🌈 博客個人主頁:Chris在Coding
🎥 本文所屬專欄:[高并發內存池]
???前置學習專欄:[Linux學習]
??我們仍在旅途? ? ? ? ? ? ? ? ? ? ?
 ?
?
目錄
前言
? ? ? ? 項目介紹
1.內存池
? ? ? ? 1.1 什么是內存池
????????池化技術
????????內存池
? ? ? ? 1.2 為什么需要內存池
????????效率原因
????????內存碎片問題
????????1.3 實現定長內存池理解池化技術
????????定長內存池的設計
????????_freelist的設計
????????New()和Delete()的設計
????????與malloc()做性能對比
前言
? ? ? ? 項目介紹
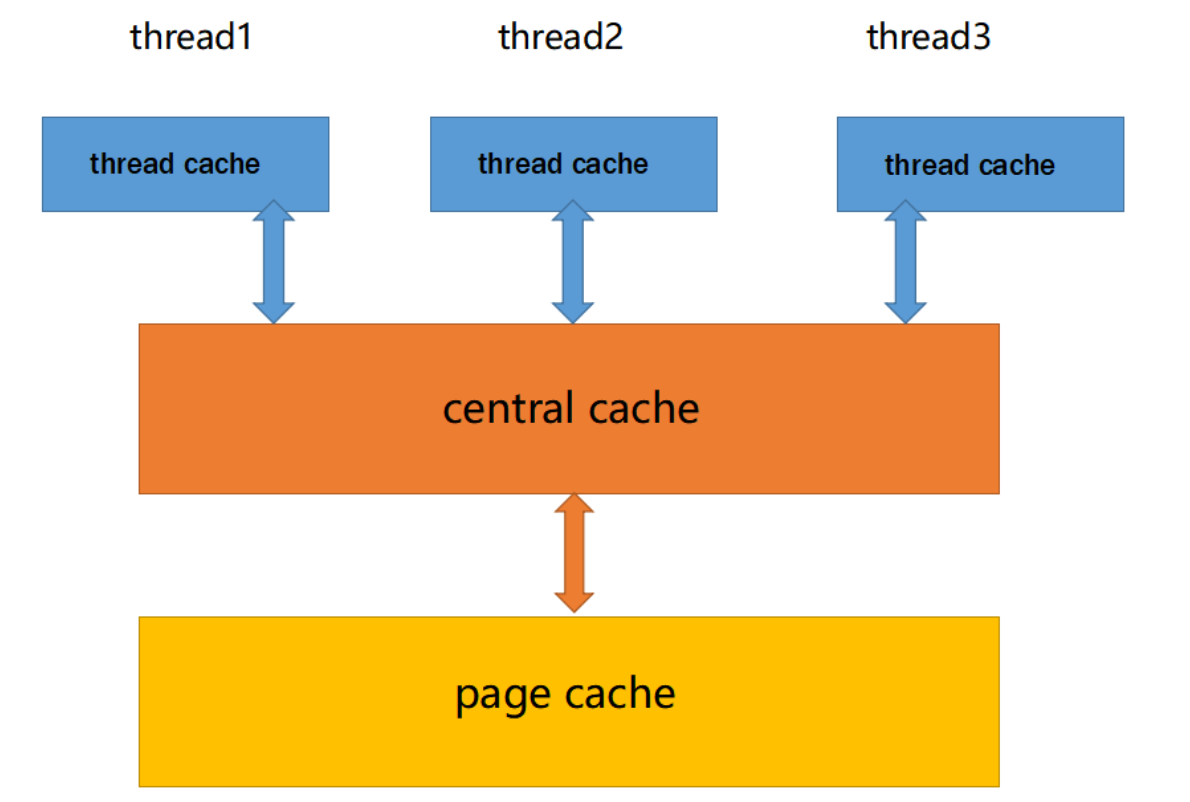
首先,本項目的原型是Google的一個開源項目TCMalloc,TCMalloc是谷歌開發的一種內存分配器(Memory Allocator),專門用于優化大規模的多線程應用程序的內存分配和管理。TCMalloc的全稱是Thread-Caching Malloc,意為線程緩存內存分配器。它最初是為谷歌的服務器應用程序而開發的,旨在解決大規模多線程服務器應用程序中內存分配性能不佳的問題。

Google作為世界級大廠,學習并復現該項目,?我們能體會到其精妙的項目架構設計
1.內存池
? ? ? ? 1.1 什么是內存池
池化技術
池 是在計算機技術中經常使用的一種設計模式,其內涵在于:將程序中需要經常使用的核心資源
先申請出來,放到一個池內,由程序自己管理,這樣可以提高資源的使用效率,也可以保證本程
序占有的資源數量。 經常使用的池技術包括內存池、線程池和連接池等,其中尤以內存池和線程
池使用最多。
內存池
內存池(Memory Pool)是一種動態內存分配與管理技術,旨在優化內存的分配和釋放過程,減少內存碎片化,提高程序和操作系統的性能。通常情況下,程序員直接使用諸如new、delete、malloc、free等API進行內存的申請和釋放,但這種方式容易導致內存碎片化問題,尤其在長時間運行的情況下性能表現更為明顯。
