“DreamTalk: When Expressive Talking Head Generation Meets Diffusion Probabilistic Models”
DreamTalk是一個基于擴散的音頻驅動的富有表現力的說話頭生成框架,可以生成不同說話風格的高質量的說話頭視頻。DreamTalk對各種輸入表現出強大的性能,包括歌曲、多語言語音、噪聲音頻和域外肖像。

項目主頁:https://dreamtalk-project.github.io/
論文地址:https://arxiv.org/pdf/2312.09767.pdf
Github地址:https://github.com/ali-vilab/dreamtalk
摘要
DreamTalk利用擴散模型生成表情豐富的說話頭像。該框架包括三個關鍵組件:去噪網絡、風格感知的唇部專家和風格預測器。去噪網絡能夠生成高質量的音頻驅動面部動作,唇部專家能夠提高唇部運動的表現力和準確性,風格預測器能夠直接從音頻中預測目標表情,減少對昂貴的風格參考的依賴。實驗結果表明,DreamTalk能夠生成逼真的說話頭像,超越現有的最先進的對手。
簡介
音頻驅動的說話頭生成是一種將肖像與語音音頻動畫化的技術,它在視頻游戲、電影配音和虛擬化身等領域引起了廣泛關注。生成逼真的面部表情對于增強說話頭的真實感至關重要。目前,生成對抗網絡(GANs)在表達性說話頭生成方面處于領先地位,但其存在的模式崩潰和不穩定訓練問題限制了其在不同說話風格上的高性能表現。擴散模型是一種新的生成技術,近年來在圖像生成、視頻生成和人體動作合成等領域取得了高質量的結果。然而,目前的擴散模型在表達性說話頭生成方面仍存在問題,如幀抖動問題。因此,如何充分發揮擴散模型在表達性說話頭生成方面的潛力是一個有前景但尚未開發的研究方向。
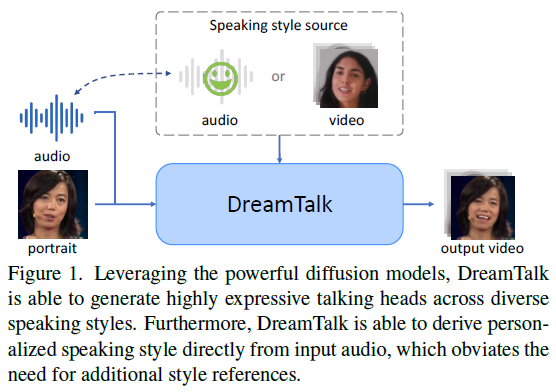
DreamTalk是一個表情豐富的說話頭生成框架,利用擴散模型提供高性能和減少對昂貴的風格參考的依賴。它由去噪網絡、風格感知的嘴唇專家和風格預測器組成。去噪網絡利用擴散模型產生具有參考視頻指定的說話風格的音頻驅動的面部動作。風格感知的嘴唇專家確保準確的嘴唇動作和生動的表情。風格預測器通過音頻直接預測個性化的說話風格。DreamTalk能夠在各種說話風格下一致生成逼真的說話頭,并最小化對額外風格參考的需求。它還能夠靈活地操縱說話風格,并在多語言、嘈雜音頻和領域外肖像等各種輸入下展現出強大的泛化能力。通過全面的定性和定量評估,證明了DreamTalk相比現有的最先進方法的優越性。
相關工作
兩種人工智能生成人物頭像的方法:音頻驅動和表情驅動。音頻驅動方法分為個人特定和個人不確定兩種,前者需要在訓練時指定演講者,后者則可以為未知演講者生成視頻。表情驅動方法早期采用離散情感類別模型,后來采用表情參考視頻進行表情轉移。然而,這些基于GAN的模型存在模式崩潰問題。本文提出了一種使用擴散模型的方法,可以從輸入音頻和肖像中推斷出個性化和情感表達。擴散模型在多個視覺任務中表現出色,但之前的嘗試在生成表情時只能產生中性情感的頭像。本文提出的方法可以生成更具表現力的頭像,而且可以從輸入音頻中推斷出演講風格。
DreamTalk

