模型部署實踐 - BevFusion
- 思路總結
- 一、網絡結構 - 總結
- 1.1、代碼
- 1.2、網絡流程圖
- 1.3、模塊大致梳理
- 二、Onnx 的導出 -總體思路分析
- 三、優化思路總結
學習 BevFusion 的部署,看了很多的資料,這篇博客進行總結和記錄自己的實踐
思路總結
對于一個模型我們要進行部署,一般有以下幾個開發流程或思路:
- PyTorch 轉 ONNX 轉 TRT
- FP16 優化
- cuda-graph 優化
- INT8 量化優化
- ONNX 模型層面優化
- Pipeline 優化
- 模型內深度優化
我們需要先快速的去了解網絡,然后將其轉換成 Onnx 和 Tensorrt,然后再去根據結果進行二次優化
一、網絡結構 - 總結
1.1、代碼
Pytorch 代碼:https://github.com/mit-han-lab/bevfusion
CUDA-BEVFusion 部署代碼:https://github.com/NVIDIA-AI-IOT/Lidar_AI_Solution/tree/master/
1.2、網絡流程圖
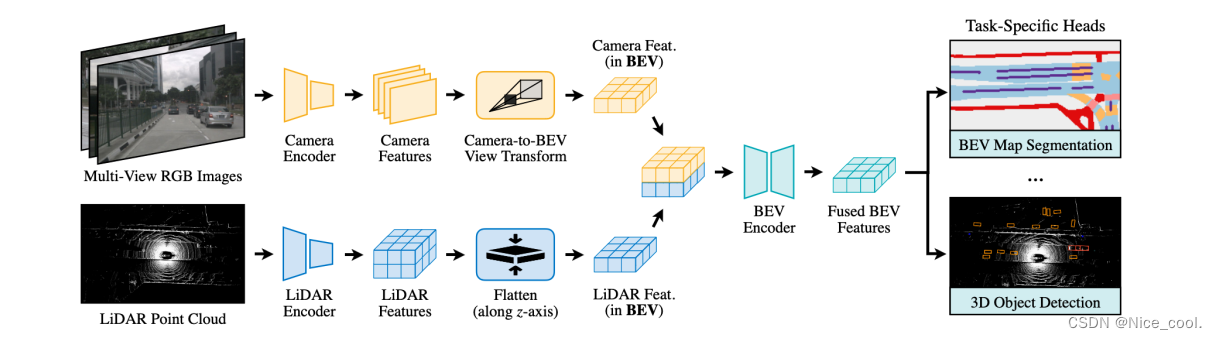
1.3、模塊大致梳理
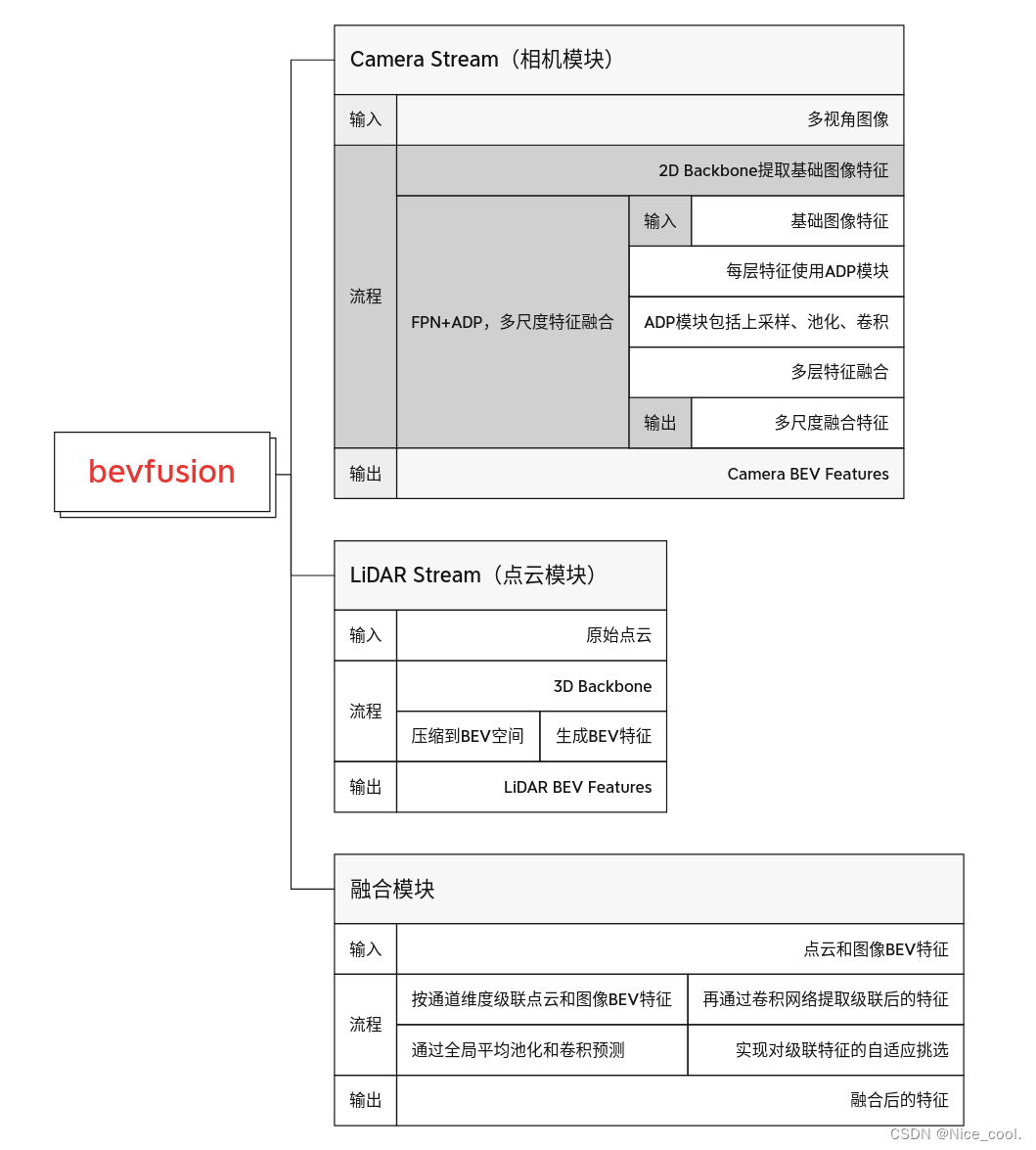
二、Onnx 的導出 -總體思路分析
在 CUDA-BEVFusion 的代碼中一共有五個 onnx ,說明作者是分模塊來導出 onnx 的。
| 模塊 | onnx 名稱 |
|---|---|
| Camera | camera.backbone.onnx |
| Camera | camera.vtransform.onnx |
| Fuse | fuser.onnx |
