尚硅谷大數據項目【電商數倉6.0】企業數據倉庫項目_bilibili
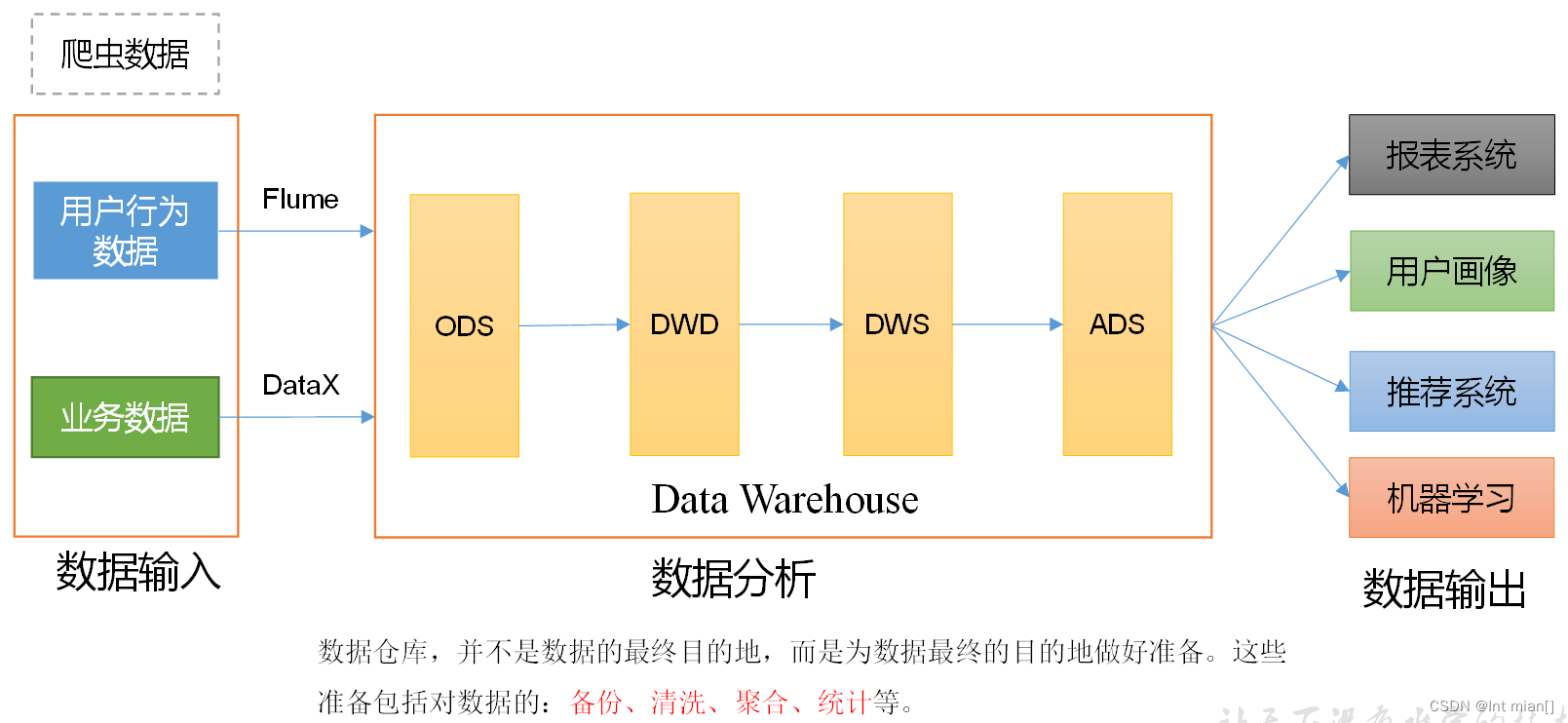
數據流轉過程
用戶??業務服務器??數據庫存儲??數倉統計分析??數據可視化
· 數據倉庫處理流程:數據源??加工數據??統計篩選數據??分析數據
數據庫不是為了數據倉庫服務的,需要給數倉單獨構建一個數據源(行式列式存儲不對應、數據庫海量數據不滿足、對mysql性能造成影響)
數據源周期性(一天、一周)從mysql數據庫同步過來,這就叫采集
HDFS承前啟后
數據存儲file??? Flume采集? ? ??HDFS??Hive數倉數據源
數據? mysql??DataX/Maxwell??HDFS??Hive數倉數據源
數倉開發需要用sql,需要用結構化數據
一些概念
數據倉庫的輸入數據通常包括:業務數據、用戶行為數據和爬蟲數據等
業務數據:就是各行業在處理事務過程中產生的數據。比如用戶在電商網站中登錄、下單、支付等過程中,需要和網站后臺數據庫進行增刪改查交互,產生的數據就是業務數據。業務數據通常存儲在MySQL、Oracle等數據庫中。
用戶行為數據:用戶在使用產品過程中,通過埋點收集與客戶端產品交互過程中產生的數據,并發往日志服務器進行保存。比如頁面瀏覽、點擊、停留、評論、點贊、收藏等。用戶行為數據通常存儲在日志文件中。
項目需求與架構設計
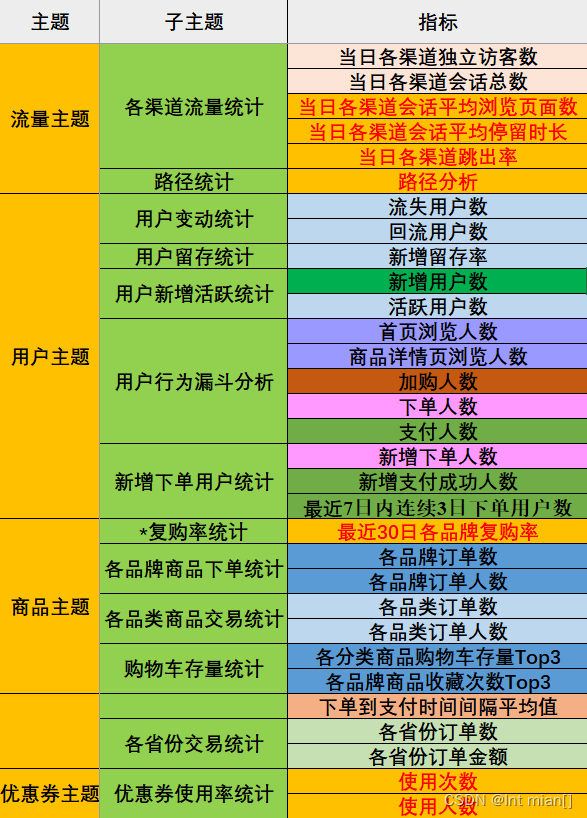
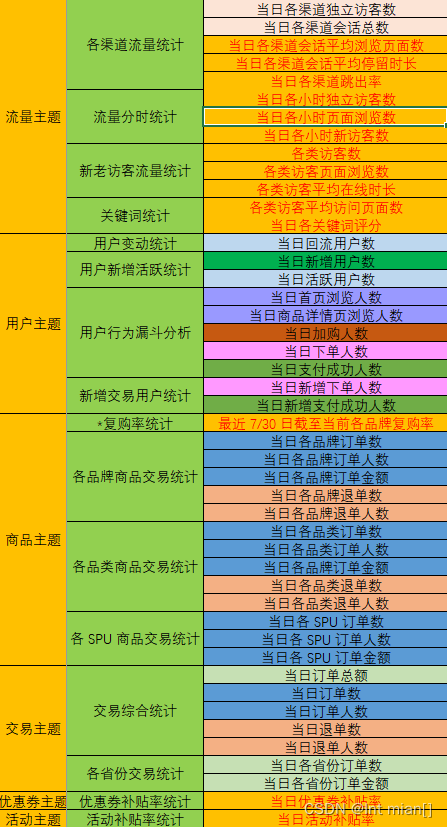
需求
?????? (1)用戶行為數據采集平臺搭建
?????? (2)業務數據采集平臺搭建
離線與實時采集需求
技術選型

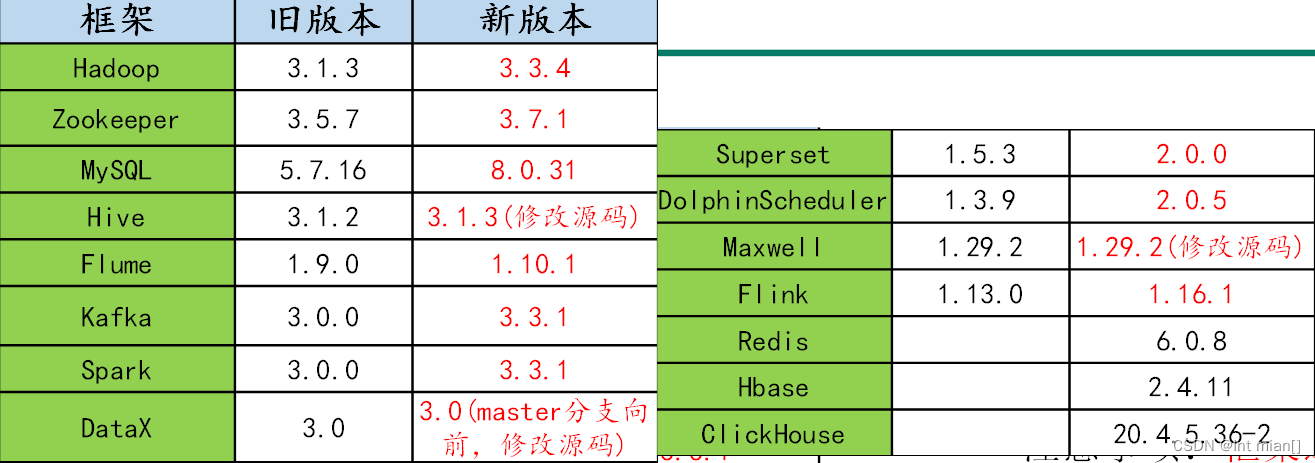
- Master節點:管理節點,保證集群的調度正常進行;主要部署NameNode、ResourceManager、HMaster 等進程;非 HA 模式下數量為1,HA 模式下數量為2。
- Core節點:為計算及存儲節點,您在 HDFS 中的數據全部存儲于 core 節點中,因此為了保證數據安全,擴容 core 節點后不允許縮容;主要部署 DataNode、NodeManager、RegionServer 等進程。非 HA 模式下數量≥2,HA 模式下數量≥3。
- Common 節點:為 HA 集群 Master 節點提供數據共享同步以及高可用容錯服務;主要部署分布式協調器組件,如 ZooKeeper、JournalNode 等節點。非HA模式數量為0,HA 模式下數量≥3。
| 服務名稱 | 子服務 | 服務器 hadoop102 | 服務器 hadoop103 | 服務器 hadoop104 |
| HDFS | NameNode | √ | ||
| DataNode | √ | √ | √ | |
| SecondaryNameNode | √ | |||
| Yarn | NodeManager | √ | √ | √ |
| Resourcemanager | √ | |||
| Zookeeper | Zookeeper Server | √ | √ | √ |
| Flume(采集日志) | Flume | √ | √ | |
| Kafka | Kafka | √ | √ | √ |
| Flume (消費Kafka日志) | Flume | √ | ||
| Flume (消費Kafka業務) | Flume | √ | ||
