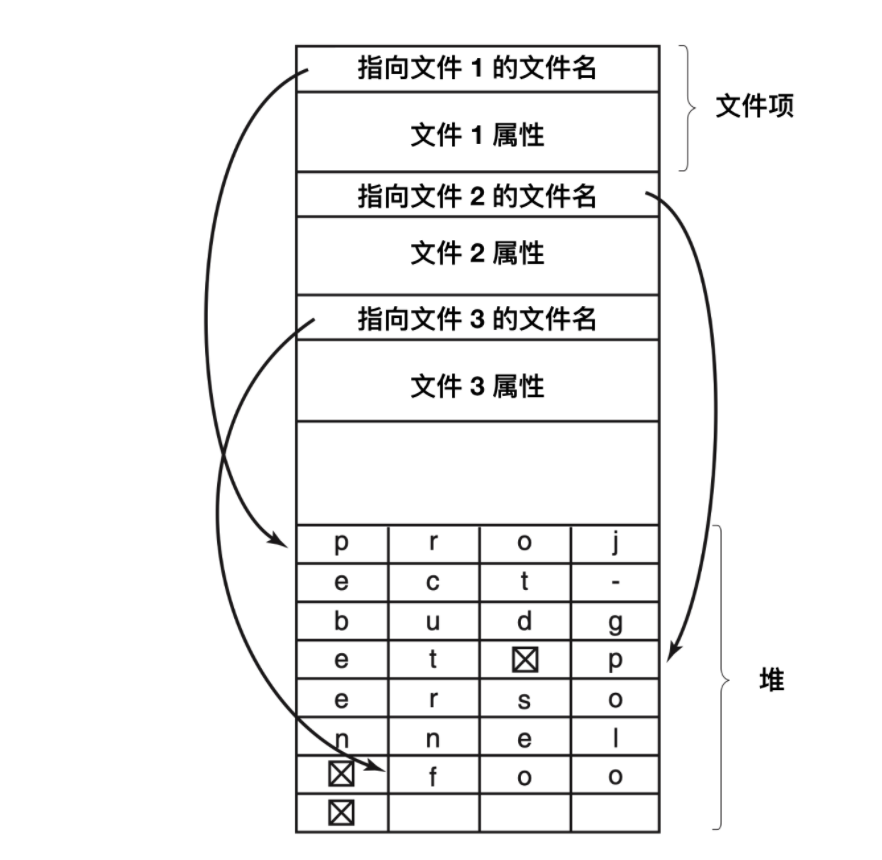
這個方法的缺點是當文件被移除后,就會留下一塊固定長度的空間,而新添加進來的文件大小不一定和空閑空間大小一致。
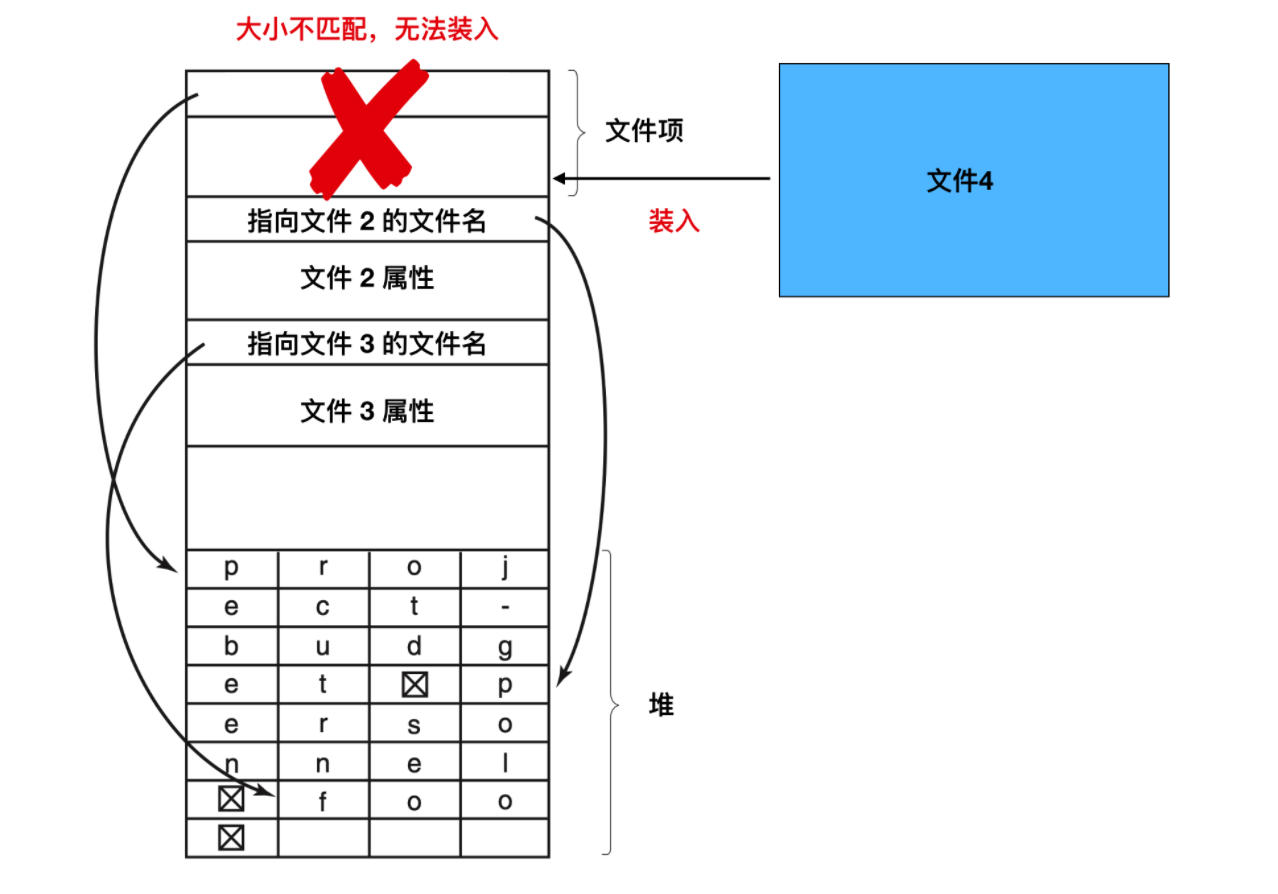
這個問題與我們上面探討的連續磁盤文件的問題是一樣的,由于整個目錄在內存中,所以只有對目錄進行緊湊拼接操作才可節省空間。另一個問題是,一個目錄項可能會分布在多個頁上,在讀取文件名時可能發生缺頁中斷。
處理可變長度文件名字的另外一種方法是,使目錄項自身具有固定長度,而將文件名放在目錄末尾的堆棧中。如上圖所示的這種方式。這種方法的優點是當目錄項被移除后,下一個文件將能夠正常匹配移除文件的空間。當然,必須要對堆進行管理,因為在處理文件名的時候也會發生缺頁異常。
到目前為止的所有設計中,在需要查找文件名時,所有的方案都是線性的從頭到尾對目錄進行搜索。對于特別長的目錄,線性搜索的效率很低。提高文件檢索效率的一種方式是在每個目錄上使用哈希表(hash table),也叫做散列表。我們假設表的大小為 n,在輸入文件名時,文件名被散列在 0 和 n - 1 之間,例如,它被 n 除,并取余數。或者對構成文件名字的字求和或類似某種方法。
無論采用哪種方式,在添加一個文件時都要對與散列值相對 應的散列表進行檢查。如果沒有使用過,就會將一個指向目錄項的指針指向這里。文件目錄項緊跟著哈希表后面。如果已經使用過,就會構造一個鏈表(這種構造方式是不是和 HashMap 使用的數據結構一樣?),鏈表的表頭指針存放在表項中,并通過哈希值將所有的表項相連。
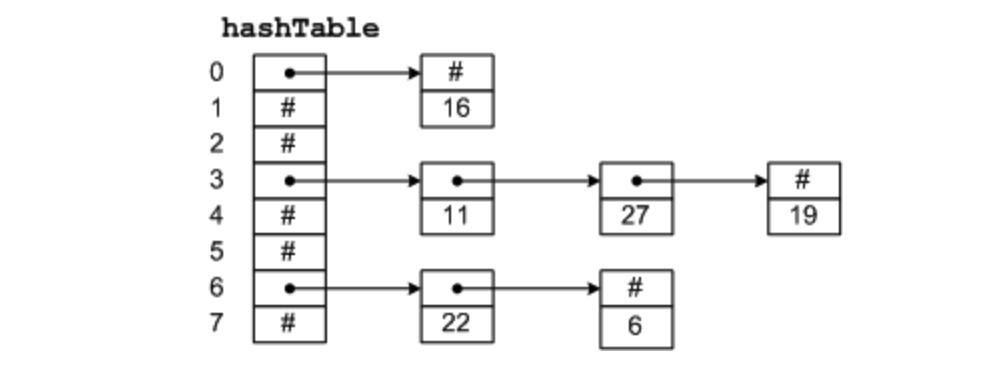
查找文件的過程和添加類似,首先對文件名進行哈希處理,在哈希表中查找是否有這個哈希值,如果有的話,就檢查這條鏈上所有的哈希項,查看文件名是否存在。如果哈希不在鏈上,那么文件就不在目錄中。
使用哈希表的優勢是查找非常迅速,缺點是管理起來非常復雜。只有在系統中會有成千上萬個目錄項存在時,才會考慮使用散列表作為解決方案。
另外一種在大量目錄中加快查找指令目錄的方法是使用緩存,緩存查找的結果。在開始查找之前,會首先檢查文件名是否在緩存中。如果在緩存中,那么文件就能立刻定位。當然,只有在較少的文件下進行多次查找,緩存才會發揮最大功效。
共享文件
當多個用戶在同一個項目中工作時,他們通常需要共享文件。如果這個共享文件同時出現在多個用戶目錄下,那么他們協同工作起來就很方便。下面的這張圖我們在上面提到過,但是有一個更改的地方,就是 C 的一個文件也出現在了 B 的目錄下。
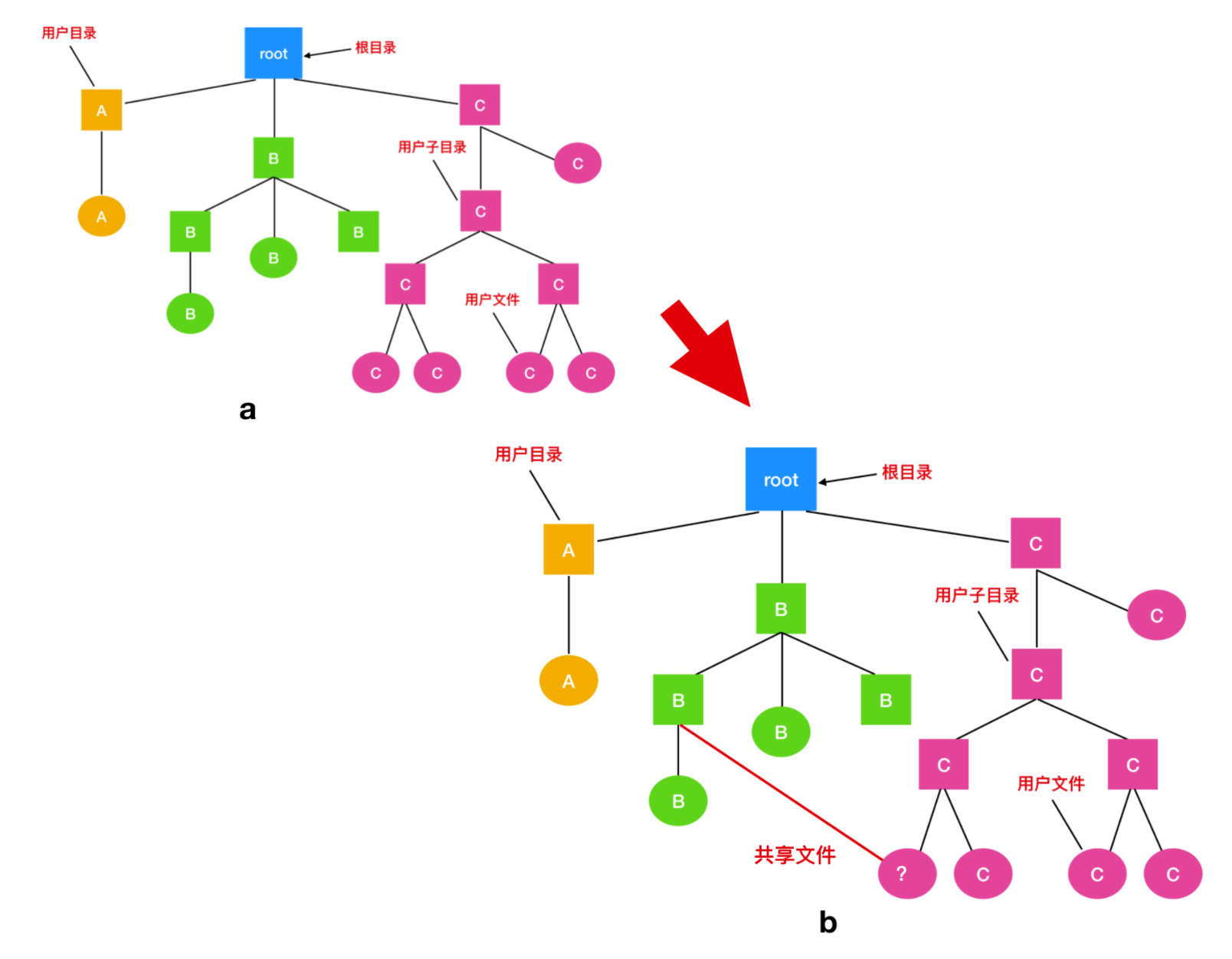
如果按照如上圖的這種組織方式而言,那么 B 的目錄與該共享文件的聯系稱為 鏈接(link)。那么文件系統現在就是一個 有向無環圖(Directed Acyclic Graph, 簡稱 DAG),而不是一棵樹了。
在圖論中,如果一個有向圖從任意頂點出發無法經過若干條邊回到該點,則這個圖是一個
有向無環圖,我們不會在此著重探討關于圖論的東西,大家可以自行 google。
將文件系統組織成為有向無環圖會使得維護復雜化,但也是必須要付出的代價。
共享文件很方便,但這也會帶來一些問題。如果目錄中包含磁盤地址,則當鏈接文件時,必須把 C 目錄中的磁盤地址復制到 B 目錄中。如果 B 或者 C 隨后又向文件中添加內容,則僅在執行追加的用戶的目錄中顯示新寫入的數據塊。這種變更將會對其他用戶不可見,從而破壞了共享的目的。
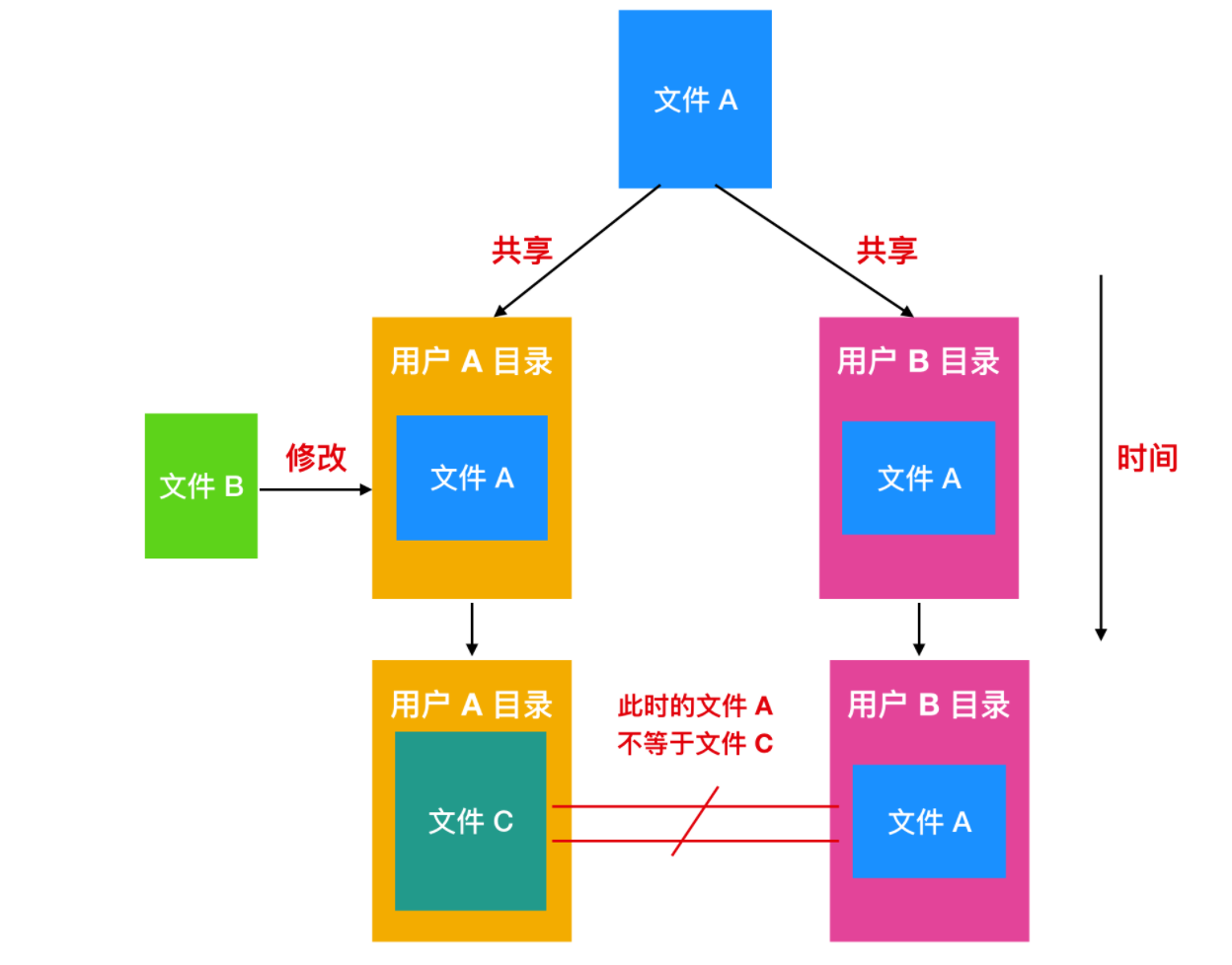
有兩種方案可以解決這種問題。
-
第一種解決方案,磁盤塊不列入目錄中,而是會把磁盤塊放在與文件本身相關聯的小型數據結構中。目錄將指向這個小型數據結構。這是
UNIX中使用的方式(小型數據結構就是 inode)。 -
在第二種解決方案中,通過讓系統建立一個類型為
LINK的新文件,并把該文件放在 B 的目錄下,使得 B 與 C 建立鏈接。新的文件中只包含了它所鏈接的文件的路徑名。當 B 想要讀取文件時,操作系統會檢查 B 的目錄下存在一個類型為 LINK 的文件,進而找到該鏈接的文件和路徑名,然后再去讀文件,這種方式稱為符號鏈接(symbolic linking)。
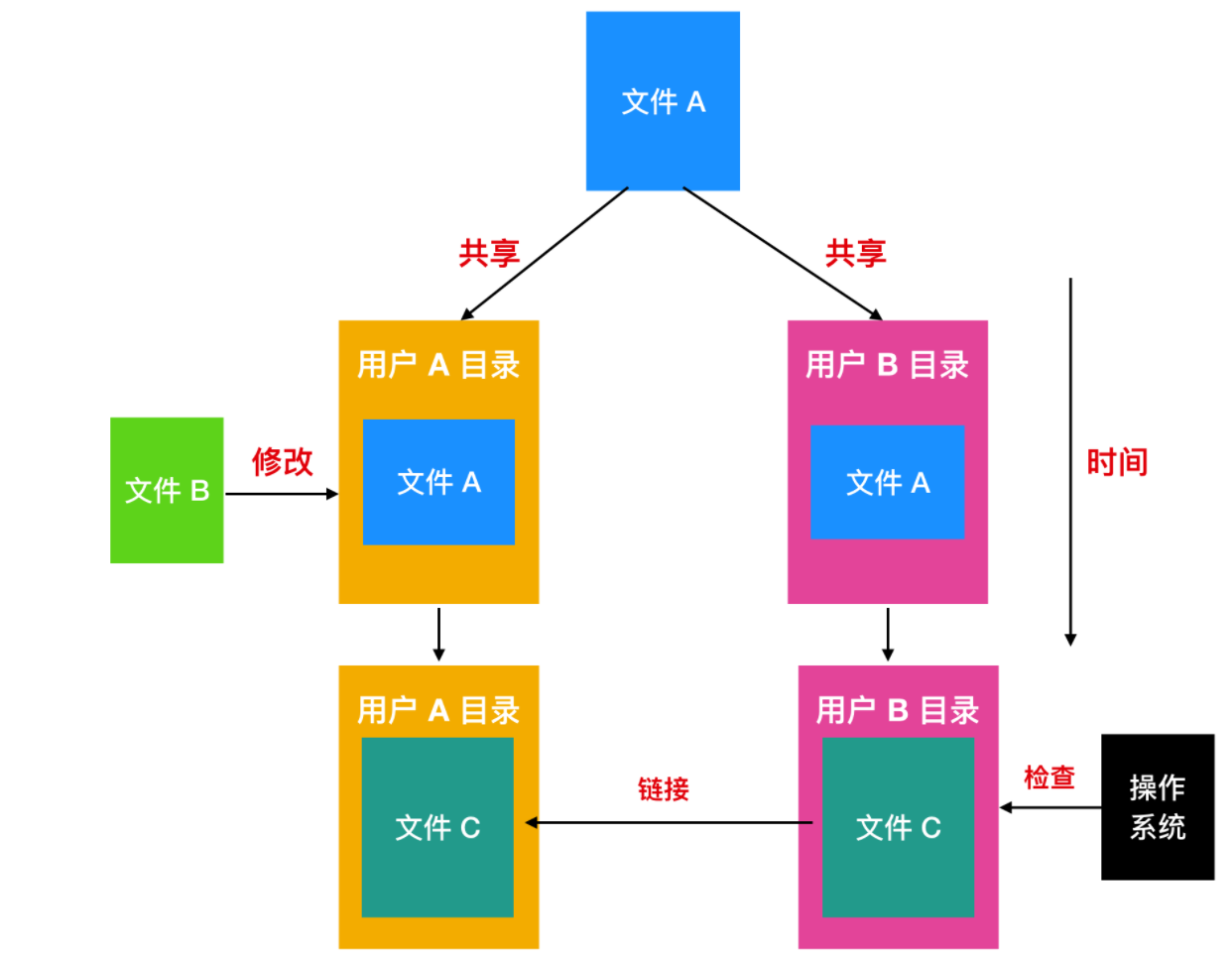
上面的每一種方法都有各自的缺點,在第一種方式中,B 鏈接到共享文件時,inode 記錄文件的所有者為 C。建立一個鏈接并不改變所有關系,如下圖所示。

第一開始的情況如圖 a 所示,此時 C 的目錄的所有者是 C ,當目錄 B 鏈接到共享文件時,并不會改變 C 的所有者關系,只是把計數 + 1,所以此時 系統知道目前有多少個目錄指向這個文件。然后 C 嘗試刪除這個文件,這個時候有個問題,如果 C 把文件移除并清除了 inode 的話,那么 B 會有一個目錄項指向無效的節點。如果 inode 以后分配給另一個文件,則 B 的鏈接指向一個錯誤的文件。系統通過 inode 可知文件仍在被引用,但是沒有辦法找到該文件的全部目錄項以刪除它們。指向目錄的指針不能存儲在 inode 中,原因是有可能有無數個這樣的目錄。
