目錄
?一、梯度消失的原因
二、梯度爆炸的原因
三、共同的結構性原因
四、解決辦法
五、補充知識
一、梯度消失的原因
梯度消失指的是在反向傳播過程中,梯度隨著層數的增加指數級減小(趨近于0),導致淺層網絡的權重幾乎無法更新。
1. 激活函數造成的梯度收縮
比如 sigmoid、tanh 函數在輸入過大或過小時,梯度趨近于 0,導致反向傳播過程中梯度逐層縮小。例如:Sigmoid的導數 σ′(x)=σ(x)(1?σ(x)),當 σ(x)接近0或1時,導數趨近于0。
2. 權重初始化不當
如果權重初始化得過小,前向傳播時值越來越小,反向傳播梯度也越來越小。
3. 網絡過深與鏈式法則的連乘效應:
深層網絡中梯度在多層鏈式求導中不斷乘以小于1的數,最終導致梯度接近 0。
反向傳播時,梯度是各層導數的連乘積
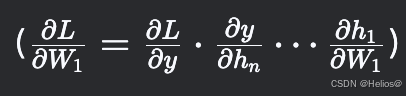 。
。
若每層導數均小于1,多層疊加后梯度會指數級縮小。
二、梯度爆炸的原因
梯度爆炸是指梯度在反向傳播過程中指數級增大(趨向無窮大),導致參數更新步長過大,模型無法收斂。
1. 激活函數或權重造成的梯度放大
比如 relu 在某些輸入下導數為1,但如果權重過大,前向傳播輸出和反向傳播梯度都可能爆炸。
2. 網絡結構太深
多層反向傳播中梯度不斷相乘,可能快速增長到很大。
3. 學習率過大
會導致更新步長過大,參數急劇變化,引發梯度爆炸。
三、共同的結構性原因
-
深層網絡或長依賴路徑:
無論是梯度消失還是爆炸,本質都是因為深層網絡的梯度需要通過多層反向傳播,鏈式法則的連乘效應被放大。 -
權重矩陣的共享(如RNN):
RNN中同一權重矩陣在時間步間共享,梯度爆炸/消失問題更顯著。
四、解決辦法
針對梯度消失:
-
使用非飽和激活函數(如ReLU、Leaky ReLU)。
-
殘差連接(ResNet中的Skip Connection)打破鏈式法則的連乘。
-
批歸一化(BatchNorm)穩定梯度分布。
-
合理的權重初始化(如He初始化)。
針對梯度爆炸:
-
梯度裁剪(Gradient Clipping)。
-
權重正則化(L2正則化)。
-
使用LSTM/GRU(通過門控機制緩解RNN中的梯度問題)。
通用策略:
-
調整網絡深度或使用分階段訓練。
-
監控梯度范數(如
torch.nn.utils.clip_grad_norm_)。
五、補充知識
非飽和激活函數和飽和激活函數有什么區別?
? 1、定義對比
| 類型 | 定義 | 特點 | 代表函數 |
|---|---|---|---|
| 飽和激活函數 | 當輸入很大或很小時,函數的導數(梯度)接近于 0 | 輸出趨于一個上限/下限,梯度變小 | Sigmoid、Tanh |
| 非飽和激活函數 | 輸入變大時,導數不會趨近于 0(或只有一邊趨近于0) | 不容易造成梯度消失 | ReLU、Leaky ReLU、ELU、Swish |
🧪 2、具體例子對比
🔻 飽和激活函數
(1) Sigmoid:
? 導數為:
? 當 時,
? 結果:反向傳播中梯度會越來越小 → 梯度消失
(2) Tanh:
? 輸出范圍在 [-1, 1]
? 同樣導數趨近于 0,容易梯度消失
🔺 非飽和激活函數
(1) ReLU(Rectified Linear Unit):
? x > 0 時導數為 1,不會梯度消失
? 缺點:x < 0 導數為 0,可能導致“神經元死亡”
(2) Leaky ReLU:
? 小于0時也有梯度(通常)
(3) Swish、ELU 等:
? 既平滑又非飽和,近年很多模型喜歡用 Swish 或 GELU(尤其是 Transformer)。
🎯 三、實戰中如何選?
| 場景 | 推薦激活函數 |
|---|---|
| 傳統全連接網絡(不太深) | Tanh / Sigmoid 勉強可用 |
| 卷積神經網絡 CNN | ReLU / Leaky ReLU / ELU |
| Transformer 等深層模型 | GELU / Swish |
| 生成式模型(例如 VAE、Flow) | ELU / LeakyReLU / Tanh(輸出層) |
🧠 一句話總結:
飽和函數容易梯度消失,不適合深層網絡; 非飽和函數傳播更穩定,是現代深度網絡的標配。




)











:藍牙面試問題與詳解)


