文章目錄
- 摘要
- 1. 前言
- 2. 相關工作
- Transformers
- DDPMs
- 架構復雜度
- 3. 擴散Transformer
- 3.1 準備知識
- 擴散公式
- Classifier-free Guidance
- LDMs
- 3.2. Diffusion Transformer Design Space
- Patch化
- DiT模塊設計
- 模型大小
- Transformer Decoder
- 4. 實驗設置
- 訓練
- 擴散
- 評估指標
- 計算
- 5. 實驗
- DiT block 設計
- 模型大小和patch大小
- DiT Gflops 對改進模型很重要
- 更大的 DiT 模型計算效率更高
- 縮放可視化
- 5.1. State-of-the-Art Diffusion Models
- 256*256 ImageNet
- 512*512 ImageNet
- 5.2. Scaling Model vs. Sampling Compute
- 總結
- 參考資料
《Scalable Diffusion Models with Transformers》
《基于transformer的可擴展擴散模型》
論文地址:
https://arxiv.org/pdf/2212.09748.pdf
項目地址:
https://github.com/facebookresearch/DiT
摘要
論文提出了一類使用transformer的擴散模型。 將其中的主干網絡 U-Net用transformer替代 ,以獲取更好的效果。
實驗證明了transformer架構在擴散模型上的scalability能力,分析發現 DiTs速度更快(Gflops更高),并且始終具有較低的FID(FID是反應生成圖片和真實圖片的距離,數據越小越好)。
1GLOPs=10億次浮點運算。是Paper里比較流行的單位。
FID是反應生成圖片和真實圖片的距離,數據越小越好
最大的模型DiT-XL/2在ImageNet數據集,類別條件生成任務上 512×512和256×256 表現優于所有先前的擴散模型,256×256上實現了SOTA的FID指標(2.27)。
1. 前言
trasnformer的提出使機器學習經歷復興。在過去的五年中,用于自然語言處理,視覺和其他幾個領域的神經架構基本上都包含trasnformer。許多圖像級通用模型仍然堅持這一趨勢。transformer在自回歸模型得到廣泛使用,但是在其他通用建模框架中采用的較少。例如,擴散模型一直處于圖像級最新進展的前沿生成模型,然而,它們都采用了卷積U-Net架構作為主干。