所以我們能做的就是刪除 C 的目錄項,但是將 inode 保留下來,并將計數設置為 1 ,如上圖 c 所示。c 表示的是只有 B 有指向該文件的目錄項,而該文件的前者是 C 。如果系統進行記賬操作的話,那么 C 將繼續為該文件付賬直到 B 決定刪除它,如果是這樣的話,只有到計數變為 0 的時刻,才會刪除該文件。
對于符號鏈接,以上問題不會發生,只有真正的文件所有者才有一個指向 inode 的指針。鏈接到該文件上的用戶只有路徑名,沒有指向 inode 的指針。當文件所有者刪除文件時,該文件被銷毀。以后若試圖通過符號鏈接訪問該文件將會失敗,因為系統不能找到該文件。刪除符號鏈接不會影響該文件。
符號鏈接的問題是需要額外的開銷。必須讀取包含路徑的文件,然后要一個部分接一個部分地掃描路徑,直到找到 inode 。這些操作也許需要很多次額外的磁盤訪問。此外,每個符號鏈接都需要額外的 inode ,以及額外的一個磁盤塊用于存儲路徑,雖然如果路徑名很短,作為一種優化,系統可以將它存儲在 inode 中。符號鏈接有一個優勢,即只要簡單地提供一個機器的網絡地址以及文件在該機器上駐留的路徑,就可以連接全球任何地方機器上的文件。
還有另一個由鏈接帶來的問題,在符號鏈接和其他方式中都存在。如果允許鏈接,文件有兩個或多個路徑。查找一指定目錄及其子目錄下的全部文件的程序將多次定位到被鏈接的文件。例如,一個將某一目錄及其子目錄下的文件轉存到磁帶上的程序有可能多次復制一個被鏈接的文件。進而,如果接著把磁帶讀入另一臺機器,除非轉出程序具有智能,否則被鏈接的文件將被兩次復制到磁盤上,而不是只是被鏈接起來。
日志結構文件系統
技術的改變會給當前的文件系統帶來壓力。這種情況下,CPU 會變得越來越快,磁盤會變得越來越大并且越來越便宜(但不會越來越快)。內存容量也是以指數級增長。但是磁盤的尋道時間(除了固態盤,因為固態盤沒有尋道時間)并沒有獲得提高。
這些因素結合起來意味著許多系統文件中出現性能瓶頸。為此,Berkeley 設計了一種全新的文件系統,試圖緩解這個問題,這個文件系統就是 日志結構文件系統(Log-structured File System, LFS)。
日志結構文件系統由 Rosenblum 和 Ousterhout 于90年代初引入,旨在解決以下問題。
-
不斷增長的系統內存
-
順序 I/O 性能勝過隨機 I/O 性能
-
現有低效率的文件系統
-
文件系統不支持 RAID(虛擬化)
另一方面,當時的文件系統不論是 UNIX 還是 FFS,都有大量的隨機讀寫(在 FFS 中創建一個新文件至少需要5次隨機寫),因此成為整個系統的性能瓶頸。同時因為 Page cache 的存在,作者認為隨機讀不是主要問題:隨著越來越大的內存,大部分的讀操作都能被 cache,因此 LFS 主要要解決的是減少對硬盤的隨機寫操作。
在這種設計中,inode 甚至具有與 UNIX 中相同的結構,但是現在它們分散在整個日志中,而不是位于磁盤上的固定位置。所以,inode 很定位。為了能夠找到 inode ,維護了一個由 inode 索引的 inode map(inode 映射)。表項 i 指向磁盤中的第 i 個 inode 。這個映射保存在磁盤中,但是也保存在緩存中,因此,使用最頻繁的部分大部分時間都在內存中。
日志結構文件系統主要使用四種數據結構:Inode、Inode Map、Segment、Segment Usage Table。
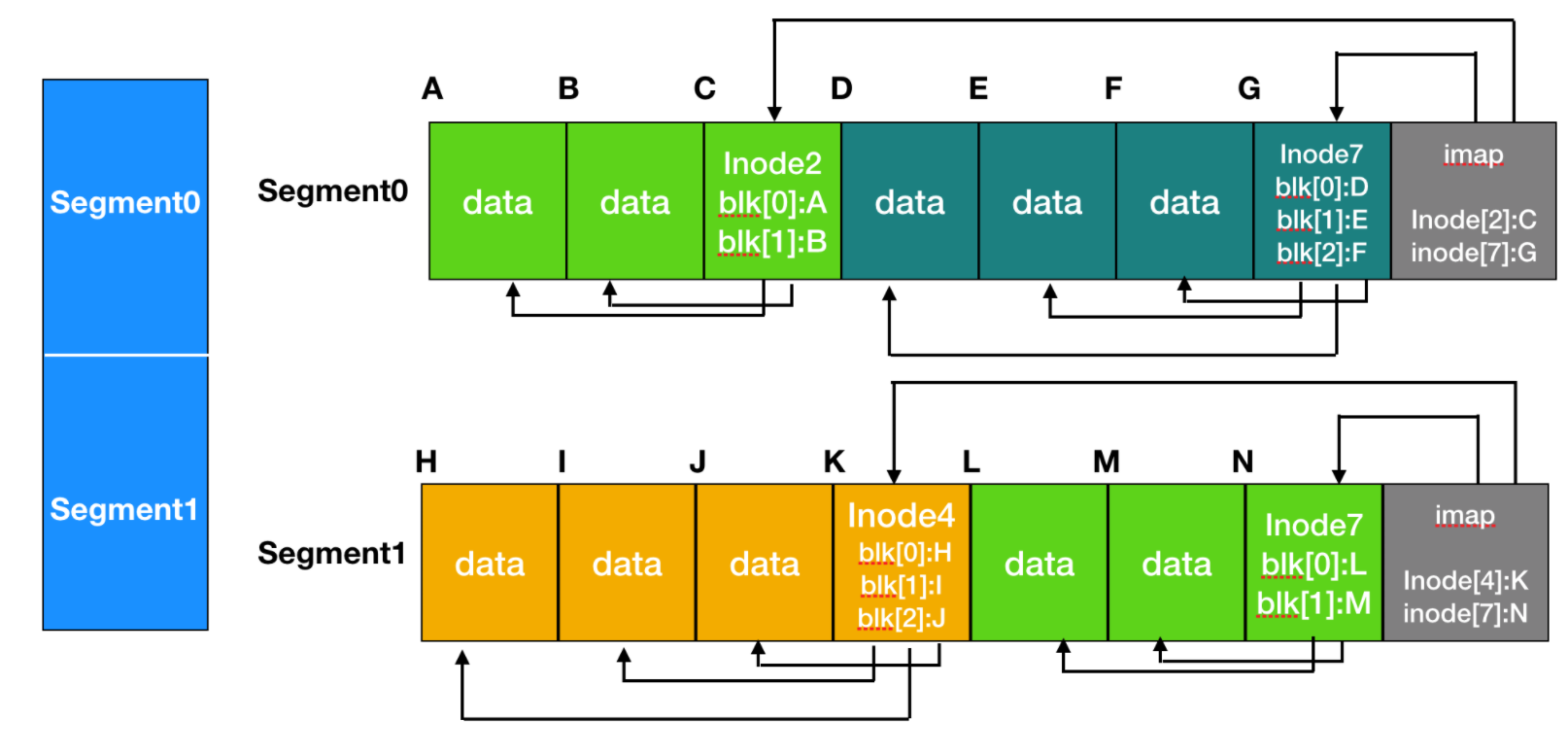
到目前為止,所有寫入最初都緩存在內存中,并且追加在日志末尾,所有緩存的寫入都定期在單個段中寫入磁盤。所以,現在打開文件也就意味著用映射定位文件的索引節點。一旦 inode 被定位后,磁盤塊的地址就能夠被找到。所有這些塊本身都將位于日志中某處的分段中。
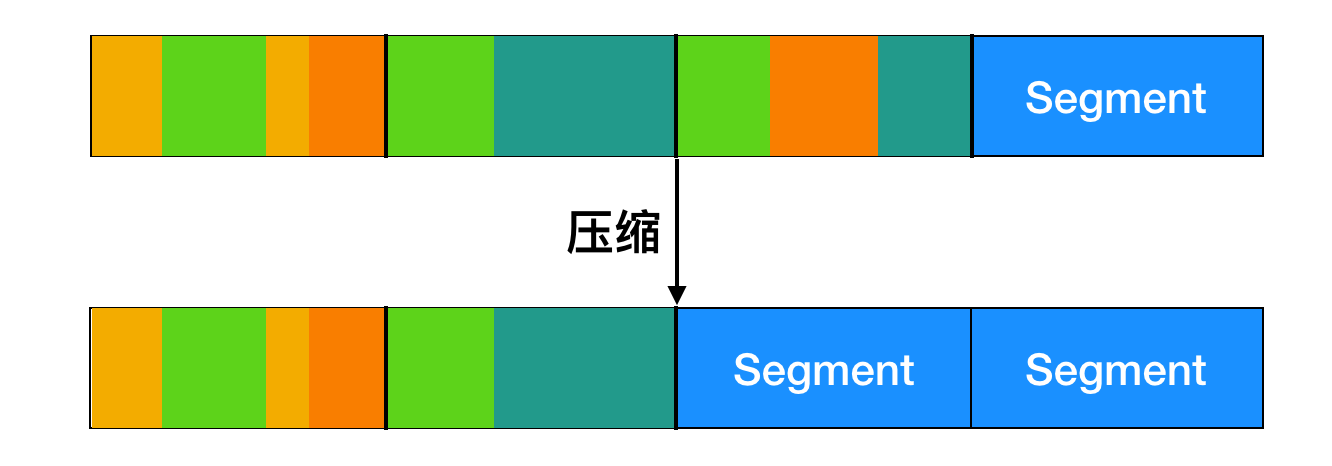
真實情況下的磁盤容量是有限的,所以最終日志會占滿整個磁盤空間,這種情況下就會出現沒有新的磁盤塊被寫入到日志中。幸運的是,許多現有段可能具有不再需要的塊。例如,如果一個文件被覆蓋了,那么它的 inode 將被指向新的塊,但是舊的磁盤塊仍在先前寫入的段中占據著空間。
為了處理這個問題,LFS 有一個清理(clean)線程,它會循環掃描日志并對日志進行壓縮。首先,通過查看日志中第一部分的信息來查看其中存在哪些索引節點和文件。它會檢查當前 inode 的映射來查看 inode 否在在當前塊中,是否仍在被使用。如果不是,該信息將被丟棄。如果仍然在使用,那么 inode 和塊就會進入內存等待寫回到下一個段中。然后原來的段被標記為空閑,以便日志可以用來存放新的數據。用這種方法,清理線程遍歷日志,從后面移走舊的段,然后將有效的數據放入內存等待寫到下一個段中。由此一來整個磁盤會形成一個大的環形緩沖區,寫線程將新的段寫在前面,而清理線程則清理后面的段。
