注:本文為 “網路性能優化” 相關文章合輯。
未整理去重。
如有內容異常,請看原文。
TCP_NODELAY 詳解
lenky0401 發表于 2012-08-25 16:40
在網絡擁塞控制領域,Nagle 算法(Nagle algorithm)是一個非常著名的算法,其名稱來源于發明者 John Nagle。1984 年,John Nagle 首次提出該算法,旨在解決福特汽車公司網絡中的擁塞問題(RFC 896)。具體問題描述如下:如果應用程序每次僅產生 1 個字節的數據,并以網絡數據包的形式發送到遠端服務器,那么很容易導致網絡因過多的數據包而過載。例如,在使用 Telnet 連接到遠程服務器時,每次擊鍵操作會生成 1 個字節的數據并發送一個數據包。在這種情況下,一個僅包含 1 個字節有效數據的數據包,卻需要攜帶 40 個字節的包頭(即 IP 頭 20 字節 + TCP 頭 20 字節),有效載荷(payload)利用率極低。這種情況被稱為“愚蠢窗口癥候群”(Silly Window Syndrome)。對于輕負載網絡,這種狀況或許可以接受,但對于重負載網絡,極易導致擁塞甚至癱瘓。
為解決上述問題,Nagle 算法的核心改進如下:如果發送端多次發送包含少量字符的數據包(長度小于 MSS 的數據包稱為小包,長度等于 MSS 的數據包稱為大包),則發送端會先發送第一個小包,而將后續到達的少量字符數據緩存起來,直到收到接收端對前一個數據包的 ACK 確認,或者當前字符屬于緊急數據,或者積攢的數據量達到一定數量(例如緩存的數據已達到數據包的最大長度),才會將這些數據組成一個較大的數據包發送出去。
以下是 Linux 內核中相關的代碼實現:
/* Filename : \linux-3.4.4\net\ipv4\tcp_output.c */
/* Return 0, if packet can be sent now without violation Nagle's rules:* 1. It is full sized.* 2. Or it contains FIN. (already checked by caller)* 3. Or TCP_CORK is not set, and TCP_NODELAY is set.* 4. Or TCP_CORK is not set, and all sent packets are ACKed.* With Minshall's modification: all sent small packets are ACKed.*/
static inline int tcp_nagle_check (const struct tcp_sock *tp,const struct sk_buff *skb,unsigned mss_now, int nonagle)
{return skb->len < mss_now &&((nonagle & TCP_NAGLE_CORK) ||(!nonagle && tp->packets_out && tcp_minshall_check (tp)));
}
/* Return non-zero if the Nagle test allows this packet to be sent now. */
static inline int tcp_nagle_test (const struct tcp_sock *tp, const struct sk_buff *skb,unsigned int cur_mss, int nonagle)
{/* Nagle rule does not apply to frames, which sit in the middle of the write_queue (they have no chances to get new data).* This is implemented in the callers, where they modify the 'nonagle' argument based upon the location of SKB in the send queue.*/if (nonagle & TCP_NAGLE_PUSH)return 1;/* Don't use the nagle rule for urgent data (or for the final FIN).* Nagle can be ignored during F-RTO too (see RFC413).*/if (tcp_urg_mode (tp) || (tp->frto_counter == 2) ||(TCP_SKB_CB (skb)->tcp_flags & TCPHDR_FIN))return 1;if (!tcp_nagle_check (tp, skb, cur_mss, nonagle))return 1;return 0;
}
從代碼中可以看出,tcp_nagle_test() 函數首先檢查是否設置了 TCP_NAGLE_PUSH 標志。如果設置了該標志(例如主動禁止 Nagle 算法,或者明確是連接的最后一個數據包),則立即返回 1,表示可以發送數據包。接下來,代碼處理特殊數據包,如緊急數據包、帶 FIN 標志的結束包以及帶 F-RTO 標志的包。最后,調用 tcp_nagle_check() 函數進行判斷。如果該函數返回 1,則表示數據包不立即發送。具體邏輯為:如果數據包長度小于當前 MSS,并且滿足以下條件之一,則緩存數據而不立即發送:
- 已主動加塞或明確標識后續還有數據(內核表示為
MSG_MORE)。 - 啟用了 Nagle 算法,并且存在未被 ACK 確認的已發送數據包。

上圖左側展示了未開啟 Nagle 算法的情況,客戶端應用層下傳的數據包被立即發送到網絡中,而不管數據包的大小如何。右側圖展示了開啟 Nagle 算法后的情況,在未收到服務器對第一個數據包的 ACK 確認之前,客戶端應用層下傳的數據包被緩存起來,直到收到 ACK 確認后才發送。這樣,總包數由原來的 3 個減少為 2 個,網絡負載降低,同時客戶端和服務器需要處理的數據包數量也減少,從而降低了 CPU 等資源的消耗。
雖然 Nagle 算法在某些場景下能夠提高網絡利用率、降低包處理主機資源消耗,但在某些場景下卻弊大于利。這需要引入另一個概念:延遲確認(Delayed ACK)。延遲確認是提高網絡利用率的另一種優化機制,它針對的是 ACK 確認包。在 TCP 協議中,正常情況下,接收端會對收到的每一個數據包向發送端發送一個 ACK 確認包。而延遲確認機制則是將 ACK 延后發送,使其與數據包或窗口更新通知包一起發送。

上圖左側展示了一般情況,右側圖展示了延遲確認機制中的兩種情況:通過反向數據攜帶 ACK 和超時發送 ACK。根據 RFC 1122,ACK 的最大超時時間為 500 毫秒,但在實際實現中,最大超時時間通常為 200 毫秒。例如,在 Linux 3.4.4 中,TCP_DELACK_MAX 宏定義了該超時最大值:
/* Filename : \linux-3.4.4\include\net\tcp.h */
#define TCP_DELACK_MAX ((unsigned)(HZ/5)) /* maximal time to delay before sending an ACK */
當 Nagle 算法與延遲確認機制相互作用時,可能會導致問題。例如,發送端有一段數據要發送給接收端,數據長度不足以組成一個大包。根據 Nagle 算法,發送端會等待接收端對第一個數據包的 ACK 確認,或者等待應用層傳下更多數據。然而,接收端由于延遲確認機制的作用,不會立即發送 ACK,而是等待。如果接收端在等待超時后才發送 ACK,那么發送端的第二個數據包就需要等待 200 毫秒才能發送。在 HTTP 等單向數據傳輸的應用中,這種情況尤為常見,可能導致時延顯著增加。
為解決上述問題,Minshall 對 Nagle 算法進行了改進,相關描述可在文檔中找到,Linux 內核中也已應用了這種改進。以下是改進后的代碼:
/* Filename : \linux-3.4.4\net\ipv4\tcp_output.c */
/* Minshall's variant of the Nagle send check. */