| Hive | √ | √ | √ | |
| MySQL | MySQL | √ | ||
| DataX | √ | √ | √ | |
| Spark | √ | √ | √ | |
| DolphinScheduler | ApiApplicationServer | √ | ||
| AlertServer | √ | |||
| MasterServer | √ | |||
| WorkerServer | √ | √ | √ | |
| LoggerServer | √ | √ | √ | |
| Superset | Superset | √ | ||
| Flink | √ | |||
| ClickHouse | √ | |||
| Redis | √ | |||
| Hbase | √ | |||
| 服務數總計 | 20 | 11 | 12 |
架構
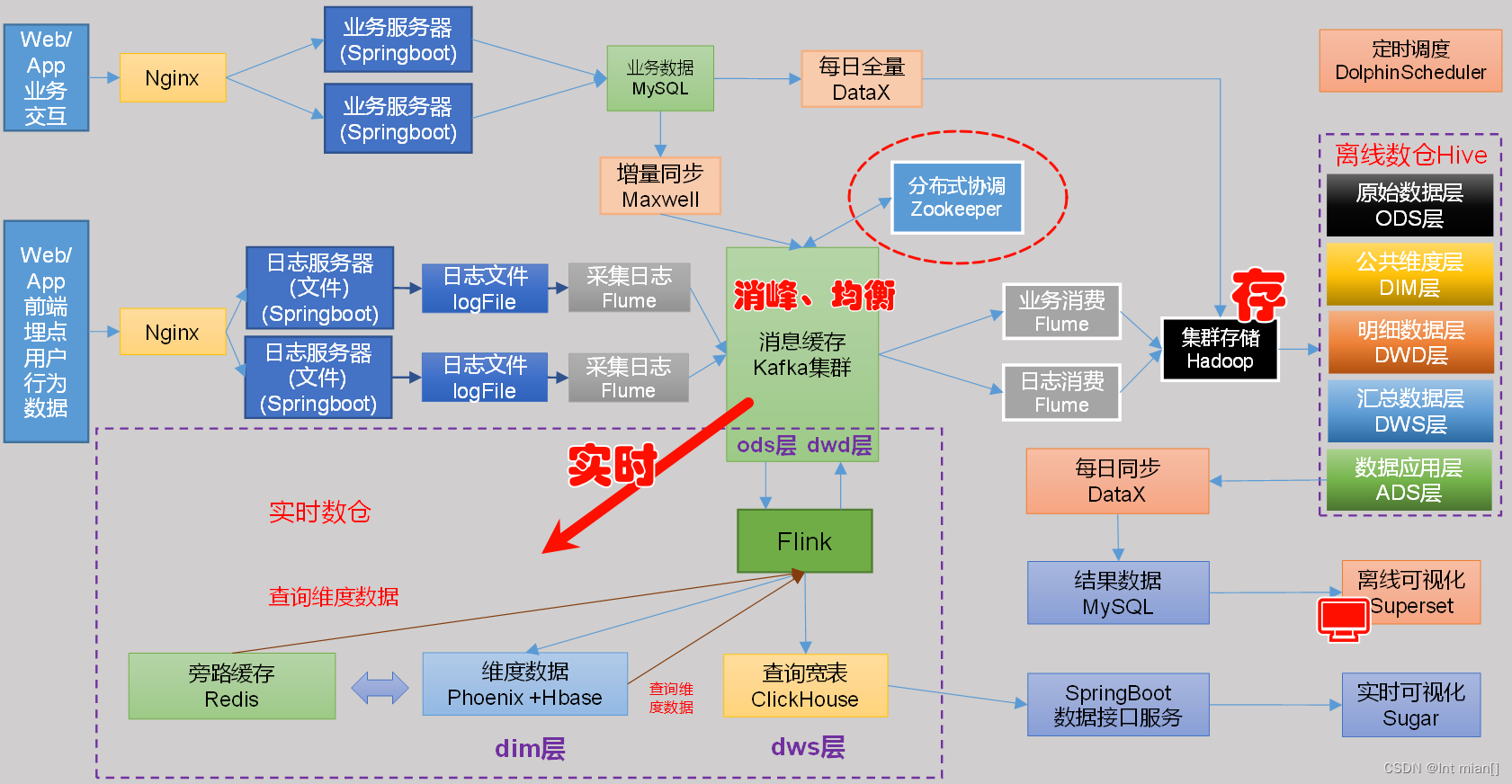
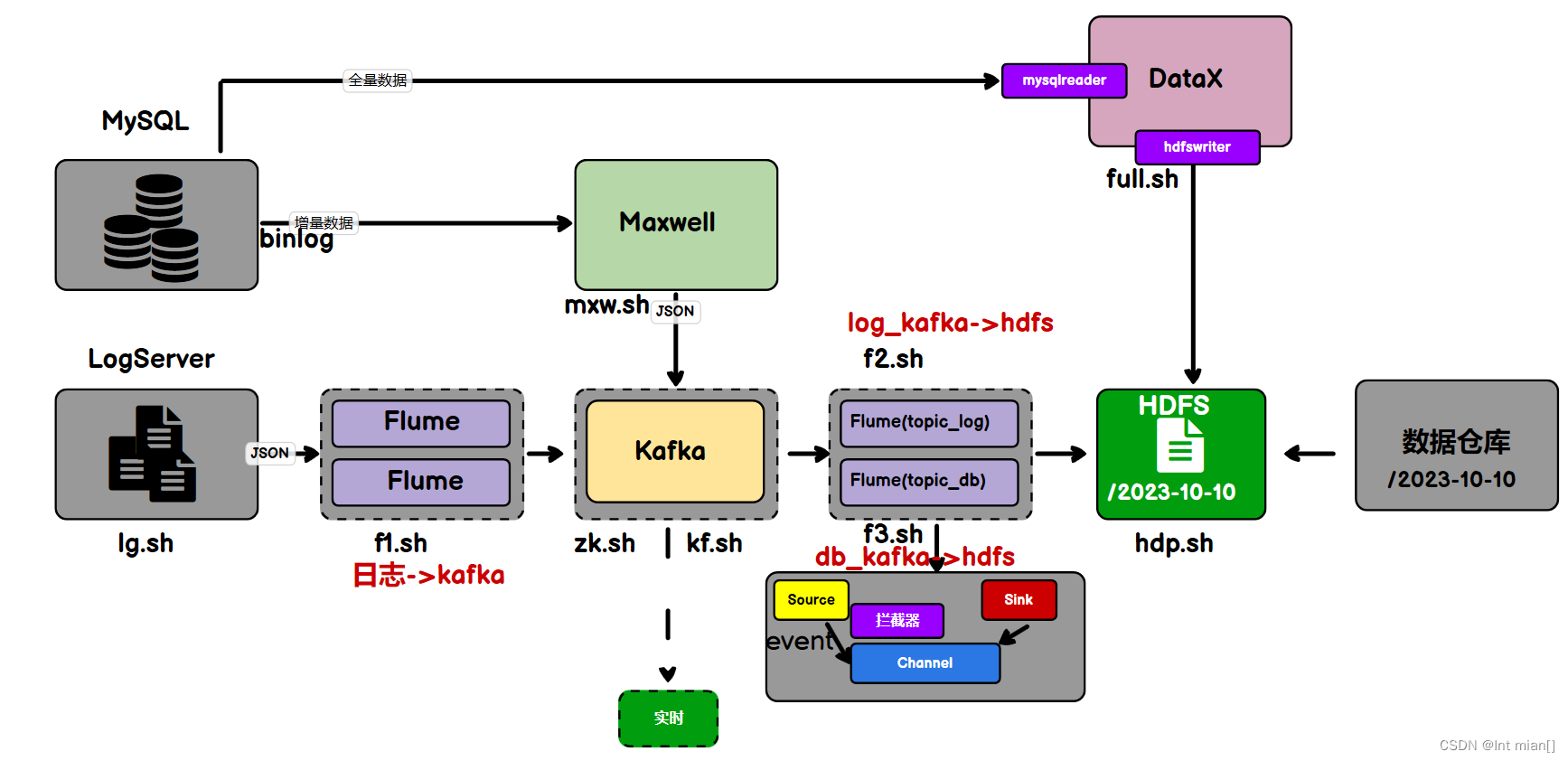
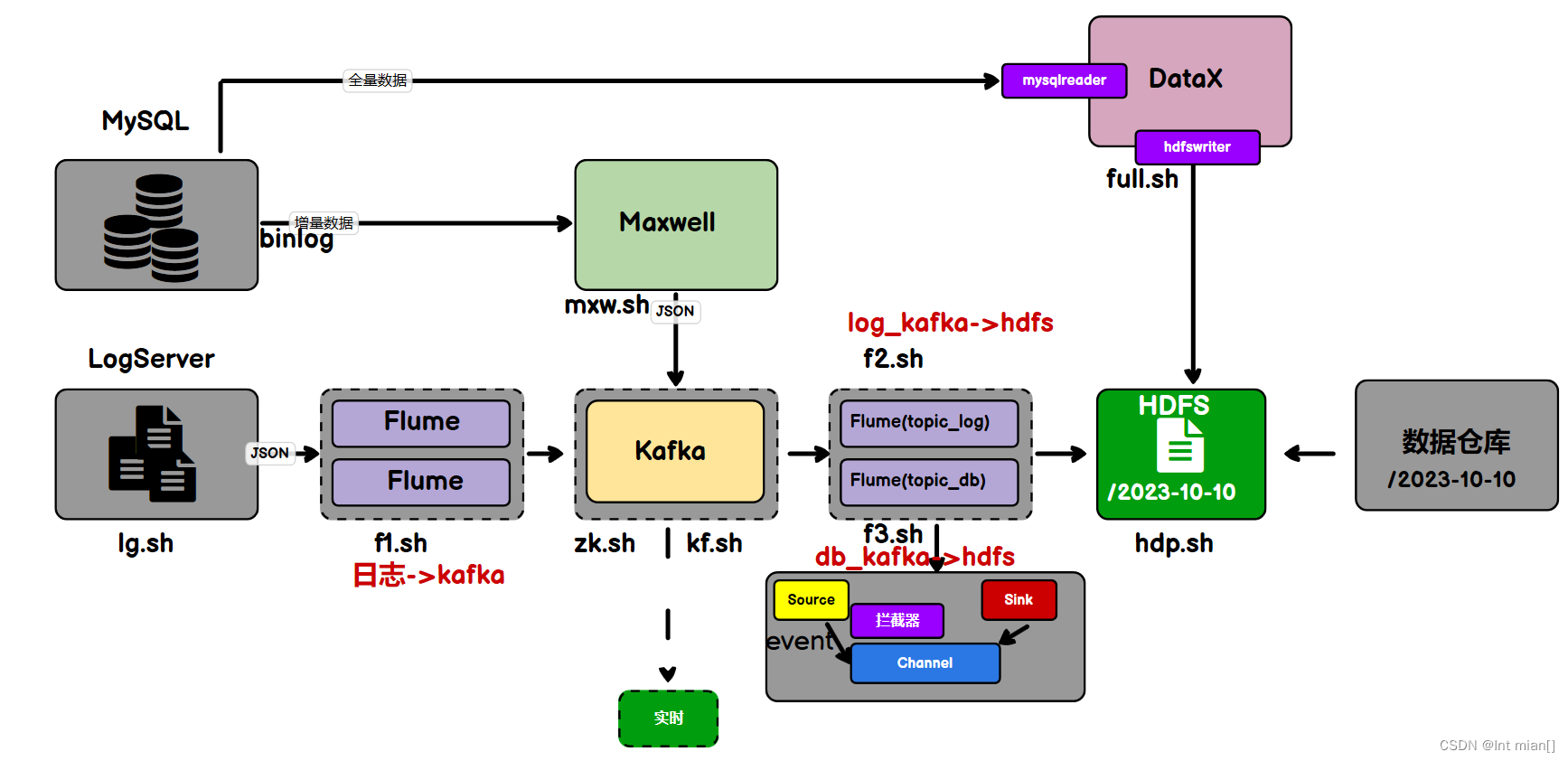
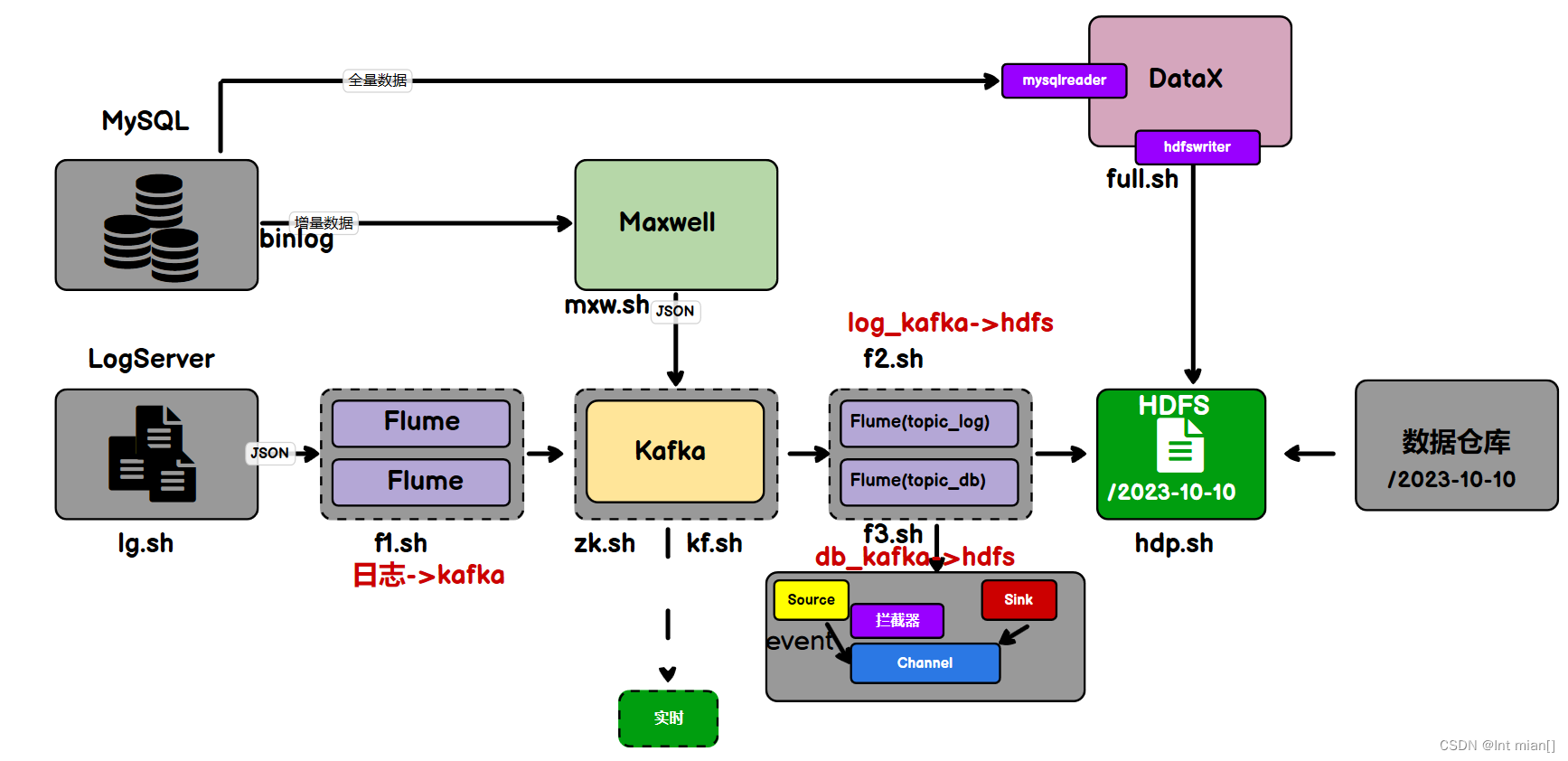
--- 回頭看整個采集大流程?---
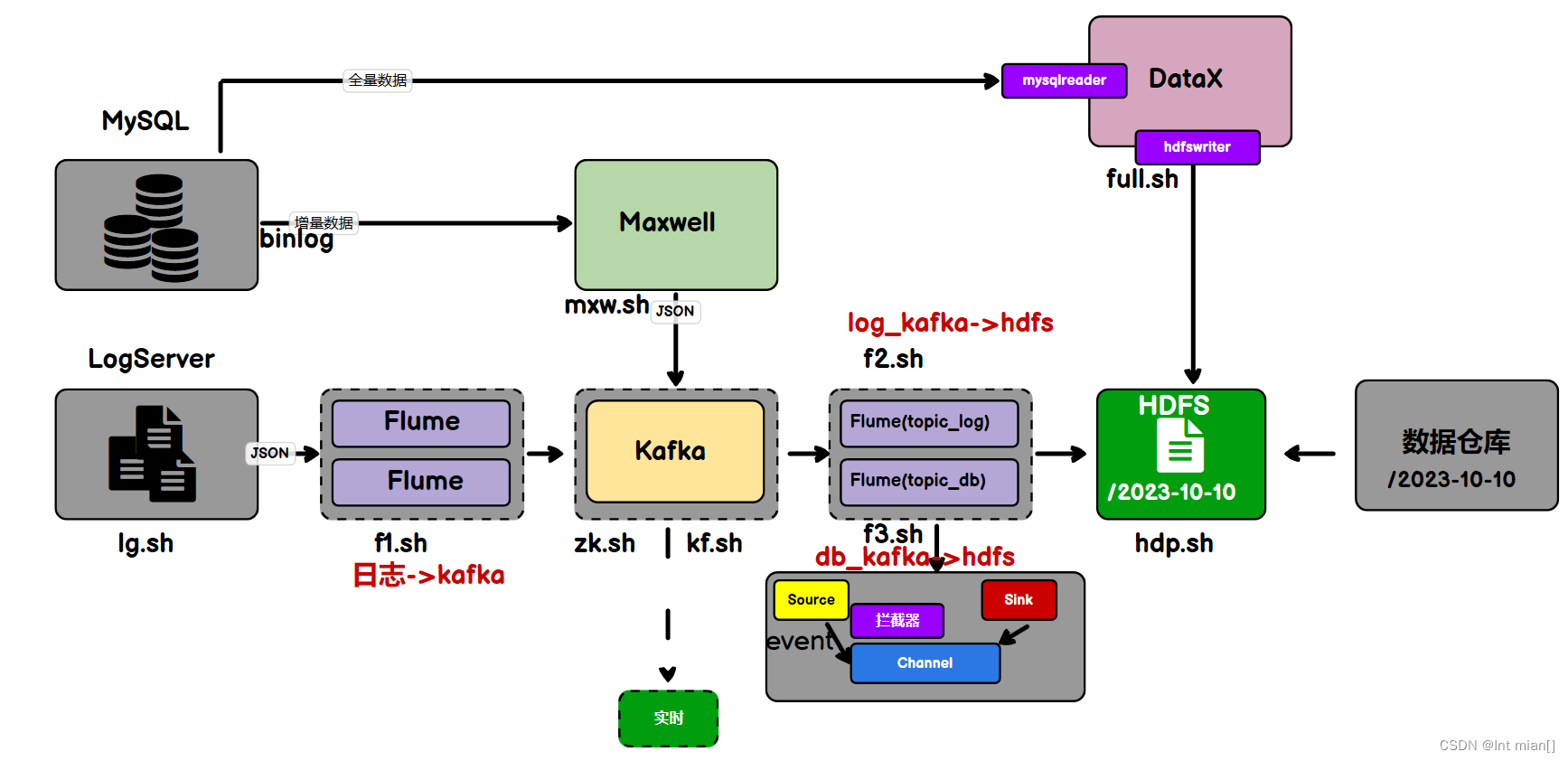
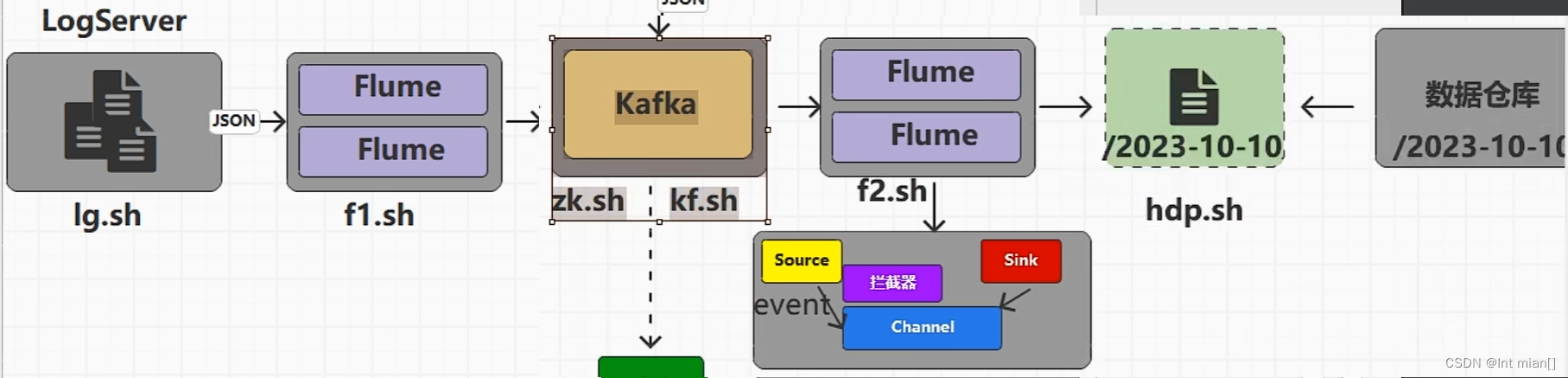
fl腳本將log采集到kafka,max將db增量采集到kafka,f2將log同步到dhfs,datax將db全量采集到hdfs,f3將db從kafka采集到hdfs
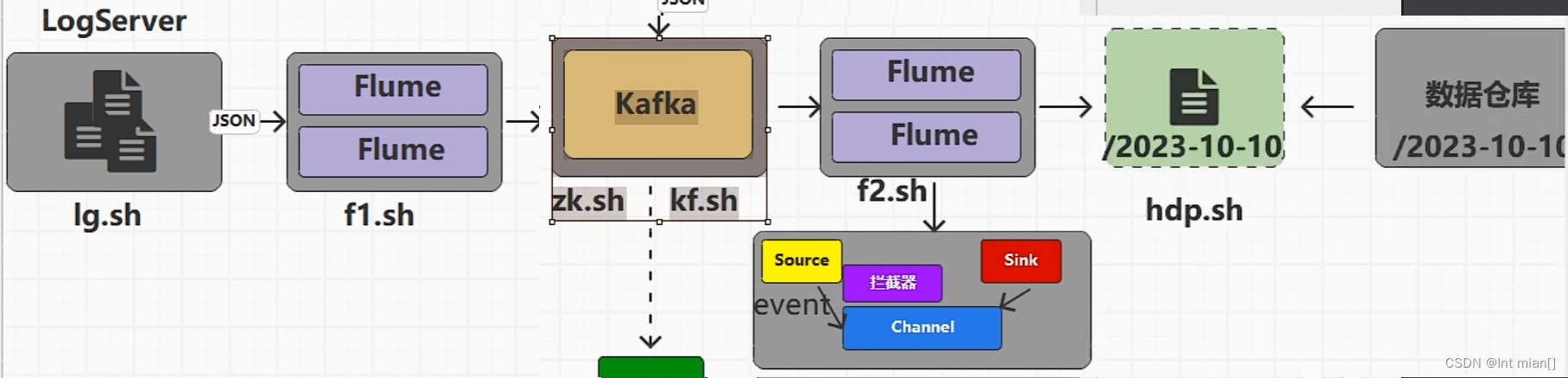
日志數據采集2Kafka
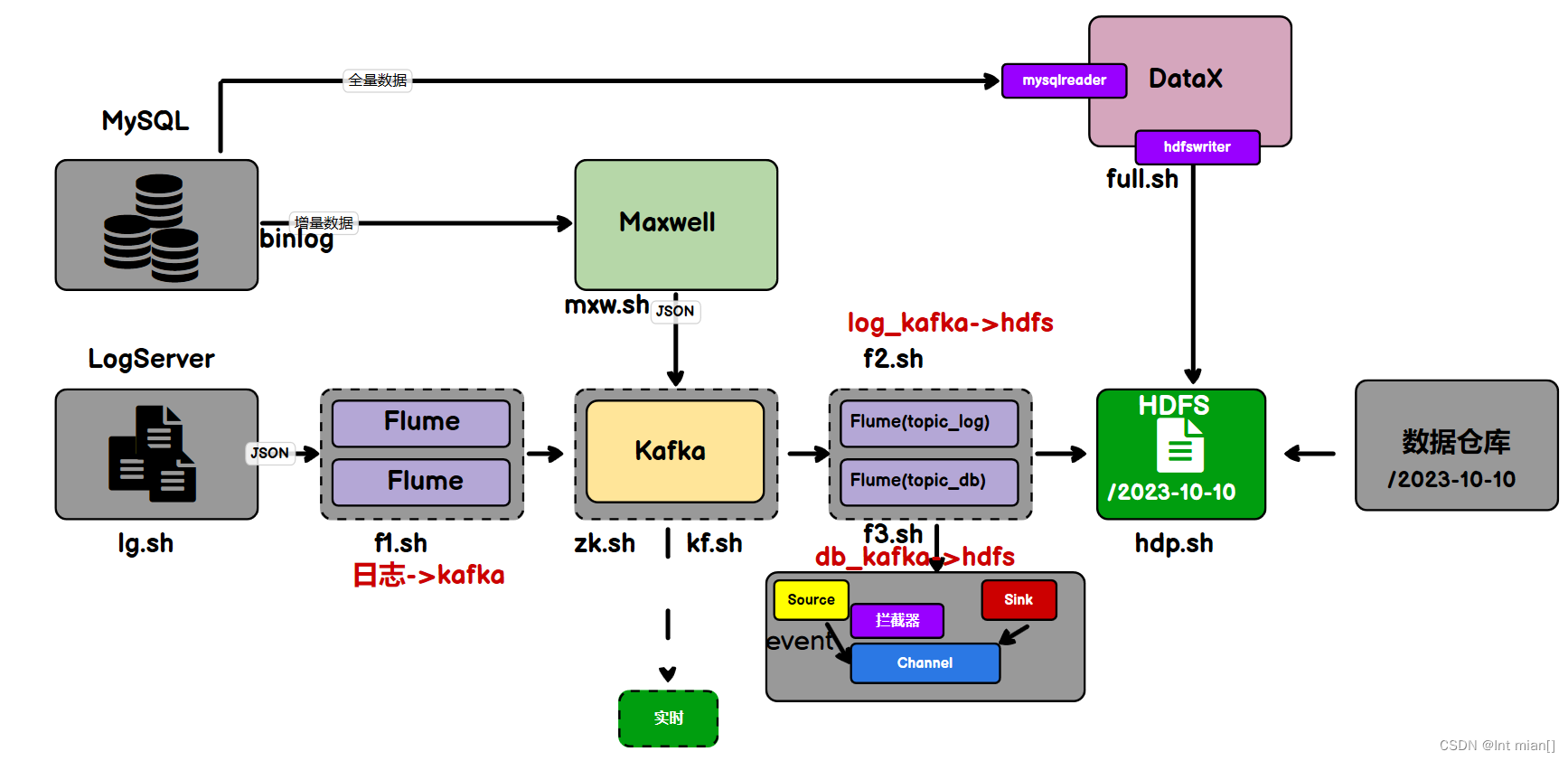
Logs(模擬生成)??Flume??Kafka????HDFS

?全套配置:?
數倉項目6.0配置大全(hadoop/Flume/zk/kafka/mysql配置)-CSDN博客
業務數據sql采集2Kafka
安裝maxwell增量采集工具
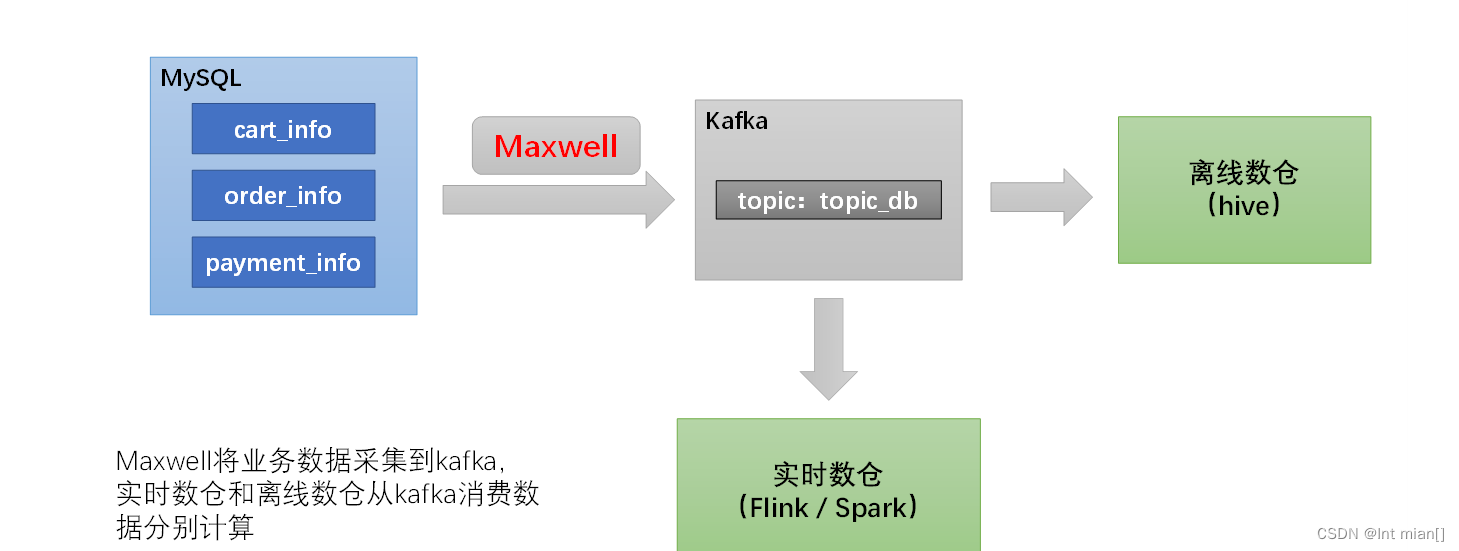
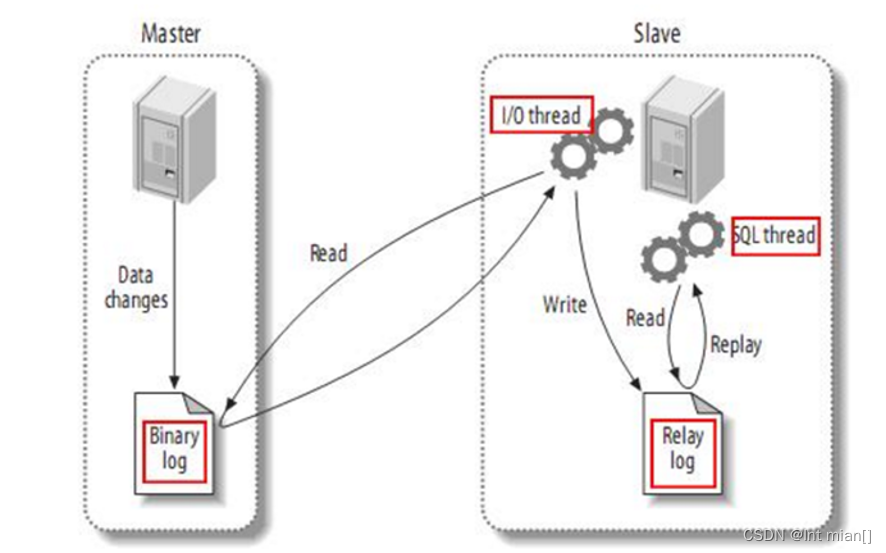
Maxwell 是由美國Zendesk公司開源,用Java編寫的MySQL變更數據抓取軟件。它會實時監控MySQL數據庫的數據變更操作(包括insert、update、delete),并將變更數據以 JSON 格式發送給 Kafka、Kinesi等流數據處理平臺
Maxwell的工作原理是實時讀取MySQL數據庫的二進制日志(Binlog),從中獲取變更數據,再將變更數據以JSON格式發送至Kafka等流處理平臺。
二進制日志(Binlog)是MySQL服務端非常重要的一種日志,它會保存MySQL數據庫的所有數據變更記錄。Binlog的主要作用包括主從復制和數據恢復。
Maxwell的工作原理和主從復制密切相關。
MySQL的主從復制,就是用來建立一個和主數據庫完全一樣的數據庫環境,這個數據庫稱為從數據庫。做數據庫的熱備、讀寫分離,在讀多寫少場景下,可以提高數據庫工作效率。
maxwell就是將自己偽裝成slave,并遵循MySQL主從復制的協議,從master同步數據。
