目錄
- 6.4 生成增強
- 6.4.1 何時增強
- 1)外部觀測法
- 2)內部觀測法
- 6.4.2 何處增強
- 6.4.3 多次增強
- 6.4.4 降本增效
- 1)去除冗余文本
- 2)復用計算結果
6.4 生成增強
檢索器得到相關信息后,將其傳遞給大語言模型以期增強模型的生成能力。利用這些信息進行生成增強是一個復雜的過程,不同的方式會顯著影響 RAG 的性能。
如何優化增強過程圍繞四個方面討論:
-
何時增強,確定何時需要檢索增強,以確保非必要不增強;
-
何處增強,確定在模型中的何處融入檢索到的外部知識,以最大化檢索的效用;
-
多次增強,如何對復雜查詢與模糊查詢進行多次迭代增強,以提升 RAG 在困難問題上的效果;
-
降本增效,如何進行知識壓縮與緩存加速,以降低增強過程的計算成本。
.
6.4.1 何時增強
大語言模型在訓練過程中掌握了大量知識,這些知識被稱為內部知識(Self Knowledge)。對于內部知識可以解決的問題,我們可以不對該問題進行增強。
不對是否需要增強進行判斷而盲目增強,可能引起生成效率和生成質量上的雙下降。
判斷是否需要增強的核心在于判斷大語言模型是否具有內部知識。兩種方法:
-
外部觀測法,通過 Prompt 直接詢問模型是否具備內部知識,或應用統計方法對是否具備內部知識進行估計,這種方法無需感知模型參數;
-
內部觀測法,通過檢測模型內部神經元的狀態信息來判斷模型是否存在內部知識, 這種方法需要對模型參數進行侵入式的探測。
1)外部觀測法
外部觀測法:通過直接對大語言模型進行詢問或者觀測調查其訓練數據來推斷其是否具備內部知識。判斷方法有:
-
Prompt 直接詢問大語言模型是否含有相應的內部知識
-
反復詢問大語言模型同一個問題觀察模型多次回答的一致性。
-
翻看訓練數據來判斷其是否具備內部知識。
-
設計偽訓練數據統計量來擬合真實訓練數據的分布,間接評估模型對知識的學習情況。比如,由于模型對訓練數據中低頻出現的知識掌握不足,而對更“流行”(高頻)的知識掌握更好,因此實體的流行度作可以作為偽訓練數據統計量。
2)內部觀測法
分析模型在生成時內部每一層的隱藏狀態變化,比如注意力模塊的輸出、多層感知器 (MLP) 層的輸出與激活值變化等,來進行評估其內部知識水平。
模型的中間層前饋網絡在內部知識檢索中起關鍵作用,通過訓練線性分類器(探針)可區分問題是否屬于模型“已知”或“未知”。研究針對注意力層輸出、MLP層輸出和隱層狀態三種內部表示設計實驗,結果表明大語言模型利用中間層隱藏狀態進行分類時準確率較高,驗證了中間層能有效反映模型對問題的知識儲備。
.
6.4.2 何處增強
在確定大語言模型需要外部知識后,我們需要考慮在何處利用檢索到的外部知識,即何處增強的問題。
輸入端、中間層和輸出端都可以進行知識融合操作:
-
在輸入端,可將問題和檢索到的外部知識拼接在 Prompt 中;
-
在中間層,可以采用交叉注意力將外部知識直接編碼到模型的隱藏狀態中;
-
在輸出端,可以利用外部知識對生成的文本進行后矯正。
.
