初識Java深度學習框架DL4J
- 1.起因
- 2.簡介
- 3.組件
- 3.1 Deeplearning4j/ScalNet
- 3.1.1 Deeplearning4jf(Java)
- 3.1.2 ScalNet(Scala)
- 3.2 ND4J/LibND4J
- 3.3 SameDiff
- 3.4 DataVec
- 3.5 Arbiter
- 3.6 RL4J
- 4.總結
內容來自網絡,基于官方文檔【 Deeplearning4j】、知乎【 DL4J開發者社區】、OSCHINA【 Deeplearning4j 分布式深度學習庫】、科普中國·科學百科【 Deeplearning4j】等文章進行整理,簡化了一些信息并通過深度學習菜鳥
我這個人形GPT〒_〒的思維方式進行闡述。
1.起因
- LLM如火如荼地影響著整個互聯網應用,AI也成為焦點,之前的大數據分析似乎熱度過去了,大家都想學點兒ML,但是Python、GPU不是都具備的。
- DL4J可以在JVM上運行,擁有了Java語言的一切優點,且支持GPU和大數據組建集成,不用擔心性能和可擴展性。
- 由于是小白,需要進行基礎知識的補充,這里整理一下分享給大家。
2.簡介
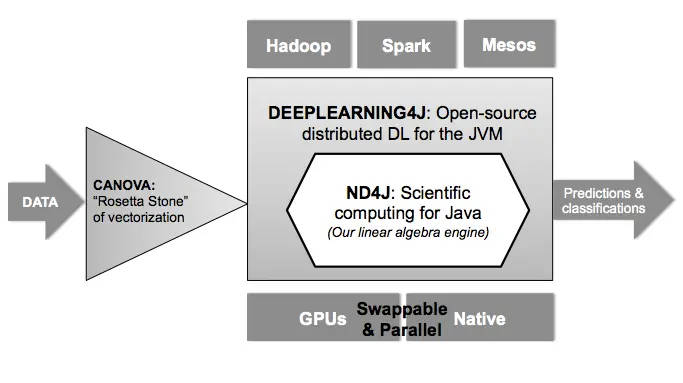
Deeplearning4j是當前最大、最流行的基于JAVA的深度學習框架,正式誕生于2013年,在2017年加入Eclipse基金會,由美國的Skymind開源并維護。
- 支持神經網絡模型的構建、模型訓練和部署;
- 能夠與現有大數據生態進行無縫銜接(Hadoop、Spark等),也是可以原生態支持分布式模型訓練的框架之一;
- 支持多線程;
- 跨平臺(硬件:CUDA GPU,
x86,ARM,PowerPC;操作系統:Windows/Mac/Linux/Android)。
小結一下:模型構建、模型訓練和部署一條龍,兼容性強,多線程,跨平臺(特別注意Android平臺,支持端側模型)?
3.組件
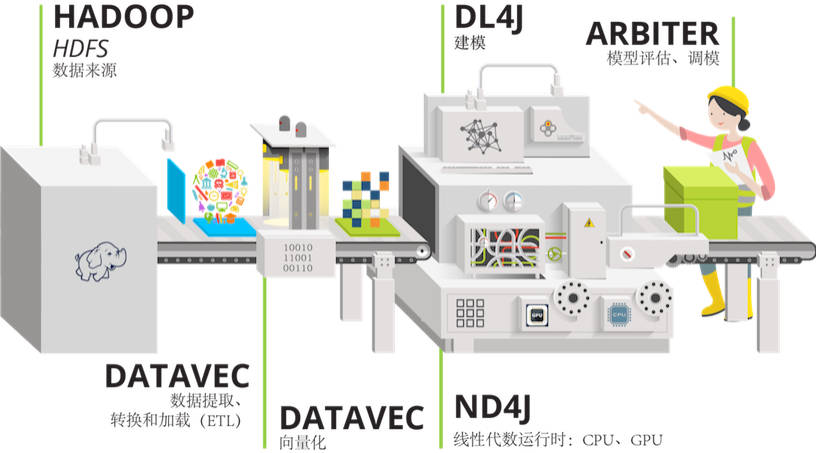
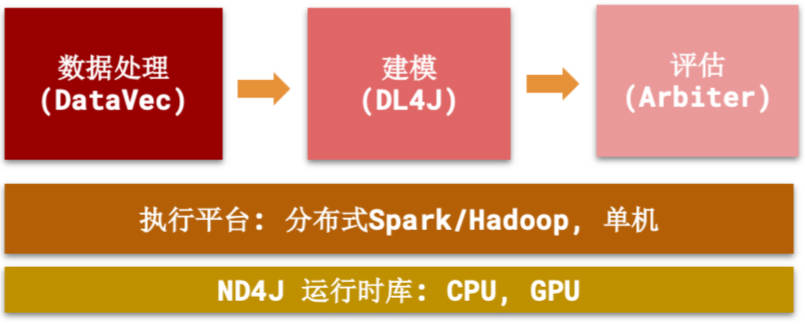
Deeplearning4j實際上是一堆項目,旨在支持基于 JVM 的深度學習應用程序的所有需求。除了 Deeplearning4j 本身(高級 API),它還包括:
- Deeplearning4j/ScalNet:JVM和Spark上運行神經網絡構建、訓練和部署的基礎框架庫;
- ND4J/libND4J:支持CPU/GPU加速的高性能數值計算庫,可以說是JVM上的Numpy;
- SameDiff:用于符合微分和計算圖庫;
- DataVec:數據處理庫,提供采樣、過濾、變換等操作;
- Arbiter:神經網絡超參數搜索和優化庫;
- RL4J:JVM上的強化學習庫;
- Model Import:模型導入庫,可以導入ONNX,TensorFlow,Keras(Caffe)模型;
- Jumpy:ND4J對應Python語言API;
