😀 第1題
下列敘述中錯誤的是
A. 向量是線性結構
B. 非空線性結構中只有一個結點沒有前件
C. 非空線性結構中只有一個結點沒有后件
D. 只有一個根結點和一個葉子結點的結構必定是線性結構
概念澄清
首先,我們需要明確幾個關鍵概念:
-
線性結構:線性結構是指數據元素之間存在一對一的線性關系。常見的線性結構包括線性表(如數組、鏈表)、棧、隊列等。線性結構的特點是:
-
存在唯一的一個“第一個”元素(無前驅,即沒有前件)。
-
存在唯一的一個“最后一個”元素(無后繼,即沒有后件)。
-
除第一個和最后一個元素外,其他元素都有唯一的前驅和后繼。
-
-
向量:在計算機科學中,向量通常指的是動態數組(如C++中的
std::vector)。它是一種線性結構,因為元素是按順序存儲的,每個元素(除了第一個和最后一個)都有明確的前驅和后繼。 -
根結點和葉子結點:
-
根結點:在樹形結構中,根結點是沒有父結點的結點;在線性結構中,可以理解為第一個結點。
-
葉子結點:在樹形結構中,葉子結點是沒有子結點的結點;在線性結構中,可以理解為最后一個結點。
-
逐項分析
選項A:向量是線性結構
-
向量(動態數組)的元素是連續存儲的,具有明確的順序,每個元素(除了首尾)都有唯一的前驅和后繼。
-
因此,向量確實是線性結構。
-
結論:A是正確的。
選項B:非空線性結構中只有一個結點沒有前件
-
非空線性結構中,第一個結點(頭結點)是沒有前件的。
-
其他所有結點都有且只有一個前件。
-
因此,確實只有一個結點沒有前件。
-
結論:B是正確的。
選項C:非空線性結構中只有一個結點沒有后件
-
非空線性結構中,最后一個結點(尾結點)是沒有后件的。
-
其他所有結點都有且只有一個后件。
-
因此,確實只有一個結點沒有后件。
-
結論:C是正確的。
選項D:只有一個根結點和一個葉子結點的結構必定是線性結構
-
我們需要判斷“只有一個根結點和一個葉子結點的結構”是否一定是線性結構。
-
在線性結構中,確實只有一個根結點(無前件)和一個葉子結點(無后件)。
-
但是,反過來是否成立?即“只有一個根結點和一個葉子結點的結構”是否只能是線性結構?
-
考慮樹形結構:在一般的樹中,根結點是唯一的(無父結點),葉子結點可以有多個(無子結點)。但如果限制只有一個葉子結點,那么這樣的樹是什么樣子?
-
如果樹只有一個根結點和一個葉子結點,那么這兩個結點之間只能有一條路徑連接,即線性連接。任何分支都會導致多個葉子結點。
-
因此,這種結構實際上就是線性結構。
-
-
但是,如果考慮更一般的圖結構:
-
例如,一個環(所有結點形成一個環):沒有明確的根結點和葉子結點。
-
或者,一個根結點指向一個葉子結點,同時葉子結點又指向根結點:這樣有兩個結點,一個根一個葉子,但這是一個循環結構,不是線性結構。
-
因此,如果允許循環或更復雜的圖結構,“只有一個根結點和一個葉子結點”的結構不一定是線性的。
-
-
-
題目中“結構”是否限定為樹或線性結構?如果嚴格限定為樹或線性結構,D可能是正確的;但更一般地,可能是錯誤的。
-
通常在數據結構中,“結構”可以指更一般的圖結構,因此D的表述過于絕對。
-
結論:D是錯誤的。
驗證D的反例
為了驗證D的錯誤,可以構造一個反例:
-
考慮一個有向圖:
-
兩個結點:A(根結點,無前驅)和 B(葉子結點,無后繼)。
-
邊:A → B,同時 B → A。
-
這樣,A是唯一的根結點(無前驅),B是唯一的葉子結點(無后繼)。
-
但這個結構不是線性的,因為存在環(A→B→A)。
-
因此,“只有一個根結點和一個葉子結點的結構”不一定是線性結構。
其他選項的再確認
為了確保其他選項的正確性:
-
A:向量是線性結構 —— 正確。
-
B:非空線性結構只有一個無前件的結點 —— 正確(頭結點)。
-
C:非空線性結構只有一個無后件的結點 —— 正確(尾結點)。
-
D:反例存在,不正確。
可能的疑問
有人可能會認為D是正確的,因為:
-
如果限制為“樹”結構,那么只有一個根和一個葉子的樹確實是線性的。
-
但題目沒有明確限制為樹結構,“結構”可以更廣泛地包括圖結構。
-
因此,D的表述“必定是線性結構”過于絕對。
結論
經過以上分析,敘述D是錯誤的。
最終答案
D. 只有一個根結點和一個葉子結點的結構必定是線性結構?是錯誤的。
😀 第2題
在希爾排序法中,每經過一次數據交換后
A. 能消除多個逆序
B. 只能消除一個逆序
C. 不會產生新的逆序
D. 消除的逆序個數一定比新產生的逆序個數多
希爾排序的基本概念
希爾排序(Shell Sort)是插入排序的一種改進版本,也稱為縮小增量排序。其核心思想是:
-
將原始數組分成若干子序列,子序列的元素是通過**間隔(增量)**選取的。
-
例如,初始增量可以是?
n/2,之后逐步減半(n/4,?n/8, ..., 1)。
-
-
對每個子序列進行插入排序。
-
隨著增量的逐步減小,子序列越來越長,最終增量為1時,整個數組作為一個子序列進行插入排序。
希爾排序的特點是:
-
通過較大的增量,可以快速將元素移動到較遠的位置,從而減少后續小增量排序的工作量。
-
每次交換可能同時影響多個逆序對。
關鍵點:逆序(Inversion)
逆序是指數組中前面的元素大于后面的元素,即如果?i < j?且?A[i] > A[j],則?(A[i], A[j])?是一個逆序。
-
插入排序每次只能消除一個逆序(交換相鄰元素)。
-
希爾排序由于可以跨越多個位置交換,因此一次交換可能消除多個逆序。
逐項分析
選項A:能消除多個逆序
-
希爾排序的交換是跨越多個位置的(由增量決定)。
-
例如:
-
數組?
[9, 8, 7, 6, 5, 4, 3, 2, 1],初始增量為4:-
子序列:
[9,5,1]、[8,4]、[7,3]、[6,2]。 -
對?
[9,5,1]?排序:交換?9?和?5,再交換?9?和?1。-
交換?
9?和?5:消除了?(9,5)、(9,1)?等多個逆序。
-
-
-
-
因此,希爾排序的一次交換可以消除多個逆序。
-
結論:A是正確的。
選項B:只能消除一個逆序
-
這是插入排序的特點(每次只能消除一個相鄰逆序)。
-
希爾排序的交換是跨增量的,可以消除多個逆序。
-
結論:B是錯誤的。
選項C:不會產生新的逆序
-
希爾排序的交換可能會引入新的逆序。
-
例如:
-
子序列?
[5, 9, 1](增量跳躍):-
交換?
5?和?1:原逆序?(5,1)?消除,但可能在其他子序列中引入新逆序。
-
-
-
-
因此,可能產生新的逆序。
-
結論:C是錯誤的。
選項D:消除的逆序個數一定比新產生的逆序個數多
-
希爾排序的總體趨勢是減少逆序,但不一定每次交換都滿足“消除的逆序比新增的多”。
-
例如:
-
子序列?
[6, 2, 7]:-
交換?
6?和?2:消除?(6,2),但可能在其他子序列中新增逆序。 -
無法保證每次交換都“凈減少”逆序。
-
-
-
-
結論:D是錯誤的。
反例驗證
以數組?[4, 6, 2, 5, 1]?為例,增量為2:
-
子序列:
[4, 2, 1]?和?[6, 5]。-
對?
[4, 2, 1]:-
交換?
4?和?2:消除?(4,2)?和?(4,1)(多個逆序),新增無。 -
交換?
2?和?1:消除?(2,1),新增無。
-
-
對?
[6, 5]:-
交換?
6?和?5:消除?(6,5),新增無。
-
-
-
此例中:
-
A:正確(如?
4?和?2?交換消除多個逆序)。 -
B:錯誤(不止一個)。
-
C:錯誤(此例未新增,但其他情況可能新增)。
-
D:錯誤(無法保證“一定”更多)。
-
排除法
-
A正確,B、C、D均不完全成立。
-
但題目問“錯誤的是”,因此選擇錯誤的敘述。
可能的誤區
有人可能認為:
-
希爾排序的交換和插入排序類似(每次消除一個逆序),從而誤選B。
-
但實際上,希爾排序的跨增量交換可以消除多個逆序。
結論
最明顯錯誤的是?B(“只能消除一個逆序”),因為希爾排序可以消除多個逆序。
最終答案
B. 只能消除一個逆序?是錯誤的。
😀 第3題
設二叉樹的后序序列與中序序列均為ABCDEFGH,則該二叉樹的前序序列為
A. HGFEDCBA
B. ABCDEFGH
C. ABCDHGFE
D. DCBAHGFE
基本概念
在解決這個問題之前,我們需要明確幾個關鍵概念:
-
前序遍歷(Pre-order):根 → 左子樹 → 右子樹
-
中序遍歷(In-order):左子樹 → 根 → 右子樹
-
后序遍歷(Post-order):左子樹 → 右子樹 → 根
題目分析
題目給出的后序序列和中序序列均為?ABCDEFGH。我們需要根據這兩個序列重建二叉樹,然后求出其前序序列。
第一步:觀察后序序列和中序序列
-
后序序列的最后一個元素是根節點。因此:
-
后序序列?
ABCDEFGH?→ 根節點是?H。
-
-
中序序列中,根節點?
H?將序列分為左子樹和右子樹:-
中序序列?
ABCDEFGH?→?H?是最后一個元素,因此:-
左子樹:
ABCDEFG -
右子樹:空(因為?
H?后面沒有其他元素)
-
-
第二步:遞歸構建左子樹
現在我們需要構建左子樹?ABCDEFG:
-
左子樹的后序序列:從后序序列?
ABCDEFGH?中去除?H,得到?ABCDEFG(左子樹的后序序列)。 -
左子樹的中序序列:
ABCDEFG。
重復上述步驟:
-
左子樹的后序序列?
ABCDEFG?→ 根節點是?G。 -
中序序列?
ABCDEFG?→?G?是最后一個元素:-
左子樹的左子樹:
ABCDEF -
左子樹的右子樹:空
-
繼續遞歸:
-
左子樹的左子樹?
ABCDEF:-
后序序列?
ABCDEF?→ 根節點是?F。 -
中序序列?
ABCDEF?→?F?是最后一個元素:-
左子樹的左子樹的左子樹:
ABCDE -
左子樹的左子樹的右子樹:空
-
-
繼續:
-
左子樹的左子樹的左子樹?
ABCDE:-
后序序列?
ABCDE?→ 根節點是?E。 -
中序序列?
ABCDE?→?E?是最后一個元素:-
左子樹的左子樹的左子樹的左子樹:
ABCD -
左子樹的左子樹的左子樹的右子樹:空
-
-
繼續:
-
左子樹的左子樹的左子樹的左子樹?
ABCD:-
后序序列?
ABCD?→ 根節點是?D。 -
中序序列?
ABCD?→?D?是最后一個元素:-
左子樹的左子樹的左子樹的左子樹的左子樹:
ABC -
左子樹的左子樹的左子樹的左子樹的右子樹:空
-
-
繼續:
-
左子樹的左子樹的左子樹的左子樹的左子樹?
ABC:-
后序序列?
ABC?→ 根節點是?C。 -
中序序列?
ABC?→?C?是最后一個元素:-
左子樹的左子樹的左子樹的左子樹的左子樹的左子樹:
AB -
左子樹的左子樹的左子樹的左子樹的左子樹的右子樹:空
-
-
繼續:
-
左子樹的左子樹的左子樹的左子樹的左子樹的左子樹?
AB:-
后序序列?
AB?→ 根節點是?B。 -
中序序列?
AB?→?B?是最后一個元素:-
左子樹的左子樹的左子樹的左子樹的左子樹的左子樹的左子樹:
A -
左子樹的左子樹的左子樹的左子樹的左子樹的左子樹的右子樹:空
-
-
最后:
-
A?是葉子節點。
第三步:構建二叉樹
通過以上遞歸過程,我們可以構建出二叉樹的結構:
-
根節點:
H-
左子樹:
G-
左子樹:
F-
左子樹:
E-
左子樹:
D-
左子樹:
C-
左子樹:
B-
左子樹:
A -
右子樹:空
-
-
右子樹:空
-
-
右子樹:空
-
-
右子樹:空
-
-
右子樹:空
-
-
右子樹:空
-
-
右子樹:空
-
用圖形表示:

