說是模型的維護,其實這堂課都是在講“在工業環境中開發和部署機器學習模型的流程”。
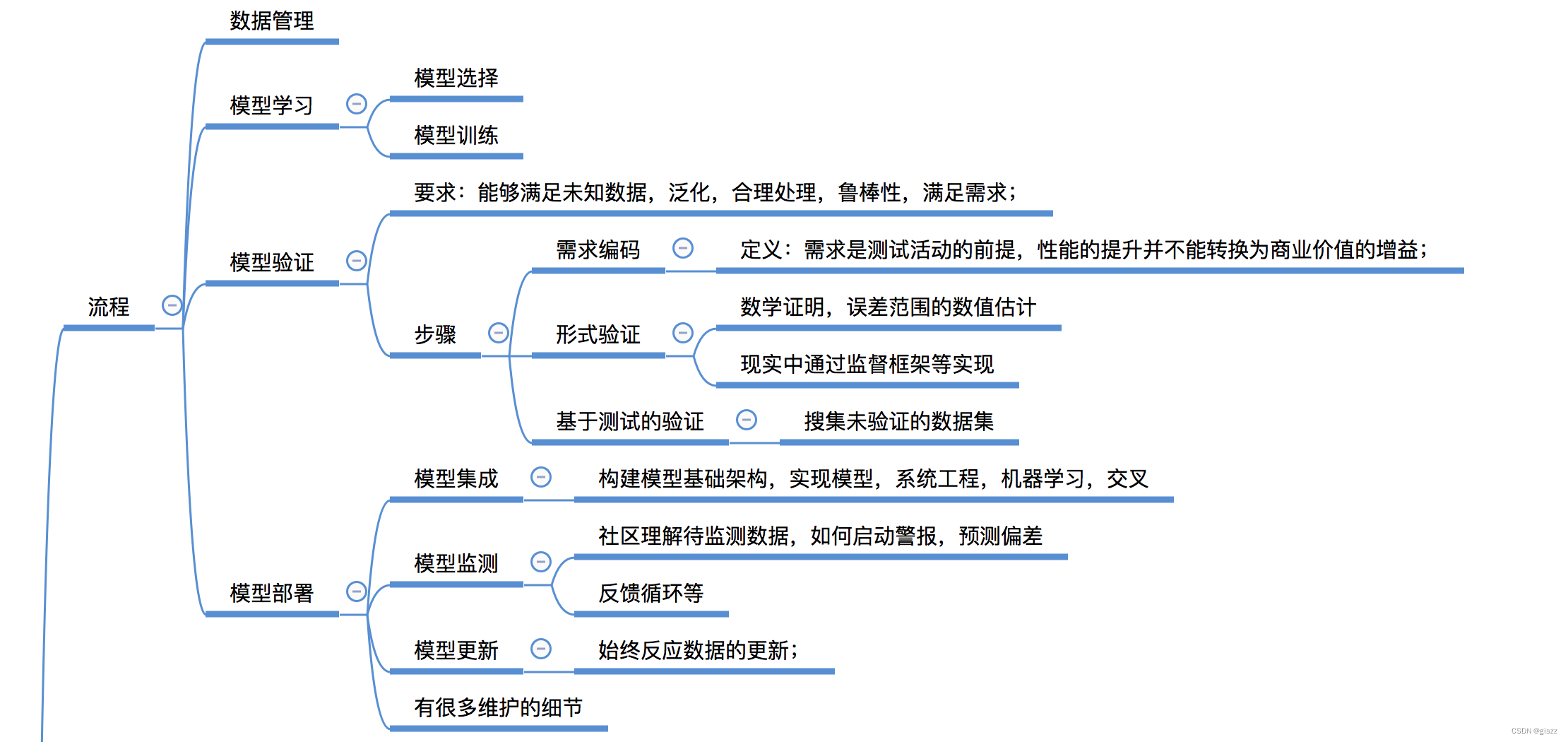
上圖來自于我的筆記思維腦圖,已經上傳,要鏈接的訪問的主頁查看資源。
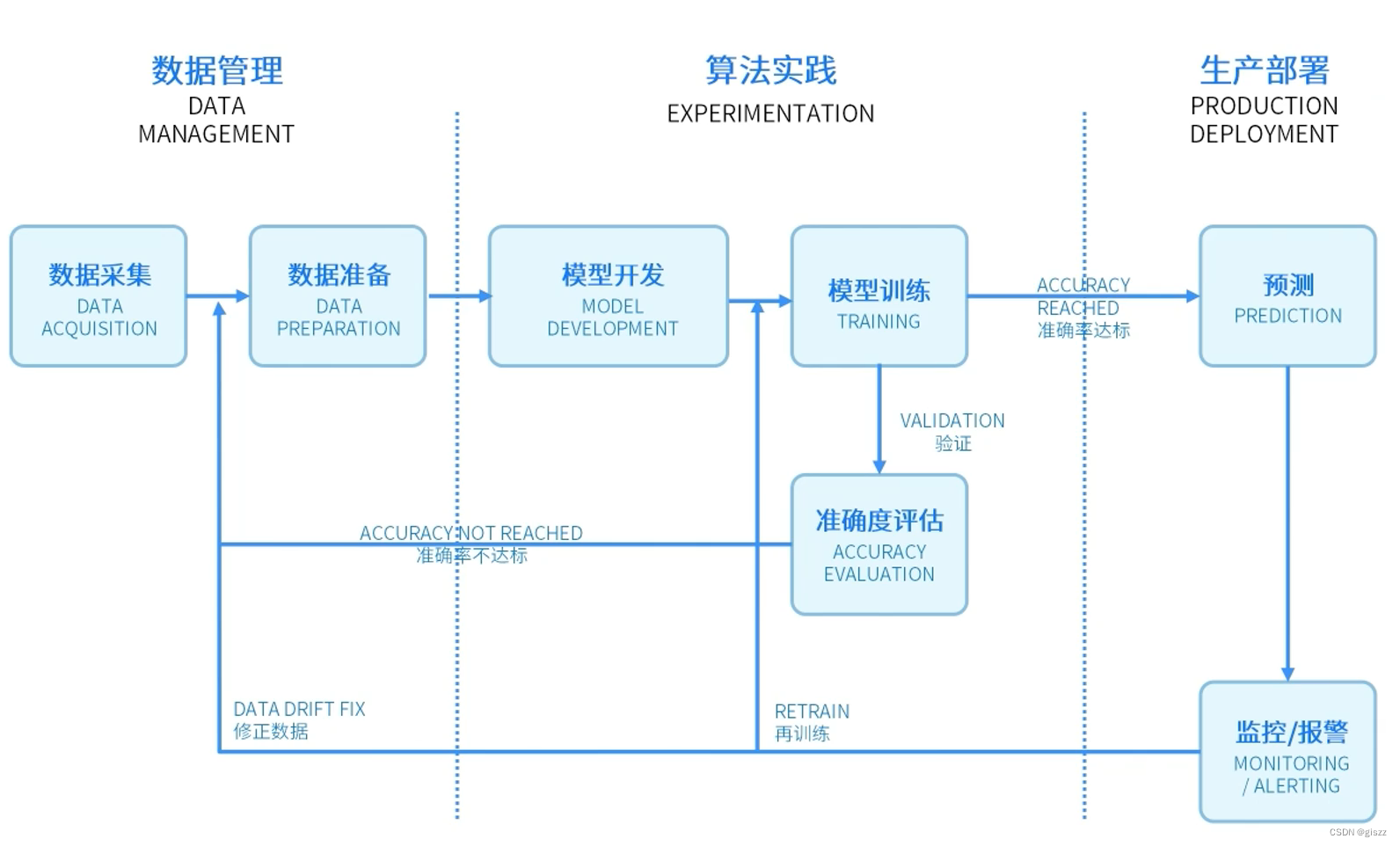 ?
?
一路走來,我們學習了數據管理、模型學習、模型驗證、模型部署等重要的步驟。
其中模型學習,包括模型選擇和模型訓練。
模型驗證,要求:能夠滿足未知數據,泛化,合理處理,魯棒性,滿足需求;
在人工智能項目中,數據管理、模型學習、模型驗證和模型部署是構建和運營機器學習模型的核心步驟。每個步驟都有其獨特的作用,包含一系列關鍵技術、細分步驟、理念和工具方法。以下是對這些步驟的詳細闡述:
數據管理
關鍵技術:
- 數據清洗:去除重復、錯誤或不完整的數據。
- 數據轉換:將數據轉換成適合模型訓練的格式。
- 數據標注:為監督學習提供標簽。
- 數據存儲:高效、安全地存儲大量數據。
主要細分步驟:
- 數據收集:從各種來源(如數據庫、API、文件等)獲取原始數據。
- 數據預處理:清洗、轉換、標準化數據,以準備訓練數據集。
- 數據分割:通常將數據分割為訓練集、驗證集和測試集。
- 數據版本控制:跟蹤數據的變化,以便能夠重現實驗結果。
理念:
- 數據質量至關重要:高質量的數據是訓練出高性能模型的基礎。
- 數據應代表實際場景:訓練數據應盡可能反映模型將面對的真實世界情況。
工具和方法:
- 使用Pandas、SQL等工具進行數據清洗和轉換。
- 利用DVC、Git LFS等進行數據版本控制。
- 應用數據湖、數據倉庫等解決方案進行數據存儲和管理。