static inline int tcp_minshall_check (const struct tcp_sock *tp)
{return after (tp->snd_sml, tp->snd_una) &&!after (tp->snd_sml, tp->snd_nxt);
}
該函數的實現基于以下字段的含義(RFC 793、RFC 1122):
tp->snd_nxt:下一個待發送的字節序號。tp->snd_una:下一個待確認的字節序號。如果其值等于tp->snd_nxt,則表示所有已發送數據均已得到確認。tp->snd_sml:最近一個已發送的小包的最后一個字節序號(不一定是已確認的)。

改進的核心思想是:在判斷當前包是否可發送時,僅檢查最近一個小包是否已確認。如果已確認(即 tcp_minshall_check(tp) 返回假),則表示可以發送;否則延遲等待。這種改進縮短了延遲,提高了帶寬利用率。
例如,對于前面提到的場景,第一個數據包是大包,因此無論其對應的 ACK 是否收到,都不會影響對第二個數據包的發送判斷。由于所有小包均已確認(實際上是因為沒有發送過小包),第二個數據包可以直接發送而無需等待。
傳統 Nagle 算法是一種“包 - 停 - 等”協議,在未收到前一個包的確認前不會發送第二個包。而改進的 Nagle 算法是一種折中處理:如果未確認的不是小包,則可以發送第二個包。這種改進保證了在同一個往返時間(RTT)內,網絡上只有一個當前連接的小包。然而,在某些特殊情況下,改進的 Nagle 算法可能會產生不利影響。例如,當 3 個數據塊相繼到達且后續沒有其他數據時,傳統 Nagle 算法僅產生一個小包,而改進的 Nagle 算法可能會產生 2 個小包(第二個小包是由于延遲等待超時產生的)。盡管如此,這種影響并不大,因此可以認為這是一種折中處理。

TCP 中的 Nagle 算法默認是啟用的,但并不適用于所有場景。對于 telnet 或 rlogin 等遠程登錄應用,Nagle 算法較為適用(原本就是為此設計的),但在某些應用場景下,需要關閉該算法。例如,在處理 HTTP 持久連接(Keep-Alive)時,可能會出現奇數包和結束小包問題。具體來說,當已有奇數個包發出,并且還有一個結束小包(不是帶 FIN 標志的包,而是 HTTP 請求或響應的結束包)等待發送時,就會出現該問題。以下是一個包含 3 個包和 1 個結束小包的發包示例:
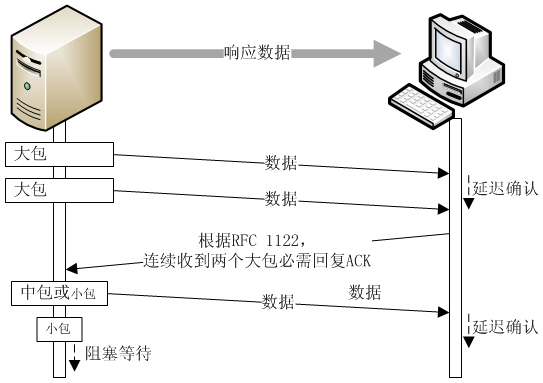
最后一個結束小包包含了整個響應數據的最后一些數據。如果當前 HTTP 是非持久連接,則在連接關閉時,最后一個小包會立即發送,不會出現問題。然而,如果當前 HTTP 是持久連接(非 pipelining 處理,僅 HTTP 1.1 支持,并且目前部分舊版瀏覽器尚不支持,nginx 對 pipelining 的支持較弱),那么由于最后一個小包受到 Nagle 算法的影響,無法及時發送。具體原因是:客戶端在未結束上一個請求前不會發送新的請求數據,導致無法攜帶 ACK 而延遲確認,進而服務器未收到客戶端對上一個小包的確認,導致最后一個小包無法發送。這會導致第 n 次請求/響應未能結束,從而客戶端第 n+1 次的請求數據無法發出。

為解決該問題,nginx 會主動關閉 Nagle 算法。以下是相關代碼:
/* Filename : \linux-3.4.4\net\ipv4\tcp_output.c */
static void
ngx_http_set_keepalive (ngx_http_request_t *r)
{...if (tcp_nodelay&& clcf->tcp_nodelay&& c->tcp_nodelay == NGX_TCP_NODELAY_UNSET){ngx_log_debug0 (NGX_LOG_DEBUG_HTTP, c->log, 0, "tcp_nodelay");if (setsockopt (c->fd, IPPROTO_TCP, TCP_NODELAY,(const void *) &tcp_nodelay, sizeof (int))== -1){...}c->tcp_nodelay = NGX_TCP_NODELAY_SET;}
}
當 nginx 執行到該函數時,表示當前連接是持久連接。如果滿足以下條件,則對套接字設置 TCP_NODELAY,禁止 Nagle 算法:
- 局部變量
tcp_nodelay用于標記TCP_CORK選項,由配置指令tcp_nopush指定,默認為 off。 clcf->tcp_nodelay對應TCP_NODELAY選項的配置指令tcp_nodelay的配置值,默認為 1。c->tcp_nodelay用于標記當前是否已對該套接字設置TCP_NODELAY選項,第一次執行時通常為NGX_TCP_NODELAY_UNSET。
因此,如果條件滿足,則設置 TCP_NODELAY,使最后的響應數據能夠立即發送,從而解決上述問題。
TCP/IP 詳解 – Nagle 算法和 TCP_NODELAY
魚思故淵 于 2014-04-19 14:38:38 發布
在客戶端持續向服務器發送小數據時,接收到響應的時間可能會很長。這可能是由于 TCP_NODELAY 的原因。現在基本可以確定,問題出在 Nagle 算法上。
在 TCP/IP 協議中,無論發送多少數據,都需要在數據前加上協議頭,同時接收方需要發送 ACK 以確認收到數據。為了盡可能利用網絡帶寬,TCP 希望每次都能發送足夠大的數據塊。Nagle 算法正是為了實現這一點,避免網絡中充斥著許多小數據塊。
Nagle 算法的基本定義是:任意時刻,最多只能有一個未被確認的小段。所謂“小段”,指的是小于 MSS 尺寸的數據塊;所謂“未被確認”,是指一個數據塊發送出去后,沒有收到對方發送的 ACK 確認該數據已收到。
例如,客戶端調用 socket 的 write 操作將一個 int 型數據(稱為 A 塊)寫入網絡中。由于此時連接是空閑的(即沒有未被確認的小段),因此該 int 型數據會立即發送到服務器端。接著,客戶端又調用 write 操作寫入“/r/n”(簡稱 B 塊),此時 A 塊的 ACK 尚未返回,因此可以認為已經存在一個未被確認的小段。于是,B 塊不會立即發送,而是等待 A 塊的 ACK 收到(大約 40 毫秒后),B 塊才會被發送。整個過程如下圖所示:

這里還隱藏了一個問題:為什么 A 塊數據的 ACK 需要 40 毫秒才收到?這是因為 TCP/IP 中不僅有 Nagle 算法,還有一個 ACK 延遲機制。當服務器端收到數據后,不會立即向客戶端發送 ACK,而是將 ACK 的發送延遲一段時間(假設為 t),希望在 t 時間內服務器端會向客戶端發送應答數據,這樣 ACK 就可以和應答數據一起發送。這解釋了為什么“/r/n”(B 塊)總是在 A 塊之后 40 毫秒才發出。
如果覺得 Nagle 算法影響了性能,可以通過 設置 TCP_NODELAY 禁用它。當然,更合理的方案是 使用一次大數據的寫操作,而不是多次小數據的寫操作。
Linux 下 TCP 延遲確認(Delayed Ack)機制導致的時延問題分析
3035597182 2015-04-26 23:03:33
案例
在進行 Server 壓力測試時發現,客戶端不斷向服務器發送請求,并接收服務器的響應。然而,在接收服務器響應的過程中,會出現 recv 阻塞 40 毫秒的情況。查看服務器端日志,服務器處理每個請求的時間均在 2 毫秒以內,并已將響應發送給客戶端。
產生原因
產生該問題的原因是 TCP 的延遲確認(Delayed Ack)機制。服務器端調用 send 向客戶端發送響應時,send 只是將數據存入 TCP 發送緩沖區。TCP 協議棧是否會發送該數據包,還需考慮 Nagle 算法。
解決辦法
在 TCP 中,recv 到數據后,調用一次 setsockopt 函數,設置 TCP_QUICKACK。例如:
setsockopt (fd, IPPROTO_TCP, TCP_QUICKACK, (int*){1}, sizeof (int));
產生問題原因的詳細分析
1. 延遲確認機制及作用
在《TCP/IP 詳解卷一:協議》第 19 章中,詳細描述了 TCP 在處理交互數據流(Interactive Data Flow)時,采用了延遲確認機制和 Nagle 算法來減少小分組數目。