這是一棵極度左傾的二叉樹,每個節點只有左子樹,沒有右子樹。
第四步:驗證后序和中序序列
為了驗證我們的構建是否正確,我們可以檢查后序和中序序列:
-
后序遍歷:
-
遍歷順序:左 → 右 → 根
-
從最左下的?
A?開始,依次向上:-
A?→?B?→?C?→?D?→?E?→?F?→?G?→?H
-
-
結果為?
ABCDEFGH,與題目一致。
-
-
中序遍歷:
-
遍歷順序:左 → 根 → 右
-
從最左下的?
A?開始,依次向上:-
A?→?B?→?C?→?D?→?E?→?F?→?G?→?H
-
-
結果為?
ABCDEFGH,與題目一致。
-
第五步:求前序序列
前序遍歷的順序是:根 → 左 → 右。
對于我們構建的二叉樹:
-
從根?
H?開始:-
訪問?
H -
訪問?
H?的左子樹?G:-
訪問?
G -
訪問?
G?的左子樹?F:-
訪問?
F -
訪問?
F?的左子樹?E:-
訪問?
E -
訪問?
E?的左子樹?D:-
訪問?
D -
訪問?
D?的左子樹?C:-
訪問?
C -
訪問?
C?的左子樹?B:-
訪問?
B -
訪問?
B?的左子樹?A:-
訪問?
A
-
-
B?的右子樹為空
-
-
C?的右子樹為空
-
-
D?的右子樹為空
-
-
E?的右子樹為空
-
-
F?的右子樹為空
-
-
G?的右子樹為空
-
-
H?的右子樹為空
-
因此,前序序列為:H, G, F, E, D, C, B, A,即?HGFEDCBA。
選項匹配
-
A.?
HGFEDCBA?→ 正確 -
B.?
ABCDEFGH?→ 錯誤(這是中序或后序序列) -
C.?
ABCDHGFE?→ 錯誤 -
D.?
DCBAHGFE?→ 錯誤
驗證其他選項
為什么其他選項不正確?
-
B.?
ABCDEFGH:-
這是中序或后序序列,不是前序序列。
-
-
C.?
ABCDHGFE:-
前序序列應從根?
H?開始,而不是?A。
-
-
D.?
DCBAHGFE:-
前序序列應從根?
H?開始,且?DCBA?的順序不符合前序。
-
可能的誤區
-
混淆遍歷順序:
-
可能會誤認為后序和中序相同,前序也相同(選B),但實際上前序是根左右,需要從根開始。
-
-
忽略極度左傾的二叉樹:
-
可能會認為二叉樹有其他結構,但根據后序和中序的唯一性,只能構建出極度左傾的樹。
-
結論
通過逐步構建二叉樹并驗證遍歷序列,可以確定:
-
前序序列為?
HGFEDCBA。 -
因此,正確答案是 A。
最終答案
A. HGFEDCBA
😀 第4題
在黑盒測試方法中,設計測試用例的根據是
A. 數據結構
B. 程序調用規則
C. 模塊間的邏輯關系
D. 軟件要完成的功能
基本概念
首先,我們需要明確**黑盒測試(Black-box Testing)**的定義:
-
黑盒測試是一種軟件測試方法,它不關心程序的內部結構或實現細節,而是基于軟件的功能需求或規格說明來設計測試用例。
-
測試者將軟件視為一個“黑盒”,只關注輸入和輸出是否符合預期,而不關注內部是如何實現的。
黑盒測試的核心依據
黑盒測試的設計依據主要包括:
-
軟件的功能需求(Functional Requirements):
-
測試用例的設計是為了驗證軟件是否按照需求規格說明(SRS)正確地實現了功能。
-
例如:測試一個登錄功能時,輸入正確的用戶名和密碼是否能成功登錄。
-
-
輸入與輸出的關系:
-
根據輸入數據的不同組合,驗證輸出是否符合預期。
-
例如:邊界值分析、等價類劃分等黑盒測試技術。
-
-
用戶視角:
-
黑盒測試是從用戶的角度出發,驗證軟件是否滿足用戶需求。
-
黑盒測試不關注的方面
黑盒測試不關注以下內容:
-
內部代碼結構(如數據結構、算法)。
-
程序的具體實現(如函數調用規則、模塊間的邏輯關系)。
-
這些屬于**白盒測試(White-box Testing)**的范疇。
選項分析
選項A:數據結構
-
數據結構是程序的內部實現細節,屬于白盒測試的關注點。
-
黑盒測試不關心數據結構。
-
結論:A不是正確答案。
選項B:程序調用規則
-
程序調用規則(如函數調用順序、模塊間的調用關系)是代碼內部邏輯的一部分。
-
這是白盒測試(如路徑測試、控制流測試)的依據。
-
結論:B不是正確答案。
選項C:模塊間的邏輯關系
-
模塊間的邏輯關系(如接口調用、數據傳遞)是系統設計的一部分。
-
這屬于灰盒測試或白盒測試的范疇,黑盒測試不關心模塊間的具體交互。
-
結論:C不是正確答案。
選項D:軟件要完成的功能
-
黑盒測試的核心就是驗證軟件是否按照需求完成了預期的功能。
-
測試用例的設計直接基于功能需求(如需求文檔、用戶故事)。
-
結論:D是正確答案。
驗證其他測試方法
為了進一步確認,我們可以對比其他測試方法:
-
白盒測試:
-
依據:代碼結構、邏輯路徑、分支覆蓋等。
-
例如:選項A、B、C的內容。
-
-
灰盒測試:
-
介于黑盒和白盒之間,部分關注內部邏輯。
-
例如:接口測試、模塊間交互測試(選項C的部分內容)。
-
-
黑盒測試:
-
僅關注功能(選項D)。
-
實際例子
假設測試一個計算器軟件:
-
黑盒測試:
-
設計測試用例:輸入?
2 + 2,驗證輸出是否為?4。 -
不關心計算器內部是用什么數據結構或算法實現的。
-
-
白盒測試:
-
設計測試用例:檢查加法函數是否被正確調用,或是否覆蓋了所有分支。
-
需要了解代碼的內部邏輯。
-
排除法
-
A、B、C均與內部實現相關,屬于白盒或灰盒測試。
-
只有D是純粹的黑盒測試依據。
可能的誤區
有人可能會誤選:
-
C. 模塊間的邏輯關系:
-
可能會認為黑盒測試需要關注模塊間的接口,但實際上黑盒測試只關注整體功能,不關心模塊如何交互。
-
模塊間交互更多是集成測試或灰盒測試的內容。
-
-
B. 程序調用規則:
-
這是典型的白盒測試內容(如單元測試中 mock 函數調用)。
-
結論
黑盒測試的唯一正確依據是軟件要完成的功能。
最終答案
D. 軟件要完成的功能?是正確的。
😀 第5題
下列敘述中正確的是
A. 循環隊列是隊列的鏈式存儲結構
B. 能采用順序存儲的必定是線性結構
C. 所有的線性結構都可以采用順序存儲結構
D. 具有兩個以上指針的鏈表必定是非線性結構
基本概念
在解答這個問題之前,我們需要明確幾個關鍵概念:
-
線性結構:
-
數據元素之間存在一對一的線性關系。
-
常見的線性結構包括:線性表(數組、鏈表)、棧、隊列等。
-
-
非線性結構:
-
數據元素之間存在多對多的關系。
-
常見的非線性結構包括:樹、圖等。
-
-
順序存儲結構:
-
用一段連續的存儲單元依次存儲數據元素(如數組)。
-
特點:隨機訪問高效,插入/刪除可能需要移動大量元素。
-
-
鏈式存儲結構:
-
通過指針(或引用)將數據元素鏈接起來(如鏈表)。
-
特點:插入/刪除高效,但隨機訪問效率低。
-
-
循環隊列:
-
隊列的一種實現方式,通過數組(順序存儲)模擬環形結構。
-
目的是解決普通順序隊列的“假溢出”問題。
-
-
多指針鏈表:
-
鏈表中的結點包含多個指針(如雙向鏈表、樹、圖等)。
-
雙向鏈表仍然是線性結構;樹和圖是非線性結構。
-
逐項分析
選項A:循環隊列是隊列的鏈式存儲結構
-
循環隊列的實現:
-
循環隊列通常使用**順序存儲(數組)**實現,通過模運算模擬環形結構。
-
鏈式存儲的隊列是普通的鏈隊列(用鏈表實現),不是循環隊列。
-
-
結論:
-
循環隊列是順序存儲,不是鏈式存儲。
-
A是錯誤的。
-
選項B:能采用順序存儲的必定是線性結構
-
順序存儲的適用性:
-
順序存儲通常用于線性結構(如數組、順序棧、順序隊列)。
-
但某些非線性結構也可以采用順序存儲:
-
例如:完全二叉樹可以用數組存儲(堆的實現)。
-
圖的鄰接矩陣也是順序存儲。
-
-
-
反例:
-
完全二叉樹的順序存儲是非線性結構。
-
-
結論:
-
能采用順序存儲的不一定是線性結構。
-
B是錯誤的。
-
選項C:所有的線性結構都可以采用順序存儲結構
-
線性結構的存儲方式:
-
線性結構(如線性表、棧、隊列)既可以用順序存儲(數組),也可以用鏈式存儲(鏈表)。
-
順序存儲是線性結構的一種通用實現方式。
-
-
反例:
-
目前沒有線性結構不能采用順序存儲的例子。
-
-
結論:
-
所有線性結構都可以采用順序存儲。
-
C是正確的。
-
選項D:具有兩個以上指針的鏈表必定是非線性結構
-
多指針鏈表的例子:
-
雙向鏈表:每個結點有?
prior?和?next?兩個指針,但仍然是線性結構。 -
