? ? ?想獲取更多高質量的Java技術文章?歡迎訪問Java技術小館官網,持續更新優質內容,助力技術成長
Java技術小館官網![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring
ES的文檔更新機制
? ?在現代應用中,數據的動態性越來越強,我們不僅需要快速地索引和查詢數據,還需要能夠有效地更新這些數據。ES作為一個強大的分布式搜索引擎,其文檔更新機制設計得相當巧妙,以確保數據的一致性與可用性。

在ES中,文檔并不是一成不變的,它們可以隨著業務需求的變化而不斷更新。這一過程并非簡單地替換舊數據,而是涉及到版本控制和沖突管理等復雜的機制。在并發環境下,多個請求同時更新同一文檔時,如何確保數據的完整性和一致性,成為我們需要解決的重要問題。
文檔更新機制
Elasticsearch(ES)的文檔更新機制是其核心功能之一,設計旨在提供高效、可靠的文檔修改能力。在ES中,每個文檔都由一個唯一的ID標識,并存儲在指定的索引中。文檔更新的過程并非直接修改原有文檔,而是采用了一種寫時復制的策略,確保數據的一致性和高效性。
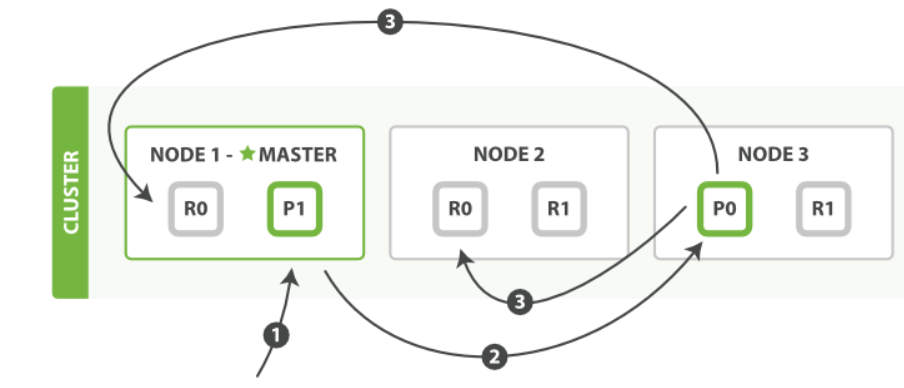
1. 更新操作的基本流程
當一個文檔需要更新時,ES首先會生成該文檔的最新版本。更新的過程包括以下幾個步驟:
- 獲取當前版本:在更新之前,系統會讀取當前文檔的狀態和版本號。
- 創建新文檔:根據提供的更新信息,創建一個新的文檔版本。此時,舊版本文檔仍然保持不變。
- 標記舊文檔為刪除:在創建新版本后,舊文檔被標記為刪除,但物理上并不會立即從磁盤中移除。這樣可以確保在高并發情況下,其他讀取操作仍可訪問到最新的有效數據。
- 提交更新:新文檔被持久化到索引中,并更新文檔的版本號。
2. 版本控制
ES使用版本控制來處理并發更新。當多個客戶端嘗試同時更新同一文檔時,ES會利用文檔的版本號來判斷更新的合法性:
- 樂觀鎖:在更新請求中,客戶端需要提供當前文檔的版本號。ES會比較這個版本號與存儲中的版本號,確保更新的文檔是基于最新的狀態進行的。如果版本號不匹配,說明該文檔已被其他請求更新,此時更新將失敗,客戶端需要重新獲取文檔并再次嘗試更新。
3. 并發沖突處理
在高并發場景下,如何處理文檔更新沖突是設計中的一個重要考慮。ES提供了以下幾種策略:
- 重試機制:當更新操作失敗時,客戶端可以捕獲到版本沖突異常,并根據應用邏輯選擇重試更新。
- 合理設計應用邏輯:在設計數據更新流程時,可以通過合并變更或批量處理來減少并發沖突的發生幾率。
4. 性能考慮
文檔更新機制需要平衡性能與一致性。雖然使用寫時復制提高了數據安全性,但在更新頻繁的場景下,可能導致較高的存儲開銷。因此,適當的索引設計、合理的更新策略及對版本管理的優化是提高系統性能的關鍵。
更新操作的類型
在Elasticsearch中,文檔更新操作主要有幾種不同的類型,每種類型適用于特定的使用場景和需求。理解這些更新操作的類型,有助于更有效地管理和優化數據處理過程。
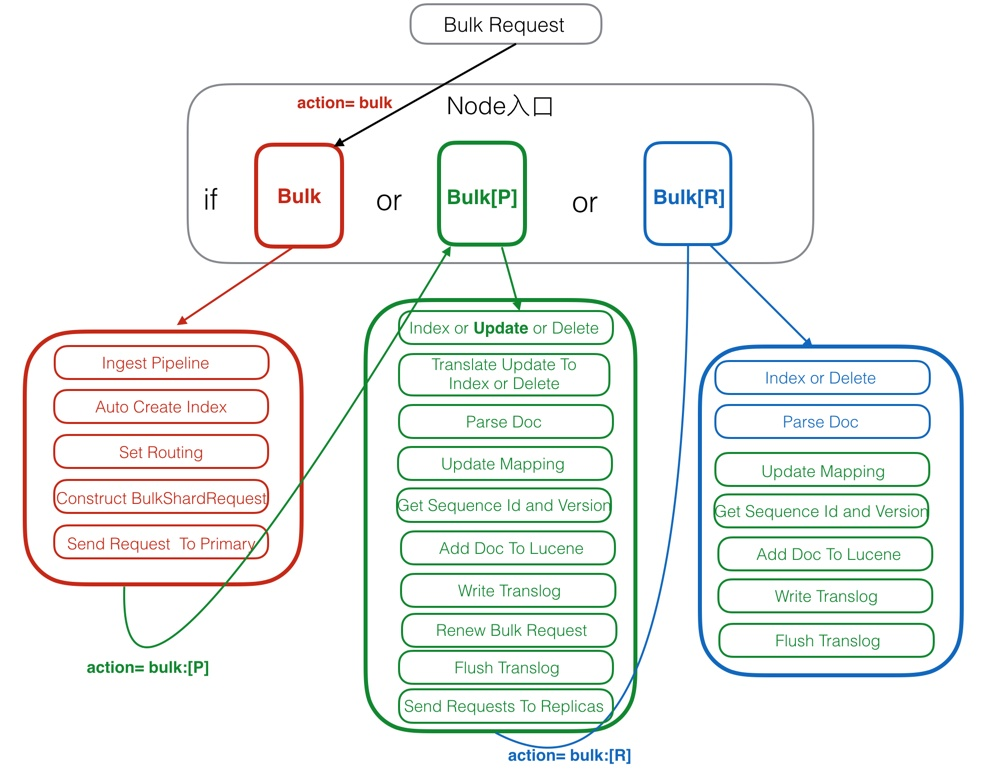
