文章目錄
- 🍖 前言
- 🎶一、抓取要求
- ?二、代碼展示
- 🏀三、運行結果
- 🏆四、知識點提示
🍖 前言
【爬蟲】網易云音樂歌詞/評論數據爬取
🎶一、抓取要求
描述:
輸入歌曲的id,獲取對應歌曲的用戶評論信息
?二、代碼展示
代碼如下:
from collections import OrderedDict
import requests as rq
import logging
import subprocess
import relogging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - 網易音樂歌詞Spider - %(message)s')# url記得脫密
url = 'aHR0cHM6Ly9tdXNpYy4xNjMuY29tL3dlYXBpL2NvbW1lbnQvcmVzb3VyY2UvY29tbWVudHMvZ2V0' headers = OrderedDict()
headers['user-agent'] = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/134.0.0.0 Safari/537.36 Edg/134.0.0.0"data = {"params": "","encSecKey": ""
}time_ = ''
for page in range(1, 10):print(['node', './js/comment.js', "2689097846", str(time_), str(page)])result = subprocess.run(['node', './js/comment.js', "2689097846", time_, str(page)], encoding='utf-8', capture_output=True, text=True, check=True)# 獲取腳本的輸出結果output = result.stdoutpattern = re.compile(r"encText.*?'(.*?)'.*?encSecKey.*?'(.*?)'", re.S)result = re.findall(pattern, output)data['params'] = result[0][0]data['encSecKey'] = result[0][1]res = rq.post(url, headers=headers, data=data, verify=False)logging.info("歌詞獲取成功:::")# logging.info(res.json()['data']['comments'])for item in res.json()['data']['comments']:logging.info("評論用戶:::" + item['user']['nickname'] + " 評論時間:::" + item['timeStr'] + " 評論內容:::"+item['content'])time_ = str(res.json()['data']['comments'][-1]['time'])
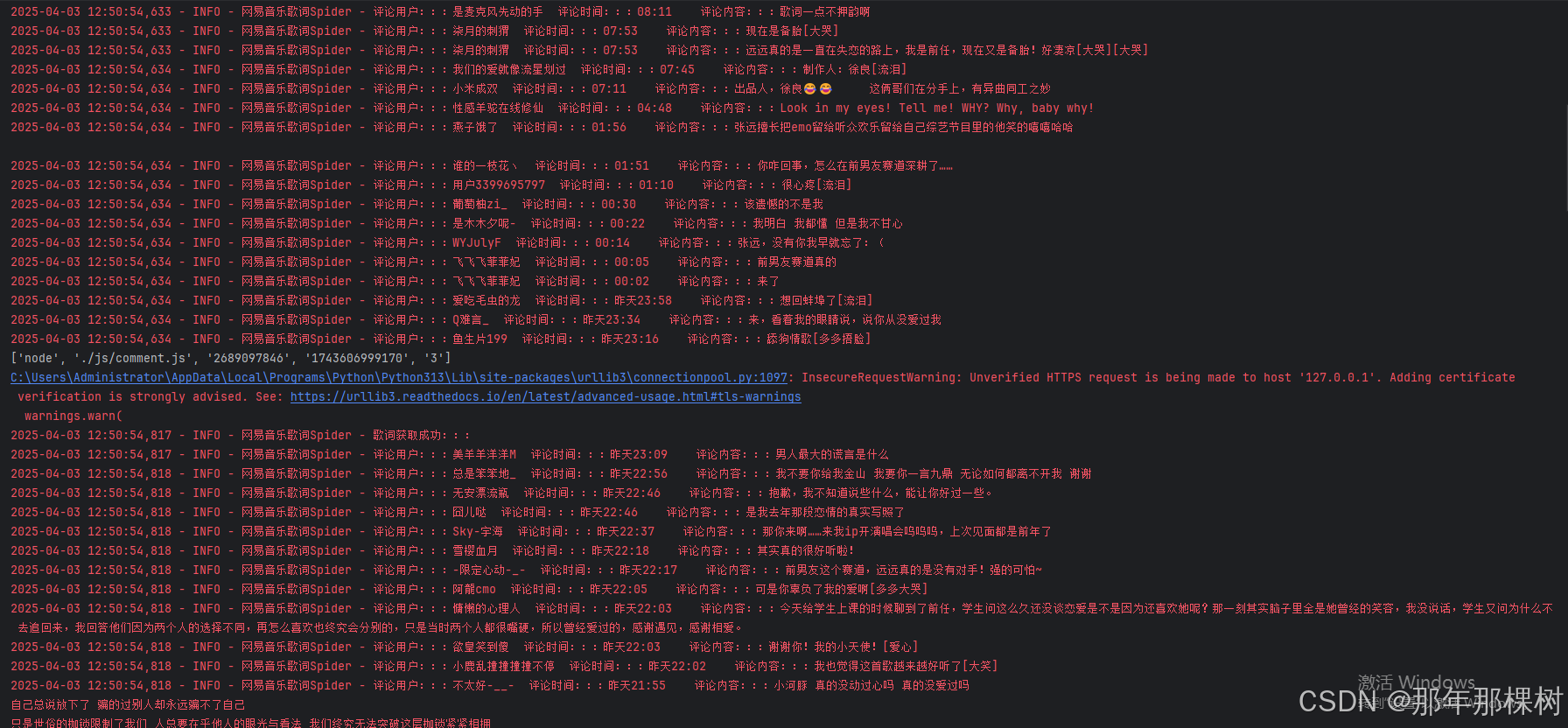
🏀三、運行結果
](https://i-blog.csdnimg.cn/direct/0ac0dbfd26fc436ca0696bb8a3f07f91.png)
🏆四、知識點提示
知識點1:
關鍵詞:扣代碼/補環境
需要源碼的留言,球球:二三六九四三三零八四
本文章中所有內容僅供學習交流使用,不用于其他任何目的,不提供完整代碼,抓包內容、敏感網址、數據接口等均已做脫敏處理,嚴禁用于商業用途和非法用途,否則由此產生的一切后果均與作者無關!本文章未經許可禁止轉載,禁止任何修改后二次傳播,擅自使用本文講解的技術而導致的任何意外,作者均不負責,若有侵權,請聯系作者立即刪除!!!



神經網絡的前向傳播TesorFlow與NumPy實現比對)


和自注意力(Self-Attention))
字符串娛樂篇16)
)