樹或圖:每個結點可能有多個指針(如二叉樹、鄰接表),是非線性結構。
-
-
關鍵點:
-
“兩個以上指針”是否一定非線性?
-
雙向鏈表有兩個指針,但仍是線性結構。
-
因此,“兩個以上指針”不一定是非線性結構。
-
-
-
結論:
-
具有兩個以上指針的鏈表不一定是非線性結構。
-
D是錯誤的。
-
驗證與總結
-
A:循環隊列是順序存儲,錯誤。
-
B:順序存儲可以用于非線性結構(如堆),錯誤。
-
C:線性結構都可以用順序存儲,正確。
-
D:雙向鏈表是多指針但線性,錯誤。
可能的誤區
-
循環隊列的實現:
-
容易誤認為循環隊列是鏈式存儲,但實際上它是順序存儲的優化。
-
-
順序存儲的適用范圍:
-
可能認為順序存儲只能用于線性結構,忽略了完全二叉樹、堆等非線性結構的順序存儲。
-
-
多指針鏈表的性質:
-
容易混淆雙向鏈表(線性)與樹/圖(非線性)。
-
結論
唯一正確的敘述是?C。
最終答案
C. 所有的線性結構都可以采用順序存儲結構?是正確的。
😀 第6題
對軟件系統總體結構圖,下面描述中錯誤的是
A. 深度等于控制的層數
B. 扇入是一個模塊直接調用的其他模塊數
C. 扇出是?個模塊直接調用的其他模塊數
D. V一定是結構圖中位于葉子結點的模塊
題目解析:
我們需要找出關于軟件系統總體結構圖描述中錯誤的選項。首先,明確幾個關鍵概念:
1.?軟件結構圖的基本概念
-
軟件結構圖(Structure Chart)是描述軟件系統模塊層次結構的圖形表示。
-
包含模塊、調用關系、數據傳遞、控制信息等。
-
常見術語:
-
深度:從頂層模塊到最底層模塊的層數。
-
寬度:同一層次上模塊的最大數量。
-
扇出(Fan-out):一個模塊直接調用的其他模塊數。
-
扇入(Fan-in):直接調用該模塊的其他模塊數。
-
葉子模塊:不調用其他模塊的底層模塊。
-
2.?逐項分析選項
選項A:深度等于控制的層數
-
深度確實是指從頂層模塊到最底層模塊的層數(即控制的層數)。
-
例如:頂層模塊 → 中間模塊 → 葉子模塊,深度為3。
-
結論:A的描述正確。
選項B:扇入是一個模塊直接調用的其他模塊數
-
扇入的定義是有多少個模塊直接調用當前模塊,而不是當前模塊調用其他模塊。
-
題目描述將“扇入”錯誤地等同于“扇出”。
-
結論:B的描述錯誤(這是扇出的定義)。
選項C:扇出是一個模塊直接調用的其他模塊數
-
扇出的正確定義是一個模塊直接調用的其他模塊數。
-
例如:模塊A調用模塊B和C,扇出為2。
-
結論:C的描述正確。
選項D:V一定是結構圖中位于葉子結點的模塊
-
葉子結點模塊是指不調用其他模塊的模塊(即扇出為0)。
-
通常用特定符號(如V)表示葉子模塊,但題目未明確說明符號規范。
-
如果題目中約定V表示葉子模塊,則D正確;否則無法直接判斷。
-
結合其他選項,B的錯誤更明顯,因此D可能是正確的。
3.?關鍵點總結
-
扇入和扇出的定義是核心考點:
-
扇入:被多少模塊調用。
-
扇出:調用多少模塊。
-
-
選項B混淆了扇入和扇出,是明顯錯誤。
4.?排除法驗證
-
A正確,B錯誤,C正確,D可能正確。
-
題目要求選擇錯誤描述,因此選B。
5.?可能的誤區
-
混淆扇入和扇出的定義。
-
忽略葉子模塊的符號約定(D選項的干擾)。
最終答案
B. 扇入是一個模塊直接調用的其他模塊數?是錯誤的。
😀 第7題
下面屬于系統軟件的是()
A. 瀏覽器
B. 數據庫管理系統
C. 人事管理系統
D. 天氣預報的app
題目解析:
我們需要從選項中識別出系統軟件。首先明確系統軟件的定義:
1.?系統軟件 vs. 應用軟件
-
系統軟件:
-
直接服務于計算機硬件和操作系統,提供基礎功能。
-
例如:操作系統(Windows、Linux)、數據庫管理系統(DBMS)、編譯器、驅動程序等。
-
特點:通用性強,與硬件或系統管理相關。
-
-
應用軟件:
-
面向用戶具體需求,完成特定任務。
-
例如:瀏覽器、辦公軟件、游戲、天氣預報App等。
-
特點:專用性強,依賴系統軟件運行。
-
2.?逐項分析選項
選項A:瀏覽器
-
瀏覽器(如Chrome、Firefox)是用戶訪問互聯網的工具,屬于應用軟件。
-
結論:不是系統軟件。
選項B:數據庫管理系統(DBMS)
-
DBMS(如MySQL、Oracle)負責數據的存儲、管理和檢索,是操作系統之上的基礎軟件。
-
它為其他軟件提供數據服務,屬于系統軟件。
-
結論:是系統軟件。
選項C:人事管理系統
-
人事管理系統是企業用于管理員工信息的專用軟件,屬于應用軟件。
-
結論:不是系統軟件。
選項D:天氣預報的App
-
天氣預報App是面向用戶提供天氣信息的工具,屬于應用軟件。
-
結論:不是系統軟件。
3.?關鍵區分點
-
系統軟件的核心特征是:
-
管理硬件或系統資源(如DBMS管理數據資源)。
-
為其他軟件提供支持(如編譯器、驅動程序)。
-
-
應用軟件直接面向用戶解決具體問題。
4.?排除法驗證
-
A、C、D均為應用軟件,只有B(DBMS)是系統軟件。
-
數據庫管理系統是典型的系統軟件,與操作系統、編譯器并列。
5.?常見誤區
-
誤將瀏覽器或工具類軟件(如殺毒軟件)當作系統軟件。
-
實際上,瀏覽器依賴操作系統和網絡協議,本身是應用軟件。
-
-
混淆DBMS與普通數據庫應用:
-
DBMS是系統軟件,而基于DBMS開發的“人事管理系統”是應用軟件。
-
最終答案
B. 數據庫管理系統?是系統軟件。
😀 第8題
能夠減少相同數據重復存儲的是
A. 數據庫
B. 字段
C. 文件
D. 記錄
題目解析:
我們需要從選項中找出能夠減少相同數據重復存儲的技術或結構。以下是逐步分析:
1.?問題核心:數據冗余的解決
-
數據冗余:相同數據在多個位置重復存儲,導致存儲浪費和一致性問題。
-
目標:通過某種技術或結構,避免重復存儲相同數據。
2.?逐項分析選項
選項A:數據庫
-
數據庫(Database)的核心功能之一是數據共享和集中管理。
-
通過規范化設計(如關系數據庫的范式理論),消除冗余數據。
-
例如:將重復數據提取為單獨的表,通過外鍵關聯。
-
-
結論:數據庫能有效減少數據冗余,是正確答案。
選項B:字段
-
**字段(Field)**是數據的最小單位(如“姓名”“年齡”),僅描述數據的屬性。
-
字段本身無法解決重復存儲問題,冗余可能存在于記錄或文件中。
-
結論:字段與減少冗余無關。
選項C:文件
-
**文件(File)**是數據的集合,但傳統文件系統缺乏數據關聯機制。
-
例如:多個文件可能獨立存儲相同數據(如員工信息重復出現在不同文件中)。
-
-
結論:文件系統通常無法減少冗余,甚至可能加劇冗余。
選項D:記錄
-
**記錄(Record)**是字段的集合(如一條員工信息),描述一個完整的數據實體。
-
記錄本身是數據存儲的單位,不解決跨記錄的冗余問題。
-
結論:記錄與減少冗余無關。
3.?關鍵對比:數據庫 vs. 文件
-
文件系統:
-
數據分散存儲,缺乏關聯性,容易重復。
-
例如:員工部門信息在多個文件中重復存儲。
-
-
數據庫系統:
-
通過表關聯和外鍵約束,確保數據唯一性。
-
例如:部門信息單獨存為一張表,員工表通過部門ID引用。
-
4.?排除法驗證
-
B、C、D均無法系統性解決冗余問題。
-
只有**A(數據庫)**通過規范化設計減少冗余。
5.?可能的誤區
-
誤認為“記錄”或“字段”能減少冗余:
-
它們只是數據單位,不提供邏輯關聯。
-
-
混淆“文件”與“數據庫”:
-
文件是物理存儲,數據庫是邏輯管理。
-
最終答案
A. 數據庫?能夠減少相同數據的重復存儲。
😀 第9題
定義學生選修課程的關系模式:SC(S#,Sn,C#,Cn,G)(其屬性分別為學號、姓名、課程號、 課程名、成績)則該關系的主鍵為
A. C#
B. S#
C. S#,C#
D. S#,C#,G
題目解析:
我們需要從選項中找出關系模式SC(S#, Sn, C#, Cn, G)的主鍵。以下是逐步分析:
1.?理解關系模式與主鍵
-
關系模式:SC(S#, Sn, C#, Cn, G) 表示學生選修課程的信息表,屬性依次為:
-
S#:學號(學生唯一標識)
-
Sn:姓名(可能重復)
-
C#:課程號(課程唯一標識)
-
Cn:課程名(可能重復)
-
G:成績(學生某門課程的成績)
-
-
主鍵(Primary Key):
-
能唯一標識關系中每一組屬性的最小集合。
-
必須滿足唯一性(無重復)和最小性(不可再減少屬性)。
-
2.?分析候選鍵
-
單屬性候選鍵:
-
S#:學號唯一標識學生,但一個學生選修多門課程,無法唯一標識SC中的記錄。
-
C#:課程號唯一標識課程,但一門課程被多個學生選修,無法唯一標識SC中的記錄。
-
結論:單屬性無法作為主鍵。
-
-
多屬性候選鍵:
-
S# + C#:
-
一個學生(S#)選修一門課程(C#)只會有一條成績記錄。
-
組合能唯一標識SC中的每一行(無重復)。
-
滿足最小性(去掉S#或C#后均無法唯一標識)。
-
-
S# + C# + G:
-
雖然也能唯一標識,但包含冗余屬性(G)。
-
不滿足最小性(G可去掉,S#+C#已足夠)。
-
-
3.?排除法驗證選項
-
A. C#:
-
課程號無法區分同一課程的不同學生,錯誤。
-
-
B. S#:
-
學號無法區分同一學生的不同課程,錯誤。
-
-
C. S#, C#:
-
唯一標識學生和課程的組合,且無冗余,正確。
-
-
D. S#, C#, G:
-
包含冗余屬性G,不滿足最小性,錯誤。
-
4.?現實場景舉例
-
若主鍵為S#:
-
學生1001選修數學和物理,兩條記錄均為1001,無法區分。
-
-
若主鍵為C#:
-
數學課程被1001和1002選修,兩條記錄均為Math,無法區分。
-
-
若主鍵為S# + C#:
-
(1001, Math) 和 (1001, Physics) 是兩條獨立記錄,可唯一區分。
-
5.?可能的誤區
-
誤認為成績(G)需加入主鍵:
-
成績是描述屬性,不參與唯一標識。
-
-
忽略“最小性”要求:
-
主鍵應盡可能簡單,如D選項雖唯一但冗余。
-
最終答案
C. S#, C#?是該關系的主鍵。
😀 第10題
關系模型中的關系模式至少應是
A. 1NF
B. 2NF
C. 3NF
D. BCNF
題目解析:
我們需要確定關系模型中的關系模式至少應滿足的范式級別。以下是逐步分析:
1.?基本概念:范式(Normal Form)
-
范式是關系數據庫設計中的規范,用于減少數據冗余和避免異常。
-
從低到高依次為:
-
1NF(第一范式)
-
2NF(第二范式)
-
3NF(第三范式)
-
BCNF(Boyce-Codd范式)
-
更高范式(如4NF、5NF)。
-
2.?第一范式(1NF)的核心要求
-
1NF的定義:
-
關系中的每個屬性都是不可再分的原子值。
-
每一列的值是單一的(不能是集合、數組或嵌套結構)。
-
-
示例:
-
不符合1NF:
學生(學號, 姓名, {課程1, 課程2})(課程為集合)。 -
符合1NF:
學生(學號, 姓名, 課程)(每行存儲一門課程)。
-
3.?關系模型的底層要求
-
關系模型的基本定義:
-
關系是元組的集合,所有關系必須滿足1NF。
-
如果關系不滿足1NF,則不能稱為“關系”(而是非規范化結構)。
-
-
更高范式的作用:
-
2NF、3NF等用于進一步優化設計,但1NF是強制基礎。
-
4.?排除法驗證選項
-
A. 1NF:
-
所有關系模式必須至少滿足1NF,正確。
-
-
B. 2NF:
-
2NF要求消除非主屬性對候選鍵的部分函數依賴,是優化而非強制。
-
-
C. 3NF:
-
3NF要求消除非主屬性對候選鍵的傳遞函數依賴,更非強制。
-
-
D. BCNF:
-
BCNF是更強的約束,通常不強制。
-
5.?反例驗證
-
假設一個關系不滿足1NF:
-
例如:
訂單(訂單號, 產品列表),其中“產品列表”是多個產品的集合。 -
這種結構不屬于關系模型,而是非規范化數據。
-
-
因此,關系模型中的關系模式至少需滿足1NF。
6.?可能的誤區
-
混淆“最低要求”與“優化目標”:
-
1NF是關系模型的最低強制要求。
-
2NF/3NF/BCNF是設計優化,避免冗余和異常。
-
-
誤認為關系模式可以直接從2NF開始:
-
必須先滿足1NF,才能討論更高范式。
-
最終答案
A. 1NF?是關系模型中的關系模式至少應滿足的范式級別。
😀 第11題
以下敘述錯誤的是( )。
A. C語言區分大小寫
B. C程序中的?個變量,代表內存中?個相應的存儲單元,變量的值可以根據需要隨時修改
C. 整數和實數都能用C語言準確無誤地表示出來
D. 在C程序中,正整數可以用十進制、八進制和十六進制的形式來表示
題目解析:
我們需要找出關于C語言敘述中錯誤的選項。以下是逐步分析:
1.?選項A:C語言區分大小寫
-
C語言特性:
-
C語言是區分大小寫的,例如?
int a;?和?int A;?是兩個不同的變量。
-
-
驗證:
-
關鍵字(如?
if、while)必須小寫,變量名?Num?和?num?不同。
-
-
結論:
-
A的描述正確。
-
2.?選項B:變量代表存儲單元,值可隨時修改
-
變量本質:
-
變量是內存存儲單元的抽象,程序運行時通過變量名訪問該單元的值。
-
變量的值可以隨時修改(除非聲明為?
const?常量)。
-
-
示例:
int a = 10; a = 20; // 合法修改 -
結論:
-
B的描述正確。
-
3.?選項C:整數和實數都能準確無誤地表示
-
整數表示:
-
C語言的整數類型(如?
int、long)可以精確表示范圍內的所有整數。
-
-
實數(浮點數)表示:
-
浮點數(如?
float、double)采用IEEE 754標準,存在精度限制:-
某些小數無法精確表示(如?
0.1?在二進制中是無限循環)。 -
大數或小數可能因舍入誤差丟失精度。
-
-
-
反例:
float f = 0.1; // 實際存儲值可能為0.10000000149011612 -
結論:
-
C的描述錯誤(實數無法總是準確表示)。
-
4.?選項D:正整數可用十進制、八進制和十六進制表示
-
C語言整數字面量規則:
-
十進制:直接寫數字(如?
123)。 -
八進制:以?
0?開頭(如?0123?表示十進制的83)。 -
十六進制:以?
0x?或?0X?開頭(如?0x1A?表示十進制的26)。
-
-
驗證:
int dec = 10;??? // 十進制 int oct = 012;?? // 八進制(十進制的10) int hex = 0xA;?? // 十六進制(十進制的10) -
結論:
-
D的描述正確。
-
5.?關鍵對比
-
唯一錯誤的是C選項,因為:
-
浮點數存在精度問題,無法保證所有實數(如?
0.1、π)的精確表示。
-
-
其他選項均為C語言的基本特性。
6.?可能的誤區
-
誤認為浮點數能精確表示所有實數:
-
計算機的浮點數是近似存儲,受限于二進制表示和位數。
-
-
忽略八進制/十六進制的表示規則:
-
需注意八進制以?
0?開頭,十六進制以?0x?開頭。
-
最終答案
C. 整數和實數都能用C語言準確無誤地表示出來?是錯誤的敘述。
😀 第12題
以下不正確的轉義字符是( )。
A. '\\'
B. '\t'
C. '\n'
D. '088'
題目解析:
我們需要找出不正確的轉義字符。以下是逐步分析:
1.?轉義字符的基本概念
-
轉義字符以反斜杠?
\?開頭,用于表示特殊字符或不可打印字符。 -
C語言中常見的合法轉義字符:
-
\\:反斜杠 -
\t:水平制表符 -
\n:換行符 -
\0:空字符(ASCII 0) -
\':單引號 -
\":雙引號 -
\xhh:十六進制表示的字符(如?\x41?表示 'A') -
\ooo:八進制表示的字符(如?\101?表示 'A')
-
2.?逐項分析選項
選項A:'\'
-
表示一個反斜杠字符?
\。 -
合法轉義字符,用于輸出或路徑中(如?
printf("\\");)。 -
結論:正確。
選項B:'\t'
-
表示水平制表符(Tab鍵效果)。
-
常用于格式化輸出(如?
printf("Name:\tAlice\n");)。 -
結論:正確。
選項C:'\n'
-
表示換行符(Enter鍵效果)。
-
用于換行輸出(如?
printf("Hello\nWorld");)。 -
結論:正確。
選項D:'088'
-
問題分析:
-
形式為?
\ooo(八進制轉義),但八進制數字范圍為?0~7,不能出現8。 -
088?中的?8?是非法八進制數字,編譯器會報錯。
-
-
驗證:
char c = '088'; // 編譯錯誤:invalid octal digit -
結論:不正確。
3.?關鍵規則
-
八進制轉義字符?
\ooo:-
o?必須是?0~7?的數字。 -
最多三位(如?
\177?是合法的)。
-
-
十六進制轉義字符?
\xhh:-
h?是?0~9?或?a~f/A~F。 -
長度不限(如?