日志文件系統
雖然日志結構系統的設計很優雅,但是由于它們和現有的文件系統不相匹配,因此還沒有廣泛使用。不過,從日志文件結構系統衍生出來一種新的日志系統,叫做日志文件系統,它會記錄系統下一步將要做什么的日志。微軟的 NTFS 文件系統、Linux 的 ext3 就使用了此日志。 OS X 將日志系統作為可供選項。為了看清它是如何工作的,我們下面討論一個例子,比如 移除文件 ,這個操作在 UNIX 中需要三個步驟完成:
- 在目錄中刪除文件
- 釋放 inode 到空閑 inode 池
- 將所有磁盤塊歸還給空閑磁盤池。
在 Windows 中,也存在類似的步驟。不存在系統崩潰時,這些步驟的執行順序不會帶來問題。但是一旦系統崩潰,就會帶來問題。假如在第一步完成后系統崩潰。inode 和文件塊將不會被任何文件獲得,也不會再分配;它們只存在于廢物池中的某個地方,并因此減少了可利用的資源。如果崩潰發生在第二步后,那么只有磁盤塊會丟失。日志文件系統保留磁盤寫入期間對文件系統所做的更改的日志或日志,該日志可用于快速重建可能由于系統崩潰或斷電等事件而發生的損壞。
一般文件系統崩潰后必須運行
fsck(文件系統一致性檢查)實用程序。
為了讓日志能夠正確工作,被寫入的日志操作必須是 冪等的(idempotent),它意味著只要有必要,它們就可以重復執行很多次,并不會帶來破壞。像操作 更新位表并標記 inode k 或者塊 n 是空閑的 可以重復執行任意次。同樣地,查找一個目錄并且刪除所有叫 foobar 的項也是冪等的。相反,把從 inode k 新釋放的塊加入空閑表的末端不是冪等的,因為它們可能已經被釋放并存放在那里了。
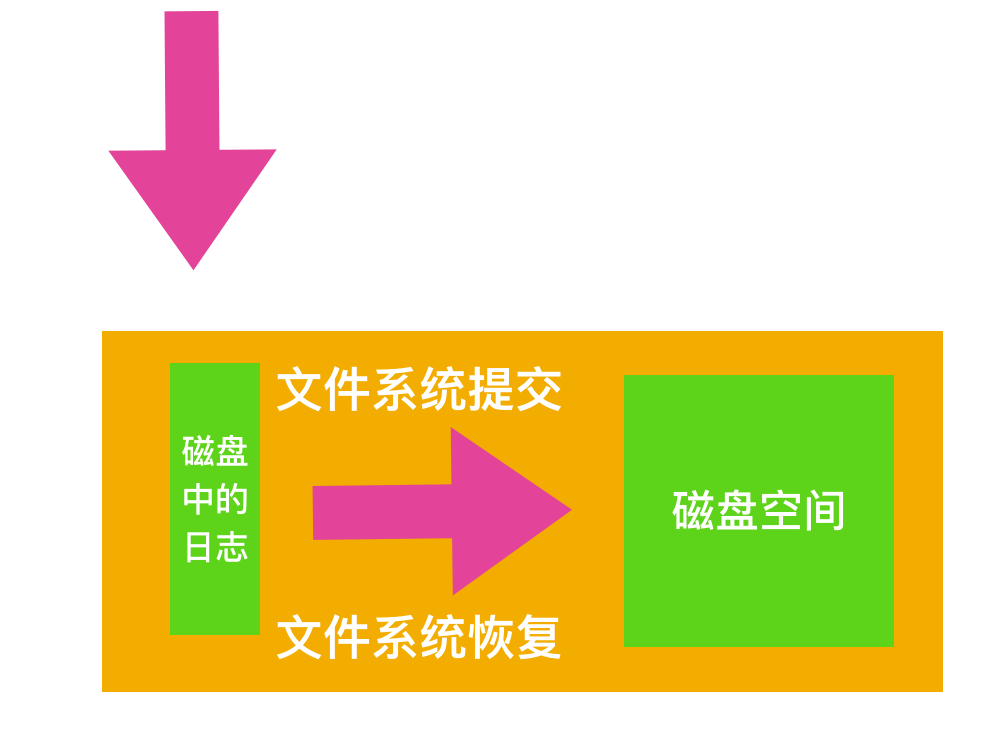
為了增加可靠性,一個文件系統可以引入數據庫中 原子事務(atomic transaction) 的概念。使用這個概念,一組動作可以被界定在開始事務和結束事務操作之間。這樣,文件系統就會知道它必須完成所有的動作,要么就一個不做。
虛擬文件系統
即使在同一臺計算機上或者在同一個操作系統下,都會使用很多不同的文件系統。Windows 中的主要文件系統是 NTFS 文件系統,但不是說 Windows 只有 NTFS 操作系統,它還有一些其他的例如舊的 FAT -32 或 FAT -16 驅動器或分區,其中包含仍需要的數據,閃存驅動器,舊的 CD-ROM 或 DVD(每個都有自己的獨特文件系統)。Windows 通過指定不同的盤符來處理這些不同的文件系統,比如 C:,D: 等。盤符可以顯示存在也可以隱式存在,如果你想找指定位置的文件,那么盤符是顯示存在;如果當一個進程打開一個文件時,此時盤符是隱式存在,所以 Windows 知道向哪個文件系統傳遞請求。
相比之下,UNIX 采用了一種不同的方式,即 UNIX 把多種文件系統整合到一個統一的結構中。一個 Linux 系統可以使用 ext2 作為根文件系統,ext3 分區裝載在 /usr 下,另一塊采用 Reiser FS 文件系統的硬盤裝載到 /home下,以及一個 ISO 9660 的 CD - ROM 臨時裝載到 /mnt 下。從用戶的觀點來看,只有一個文件系統層級,但是事實上它們是由多個文件系統組合而成,對于用戶和進程是不可見的。
UNIX 操作系統使用一種 虛擬文件系統(Virtual File System, VFS) 來嘗試將多種文件系統構成一個有序的結構。關鍵的思想是抽象出所有文件系統都共有的部分,并將這部分代碼放在一層,這一層再調用具體文件系統來管理數據。下面是一個 VFS 的系統結構
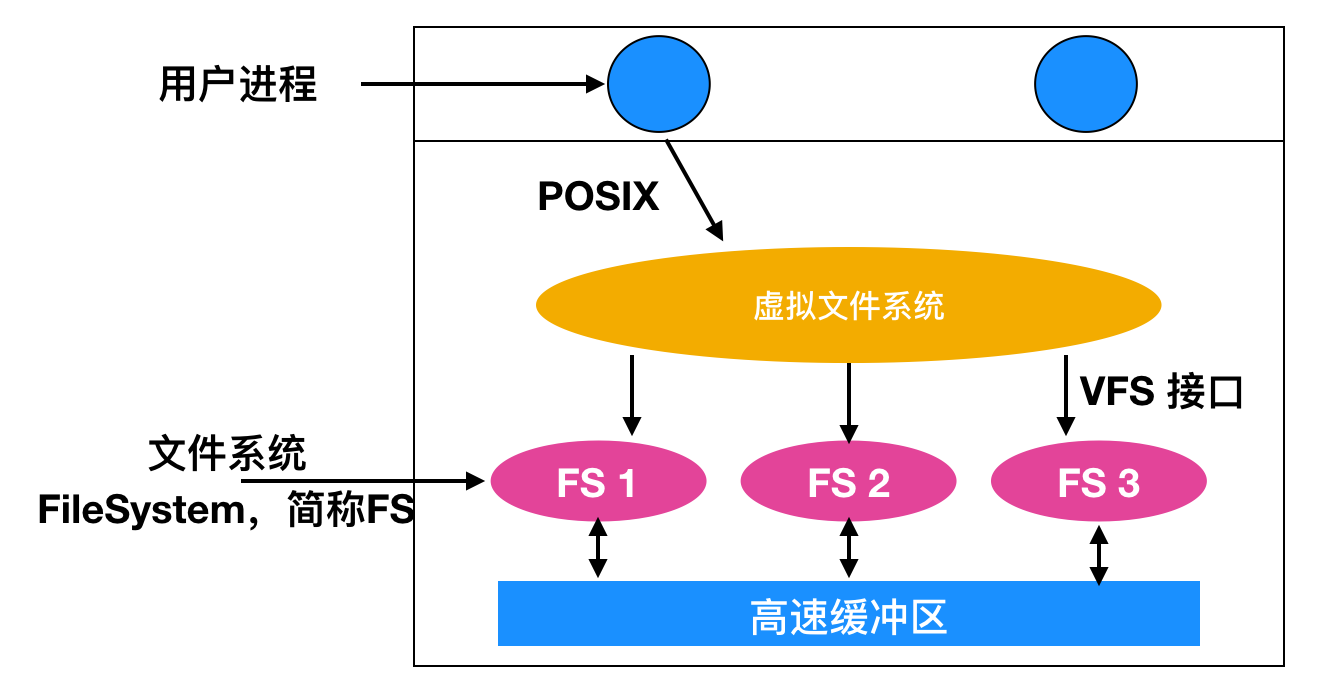
還是那句經典的話,在計算機世界中,任何解決不了的問題都可以加個代理來解決。所有和文件相關的系統調用在最初的處理上都指向虛擬文件系統。這些來自用戶進程的調用,都是標準的 POSIX 系統調用,比如 open、read、write 和 seek 等。VFS 對用戶進程有一個 上層 接口,這個接口就是著名的 POSIX 接口。
VFS 也有一個對于實際文件的 下層 接口,就是上圖中標記為 VFS 的接口。這個接口包含許多功能調用,這樣 VFS 可以使每一個文件系統完成任務。因此,要創建一個可以與 VFS 一起使用的新文件系統,新文件系統的設計者必須確保它提供了 VFS 要求的功能。一個明顯的例子是從磁盤讀取特定的塊,然后將其放入文件系統的緩沖區高速緩存中,然后返回指向該塊的指針的函數。 因此,VFS具有兩個不同的接口:上一個到用戶進程,下一個到具體文件系統。
當系統啟動時,根文件系統在 VFS 中注冊。另外,當裝載其他文件時,不管在啟動時還是在操作過程中,它們也必須在 VFS 中注冊。當一個文件系統注冊時,根文件系統注冊到 VFS。另外,在引導時或操作期間掛載其他文件系統時,它們也必須向 VFS 注冊。當文件系統注冊時,其基本作用是提供 VFS 所需功能的地址列表、調用向量表、或者 VFS 對象。因此一旦文件系統注冊到 VFS,它就知道從哪里開始讀取數據塊。
