
發現了一個寶藏項目, 宣傳是完全從0開始,僅用3塊錢成本 + 2小時!即可訓練出僅為25.8M的超小語言模型MiniMind,最小版本體積是 GPT-3 的?17000,做到最普通的個人GPU也可快速訓練
https://github.com/jingyaogong/minimind![]() https://github.com/jingyaogong/minimind
https://github.com/jingyaogong/minimind
項目包含
- MiniMind-LLM結構的全部代碼(Dense+MoE模型)。
- 包含Tokenizer分詞器詳細訓練代碼。
- 包含Pretrain、SFT、LoRA、RLHF-DPO、模型蒸餾的全過程訓練代碼。
- 收集、蒸餾、整理并清洗去重所有階段的高質量數據集,且全部開源。
- 從0實現預訓練、指令微調、LoRA、DPO強化學習,白盒模型蒸餾。關鍵算法幾乎不依賴第三方封裝的框架,且全部開源。
- 同時兼容
transformers、trl、peft等第三方主流框架。 - 訓練支持單機單卡、單機多卡(DDP、DeepSpeed)訓練,支持wandb可視化訓練流程。支持動態啟停訓練。
- 在第三方測評榜(C-Eval、C-MMLU、OpenBookQA等)進行模型測試。
- 實現Openai-Api協議的極簡服務端,便于集成到第三方ChatUI使用(FastGPT、Open-WebUI等)。
- 基于streamlit實現最簡聊天WebUI前端。
訓練數據集下載地址?魔搭社區
創建./dataset目錄, 存放訓練數據集,該pretrain_hq.jsonl數據集是從?匠數大模型數據集?里清洗出字符<512長度的大約1.6GB的語料直接拼接而成
關于匠數大模型SFT數據集?“, 它是一個完整、格式統一、安全的大模型訓練和研究資源。 從網絡上的公開數據源收集并整理了大量開源數據集,對其進行了格式統一,數據清洗, 包含10M條數據的中文數據集和包含2M條數據的英文數據集。” 以上是官方介紹,下載文件后的數據總量大約在4B tokens,肯定是適合作為中文大語言模型的SFT數據的。 但是官方提供的數據格式很亂,全部用來sft代價太大。
預訓練?pretrain_hq.jsonl?數據格式為
{"text": "如何才能擺脫拖延癥? 治愈拖延癥并不容易,但以下建議可能有所幫助..."}
關于提高語料質量,有一種基于query-utterance pair拼接方式,Query-Utterance Pair 拼接方式是一種多輪對話上下文建模方法。它將當前的用戶輸入(query)與歷史對話中的某一句或多句用戶發言(utterance)配對拼接,作為模型的輸入。這種方式的核心是顯式地利用對話歷史中的關鍵信息,而不是簡單地將所有歷史對話拼接在一起。
假設一個多輪對話場景:
- 歷史對話:
- 用戶第1輪:我想訂一張去上海的機票。
- 模型第1輪:好的,請告訴我出發地和日期。
- 用戶第2輪:從北京出發,明天。
- 當前輸入(query):多少錢?
如果直接將所有歷史對話拼接,可能得到:
我想訂一張去上海的機票。好的,請告訴我出發地和日期。從北京出發,明天。多少錢?
這種方式雖然包含了完整上下文,但信息冗余且缺乏重點,可能導致模型難以聚焦關鍵信息。
Query-Utterance Pair 拼接則會選擇與當前 query 最相關的歷史 utterance
去上海,明天。多少錢?
