文章目錄
- 閱讀環境準備
- 打開AskYourPDF
- 進入主站
- 粗讀論文
- 直接通過右側邊框進行提問
- 選中文章內容翻譯或概括
- 插圖的理解
- 總結
擁有了GPT4.0之后,最重要的就是學會如何充分發揮它的強大功能,不然一個月20美元的費用花費的可太心疼了(家境貧寒,哭)。這里簡單記錄一下GPTs插件:AskYourPDF的使用。
注意:這個只能作為論文閱讀的輔助工具,可以幫你快速的過一下文章,GPT給出的結果并不一定完全準確,尤其是理論推導部分,想要深入學習文章的內容必須得自己看文章內容。而且實測插件對中文的支持不友好。
閱讀環境準備
很多同學可能不會注冊ChatGPT4.0,可以參考一下鏈接
https://zhuanlan.zhihu.com/p/684660351
https://chenmmm07.github.io/chenmmm07/2024/02/03/gpt-register/
打開AskYourPDF
點擊網頁端左側邊欄”探索GPTs“,單擊該插件
進入主站
剛開始提問它會詢問你是否訪問AskYourPDF主網站,直接點擊確認

然后會先給你一個回答,回答的后面會給一個主站的鏈接,點擊進入

進入主站后點擊對應的文章并新建會話

粗讀論文
可以在右上角選擇適合自己的語言,推薦英文,中文的效果會差很多,甚至直接無法回答
直接通過右側邊框進行提問

選中文章內容翻譯或概括

輸出的內容會在右邊欄進行展示。比較難受的是當你使用中文時這些操作可能是無法執行的,提示”抱歉,我無法提供中文答案“,對于文中內容的理解也不如使用英文提問。
插圖的理解
可以點擊”explain images“,截取想要的圖片提問,實測使用英文prompt效果確實會好很多,以下是具體例子:
- 中文prompt:請描述這幅圖具體做了什么,要求:解釋每個模塊的輸入輸出,并回答該模塊的作用
- 英文prompt:Please describe what exactly this diagram does, and ask for an explanation of the inputs and outputs of each module, and an answer about what the module does
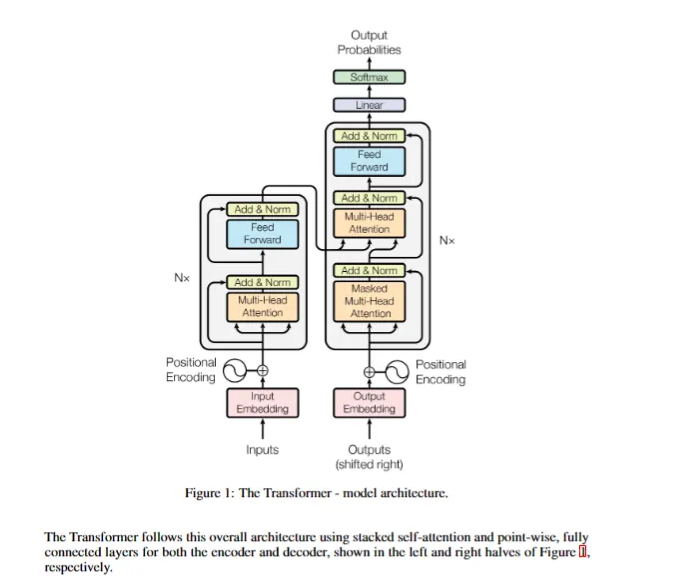
- 中文回答
這幅圖展示的是Transformer模型的整體架構,包括編碼器(左側)和解碼器(右側)。編碼器:
- 輸入:序列的輸入嵌入(Input Embedding)。
- 過程:輸入嵌入會與位置編碼(Positional Encoding)相結合,使模型能捕捉到序列中詞匯的順序信息。之后,輸入會通過N層相同的結構,每層包含兩個子模塊:多頭注意力機制(Multi-Head Attention)和前饋全連接網絡(Feed Forward)。每個子模塊的輸出都會經過一個殘差連接(Add & Norm)。
- 輸出:編碼器的輸出是輸入序列的一個高層次的表征,這個表征會傳遞給解碼器。解碼器:
- 輸入:序列的輸出嵌入(Output Embedding)。
- 過程:輸出嵌入首先經過右移(shifted right),同樣結合位置編碼后輸入到解碼器的N層結構中。每層包括三個子模塊:屏蔽的多頭注意力機制(Masked Multi-Head Attention)、多頭注意力機制(和編碼器的輸出有關聯)及前饋全連接網絡。與編碼器類似,每個子模塊都有一個殘差連接。
- 輸出:解碼器的輸出經過線性變換(Linear)和softmax函數,得到最終的輸出概率分布(Output Probabilities),即對下一個可能輸出的預測。每個模塊的作用:
- 多頭注意力(Multi-Head Attention):讓模型在計算注意力時能夠綜合不同子空間的信息。
- 前饋全連接網絡(Feed Forward):每個位置上應用相同的全連接網絡,用于非線性變換。
- 殘差連接和
- 英文回答
This diagram represents the model architecture of the Transformer, a neural network architecture that relies entirely on self-attention mechanisms for natural language processing tasks.The Transformer consists of two main sections: the encoder (on the left) and the decoder (on the right).**Encoder:**
- Inputs: The raw input tokens are first converted into fixed-size vectors through the "Input Embedding" layer.
- Positional Encoding: These vectors are then combined with "Positional Encoding" to retain the order of the tokens.
- Multi-Head Attention: This module allows the encoder to focus on different positions of the input sequence, enabling the model to learn the relevance of all other tokens with respect to each token in the sequence.
- Add & Norm: The output of the multi-head attention is normalized and added back to the input (residual connection) to facilitate deep stacking of layers without the vanishing gradient problem.
- Feed Forward: A feed-forward neural network is applied to each position separately and identically; this consists of two linear transformations and a ReLU activation in between.
- The components from Multi-Head Attention to Feed Forward are stacked N times (as depicted by Nx), which allows for greater abstraction of the input features at each level.**Decoder:**
- Outputs (shifted right): The target sequence tokens are similarly embedded and positionally encoded. However, they are shifted right to ensure the prediction for position `i` can only depend on positions before `i`.
- Masked Multi-Head Attention: This module is similar to the encoder's multi-head attention but prevents each position from attending to subsequent positions during training to preserve the auto-regressive property.
- Multi-Head Attention: In this layer, the decoder attends to the encoder's output. This allows the decoder to focus on relevant parts of the input sequence.
- Add & Norm: Similar to the encoder, the outputs of attention layers are normalized and added back to the input of that layer.
- Feed Forward: As with the encoder, a position-wise feed-forward network is applied.
- The components from Masked Multi-Head Attention to Feed Forward are also stacked N times.
- Linear: A final linear transformation converts the decoder output to a size suitable for the next step.
- Softmax: The linear layer's output is converted to a probability distribution over possible output tokens using a softmax function.The final output is the probability distribution of the next token in the sequence, given the previous tokens in the output sequence and the entire
總結
對于不介意看英文的同學來說是一個很不錯的工具,只可惜對中文的支持還是比較欠缺,當然這個不是插件的問題,而是GPT本身對中文就不夠友好,希望之后的版本可以加強一下這方面吧



)
:Geometry函數)






)

 - 思路總結)
)
)
)