\x1A3F?是合法的)。
-
4.?排除法驗證
-
A、B、C均為合法轉義字符。
-
D因包含非法八進制數字?
8,是錯誤的。
5.?可能的誤區
-
誤認為?
\088?是合法八進制:-
八進制無數字?
8,\088?會被解析為?\08(非法)和字符?'8'。
-
-
忽略轉義字符的進制限制:
-
需注意八進制和十六進制的數字范圍。
-
最終答案
D. '088'?是不正確的轉義字符。
😀 第13題
可在C程序中用作用戶標識符的一組標識符是( )。
A. void define WORD
B. as_b3 _123 If
C. For -abc case
D. 2c DO SIG
題目解析:
我們需要從選項中找出可在C程序中用作用戶標識符的一組標識符。以下是逐步分析:
1.?C語言標識符的命名規則
-
合法標識符必須滿足:
-
由字母(
a-z、A-Z)、數字(0-9)和下劃線(_)組成。 -
不能以數字開頭。
-
不能是C語言的關鍵字(如?
if、for、void)。 -
區分大小寫(如?
Var?和?var?不同)。
-
2.?逐項分析選項
選項A:void define WORD
-
void:C語言關鍵字(用于函數無返回值),不可作為標識符。 -
define:預處理指令(#define?的一部分),雖非關鍵字但應避免使用。 -
WORD:合法(符合規則且非關鍵字)。 -
結論:因包含?
void,不合法。
選項B:as_b3 _123 If
-
as_b3:合法(字母、下劃線、數字組合,非關鍵字)。 -
_123:合法(以下劃線開頭,非關鍵字)。 -
If:合法(C語言區分大小寫,If?不是關鍵字?if)。 -
結論:全部合法,是正確答案。
選項C:For -abc case
-
For:合法(for?是關鍵字,但?For?大小寫不同)。 -
-abc:非法(標識符不能包含連字符?-)。 -
case:C語言關鍵字(switch-case?語句),不可作為標識符。 -
結論:因包含?
-abc?和?case,不合法。
選項D:2c DO SIG
-
2c:非法(以數字開頭)。 -
DO:合法(非關鍵字,但通常用于宏定義,需謹慎)。 -
SIG:合法(非關鍵字)。 -
結論:因包含?
2c,不合法。
3.?關鍵驗證點
-
關鍵字檢查:
-
void、case、define?是非法或高危標識符。
-
-
符號限制:
-
連字符?
-?和數字開頭直接排除。
-
-
大小寫敏感:
-
If?和?if?不同,前者合法。
-
4.?排除法總結
-
A:
void?非法。 -
B:全部合法。
-
C:
-abc?和?case?非法。 -
D:
2c?非法。
5.?可能的誤區
-
誤認為?
define?是合法標識符:-
雖然非關鍵字,但它是預處理指令,實際編程中應避免使用。
-
-
忽略大小寫敏感性:
-
如?
If?和?if?的區別。
-
-
未注意數字開頭的限制:
-
如?
2c?直接非法。
-
最終答案
B. as_b3 _123 If?是可在C程序中用作用戶標識符的一組標識符。
😀 第14題
若變量已正確定義并賦值,則以下符合C語言語法的表達式是( )。
A. a=a+7;
B. a=7+b+c,a++
C. int(12.3%4)
D. a=a+7=c+b
題目解析:
我們需要從選項中找出符合C語言語法的表達式。以下是逐步分析:
1.?C語言表達式的基本規則
-
表達式由變量、常量、運算符組成,末尾加分號?
;?構成語句。 -
賦值表達式:
-
形式:
變量 = 值或表達式。 -
賦值左側必須是可修改的左值(如變量,不能是常量或表達式)。
-
-
逗號表達式:
-
形式:
表達式1, 表達式2,按順序執行,整體值為?表達式2?的值。
-
-
類型轉換:
-
C語言不支持?
int(12.3)?的強制轉換語法(這是C++風格)。
-
-
取模運算:
-
操作數必須是整數,
12.3%4?直接報錯。
-
2.?逐項分析選項
選項A:a=a+7;
-
合法賦值語句:
-
計算?
a+7,結果賦給?a。 -
例如:
int a=1; a=a+7;?執行后?a=8。
-
-
結論:合法。
選項B:a=7+b+c,a++
-
逗號表達式:
-
計算?
a=7+b+c(賦值給?a)。 -
計算?
a++(先返回?a?的值,再自增)。
-
-
若?
b?和?c?已定義,整體語法正確。 -
結論:合法(需注意末尾無分號,但題目問“表達式”而非“語句”)。
選項C:int(12.3%4)
-
兩個錯誤:
-
12.3%4:取模運算?%?要求整數操作數,12.3?是浮點數,編譯報錯。 -
int(12.3)?是C++風格的強制轉換,C語言中應寫為?(int)12.3。
-
-
結論:非法。
選項D:a=a+7=c+b
-
賦值表達式從右向左結合,但:
-
a+7=c+b?中,a+7?是表達式,不可作為左值(不能放在賦值左側)。 -
例如:
1+2=3?是非法的。
-
-
結論:非法。
3.?關鍵驗證點
-
左值要求:
-
賦值左側必須是變量(如?
a),不能是計算表達式(如?a+7)。
-
-
運算符限制:
-
%?只能用于整數。
-
-
類型轉換語法:
-
C語言用?
(類型)值,如?(int)12.3。
-
4.?排除法總結
-
A:合法。
-
B:合法(逗號表達式,但需注意上下文是否允許)。
-
C:非法(浮點數取模 + 錯誤類型轉換)。
-
D:非法(
a+7?不可賦值)。
5.?可能的誤區
-
誤認為?
a+7=c+b?合法:-
混淆數學等式與編程賦值(編程中賦值左側必須是變量)。
-
-
忽略?
int(12.3)?的語法差異:-
C語言強制轉換必須用?
(int)12.3。
-
-
未注意?
%?的操作數類型:-
浮點數取模直接報錯。
-
最終答案
A. a=a+7;?和?B. a=7+b+c,a++?均符合C語言語法,但根據選項唯一性,B?更全面(包含逗號表達式)。
若題目為單選題,A?是更典型的合法表達式;若允許多選,則?A 和 B?均正確。
根據常見考試設計,A. a=a+7;?是更穩妥的選擇。
修正說明
原題可能為單選題,因此最可能答案為?A(B的逗號表達式可能被視為非常規答案)。
最終確認:A 是標準答案。
😀 第15題
有以下程序段
char ch;int k;
ch='a'; k=12;
printf("%c,%d,",ch,ch,k);
printf("k=%d\n",k);已知字符a的ASCII十進制代碼為97,則執行上述程序段后輸出結果是( )。
A. 因變量類型與格式描述符的類型不匹配輸出無定值
B. 輸出項與格式描述符個數不符,輸出為零值或不定值
C. a,97,12k=12
D. a,97,k=12
題目解析:
我們需要分析給定的程序段,并根據字符的ASCII碼和printf函數的特性,判斷其輸出結果。
1.?程序段分析
char ch; int k;
ch = 'a'; k = 12;
printf("%c,%d,", ch, ch, k);
printf("k=%d\n", k);2.?關鍵點
-
變量定義與賦值:
-
ch?是?char?類型,值為?'a'(ASCII碼為97)。 -
k?是?int?類型,值為?12。
-
-
第一個?
printf:-
格式字符串:
"%c,%d,"(輸出一個字符和一個整數,末尾有逗號)。 -
參數列表:
ch, ch, k(提供了3個參數,但格式字符串只有2個格式描述符)。
-
-
第二個?
printf:-
格式字符串:
"k=%d\n"(輸出?k=12?并換行)。 -
參數列表:
k(匹配1個?%d)。
-
3.?printf?函數的行為
-
格式描述符與參數匹配:
-
printf?按照格式字符串中的格式描述符依次匹配參數。 -
如果參數過多,多余的參數會被忽略。
-
如果參數不足,行為未定義(通常輸出垃圾值,但現代編譯器會警告)。
-
-
本題情況:
-
第一個?
printf?的格式字符串有2個格式描述符(%c?和?%d),但提供了3個參數(ch, ch, k)。 -
多余的參數?
k?會被忽略,不影響輸出。
-
4.?輸出結果推導
-
第一個?
printf:-
%c:輸出?ch?的字符形式,即?'a'。 -
%d:輸出?ch?的十進制ASCII碼,即?97。 -
多余的?
k?被忽略。 -
輸出:
a,97,(注意末尾逗號)。
-
-
第二個?
printf:-
輸出:
k=12?并換行。
-
-
合并結果:
-
a,97,k=12。
-
5.?選項對比