通過這種配對,模型輸入被簡化為一個更緊湊、更相關的上下文表示
- 增強上下文相關性
- 多輪問答任務需要模型理解當前問題與歷史對話的關聯。Query-Utterance Pair 通過篩選關鍵歷史 utterance,避免無關信息干擾,提升模型對上下文的理解能力。
- 減少輸入長度
- 完整歷史拼接可能導致輸入過長(尤其在 Transformer 模型中會增加計算成本或超過最大長度限制)。這種方式減少了輸入長度,提高了計算效率。
- 提升多輪問題準確率
- 你的實驗表明,這種拼接方式使多輪問題準確率提升了 17%,說明它幫助模型更好地捕捉對話中的邏輯鏈條。例如,“多少錢”與“從北京出發,明天”的配對直接關聯到價格查詢意圖。
- 提高 BLEU 分數
- BLEU(Bilingual Evaluation Understudy)衡量生成文本與參考文本的相似度,提升 12% 表明模型生成的回答更貼近預期,這得益于上下文輸入的精準性。
sft_mini_512.jsonl 文件的數據格式
{"conversations": [{"role": "user","content": "打開音樂播放器。"}, {"role": "assistant","content": "好的,現在您的音樂播放器已經打開了。請問您想聽哪首歌曲呢?"}, {"role": "user","content": "隨便放一首歌吧。"}, {"role": "assistant","content": "好的,現在為您播放歌曲。請問還需要我為您做其他的什么嗎?"}, {"role": "user","content": "給我推薦一部好看的電影。"}, {"role": "assistant","content": "好的,這里有一部近期口碑還不錯的電影《大魚海棠》。它是一部優秀的國產動畫電影,非常值得一看。不知道您是否喜歡呢?"}, {"role": "user","content": "我想知道現在的天氣情況。"}, {"role": "assistant","content": "好的,請問您現在的所在地點是哪里?我可以根據您所在的位置來查詢天氣情況。"}, {"role": "user","content": "上海。"}, {"role": "assistant","content": "好的,現在上海地區的天氣情況如下:溫度為20℃,多云轉晴。請問還需要我為您做其他的什么嗎?"}]
}MiniMindLM 模型結構
MiniMindLM 是一個高效的 Transformer 語言模型,通過 MoE 機制在保持強大表達能力的同時降低計算成本。其結構設計清晰,兼顧訓練和推理需求,適合生成任務和資源受限場景 ,MoE 的引入(MoEGate 和 MOEFeedForward)是最大亮點,通過稀疏激活和專家均衡優化,顯著提升了模型的性能和可擴展性。查看下模型結構
class MiniMindLM(PreTrainedModel):config_class = LMConfigdef __init__(self, params: LMConfig = None):self.params = params or LMConfig()super().__init__(self.params)self.vocab_size, self.n_layers = params.vocab_size, params.n_layersself.tok_embeddings = nn.Embedding(params.vocab_size, params.dim)self.dropout = nn.Dropout(params.dropout)self.layers = nn.ModuleList([MiniMindBlock(l, params) for l in range(self.n_layers)])self.norm = RMSNorm(params.dim, eps=params.norm_eps)self.output = nn.Linear(params.dim, params.vocab_size, bias=False)self.tok_embeddings.weight = self.output.weightself.register_buffer("pos_cis",precompute_pos_cis(dim=params.dim // params.n_heads, theta=params.rope_theta),persistent=False)self.OUT = CausalLMOutputWithPast()def forward(self,input_ids: Optional[torch.Tensor] = None,past_key_values: Optional[List[Tuple[torch.Tensor, torch.Tensor]]] = None,use_cache: bool = False,**args):past_key_values = past_key_values or [None] * len(self.layers)start_pos = args.get('start_pos', 0)h = self.dropout(self.tok_embeddings(input_ids))pos_cis = self.pos_cis[start_pos:start_pos + input_ids.size(1)]past_kvs = []for l, layer in enumerate(self.layers):h, past_kv = layer(h, pos_cis,past_key_value=past_key_values[l],use_cache=use_cache)past_kvs.append(past_kv)logits = self.output(self.norm(h))aux_loss = sum(l.feed_forward.aux_loss for l in self.layers if isinstance(l.feed_forward, MOEFeedForward))self.OUT.