https://github.com/zendesk/maxwell/releases/download/v1.29.2/maxwell-1.29.2.tar.gz
將安裝包解壓至/opt/module
MySQL服務器的Binlog默認是未開啟的,如需進行同步,需要先進行開啟
vim /etc/my.cnf
#數據庫id
server-id = 1
#啟動binlog,該參數的值會作為binlog的文件名
log-bin=mysql-bin
#binlog類型,maxwell要求為row類型
binlog_format=row
#啟用binlog的數據庫,需根據實際情況作出修改
binlog-do-db=gmall
重啟MySQL服務systemctl restart mysqld
Maxwell需要在MySQL中存儲其運行過程中的所需的一些數據,包括binlog同步的斷點位置(Maxwell支持斷點續傳)等等,故需要在MySQL為Maxwell創建數據庫及用戶。
CREATE DATABASE maxwell;CREATE USER 'maxwell'@'%' IDENTIFIED BY 'maxwell';
GRANT ALL ON maxwell.* TO 'maxwell'@'%';
GRANT SELECT, REPLICATION CLIENT, REPLICATION SLAVE ON *.* TO 'maxwell'@'%';修改Maxwell配置文件名稱
cd /opt/module/maxwell
cp config.properties.example?config.properties
vim config.properties
#Maxwell數據發送目的地,可選配置有stdout|file|kafka|kinesis|pubsub|sqs|rabbitmq|redis
producer=kafka
# 目標Kafka集群地址
kafka.bootstrap.servers=hadoop102:9092,hadoop103:9092,hadoop104:9092
#目標Kafka topic,可靜態配置,例如:maxwell,也可動態配置,例如:%{database}_%{table}
kafka_topic=topic_db
# MySQL相關配置
host=hadoop102
user=maxwell
password=maxwell
jdbc_options=useSSL=false&serverTimezone=Asia/Shanghai&allowPublicKeyRetrieval=true
# 過濾gmall中的z_log表數據,該表是日志數據的備份,無須采集
filter=exclude:gmall.z_log
# 指定數據按照主鍵分組進入Kafka不同分區,避免數據傾斜
producer_partition_by=primary_key
若Maxwell發送數據的目的地為Kafka集群,則需要先確保zk、Kafka集群為啟動狀態。
啟動腳本
#!/bin/bash
MAXWELL_HOME=/opt/module/maxwell
status_maxwell(){result=`ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | wc -l`return $result
}start_maxwell(){status_maxwellif [[ $? -lt 1 ]]; thenecho "啟動Maxwell"$MAXWELL_HOME/bin/maxwell --config $MAXWELL_HOME/config.properties --daemonelseecho "Maxwell正在運行"fi