1. 全量更新(Full Update)
全量更新是指對一個文檔進行完全替換。更新請求包含整個文檔的內容,ES會將現有文檔替換為新的版本。這種方式適用于當文檔內容發生較大變化時,且更新的數據量相對較小。
- 優點:操作簡單,易于理解,適合一次性修改大部分字段。
- 缺點:如果文檔較大或更新頻繁,可能會造成較高的存儲開銷。
2. 部分更新(Partial Update)
部分更新允許用戶僅更新文檔中的某些字段,而不必提供整個文檔。這通過使用update API實現,用戶只需指定需要更改的字段及其新值。
- 優點:節省帶寬和存儲空間,特別適用于大文檔中的小改動。性能相對較高,因為只涉及必要的字段。
- 缺點:可能導致更新過程中數據的不一致,特別是在多次快速更新的情況下。
3. 腳本更新(Scripted Update)
腳本更新允許用戶通過自定義腳本對文檔進行動態修改。用戶可以編寫腳本來執行復雜的更新邏輯,例如根據當前值計算新值。
- 優點:提供靈活性,可以實現復雜的業務邏輯,適合動態變化的場景。
- 缺點:性能開銷可能較大,尤其是在高并發情況下,復雜的腳本可能會影響更新速度。
4. 批量更新(Bulk Update)
批量更新允許一次性對多個文檔進行更新,適合在處理大量數據時使用。通過bulk API,可以將多個更新操作打包為一個請求,顯著提高效率。
- 優點:減少網絡延遲,降低請求數量,提升處理速度。
- 缺點:需要合理設計批量大小,以避免超出系統的處理能力。
5. 條件更新(Conditional Update)
條件更新通過版本控制實現,只在滿足特定條件時才執行更新操作。例如,可以在更新請求中包含一個版本號,確保文檔在更新時沒有被其他請求修改。
- 優點:增加數據一致性,確保更新操作的原子性。
- 缺點:可能導致重試邏輯的復雜性,特別是在高并發場景中。
更新過程詳細步驟
在Elasticsearch中,文檔的更新過程是一個復雜而高效的操作,涉及多個步驟和機制。以下是文檔更新的詳細步驟,以及每一步所涉及的關鍵概念。
1. 接收更新請求
當應用程序發起文檔更新請求時,它會通過REST API向Elasticsearch發送HTTP請求。更新請求通常包含要更新的文檔ID、要更新的字段及其新值,以及更新類型(全量或部分更新)。
2. 請求解析
Elasticsearch接收到請求后,會解析請求內容,提取出目標索引、文檔ID、要更新的字段及值等信息。此時,系統會檢查請求的有效性,包括目標索引是否存在,文檔ID是否有效等。
3. 文檔查找
Elasticsearch使用分片機制來快速定位存儲文檔的分片。系統會根據文檔ID計算出對應的分片,并在該分片中查找目標文檔。如果文檔存在,系統將繼續處理;如果不存在,處理結果可能是創建新文檔(在使用全量更新時)。
4. 獲取文檔的當前版本
在更新過程中,Elasticsearch會讀取文檔的當前版本號,這是實現樂觀鎖的關鍵。版本號用于判斷在更新過程中文檔是否被其他請求修改,以防止數據不一致。
5. 文檔更新
根據更新類型的不同,Elasticsearch會執行以下操作:
- 全量更新:用新的文檔替換舊的文檔。系統會刪除舊文檔并創建新文檔,新的版本號會加1。
- 部分更新:系統只更新指定的字段。此時,Elasticsearch會讀取當前文檔的內容,并將需要更新的字段值替換為新的值,保留其他字段不變。
- 腳本更新:如果更新請求中包含腳本,系統會在執行更新之前運行該腳本。腳本可以訪問當前文檔的所有字段并根據業務邏輯計算新值。
6. 版本檢查
在更新過程中,Elasticsearch會檢查當前文檔的版本號是否與請求中的版本號一致。這是實現樂觀鎖的一部分。若版本不一致,更新請求將被拒絕,返回沖突錯誤。用戶可以根據需要選擇重試或處理沖突。
7. 寫入操作
一旦文檔成功更新,Elasticsearch會將更新操作寫入內存中的緩沖區(translog)。此時,更新操作仍然是暫時的,只有在數據持久化后才會成為永久性更改。
8. 刷新與持久化
- 刷新:Elasticsearch會在后臺定期刷新緩沖區,將內存中的數據寫入磁盤索引。此時,更新的數據才會對搜索可見。用戶也可以手動觸發刷新,但這會影響性能。
- 持久化:數據在刷新后會持久化到磁盤,確保在節點重啟或故障時數據不會丟失。
9. 更新的確認
更新操作完成后,Elasticsearch會向客戶端發送確認響應,指示更新是否成功。如果更新過程中發生任何錯誤或沖突,系統會返回相應的錯誤信息。
并發更新處理
在Elasticsearch中,處理并發更新是確保數據一致性和系統穩定性的關鍵。由于Elasticsearch是一個分布式系統,多個客戶端可能同時嘗試更新同一文檔。為此,Elasticsearch采用了樂觀鎖機制和版本控制來有效管理并發更新。
1. 樂觀鎖機制
Elasticsearch使用樂觀鎖來處理并發更新。這種機制允許多個更新請求并行處理,但在實際更新時會檢查文檔的版本號,從而防止數據沖突。
- 版本號:每個文檔都有一個版本號,代表該文檔的當前狀態。當文檔被更新時,版本號會自增。更新請求中可以包含一個期望的版本號,用于檢查當前文檔的版本是否與期望一致。
2. 更新請求
當多個客戶端同時發送更新請求時,Elasticsearch會為每個請求執行以下操作:
- 版本檢查:在處理更新請求時,系統會讀取目標文檔的當前版本號,并與請求中的版本號進行比較。
-
- 一致:如果版本一致,系統會繼續執行更新操作。
- 不一致:如果版本不一致,Elasticsearch會返回沖突錯誤(通常是HTTP 409)。這意味著在更新請求發出后,目標文檔已被其他請求修改。
3. 沖突處理策略
在處理版本沖突時,Elasticsearch提供了幾種處理策略:
- 重試機制:客戶端可以選擇重試更新請求。在重試時,客戶端通常會重新獲取最新的文檔版本,以確保更新是基于最新狀態的。
- 放棄更新:客戶端也可以選擇在發生版本沖突時放棄更新。這樣可以避免不必要的重試開銷,尤其是在高并發環境中。
- 合并更新:某些應用場景可能需要合并多個更新。客戶端可以先讀取當前文檔的最新狀態,然后計算出合并后的新值,再進行更新。這種方法需要客戶端處理邏輯復雜性。
4. 腳本更新與沖突