模型學習
關鍵技術:
- 算法選擇:根據問題類型(分類、回歸、聚類等)選擇合適的機器學習算法。
- 超參數調優:調整模型參數以優化性能。
- 損失函數:定義模型訓練過程中的優化目標。
- 優化器:選擇如梯度下降等算法來最小化損失函數。
主要細分步驟:
- 模型設計:基于業務理解和數據特征構建模型結構。
- 訓練模型:使用訓練數據集進行模型訓練。
- 模型評估:在驗證集上評估模型性能。
- 模型調整:根據評估結果調整模型結構或參數。
理念:
- 簡潔性優先:在保持性能的同時,盡量簡化模型以減少過擬合的風險和提高可解釋性。
- 持續學習:隨著新數據的到來,模型應能夠適應新的知識和模式。
工具和方法:
- 利用TensorFlow、PyTorch等深度學習框架進行模型設計和訓練。
- 使用Scikit-learn等機器學習庫進行傳統機器學習模型的構建。
- 應用網格搜索、隨機搜索或貝葉斯優化等方法進行超參數調優。
模型驗證
關鍵技術:
- 交叉驗證:評估模型在不同數據集上的泛化能力。
- 性能指標:根據業務需求選擇合適的評估指標(如準確率、召回率、F1分數等)。
- 模型穩定性:檢查模型在不同運行或不同數據分割下的性能一致性。
- 偏差和方差分析:診斷模型性能不足的原因。
主要細分步驟:
- 性能度量:在獨立的測試集上評估模型性能。
- 錯誤分析:檢查模型預測錯誤的案例以理解其局限性。
- 對比實驗:與其他模型或基線進行比較以驗證優越性。
- 模型解釋性:使用如SHAP、LIME等工具理解模型決策依據。
理念:
- 信任但驗證:即使模型在訓練數據上表現良好,也需要在未見過的數據上進行驗證。
- 透明性和可解釋性:模型應能夠提供其決策的合理解釋。
工具和方法:
- 使用模型評估庫如MLflow、Neptune等進行實驗跟蹤和性能比較。
- 應用統計測試來驗證模型性能的提升是否顯著。
- 利用模型解釋性工具進行模型決策的可視化和理解。
模型部署
關鍵技術:
- 模型序列化:將訓練好的模型轉換為可部署的格式。
- 模型服務:構建API或Web服務以提供模型預測功能。
- 容器化:使用Docker等技術將模型及其依賴項打包為容器。
- 自動化部署:通過CI/CD流程自動將模型部署到生產環境。
主要細分步驟:
- 模型導出:將模型從訓練環境導出為可部署格式(如TensorFlow SavedModel、ONNX等)。
- 環境準備:設置生產環境的硬件和軟件依賴。
- 部署模型:將模型部署到生產服務器或云平臺上。
- 監控與維護:實時監控模型性能并進行必要的維護。
理念:
- 可靠性與穩定性至關重要:生產環境中的模型必須能夠持續、穩定地提供服務。
- 快速響應和彈性擴展:模型應能夠迅速適應流量變化并彈性擴展資源。
工具和方法:
- 利用TensorFlow Serving、TorchServe或自定義服務框架進行模型服務化。
- 使用Docker和Kubernetes進行容器化部署和管理。
- 應用監控工具如Prometheus、Grafana以及日志分析工具進行實時性能監控和故障排查。
? ? ? ?
以上內容,在前面的筆記中,都有提到,歡迎關注,到我的主頁查看。?
?




真題講解每日一題:《字典字符查找》)


![[項目設計] 從零實現的高并發內存池(一)](http://pic.xiahunao.cn/[項目設計] 從零實現的高并發內存池(一))


)

)





)
:Geometry函數)