}stop_maxwell(){status_maxwellif [[ $? -gt 0 ]]; thenecho "停止Maxwell"ps -ef | grep com.zendesk.maxwell.Maxwell | grep -v grep | awk '{print $2}' | xargs kill -9elseecho "Maxwell未在運行"fi
}case $1 instart )start_maxwell;;stop )stop_maxwell;;restart )stop_maxwellstart_maxwell;;
esac
啟動后,進行數據庫的修改,手動改一個數、運行lg使用jar包向數據庫中添加內容,都會引起maxwell寫入kafka
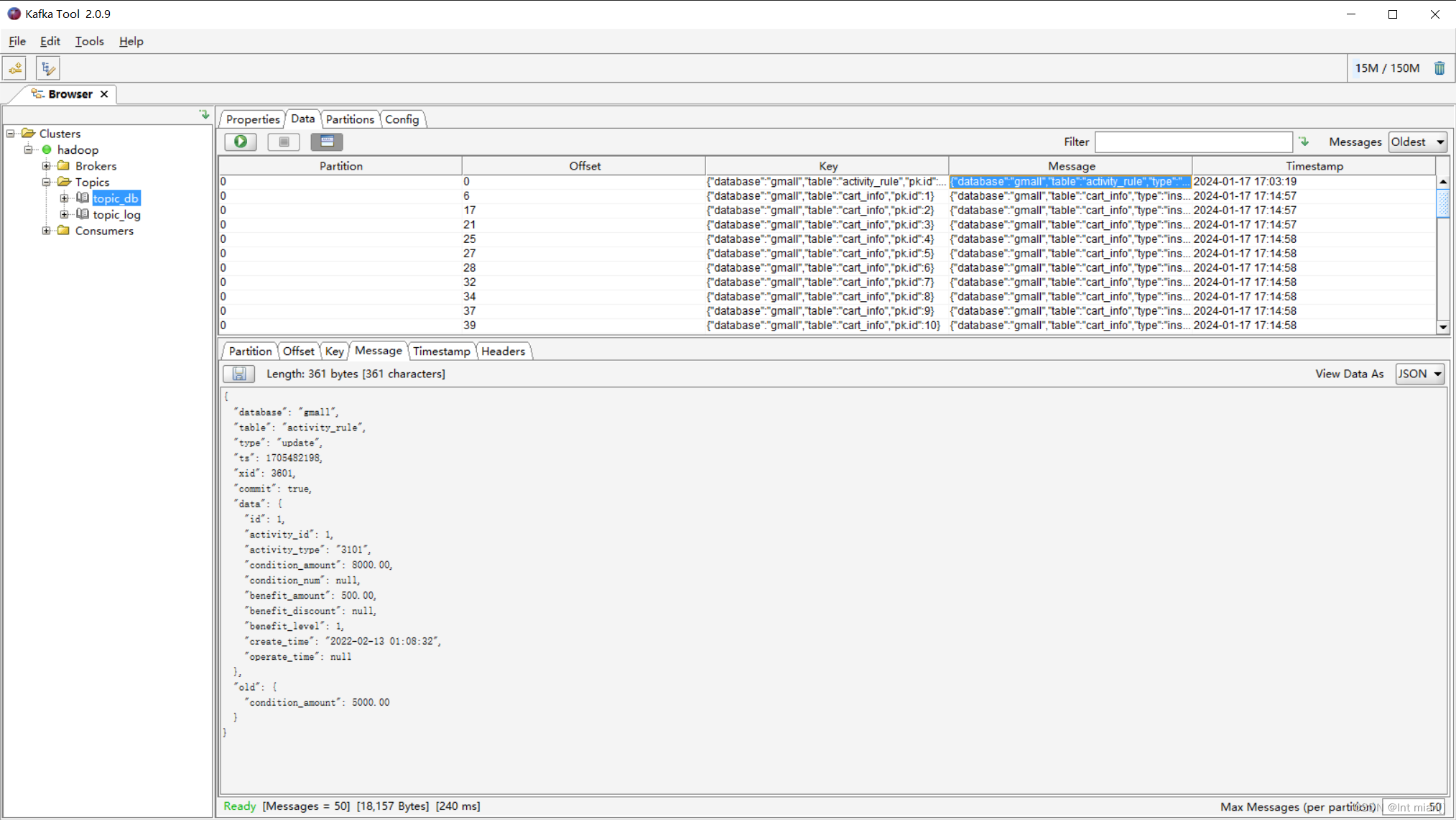
歷史數據全量同步
可能需要使用到MySQL數據庫中從歷史至今的一個完整的數據集。這就需要我們在進行增量同步之前,先進行一次歷史數據的全量同步。這樣就能保證得到一個完整的數據集。
Maxwell提供了bootstrap功能來進行歷史數據的全量同步,命令如下:
/opt/module/maxwell/bin/maxwell-bootstrap
--database gmall
--table activity_info
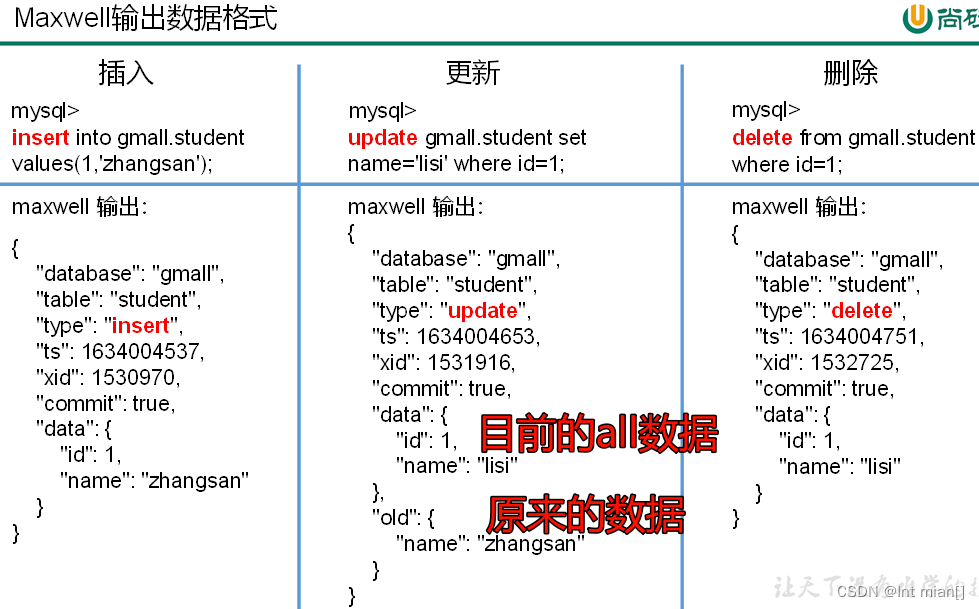
--config /opt/module/maxwell/config.properties采用bootstrap方式同步的輸出數據格式如下,注意?"type": "bootstrap-start","type": "bootstrap-complete",
{"database": "gmall","table": "activity_info","type": "bootstrap-start","ts": 1705484093,"data": {}
}
{"database": "gmall","table": "activity_info","type": "bootstrap-insert","ts": 1705484093,"data": {"id": 4,"activity_name": "TCL全場9折","activity_type": "3103","activity_desc": "TCL全場9折","start_time": "2022-01-13 01:01:54","end_time": "2023-06-19 00:00:00","create_time": "2022-05-27 00:00:00","operate_time": null}
}
······
{"database": "gmall","table": "activity_info","type": "bootstrap-complete","ts": 1705484093,"data": {}
}日志數據同步2HDFS
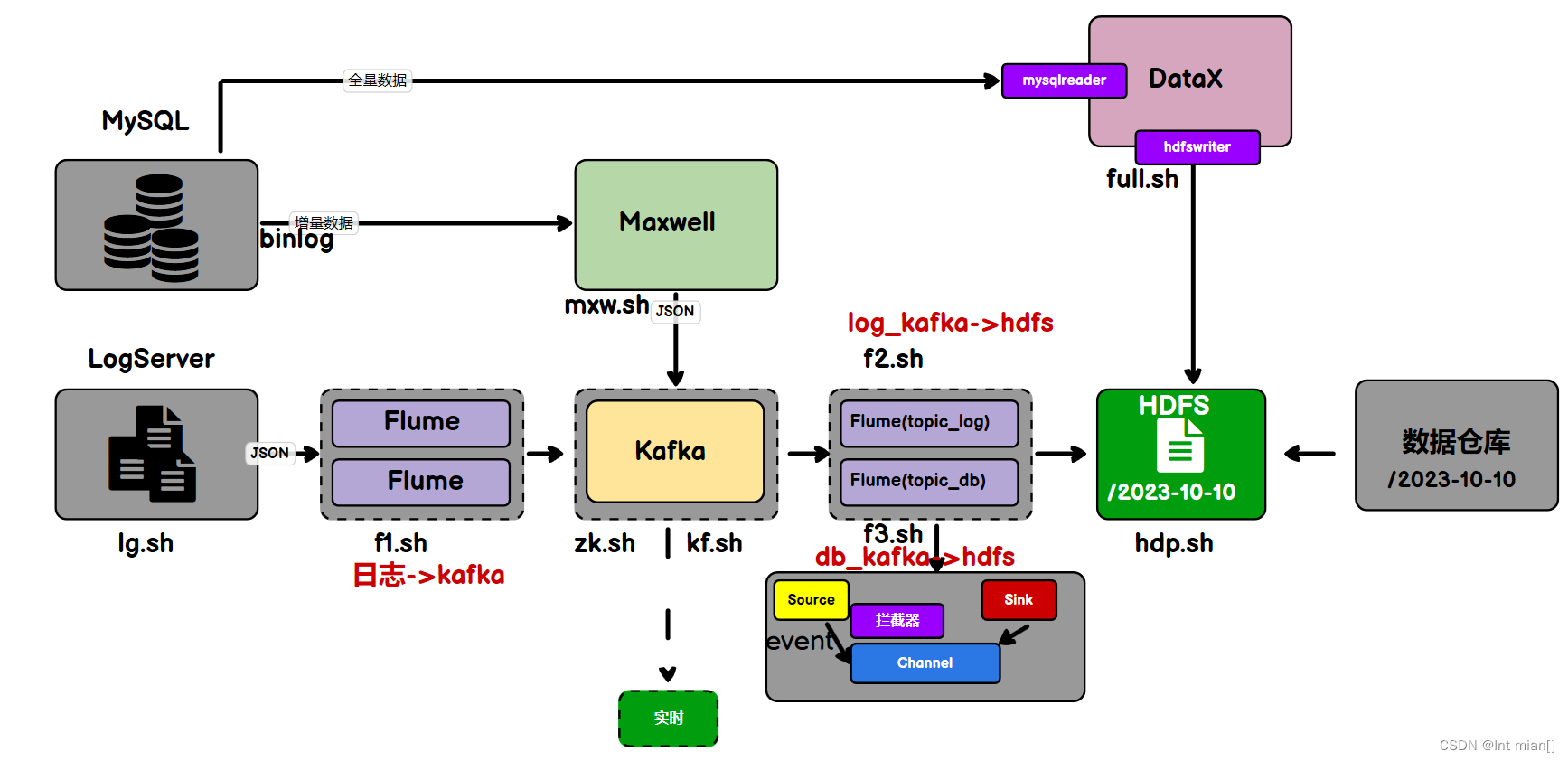
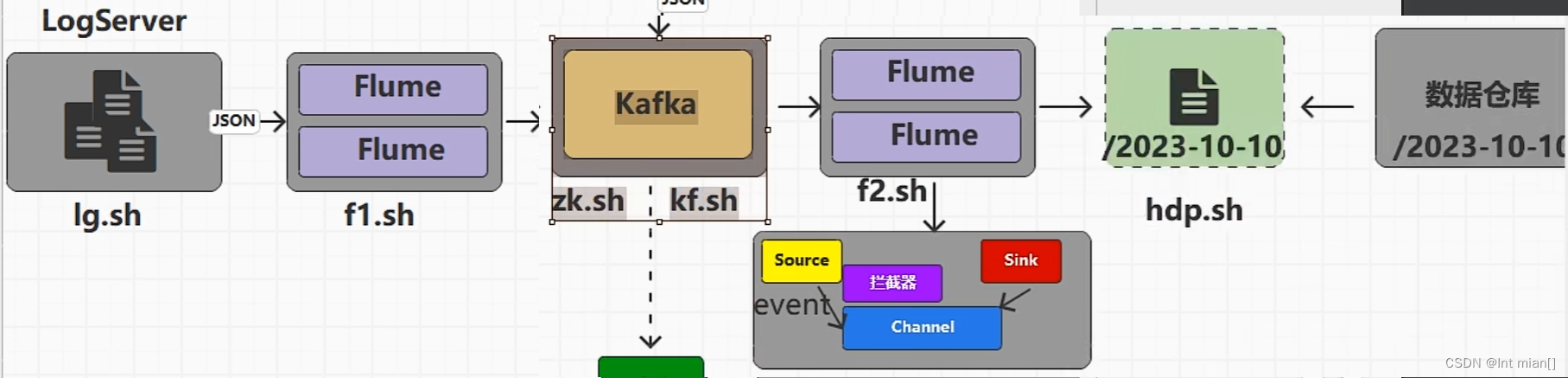
實時數倉由Flink源源不斷從Kafka當中讀數據計算,所以不需要手動同步數據到實時數倉。