__setitem__('logits', logits)self.OUT.__setitem__('aux_loss', aux_loss)self.OUT.__setitem__('past_key_values', past_kvs)return self.OUT該模型是一個基于 Transformer 的語言模型,結合了混合專家模型(Mixture of Experts, MoE)技術,旨在通過高效的計算和稀疏激活提升性能。
整體架構
MiniMindLM 是一個典型的因果語言模型(Causal Language Model),其結構遵循 Transformer 的 Decoder-only 設計,類似于 GPT 系列,但加入了 MoE 機制以提升效率和性能。主要組成部分包括:
- 輸入嵌入層(tok_embeddings):將輸入 token 映射為高維向量。
- 多層 Transformer Block(MiniMindBlock):核心計算單元,包含注意力機制和前饋網絡(可選 MoE)。
- 歸一化層(norm):RMSNorm 用于穩定訓練。
- 輸出層(output):將隱藏狀態映射回詞匯表大小的 logits。
- 位置編碼(pos_cis):采用 RoPE(Rotary Position Embedding)來編碼序列位置信息。
關鍵特點
- 因果性:通過 CausalLMOutputWithPast 輸出,表明這是一個自回歸模型,適用于生成任務。
- MoE 支持:通過 use_moe 參數控制是否使用 MOEFeedForward,替代傳統的 FeedForward,引入稀疏專家機制。
- 緩存支持:past_key_values 和 use_cache 參數表明支持增量推理(incremental decoding),優化生成效率。
- 共享權重:tok_embeddings.weight = self.output.weight,輸入嵌入和輸出層的權重共享,減少參數量。
核心組件分析
(1) MiniMindBlock
這是 Transformer 的單層結構,包含以下子模塊:
- 注意力機制(Attention):
- 使用多頭自注意力(Multi-Head Self-Attention),頭數由 n_heads 控制,每個頭的維度為 head_dim = dim // n_heads。
- 輸入經過 attention_norm(RMSNorm)歸一化后,進入注意力計算。
- 支持緩存(past_key_value),用于加速推理。
- 輸出 h_attn 與輸入殘差連接(x + h_attn)。
- 前饋網絡(FeedForward 或 MOEFeedForward):
- 默認使用標準前饋網絡(FeedForward),但若 use_moe=True,則切換為 MOEFeedForward。
- 輸入經過 ffn_norm(RMSNorm)歸一化后,進入前饋計算。
- 輸出與殘差連接(h + feed_forward(...))。
- 歸一化:使用 RMSNorm 而非 LayerNorm,計算效率更高,且穩定性較好。
作用:
MiniMindBlock 是模型的核心計算單元,負責捕捉序列中的依賴關系(注意力)和進行特征變換(前饋網絡)。MoE 的引入使得前饋部分更高效,僅激活部分專家而非全部參數。
(2) MOEFeedForward
這是混合專家模型的前饋網絡實現,替代傳統全連接層。主要特點:
- 專家模塊(experts):
- 包含 n_routed_experts 個獨立的前饋網絡(FeedForward),每個專家處理特定的輸入子集。
- 門控機制(gate):
- 通過 MoEGate 決定每個 token 分配給哪些專家(topk_idx)及其權重(topk_weight)。
- 共享專家(shared_experts):
- 可選模塊(n_shared_experts 不為 None 時啟用),為所有 token 提供一個共享的前饋計算,增強通用性。
- 訓練與推理差異:
- 訓練模式:輸入重復 num_experts_per_tok 次,分別送入對應專家,輸出加權求和。
- 推理模式:通過 moe_infer 函數高效計算,僅激活必要專家。
作用:
MOEFeedForward 通過稀疏激活減少計算量,同時利用多個專家捕捉不同模式,提升模型容量和表達能力。aux_loss(輔助損失)用于平衡專家的使用率,避免某些專家被過度忽略。
(3) MoEGate
這是 MoE 的門控機制,負責為每個 token 選擇 Top-k 專家。主要邏輯:
- 線性評分:
- 輸入 hidden_states 通過線性層(F.linear)計算與 n_routed_experts 個專家的得分(logits)。
- 得分歸一化:
- 默認使用 softmax 將 logits 轉為概率分布(scores)。
- Top-k 選擇:
- 使用 torch.topk 選取得分最高的 top_k 個專家及其權重。
- 若 norm_topk_prob=True,對 Top-k 權重歸一化(和為 1)。
- 輔助損失(aux_loss):
- 在訓練時計算,用于鼓勵專家均衡使用。
- 有兩種模式:
- seq_aux=True:基于序列級別的專家使用率計算交叉熵。