Ho等人的開創性工作首次引入了擴散模型的U-Net主干。最初我們看到像素級自回歸模型和傳統GANs的成功,U-Net是從Pixel CNN++繼承而來。U-Net是卷積網絡,主要由ResNet塊組成。在與標準的U-Net相比,額外的 spatial self-attention blocks 在trasnformer中是必不可少的組成部分,穿插在較低分辨率下。Dhariwal和Nichol取消了U-Net的幾個結構 ,例如注入條件信息的adaptive normalization layers 和 卷積層中的卷積通道數。然而,Ho等人提出的U-Net網絡的高層設計在很大程度上保持完整。
通過這項工作,我們旨在揭開擴散模型的架構選擇的意義,并為未來生成建模研究提供經驗基線。我們表明U-Net歸納偏差對擴散模型的性能表現不是至關重要的,并且可以很容易地將它們重新與transformer等標準設計放在一起。結果就是,擴散模型很好地從結構上進行統一,符合最新的發展趨勢。 通過繼承來自其他領域的最佳實踐和訓練方法,如以及保持良好的性能,如可擴展性,魯棒性和效率。標準化的架構將會也為跨領域研究開辟了新的可能性。
本文主要研究基于transformer的一類新的擴散模型。我們稱它們為 Diffusion Transformers,或簡稱DiTs。DiTs遵循的是的最佳實踐視覺transformer (vit),已被證明可以比傳統的視覺識別更有效的縮放卷積網絡(例如ResNet)。
更具體地說,本文研究了不同規模的transformer在 網絡復雜性vs樣本質量 之間的平衡。通過在潛在擴散模型(LDMs)框架下構建 DiT設計空間并進行基準測試,其中擴散模型在VAE的潛空間中訓練,我們可以成功用transformer替換U-Net主干。我們進一步顯示DiTs是擴散模型的可擴展架構:網絡計算復雜性(由Gflops測量)與樣本質量(測量FID)。通過簡單地擴大DiT和訓練LDM有了高容量的骨干網(118.6 Gflops),我們可以做到在class有條件的256 × 256 ImageNet生成基準上取得了2.27 FID的最新結果。
2. 相關工作
Transformers
transformer已經取代了跨語言、視覺、強化學習 和元學習 領域特定架構。他們在不斷增加的模型大小、訓練計算和語言數據下顯示出顯著的擴展性,作為通用自回歸模型和除了語言,transformer已經訓練自回歸預測像素。他們也在離散編碼上訓練過 自回歸模型和掩碼生成模型 ;前者具有良好的擴展性能多達20B參數。最后,transformer已經在DDPM中探索非空間數據合成。例如,對在DALL·E 2中生成CLIP圖像嵌入。