2. TCP 的延遲確認機制為什么會導致 recv 延時?
僅 TCP 的延遲確認機制本身,并不會導致請求延時(因為 recv 系統調用并不需要等待 ACK 包發出去才能返回)。一般來說,只有當該機制與 Nagle 算法或擁塞控制(如慢啟動或擁塞避免)混合作用時,才可能會導致時延增加。
3. 延遲確認機制與 Nagle 算法
Nagle 算法的規則如下(可參考 tcp_output.c 文件中 tcp_nagle_check 函數的注釋):
1). 如果包長度達到 MSS,則允許發送。
2). 如果該包含有 FIN,則允許發送。
3). 如果設置了 TCP_NODELAY 選項,則允許發送。
4). 如果未設置 TCP_CORK 選項,并且所有已發送的包均已被確認,或者所有已發送的小數據包(包長度小于 MSS)均已被確認,則允許發送。
對于規則 4),一個 TCP 連接上最多只能有一個未被確認的小數據包。如果某個小分組的確認被延遲(如案例中的 40 毫秒),那么后續小分組的發送也會相應延遲。也就是說,延遲確認不僅影響被延遲確認的那個數據包,還會影響后續的所有應答包。
4. 關于 TCP_NODELAY 和 TCP_CORK 選項
TCP_CORK 選項與 TCP_NODELAY 一樣,用于控制 Nagle 化。
-
打開
TCP_NODELAY選項,則無論數據包多么小,都會立即發送(不考慮擁塞窗口)。 -
如果將 TCP 連接比喻為一個管道,那么
TCP_CORK選項的作用就像一個塞子。設置TCP_CORK選項,就是用塞子塞住管道;取消TCP_CORK選項,就是將塞子拔掉。當TCP_CORK選項被設置時,TCP 連接不會發送任何小包,只有當數據量達到 MSS 時,才會發送。通常在數據傳輸完成后,需要取消該選項,以便讓不夠 MSS 大小的包能夠及時發送。
5. 為什么 TCP_QUICKACK 需要在每次 recv 后重新設置?
因為 TCP_QUICKACK 不是永久的,所以在每次 recv 數據后,應該重新設置。
神秘的 40 毫秒延遲與 TCP_NODELAY
posted on 2017-03-18 12:31 wajika
在編寫 HTTP Server 并使用 ab 進行性能測試時,出現了一個困擾了幾天的問題:神秘的 40 毫秒延遲。
1. 現象
首先,使用 ab 不加 -k 選項進行測試:
[~/dev/personal/breeze]$ /usr/sbin/ab -c 1 -n 10 http://127.0.0.1:8000/styles/shThemeRDark.css
測試結果顯示,響應時間不超過 1 毫秒。然而,一旦加上 -k 選項啟用 HTTP Keep-Alive,結果就變成了這樣:
[~/dev/personal/breeze]$ /usr/sbin/ab -k -c 1 -n 10 http://127.0.0.1:8000/styles/shThemeRDark.css
響應時間變成了 36 毫秒。使用 strace 工具跟蹤,發現是讀取下一個請求之前的 epoll_wait 花了 40 毫秒才返回。這意味著要么是客戶端等待了 40 毫秒才發送請求,要么是之前寫入的響應數據過了 40 毫秒才到達客戶端。由于 ab 作為壓力測試工具不可能故意延遲發送請求,因此問題出在響應數據的延遲上。
2. 背后的原因
40 毫秒的延遲是由于 TCP 協議中的 Nagle 算法和延遲確認機制共同作用的結果。Nagle 算法旨在提高帶寬利用率,通過合并小的 TCP 包來避免過多的小報文浪費帶寬。如果開啟了該算法(默認情況下),協議棧會累積數據,直到滿足以下條件之一才發送:
- 積累的數據量達到最大的 TCP Segment Size。
- 收到一個 ACK。
TCP 延遲確認機制也是為了類似的目的而設計的,它會延遲 ACK 包的發送,以便協議棧有機會合并多個 ACK,從而提高網絡性能。如果一個 TCP 連接的一端啟用了 Nagle 算法,而另一端啟用了延遲確認機制,且發送的數據包較小,則可能會出現以下情況:發送端等待接收端對上一個數據包的 ACK 才發送當前數據包,而接收端則延遲了 ACK 的發送。因此,當前數據包也會被延遲。延遲確認機制有一個超時機制,默認超時時間為 40 毫秒。
3. 為什么只有 Write-Write-Read 時才會出問題
維基百科上有一段偽代碼介紹了 Nagle 算法:
if there is new data to sendif the window size >= MSS and available data is >= MSSsend complete MSS segment nowelseif there is unconfirmed data still in the pipeenqueue data in the buffer until an acknowledge is receivedelsesend data immediatelyend ifend if
end if
從偽代碼可以看出,當待發送的數據小于 MSS 時(外層的 else 分支),還需判斷是否有未確認的數據。只有當管道中存在未確認的數據時,才會將數據緩存起來等待 ACK。因此,發送端發送的第一個 write 不會被緩存,而是立即發送(進入內層的 else 分支)。此時,接收端收到數據后,由于期待更多數據,不會立即發送 ACK。根據延遲確認機制,ACK 會被延遲。當發送端發送第二個數據包時,由于隊列中存在未確認的數據包,會進入內層 if 的 then 分支,該數據包會被緩存起來。此時,發送端等待接收端的 ACK,而接收端則延遲發送 ACK,直到超時(40 毫秒),ACK 才被發送回去,發送端緩存的數據包才會被發送。
如果采用 write-read-write-read 模式,則不會出現問題。因為第一個 write 不會被緩存,會立即到達接收端。接收端處理完后發送結果,并將 ACK 與數據一起發送回去,無需延遲確認,因此不會導致任何問題。
4. 解決方案
4.1 優化協議
連續 write 小數據包然后 read 是一種不好的網絡編程模式。這種連續的 write 應該在應用層合并成一次 write。然而,如果程序難以進行這樣的優化,可以采用以下方法。
