1目標
分析RPP算法時控制器算法學習1-RPP受控純追蹤算法發現,在終點時如果角度還有較大偏差,該算法無法進行很好的調整,故開始嘗試在末端接近目標點時,用自己的控制算法去調整位姿,姑且命名為TEA算法(Target-End-Adjust Algorithm for Ackermann)
2控制思路
step1.
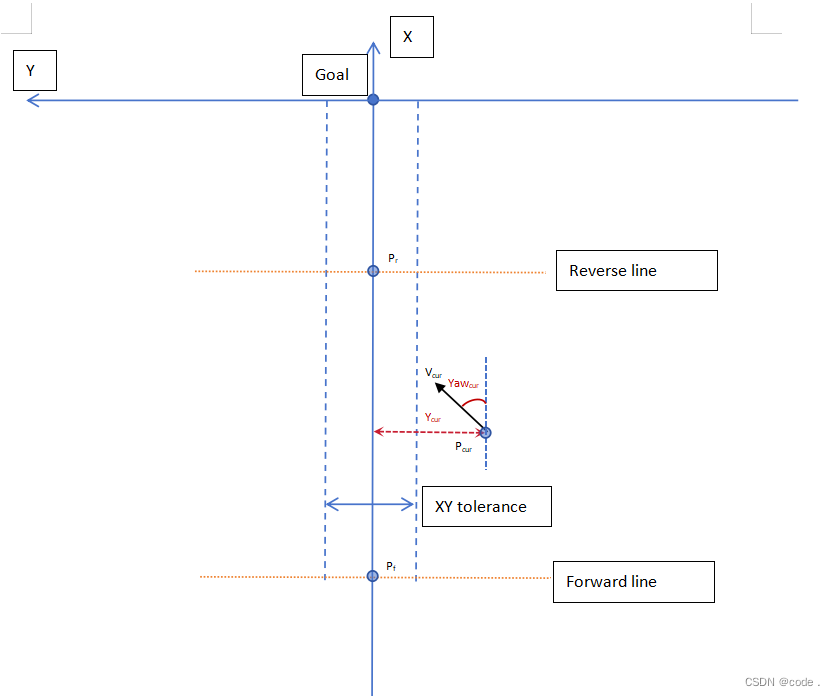
將小車當前坐標轉換到目標點為原點,目標方向為x軸的坐標系(CSgoal)下,如上圖所示。
step2.
末端調整算法的目標就是:在終點前面一小段空間內(橙色標記),把小車位置點調整到Y=0(或直線誤差許可范圍內:<=XY tolerance),yaw為0(或yaw誤差許可范圍內,<=yaw tolerance)
step3.
設定倒車距離和前進距離(兩個【系統參數】X值:Xrev和Xfwd)。如果step2的目標沒有滿足,而小車當前坐標的Xcur>Xrev就倒車去調整;而如果Xcur<Xfwd就前進去調整;在Xrev和Xfwd之間就按規律逐步修正速度。
)

享元模式)




| 121. 買賣股票的最佳時機 122.買賣股票的最佳時機II)