裝載文件系統后就可以使用它了。比如,如果一個文件系統裝載到 /usr 并且一個進程調用它:
open("/usr/include/unistd.h",O_RDONLY)
當解析路徑時, VFS 看到新的文件系統被掛載到 /usr,并且通過搜索已經裝載文件系統的超級塊來確定它的超塊。然后它找到它所轉載的文件的根目錄,在那里查找路徑 include/unistd.h。然后 VFS 創建一個 vnode 并調用實際文件系統,以返回所有的在文件 inode 中的信息。這個信息和其他信息一起復制到 vnode (內存中)。而這些其他信息中最重要的是指向包含調用 vnode 操作的函數表的指針,比如 read、write 和 close 等。
當 vnode 被創建后,為了進程調用,VFS 在文件描述符表中創建一個表項,并將它指向新的 vnode,最后,VFS 向調用者返回文件描述符,所以調用者可以用它去 read、write 或者 close 文件。
當進程用文件描述符進行一個讀操作時,VFS 通過進程表和文件描述符確定 vnode 的位置,并跟隨指針指向函數表,這樣就調用了處理 read 函數,運行在實際系統中的代碼并得到所請求的塊。VFS 不知道請求時來源于本地硬盤、還是來源于網絡中的遠程文件系統、CD-ROM 、USB 或者其他介質,所有相關的數據結構歐如下圖所示
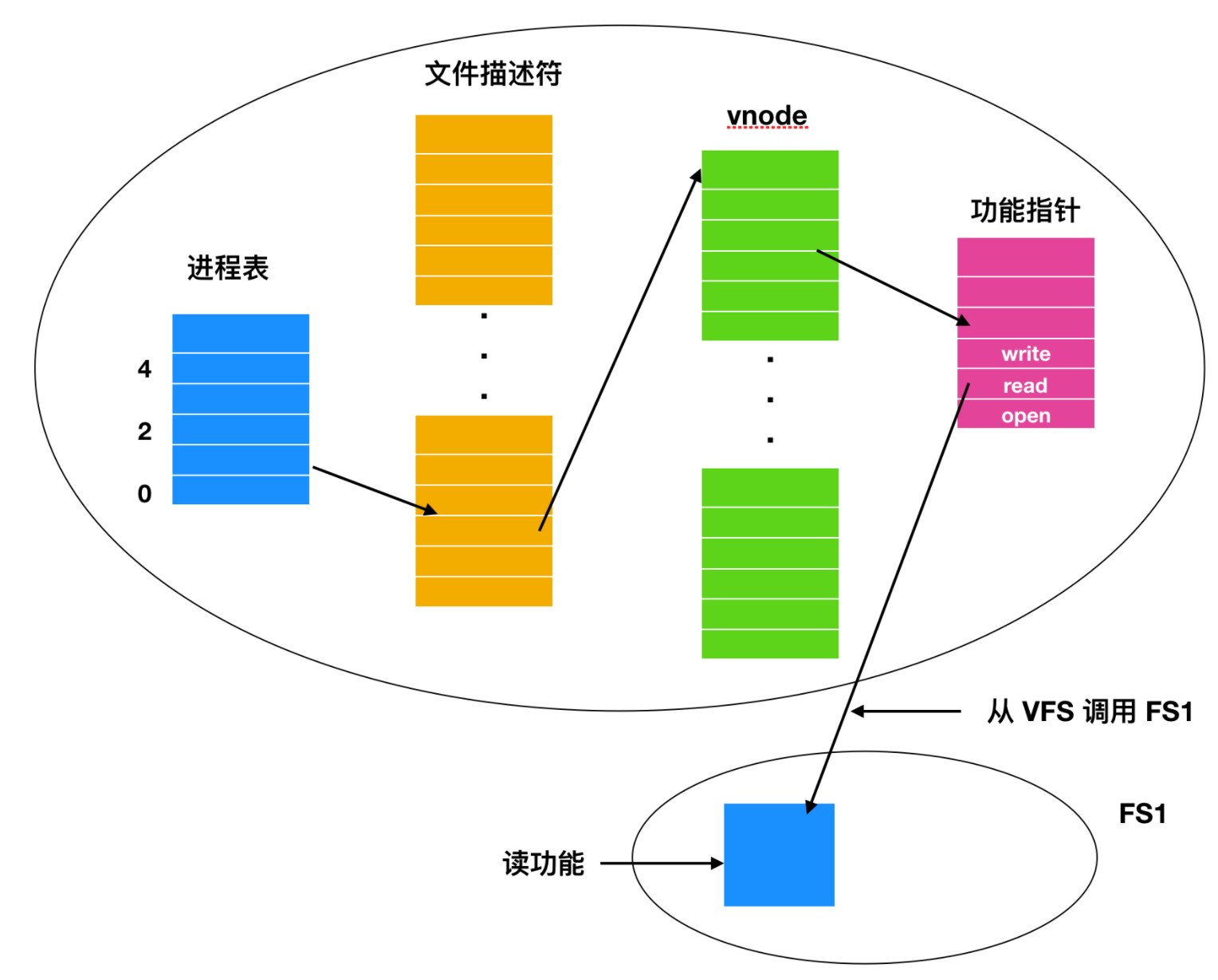
從調用者進程號和文件描述符開始,進而是 vnode,讀函數指針,然后是對實際文件系統的訪問函數定位。
文件系統的管理和優化
能夠使文件系統工作是一回事,能夠使文件系統高效、穩定的工作是另一回事,下面我們就來探討一下文件系統的管理和優化。
磁盤空間管理
文件通常存在磁盤中,所以如何管理磁盤空間是一個操作系統的設計者需要考慮的問題。在文件上進行存有兩種策略:分配 n 個字節的連續磁盤空間;或者把文件拆分成多個并不一定連續的塊。在存儲管理系統中,主要有分段管理和 分頁管理 兩種方式。
正如我們所看到的,按連續字節序列存儲文件有一個明顯的問題,當文件擴大時,有可能需要在磁盤上移動文件。內存中分段也有同樣的問題。不同的是,相對于把文件從磁盤的一個位置移動到另一個位置,內存中段的移動操作要快很多。因此,幾乎所有的文件系統都把文件分割成固定大小的塊來存儲。
塊大小
一旦把文件分為固定大小的塊來存儲,就會出現問題,塊的大小是多少?按照磁盤組織方式,扇區、磁道和柱面顯然都可以作為分配單位。在分頁系統中,分頁大小也是主要因素。
擁有大的塊尺寸意味著每個文件,甚至 1 字節文件,都要占用一個柱面空間,也就是說小文件浪費了大量的磁盤空間。另一方面,小塊意味著大部分文件將會跨越多個塊,因此需要多次搜索和旋轉延遲才能讀取它們,從而降低了性能。因此,如果分配的塊太大會浪費空間;分配的塊太小會浪費時間。
記錄空閑塊
一旦指定了塊大小,下一個問題就是怎樣跟蹤空閑塊。有兩種方法被廣泛采用,如下圖所示
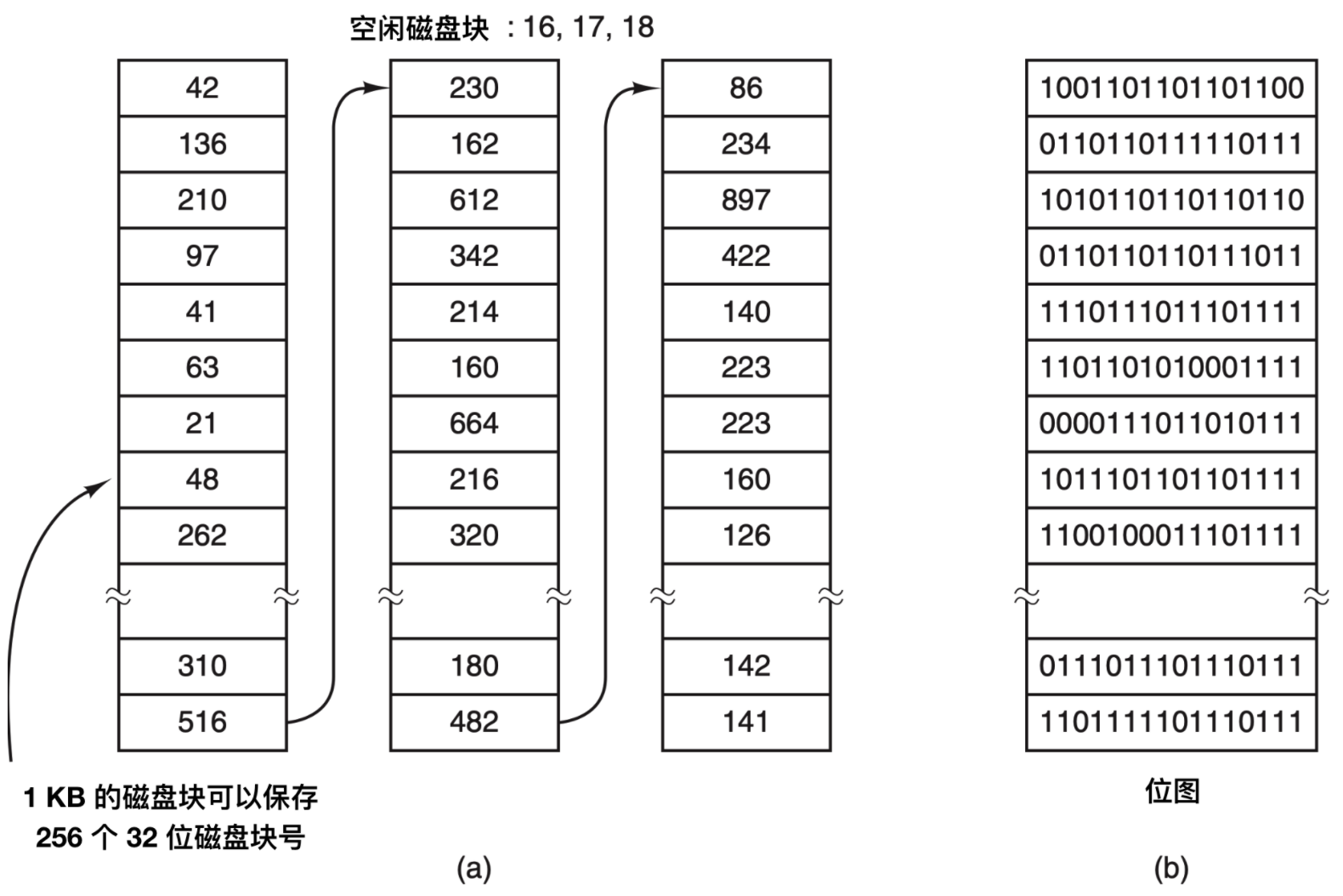
第一種方法是采用磁盤塊鏈表,鏈表的每個塊中包含極可能多的空閑磁盤塊號。對于 1 KB 的塊和 32 位的磁盤塊號,空閑表中每個塊包含有 255 個空閑的塊號。考慮 1 TB 的硬盤,擁有大概十億個磁盤塊。為了存儲全部地址塊號,如果每塊可以保存 255 個塊號,則需要將近 400 萬個塊。通常,空閑塊用于保存空閑列表,因此存儲基本上是空閑的。
另一種空閑空間管理的技術是位圖(bitmap),n 個塊的磁盤需要 n 位位圖。在位圖中,空閑塊用 1 表示,已分配的塊用 0 表示。對于 1 TB 硬盤的例子,需要 10 億位表示,即需要大約 130 000 個 1 KB 塊存儲。很明顯,和 32 位鏈表模型相比,位圖需要的空間更少,因為每個塊使用 1 位。只有當磁盤快滿的時候,鏈表需要的塊才會比位圖少。
如果空閑塊是長期連續的話,那么空閑列表可以改成記錄連續分塊而不是單個的塊。每個塊都會使用 8位、16位、32 位的計數來與每個塊相聯,來記錄連續空閑塊的數量。最好的情況是一個空閑塊可以用兩個數字來表示:第一個空閑塊的地址和空閑塊的計數。另一方面,如果磁盤嚴重碎片化,那么跟蹤連續分塊要比跟蹤單個分塊運行效率低,因為不僅要存儲地址,還要存儲數量。
這種情況說明了一個操作系統設計者經常遇到的一個問題。有許多數據結構和算法可以用來解決問題,但是選擇一個
最好的方案需要數據的支持,而這些數據是設計者無法預先擁有的。只有在系統部署完畢真正使用使用后才會獲得。
現在,回到空閑鏈表的方法,只有一個指針塊保存在內存中。創建文件時,所需要的塊從指針塊中取出。當它用完時,將從磁盤中讀取一個新的指針塊。類似地,刪除文件時,文件的塊將被釋放并添加到主存中的指針塊中。當塊被填滿時,寫回磁盤。
在某些特定的情況下,這個方法導致了不必要的磁盤 IO,如下圖所示