在本文研究了transformer的縮放特性 用作圖像擴散模型的主干。
DDPMs
去噪擴散概率模型,Denoising diffusion probabilistic models (DDPMs)
擴散和基于分數的生成模型 在圖像生成尤其成功。在許多情況下,圖像的性能優于 迭代對抗網絡(GANs)。
過去的兩年,DDPMS的改進很大程度上是由采樣技術改進帶來的,最著名的分類指導,重新制定擴散模型預測噪聲而不是像素,并使用級聯DDPM piplines,低分辨率的基礎擴散模型與上采樣器并行訓練 。對于上面列出的所有融合模型,backbone架構選擇了卷積U-Nets。當前的Work引入了一種新穎、高效的在DDPMS中引入attention,而我們研究純transformer。
架構復雜度
對于圖片生成的迭代過程,我們可以使用參數量來衡量不同模型的復雜度。一般而言,參數量來評估模型復雜度不是很合適,因為參數量并不能代表模型的計算復雜度,比如當模型參數量相同時,圖片分辨率不同會導致計算復雜度上較大的差異。所以文章采用Gflops來衡量模型架構的復雜度。
3. 擴散Transformer
3.1 準備知識
擴散公式
-
DDPM 主要分為兩個過程:
- forward 加噪過程(從右往左):加噪過程是指向數據集中的真實圖像逐步加入高斯噪聲, 加噪過程滿足一定的數學規律,不需要學習
- reverse 去噪過程(從左往右):去噪過程是指對加了噪聲的圖片逐步去噪,從而還原出真實圖像。去噪過程則采用神經網絡模型來學習。這樣一來,神經網絡模型就可以從一堆雜亂無章的噪聲圖片中生成真實圖片了。
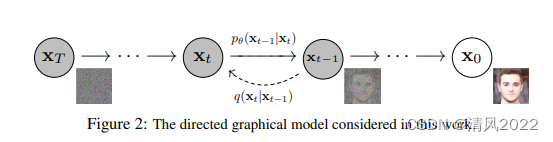
擴散模型需要訓練反向過程
輸入 x t , 輸出 x t ? 1 輸入x_t, 輸出x_t-1 輸入xt?,輸出xt??1
擴散過程的nosie scheduler采用簡單的linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02),這個和SD是不同的。
其次,DiT所使用的擴散模型沿用了OpenAI的**Improved DDPM,相比原始DDPM一個重要的變化是不再采用固定的方差,而是采用網絡來預測方差**。在DDPM中,生成過程的分布采用一個參數化的高斯分布來建模。

Classifier-free Guidance
模型在訓練時,使用一個網絡架構優化兩個模型(uncond,cond)。眾所周知,與通用采樣技術相比,無分類器指導可以產生顯著改進的樣本,并且這種趨勢也適用于DiT模型。
LDMs
潛在擴散模型,我們使用現成的卷積VAE和基于Transformer的DDPM。