- seq_aux=False:基于全局專家使用率計算交叉熵。
- 損失乘以超參數 alpha,加到總損失中。
作用:
MoEGate 是 MoE 的核心調度器,確保每個 token 只激活少量專家(top_k),降低計算成本,同時通過 aux_loss 防止專家使用不均。
(4) MiniMindLM
頂層模型整合所有組件:
- 輸入處理:
- tok_embeddings 將 token ID 轉為嵌入向量,加入 dropout。
- pos_cis(RoPE 位置編碼)動態截取,適配輸入長度。
- 層級計算:
- 依次通過 n_layers 個 MiniMindBlock,每層更新隱藏狀態并緩存鍵值對。
- 輸出:
- 經過 norm 歸一化后,output 層生成 logits。
- 若使用 MoE,累加所有層的 aux_loss。
輸出格式:
CausalLMOutputWithPast 包含 logits(預測分布)、aux_loss(MoE 輔助損失)和 past_key_values(緩存)。
設計亮點
- MoE 優化:
- 通過 top_k 和 n_routed_experts,模型只激活部分專家,大幅減少計算量。例如,若 n_routed_experts=8,top_k=2,每個 token 只調用 25% 的專家參數。
- aux_loss 確保專家分配均衡,避免“專家坍縮”(某些專家從未被使用)。
- 高效推理:
- moe_infer 使用 scatter_add_ 高效聚合專家輸出,避免顯式循環。
- 緩存機制(past_key_values)支持自回歸生成,適合對話或文本生成任務。
- 靈活性:
- use_moe 參數允許切換傳統 FFN 和 MoE FFN,便于實驗對比。
- n_shared_experts 提供通用專家,彌補稀疏專家的局限性。
- 穩定性:
- RMSNorm 和 Kaiming 初始化(reset_parameters)提升訓練穩定性。
- 權重共享(嵌入和輸出層)減少參數量,適合資源受限場景。
- 計算復雜度:
- 傳統 Transformer 的 FFN 復雜度為 O(bsz?seqlen?dim2)O(bsz \cdot seq_len \cdot dim^2)O(bsz?seql?en?dim2)。
- MoE 模式下,每個 token 只激活 top_k 個專家,復雜度降為 O(bsz?seqlen?dim?topk?nroutedexperts/totalexperts)O(bsz \cdot seq_len \cdot dim \cdot top_k \cdot n_routed_experts / total_experts)O(bsz?seql?en?dim?topk??nr?outede?xperts/totale?xperts),顯著降低。
- 內存需求:增加 n_routed_experts 會提升參數量,但實際激活的參數量由 top_k 控制,內存占用可控。
- 訓練開銷:aux_loss 引入額外計算,但對性能提升至關重要,尤其在專家數量較多時。
評估下minimind的訓練參數量
計算 MiniMindLM 的訓練參數量,我們需要分析其所有可訓練的模塊,并根據代碼中的配置參數(LMConfig)推導出具體的參數數量。按照默認的LMConfig
class LMConfig(PretrainedConfig):model_type = "minimind"def __init__(self,dim: int = 512,n_layers: int = 8,n_heads: int = 8,n_kv_heads: int = 2,vocab_size: int = 6400,hidden_dim: int = None,multiple_of: int = 64,norm_eps: float = 1e-5,max_seq_len: int = 8192,rope_theta: int = 1e6,dropout: float = 0.0,flash_attn: bool = True,##################################################### Here are the specific configurations of MOE# When use_moe is false, the following is invalid####################################################use_moe: bool = False,####################################################num_experts_per_tok: int = 2,n_routed_experts: int = 4,n_shared_experts: bool = True,scoring_func: str = 'softmax',aux_loss_alpha: float = 0.1,seq_aux: bool = True,norm_topk_prob: bool = True,**kwargs,)從 LMConfig 中提取關鍵參數:
- dim = 512(隱藏層維度)。
- n_layers = 8(Transformer 層數)。
- n_heads = 8(注意力頭數)。
- n_kv_heads = 2(鍵值頭的數量,可能用于分組查詢注意力 GQA,但這里先按標準計算)。
- vocab_size = 6400(詞匯表大小)。
- hidden_dim = None(未指定,假設前饋網絡中間層維度為 4 * dim,即 2048)。