用戶行為數據由Flume從Kafka直接同步到HDFS,由于離線數倉采用Hive的分區表按天統計,所以目標路徑要包含一層日期。具體數據流向如下圖所示。
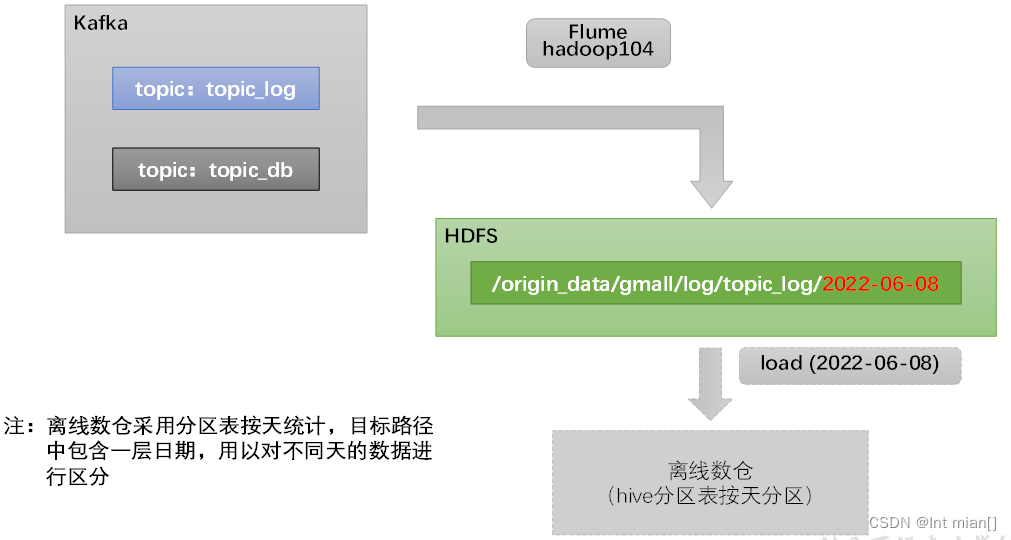
按照規劃,該Flume需將Kafka中topic_log的數據發往HDFS。并且對每天產生的用戶行為日志進行區分,將不同天的數據發往HDFS不同天的路徑。
此處選擇KafkaSource、FileChannel、HDFSSink。
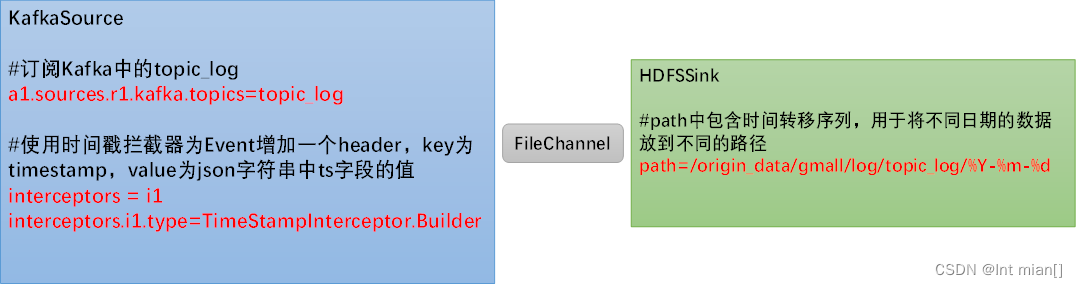
#定義組件
a1.sources=r1
a1.channels=c1
a1.sinks=k1#配置source1
a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092,hadoop104:9092
a1.sources.r1.kafka.topics=topic_log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampInterceptor$Builder#配置channel
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior1
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior1
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6#配置sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/log/topic_log/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = log
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0#控制輸出文件類型
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip#組裝
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1零點漂移問題
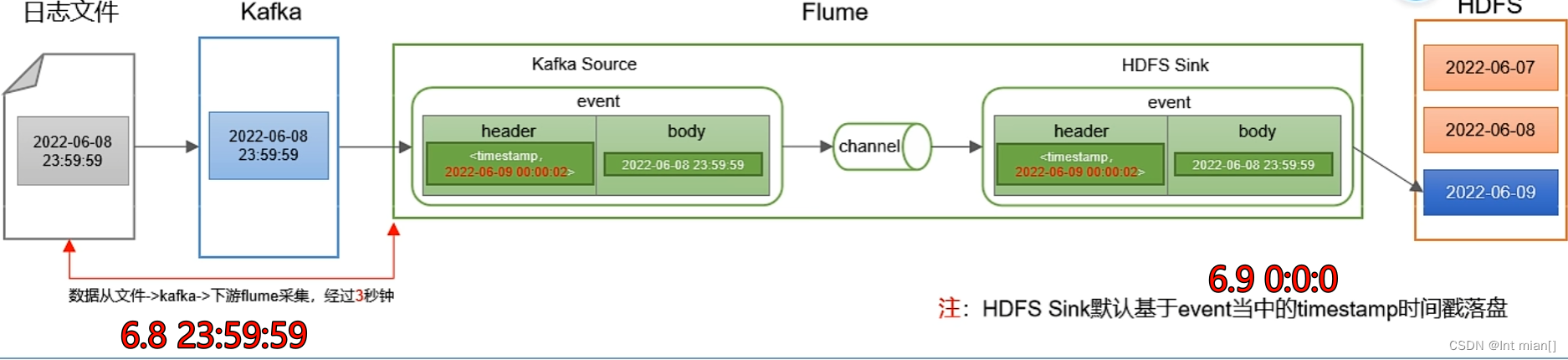
這里就是Flume配置job文件中,在源處加自定義攔截器 的 原因
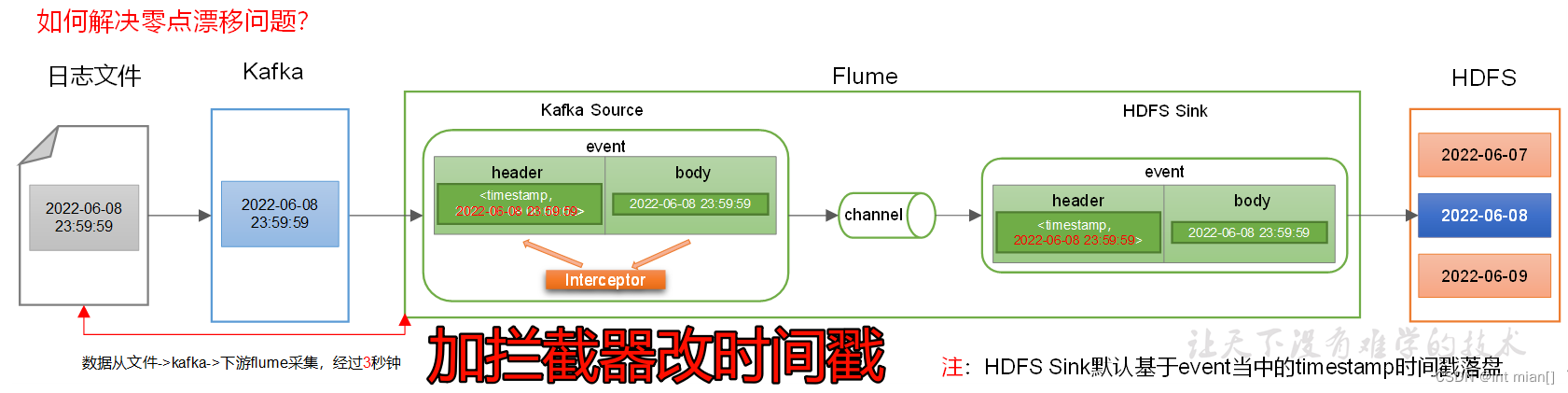
攔截器jar包
生成jar包,放到flume的lib下,jar包的java文件存放路徑要和job中那個攔截器路徑一致,然后溝通Kafka-flume-hdfs
package com.atguigu.gmall.flume.interceptor;import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;
import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import java.nio.charset.StandardCharsets;
import java.util.Iterator;import java.util.List;