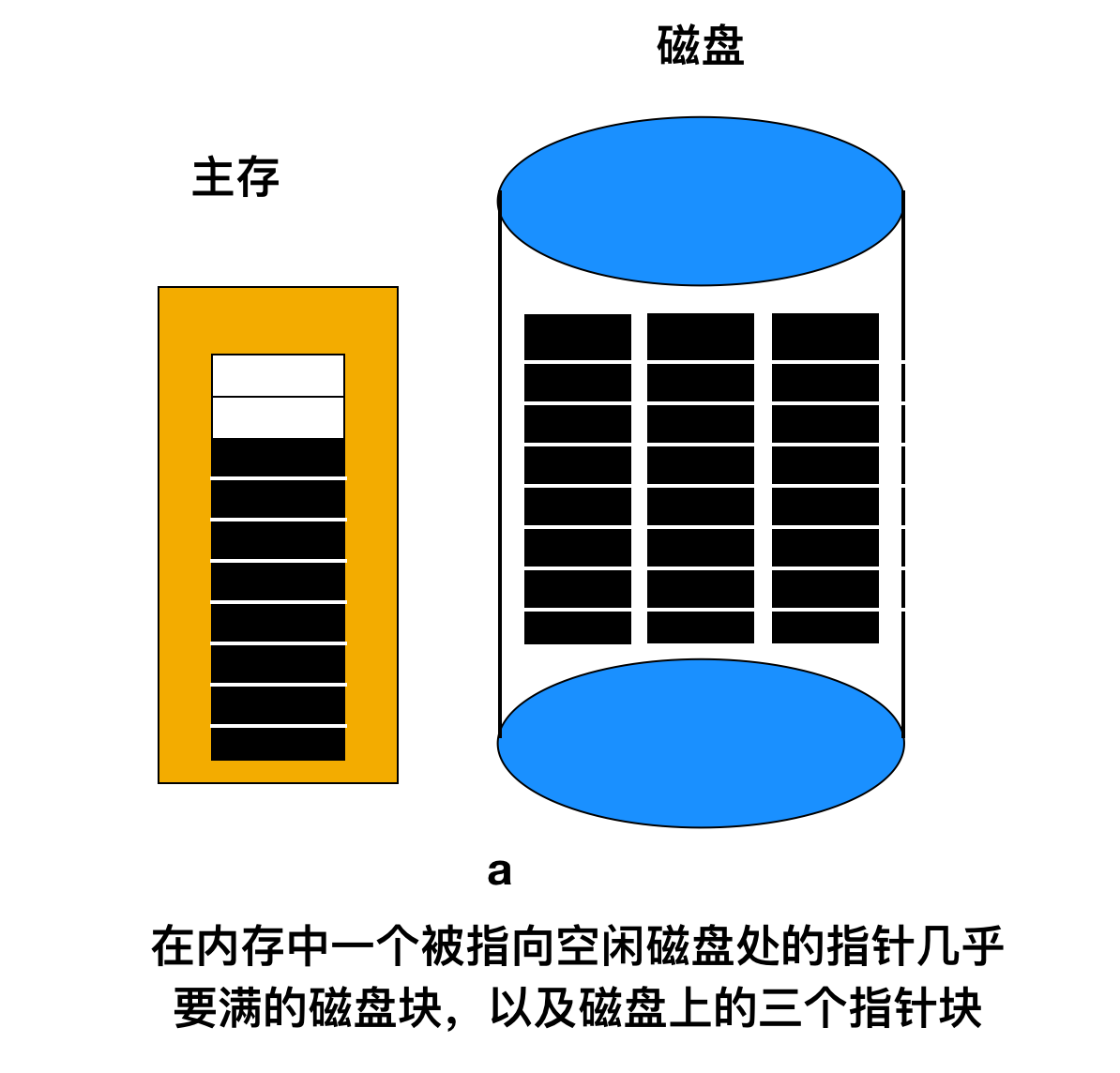
上面內存中的指針塊僅有兩個空閑塊,如果釋放了一個含有三個磁盤塊的文件,那么該指針塊就會溢出,必須將其寫入磁盤,那么就會產生如下圖的這種情況。
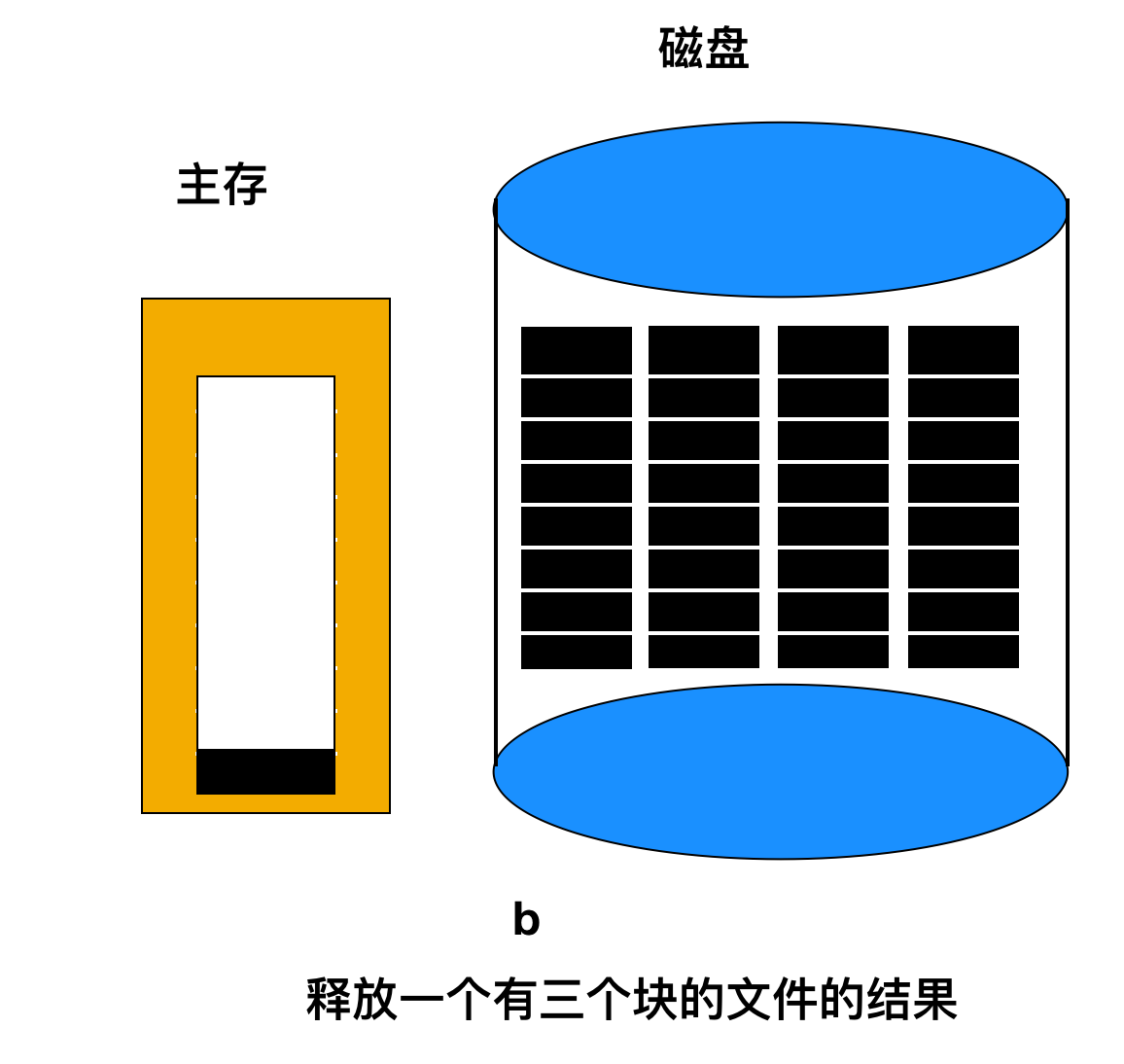
如果現在寫入含有三個塊的文件,已滿的指針不得不再次讀入,這將會回到上圖 a 中的情況。如果有三個塊的文件只是作為臨時文件被寫入,在釋放它時,需要進行另一次磁盤寫操作以將完整的指針塊寫回到磁盤。簡而言之,當指針塊幾乎為空時,一系列短暫的臨時文件可能會導致大量磁盤 I/O。
避免大部分磁盤 I/O 的另一種方法是拆分完整的指針塊。這樣,當釋放三個塊時,變化不再是從 a - b,而是從 a - c,如下圖所示
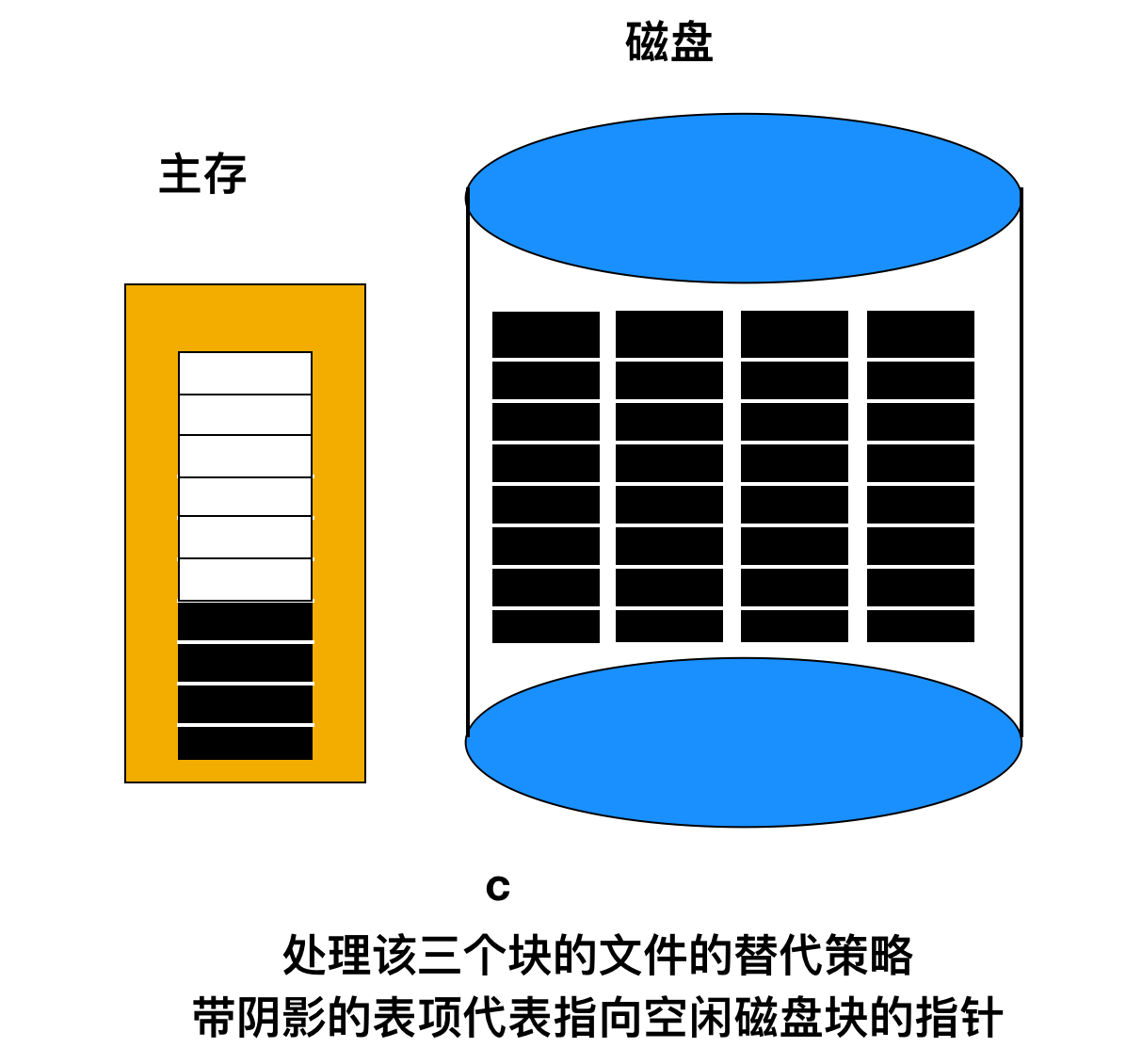
現在,系統可以處理一系列臨時文件,而不需要進行任何磁盤 I/O。如果內存中指針塊滿了,就寫入磁盤,半滿的指針塊從磁盤中讀入。這里的思想是:要保持磁盤上的大多數指針塊為滿的狀態(減少磁盤的使用),但是在內存中保留了一個半滿的指針塊。這樣,就可以既處理文件的創建又同時可以處理文件的刪除操作,而不會為空閑表進行磁盤 I/O。
對于位圖,會在內存中只保留一個塊,只有在該塊滿了或空了的情形下,才到磁盤上取另一個塊。通過在位圖的單一塊上進行所有的分配操作,磁盤塊會緊密的聚集在一起,從而減少了磁盤臂的移動。由于位圖是一種固定大小的數據結構,所以如果內核是分頁的,就可以把位圖放在虛擬內存中,在需要時將位圖的頁面調入。
磁盤配額
為了防止一些用戶占用太多的磁盤空間,多用戶操作通常提供一種磁盤配額(enforcing disk quotas)的機制。系統管理員為每個用戶分配最大的文件和塊分配,并且操作系統確保用戶不會超過其配額。我們下面會談到這一機制。
在用戶打開一個文件時,操作系統會找到文件屬性和磁盤地址,并把它們送入內存中的打開文件表。其中一個屬性告訴文件所有者是誰。任何有關文件的增加都會記到所有者的配額中。
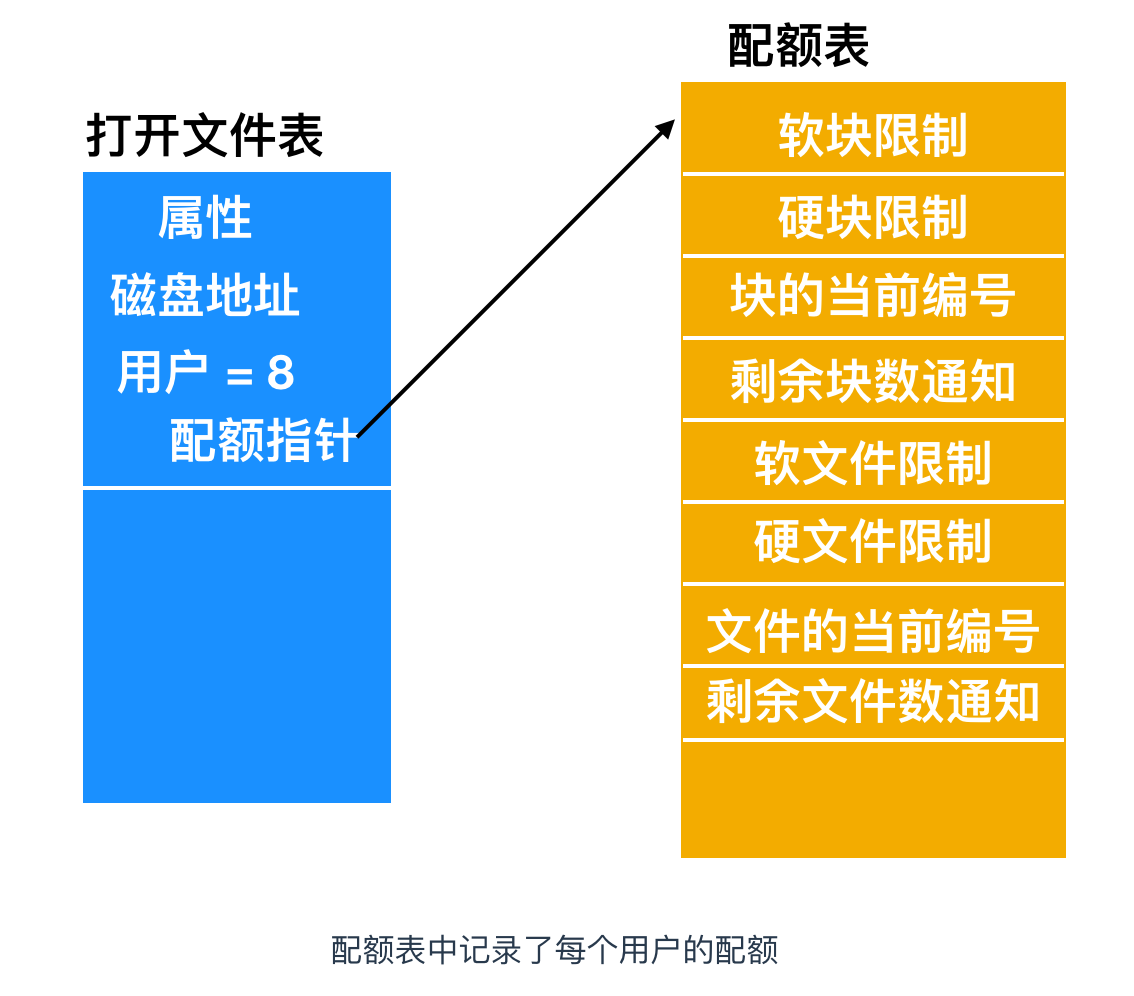
第二張表包含了每個用戶當前打開文件的配額記錄,即使是其他人打開該文件也一樣。如上圖所示,該表的內容是從被打開文件的所有者的磁盤配額文件中提取出來的。當所有文件關閉時,該記錄被寫回配額文件。
當在打開文件表中建立一新表項時,會產生一個指向所有者配額記錄的指針。每次向文件中添加一個塊時,文件所有者所用數據塊的總數也隨之增加,并會同時增加硬限制和軟限制的檢查。可以超出軟限制,但硬限制不可以超出。當已達到硬限制時,再往文件中添加內容將引發錯誤。同樣,對文件數目也存在類似的檢查。
什么是硬限制和軟限制?硬限制是軟限制的上限。軟限制是為會話或進程實際執行的限制。這允許管理員(或用戶)將硬限制設置為允許它們希望允許的最大使用上限。然后,其他用戶和進程可以根據需要使用軟限制將其資源使用量自限制到更低的上限。
當一個用戶嘗試登陸,系統將檢查配額文件以查看用戶是否超出了文件數量或磁盤塊數量的軟限制。如果違反了任一限制,則會顯示警告,保存的警告計數減 1,如果警告計數為 0 ,表示用戶多次忽略該警告,因而將不允許該用戶登錄。要想再得到登錄的許可,就必須與系統管理員協商。
如果用戶在退出系統時消除所超過的部分,他們就可以再一次終端會話期間超過其軟限制,但無論什么情況下都不會超過硬限制。
文件系統備份
文件系統的毀壞要比計算機的損壞嚴重很多。無論是硬件還是軟件的故障,只要計算機文件系統被破壞,要恢復起來都是及其困難的,甚至是不可能的。因為文件系統無法抵御破壞,因而我們要在文件系統在被破壞之前做好數據備份,但是備份也不是那么容易,下面我們就來探討備份的過程。
許多人認為為文件系統做備份是不值得的,并且很浪費時間,直到有一天他們的磁盤壞了,他們才意識到事情的嚴重性。相對來說,公司在這方面做的就很到位。磁帶備份主要要處理好以下兩個潛在問題中的一個
- 從意外的災難中恢復
這個問題主要是由于外部條件的原因造成的,比如磁盤破裂,水災火災等。
- 從錯誤的操作中恢復
第二個問題通常是由于用戶意外的刪除了原本需要還原的文件。這種情況發生的很頻繁,使得 Windows 的設計者們針對 刪除 命令專門設計了特殊目錄,這就是 回收站(recycle bin),也就是說,在刪除文件的時候,文件本身并不真正從磁盤上消失,而是被放置到這個特殊目錄下,等以后需要的時候可以還原回去。文件備份更主要是指這種情況,能夠允許幾天之前,幾周之前的文件從原來備份的磁盤進行還原。
做文件備份很耗費時間而且也很浪費空間,這會引起下面幾個問題。首先,是要備份整個文件還是僅備份一部分呢?一般來說,只是備份特定目錄及其下的全部文件,而不是備份整個文件系統。
其次,對上次未修改過的文件再進行備份是一種浪費,因而產生了一種增量轉儲(incremental dumps) 的思想。最簡單的增量轉儲的形式就是周期性的做全面的備份,而每天只對增量轉儲完成后發生變化的文件做單個備份。