- max_seq_len = 8192(最大序列長度,僅影響緩沖區,不影響參數量)。
- use_moe = False(默認不使用 MoE)。
- MoE 相關參數(僅在 use_moe=True 時生效):
- num_experts_per_tok = 2(每個 token 激活的專家數,Top-k)。
- n_routed_experts = 4(路由專家數量)。
- n_shared_experts = True(布爾值,但代碼中應為整數,假設為 1)。
- norm_eps 和 dropout 等不影響參數量。
由于 use_moe 默認值為 False,我將先計算非 MoE 模式下的參數量,然后再計算 use_moe=True 的情況以作對比。
2. 參數量計算(use_moe=False)
(1) 輸入嵌入層(tok_embeddings)
- 結構:nn.Embedding(vocab_size, dim)。
- 參數量:vocab_size * dim = 6400 * 512 = 3,276,800。
- 說明:嵌入層和輸出層共享權重,因此只計算一次。
(2) 輸出層(output)
- 結構:nn.Linear(dim, vocab_size, bias=False)。
- 參數量:dim * vocab_size = 512 * 6400 = 3,276,800。
- 共享權重后,總嵌入參數仍為 3,276,800。
(3) MiniMindBlock(每層)
每層包含注意力模塊、前饋網絡和兩個 RMSNorm。
注意力模塊(Attention)
- 假設為標準多頭自注意力(未明確使用 GQA,但 n_kv_heads=2 暗示可能優化 KV 計算,暫按標準計算):
- QKV 線性變換:
- 輸入 dim,輸出 dim(n_heads * head_dim,head_dim = 512 // 8 = 64)。
- 參數量:dim * dim * 3 = 512 * 512 * 3 = 786,432。
- 輸出線性變換:
- 參數量:dim * dim = 512 * 512 = 262,144。
- 總計:786,432 + 262,144 = 1,048,576。
- QKV 線性變換:
RMSNorm(attention_norm 和 ffn_norm)
- 每個 RMSNorm:dim = 512。
- 兩個 RMSNorm:2 * 512 = 1,024。
前饋網絡(FeedForward)
- 假設為標準兩層 MLP,中間層維度 ffn_dim = 4 * dim = 2048(常見設置):
- 第一層:dim -> ffn_dim,參數量 512 * 2048 = 1,048,576。
- 第二層:ffn_dim -> dim,參數量 2048 * 512 = 1,048,576。
- 無偏置假設,總計:1,048,576 + 1,048,576 = 2,097,152。
單層總參數量
- 注意力:1,048,576。
- 前饋:2,097,152。
- RMSNorm:1,024。
- 總計:1,048,576 + 2,097,152 + 1,024 = 3,146,752。
(4) 所有層
- n_layers = 8。
- 總計:8 * 3,146,752 = 25,174,016。
(5) 頂層 RMSNorm(norm)
- 參數量:dim = 512。
總參數量(use_moe=False)
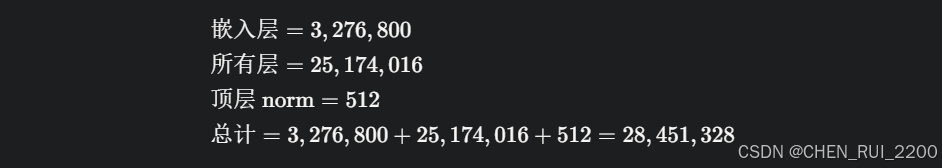
3. 參數量計算(use_moe=True)
假設 use_moe=True,并使用 MoE 參數:
- n_routed_experts = 4。
- n_shared_experts = 1(將布爾值 True 視為 1)。
(1) 輸入嵌入層和輸出層
- 同上:3,276,800。
(2) MiniMindBlock(每層)
注意力模塊和 RMSNorm 不變,變化在于 MOEFeedForward。
注意力模塊
- 同上:1,048,576。
RMSNorm
- 同上:1,024。
MOEFeedForward
- 專家網絡(experts):
- n_routed_experts = 4,每個專家是一個 FeedForward。
- 單個專家:2,097,152(如上計算)。
- 總計:4 * 2,097,152 = 8,388,608。
- 共享專家(shared_experts):
- n_shared_experts = 1,參數量:2,097,152。
- 門控機制(MoEGate):
- 權重:n_routed_experts * dim = 4 * 512 = 2,048。
- MOEFeedForward 總計:
- 8,388,608 + 2,097,152 + 2,048 = 10,487,808。
單層總參數量
- 注意力:1,048,576。
- 前饋(MoE):10,487,808。
- RMSNorm:1,024。
- 總計:1,048,576 + 10,487,808 + 1,024 = 11,537,408。
(3) 所有層
- n_layers = 8。
- 總計:8 * 11,537,408 = 92,299,264。
(4) 頂層 RMSNorm
- 同上:512。
總參數量(use_moe=True)

4. 結果對比
- use_moe=False:28,451,328 參數(約 28.45M)。
- use_moe=True(n_routed_experts=4, n_shared_experts=1):95,576,576 參數(約 95.58M)。 后面可以看下模型文件大小滿足該理論值
開啟預訓練?