3.2. Diffusion Transformer Design Space
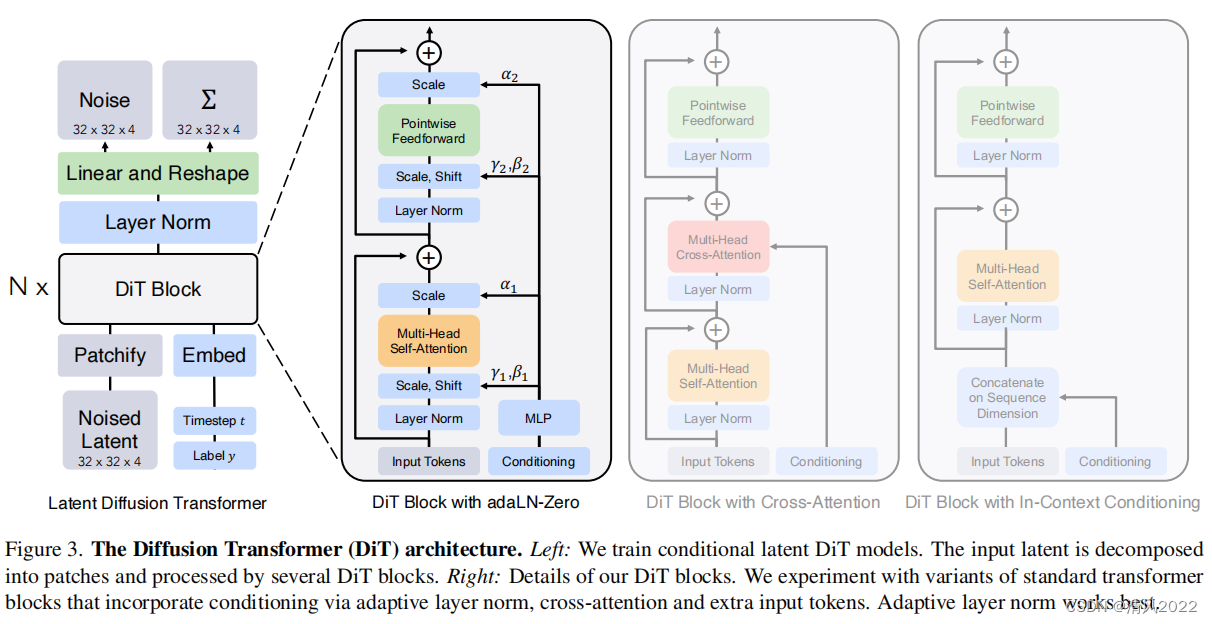
DiTs 模型架構圖,如下所示:
-
左部分:我們訓練了傳統的latent DiT 模型。輸入的latent被分解為patches , 并經過幾個 DiT blocks;
-
右部分:是 DiT blocks內部的詳細結構。
Patch化
DiT的輸入是通過VAE后的一個稀疏的表示z(輸入為256×256×3的圖片,輸出得到壓縮后的latent為32×32×4),其中采用的autoencoder是SD所使用的KL-f8,這就降低了擴散模型的計算量。
然后將輸入轉成patch,文章采用超參p=2,4,8進行對比實驗。

DiT模塊設計
-
**In-context **
in-context條件是將時間步t 的embedding 和c 作為額外的token拼接到 DiT的輸入序列中;
輸入:
latent image,t的embedding和 類別標簽c將兩個embeddings看成兩個tokens合并在輸入的tokens中,這種處理方式有點類似ViT中的cls token,實現起來比較簡單,也不基本上不額外引入計算量。
-
Cross-attention
DiT結構與Condition交互的方式,與原來U-Net結構類似;將兩個embeddings拼接成一個數量為2的序列,然后在transformer block中插入一個cross attention,條件embeddings作為cross attention的key和value;這種方式也是目前文生圖模型所采用的方式,它需要額外引入15%的Gflops。
-
Adaptive layer norm(adaLN)
采用adaLN,這里是將time embedding和class embedding相加,然后來回歸scale和shift兩個參數,這種方式也基本不增加計算量。
-
adaLN-zero:
采用zero初始化的adaLN,這里是將adaLN的linear層參數初始化為zero,這樣網絡初始化時transformer block的殘差模塊就是一個identity函數;另外一點是,這里除了在LN之后回歸scale和shift,還在每個殘差模塊結束之前回歸一個scale。
上面四種嵌入,adaLN-Zero最好,DiT默認這種方式來嵌入條件embedding。DiT發現adaLN-Zero最好,但是這種方式只適合這種只有類別信息的簡單條件嵌入,只需要引入一個class embedding,但對于文生圖來說,條件往往是序列化的text embeddings,因此采用cross-attention通常是更合適的方式。