6.4.3 多次增強
實際應用中,用戶對大語言模型的提問可能是復雜或模糊的。
-
處理復雜問題時,常采用分解式增強的方案。該方案將復雜問題分解為多個子問題,子問題間進行迭代檢索增強, 最終得到正確答案。
-
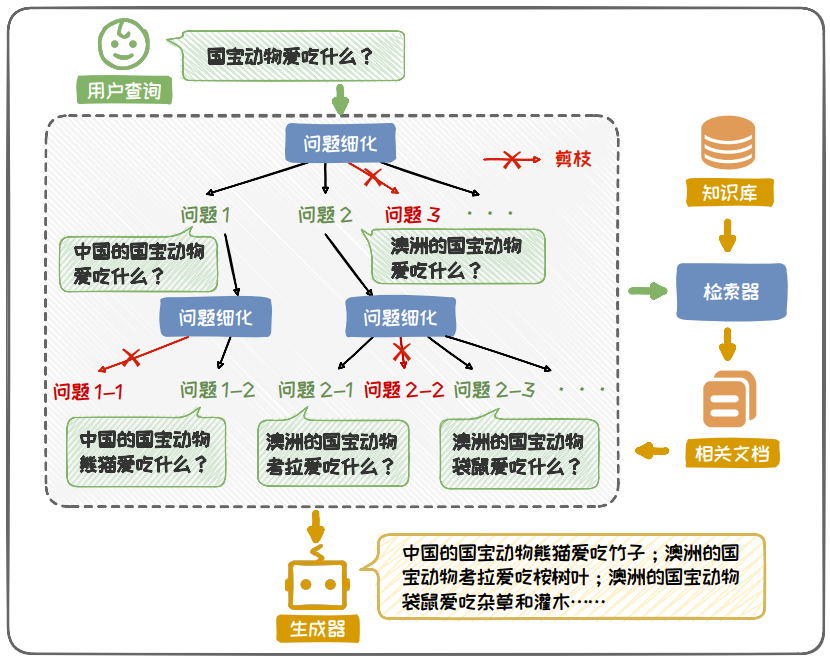
處理模糊問題時,常采用漸進式增強的方案。該方案將問題的不斷細化,然后分別對細化的問題進行檢索增強,力求給出全面的答案,以覆蓋用戶需要的答案。
圖 6.24: DSP 流程示意圖(分解式增強)
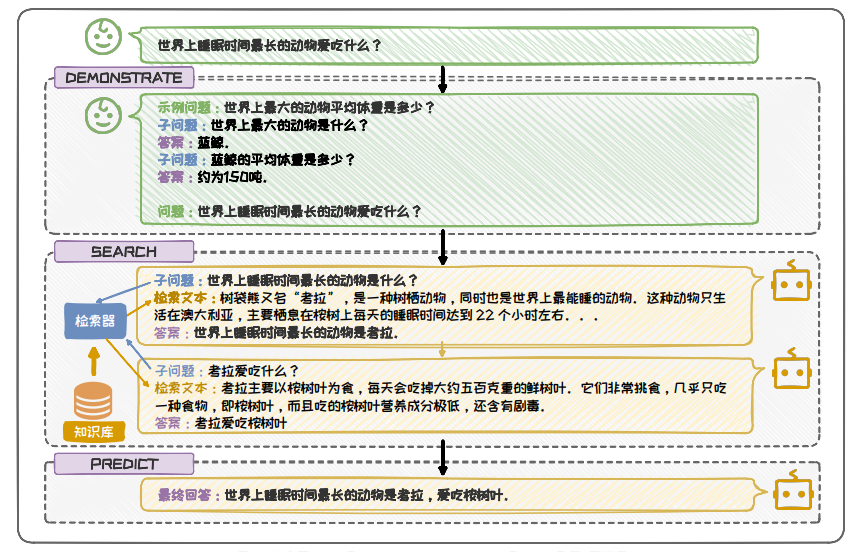
圖 6.25: TOC 框架流程示意圖(漸進式增強)
.