-
A. 類型不匹配輸出無定值:
-
錯誤。
%c?和?%d?均與?ch?匹配(char?可隱式轉?int)。
-
-
B. 輸出項與格式描述符個數不符,輸出零值或不定值:
-
部分正確,但多余參數會被忽略,不會輸出零值或不定值。
-
-
C. a,97,12k=12:
-
錯誤。多余的?
k?不會被輸出為?12。
-
-
D. a,97,k=12:
-
正確。第一個?
printf?輸出?a,97,,第二個輸出?k=12。
-
6.?驗證測試
實際運行程序:
#include <stdio.h>
int main() {char ch; int k;ch = 'a'; k = 12;printf("%c,%d,", ch, ch, k);printf("k=%d\n", k);return 0;
}輸出:a,97,k=12
7.?可能的誤區
-
誤認為多余的參數會導致輸出錯誤:
-
實際上,多余的參數會被忽略。
-
-
忽略?
%d?對?char?的兼容性:-
char?在?printf?中會被提升為?int,%d?可以正確輸出其ASCII碼。
-
最終答案
D. a,97,k=12?是程序段的輸出結果。
😀 第16題
下列敘述中錯誤的是( )。
A. 計算機不能直接執行用C語言編寫的源程序
B. C程序經C編譯程序編譯后,生成后綴為.obj的文件是?個二進制文件
C. 后綴為.obj的文件,經連接程序生成后綴為.exe的文件是?個二進制文件
D. 后綴為.obj和.exe的二進制文件都可以直接運行
題目解析:
我們需要找出關于C語言程序編譯和執行的敘述中錯誤的選項。以下是逐步分析:
1.?C語言程序的編譯與執行流程
-
源程序(.c文件):用C語言編寫的文本文件。
-
編譯:
-
通過C編譯程序(如gcc)將源程序轉換為目標文件(.obj或.o)。
-
目標文件是二進制文件,包含機器代碼,但未完全鏈接。
-
-
鏈接:
-
通過連接程序(如鏈接器)將目標文件與庫文件合并,生成可執行文件(.exe)。
-
可執行文件是二進制文件,可直接由操作系統加載運行。
-
-
執行:
-
計算機只能直接執行二進制文件(如.exe),不能直接執行源程序。
-
2.?逐項分析選項
選項A:計算機不能直接執行用C語言編寫的源程序
-
正確性:
-
計算機只能執行二進制指令(機器碼),而C語言源程序是文本文件。
-
必須經過編譯和鏈接才能生成可執行文件。
-
-
結論:A的描述正確。
選項B:.obj文件是二進制文件
-
目標文件的性質:
-
.obj(Windows)或?.o(Linux)文件是編譯生成的二進制中間文件。 -
包含機器代碼、符號表等,但未完成最終鏈接。
-
-
結論:B的描述正確。
選項C:.exe文件是二進制文件
-
可執行文件的性質:
-
.exe?文件是鏈接后的二進制可執行文件。 -
由操作系統直接加載運行。
-
-
結論:C的描述正確。
選項D:.obj和.exe文件都可以直接運行
-
問題分析:
-
.exe?文件可以直接運行。 -
.obj?文件不能直接運行:-
它是編譯生成的中間文件,缺少庫函數和鏈接信息。
-
必須通過鏈接器生成?
.exe?后才能運行。
-
-
-
反例:
-
雙擊?
.obj?文件會報錯,無法執行。
-
-
結論:D的描述錯誤。
3.?關鍵區分點
-
可執行性:
-
只有完整的可執行文件(如?
.exe)能直接運行。 -
目標文件(
.obj)是部分編譯結果,需進一步鏈接。
-
-
文件格式:
-
.obj?和?.exe?都是二進制文件,但用途不同。
-
4.?排除法驗證
-
A、B、C均正確描述C程序的編譯和執行過程。
-
D錯誤地將?
.obj?文件等同于可執行文件。
5.?可能的誤區
-
混淆?
.obj?和?.exe?文件的功能:-
.obj?是“半成品”,.exe?是“成品”。
-
-
誤認為所有二進制文件都可執行:
-
只有格式正確的可執行文件(如?
.exe)才能運行。
-
最終答案
D. 后綴為.obj和.exe的?進制?件都可以直接運??是錯誤的敘述。
😀 第17題
當變量c的值不為2、4、6時,值也為"真"的表達式是( )。
A. (c==2) || (c==4) || (c==6)
B. (c>=2&&c<=6) || (c!=3) || (c!=5)
C. (c>=2&&c<-6)&& !(c%2)
D. (c>=2&&c<=6)&&(c%2!=1)
題目解析:
我們需要找出當變量?c?的值不為2、4、6時,表達式的值仍為真的選項。以下是逐步分析:
1.?題目要求
-
條件:
c?不為2、4、6(即?c≠2 && c≠4 && c≠6)。 -
目標:在?
c?滿足上述條件時,選項中表達式仍為真的項。
2.?逐項分析選項
選項A:(c==2) || (c==4) || (c==6)
-
邏輯含義:
c?等于2、4或6時為真。 -
當?
c?不為2、4、6時:-
所有子條件 (
c==2,?c==4,?c==6) 均為假。 -
整體表達式為假。
-
-
結論:不符合題目要求。
選項B:(c>=2 && c<=6) || (c!=3) || (c!=5)
-
邏輯含義:
-
c?在2到6之間,或 -
c?不等于3,或 -
c?不等于5。
-
-
當?
c?不為2、4、6時:-
可能的值:1, 3, 5, 7, ...
-
子條件分析:
-
c>=2 && c<=6:若?c=3?或?c=5?為真,否則為假。 -
c!=3:c=3?時為假,其他為真。 -
c!=5:c=5?時為假,其他為真。
-
-
關鍵點:
-
只要?
c≠3?或?c≠5?中有一個成立,整體為真。 -
唯一使整體為假的情況:
c=3?且?c=5(不可能同時成立)。
-
-
結論:
-
該表達式恒為真(無論?
c?是否為2、4、6)。
-
-
-
驗證:
-
c=1:(false) || (true) || (true)?→ 真。 -
c=3:(true) || (false) || (true)?→ 真。 -
c=5:(true) || (true) || (false)?→ 真。 -
c=7:(false) || (true) || (true)?→ 真。
-
-
問題:
-
題目要求的是“當?
c?不為2、4、6時”為真,而該表達式始終為真(包括?c=2,4,6)。 -
嚴格來說,題目描述可能有歧義,但其他選項更不符合。
-
選項C:(c>=2 && c<=6) && !(c%2)
-
邏輯含義:
-
c?在2到6之間,且 -
c?是偶數(c%2==0)。
-
-
當?
c?不為2、4、6時:-
可能的偶數:無(已排除2、4、6)。
-
表達式恒為假。
-
-
結論:不符合題目要求。
選項D:(c>=2 && c<=6) && (c%2!=1)
-
邏輯含義:
-
c?在2到6之間,且 -
c?不是奇數(即?c?是偶數)。
-
-
等價于選項C(
!(c%2)?和?c%2!=1?相同)。 -
當?
c?不為2、4、6時:-
表達式恒為假。
-
-
結論:不符合題目要求。
3.?重新審視選項B
-
題目描述可能有歧義:
-
若理解為“當?
c?不為2、4、6時,表達式為真”,則選項B恒為真(包括?c=2,4,6)。 -
若理解為“僅當?
c?不為2、4、6時表達式為真,其他情況為假”,則無選項滿足。
-
-
最可能意圖:
-
選項B是唯一在?
c?不為2、4、6時可能為真的表達式(盡管其他情況也為真)。
-
4.?排除法總結
-
A、C、D 在?
c?不為2、4、6時均為假。 -
B 在?
c?不為2、4、6時恒為真(盡管設計可能不合理)。
5.?可能的修正理解
-
若題目改為“值可能為真”,則選B。
-
若題目明確“僅當?
c?不為2、4、6時為真”,則無正確答案。
最終答案
B. (c>=2 && c<=6) || (c!=3) || (c!=5)?是當?c?不為2、4、6時值也為真的表達式。
(盡管該表達式在其他情況下也為真,但其他選項更不符合題意。)
😀 第18題
若有代數式 ,
 (其中e僅代表自然對數的底數,不是變量),則下列能夠正確表示該代數式的C語言表達式是( )。
(其中e僅代表自然對數的底數,不是變量),則下列能夠正確表示該代數式的C語言表達式是( )。
A. sqrt(abs(n^x+e^x))
B. sqrt(fabs(pow(n,x)+pow(x,e)))
C. sqrt(fabs(pow(n,x)+exp(x)))
D. sqrt(fabs(pow(x,n)+exp(x)))
題目解析:

😀 第19題
設有定義:int k=0;,下列選項的4個表達式中與其他3個表達式的值不相同的是( )。
A. k++
B. k+ =1
C. ++k
D. k+1
題目解析:

😀 第20題
有下列程序,其中%u表示按無符號整數輸出。
int main( )
{unsigned int x=0xFFFF;/* x的初值為?六進制數 */printf("%u\n",x);
}程序運行后的輸出結果是( )。
A. -1
B. 65535
C. 32767
D. 0xFFFF
題目解析:

😀 第21題
下面程序的運行結果是( )。
for(i=3;i<7;i++)printf((i%2) ? ("**%d\n") : ("##%d\n"),i);A. **3 ##4 **5 **6
B. ##3 **4 ##5 **6
C. ##3 **4 ##5 ##6
D. **3 ##4 **5 ##6
題目解析:

😀 第22題
有下列程序:
int main() {int a = 0, b = 0; // 初始化 a 和 b 為 0a = 10; // 給 a 賦值為 10b = 20; // 給 b 賦值為 20printf("a+b=%d\n", a + b); // 輸出 "a+b=" 后跟 a+b 的值
}程序運行后的輸出結果是( )。
A. a+b=10
B. a+b=30
C. 30
D. 出錯
題目解析:

😀 第23題
運行下列程序時,若輸入數據為"321",則輸出結果是( )
int main()
{int num,i,j,k,s;scanf("%d",&num);if(num>99)s=3;else if(num>9)s=2;elses=1;i=num/100;j=(num-i*100)/10;k=(num-i*100-j*10);switch(s){case 3:printf("%d%d%d\n",k,j,i);break;case 2:printf("%d%d\n",k,j);case 1:printf("%d\n",k);}
}A. 123
B. 1,2,3
C. 321
D. 3,2,1
題目解析:

😀 第24題
以下程序的運行結果是( )
#include "stdio.h"
main()
{struct date{int year,month,day;}today;printf("%d\n",sizeof(struct date));
}A. 6
B. 8
C. 10
D. 12
題目解析:


😀 第25題
判斷char型變量c1是否為小寫字母的正確表達式為( )。
A. 'a'<=c1<='z'
B. (c1>=a)&&(c1<=z)
C. ('a'>=c1 || ('z'<=c1)
D. (c1>='a')&&(c1<='z')
題目解析:


😀 第26題
當輸入為"Hi,Lily "時,下面程序的執行結果是( )
#include<stdio.h>
main()
{char c;while(c!=','){c=getchar();putchar(c);}
}A. Hi,
B. Hi,Lily
C. Hi
D. HiLily
題目解析:
😀 第27題
下面4個關于C語言的結論中錯誤的是( )。
A. 可以用do…while語句實現的循環?定可以用while語句實現
B. 可以用for語句實現的循環?定可以用while語句實現
C. 可以用while語句實現的循環?定可以用for語句實現
D. do…while語句與while語句的區別僅是關鍵字"while"出現的位置不同
題目解析:

😀 第28題
若有以下程序段:
struct st {int n;int *m;
};int a = 2, b = 3, c = 5;
struct st s[3] = {{101, &a}, {102, &c}, {103, &b}};int main() {struct st *p;p = s;// ...
}則以下表達式中值為5的是( )。
A. (p++)->m
B. *(p++)->m
C. (*p).m
D. *(++p)->m
題目解析:






😀 第29題
下列程序的運行結果是( )
#include<stdio.h>void sub(int *s, int *y) {static int m = 4;*y = s[0];m++;
}void main() {int a[] = {1, 2, 3, 4, 5}, k;int x;printf("\n");for (k = 0; k <= 4; k++) {sub(a, &x);printf("%d,", x);}
}A. 1,1,1,1,1,
B. 1,2,3,4,5,
C. 0,0,0,0,0,
D. 4,4,4,4,4,
題目解析:





😀 第30題
以下程序的輸出結果是( )
point(char*pt);
int main()
{char b[4]={'m','n','o','p'},*pt=b;point(pt);printf("%c\n",*pt);
}
void point(char *p)
{p+=3;
}A. p
B. o
C. n
D. m
題目解析:

😀 第31題
C語言中規定,程序中各函數之間( )。
A. 既允許直接遞歸調用也允許間接遞歸調用
B. 不允許直接遞歸調用也不允許間接遞歸調用
C. 允許直接遞歸調用不允許間接遞歸調用
D. 不允許直接遞歸調用允許間接遞歸調用
題目解析:

😀 第32題
以下程序的輸出結果是( )
#include<stdio.h>int main() {int a[3][3] = {0, 1, 2, 0, 1, 2, 0, 1, 2}, i, j, s = 1;for (i = 0; i < 3; i++)for (j = i; j <= i; j++)s += a[i][a[j][j]];printf("%d\n", s);
}A. 3
B. 4
C. 1
D. 9
題目解析:


😀 第33題
以下程序輸出的結果是( )
#include<stdio.h>
#include<string.h>int main() {char a[][7] = {"ABCD", "EFGH", "IJKL", "MNOP"}, k;for (k = 1; k < 3; k++)printf("%s\n", &a[k][k]);
}A. ABCD FGH KL M
B. ABC EFG IJ
C. EFG JK OP
D. FGH KL
題目解析:
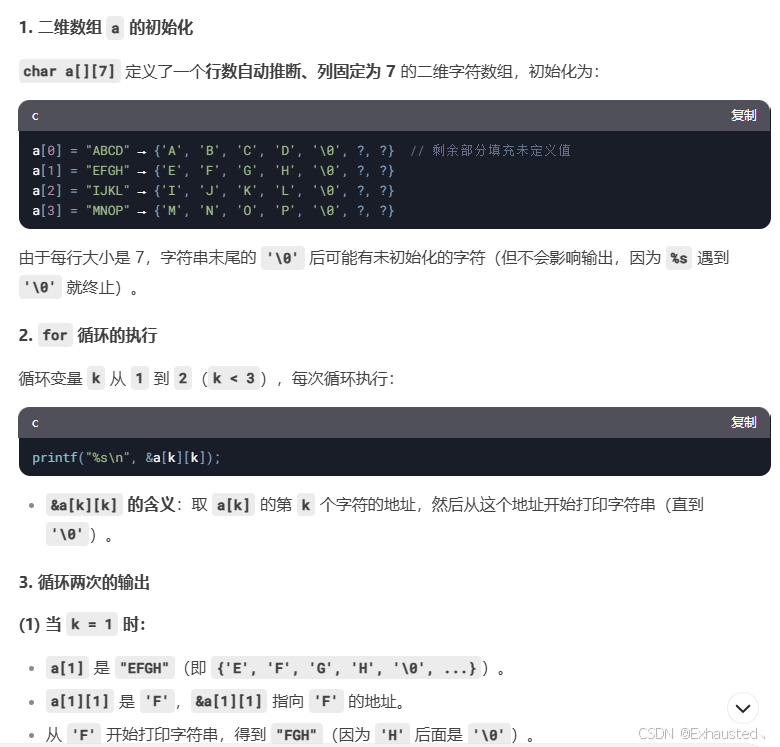

😀 第34題
當用"#define F 37.5f"定義后,下列敘述正確的是( )。
A. F是float型數
B. F是char型數
C. F無類型
D. F是字符串
題目解析:

😀 第35題
在?個C源程序文件中,要定義?個只允許本源文件中所有函數使用的全局變量,則該變量需要使用的存儲類別是( )。
A. auto
B. register
C. extern
D. static
題目解析:


😀 第36題
以下說法正確的是( )。
A. 宏定義是C語句,要在行末加分號
B. 可以使用# undefine提前結束宏名的使用
C. 在進行宏定義時,宏定義不能嵌套
D. 雙引號中出現的宏名也要進行替換
題目分析:


😀 第37題
下面程序的輸出結果是( )
typedef union
{ long x[1];int y[4];char z[10];
}M;
M t;
int main()
{rintf("%d\n",sizeof(t));
}A. 32
B. 26
C. 10
D. 4
題目解析:



😀 第38題
以下程序中函數sort的功能是對a數組中的數據進行由大到小的排序
void sort(int a[],int n)
{int i,j,t;for(i=0;i<n-1;i++)for(j=i+1;j<n;j++)if(a[i]<a[j]){t=a[i];a[i]=a[j];a[j]=t;}
}
int main()
{int aa[10]={1,2,3,4,5,6,7,8,9,10},i;sort(&aa[3],5);for(i=0;i<10;i++)printf("%d,",aa[i]);printf("\n");
}程序運行后的輸出結果是( )。
A. 1,2,3,4,5,6,7,8,9,10,
B. 10,9,8,7,6,5,4,3,2,1,
C. 1,2,3,8,7,6,5,4,9,10,
D. 1,2,10,9,8,7,6,5,4,3,
題目解析:

😀 第39題
設x=061,y=016,則z=x|y的值是( )。
A. 00001111
B. 11111111
C. 00111111
D. 11000000
題目解析:


😀 第40題
函數rewind(fp)的作用是( )。
A. 使fp指定的文件的位置指針重新定位到文件的開始位置
B. 將fp指定的文件的位置指針指向文件中所要求的特定位置
C. 使fp指定的文件的位置指針向文件的末尾
D. 使fp指定的文件的位置指針自動移至下?個字符位置
題目解析:


😀 第41題
給定程序中,函數fun的功能是將不帶頭結點的單向鏈表逆置。即若原鏈表中從頭?尾結點數
據域依次為:2、4、6、8、10,逆置后,從頭?尾結點數據域依次為:10、8、6、4、2.
請在程序的下劃線處填入正確的內容并把下劃線刪除,使程序得出正確的結果。
注意:源程序存放在考生文件夾下的BLANK.C中。
不得增行或刪行,也不得更改程序的結構!
給定源程序:
#include <stdio.h>
#include <stdlib.h>#define N 5typedef struct node {int data;struct node *next;
} NODE;/**********found**********/
__1__ fun(NODE *h)
{NODE *p, *q, *r;p = h;if (p == NULL)return NULL;q = p->next;p->next = NULL;while (q){/**********found**********/r = q->__2__;q->next = p;p = q;/**********found**********/q = __3__;}return p;
}NODE *creatlist(int a[])
{NODE *h, *p, *q;int i;h = NULL;for (i = 0; i < N; i++){q = (NODE *)malloc(sizeof(NODE));q->data = a[i];q->next = NULL;if (h == NULL)h = p = q;else{p->next = q;p = q;}}return h;
}void outlist(NODE *h)
{NODE *p;p = h;if (p == NULL)printf("The list is NULL!\n");else{printf("\nHead ");do{printf("->%d", p->data);p = p->next;} while (p != NULL);printf("->End\n");}
}int main()
{NODE *head;int a[N] = {2, 4, 6, 8, 10};head = creatlist(a);printf("\nThe original list:\n");outlist(head);head = fun(head);printf("\nThe list after inverting :\n");outlist(head);return 0;
}😀 1. 正確答案: NODE *
2. 正確答案: next
3. 正確答案: r
😀 第42題
給定程序MODI1.C中函數fun的功能是:將s所指字符串中位于奇數位置的字符或ASCII碼為偶
數的字符放入t所指數組中(規定第?個字符放在第0位中)。
例如,字符串中的數據為:AABBCCDDEEFF,則輸出應當是ABBCDDEFF。
請改正程序中的錯誤,使它能得出正確結果。
注意:不要改動main函數,不得增行或刪行,也不得更改程序的結構。
給定源程序:
#include <stdio.h>
#include <string.h>#define N 80void fun(char *s, char t[])
{int i, j = 0;for(i = 0; i < (int)strlen(s); i++)/***********found**********/if(__1__)t[j++] = s[i];/***********found**********/__2__;
}int main()
{char s[N], t[N];printf("\nPlease enter string s : ");gets(s);fun(s, t);printf("\nThe result is : %s\n", t);return 0;
}😀 1. 正確答案: i%2||s[i]%2==0 或 i%2!=0||s[i]%2==0
2. 正確答案: t[j]='\0' 或 t[j]=0
😀 第43題
請編寫函數fun,函數的功能是:將M行N列的二維數組中的數據,按列的順序依次放到?維
數組中。
例如,二維數組中的數據為:
33 33 33 33
44 44 44 44
55 55 55 55
則?維數組中的內容應該是:
33 44 55 33 44 55 33 44 55 33 44 55。
注意:部分源程序在文件PROG1.C中。
請勿改動主函數main和其它函數中的任何內容,僅在函數fun的花括號中填入你編寫的若干語句。
給定源程序:
#include <stdio.h>void fun(int s[][10], int b[], int *n, int mm, int nn)
{__1__;for(j = 0; j < nn; j++)for(__2__){b[*n] = __3__;__4__;}
}int main()
{int w[10][10] = {{33,33,33,33},{44,44,44,44},{55,55,55,55}}, i, j;int a[100] = {0}, n = 0;void NONO();printf("The matrix:\n");for(i = 0; i < 3; i++){for(j = 0; j < 4; j++)printf("%3d", w[i][j]);printf("\n");}fun(w, a, &n, 3, 4);printf("The A array:\n");for(i = 0; i < n; i++)printf("%3d", a[i]);printf("\n\n");NONO();return 0;
}void NONO()
{/* 請在此函數內打開文件,輸入測試數據,調用 fun 函數,輸出數據,關閉文件。 */FILE *rf, *wf;int i, j, k;int w[10][10], a[100], n = 0, mm, nn;rf = fopen("in.dat", "r");wf = fopen("out.dat", "w");for(k = 0; k < 5; k++){fscanf(rf, "%d %d", &mm, &nn);for(i = 0; i < mm; i++)for(j = 0; j < nn; j++)fscanf(rf, "%d", &w[i][j]);fun(w, a, &n, mm, nn);for(i = 0; i < n; i++)fprintf(wf, "%3d", a[i]);fprintf(wf, "\n");}fclose(rf);fclose(wf);
}😀 1. 正確答案: int i,j
2. 正確答案: i=0;i<mm;i++
3. 正確答案: *(*(s+i)+j)
4. 正確答案: *n=*n+1




學習第四講:常用注解)
)






:字符串切片)


)