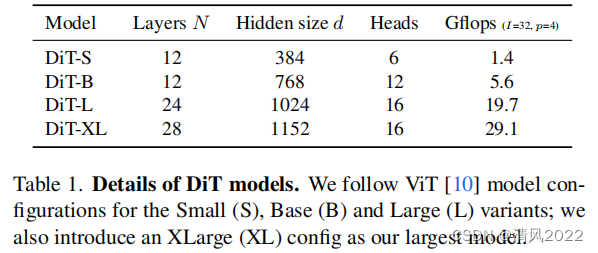
模型大小
與ViT大小相似,分別使用DiT-S、DiT-B、DiT-L和DiT-XL(2.5G),Gflops從0.3到118.6。
Transformer Decoder
在Transformer最上層需要預測噪音,因為Transformer可以保證大小與輸入一致,所以在最上層使用一層線性進行decoder。
在最后一個DiT塊之后,我們需要將我們的圖像標記列解碼為輸出噪聲和輸出對角協方差預測。
這兩個輸出的形狀都等于原始的spatial輸入。我們使用標準的線性解碼器來完成這項工作。
我們應用最終層范數(如果使用adaLN,則為自適應)和lin將每個token提前解碼為p×p×2C張量,其中C為
空間輸入到DiT的通道數。最后, 將解碼的token重新排列到其原始空間中布局以獲得預測的噪聲和協方差。
4. 實驗設置
我們探索了DiT 設計空間,并研究了模型類別的擴展特性。
模型使用 【結構/patch數量】 方式命名,比如【DiT-XL/2】表示模型采用DiT-XL,patch size為2。
訓練
在ImageNet 256×256和512×512分辨率的數據集上訓練 條件類別的 latent DiTs。初始化最后一層線性層為0,另外,其他初始化都與ViT一致。訓練模型采用AdamW,常量學習率1e-4,no weight decay,batch size為256,數據增廣僅使用水平翻轉。和之前的很多工作不同,此處沒有使用學習率warmup和正則化。
盡管沒有使用這些技術,訓練非常穩定,在所有模型配置中,我們沒有觀察到任何訓練transformer時常見的峰值損失。和很多生成模型相同,我們在訓練中保持了 exponential moving average (EMA) (decay 0.9999)。所有的結果都使用了EMA model。我們在所有DiT模型大小和patch 大小上使用完全相同的訓練超參數。訓練超參數大部分來源于ADM,并且我們并沒有進行 learning rates, decay/warm-up, schedules, Adam, β1*/ β*2 or weight decays的調參
擴散
我們使用Stable Diffusion中一個現成的預訓練變分自編碼器。
VAE encoder使用下采樣參數8—— 將RGB圖像256×256×3的圖像編碼到32×32×4的隱空間,
擴散模型作用于隱空間,采樣得到新的 latent后,使用VAE decoder將32×32×4的隱空間還原到256×256×3的圖像。