使用腳本更新時,Elasticsearch會在執行腳本之前進行版本檢查。這種情況下,腳本的執行可能會涉及到復雜的邏輯,因此要確保腳本能處理并發沖突。
- 原子性:腳本執行是在單個操作中完成的,確保在版本檢查通過后,文檔的狀態不會在腳本執行過程中被其他更新所影響。
5. 事務性更新
Elasticsearch本身不支持嚴格的事務性,但通過版本控制,開發者可以在應用層實現事務性邏輯。例如,可以通過事務管理工具來協調多個更新操作,確保在發生沖突時能夠回滾到安全狀態。
6. 監控與調優
在高并發環境下,監控Elasticsearch的性能和版本沖突率非常重要。開發者可以通過監控工具觀察沖突數量、重試次數等指標,及時調整更新策略和系統配置。
- 參數調整:根據監控結果,可以調整Elasticsearch的索引設置(如刷新頻率、分片數)和客戶端的重試策略,以優化并發更新性能。
更新性能優化
在Elasticsearch中,更新性能優化是確保系統高效響應和減少資源消耗的關鍵。由于Elasticsearch的設計理念是針對搜索和分析優化,更新操作相對較為復雜,尤其是在高并發場景下。
1. 批量更新操作
- 使用Bulk API:Elasticsearch支持批量操作,可以通過Bulk API一次性提交多個更新請求。這樣可以減少網絡往返次數,降低請求開銷,提高整體更新性能。
- 合理設置批量大小:在進行批量更新時,合理選擇每個批次的大小非常重要。過大的批量可能導致內存壓力,而過小的批量則無法充分利用網絡帶寬。一般來說,建議每批次處理數十到幾百條記錄。
2. 版本控制優化
- 減少版本沖突:在高并發環境中,頻繁的版本沖突會導致性能下降。通過合理設計應用邏輯,例如減少對同一文檔的競爭更新,或在應用層實現合并邏輯,可以有效降低沖突發生率。
- 使用樂觀并發控制:在進行更新時,盡量使用樂觀鎖而不是悲觀鎖,降低因鎖競爭引起的性能瓶頸。
3. 索引設計
- 使用合適的分片和副本設置:合理設置索引的分片數量和副本,可以提升寫入性能。分片過多會增加管理開銷,而分片過少則可能造成單個分片的寫入瓶頸。
- 避免頻繁的映射變化:每次對索引映射的修改都會引發重建過程,影響性能。提前設計好文檔結構和映射,減少后續的變更。
4. 刷新與合并策略
- 調整刷新間隔:Elasticsearch默認每秒會刷新一次索引,這會導致頻繁的寫入操作。如果對實時性要求不高,可以通過調整
refresh_interval參數來減少刷新頻率,從而提高寫入性能。 - 控制合并策略:定期合并段會提高查詢性能,但在高頻更新時會影響寫入性能。可以根據業務需求,調整合并策略和合并的觸發條件。
5. 使用腳本更新
- 減少數據傳輸:通過腳本直接在Elasticsearch中進行更新,可以減少從客戶端傳輸數據的需求,從而提高更新速度。腳本允許在Elasticsearch服務器端執行邏輯,直接更新文檔內容。
- 確保腳本性能:編寫高效的腳本邏輯,避免不必要的復雜計算和資源消耗,以保證腳本執行時的性能。
6. 資源監控與調整
- 監控性能指標:使用Elasticsearch提供的監控工具,實時觀察更新操作的性能,特別是請求延遲、沖突率和資源使用情況。