| Lidar | lidar.backbone.xyz.onnx |
| decoder + post | head.bbox.onnx |
- (1) 在 Camera 模塊 中導出了兩個 onnx,為什么要分兩個 onnx 導出?
-
因為 bev_pool 中有個下采樣的部分,會影響整個onnx的導出,所以才選擇分開兩個 onnx。第一個是backone相關的,第二個是bev_pool相關的
(2) Camera 的 backone 為什么選擇了 Resnet50? -
源代碼的 backone 是選擇了SwinTransform,但是由于 bev_pool 有大量的計算,并且SwinTransform含有大量的復雜計算,所以在部署的時候會選擇 Resnet50,因為它結構簡單,容易做量化且精度不會損失太大。
(3) 如何導出 bev_pool ? -
有兩種方式實現。
-
方法一: 做成 Plugin,但是這樣太麻煩,所以不太推薦
-
方法二:使用核函數實現,分成三個部分(
subclass機制) -
- bev_pool之前用onnx;
-
- bev_pool不導出onnx,用cuda核函數實現;
-
- bev_pool后的 downsample使用 onnx
(4) lidar模塊如何導出 onnx? -
因為模塊中包含 spconv ,pytorch不能直接導出onnx,所以使用 onnx.helper 自定義導出 onnx
(5) decoder部分為什么不能用int8? -
因為模塊中包含 transformer,并且Tensorrt推理中容易出現 NAN(這種情況極難解決)
三、優化思路總結
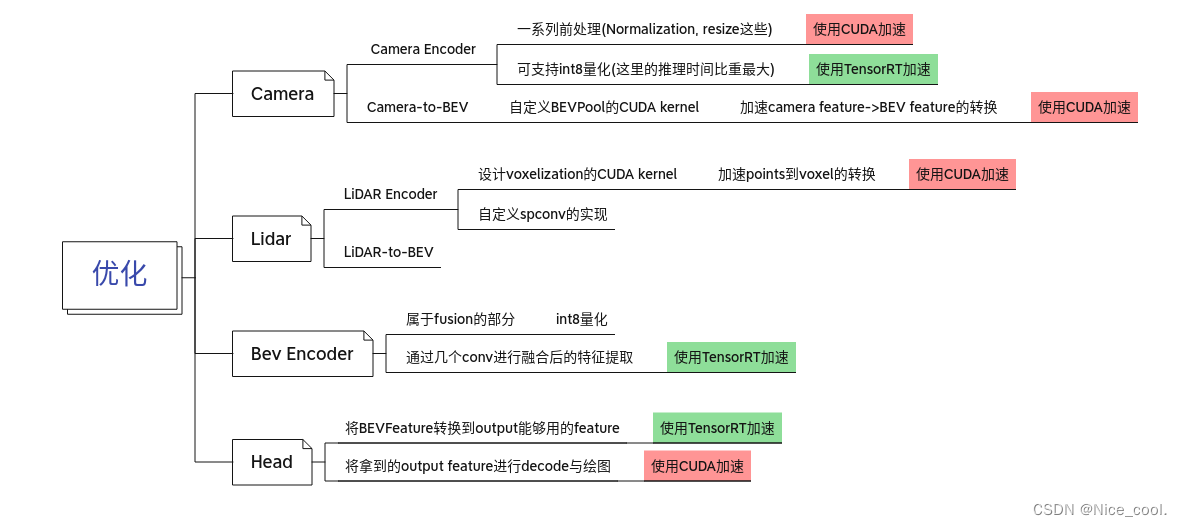
)
)
)





 - 天氣預報)

)







最長公共前綴)
)