我們保留了ADM 中的超參數,同時沿用了標簽 和時間步embedding 的方法,擴散過程的nosie scheduler采用簡單的linear scheduler(timesteps=1000,beta_start=0.0001,beta_end=0.02),
評估指標
我們使用FID測量擴展性能, FID是反應生成圖片和真實圖片的距離,數據越小越好。
在與之前的論文進行比較時,我們遵循慣例并使用250 DDPM 采樣步驟報告 FID-50K。眾所周知,FID對小范圍實現很敏感。
為了保證對比的公平性,本文中移植的所有值都是通過導出樣本和獲得的使用ADM的TensorFlow評估套件。
本節中報告的FID 值不使用無分類的,除非另有說明。
另外我們增加了 Score [51], sFID [34] and Precision/Recall [32] 作為第二評價指標。
計算
我們在JAX上實現了所有的模型,并在TPU-v3 pods上進行訓練。
DiT-XL/2, 是計算密集的模型,在全局批量大小為256的TPU v3-256 pod上以大約5.7次迭代/秒的速度進行訓練
5. 實驗
DiT block 設計
我們訓練四個Gflop最高的DiT-XL/2模型,每個使用不同的塊設計-
-
in-context(119.4 Gflops)
-
cross-attention (137.6 Gflops)
-
adaptive layer norm(adaLN, 118.6 Gflops)
-
adaLN- Zero(118.6 Gflops) ,藍色,FID最低,效果最好
我們在訓練過程中測量FID。如下圖所示
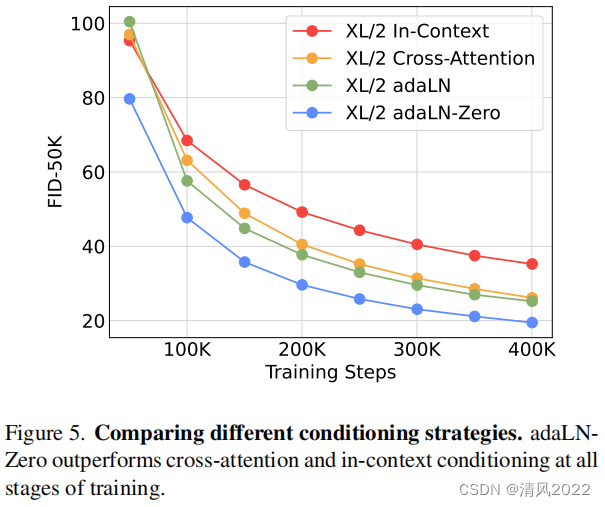
結果顯示在400 k迭代后,adaLN-Zero實現的FID是in-context FID的一半, 表明條件作用機制對模型的質量很重要。
初始化也很重要——adaLNZero,它將每個DiT塊初始化,顯著優于 vanilla adaLN。
在本文中,所有模型都將使用adaLN-Zero DiT塊。
模型大小和patch大小
我們訓練了12個DiT models,模型配置(S, B, L, XL)和patch size(8、4、2)。
注意,DiT-L和DiT-XL的 Gflops是很接近的
圖2(左)給出了不同Gflop模型及其在400K訓練迭代時的FID。
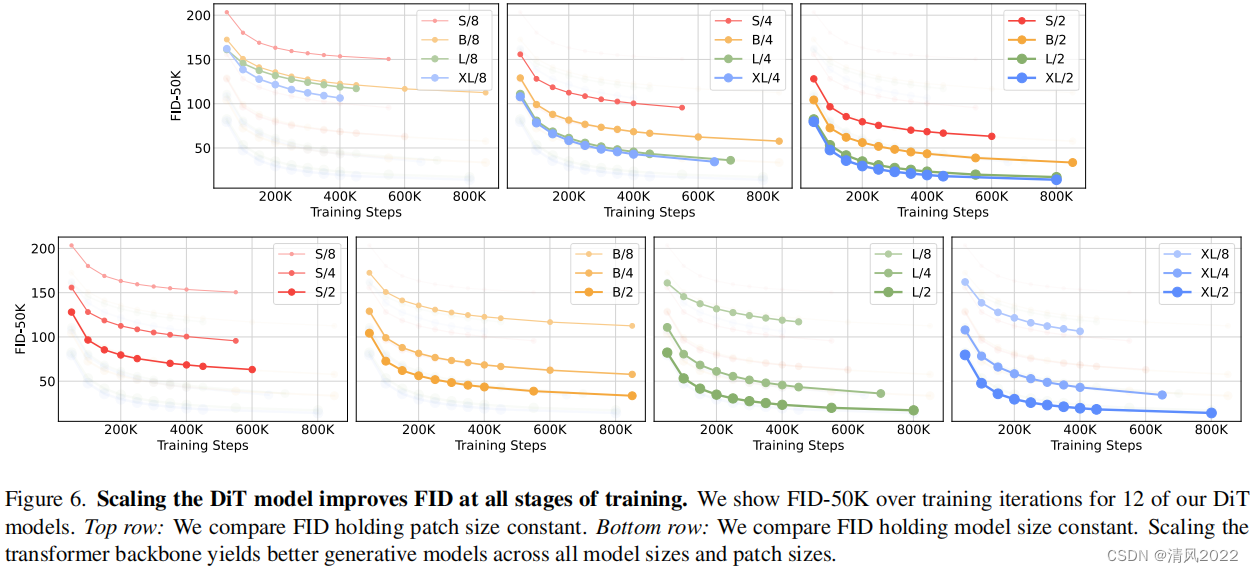
在所有情況下,我們發現模型大小越大,patch size 越小,產生的擴散模型越好。
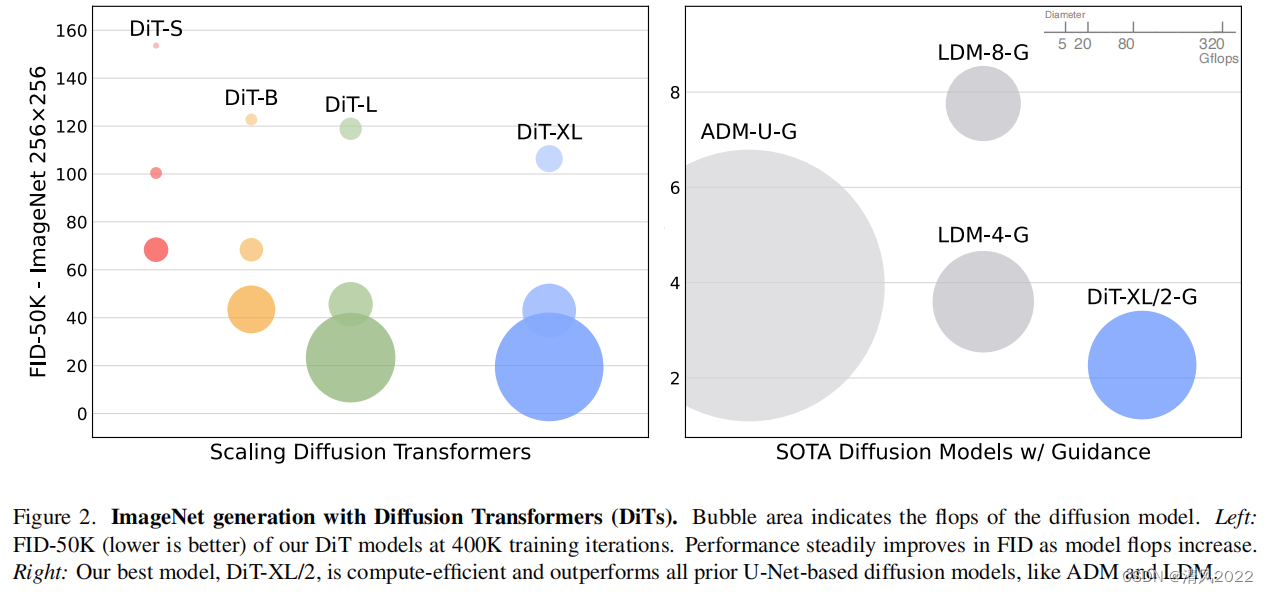