DreamTalk由3個關鍵組件組成:去噪網絡,風格感知唇形專家和風格預測器。去噪網絡根據語音和風格參考視頻計算人臉運動。人臉運動被參數化為來自3D形變模型的表情參數序列。人臉運動由渲染器渲染成視頻幀。風格感知唇形專家提供不同表情下的唇動指導,從而驅動去噪網絡在保證風格表現力的同時實現準確的唇形同步。風格預測器可以預測與講話中傳達的風格一致的說話風格。
去噪的網絡。去噪網絡以滑動窗口的方式逐幀合成人臉運動序列。它使用音頻窗口預測運動幀。音頻窗口首先被饋送到基于transformer的音頻編碼器中,輸出與信道維度的噪聲運動級聯。線性投影到相同維度后,將拼接結果和時間步長t求和,作為transformer解碼器的鍵和值。為了從風格參考中提取說話風格,風格編碼器首先提取3DMM表情參數序列,然后將它們輸入transformer編碼器。使用自注意力池化層聚合輸出標記,以獲得風格代碼。風格代碼重復2w + 1次,并添加位置編碼。結果作為transformer解碼器的查詢。解碼器的中間輸出令牌被饋送到前饋網絡以預測信號。
風格感知唇形專家。我們觀察到,僅使用標準擴散模型中的去噪損失會導致不準確的唇動。為解決這個問題,本文提出一名風格感知的唇形專家。該唇部專家經過訓練,可以評估不同說話風格下的口型同步。因此,它可以在不同的說話風格下提供唇動指導,更好地在風格表現力和口型同步之間取得平衡。嘴唇專家E根據風格參考R計算一段音頻和嘴唇運動同步的概率:
![]()
具有風格感知的唇部專家將唇動和音頻編碼為以風格參考為條件的各自嵌入,然后計算余弦相似度以表示同步概率。為了從人臉運動中獲取唇動信息,首先將人臉運動轉換為相應的人臉網格,并選擇嘴巴區域的頂點作為唇動表示。首先使用風格編碼器從風格參考中提取風格特征,該特征反映了去噪網絡中的風格結構,然后將風格特征與嵌入編碼器的中間特征圖連接起來,從而將風格條件融合到嵌入網絡中。
風格的預測。風格預測器預測由訓練的去噪網絡中的風格編碼器提取的風格代碼。觀察說話人身份和風格代碼之間的相關性,風格預測器還將肖像作為輸入進行集成。風格預測器被實例化為擴散模型,并被訓練來預測風格代碼本身:
![]()
風格預測器是序列上的transformer編碼器,序列按順序包括:音頻嵌入,擴散時間步的嵌入,說話人信息嵌入,噪聲風格代碼嵌入,和一個稱為learned query的最終嵌入,它的輸出用于預測無噪聲風格代碼。音頻嵌入是使用自監督預訓練語音模型提取的音頻特征。為獲得說話人信息嵌入,該方法首先提取了3DMM身份參數,其中包括人臉形狀信息,但從肖像中刪除了表情等無關信息,然后使用MLP將其嵌入到token中。
訓練和推理
訓練。首先,通過確定隨機采樣的音頻和唇動剪輯是否像中那樣同步,對風格感知的唇動專家進行預訓練,然后在訓練去噪網絡期間進行凍結。
去噪網絡是通過從數據集中抽樣隨機元組來訓練的,優化損失:
![]()
具體來說,從同一時刻的訓練視頻中提取地面真實運動和語音音頻窗口。樣式引用是從同一個視頻中隨機抽取的視頻片段。
我們首先計算擴散模型的去噪損失定義為:
![]()
然后,去噪網絡通過對生成的片段進行同步損失來最大化同步概率:
![]()
使用無分類器指導的進行模型訓練。對于推理,預測信號由一下公式計算:
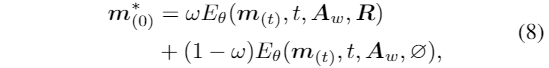
該方法通過調節比例因子ω來控制風格參考R的效果。
當訓練風格預測器時,我們抽取一個隨機視頻,然后從中提取音頻和風格代碼。由于3DMM身份參數可能會泄露表情信息,因此從具有相同說話人身份的另一個視頻中采樣肖像。樣式預測器通過優化損失值來訓練:
![]()
利用PIRenderer作為渲染器,并對其進行精心微調,使渲染器具有情感表達生成能力。
推理。本方法可以使用參考視頻或僅通過輸入音頻和肖像來指定說話風格。在參考視頻的情況下,使用去噪網絡中的風格編碼器導出風格代碼。當僅依賴輸入的音頻和人像時,這些輸入由風格預測器處理,采用去噪過程來獲得風格代碼。
有了風格代碼,去噪網絡利用DDPM的采樣算法產生人臉運動。它首先對隨機運動進行采樣,然后計算去噪序列。最后,生成人臉運動。利用DDIM可以加速采樣過程。然后,渲染器PIRenderer將輸出的人臉運動渲染為視頻。
實驗
實驗設置
數據集。我們在MEAD、HDTF和Voxceleb2上訓練和評估去噪網絡。風格感知唇形專家使用MEAD和HDTF訓練。我們在MEAD上訓練風格預測器,并在MEAD和RAVEDESS上對其進行評估。
基線。我們與以下方法進行對比:MakeitTalk、Wav2Lip、PCAVS、AVCT、GC-AVT、EAMM、StyleTalk、DiffTalk、SadTalker、PDFGC、EAT。
指標。使用了廣泛使用的指標:SSIM[88]、模糊檢測的累積概率(CPBD)、SyncNet置信度分數(Sync conf)、嘴巴區域周圍的地標距離(M-LMD)、全臉地標距離(F-LMD)。
結果
定量比較。本方法在大多數指標上優于先前的方法,尤其在精確的嘴唇同步和生成與參考說話風格一致的面部表情方面表現出色。

