CNAN知識圖譜輔助推薦系統
文章介紹了一個基于KG的推薦系統模型,代碼也已開源,可以看出主要follow了KGNN-LS 。算法流程大致如下:

1. 算法介紹
算法除去attention機制外,主要的思想在于:user由交互過的item來表示、item由交互過的user交互過的item表示。如下圖:

即user自身是不具備embedding表示的,完全靠KG部分。 這樣的好處在于可以很方便的處理新增加的user,并不需要重新訓練新用戶的embedding。
user的initial entity set(即該user交互過的item id在KG的id)定義為:

item的initial entity set定義為:

�� 是item交互過的user交互過的item集合,公式3將item id轉化為在KG的id,即對齊操作。
由此,我們相當于得到了user、item的鄰居set,再由這些鄰居set在KG中延伸出 � 階鄰居做聚合,第 � 階tail entity集合與三元組集合定義為:


符號 � 代表某個user或item。如下圖所示,多個Layer即代表多階鄰居:

這一步在算法執行中會占據相當大的時間。
2.聚合方式
對于某個triplet (��?,�,���) 而言,我們定義從tail entity ��� 沿著 � 聚合到head entity �?� 得到的attentive embedding �� :



CKAN的聚集首先將不同layer(總共 � 個layer)的三元組分別聚集得到 �� 、再將處于相同layer的 �� 累加到一起作為該layer的表示:

接著,除去這 � 個向量外,還會將initial entity set的embedding累加起來作為第0階layer表示:

對于target item而言,它自身也是entity,所以單獨多引入一個origin embedding:

因此,target user和target item擁有如下embedding set:

最后聚合target user/target item的embedding set得到final embedding。正如圖一的Knowledge-aware Attentive Network所示。聚合的方式有三種:

可以看出CKAN的聚集和其他的GNN算法不同,一般的GNN聚集是聚集多次、最后多階信息都會聚集在target node上。訓練采用cross-entropy loss。
3.實驗
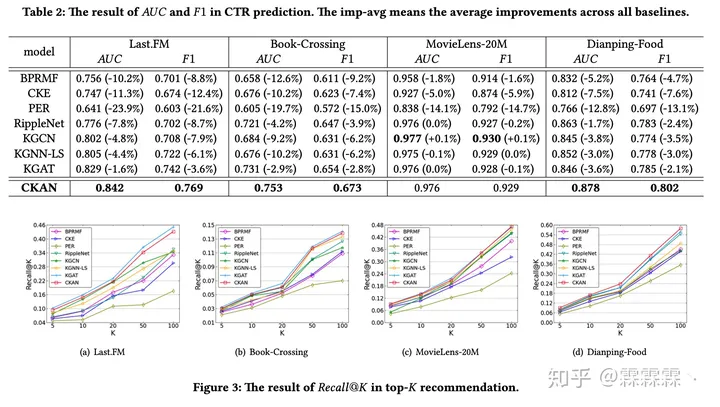
實驗對比如下:
loss。
3.實驗
實驗對比如下:
[外鏈圖片轉存中…(img-XHaKhNr4-1709550222389)]
數據集均是采用KGNN-LS使用的數據集






:用戶操作)


:Python語言介紹及第一個Pyhon程序)









)