周期性:比如一周或者一個月
稍微好一點的方式是只備份最近一次轉儲以來更改過的文件。當然,這種做法極大的縮減了轉儲時間,但恢復起來卻更復雜,因為最近的全面轉儲先要全部恢復,隨后按逆序進行增量轉儲。為了方便恢復,人們往往使用更復雜的轉儲模式。
第三,既然待轉儲的往往是海量數據,那么在將其寫入磁帶之前對文件進行壓縮就很有必要。但是,如果在備份過程中出現了文件損壞的情況,就會導致破壞壓縮算法,從而使整個磁帶無法讀取。所以在備份前是否進行文件壓縮需慎重考慮。
第四,對正在使用的文件系統做備份是很難的。如果在轉儲過程中要添加,刪除和修改文件和目錄,則轉儲結果可能不一致。因此,因為轉儲過程中需要花費數個小時的時間,所以有必要在晚上將系統脫機進行備份,然而這種方式的接受程度并不高。所以,人們修改了轉儲算法,記下文件系統的瞬時快照,即復制關鍵的數據結構,然后需要把將來對文件和目錄所做的修改復制到塊中,而不是到處更新他們。
磁盤轉儲到備份磁盤上有兩種方案:物理轉儲和邏輯轉儲。物理轉儲(physical dump) 是從磁盤的 0 塊開始,依次將所有磁盤塊按照順序寫入到輸出磁盤,并在復制最后一個磁盤時停止。這種程序的萬無一失性是其他程序所不具備的。
第二個需要考慮的是壞塊的轉儲。制造大型磁盤而沒有瑕疵是不可能的,所以也會存在一些壞塊(bad blocks)。有時進行低級格式化后,壞塊會被檢測出來并進行標記,這種情況的解決辦法是用磁盤末尾的一些空閑塊所替換。
然而,一些塊在格式化后會變壞,在這種情況下操作系統可以檢測到它們。通常情況下,它可以通過創建一個由所有壞塊組成的文件來解決問題,確保它們不會出現在空閑池中并且永遠不會被分配。那么此文件是完全不可讀的。如果磁盤控制器將所有的壞塊重新映射,物理轉儲還是能夠正常工作的。
Windows 系統有分頁文件(paging files) 和 休眠文件(hibernation files) 。它們在文件還原時不發揮作用,同時也不應該在第一時間進行備份。
物理轉儲和邏輯轉儲
物理轉儲的主要優點是簡單、極為快速(基本上是以磁盤的速度運行),缺點是全量備份,不能跳過指定目錄,也不能增量轉儲,也不能恢復個人文件的請求。因此句大多數情況下不會使用物理轉儲,而使用邏輯轉儲。
邏輯轉儲(logical dump)從一個或幾個指定的目錄開始,遞歸轉儲自指定日期開始后更改的文件和目錄。因此,在邏輯轉儲中,轉儲磁盤上有一系列經過仔細識別的目錄和文件,這使得根據請求輕松還原特定文件或目錄。
既然邏輯轉儲是最常用的方式,那么下面就讓我們研究一下邏輯轉儲的通用算法。此算法在 UNIX 系統上廣為使用,如下圖所示
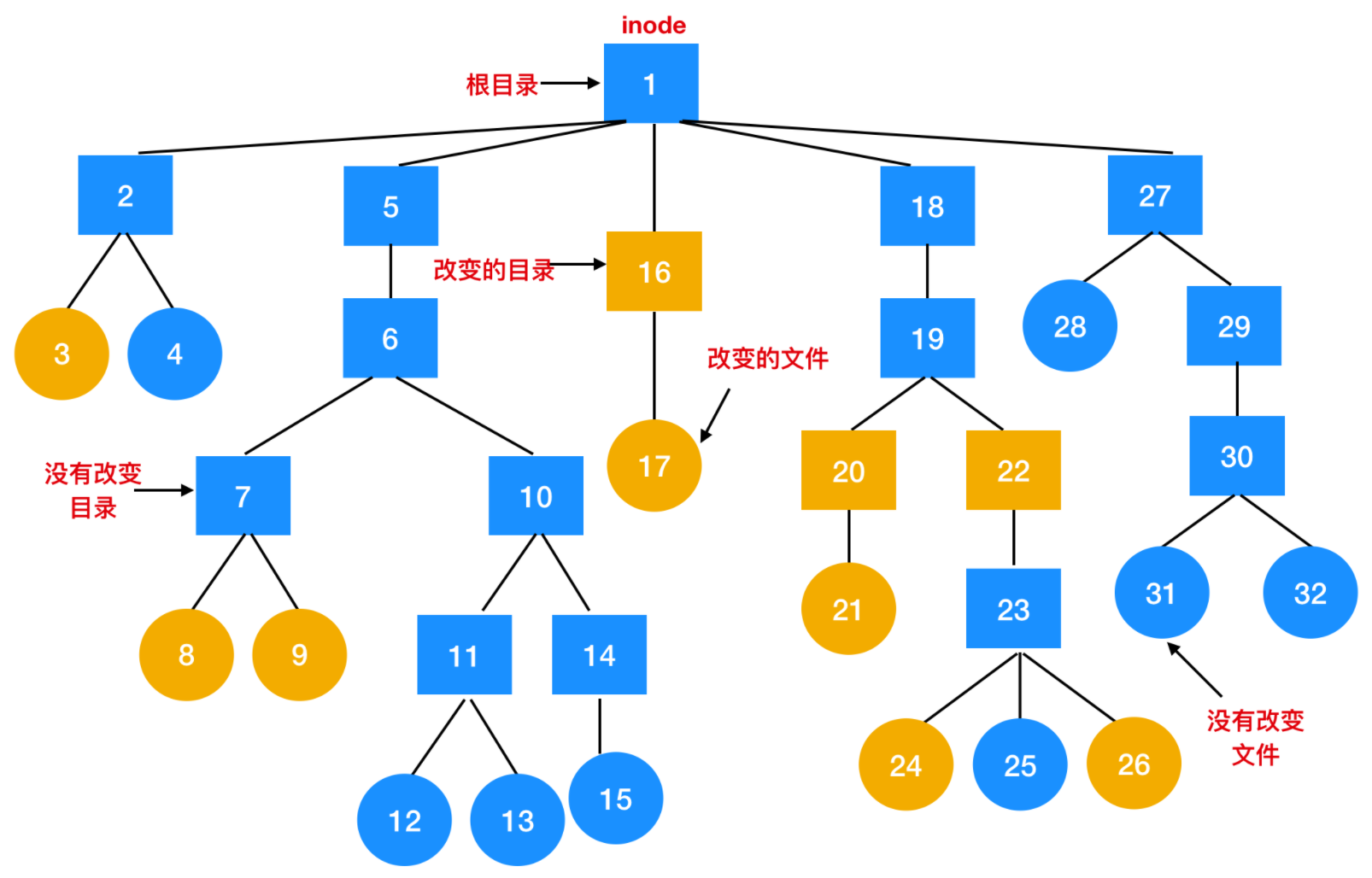
待轉儲的文件系統,其中方框代表目錄,圓圈代表文件。黃色的項目表是自上次轉儲以來修改過。每個目錄和文件都被標上其 inode 號。
此算法會轉儲位于修改文件或目錄路徑上的所有目錄(也包括未修改的目錄),原因有兩個。第一是能夠在不同電腦的文件系統中恢復轉儲的文件。通過這種方式,轉儲和重新存儲的程序能夠用來在兩個電腦之間傳輸整個文件系統。第二個原因是能夠對單個文件進行增量恢復。
邏輯轉儲算法需要維持一個 inode 為索引的位圖(bitmap),每個 inode 包含了幾位。隨著算法的進行,位圖中的這些位會被設置或清除。算法的執行分成四個階段。第一階段從起始目錄(本例為根目錄)開始檢查其中所有的目錄項。對每一個修改過的文件,該算法將在位圖中標記其 inode。算法還會標記并遞歸檢查每一個目錄(不管是否修改過)。
在第一階段結束時,所有修改過的文件和全部目錄都在位圖中標記了,如下圖所示

理論上來說,第二階段再次遞歸遍歷目錄樹,并去掉目錄樹中任何不包含被修改過的文件或目錄的標記。本階段執行的結果如下

注意,inode 編號為 10、11、14、27、29 和 30 的目錄已經被去掉了標記,因為它們所包含的內容沒有修改。它們也不會轉儲。相反,inode 編號為 5 和 6 的目錄本身盡管沒有被修改過也要被轉儲,因為在新的機器上恢復當日的修改時需要這些信息。為了提高算法效率,可以將這兩階段的目錄樹遍歷合二為一。
現在已經知道了哪些目錄和文件必須被轉儲了,這就是上圖 b 中標記的內容,第三階段算法將以節點號為序,掃描這些 inode 并轉儲所有標記為需轉儲的目錄,如下圖所示

為了進行恢復,每個被轉儲的目錄都用目錄的屬性(所有者、時間)作為前綴。

最后,在第四階段,上圖中被標記的文件也被轉儲,同樣,由其文件屬性作為前綴。至此,轉儲結束。
從轉儲磁盤上還原文件系統非常簡單。一開始,需要在磁盤上創建空文件系統。然后恢復最近一次的完整轉儲。由于磁帶上最先出現目錄,所以首先恢復目錄,給出文件系統的框架(skeleton),然后恢復文件系統本身。在完整存儲之后是第一次增量存儲,然后是第二次重復這一過程,以此類推。
盡管邏輯存儲十分簡單,但是也會有一些棘手的問題。首先,既然空閑塊列表并不是一個文件,那么在所有被轉儲的文件恢復完畢之后,就需要從零開始重新構造。