- Python4j:可以在JVM里運行Python腳本語言。
3.1 Deeplearning4j/ScalNet
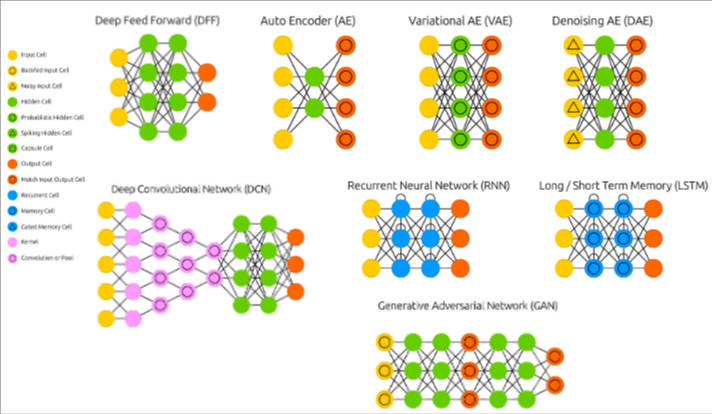
- 前向神經網絡(Feedforward Neural Networks, FNN)
- 自動編碼器(AutoEncoders)
- 卷積神經網絡(Convolutional Neural Networks, CNN)
- 循環神經網絡(Recurrent Neural Networks ,RNN)
- 生成對抗網絡(Generative Adversarial Networks)
- 遞歸神經網絡(Recursive Neural Network )
- 深度信念網絡(Deep Belief Networks)和受限制玻爾茲曼機(Restricted Boltzmann Machines)
- 圖神經網絡(Graph Neural Networks)
3.1.1 Deeplearning4jf(Java)
神經網絡高層API庫,用于構建具有各種層的多層神經網絡(MultiLayerNetworks)和計算圖(ComputationGraphs),支持從其他框架導入模型和在Apache Spark上進行分布式訓練
3.1.2 ScalNet(Scala)
ScalNet是受Keras啟發而為Deeplearning4j開發的Scala語言包裝。它通過Spark在多個GPU上運行。功能相當于Keras。
Keras是一個由Python編寫的開源人工神經網絡庫,可以作為Tensorflow、Microsoft-CNTK和Theano的高階應用程序接口,進行深度學習模型的設計、調試、評估、應用和可視化。
3.2 ND4J/LibND4J
ND4J是Deeplearning4j的數值處理庫和張量庫,在JVM中實現Numpy的功能:
- Java科學運算引擎,用來驅動矩陣操作;
- JavaCPP功能: Java 到 Objective-C 的橋,可像其他 Java 對象一樣來使用 Objective-C 對象;
- CPU 后瑞:OpenMP、OpenBlas 或 MKL、與SIMD的擴展;
- GPU 后瑞:最新CUDA 及 CuDNN。
包含500多種數學、線性代數和神經網絡操作。
3.3 SameDiff
SameDiff是具有自動微分功能的張量計算庫,其自動微分方法是基于靜態圖的方法,提供神經網絡運算中更為底層的接口,主要用于自定義神經網絡拓撲結構。
另外,SameDiff支持導入Tensorflow凍結模型格式的.pd(protobuf)模型。對ONNX、TensorFlow SaveModel和Keras模型的導入正在完善中。可以簡單的認為SameDiff和DL4J的關系類似于Tensorflow和Keras。
符合微分和計算圖庫是深度學習中的兩個關鍵概念:
- 符合微分(Automatic Differentiation,簡稱AD)
- 符合微分是一種計算梯度的技術,用于優化神經網絡中的參數。
- 在神經網絡訓練過程中,我們需要計算損失函數對模型參數的梯度,以便使用梯度下降等優化算法來更新參數。
