論文下載:
https://arxiv.org/pdf/2310.19210
一、基本原理
該方法包括兩個階段:半監督表示學習和社區檢測。在半監督表示學習中,使用了監督對比損失來充分地推導標記信息。此外,由于對比學習方法與協同訓練假設一致,研究引入了同一樣本的弱增強和強增強以提取兩種不同的視圖。最后,該研究還部署了協同訓練框架,以加強兩個視圖之間特征原型相似性和聚類分配的一致性。在社區檢測中,研究利用在半監督表示學習中學習到的特征嵌入來構造主圖,然后應用社區檢測方法來獲得結果。
二、擬解決的關鍵問題
為了克服使用新類別發現(NCD)、半監督學習k-means的限制,該研究提出了一種用于聚類分配的協同訓練一致性策略,以發現未標記數據集中的潛在表示。對于最終的聚類目標,研究利用社區檢測技術為未標記的實例分配標簽,并根據學習到的表示自動確定聚類類別的最佳數量。
三、相關解決方案
對通用數據集的評估結果如圖1所示。該方法在所有通用數據集(特別是在ImageNet100上)上的All和Novel測試中達到了最先進的性能,也與已知的其他方法取得了相當的結果。具體來說,對于所有類,該方法在CIFAR-10、CIFAR-100和ImageNet-100上分別比GCD方法高0.8%、5.5%和7.0%。對于Novel類,它在CIFAR-10上高6.2%,在CIFAR-100上高9.1%,在ImageNet-100上高15.5%。這些實驗結果表明,該方法在未標記的數據集上學習到更緊湊的表示。此外,UNO+使用線性分類器,它在已知類上顯示出很強的準確性,但在新穎類上導致性能較差。
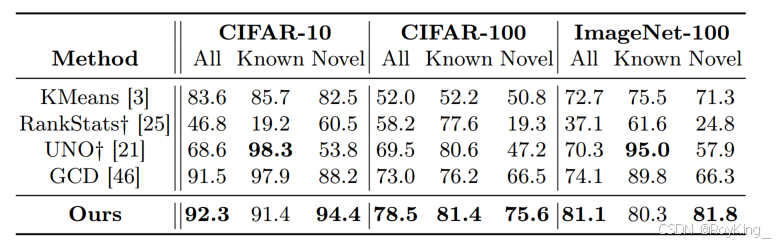
圖1 通用數據集驗結果
圖2中報告了三個細粒度數據集的結果。該方法在測試的三個數據集的所有類上顯示出最佳性能,并且在已知類和新穎類上取得了可比的結果,證明了方法在細粒度類別發現方面的有效性。具體來說,在CUB-200、Stanford-Scars和herbarum19數據集上,方法在所有類別上分別比最先進的方法提高了6.7%、8.6%和0.9%。對于Novel類,方法在Stanford-cars和herbararium19上分別比GCD高3.9%和3.7%。同時,研究發現,由于細粒度數據集之間的低可變性,使得發現新穎類更加困難,因此在結果方面,新穎類的精度通常較低。
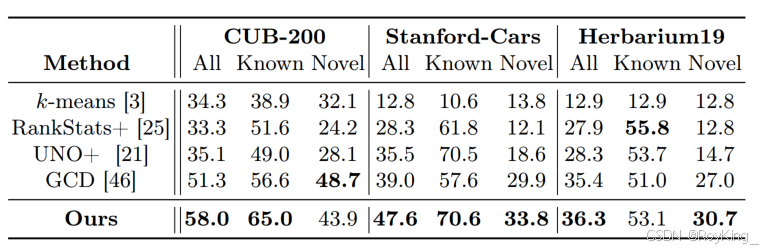
圖2 三個細粒度數據集實驗結果
為了更直觀地探索不同方法上的聚類特征,本研究在CIFAR-10上使用T-SNE將DINO、GCD和我們的方法提取的特征進一步可視化。如圖所示,與DINO和GCD相比,該方法得到了更清晰的群間邊界,也得到了更緊湊的簇。

圖3 鄰域大小消融實驗結果
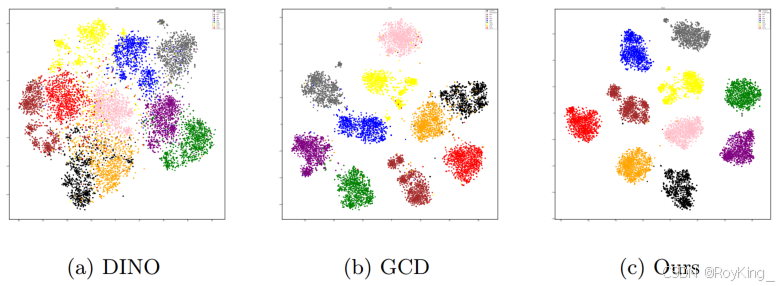
圖4 聚類結果
四、總結
本研究引入了一個聚類分配一致性框架,提出了一種GCD的協同訓練策略。此外,還提出了一種社區檢測方法來解決GCD中的半監督聚類問題。實驗結果表明,該方法在通用和細粒度任務中都達到了最先進的性能。
五、思考
通過研究結果可以看出,該研究提出的一種用于聚類分配的協同訓練一致性策略在對通用數據集以及三個細粒度數據集上都取得了較好的結果,也得到了更清晰的簇與簇邊界,但是在新穎類的發現上性能較差,可以嘗試對該方法進行改進。







服務器)









)

:目標檢測與 YOLOv12 實戰)