圖6 (top)在固定patch size的情況下,模型越大,FID越小
圖6 (bottom)在固定模型 size 的情況下, patch size越小,FID越小
DiT Gflops 對改進模型很重要
圖6的結果表明,參數計數并不是唯一決定DiT模型的質量。
當模型size保持不變,patch大小減少,transformer的總參數有效保持不變(actually,總參數略有下降),只有
Gflops增加了。
這些結果表明,模型Gflops實際上是提高性能的關鍵。
為了進一步研究,我們在400K訓練步驟中繪制FID-50K。圖8中的模型Gflops。
結果表明,不同的DiT配置會獲得相似的FID值,它們的Gflops總量相似(例如DiT-S/2和DiT-B/4)。
發現模型Gflops和FID-50K之間存在很強的負相關性,表明額外的模型計算是改進DiT模型的關鍵因素。
在圖 12(附錄)中,我們發現這種趨勢適用于其他像Inception分數這樣的指標。
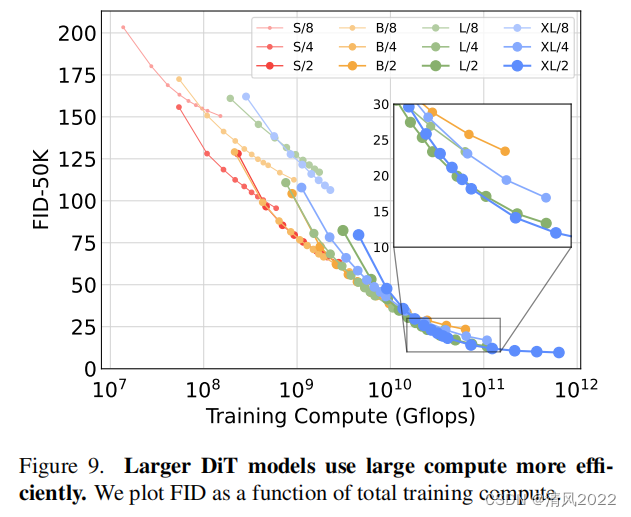
更大的 DiT 模型計算效率更高
在圖9,我們繪制適用于所有DiT訓練模型FID函數。
我們評估了訓練計算:Gflops · batch size · training steps ·3,其中的因子3大致將向后傳遞近似為兩次和前向傳
遞一樣計算量。
我們發現即使是小的DiT 模型,訓練時間很長時, 相比訓練少量step的較大DiT模型也會變得計算效率低。
類似地,當控制Gflops時,我們發現除了patch size之外, 不同配置的模型也會有不同的性能。
例如,XL/4在大約10的10次方Gflops后的表現要優于XL/2。
縮放可視化
我們將縮放的效果可視化如圖7中的樣本質量。
在400K訓練步驟中,我們使用相同的起始噪聲,從我們的12個DiT模型中的每個模型中sample圖像
例如,對噪聲和類標簽進行采樣。
這讓我們可以直觀地解釋縮放如何影響DiT sample質量。
實際上,擴展了模型的大小和數量token的使用可以顯著提高視覺質量。
5.1. State-of-the-Art Diffusion Models
256*256 ImageNet
根據我們的縮放設置,我們訓練了最高Gflops的模型 DiT-XL/2, for 7M steps。
figures1中展示了生成的樣本。
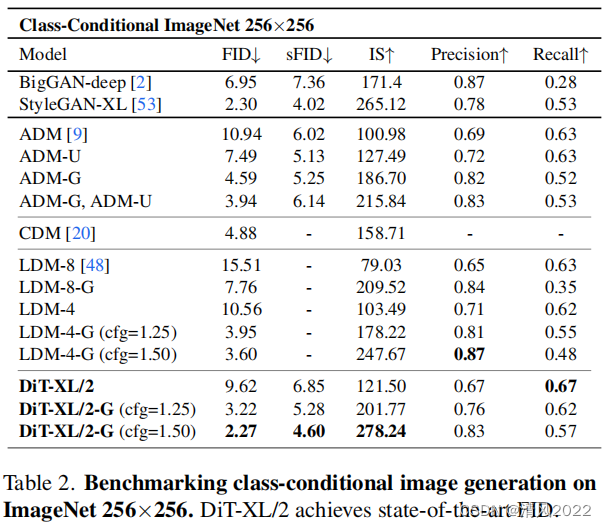
我們還和當前類別條件生成模型進行了對比,如表2所示
當使用無類別引導時 , DiT-XL/2 表現優于所有先前的擴散模型,將之前最好的FID-50K LDM 的3.6降低到2.27.