定性比較。與其他方法相比,MakeItTalk和AVCT在準確的嘴唇同步方面存在困難,Wav2Lip和PC-AVS的輸出模糊不清,SadTalker在嘴唇運動方面有時顯示出不自然的抖動。EAT的能力僅限于生成離散的情緒,缺乏細膩的表達。EAMM、GC-AVT、StyleTalk和PD-FGC能夠產生細致的表情,但EAMM在嘴唇同步方面表現不佳,GC-AVT和PDFGC在保持說話者身份方面有困難,而且三者都存在渲染合理背景的問題。StyleTalk能夠生成細致的表情,但有時會減弱強度并且無法準確地生成某些單詞的嘴唇運動。DiffTalk在嘴唇同步方面存在困難,并且在嘴部區域引入抖動和偽影。DreamTalk在生成逼真的說話人臉方面表現出色,不僅能夠模仿參考說話風格,還能實現精確的嘴唇同步和優質的視頻質量。


泛化能力。本方法還展示了在不同領域的肖像、各種語言的語音、嘈雜的音頻輸入和歌曲中生成逼真的說話頭視頻的能力。

說話風格預測結果。本方法能夠準確識別細微的表情差異,并根據原始視頻中觀察到的個性化說話風格進行預測。

消融分析
本文通過消融實驗分析了設計的貢獻,包括去除口型專家和使用無條件口型專家的變體。結果表明,去除口型專家會導致情感數據集MEAD的唇同步精度下降,而使用無條件口型專家則會犧牲表達風格的精度。全模型通過引導擴散模型的表達潛力,實現了精確的唇同步和生動的表情,達到了平衡。


風格代碼可視化
使用tSNE將MEAD數據集中15個說話者的風格代碼映射到2D空間中,這些說話者展示了22種不同的說話風格,包括三個強度級別的七種情緒和一種中性風格。每種風格從10個隨機選擇的視頻中提取風格代碼。結果顯示,相同說話者的風格代碼傾向于聚集在一起,這表明個體說話者的獨特性對說話風格的差異產生了更大的影響,這也是使用肖像信息推斷說話風格的合理性的基礎。此外,每個說話者的風格代碼分布都展示了共同的模式和個性化的特征。

風格編輯
調整分類器自由指導方案中的比例因子ω可以調節輸入風格的影響,當ω超過2時,唇同步準確度會下降。利用風格空間進行風格代碼插值可以實現無縫過渡和生成新的說話風格。

用戶研究
用戶研究共有20名參與者,測試樣本涵蓋多種說話風格和說話人。每種方法都需要參與者對10個視頻進行評分,評分包括三個方面:唇同步質量、結果真實性和生成視頻與風格參考之間的一致性。結果表明,該方法在所有方面均優于現有方法,尤其是在風格一致性方面表現出色。

總結
DreamTalk利用擴散模型生成表情豐富的說話頭像。該方法旨在在多樣的說話風格中表現出色,同時最小化對額外風格參考的依賴。作者開發了一個去噪網絡來創建表情豐富的音頻驅動面部動作,并引入了一個風格感知的唇部專家來優化唇語同步,而不會影響風格表現力。此外,作者設計了一個風格預測器,直接從音頻中推斷說話風格,消除了對視頻參考的需求。作者通過大量實驗驗證了DreamTalk的有效性。
文章轉載于靈度智能






)
)
導航)







函數的使用介紹)
)

