一、單目視覺測距和雙目視覺測距簡介
1、單目視覺測距
模型:深度估計(Depth Estimation)
-
原理:通過深度學習模型(如MonoDepth2、MiDaS)或傳統的計算機視覺方法(如單目相機結合物體大小推斷)估計場景深度。
-
實現方式:
-
使用卷積神經網絡(CNN)或Transformer模型,從單張圖像預測像素級深度信息。
-
需要大量帶深度信息的標注數據進行訓練,如KITTI、NYU Depth等數據集。
-
2、雙目視覺測距
模型:立體匹配(Stereo Matching)
-
原理:基于視差計算(Disparity Calculation),通過兩個攝像頭的圖像視差計算目標距離。
-
計算步驟:
-
通過SGBM(Semi-Global Block Matching)或深度學習模型(如PASMNet、GA-Net)獲取視差圖。
-
結合攝像頭參數(基線長度、焦距)使用公式:
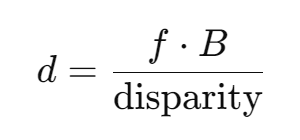
其中:
-
d:目標距離
-
f:攝像頭焦距
-
B:攝像頭基線距離
-
disparity:視差
-
-
二、深度學習在雙目視覺測距領域的應用
1、視差圖計算階段
這是深度學習應用最廣泛的階段。傳統方法(如SGBM、BM等)在復雜場景下效果不佳。
(1)什么是視差圖?
- 視差圖(Disparity Map)是表示同一場景在不同視角下圖像中對應點之間水平位移的圖
- 每個像素值代表該點在左右圖像中的水平位移(視差值)
- 視差越大,表示物體距離相機越近
- 視差越小,表示物體距離相機越遠
(2)視差圖的特點
- 灰度圖像:每個像素值表示視差大小
- 顏色越亮:表示視差越大(物體越近)
- 顏色越暗:表示視差越小(物體越遠)
- 黑色區域:表示無法計算視差(遮擋或無效區域)
(3)深度學習方法(如PSMNet、GCNet等)可以:
- 更好地處理遮擋區域
- 提高視差計算的準確性
- 減少計算時間
- 更好地處理弱紋理區域
2、特征提取階段
使用卷積神經網絡(CNN)提取更魯棒的特征
相比傳統SIFT、SURF等特征,深度學習特征:
- 具有更強的表達能力
- 對光照變化更魯棒
- 計算速度更快
3、視差圖優化階段
使用深度學習模型進行視差圖的后處理可以:
- 填充視差空洞
- 平滑視差圖
- 提高視差圖的連續性
4、深度估計階段
直接使用端到端的深度估計網絡
例如:
- MonoDepth2
- DeepStereo
- 這些方法可以直接從雙目圖像估計深度圖
深度學習應用于測距領域的主要優勢:
- 精度更高:相比傳統方法,深度學習方法的精度顯著提升
- 魯棒性更強:對復雜場景、光照變化等具有更好的適應性
- 速度更快:通過GPU加速,可以實現實時處理
- 端到端訓練:可以直接優化最終目標






)