4.2 開啟 TCP_NODELAY
簡單來說,該選項的作用是禁用 Nagle 算法。禁用后,就不會出現由該算法引起的問題。在 UNIX C 中,可以使用 setsockopt 來實現:
static void _set_tcp_nodelay (int fd)
{int enable = 1;setsockopt (fd, IPPROTO_TCP, TCP_NODELAY, (void*)&enable, sizeof (enable));
}
在 Java 中,Socket 對象有一個 setTcpNoDelay 方法,直接設置為 true 即可。據我所知,Nginx 默認開啟了這個選項,這為我提供了一些安慰:既然 Nginx 都這么做了,我也可以先默認開啟 TCP_NODELAY。
Linux 下 TCP 延遲確認(Delayed Ack)機制導致的時延問題分析
潘安群 修改于 2017-06-19 19:29:42
案例一
同事隨手寫了一個壓力測試程序,其邏輯為:每秒鐘先連續發送 N 個 132 字節的包,然后連續接收 N 個由后臺服務回顯回來的 132 字節包。代碼簡化如下:
char sndBuf [132];
char rcvBuf [132];
while (1) {for (int i = 0; i < N; i++) {send (fd, sndBuf, sizeof (sndBuf), 0);...}for (int i = 0; i < N; i++) {recv (fd, rcvBuf, sizeof (rcvBuf), 0);...}sleep (1);
}
在實際測試中發現,當 N 大于等于 3 時,從第 2 秒開始,每次第三個 recv 調用總會阻塞 40 毫秒左右。然而,在分析服務器端日志時,發現所有請求在服務器端的處理時間均在 2 毫秒以下。
定位過程如下:首先嘗試使用 strace 跟蹤客戶端進程,但奇怪的是,一旦 strace attach 上進程,所有收發都正常,不會出現阻塞現象。退出 strace 后,問題重現。經同事提醒,可能是 strace 改變了程序或系統的某些設置。于是使用 tcpdump 抓包分析,發現服務器端在回顯應答包后,客戶端并沒有立即對該數據進行 ACK 確認,而是等待了近 40 毫秒后才確認。經過 Google 并查閱《TCP/IP 詳解卷一:協議》,得知這是 TCP 的延遲確認(Delayed Ack)機制。
解決辦法如下:在 recv 系統調用后,調用一次 setsockopt 函數,設置 TCP_QUICKACK。最終代碼如下:
char sndBuf [132];
char rcvBuf [132];
while (1) {for (int i = 0; i < N; i++) {send (fd, sndBuf, 132, 0);...}for (int i = 0; i < N; i++) {recv (fd, rcvBuf, 132, 0);setsockopt (fd, IPPROTO_TCP, TCP_QUICKACK, (int []){1}, sizeof (int));}sleep (1);
}
案例二
在營銷平臺內存化 CDKEY 版本進行性能測試時,發現請求時延分布異常:90% 的請求時延在 2 毫秒以內,而 10% 的請求時延始終在 38-42 毫秒之間。這是一個非常有規律的數字:40 毫秒。由于之前經歷過案例一,因此猜測這也是由延遲確認機制引起的時延問題。經過簡單的抓包驗證后,通過設置 TCP_QUICKACK 選項,成功解決了時延問題。
延遲確認機制
在《TCP/IP 詳解卷一:協議》第 19 章中,詳細描述了 TCP 在處理交互數據流(Interactive Data Flow)時,采用了延遲確認機制和 Nagle 算法來減少小分組數目。
1. 為什么 TCP 延遲確認會導致延遲?
實際上,僅延遲確認機制本身并不會導致請求延遲(最初以為必須等到 ACK 包發出去,recv 系統調用才會返回)。一般來說,只有當該機制與 Nagle 算法或擁塞控制(如慢啟動或擁塞避免)混合作用時,才可能會導致時延增加。接下來詳細分析它們是如何相互作用的。
延遲確認與 Nagle 算法
Nagle 算法的規則如下(可參考 tcp_output.c 文件中 tcp_nagle_check 函數的注釋):
- 如果包長度達到 MSS,則允許發送。
- 如果該包含有 FIN,則允許發送。
- 如果設置了
TCP_NODELAY選項,則允許發送。 - 如果未設置
TCP_CORK選項,并且所有已發送的包均已被確認,或者所有已發送的小數據包(包長度小于 MSS)均已被確認,則允許發送。
對于規則 4),一個 TCP 連接上最多只能有一個未被確認的小數據包。如果某個小分組的確認被延遲(如案例中的 40 毫秒),那么后續小分組的發送也會相應延遲。也就是說,延遲確認影響的并不是被延遲確認的那個數據包,而是后續的應答包。
延遲確認與擁塞控制
我們先利用 TCP_NODELAY 選項關閉 Nagle 算法,再來分析延遲確認與 TCP 擁塞控制是如何相互作用的。
慢啟動
TCP 的發送方維護一個擁塞窗口(cwnd)。TCP 連接建立時,該值初始化為 1 個報文段。每收到一個 ACK,該值就增加 1 個報文段。發送方取擁塞窗口與通告窗口(與滑動窗口機制對應)中的最小值作為發送上限。發送方開始發送 1 個報文段,收到 ACK 后,cwnd 從 1 增加到 2,即可以發送 2 個報文段。當收到這兩個報文段的 ACK 后,cwnd 就增加為 4,即指數增長。例如,在第一個 RTT 內,發送一個包,并收到其 ACK,cwnd 增加 1。在第二個 RTT 內,可以發送兩個包,并收到對應的兩個 ACK,則 cwnd 每收到一個 ACK 就增加 1,最終變為 4,實現了指數增長。
在 Linux 實現中,并不是每收到一個 ACK 包,cwnd 就增加 1。如果在收到 ACK 時,并沒有其他數據包在等待被 ACK,則不增加。
2. 為什么是 40 毫秒?這個時間能否調整?