另外一個問題是關于鏈接。如果文件鏈接了兩個或者多個目錄,而文件只能還原一次,那么并且所有指向該文件的目錄都必須還原。
還有一個問題是,UNIX 文件實際上包含了許多 空洞(holes)。打開文件,寫幾個字節,然后找到文件中偏移了一定距離的地址,又寫入更多的字節,這么做是合法的。但兩者之間的這些塊并不屬于文件本身,從而也不應該在其上進行文件轉儲和恢復。
最后,無論屬于哪一個目錄,特殊文件,命名管道以及類似的文件都不應該被轉儲。
文件系統的一致性
影響可靠性的一個因素是文件系統的一致性。許多文件系統讀取磁盤塊、修改磁盤塊、再把它們寫回磁盤。如果系統在所有塊寫入之前崩潰,文件系統就會處于一種不一致(inconsistent)的狀態。如果某些尚未寫回的塊是索引節點塊,目錄塊或包含空閑列表的塊,則此問題是很嚴重的。
為了處理文件系統一致性問題,大部分計算機都會有應用程序來檢查文件系統的一致性。例如,UNIX 有 fsck;Windows 有 sfc,每當引導系統時(尤其是在崩潰后),都可以運行該程序。
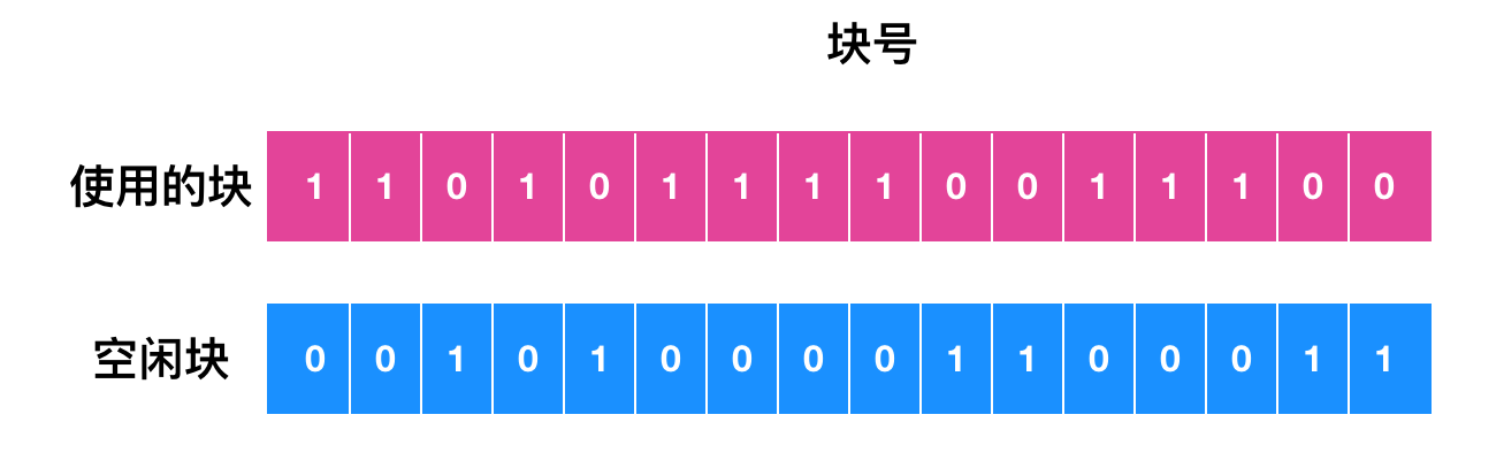
可以進行兩種一致性檢查:塊的一致性檢查和文件的一致性檢查。為了檢查塊的一致性,應用程序會建立兩張表,每個包含一個計數器的塊,最初設置為 0 。第一個表中的計數器跟蹤該塊在文件中出現的次數,第二張表中的計數器記錄每個塊在空閑列表、空閑位圖中出現的頻率。
然后檢驗程序使用原始設備讀取所有的 inode,忽略文件的結構,只返回從零開始的所有磁盤塊。從 inode 開始,很容易找到文件中的塊數量。每當讀取一個塊時,該塊在第一個表中的計數器 + 1,應用程序會檢查空閑塊或者位圖來找到沒有使用的塊。空閑列表中塊的每次出現都會導致其在第二表中的計數器增加。
如果文件系統一致,則每一個塊或者在第一個表計數器為 1,或者在第二個表計數器中為 1,如下圖所示
但是當系統崩潰后,這兩張表可能如下所示
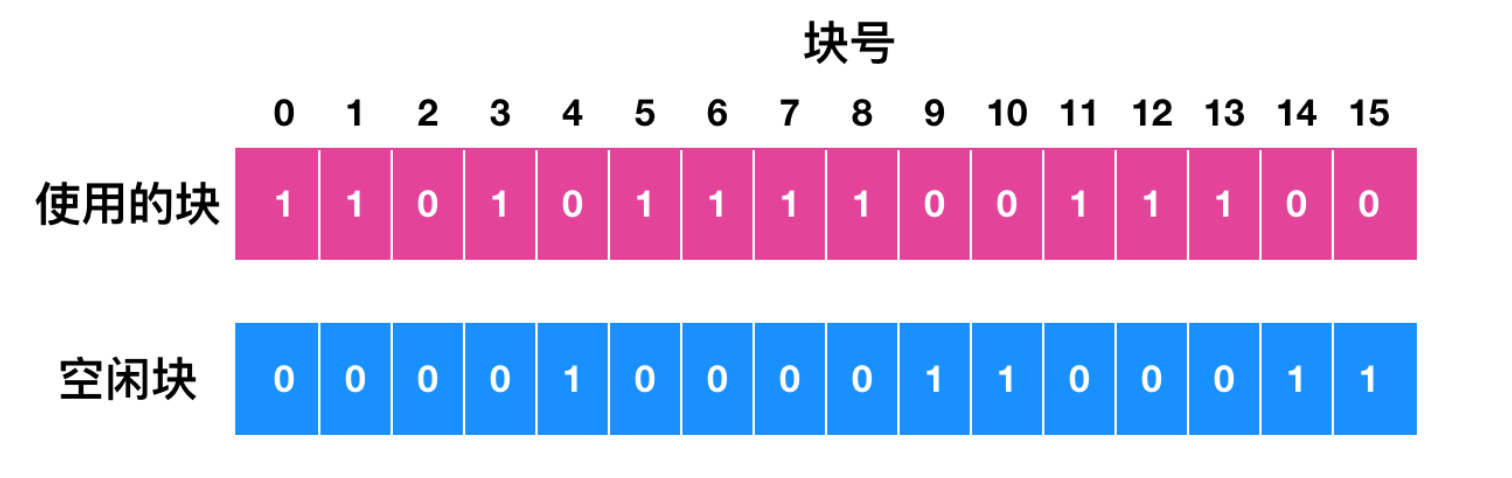
其中,磁盤塊 2 沒有出現在任何一張表中,這稱為 塊丟失(missing block)。盡管塊丟失不會造成實際的損害,但它的確浪費了磁盤空間,減少了磁盤容量。塊丟失的問題很容易解決,文件系統檢驗程序把他們加到空閑表中即可。
有可能出現的另外一種情況如下所示
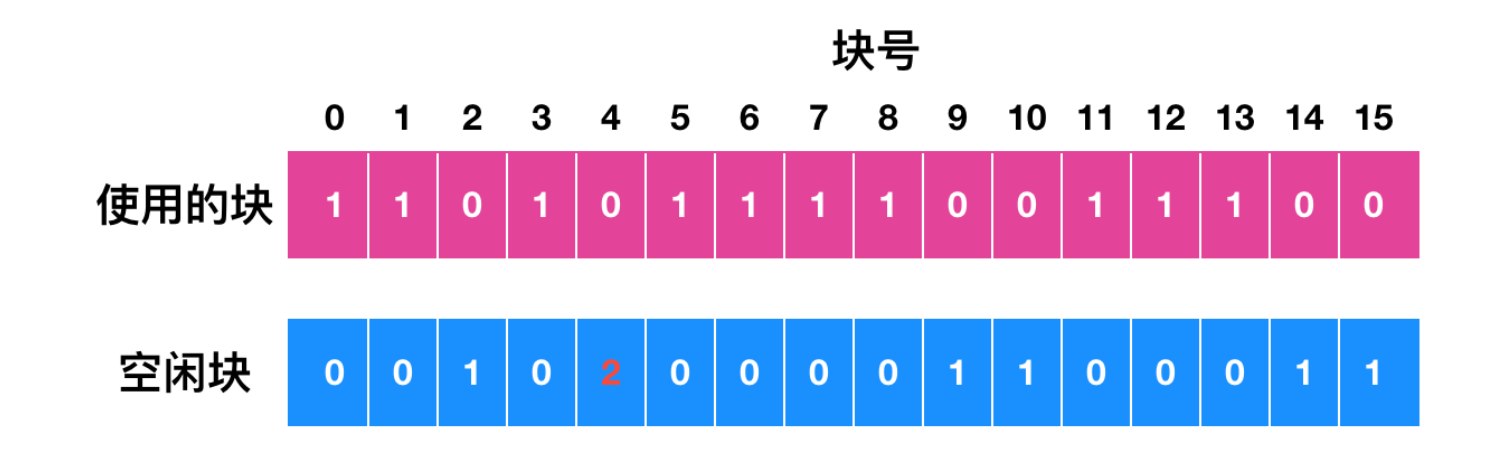
其中,塊 4 在空閑表中出現了 2 次。這種解決方法也很簡單,只要重新建立空閑表即可。
最糟糕的情況是在兩個或者多個文件中出現同一個數據塊,如下所示
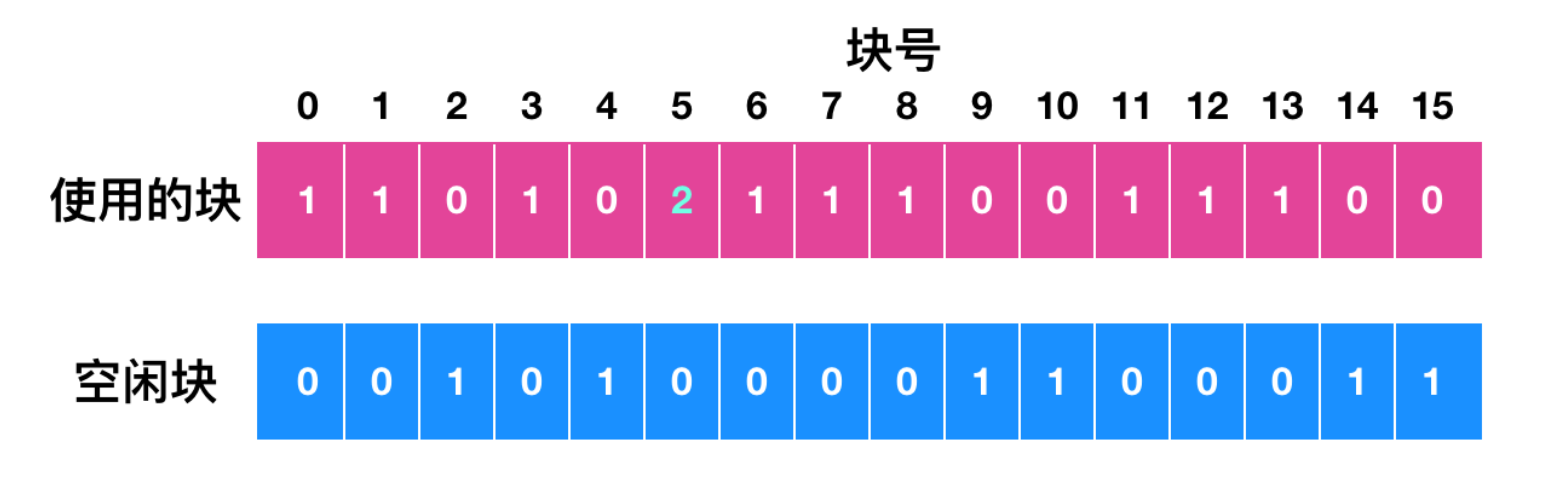
比如上圖的磁盤塊 5,如果其中一個文件被刪除,塊 5 會被添加到空閑表中,導致一個塊同時處于使用和空閑的兩種狀態。如果刪除這兩個文件,那么在空閑表中這個磁盤塊會出現兩次。
文件系統檢驗程序采取的處理方法是,先分配一磁盤塊,把塊 5 中的內容復制到空閑塊中,然后把它插入到其中一個文件中。這樣文件的內容未改變,雖然這些內容可以肯定是不對的,但至少保證了文件的一致性。這一錯誤應該報告給用戶,由用戶檢查受檢情況。
除了檢查每個磁盤塊計數的正確性之外,文件系統還會檢查目錄系統。這時候會用到一張計數器表,但這時是一個文件(而不是一個塊)對應于一個計數器。程序從根目錄開始檢驗,沿著目錄樹向下查找,檢查文件系統的每個目錄。對每個目錄中的文件,使其計數 + 1。
注意,由于存在硬連接,一個文件可能出現在兩個或多個目錄中。而遇到符號鏈接是不計數的,不會對目標文件的計數器 + 1。
在檢驗程序完成后,會得到一張由 inode 索引的表,說明每個文件和目錄的包含關系。檢驗程序會將這些數字與存儲在文件 inode 中的鏈接數目做對比。如果 inode 節點的鏈接計數大戶目錄項個數,這時即使所有文件從目錄中刪除,這個計數仍然不是 0 ,inode 不會被刪除。這種錯誤不嚴重,卻因為存在不屬于任何目錄的文件而浪費了磁盤空間。
另一種錯誤則是潛在的風險。如果同一個文件鏈接兩個目錄項,但是 inode 鏈接計數只為 1,如果刪除了任何一個目錄項,對應 inode 鏈接計數變為 0。當 inode 計數為 0 時,文件系統標志 inode 為 未使用,并釋放全部的塊。這會導致其中一個目錄指向一未使用的 inode,而很有可能其塊馬上就被分配給其他文件。
文件系統性能
訪問磁盤的效率要比內存滿的多,是時候又祭出這張圖了
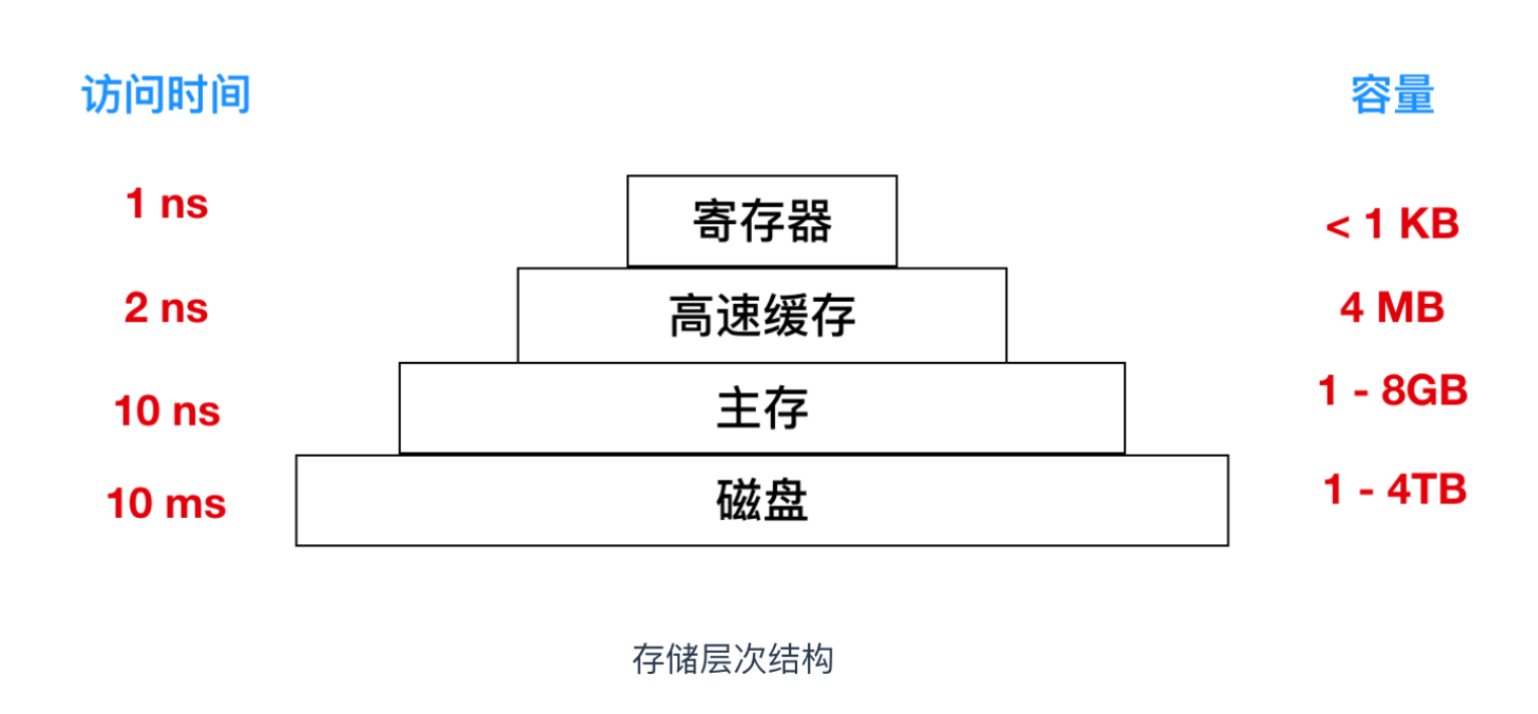
從內存讀一個 32 位字大概是 10ns,從硬盤上讀的速率大概是 100MB/S,對每個 32 位字來說,效率會慢了四倍,另外,還要加上 5 - 10 ms 的尋道時間等其他損耗,如果只訪問一個字,內存要比磁盤快百萬數量級。所以磁盤優化是很有必要的,下面我們會討論幾種優化方式
高速緩存