- 符合微分通過構建計算圖并自動計算每個節點的梯度,使得梯度計算變得高效且不容易出錯。
- 常見的深度學習框架(如TensorFlow、PyTorch和Deeplearning4j)都使用符合微分來實現反向傳播算法。
- 計算圖庫
- 計算圖是一種表示復雜計算過程的圖結構,其中節點表示操作(例如加法、乘法、激活函數等),邊表示數據流。
- 計算圖庫用于構建、管理和執行計算圖。
- 在深度學習中,計算圖用于描述神經網絡的前向傳播和反向傳播過程。
3.4 DataVec
神經網絡專門處理多維數組形式的數值數據。DataVec可以將來自一個CSV文件或一批圖像的數據序列化,轉換為數值數組。數據的攝取、清理、聯接、縮放、標準化和轉換是開展任何類型的數據分析時都必須完成的工作。是深度學習的先決條件。DataVec是專為這一流程設計的工具包。數據科學家和開發人員可以用其中的工具將圖像、視頻、聲音、文本和時間序列等原始數據轉變為特征向量,輸入神經網絡。
- 數據的的 ETL (抽取、轉換、裝載)和向量化;
- DataVec幫助克服機器學習及深度學習實現過程中最重大的障礙之一:將數據轉化為神經網絡能夠識別的格式;
- DataVec使用Apache Spark來進行轉換運算。
整體流程如下:
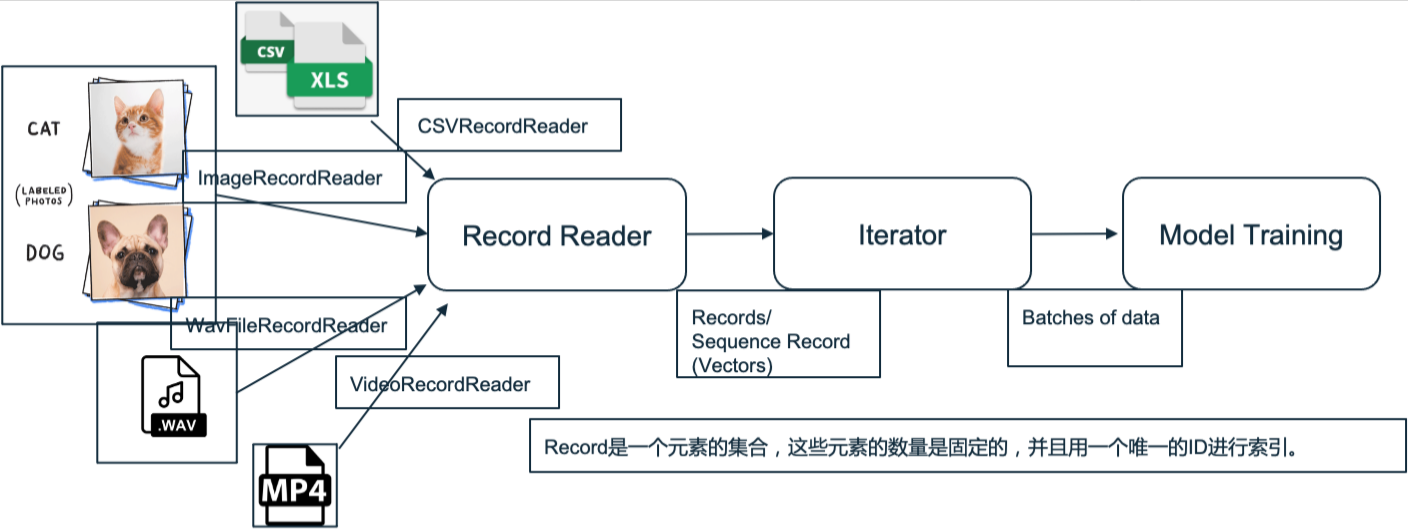
同時,DataVec也支持所有主要類型的輸入(CSV、文本、圖像、音頻、視頻和數據庫)整體流程如下:

除了明顯提供經典數據格式的讀取器,DataVec還提供了一個接口用來攝取特定的自定義數據。
3.5 Arbiter
Arbiter幫助您搜索超參數空間,為神經網絡尋找最理想的參數組合及架構。這非常重要,因為尋找恰當的架構和超參數是一個很大的組合問題。來自微軟研發部等企業實驗室的ImageNet大賽獲勝團隊正是通過搜索超參數空間才得出了ResNet這樣的150層神經網絡:
- 深度學習模型檢測、評估器;
- 調整及優化機器學習模型;
- 使用Grid search和Random Search 作超參數尋優;
- arbiter-core:Aribter-core用網格搜索等算法來搜索超參數空間。它會提供一個GUI界面。
- arbiter-deeplearning4j:Arbiter可以同DL4J模型互動。在進行模型搜索時,您需要能運行模型。這樣可以對模型進行試點,進而找出最佳的模型。
3.6 RL4J
RL4J是在Java中實現深度Q學習、A3C及其他強化學習算法的庫和環境,與DL4J和ND4J相集成。
4.總結
簡而言之,Deeplearning4j 能夠讓你從各類淺層網絡(其中每一層在英文中被稱為layer)出發,設計深層神經網絡。這一靈活性使用戶可以根據所需,在分布式、生產級、能夠在分布式 CPU 或 GPU 的基礎上與 Spark 和 Hadoop 協同工作的框架內,整合受限玻爾茲曼機、其他自動編碼器、卷積網絡或遞歸網絡。此處為我們已經建立的各個庫及其在系統整體中的所處位置:





即將召開!)


: C++實現線程池)







)