在 RedHat 的官方文檔中,有如下說明:某些應用在發送小報文時,可能會因為 TCP 的延遲確認機制而產生延遲。其默認值為 40 毫秒。可以通過修改 tcp_delack_min,調整系統級別的最小延遲確認時間。例如:
# echo 1 > /proc/sys/net/ipv4/tcp_delack_min
這表示期望設置最小的延遲確認超時時間為 1 毫秒。然而,在 Slackware 和 SUSE 系統下,均未找到該選項,這意味著在這些系統中,40 毫秒的最小值無法通過配置調整。
在 linux-2.6.39.1/net/tcp.h 中,有如下宏定義:
#define TCP_DELACK_MIN ((unsigned)(HZ/25)) /* minimal time to delay before sending an ACK */
Linux 內核每隔固定周期會發出 timer interrupt (IRQ 0),HZ 用于定義每秒的 timer interrupts 次數。例如,HZ 為 1000,表示每秒有 1000 次 timer interrupts。HZ 可在編譯內核時設置。在現有服務器上運行的系統中,HZ 值均為 250。
因此,最小的延遲確認時間為 40 毫秒。TCP 連接的延遲確認時間通常初始化為最小值 40 毫秒,隨后根據連接的重傳超時時間(RTO)、上次收到數據包與本次接收數據包的時間間隔等參數進行調整。具體的調整算法可以參考 linux-2.6.39.1/net/ipv4/tcp_input.c 中的 tcp_event_data_recv 函數。
3. 為什么 TCP_QUICKACK 需要在每次調用 recv 后重新設置?
在 man 7 tcp 中,有如下說明:
TCP_QUICKACK
Enable quickack mode if set or disable quickack mode if cleared. In quickack mode, acks are sent immediately, rather than delayed if needed in accordance to normal TCP operation. This flag is not permanent, it only enables a switch to or from quickack mode. Subsequent operation of the TCP protocol will once again enter/leave quickack mode depending on internal protocol processing and factors such as delayed ack timeouts occurring and data transfer. This option should not be used in code intended to be portable.
手冊中明確指出 TCP_QUICKACK 不是永久的。其具體實現如下:
case TCP_QUICKACK:if (!val) {icsk->icsk_ack.pingpong = 1;} else {icsk->icsk_ack.pingpong = 0;if ((1 << sk->sk_state) &(TCPF_ESTABLISHED | TCPF_CLOSE_WAIT) &&inet_csk_ack_scheduled (sk)) {icsk->icsk_ack.pending |= ICSK_ACK_PUSHED;tcp_cleanup_rbuf (sk, 1);if (!(val & 1))icsk->icsk_ack.pingpong = 1;}}break;
Linux 下的 socket 有一個 pingpong 屬性,用于表明當前連接是否為交互數據流。如果其值為 1,則表示為交互數據流,會使用延遲確認機制。然而,pingpong 的值是動態變化的。例如,當 TCP 連接要發送一個數據包時,會執行如下函數(linux-2.6.39.1/net/ipv4/tcp_output.c,Line 156):
/* Congestion state accounting after a packet has been sent. */
static void tcp_event_data_sent (struct tcp_sock *tp, struct sk_buff *skb, struct sock *sk)
{...tp->lsndtime = now;/* If it is a reply for ato after last received* packet, enter pingpong mode.*/if ((u32)(now - icsk->icsk_ack.lrcvtime) < icsk->icsk_ack.ato)icsk->icsk_ack.pingpong = 1;
}
最后兩行代碼說明:如果當前時間與最近一次接收數據包的時間間隔小于計算的延遲確認超時時間,則重新進入交互數據流模式。也可以這樣理解:延遲確認機制被確認有效時,會自動進入交互式。
通過以上分析可知,TCP_QUICKACK 選項需要在每次調用 recv 后重新設置。
4. 為什么不是所有包都延遲確認?
在 TCP 實現中,使用 tcp_in_quickack_mode 函數(linux-2.6.39.1/net/ipv4/tcp_input.c,Line 197)來判斷是否需要立即發送 ACK。其函數實現如下:
/* Send ACKs quickly, if "quick" count is not exhausted* and the session is not interactive.*/
static inline int tcp_in_quickack_mode (const struct sock *sk)
{const struct inet_connection_sock *icsk = inet_csk (sk);return icsk->icsk_ack.quick && !icsk->icsk_ack.pingpong;
}
要滿足以下兩個條件才能進入 quickack 模式:
pingpong被設置為 0。- 快速確認數(
quick)必須為非 0。
關于 pingpong 的值,前面已有描述。而 quick 屬性的代碼注釋為:scheduled number of quick acks,即快速確認的包數量。每次進入 quickack 模式時,quick 被初始化為接收窗口除以 2 倍 MSS 值(linux-2.6.39.1/net/ipv4/tcp_input.c,Line 174)。每次發送一個 ACK 包時,quick 就減 1。
5. 關于 TCP_CORK 選項
TCP_CORK 選項與 TCP_NODELAY 一樣,用于控制 Nagle 化。
- 打開
TCP_NODELAY選項,則意味著無論數據包多么小,都會立即發送(不考慮擁塞窗口)。 - 如果將 TCP 連接比喻為一個管道,那么
TCP_CORK選項的作用就像一個塞子。設置TCP_CORK選項,就是用塞子塞住管道;取消TCP_CORK選項,就是將塞子拔掉。例如,以下代碼:
int on = 1;
setsockopt (sockfd, SOL_TCP, TCP_CORK, &on, sizeof (on)); // 設置 TCP_CORK
write (sockfd, ...); // 例如,HTTP 頭
sendfile (sockfd, ...); // 例如,HTTP 正文
on = 0;
setsockopt (sockfd, SOL_TCP, TCP_CORK, &on, sizeof (on)); // 取消 TCP_CORK
當 TCP_CORK 選項被設置時,TCP 連接不會發送任何小包,只有當數據量達到 MSS 時,才會發送。當數據傳輸完成時,通常需要取消該選項,以便讓不夠 MSS 大小的包能夠及時發送。如果應用程序確定可以一起發送多個數據集合(例如 HTTP 響應的頭和正文),建議設置 TCP_CORK 選項,這樣在這些數據之間不存在延遲。為了提升性能和吞吐量,Web Server 和文件服務器通常會使用該選項。
著名的高性能 Web 服務器 Nginx,在使用 sendfile 模式時,可以通過將 nginx.conf 配置文件中的 tcp_nopush 配置為 on 來打開 TCP_CORK 選項。TCP_NOPUSH 與 TCP_CORK 功能類似,只不過 NOPUSH 是 BSD 下的實現,而 CORK 是 Linux 下的實現。此外,Nginx 為了減少系統調用,追求性能極致,針對短連接(一般傳送完數據后,立即主動關閉連接,對于 Keep-Alive 的 HTTP 持久連接除外),程序并不通過 setsockopt 調用取消 TCP_CORK 選項,因為關閉連接會自動取消 TCP_CORK 選項,并將剩余數據發送出去。
套接字 socket 選項 TCP_NODELAY、TCP_CORK 與 TCP_QUICKACK
冬生0 已于 2022-03-02 14:15:28 修改
一、簡介
TCP_NODELAY:關閉 Nagle 算法,控制數據的發送。Nagle 算法規定,如果包大于 MSS(Max Segment Size)或含有 FIN,則立即發送;否則放入緩沖區,等待已發送的包被確認后再發送。該算法可以減少網絡中的小包數量,降低 IP 頭部在網絡中的比重,從而提升網絡性能。TCP_CORK:設置后不會發送任何小包(小于 MSS),除非超時 200 毫秒。TCP_QUICKACK(自 Linux 2.4.4 起可用):設置后會立即發送確認 ACK,而不是延遲發送 ACK。如果未開啟,則延遲確認,使得協議有機會合并 ACK,提高網絡利用率。默認超時確認時間為 40 毫秒,該系統值可配置。
二、測試
測試方法:服務器 IP 為 192.168.x.5,客戶端 IP 為 192.168.x.7。服務器端接受客戶端連接,但不做任何處理;客戶端與服務器建立連接后,連續發送 10 個字符。
-
服務器端關閉
QUICKACK,客戶端關閉NODELAY(即會延遲發送):服務器關閉了QUICKACK,因此會等待超時后再確認,或等到有數據發送時順帶發送確認 ACK。但由于服務器沒有數據發送,因此會等待 40 毫秒超時。由于客戶端沒有收到服務器端的確認 ACK,且nodelay關閉(即開啟了延遲發送),因此會等待收到服務器的 ACK 后才繼續發送剩余數據。
-
服務器端開啟
QUICKACK,客戶端開啟NODELAY(立即發送):服務器端收到一個數據后立即發送確認給客戶端。
-
服務器端關閉
QUICKACK,客戶端開啟NODELAY(立即發送):客戶端不等待確認,連續發送 10 個字符。服務器端在 10 毫秒后發送 ACK。疑問:為什么是 10 毫秒后發送 ACK?