圖2(右)表示DiT-XL/2 (118.6 Gflops) 計算高效 相比latent space U-Net models like LDM-4 (103.6 Gflops) ,
并且比像素空間U-Net 更有效,如ADM (1120 Gflops)或ADM- u (742 Gflops)。
我們的模型相比之前的生成式模型包括StyleGAN-XL, 都獲得了更低的FID。
最后,我們還發現DiT-XL/2相比LDM-4 和 LDM-8 獲得了更高的recall。
當訓練到2.35M steps時, XL/2 以FID2.55同樣優于先前所有的擴散模型。
512*512 ImageNet
我們在ImageNet的分辨率為512 × 512上,訓練一個新的DiT-XL/2模型,迭代次數為3M,使用與256 × 256模型相
同的超參數。
patch大小為2,XL/2模型總共處理1024個tokens的標記,64 × 64 × 4 input latent(524.6Gflops)。
表3顯示了與最新技術的比較方法。
XL/2再次優于所有先前的擴散模型在此分辨率下,將之前的最佳FID 3.85(ADM ) 改進為3.04。
即使增加了token的number, XL/2仍然是計算高效的。
例如 ADM使用1983 Gflops, ADM-U使用2813 Gflops; XL/2使用了524.6 Gflops。
我們在圖1和附錄中展示了高分辨率XL/2模型的示例
5.2. Scaling Model vs. Sampling Compute
擴散模型的獨特之處在于,它們可以在訓練后通過增加模型的數量來使用額外的計算生成圖像時的采樣步驟。
鑒于模型Gflops對樣本質量的影響,在本節中,我們研究較小模型的計算DiT是否可以勝過較大模型
一種是通過使用更多的采樣計算。我們計算FID, 對于經過400K訓練步驟的所有12個DiT模型,我們使用[16, 32, 64, 128, 256, 1000]每個圖像的采樣
步驟。考慮一下DiT-L/2 使用1000步采樣和DiT-XL/2的128步采樣。
在這種情況下,L/2使用80.7 Tflops對每個圖像進行采樣; XL/2對每個樣本的計算量減少了5倍,即15.2 tflops。盡管如此,XL/2有更好的FID-10K (23.7vs 25.9)。一般來說,上擴采樣計算不能彌補模型計算的不足。
總結
本文介紹擴散transformer (DiTs),一種簡單的基于transformer的擴散模型骨干,表現優于之前的U-Net模型,并繼承了transformer模型類的優秀可擴展特性。考慮到有希望的擴展結果,未來的工作應該
繼續將dit擴展到更大的模型和token計數。DiT還可以作為文本到圖像模型(如DALL·E 2和穩定擴散)的基本框架。
參考資料
https://zhuanlan.zhihu.com/p/557971459
https://blog.csdn.net/u012193416/article/details/134268353










)
)
導航)