import java.util.Map;public class TimestampInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {//1、獲取header和body的數據Map<String, String> headers = event.getHeaders();String log = new String(event.getBody(), StandardCharsets.UTF_8);try {//2、將body的數據類型轉成jsonObject類型(方便獲取數據)JSONObject jsonObject = JSONObject.parseObject(log);//3、header中timestamp時間字段替換成日志生成的時間戳(解決數據漂移問題)String ts = jsonObject.getString("ts");headers.put("timestamp", ts);return event;} catch (Exception e) {e.printStackTrace();return null;}}@Overridepublic List<Event> intercept(List<Event> list) {Iterator<Event> iterator = list.iterator();while (iterator.hasNext()) {Event event = iterator.next();if (intercept(event) == null) {iterator.remove();}}return list;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampInterceptor();}public void configure(Context context) {}}}
<dependencies><dependency><groupId>org.apache.flume</groupId><artifactId>flume-ng-core</artifactId><version>1.10.1</version><scope>provided</scope></dependency><dependency><groupId>com.alibaba</groupId><artifactId>fastjson</artifactId><version>1.2.62</version></dependency></dependencies><build><plugins><plugin><artifactId>maven-compiler-plugin</artifactId><version>2.3.2</version><configuration><source>1.8</source><target>1.8</target></configuration></plugin><plugin><artifactId>maven-assembly-plugin</artifactId><configuration><descriptorRefs><descriptorRef>jar-with-dependencies</descriptorRef></descriptorRefs></configuration><executions><execution><id>make-assembly</id><phase>package</phase><goals><goal>single</goal></goals></execution></executions></plugin></plugins></build>同步!