python train_pretrain.py???預訓練(學知識)

python train_full_sft.py 監督微調(學對話方式)
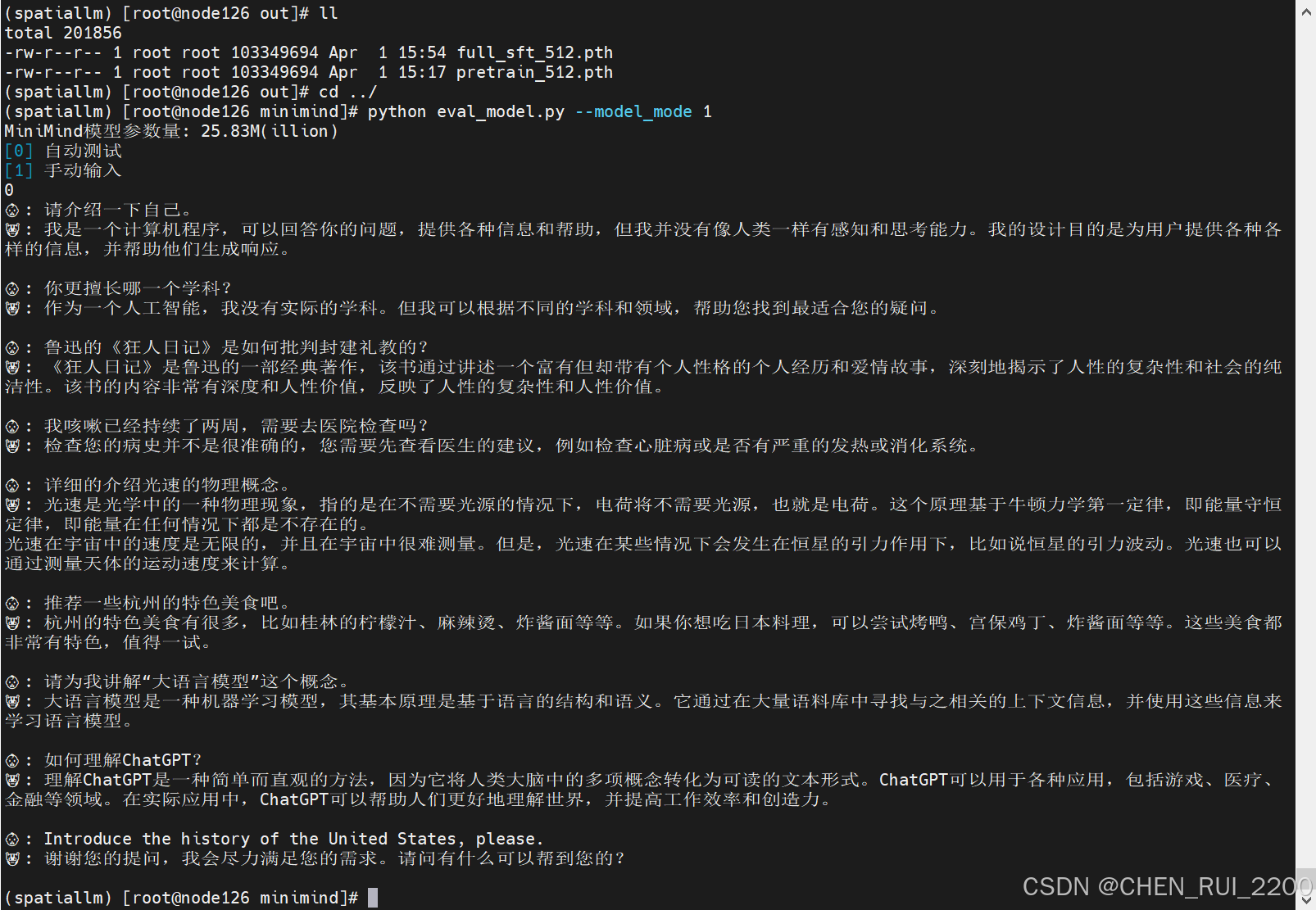
測試模型效果
確保需要測試的模型*.pth文件位于./out/目錄下

# 默認為0:測試pretrain模型效果,設置為1:測試full_sft模型效果
python eval_model.py --model_mode 1自動測試
模型轉換下格式方便在 webui上使用
(spatiallm) [root@node126 minimind]# cd scripts/
(spatiallm) [root@node126 scripts]# python convert_model.py
模型參數: 25.829888 百萬 = 0.025829888 B (Billion)
模型已保存為 Transformers 格式: ../MiniMind2-Small
修改下 web_demo.py里模型路徑映射
# 模型路徑映射
MODEL_PATHS = {"MiniMind2-Small (0.025829888 B)": ["../MiniMind2-Small", "MiniMind2-Small"],
}
selected_model = st.sidebar.selectbox('Models', list(MODEL_PATHS.keys()), index=0)看下web demo的提示詞是怎么寫的
分析下是怎么組織提示詞和關聯多輪對話的
def setup_seed(seed):random.seed(seed)np.random.seed(seed)torch.manual_seed(seed)torch.cuda.manual_seed(seed)torch.cuda.manual_seed_all(seed)torch.backends.cudnn.deterministic = Truetorch.backends.cudnn.benchmark = Falsedef main():model, tokenizer = load_model_tokenizer(model_path)# 初始化消息列表if "messages" not in st.session_state:st.session_state.messages = []st.session_state.chat_messages = []# Use session state messagesmessages = st.session_state.messages# 在顯示歷史消息的循環中for i, message in enumerate(messages):if message["role"] == "assistant":with st.chat_message("assistant", avatar=image_url):st.markdown(process_assistant_content(message["content"]), unsafe_allow_html=True)if st.button("×", key=f"delete_{i}"):# 刪除當前消息及其之后的所有消息st.session_state.messages = st.session_state.messages[:i - 1]st.session_state.chat_messages = st.session_state.chat_messages[:i - 1]st.rerun()else:st.markdown(f'<div style="display: flex; justify-content: flex-end;"><div style="display: inline-block; margin: 10px 0; padding: 8px 12px 8px 12px; background-color: gray; border-radius: 10px; color:white; ">{message["content"]}</div></div>',unsafe_allow_html=True)# 處理新的輸入或重新生成prompt = st.chat_input(key="input", placeholder="給 MiniMind 發送消息")# 檢查是否需要重新生成if hasattr(st.session_state, 'regenerate') and st.session_state.regenerate:prompt = st.session_state.last_user_messageregenerate_index = st.session_state.regenerate_index # 獲取重新生成的位置# 清除所有重新生成相關的狀態delattr(st.session_state, 'regenerate')delattr(st.session_state, 