?內存池的工作原理是在程序啟動時預先申請一大塊內存作為池,之后在程序運行過程中,從這個內存池中動態分配內存給程序使用。當程序需要內存時,可以直接從內存池中取出一個空閑的內存塊;當程序釋放內存時,將釋放的內存塊重新放回內存池中,以備后續使用。同時,內存池會盡可能地與周邊的空閑內存塊合并,以減少內存碎片的產生。如果內存池的空閑內存不足以滿足程序需求,內存池會自動擴大,向操作系統申請更大的內存空間。
內存池的優點包括:
- 減少內存碎片化:通過提前申請一大塊內存并動態分配管理,內存池可以有效減少內存碎片的產生。
- 提高性能:內存池避免了頻繁的內存申請和釋放操作,從而減少了系統開銷,提高了程序和操作系統的性能。
? ? ? ? 1.2 為什么需要內存池
效率原因
假設你是一個圖書管理員,你管理著一個圖書館的書籍。每當有讀者來借書時,你需要為他們分配一本書。如果每次有讀者來借書時都去印刷新書(動態分配內存),等讀者歸還書籍后再銷毀書籍(釋放內存),那么你將花費大量的時間和精力來管理這個過程,而且頻繁的印刷和銷毀書籍會帶來一定的成本和效率損失。
相反,如果你有一個固定數量的書庫(內存池),這些書籍已經預先準備好并且處于待命狀態。當讀者來借書時,你只需要從書庫中選擇一本可用的書分配給他們,歸還后書籍繼續留在書庫中等待下一個讀者的到來。這樣可以避免頻繁的書籍印刷(內存分配)和銷毀(內存釋放),節省了時間和成本,提高了效率。
內存碎片問題

假設我們直接在堆上直接申請內存,依次申請出8ytes,24bytes,10bytes,20bytes,此時堆上還剩8bytes沒被申請,而這時候我們向堆歸還了原先的24bytes和20bytes的內存,這時如果我們想再去堆上申請一個30bytes的內存是申請不出來的,但是實際上我們此時空余的內存達到了52bytes,但可惜的是我們無法湊出連續的30bytes內存塊.而這也就是所謂的外部內存碎片問題.