先把日志/opt/module/applog/log清空,kafka清空
啟動zk、kafka、hadoop、f1(日志到kafka)、f2(kafka到hdfs),然后生成模擬日志數據就行了
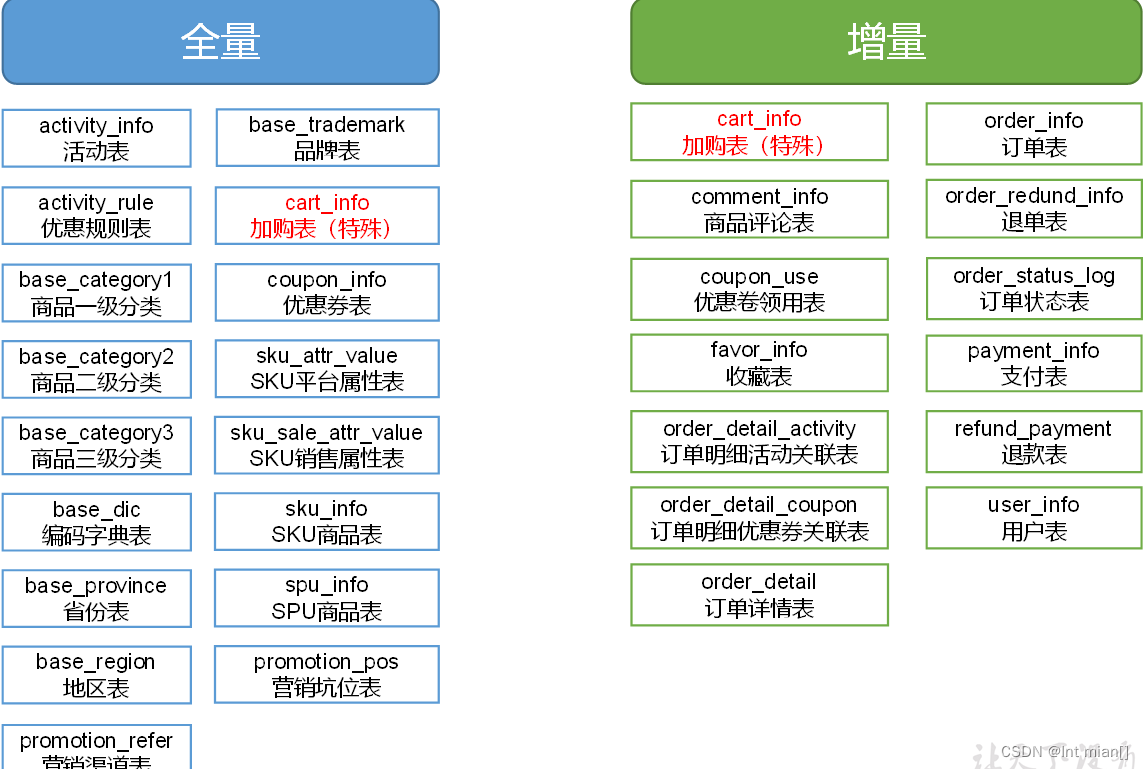
全量還是增量
通常情況,業務表數據量比較大,變動頻繁,優先考慮增量,數據量比較小,不怎么變動,優先考慮全量
數據同步工具種類繁多,大致可分為兩類,一類是以DataX、Sqoop為代表的基于Select查詢的離線、批量同步工具,另一類是以Maxwell、Canal為代表的基于數據庫數據變更日志(例如MySQL的binlog,其會實時記錄所有的insert、update以及delete操作)的實時流式同步工具。
全量同步采用DataX,增量同步采用Maxwell。
安裝DataX
https://github.com/alibaba/DataX?tab=readme-ov-file
DataX 是阿里巴巴開源的一個異構數據源離線同步工具,致力于實現包括關系型數據庫(MySQL、Oracle等)、HDFS、Hive、ODPS、HBase、FTP等各種異構數據源之間穩定高效的數據同步功能。
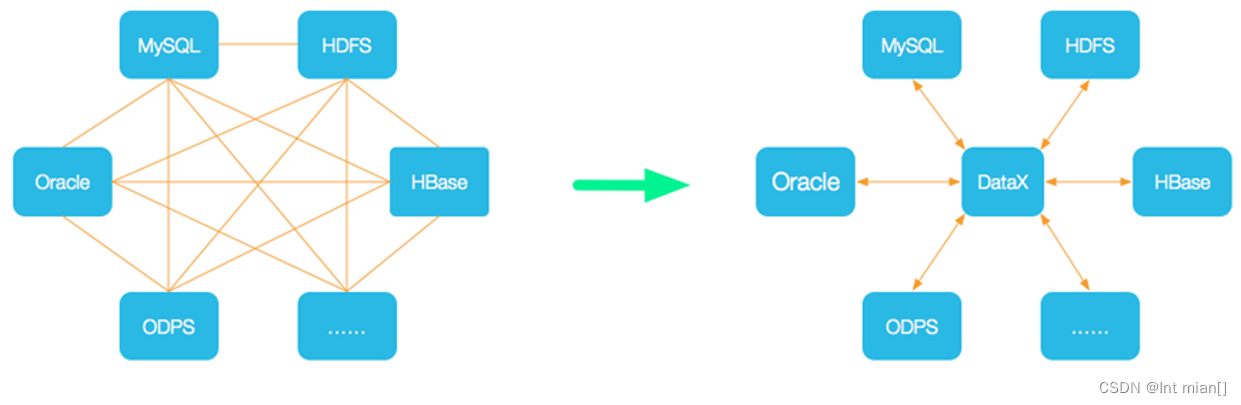
DataX的使用,用戶只需根據數據的數據源和目的地選擇相應的Reader和Writer,并將Reader和Writer的信息配置在一個json文件中,然后執行如下命令提交數據同步任務即可。
可以使用如下命名查看DataX配置文件模板
python bin/datax.py -r mysqlreader -w hdfswriterTableMode
同步gmall數據庫中base_province表數據到HDFS的/base_province目錄
要實現該功能,需選用MySQLReader和HDFSWriter,MySQLReader具有兩種模式分別是TableMode和QuerySQLMode,前者使用table,column,where等屬性聲明需要同步的數據;后者使用一條SQL查詢語句聲明需要同步的數據。
vim /opt/module/datax/job/base_province.json
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"column": ["id","name","region_id","area_code","iso_code","iso_3166_2","create_time","operate_time"],"where": "id>=3","connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8"],"table": ["base_province"]}],"password": "000000","splitPk": "","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"},{"name": "create_time","type": "string"},{"name": "operate_time","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}HFDS Writer并未提供nullFormat參數:也就是用戶并不能自定義null值寫到HFDS文件中的存儲格式。默認情況下,HFDS Writer會將null值存儲為空字符串(''),而Hive默認的null值存儲格式為\N。所以后期將DataX同步的文件導入Hive表就會出現問題。
創建hdfs中的目錄
hadoop fs -mkdir /base_province
運行
python bin/datax.py job/base_province.json
查看gz
hadoop fs -cat /base_province/* | zca
QuerySQLMode
{"job": {"content": [{"reader": {"name": "mysqlreader","parameter": {"connection": [{"jdbcUrl": ["jdbc:mysql://hadoop102:3306/gmall?useUnicode=true&allowPublicKeyRetrieval=true&characterEncoding=utf-8"],"querySql": ["select id,name,region_id,area_code,iso_code,iso_3166_2,create_time,operate_time from base_province where id>=3"]}],"password": "000000","username": "root"}},"writer": {"name": "hdfswriter","parameter": {"column": [{"name": "id","type": "bigint"},{"name": "name","type": "string"},{"name": "region_id","type": "string"},{"name": "area_code","type": "string"},{"name": "iso_code","type": "string"},{"name": "iso_3166_2","type": "string"},{"name": "create_time","type": "string"},{"name": "operate_time","type": "string"}],"compress": "gzip","defaultFS": "hdfs://hadoop102:8020","fieldDelimiter": "\t","fileName": "base_province","fileType": "text","path": "/base_province","writeMode": "append"}}}],"setting": {"speed": {"channel": 1}}}
}傳參
DataX配置文件中HDFS Writer的path參數的值應該是動態的。為實現這一效果,就需要使用DataX傳參的功能。
DataX傳參的用法如下,在JSON配置文件中使用${param}引用參數,在提交任務時使用-p"-Dparam=value"傳入參數值,具體示例如下。
"path": "/base_province/${dt}",
創建文件夾
hadoop fs -mkdir /base_province/2022-06-08
運行
python bin/datax.py -p"-Ddt=2022-06-08" job/base_province.json
sql2hdfs全量同步
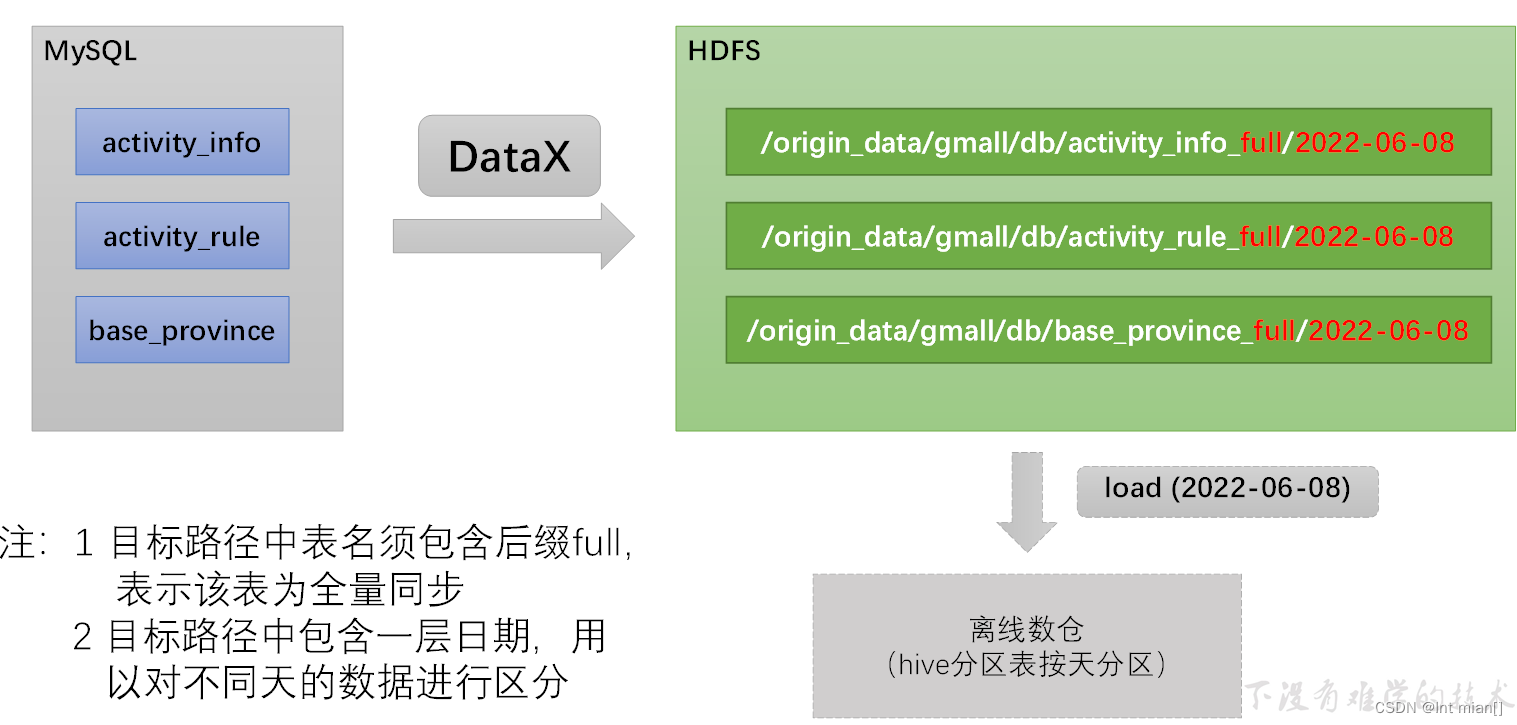
需要為每張全量表編寫一個DataX的json配置文件
寫了一個腳本,流程不難但繁瑣,建議回去看尚硅谷的資料
大致流程梳理:
目的是把數據庫全量同步到hdfs,那么準備好datax配置文件json。
從資料里拉了個配置文件json生成器,一下就生成了所有要導的表的json。
然后寫了一個腳本,執行mysql_to_hdfs_full.sh all 2022-06-08
慢慢等。。。。。。。。。。17張表導入
業務數據sql2hdfs增量同步?
通過maxwell和flume

Flume需要將Kafka中topic_db主題的數據傳輸到HDFS,故其需選用KafkaSource以及HDFSSink,Channel選用FileChannel。
需要注意的是, HDFSSink需要將不同MySQL業務表的數據寫到不同的路徑,并且路徑中應當包含一層日期,用于區分每天的數據。關鍵配置如下:
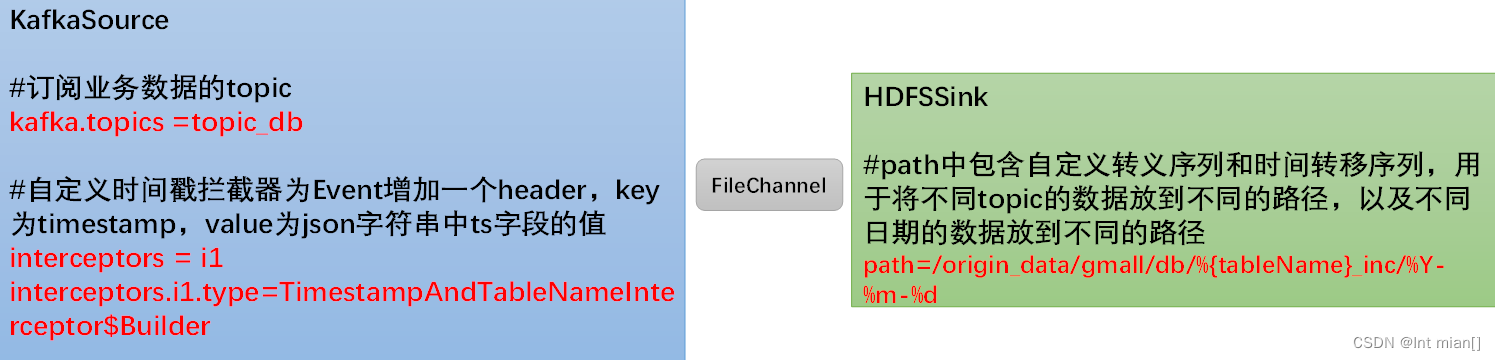
vim job/kafka_to_hdfs_db.conf
a1.sources = r1
a1.channels = c1
a1.sinks = k1a1.sources.r1.type = org.apache.flume.source.kafka.KafkaSource
a1.sources.r1.batchSize = 5000
a1.sources.r1.batchDurationMillis = 2000