'last_user_message')delattr(st.session_state, 'regenerate_index')if prompt:st.markdown(f'<div style="display: flex; justify-content: flex-end;"><div style="display: inline-block; margin: 10px 0; padding: 8px 12px 8px 12px; background-color: gray; border-radius: 10px; color:white; ">{prompt}</div></div>',unsafe_allow_html=True)messages.append({"role": "user", "content": prompt})st.session_state.chat_messages.append({"role": "user", "content": prompt})with st.chat_message("assistant", avatar=image_url):placeholder = st.empty()random_seed = random.randint(0, 2 ** 32 - 1)setup_seed(random_seed)st.session_state.chat_messages = system_prompt + st.session_state.chat_messages[-(st.session_state.history_chat_num + 1):]new_prompt = tokenizer.apply_chat_template(st.session_state.chat_messages,tokenize=False,add_generation_prompt=True)[-(st.session_state.max_new_tokens - 1):]x = torch.tensor(tokenizer(new_prompt)['input_ids'], device=device).unsqueeze(0)with torch.no_grad():res_y = model.generate(x, tokenizer.eos_token_id, max_new_tokens=st.session_state.max_new_tokens,temperature=st.session_state.temperature,top_p=st.session_state.top_p, stream=True)try:for y in res_y:answer = tokenizer.decode(y[0].tolist(), skip_special_tokens=True)if (answer and answer[-1] == '�') or not answer:continueplaceholder.markdown(process_assistant_content(answer), unsafe_allow_html=True)except StopIteration:print("No answer")assistant_answer = answer.replace(new_prompt, "")messages.append({"role": "assistant", "content": assistant_answer})st.session_state.chat_messages.append({"role": "assistant", "content": assistant_answer})with st.empty():if st.button("×", key=f"delete_{len(messages) - 1}"):st.session_state.messages = st.session_state.messages[:-2]st.session_state.chat_messages = st.session_state.chat_messages[:-2]st.rerun()if __name__ == "__main__":from transformers import AutoModelForCausalLM, AutoTokenizermain()基于 Streamlit 的交互式對話界面,使用 MiniMindLM 自回歸語言模型(通過 transformers.AutoModelForCausalLM 加載)進行多輪對話。
- 處理輸入:通過 st.chat_input 獲取用戶輸入,生成提示詞,調用模型生成回答,并更新會話狀態。
- 多輪對話:通過 st.session_state.chat_messages 維護對話歷史,關聯上下文。
提示詞組織方式
提示詞的構建主要發生在用戶輸入 prompt 后,通過以下步驟生成并傳遞給模型:
(1) 會話狀態管理