內存碎片問題通常被分為內部碎片問題和外部碎片問題。這兩種碎片問題都是指在內存管理過程中未被有效利用的內存空間,但它們的來源和解決方法略有不同。
-
內部碎片問題(Internal Fragmentation): 內部碎片是指已經被分配給進程或對象的內存空間中,由于未被完全利用而產生的空閑部分。這種情況通常出現在動態內存分配中,比如在分配內存時,由于分配的內存塊大于所需大小,導致分配的內存中存在一些未被使用的空間。內部碎片問題通常由內存分配算法引起,例如,如果使用固定大小的內存塊進行分配(如固定大小的內存池),而分配的內存大小與需求不匹配,就會產生內部碎片。
-
外部碎片問題(External Fragmentation): 外部碎片是指未分配給任何進程或對象的內存空間中的零散碎片。這些碎片可能由已釋放的內存塊留下,但由于它們的大小和位置不符合當前內存分配需求,因此無法被有效利用。外部碎片問題通常由內存釋放操作引起,釋放的內存塊使得內存空間出現了不連續的空閑區域,這些零散的空閑區域無法滿足大塊內存分配的需求,從而產生了外部碎片。
????????1.3 實現定長內存池理解池化技術
malloc
在C/C++編程中,當我們需要動態分配內存時,確實不是直接與操作系統打交道,而是通過諸如malloc這樣的函數來完成。malloc是一個C標準庫提供的函數,它幫助我們從計算機系統的堆內存區域請求一定數量的連續內存空間。
在C++中,new關鍵字則是用來進行動態內存分配的另一種方式,它本質上是對malloc功能的擴展和封裝,不僅分配內存,還能自動調用構造函數初始化對象(對于類類型數據)。當你使用new分配數組或對象時,它會確保每個元素或對象都被正確初始化。而delete關鍵字在釋放內存的同時,也會調用析構函數來清理對象。

不同編譯器和操作系統環境下,malloc的具體實現可能會有所不同。例如,在Windows下的Visual Studio編譯器中,malloc由微軟進行了特定的優化實現;而在Linux系統下,采用glibc庫的編譯器(如GCC)則使用ptmalloc作為默認的malloc實現。這些實現通常包含高級算法,旨在提高內存分配的效率、減少碎片并滿足各種內存需求。
定長內存池的設計
malloc函數作為一個通用的內存分配器,它可以接受任意大小的內存請求,并試圖在堆上找到合適的連續空間進行分配。然而,由于它的通用性,它必須處理各種尺寸的請求,這可能導致內部碎片(即分配出的內存塊之間存在無法使用的空隙),并且每次分配或釋放都需要一定的查找和維護成本,所以對于特定場景而言,其性能可能不如針對性設計的內存管理方案。
定長內存池(Fixed-size Memory Pool)正是這樣一種針對性的設計,它適用于那些內存塊大小固定的場景,例如在大量創建和銷毀相同大小對象的應用中。在定長內存池中,內存預先按照固定大小進行劃分,申請和釋放內存的操作可以簡化為從池中取出或歸還一個預設大小的內存塊,無需像malloc那樣復雜的尋找合適大小的空間。這種做法能夠顯著減少內存分配和釋放的開銷,消除內部碎片。
通過從零實現一個定長內存池,我們可以更直接的理解池化技術,同時也是在為高并發內存池項目的實現做鋪墊。
template<class T, long long Nums>
class ObjMemoryPool
{
public:ObjMemoryPool():_freelist(nullptr), _pool(nullptr), _remainder(0){}T* New(){}void Delete(T* obj){}
private:void* _freelist;char* _pool;size_t _remainder;
};我們首先寫出定長內存池類ObjMemoryPool的大致框架,同時使用可變模板參數class T表示定長內存池存儲的對象的類型和long long Nums來表示每次內存池預先申請多少個T大小的空間。
同時我們后面會通過一個_freelist來實現對回收對象的管理,_remainder則表示內存池剩余的字節數,同時我們會留出接口New(),Delete(),來調用以申請和銷毀對象。
_freelist的設計
這里我們將_freelist(自由鏈表)設計成一個不帶頭的單向鏈表,把每個回收的對象當作鏈表的節點鏈接存儲維護。

我們會從每一個對象的內存塊中取出一塊來存放下一個內存塊的地址來實現指針鏈接
但是這個時候我們會遇到一個問題:指針的大小在32位和64位下的大小不一致,如何在32位平臺取出4個字節,而在64位平臺下取出8個字節呢?