a1.sources.r1.kafka.bootstrap.servers = hadoop102:9092,hadoop103:9092
a1.sources.r1.kafka.topics = topic_db
a1.sources.r1.kafka.consumer.group.id = flume
a1.sources.r1.setTopicHeader = true
a1.sources.r1.topicHeader = topic
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = com.atguigu.gmall.flume.interceptor.TimestampAndTableNameInterceptor$Buildera1.channels.c1.type = file
a1.channels.c1.checkpointDir = /opt/module/flume/checkpoint/behavior2
a1.channels.c1.dataDirs = /opt/module/flume/data/behavior2/
a1.channels.c1.maxFileSize = 2146435071
a1.channels.c1.capacity = 1000000
a1.channels.c1.keep-alive = 6
## sink1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = /origin_data/gmall/db/%{tableName}_inc/%Y-%m-%d
a1.sinks.k1.hdfs.filePrefix = db
a1.sinks.k1.hdfs.round = falsea1.sinks.k1.hdfs.rollInterval = 10
a1.sinks.k1.hdfs.rollSize = 134217728
a1.sinks.k1.hdfs.rollCount = 0a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = gzip## 拼裝
a1.sources.r1.channels = c1
a1.sinks.k1.channel= c1編寫Flume攔截器
在com.atguigu.gmall.flume.interceptor包下創建TimestampAndTableNameInterceptor類
package com.atguigu.gmall.flume.interceptor;import com.alibaba.fastjson.JSONObject;
import org.apache.flume.Context;
import org.apache.flume.Event;
import org.apache.flume.interceptor.Interceptor;import java.nio.charset.StandardCharsets;
import java.util.List;
import java.util.Map;public class TimestampAndTableNameInterceptor implements Interceptor {@Overridepublic void initialize() {}@Overridepublic Event intercept(Event event) {Map<String, String> headers = event.getHeaders();String log = new String(event.getBody(), StandardCharsets.UTF_8);JSONObject jsonObject = JSONObject.parseObject(log);Long ts = jsonObject.getLong("ts");//Maxwell輸出的數據中的ts字段時間戳單位為秒,Flume HDFSSink要求單位為毫秒String timeMills = String.valueOf(ts * 1000);String tableName = jsonObject.getString("table");headers.put("timestamp", timeMills);headers.put("tableName", tableName);return event;}@Overridepublic List<Event> intercept(List<Event> events) {for (Event event : events) {intercept(event);}return events;}@Overridepublic void close() {}public static class Builder implements Interceptor.Builder {@Overridepublic Interceptor build() {return new TimestampAndTableNameInterceptor ();}@Overridepublic void configure(Context context) {}}
}
重新打包,放到flume/lib中
為方便使用,此處編寫一個Flume的啟停腳本。
vim f3
#!/bin/bashcase $1 in "start")echo " --------啟動 hadoop104 業務數據flume-------"ssh hadoop104 "nohup /opt/module/flume/bin/flume-ng agent -n a1 -c /opt/module/flume/conf -f /opt/module/flume/job/kafka_to_hdfs_db.conf >/dev/null 2>&1 &" ;;"stop")echo " --------停止 hadoop104 業務數據flume-------"ssh hadoop104 "ps -ef | grep kafka_to_hdfs_db | grep -v grep |awk '{print \$2}' | xargs -n1 kill" ;; esac
DataX同步不常變數據,maxwell增量全量同步常變業務數據!!!!
增量表首日全量同步
通常情況下,增量表需要在首日進行一次全量同步,后續每日再進行增量同步,首日全量同步可以使用Maxwell的bootstrap功能,方便起見,下面編寫一個增量表首日全量同步腳本。
vim mysql_to_kafka_inc_init.sh
#!/bin/bash# 該腳本的作用是初始化所有的增量表,只需執行一次
MAXWELL_HOME=/opt/module/maxwellimport_data() {$MAXWELL_HOME/bin/maxwell-bootstrap --database gmall --table $1 --config $MAXWELL_HOME/config.properties}
case $1 in
"cart_info")import_data cart_info;;"all")import_data cart_infoimport_data comment_infoimport_data coupon_useimport_data favor_infoimport_data order_detailimport_data order_detail_activityimport_data order_detail_couponimport_data order_infoimport_data order_refund_infoimport_data order_status_logimport_data payment_infoimport_data refund_paymentimport_data user_info;;
esac
現將HDFS上之前同步的增量表數據刪除。
hadoop fs -ls /origin_data/gmall/db | grep _inc | awk '{print $8}' | xargs hadoop fs -rm -r -f
mysql_to_kafka_inc_init.sh all
觀察HDFS上是否重新出現增量表數據。




)


。Javaee項目,springboot項目。)







1------遞歸)