-
服務器端開啟
QUICKACK,客戶端關閉NODELAY(即會延遲發送):服務器收到數據后立即發送確認給客戶端,客戶端將剩余的 9 個字符合并發送。
-
服務器端關閉
QUICKACK,客戶端開啟TCP_CORK:客戶端發送 10 個字符,遠小于 MSS,因此會等待 200 毫秒超時后發送。

三、總結
延遲與帶寬利用率不可兼得。如果需要降低延遲,則應開啟 QUICKACK 和 NODELAY;否則關閉兩者,以提高帶寬利用率。
四、附 demo
Server 代碼
#include <stdio.h>
#include <string.h>
#include <unistd.h>
#include <stdlib.h>
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <sys/socket.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <netinet/tcp.h>
#include <signal.h>
#include <sys/wait.h>#define BUFLEN 1024int main (int argc, char** argv)
{int listenfd, connfd;socklen_t clilen;struct sockaddr_in cliaddr, servaddr;listenfd = socket (AF_INET, SOCK_STREAM, 0);memset (&cliaddr, 0, sizeof (cliaddr));memset (&servaddr, 0, sizeof (servaddr));servaddr.sin_family = AF_INET;servaddr.sin_addr.s_addr = htonl (INADDR_ANY);servaddr.sin_port = htons (9000);bind (listenfd, (struct sockaddr*)&servaddr, sizeof (servaddr));listen (listenfd, 128);printf ("Listening on port 9000...\n");clilen = sizeof (cliaddr);connfd = accept (listenfd, (struct sockaddr*)&cliaddr, &clilen);if (connfd <= 0) {perror ("accept error\n");exit (1);}int quick = 1;setsockopt (connfd, IPPROTO_TCP, TCP_QUICKACK, &quick, sizeof (int));sleep (10);close (connfd);return 0;
}
Client 代碼
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <netdb.h>
#include <errno.h>
#include <syslog.h>
#include <netinet/tcp.h>
#include <sys/socket.h>#define BUFLEN 1024int main (int argc, char** argv)
{int sockfd;struct sockaddr_in servaddr;if (argc != 2) {printf ("Usage: %s <server_addr>\n", argv[0]);exit (1);}sockfd = socket (AF_INET, SOCK_STREAM, 0);memset (&servaddr, 0, sizeof (servaddr));servaddr.sin_family = AF_INET;servaddr.sin_port = htons (9000);if (inet_pton (AF_INET, argv[1], &servaddr.sin_addr) <= 0) {printf ("Invalid address: %s\n", argv[1]);return 1;}if (connect (sockfd, (struct sockaddr*)&servaddr, sizeof (servaddr)) != 0) {printf ("Failed to connect to server %s, errno: %d\n", argv[1], errno);return 1;}int rc = 0;int nodelay = 1;rc = setsockopt (sockfd, IPPROTO_TCP, TCP_NODELAY, &nodelay, sizeof (int));int cork = 1;rc = setsockopt (sockfd, IPPROTO_TCP, TCP_CORK, &cork, sizeof (int));printf ("Connected and options set.\n");char sendline [2] = {0};sendline [0] = 'a';int n = 0;for (int i = 0; i < 10; i++)n += write (sockfd, sendline, strlen (sendline));printf ("%d bytes sent\n", n);if (read (sockfd, sendline, 2) <= 0) {printf ("Server terminated\n");exit (1);}return 0;
}
【計算機網絡】Socket 的 TCP_NODELAY 選項與 Nagle 算法
morris131 于 2024-01-19 09:44:36 發布
TCP_NODELAY 是一個套接字選項,用于控制 TCP 套接字的延遲行為。當 TCP_NODELAY 選項被啟用(即設置為 true)時,會禁用 Nagle 算法,從而實現 TCP 套接字的無延遲傳輸。這意味著每次發送數據時都會立即發送,不會等待緩沖區的填充或等待確認。
TCP_NODELAY 選項的演示
Socket 服務端代碼
package com.morris.socket;import java.io.IOException;
import java.io.InputStream;
import java.net.ServerSocket;
import java.net.Socket;/*** Socket 服務端,演示 TCP_NODELAY** @see java.net.SocketOptions*/
public class TcpNoDelayServerDemo {public static void main (String [] args) throws IOException {ServerSocket serverSocket = new ServerSocket (8090);while (true) {Socket client = serverSocket.accept ();System.out.println ("Accepted connection from: " + client.getRemoteSocketAddress ());new Thread (() -> {try {InputStream inputStream = client.getInputStream ();byte [] buffer = new byte [1024];while (true) {int len = inputStream.read (buffer);if (len == -1) {System.out.println ("Connection closed by: " + client.getRemoteSocketAddress ());inputStream.close ();client.close ();break;} else {System.out.print ("Received: " + new String (buffer, 0, len));}}} catch (IOException e) {e.printStackTrace ();}}).start ();}}
}
Socket 客戶端代碼
package com.morris.socket;import java.io.IOException;
import java.io.OutputStream;
import java.net.Socket;
import java.nio.charset.StandardCharsets;/*** Socket 客戶端,演示 TCP_NODELAY** @see java.net.SocketOptions*/
public class TcpNoDelayClientDemo {public static void main (String [] args) throws IOException {Socket socket = new Socket ("192.168.1.11", 8099);socket.setTcpNoDelay (true);OutputStream outputStream = socket.getOutputStream ();for (int i = 0; i < 10; i++) {outputStream.write ((i + "\n").getBytes (StandardCharsets.UTF_8));outputStream.flush ();}outputStream.close ();socket.close ();}