void* nextobj = *(void**)obj;這里通過將當前obj對象的指針強轉為void**類型,即認為obj指向一個指針類型,這時候直接解引用該指針就一定是取出一個指針大小的內存塊,我們就可以在其中讀取或者寫入下一個內存塊的地址。
New()和Delete()的設計
由于是_freelist是單向鏈表,這里我們將節點的插入與取出都設計成O(1)時間復雜度的頭插和頭刪。
Delete()
void Delete(T* obj)
{obj->~T();*(void**)obj = _freelist;_freelist = obj;
}Delete()接口的實現最簡單,我們只需要去調用內存塊中對應類型的析構函數,再直接將其頭插進_freelist里面即可。
?直接向堆申請空間
這里我們的項目將擺脫與malloc的聯系,直接向堆申請空間使用和管理。
要想直接向堆申請內存空間,在Windows下,可以調用VirtualAlloc函數;在Linux下,可以調用brk或mmap函數。這里我在Windows下便選擇使用VirtualAlloc函數。
#ifdef _WIN32#include <windows.h>
#endifinline static void* SystemAlloc(size_t kpage) {
#ifdef _WIN32void* ptr = VirtualAlloc(0, kpage << 13, MEM_COMMIT | MEM_RESERVE, PAGE_READWRITE);
#endifif (ptr == nullptr)throw std::bad_alloc();return ptr;
}
inline static void SystemFree(void* ptr)
{
#ifdef _WIN32VirtualFree(ptr, 0, MEM_RELEASE);
#endif
- 0:此參數指定要分配的區域的起始地址。當設置為0時,系統會確定在哪里分配該區域。
- kpage << 13:此參數指定要分配的內存大小,VirtualAlloc 函數返回的內存區域地址會在頁邊界上對齊,頁大小通常是4KB(即2的12次方字節),這里就是指我們一次申請的內存塊大小為kpage頁
- MEM_COMMIT表示根據需要分配已提交頁面的物理存儲或后備空間。
- MEM_RESERVE表示保留進程虛擬地址空間的一段范圍,而不分配任何實際的物理存儲。
- PAGE_READWRITE:此參數指定區域的內存保護。在這種情況下,它允許對分配的內存進行讀取和寫入。
?_RoundUp()對齊
inline size_t _RoundUp(size_t size, size_t alignsize)
{if (size % alignsize == 0){return size / alignsize;}return size / alignsize + 1;
}既然我們是選擇以頁為單位申請內存塊,?這里我們在申請內存前就要將申請的內存大小向上取整對齊頁的大小,這里的alignsize使用時就傳入一頁的字節大小。
New()
T* New()
{T* allocate = nullptr;if (_freelist){allocate = (T*)_freelist;_freelist = *(void**)_freelist;}else {if (_remainder < sizeof T){size_t kpage = (_RoundUp(sizeof T * Nums, 1 << 13) >> 13);_remainder = sizeof T * Nums;_pool = (char*)malloc(_remainder);if (_pool == nullptr){throw std::bad_alloc();}}allocate = (T*)_pool;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_pool += objSize;_remainder -= objSize;}new(allocate) T(); //定位new,顯示調用T的構造函數初始化if (allocate == nullptr){int n = 0;}return allocate;
}- 用于從內存池中分配一個新的對象。如果有空閑對象可用,則從 _freelist 中獲取一個,并將 _freelist 指向下一個空閑對象。
- 如果沒有空閑對象,則從內存池 _pool 中分配新的內存,如果剩余空間不足以容納一個對象,則重新分配內存池。
- 在分配的內存位置使用定位 new 構造一個類型為 T 的對象,并返回指向該對象的指針。
與malloc()做性能對比
完整代碼:
#pragma once
#include <iostream>
#include <vector>
#include <time.h>
using std::cout;
using std::endl;
inline size_t _RoundUp(size_t size, size_t alignsize)