6.4.4 降本增效
檢索出的外部知識通常包含大量原始文本。將其通過 Prompt 輸入給大語言模型時,會大幅度增加輸入 Token 的數量,從而增加了大語言模型的推理計算成本。
此問題可從去除冗余文本與復用計算結果兩個角度進行解決。
1)去除冗余文本
去除冗余文本的方法通過對檢索出的原始文本的詞句進行過濾,從中選擇出部分有益于增強生成的部分。
去除冗余文本的方法主要分為三類:
-
Token級別的方法:
-
子文本級別的方法;
-
全文本級別的方法。
(1)Token級別的壓縮方法:
通過評估Token的困惑度來剔除冗余信息。困惑度低的Token表示信息量少,可能是冗余的;困惑度高的Token則包含更多信息。LongLLMLingua框架利用小模型計算困惑度,首先進行粗粒度壓縮,通過文檔的困惑度均值評估其重要性;然后進行細粒度壓縮,逐個Token評估并刪除低困惑度的Token。此外,該方法還引入了文檔重排序、動態壓縮比率和子序列恢復機制,以確保重要信息被有效保留。
(2)子文本級別方法通過:
評估子文本的有用性進行成片刪除。FITRAG方法利用雙標簽子文檔打分器,從事實性和模型偏好兩個維度評估子文檔。具體步驟為:滑動窗口分割文檔,雙標簽打分器評分,最后刪除低評分子文檔以去除冗余。
(3)全文本級別方法:
通過訓練信息提取器直接從文檔中抽取出重要信息以去除冗余。PRCA方法分為兩個階段:
-
上下文提取階段:通過監督學習最小化壓縮文本與原始文檔的差異,訓練提取器將文檔精煉為信息豐富的壓縮文本。
-
獎勵驅動階段:利用大語言模型作為獎勵模型,根據壓縮文本生成答案與真實答案的相似度作為獎勵信號,通過強化學習優化提取器。
最終,經典方法PRCA能夠端到端地將輸入文檔轉化為壓縮文本,高效去除冗余信息。
2)復用計算結果
可以對計算必需的中間結果進行復用,以優化 RAG 效率。
(1)KV-cache 復用
在大語言模型推理自回歸過程中,每個 Token 都要用之前 Token 注意力模塊的 Key 和 Value 的結果。為避免重新計算,我們將之前計算的 Key 和 Value 的結果進行緩存(即 KV-cache),在需要是直接從 KV-cache 中調用。
然而,隨著輸入文本長度的增加,KV-cache 的 GPU 顯存占用會顯著增加,甚至超過模型參數的顯存占用。
圖 6.26: RAGCache 框架流程示意圖
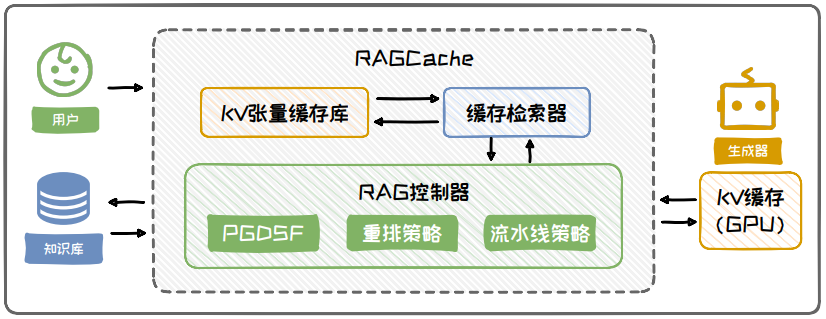
不過,RAG 中不同用戶查詢經常檢索到相同的文本,而且常見的查詢通常數量有限。因此,我們可以將常用的重復文本的 KV-cache 進行復用。基于此,RAGCache 設計了一種 RAG 系統專用的多級動態緩存機制,核心部分:
-
KV 張量緩存庫:采用樹結構來緩存所計算出的文檔 KV 張量,其中每個樹節點代表一個文檔;
-
緩存檢索器:負責在緩存庫中快速查找是否存在所需的緩存節點;
-
RAG 控制器:作為系統的策略中樞,負責制定核心的緩存策略。
為優化 RAG 性能,RAG 控制器采用了以下策略:
-
PGDSF 替換策略:通過綜合考慮文檔的訪問頻率、大小、訪問成本和最近訪問時間,優化頻繁使用文檔的檢索效率。
-
重排策略:調整請求處理順序,優先處理高緩存利用率的請求,減少重新計算的需求。
-
動態推測流水線策略:并行執行 KV 張量檢索和模型推理,降低端到端延遲。
.
其他參考:【大模型基礎_毛玉仁】系列文章
聲明:資源可能存在第三方來源,若有侵權請聯系刪除!

預覽的vue組件庫)





:DMP與DSP對接及數據統計原理剖析)
)
【本期題目:砍柴,回文字符串】)
)


)