}
默認情況下(即 TcpNoDelay 為 false,開啟 Nagle 算法)的運行結果:
Accepted connection from: /192.168.1.10:4760
Received: 0
Received: 1
2
3
4
5
6
7
8
9
客戶端發送了 10 個報文,而服務端只收到了 2 個。客戶端在發送報文的過程中進行了合并。
以下是 tcpdump 抓到的服務端的報文,從中也可以清晰地看到,客戶端往服務端發送了 2 個數據報文(Flags 為 PSH):
$ tcpdump tcp port 8099
19:37:53.914138 IP 192.168.1.10.4760 > 192.168.1.11.8099: Flags [S], seq 3193331081, win 64240, options [mss 1452,nop,wscale 8,nop,nop,sackOK], length 0
19:37:53.914182 IP 192.168.1.11.8099 > 192.168.1.10.4760: Flags [S.], seq 2693275116, ack 3193331082, win 29200, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
19:37:53.925761 IP 192.168.1.10.4760 > 192.168.1.11.8099: Flags [.], ack 1, win 516, length 0
19:37:53.927131 IP 192.168.1.10.4760 > 192.168.1.11.8099: Flags [P.], seq 1:3, ack 1, win 516, length 2
19:37:53.927172 IP 192.168.1.11.8099 > 192.168.1.10.4760: Flags [.], ack 3, win 229, length 0
19:37:53.927977 IP 192.168.1.10.4760 > 192.168.1.11.8099: Flags [FP.], seq 3:21, ack 1, win 516, length 18
19:37:53.928363 IP 192.168.1.11.8099 > 192.168.1.10.4760: Flags [F.], seq 1, ack 22, win 229, length 0
19:37:53.940733 IP 192.168.1.10.4760 > 192.168.1.11.8099: Flags [.], ack 2, win 516, length 0
將 TcpNoDelay 設置為 true 后(即禁用 Nagle 算法)的運行結果:
Accepted connection from: /192.168.1.10:3307
Received: 0
Received: 1
Received: 2
Received: 3
4
Received: 5
6
Received: 7
Received: 8
9
客戶端發送了 10 個報文,而服務端收到了 7 個。客戶端在發送報文的過程中允許小的數據包立即發送,盡量不合并。
以下是 tcpdump 抓到的服務端的報文,從中也可以清晰地看到,客戶端往服務端發送了 10 個數據報文(Flags 為 PSH):
$ tcpdump tcp port 8099
19:39:07.953002 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [S], seq 2087425409, win 64240, options [mss 1452,nop,wscale 8,nop,nop,sackOK], length 0
19:39:07.953071 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [S.], seq 1383068300, ack 2087425410, win 29200, options [mss 1460,nop,nop,sackOK,nop,wscale 7], length 0
19:39:07.961935 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [.], ack 1, win 516, length 0
19:39:07.963806 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 1:3, ack 1, win 516, length 2
19:39:07.963808 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 3:5, ack 1, win 516, length 2
19:39:07.963858 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 3, win 229, length 0
19:39:07.963867 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 5, win 229, length 0
19:39:07.963903 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 5:7, ack 1, win 516, length 2
19:39:07.963925 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 7, win 229, length 0
19:39:07.963904 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 7:9, ack 1, win 516, length 2
19:39:07.963933 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 9, win 229, length 0
19:39:07.963904 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 9:11, ack 1, win 516, length 2
19:39:07.963939 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 11, win 229, length 0
19:39:07.964809 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 11:13, ack 1, win 516, length 2
19:39:07.964810 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 13:15, ack 1, win 516, length 2
19:39:07.964811 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 15:17, ack 1, win 516, length 2
19:39:07.964812 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 17:19, ack 1, win 516, length 2
19:39:07.964813 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [P.], seq 19:21, ack 1, win 516, length 2
19:39:07.964861 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 13, win 229, length 0
19:39:07.964868 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 15, win 229, length 0
19:39:07.964871 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 17, win 229, length 0
19:39:07.964874 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 19, win 229, length 0
19:39:07.964878 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [.], ack 21, win 229, length 0
19:39:07.964923 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [F.], seq 21, ack 1, win 516, length 0
19:39:07.965196 IP 192.168.1.11.8099 > 192.168.1.10.3307: Flags [F.], seq 1, ack 22, win 229, length 0