{if (size % alignsize == 0){return size / alignsize;}return size / alignsize + 1;
}
template<class T, long long Nums>
class ObjMemoryPool
{
public:ObjMemoryPool():_freelist(nullptr), _pool(nullptr), _remainder(0){}T* New(){T* allocate = nullptr;if (_freelist){allocate = (T*)_freelist;_freelist = *(void**)_freelist;}else {if (_remainder < sizeof T){size_t kpage = (_RoundUp(sizeof T * Nums, 1 << 13) >> 13);_remainder = sizeof T * Nums;_pool = (char*)malloc(_remainder);if (_pool == nullptr){throw std::bad_alloc();}}allocate = (T*)_pool;size_t objSize = sizeof(T) < sizeof(void*) ? sizeof(void*) : sizeof(T);_pool += objSize;_remainder -= objSize;}new(allocate) T(); //定位new,顯示調用T的構造函數初始化if (allocate == nullptr){int n = 0;}return allocate;}void Delete(T* obj){obj->~T();*(void**)obj = _freelist;_freelist = obj;}
private:void* _freelist;char* _pool;size_t _remainder;
};
struct TreeNode
{int _val;TreeNode* _left;TreeNode* _right;TreeNode():_val(0), _left(nullptr), _right(nullptr){}
};
int main()
{// 申請釋放的輪次const size_t Rounds = 5;// 每輪申請釋放多少次const size_t N = 100000;std::vector<TreeNode*> v1;v1.reserve(N);size_t begin1 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v1.push_back(new TreeNode);}for (int i = 0; i < N; ++i){delete v1[i];}v1.clear();}size_t end1 = clock();std::vector<TreeNode*> v2;v2.reserve(N);ObjMemoryPool<TreeNode,10000> TNPool;size_t begin2 = clock();for (size_t j = 0; j < Rounds; ++j){for (int i = 0; i < N; ++i){v2.push_back(TNPool.New());}for (int i = 0; i < N; ++i){TNPool.Delete(v2[i]);}int x=1;v2.clear();}size_t end2 = clock();cout << "new cost time:" << end1 - begin1 << endl;cout << "object pool cost time:" << end2 - begin2 << endl;return 0;
}1)定義了一個簡單的二叉樹節點結構 TreeNode,做為被測試申請釋放的obj類型
2)在 main() 函數中:
- 設置了兩組實驗參數:每輪申請釋放的次數 N 和申請釋放的輪次 Rounds。
- 創建了兩個空的 vector 容器 v1 和 v2,用于存放申請的節點指針。
- 對第一組實驗使用了直接使用 new 的方式進行內存分配和釋放。通過循環在每輪中申請 N 個節點,然后釋放它們,并清空容器。
- 對第二組實驗使用了自定義的對象內存池 ObjMemoryPool 進行內存分配和釋放。同樣地,通過循環在每輪中申請 N 個節點,然后釋放它們,并清空容器。 記
3)錄了每組實驗的開始和結束時間,并輸出兩組實驗的時間差,以比較它們的性能。 最后輸出了兩組實驗的耗時情況。
測試結果:
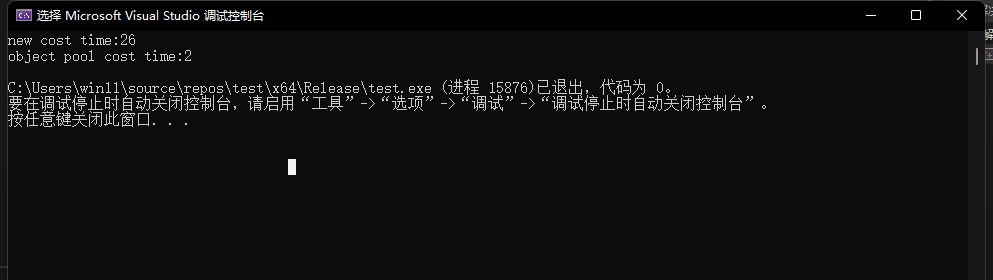
這里我們可以明顯看到,此時定長內存池的申請釋放效率明顯快過malloc和free
?
![]()
?


)

)





)
:Geometry函數)






)