最常用的減少磁盤訪問次數的技術是使用 塊高速緩存(block cache) 或者 緩沖區高速緩存(buffer cache)。高速緩存指的是一系列的塊,它們在邏輯上屬于磁盤,但實際上基于性能的考慮被保存在內存中。
管理高速緩存有不同的算法,常用的算法是:檢查全部的讀請求,查看在高速緩存中是否有所需要的塊。如果存在,可執行讀操作而無須訪問磁盤。如果檢查塊不再高速緩存中,那么首先把它讀入高速緩存,再復制到所需的地方。之后,對同一個塊的請求都通過高速緩存來完成。
高速緩存的操作如下圖所示
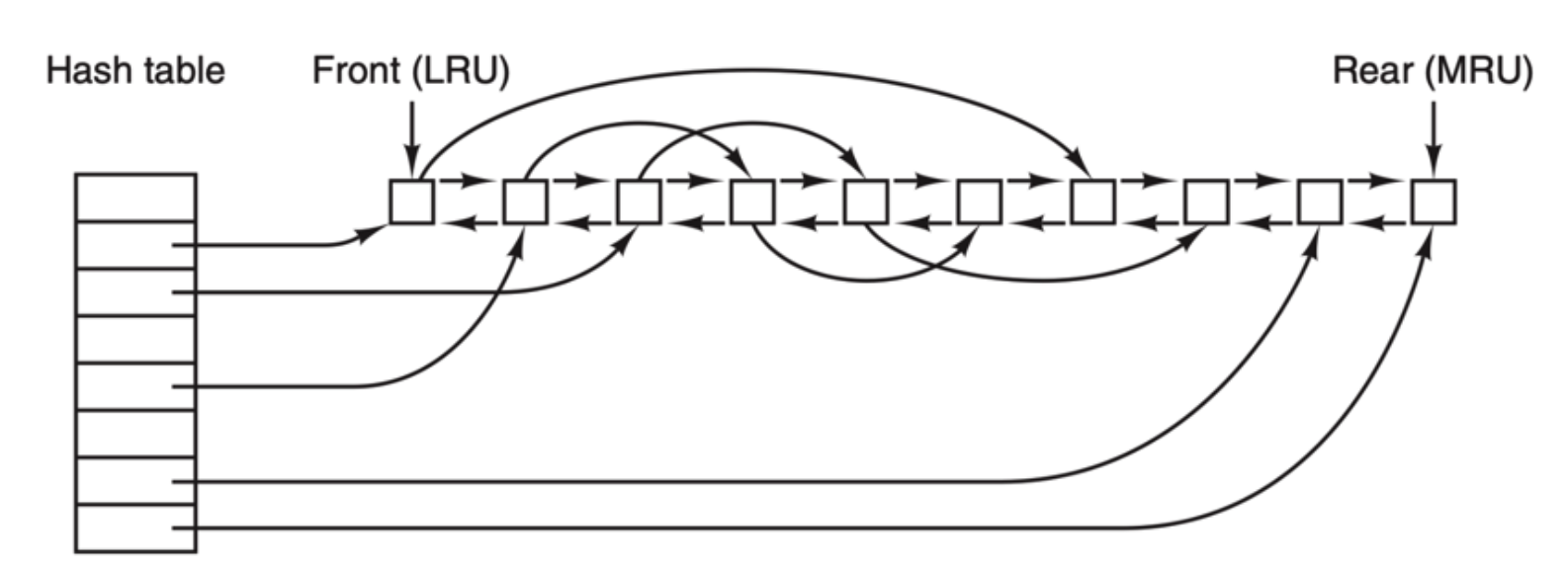
由于在高速緩存中有許多塊,所以需要某種方法快速確定所需的塊是否存在。常用方法是將設備和磁盤地址進行散列操作,然后,在散列表中查找結果。具有相同散列值的塊在一個鏈表中連接在一起(這個數據結構是不是很像 HashMap?),這樣就可以沿著沖突鏈查找其他塊。
如果高速緩存已滿,此時需要調入新的塊,則要把原來的某一塊調出高速緩存,如果要調出的塊在上次調入后已經被修改過,則需要把它寫回磁盤。這種情況與分頁非常相似,所有常用的頁面置換算法我們之前已經介紹過,如果有不熟悉的小伙伴可以參考 https://mp.weixin.qq.com/s/5-k2BJDgEp9symxcSwoprw。比如 FIFO 算法、第二次機會算法、LRU 算法、時鐘算法、老化算法等。它們都適用于高速緩存。
塊提前讀
第二個明顯提高文件系統的性能是,在需要用到塊之前,試圖提前將其寫入高速緩存,從而提高命中率。許多文件都是順序讀取。如果請求文件系統在某個文件中生成塊 k,文件系統執行相關操作并且在完成之后,會檢查高速緩存,以便確定塊 k + 1 是否已經在高速緩存。如果不在,文件系統會為 k + 1 安排一個預讀取,因為文件希望在用到該塊的時候能夠直接從高速緩存中讀取。
當然,塊提前讀取策略只適用于實際順序讀取的文件。對隨機訪問的文件,提前讀絲毫不起作用。甚至還會造成阻礙。
減少磁盤臂運動
高速緩存和塊提前讀并不是提高文件系統性能的唯一方法。另一種重要的技術是把有可能順序訪問的塊放在一起,當然最好是在同一個柱面上,從而減少磁盤臂的移動次數。當寫一個輸出文件時,文件系統就必須按照要求一次一次地分配磁盤塊。如果用位圖來記錄空閑塊,并且整個位圖在內存中,那么選擇與前一塊最近的空閑塊是很容易的。如果用空閑表,并且鏈表的一部分存在磁盤上,要分配緊鄰的空閑塊就會困難很多。
不過,即使采用空閑表,也可以使用 塊簇 技術。即不用塊而用連續塊簇來跟蹤磁盤存儲區。如果一個扇區有 512 個字節,有可能系統采用 1 KB 的塊(2 個扇區),但卻按每 2 塊(4 個扇區)一個單位來分配磁盤存儲區。這和 2 KB 的磁盤塊并不相同,因為在高速緩存中它仍然使用 1 KB 的塊,磁盤與內存數據之間傳送也是以 1 KB 進行,但在一個空閑的系統上順序讀取這些文件,尋道的次數可以減少一半,從而使文件系統的性能大大改善。若考慮旋轉定位則可以得到這類方法的變體。在分配塊時,系統盡量把一個文件中的連續塊存放在同一個柱面上。
在使用 inode 或任何類似 inode 的系統中,另一個性能瓶頸是,讀取一個很短的文件也需要兩次磁盤訪問:一次是訪問 inode,一次是訪問塊。通常情況下,inode 的放置如下圖所示
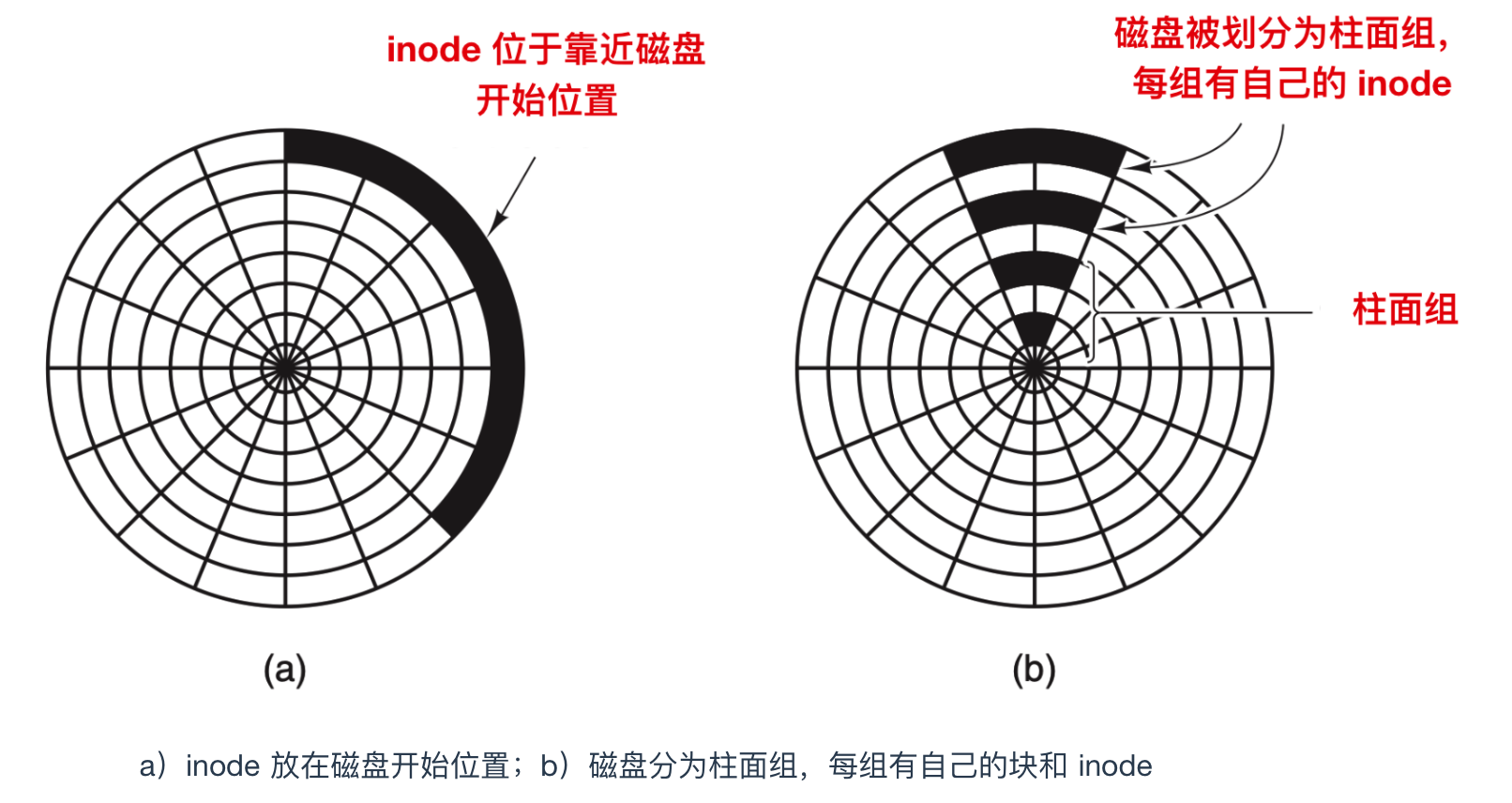
其中,全部 inode 放在靠近磁盤開始位置,所以 inode 和它所指向的塊之間的平均距離是柱面組的一半,這將會需要較長時間的尋道時間。
一個簡單的改進方法是,在磁盤中部而不是開始處存放 inode ,此時,在 inode 和第一個塊之間的尋道時間減為原來的一半。另一種做法是:將磁盤分成多個柱面組,每個柱面組有自己的 inode,數據塊和空閑表,如上圖 b 所示。
當然,只有在磁盤中裝有磁盤臂的情況下,討論尋道時間和旋轉時間才是有意義的。現在越來越多的電腦使用 固態硬盤(SSD),對于這些硬盤,由于采用了和閃存同樣的制造技術,使得隨機訪問和順序訪問在傳輸速度上已經較為相近,傳統硬盤的許多問題就消失了。但是也引發了新的問題。
磁盤碎片整理
在初始安裝操作系統后,文件就會被不斷的創建和清除,于是磁盤會產生很多的碎片,在創建一個文件時,它使用的塊會散布在整個磁盤上,降低性能。刪除文件后,回收磁盤塊,可能會造成空穴。
磁盤性能可以通過如下方式恢復:移動文件使它們相互挨著,并把所有的至少是大部分的空閑空間放在一個或多個大的連續區域內。Windows 有一個程序 defrag 就是做這個事兒的。Windows 用戶會經常使用它,SSD 除外。
磁盤碎片整理程序會在讓文件系統上很好地運行。Linux 文件系統(特別是 ext2 和 ext3)由于其選擇磁盤塊的方式,在磁盤碎片整理上一般不會像 Windows 一樣困難,因此很少需要手動的磁盤碎片整理。而且,固態硬盤并不受磁盤碎片的影響,事實上,在固態硬盤上做磁盤碎片整理反倒是多此一舉,不僅沒有提高性能,反而磨損了固態硬盤。所以碎片整理只會縮短固態硬盤的壽命。



