19:39:07.974934 IP 192.168.1.10.3307 > 192.168.1.11.8099: Flags [.], ack 2, win 516, length 0
Nagle 算法
TCP 協議是網絡編程中最重要的協議之一。TCP 協議將上層的數據附上 TCP 報頭等信息,封裝成一個個報文段(segment),然后交由下層網絡層去處理。TCP 協議定義了 TCP 報文段的結構,如下圖所示:

可以看出,TCP 每個報文段的首部大小至少是 20 字節。因此,如果用戶數據僅為 1 字節,再加上網絡層 IP 包頭 20 字節,則整個 IP 數據包的大小為 41 字節。那么整個 IP 數據包的負荷率為 1/41。這顯然是不劃算的,會降低網絡的傳輸效率。當網絡中充斥著這種 IP 數據包時,整個網絡幾乎都在傳輸一些無用的包頭信息,這種問題被稱為小包問題。特別是在 Telnet 協議中,當用戶遠程登錄到一個主機時,他的每一次鍵盤敲擊實際上都會產生一個攜帶用戶數據量小的數據包,這是典型的小包問題。
為了解決這種問題,出現了 Nagle 算法。該算法由 John Nagle 為解決實際過程中的小包問題而發明。其思想是將多個即將發送的小段用戶數據緩存并合并成一個大段數據,一次性發送出去。特別地,只要發送者還沒有收到前一次發送的 TCP 報文段的 ACK(即連接中還存在未回執 ACK 的 TCP 報文段),發送方就應該一直緩存數據,直到數據達到可以發送的大小,然后再統一合并到一起發送出去。如果收到上一次發送的 TCP 報文段的 ACK,則立即發送緩存的數據。
與之相呼應的還有一個網絡優化機制,稱為 TCP 延遲確認。這是針對接收方的機制。由于 ACK 包屬于有效數據較少的小包,因此延遲確認機制會導致接收方將多個收到數據包的 ACK 打包成一個回復包返回給發送方。這樣可以避免過多的只包含 ACK 的 TCP 報文段導致網絡額外開銷(前面提到的小包問題)。延遲確認機制有一個超時機制,即當收到每一個 TCP 報文段后,如果該 TCP 報文段的 ACK 超過一定時間還未發送,就會啟動超時機制,立刻將該 ACK 發送出去。因此,延遲確認機制可能會帶來 500 毫秒的 ACK 延遲確認時間。
延遲確認機制和 Nagle 算法幾乎是在同一時期提出的,但由不同的團隊提出。這兩種機制在某種程度上確實對網絡傳輸進行了優化,在通常的協議棧實現中,這兩種機制是默認開啟的。
然而,這兩種機制結合起來時,可能會產生一些負面的影響,導致應用程序的性能下降。
TCP_NODELAY 使用注意事項
Nagle 算法應用于發送端。簡而言之,對于發送端而言:
- 當第一次發送數據時,不需要等待,即使是 1 字節的小包也會立即發送。
- 后續發送數據時,需要累積數據包,直到滿足以下條件之一才會繼續發送數據:
- 數據包達到最大段大小 MSS。
- 接收端收到之前數據包的確認 ACK。
MTU(Maximum Transmission Unit)是指在網絡通信中能夠傳輸的最大數據包大小。MSS(Maximum Segment Size)通常小于等于 MTU,因為數據包中還包含 TCP/IP 協議頭部的額外開銷。一般情況下,IPv4 網絡中的 MTU 大小為 1500 字節,而 IPv6 網絡中的 MTU 大小為 1280 字節。
可以通過網卡信息查看 MTU 的大小:
$ ifconfig
eth0: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500
inet 172.24.104.61 netmask 255.255.240.0 broadcast 172.24.111.255
inet6 fe80::215:5dff:fe6f:5634 prefixlen 64 scopeid 0x20<link>
ether 00:15:5d:6f:56:34 txqueuelen 1000 (Ethernet)
RX packets 213794 bytes 293979318 (293.9 MB)
RX errors 0 dropped 0 overruns 0 frame 0
TX packets 106646 bytes 8514354 (8.5 MB)
TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
禁用 Nagle 算法可以降低延遲,適用于實時性要求較高的應用,如實時音視頻傳輸或實時游戲。然而,禁用 Nagle 算法可能會導致更頻繁的網絡傳輸,增加網絡開銷。因此,在傳輸大量小數據包的情況下,禁用 Nagle 算法可能會降低網絡效率。
TCP_NODELAY 選項通常在創建套接字后設置。對于已經建立的連接,可能需要重新創建套接字并設置選項。
需要根據具體的需求和場景來決定是否使用 TCP_NODELAY 選項,權衡延遲和網絡效率之間的關系。
TCP Nagle 算法:網絡優化的雙刃劍
Linux編程用C 發布于 2024-02-23 21:13?IP 屬地四川
在網絡通信的世界里,TCP(傳輸控制協議)是確保數據可靠傳輸的基石。然而,為了進一步提高網絡效率,TCP 引入了一系列優化算法,其中 Nagle 算法就是其中之一。今天,我們將探討 Nagle 算法的原理、作用 以及它在現代網絡中的應用。
Nagle 算法的起源
Nagle 算法由 John Nagle 在 1984 年提出,旨在解決 TCP/IP 網絡中的小分組問題。在廣域網(WAN)中,頻繁發送小數據包可能會導致網絡擁塞,因為每個小數據包都需要單獨的確認(ACK),這增加了網絡的負載。Nagle 算法通過合并小數據包來減少這種擁塞。
Nagle 算法的工作原理
Nagle 算法的核心思想是:在一個 TCP 連接上,最多只能有一個未被確認的小數據包(小于 MSS,即最大報文段大小)在網絡中。算法的邏輯如下:
- 如果有數據要發送,且可用窗口大小大于等于 MSS,或者數據包含 FIN 標志(表示連接即將關閉),則立即發送數據。
- 如果有未確認的數據,且新數據可以與未確認的數據合并(即新數據的大小加上未確認數據的大小小于 MSS),則將新數據添加到未確認數據的末尾。
- 如果新數據不能與未確認數據合并,且未確認數據已收到 ACK,那么發送未確認數據和新數據。
- 如果新數據不能與未確認數據合并,且未確認數據未收到 ACK,那么等待 ACK 到達后再發送新數據。
Nagle 算法的優勢與劣勢
優勢
- 減少網絡擁塞:通過合并小數據包,減少了網絡中的數據包數量,降低了擁塞的可能性。
- 提高網絡效率:在低速網絡中,Nagle 算法可以顯著提高傳輸效率。
劣勢
- 增加延遲:在交互式應用中,Nagle 算法可能導致顯著的延遲,因為它等待 ACK 或合并數據包。
- 不適用于實時應用:對于需要快速響應的應用(如在線游戲、實時視頻流),Nagle 算法可能會影響用戶體驗。
如何調整 Nagle 算法
在某些情況下,我們可能需要關閉 Nagle 算法以減少延遲。這可以通過設置 TCP_NODELAY 套接字選項來實現。在編程時,可以通過以下代碼片段來禁用 Nagle 算法:
int noDelay = 1;
setsockopt (socket, IPPROTO_TCP, TCP_NODELAY, (char *)&noDelay, sizeof (noDelay));
結語
Nagle 算法是 TCP 協議中的一個重要優化。它在提高網絡效率的同時,也可能帶來延遲問題。在設計網絡應用時,開發者需要根據應用的特性和網絡環境來決定是否使用 Nagle 算法。通過合理配置,我們可以在保證數據傳輸可靠性的同時,優化用戶體驗。
via:
-
TCP_NODELAY 詳解 - C/C+±Chinaunix
http://bbs.chinaunix.net/thread-3767363-1-1.html -
TCP/IP 詳解 --nagle 算法和 TCP_NODELAY_nagle 和 nodelay-CSDN 博客
https://blog.csdn.net/yusiguyuan/article/details/24109845 -
Linux 下 TCP 延遲確認(Delayed Ack)機制導致的時延問題分析_產生原因 (延遲確認機制和 Nagle 算法及_行者無疆_新浪博客
https://blog.sina.com.cn/s/blog_b4ef897e0102vgch.html -
神秘的 40 毫秒延遲與 TCP_NODELAY - wajika - 博客園
https://www.cnblogs.com/wajika/p/6573028.html -
Linux 下 TCP 延遲確認 (Delayed Ack) 機制導致的時延問題分析 - 騰訊云開發者社區 - 騰訊云
https://cloud.tencent.com/developer/article/1004356 -
套接字 socket 選項 TCP_NODELAY、TCP_CORK 與 TCP_QUICKACK_socket nodelay-CSDN 博客
https://blog.csdn.net/WEI_GW2012/article/details/123213084 -
【計算機網絡】Socket 的 TCP_NODELAY 選項與 Nagle 算法_tcp nodelay-CSDN 博客
https://blog.csdn.net/u022812849/article/details/135689740 -
TCP Nagle 算法:網絡優化的雙刃劍 - 知乎
https://zhuanlan.zhihu.com/p/683650018



