- 集群規模與資源分配:根據監控結果,適時擴展集群規模,增加節點或調整內存、CPU等資源分配,確保集群能夠承受高負載的更新請求。
7. 合理的應用設計
- 設計合理的更新邏輯:避免不必要的更新操作,例如在數據未變動時不進行更新。可以在應用層進行緩存或數據比較,以降低更新頻率。
- 使用事件驅動架構:通過消息隊列等機制,將更新請求異步處理,減少對主流程的阻塞,提高系統響應能力。
更新對索引和查詢的影響
在Elasticsearch中,文檔更新不僅影響索引的性能,還會對查詢性能產生深遠的影響。這是由于Elasticsearch的底層設計及其在處理更新時的機制。
1. 索引的影響
- 更新操作的復雜性:Elasticsearch采用的是一種基于Lucene的倒排索引結構。當文檔被更新時,實際上并不是在原位置直接修改數據,而是創建一個新的文檔版本,并將其插入到索引中。這一過程包括刪除舊文檔的引用并添加新文檔的引用,這會引起一定的索引開銷。
- 段合并:更新導致的文檔版本增加會產生更多的段。Elasticsearch會定期合并這些段,以優化存儲和查詢性能。然而,在合并的過程中,更新操作會導致CPU和I/O的負載增加,影響系統的整體性能。頻繁的更新操作可能使得合并過程更加復雜,從而增加延遲。
- 內存和存儲消耗:每次更新都會消耗額外的內存和存儲空間,因為更新會暫時保留舊版本,直到合并完成。這可能導致內存壓力增大,尤其是在高更新頻率的場景中,增加了系統的內存使用。
2. 查詢的影響
- 查詢延遲:在高并發更新的情況下,查詢延遲可能會增加。尤其是當系統正在進行大量更新操作時,查詢可能會遇到更多的延遲,因為數據可能在多次更新中處于不一致狀態。此時,系統需要更多的資源來處理并發的讀寫請求。
- 數據一致性:在更新過程中,用戶在查詢時可能會看到過時的數據,尤其是在使用實時搜索的場景下。Elasticsearch的默認刷新間隔為1秒,這意味著更新后的數據可能在此時間段內不可見,導致短暫的數據不一致問題。
- 影響查詢結果:當某個文檔被更新后,如果查詢的條件與更新前的數據相關,可能會導致查詢結果的顯著變化。尤其是在使用聚合查詢時,頻繁的更新可能導致聚合結果的不穩定,從而影響數據分析的準確性。
3. 性能調優
- 調整刷新策略:通過調整
refresh_interval參數,可以減少索引的刷新頻率,從而提高寫入性能。在對實時性要求不高的情況下,適當延長刷新時間可以減少查詢的延遲。 - 使用版本控制:樂觀鎖和版本控制機制可以減少并發更新帶來的沖突,從而降低對查詢性能的影響。
- 監控與分析:實時監控查詢性能和更新操作的指標,及時調整系統資源和配置,以確保查詢和索引性能的平衡。
想獲取更多高質量的Java技術文章?歡迎訪問Java技術小館官網,持續更新優質內容,助力技術成長
Java技術小館官網![]() https://www.yuque.com/jtostring
https://www.yuque.com/jtostring

:慢查詢定位及索引、B樹相關知識詳解)
)
)



)







)