- st.session_state.messages:
- 存儲所有對話消息,格式為 [{"role": "user/assistant", "content": "..."}, ...]。
- 用于渲染歷史消息和支持刪除功能。
- st.session_state.chat_messages:
- 與 messages 類似,但專門用于構建提示詞,可能包含系統提示(system_prompt)和裁剪后的歷史。
- 通過 -(st.session_state.history_chat_num + 1) 限制歷史長度。
(2)系統提示與歷史拼接
st.session_state.chat_messages = system_prompt + st.session_state.chat_messages[ -(st.session_state.history_chat_num + 1):]
- 系統提示(system_prompt):
- 未在代碼中顯式定義,假設是一個預定義的列表(如 [{"role": "system", "content": "You are a helpful assistant."}])。
- 作為對話的初始上下文,定義模型行為。
- 歷史裁剪:
- history_chat_num 控制保留的歷史對話輪數(未定義,假設為一個整數,如 5)。
- -(history_chat_num + 1) 從 chat_messages 末尾取最近的若干輪對話,加上當前輸入。
- 例如,若 history_chat_num=2,則保留最近 2 輪對話 + 當前輸入。
(3)?提示詞模板化
new_prompt = tokenizer.apply_chat_template(st.session_state.chat_messages,tokenize=False,add_generation_prompt=True
)[-(st.session_state.max_new_tokens - 1):]-
- 假設模板為簡單拼接(如 <|system|>... <|user|>... <|assistant|>),最終生成類似:
<|system|>You are a helpful assistant.<|user|>Hello!<|assistant|>Hi there!<|user|>What's the weather? - 長度截斷:
- -(max_new_tokens - 1) 限制提示詞長度,確保加上生成 token 后不超過 max_new_tokens。
- 若歷史過長,只保留末尾部分,防止溢出。
多輪對話關聯機制
多輪對話的上下文通過以下方式關聯和維護:
(1) 會話狀態的持久化
- Streamlit 的 st.session_state 是一個持久化的狀態存儲,跨頁面刷新保留數據。
- messages 和 chat_messages 在會話開始時初始化,并在每次用戶輸入或模型回復后更新。
- 示例:
- 用戶輸入 "Hello" → messages.append({"role": "user", "content": "Hello"})。
- 模型回復 "Hi there!" → messages.append({"role": "assistant", "content": "Hi there!"})。
(2) 歷史消息的動態管理
- 顯示歷史:
- 循環遍歷 messages,根據 role 渲染用戶或助手消息。
- 支持刪除:點擊 "×" 按鈕,截斷 messages 和 chat_messages 到指定位置。
- 重新生成支持:
- 若 st.session_state.regenerate=True,從 last_user_message 重新生成回答,并清除相關狀態。
(3) 上下文傳遞
- chat_messages 將系統提示和最近歷史拼接,確保模型接收到完整的上下文。
- 示例:
- 系統提示:[{"role": "system", "content": "You are a helpful assistant"}]
- 第1輪:用戶 "Hello" → 助手 "Hi there!"
- 第2輪:用戶 "What's next?" →
- chat_messages = [{"role": "system", ...}, {"role": "user", "Hello"}, {"role": "assistant", "Hi there!"}, {"role": "user", "What's next?"}]
- 模板化后:You are a helpful assistant. <|user|>Hello<|assistant|>Hi there!<|user|>What's next?
webui測試結果
測試下?Top-P 和?Temperature, 效果比較明顯?Temperature 越大模型的發散思考能力越高,給出的回答更有創造性,也伴隨著模型幻覺問題





)

:目標檢測與 YOLOv12 實戰)












